

在本文中,我们将为读者详细介绍覆盖率导向的UEFI固件模糊测试技术。
在本文上一部分中,我们为读者介绍内存池Sanitizer,接下来,我们将为读者演示如何检测未初始化的内存泄露。
检测未初始化的内存泄露情况
在搜索与NVRAM变量有大量交互的UEFI驱动程序时,我们意外地在某个模块中发现了一个看起来很奇怪的函数。在使用efiXplorer对其进行注释后,反编译后的伪代码如下所示:
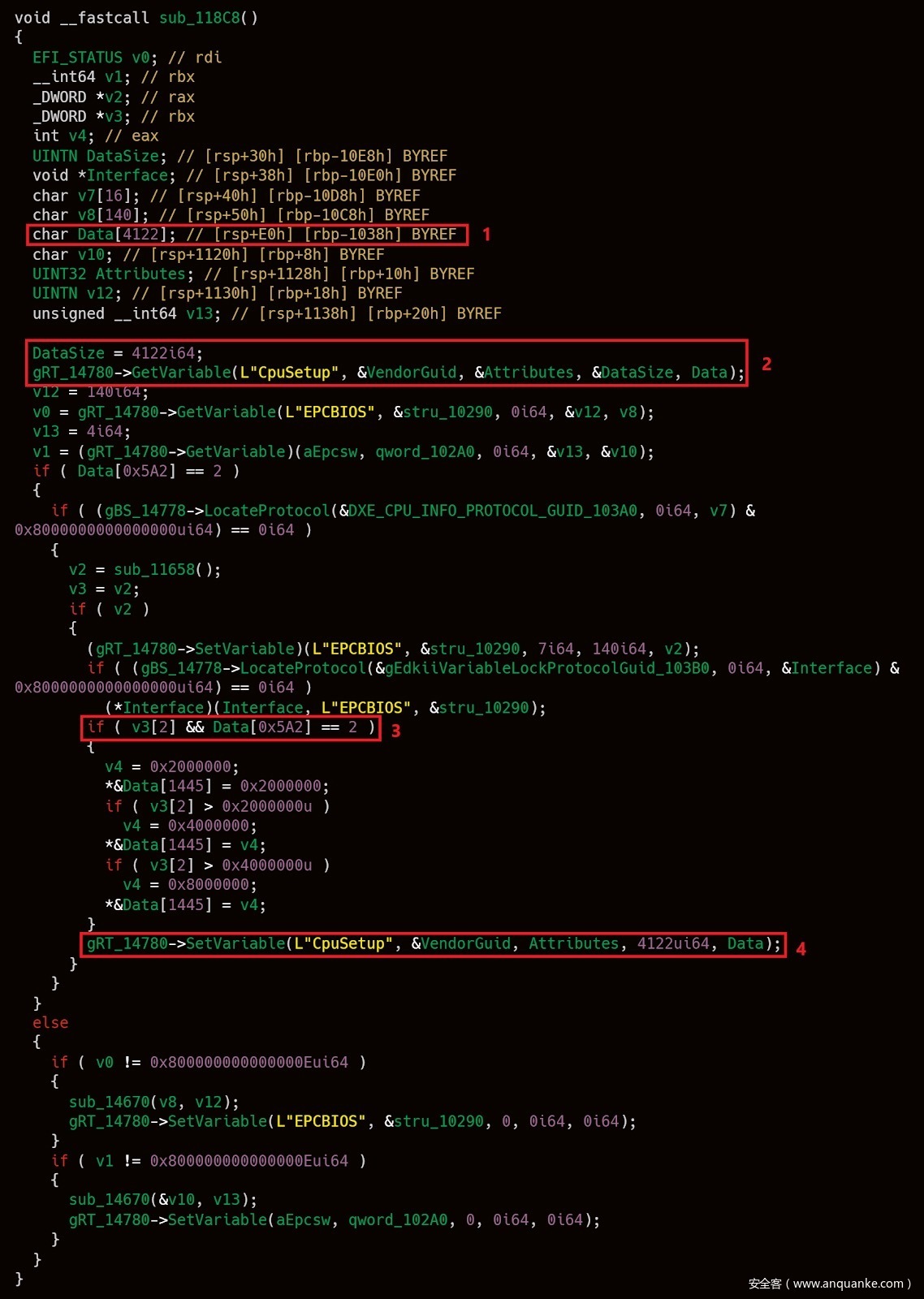
我们来仔细分析这个函数,看看它到底做了些什么:
- 首先(1),它在栈上分配了一个大小为4122字节的大型缓冲区。同时,这个缓冲区并没有初始化为零,所以,它目前存放的是之前函数调用的遗留数据。
- 之后(2),一个名为DataSize的变量被初始化为4122,也就是堆栈缓冲区的大小。然后,驱动程序调用GetVariable()服务,将一个名为CpuSetup的变量的内容读入栈缓冲区。结果,DataSize将被修改为反映从NVRAM中读取的实际字节数。
- 在进行一些其他无关紧要的操作后,它会对堆栈缓冲区的字节0x5A2与2的值进行比较(3)。
- 如果比较结果为真,则将修改后的堆栈缓冲区写回CpuSetup NVRAM变量(4)。注意,在写入时,驱动程序传递了一个4122的硬编码值作为缓冲区的大小。
就像我们在上一节说的,我们的假设是NVRAM变量至少可以被攻击者部分控制。一个有趣的问题是,如果我们将CpuSetup设置为短于4122字节的blob会发生什么。在这种情况下,我们可以清楚地看到,即使在调用(2)中的GetVariable()之后,堆栈缓冲区仍然会包含一些未初始化的字节。如果除此之外,我们还将字节0x5A2设置为等于2,那么这些未初始化的字节将作为处理(4)中SetVariable()调用的一部分写回NVRAM。由于NVRAM变量可以从操作系统中进行查询,所以使用这样的技术时,理论上我们可以公开最多4122 – 1442(0x5A2)=2680字节未初始化的栈内存。
我们很难相信这个特殊的漏洞可以在现实世界中被利用,因为我们怀疑有太多的东西依赖于CpuSetup的全部值,所以它不能被攻击者随意截断。然而,在Qiling提供的一个更加受控的环境下,我们可以设法将其用于PoC。为了达到这个目的,我们使用了一个可识别的标记字节在堆栈中下毒,这样的话,当这些标记字节被写回CpuSetup时,我们就能够发现它们的踪迹。读者可以在这里观看一段记录我们攻击过程的短视频。
虽然这个案例不具有现实的可利用性,但它向我们证明了NVRAM变量不仅可以作为攻击载体,而且还可以作为数据外泄的通道。根据特定的应用,泄露的数据可能是高度敏感的,或者是对攻击者非常有价值的,可用来利用其他漏洞或绕过平台的安全缓解措施(我们甚至可以想到用这种方式泄露SMRAM内存的SMM驱动程序)。总而言之,这个案例说服我们开始寻找自动检测此类信息泄露的方法。但是,在实践中如何才能做到这一点呢?
答案是,进行污点分析。从字面上来讲,污点分析的目的被卡耐基梅隆大学的研究人员定义为获得“跟踪源和汇之间的信息流的能力。任何程序值,如果其计算依赖于来自污点源的数据,则被认为是受污染的(……)。任何其他值被认为是未受污染的(……)。污点策略……旨在准确地了解程序执行时污点如何流动,什么样的操作会引入新的污点,以及需要对污点值进行什么样的检查。”
在典型的安全研究中,污点分析通常应用于用户控制的值,目的是发现程序的哪些部分可以被攻击者影响,以及影响的程度。在这里,我们将以一种非常规的方式来进行污点分析。我们不会污染未初始化的内存,而是会污染未初始化的内存并进行跟踪,以期最终将其暴露给NVRAM。
尽管从头开始构建x86架构的简单污点引擎并不是什么难事,但我们更喜欢使用更值得信赖的现成解决方案。在选择使用哪种污点引擎时,最突出的竞争者毫无疑问是Jonathan Salwan的Triton。当然,其他针对x86架构的引擎也有一些,并且各有其优点和缺点,但最终我们决定选择Triton,因为它比大多数引擎更适合Qiling。
实验:使用Triton进行污点分析
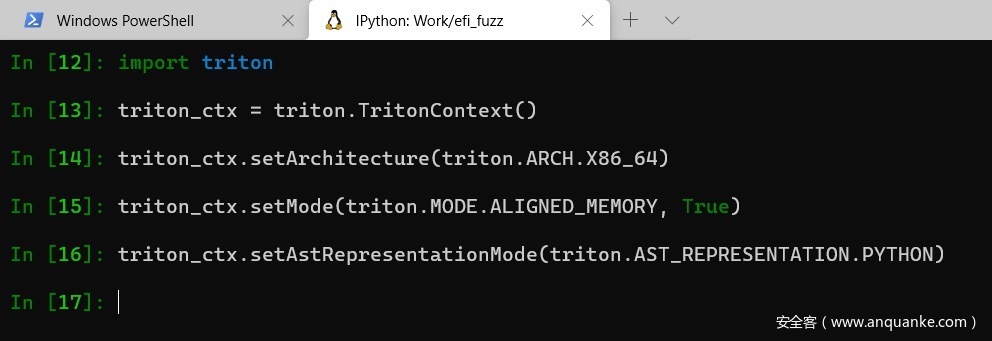
为了展示Triton的污点分析能力,我们将进行一些小型的概念验证演示。如果您认为自己已经有足够的污点分析实践经验,可以随意跳过这部分。要进行实验,请遵循以下步骤:
- 克隆、构建并安装Triton。为了确保Triton已被正确安装,请打开一个IPython shell并键入import triton,如果一切正常,说明安装成功了。
- 初始化一个TritonContext对象,具体如下所示:
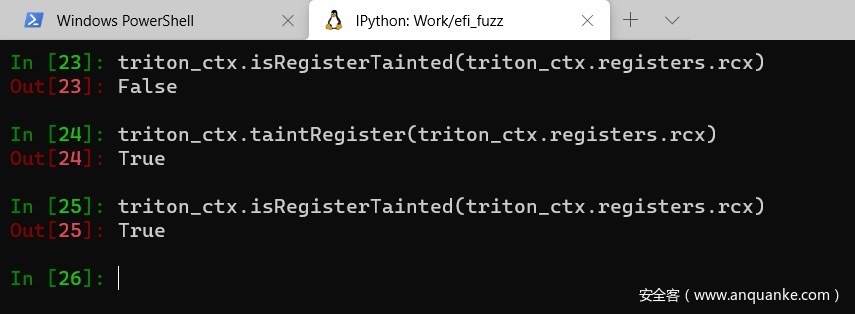
- 为了完成演示,让我们污染一个通用寄存器,比如说rcx寄存器。
- 现在,让我们处理一些x64指令,看看污点传播的情况。我们将使用一个简单的mov rax, rcx 指令,并期望污点会从一个寄存器传播到另一个寄存器。
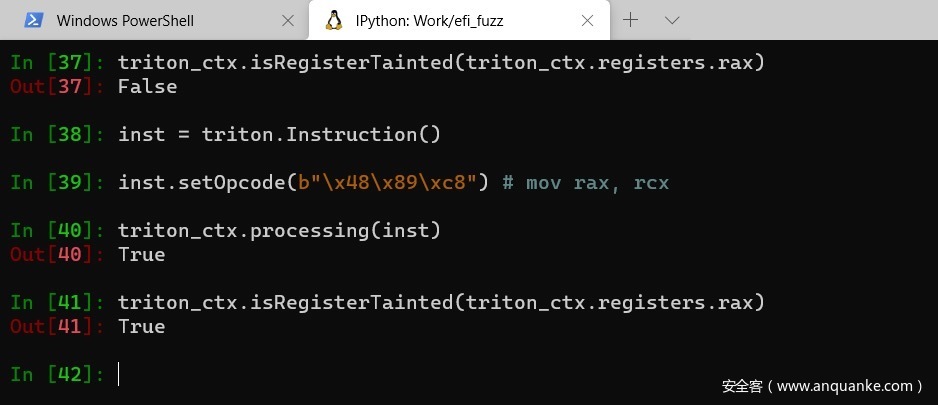
- 一旦rax寄存器被污染,我们就可以继续处理一些其他指令,很可能是那些执行内存存储的指令。另外,请注意rax寄存器的污染是如何隐式污染其所有子寄存器(如eax, ax寄存器等)的。
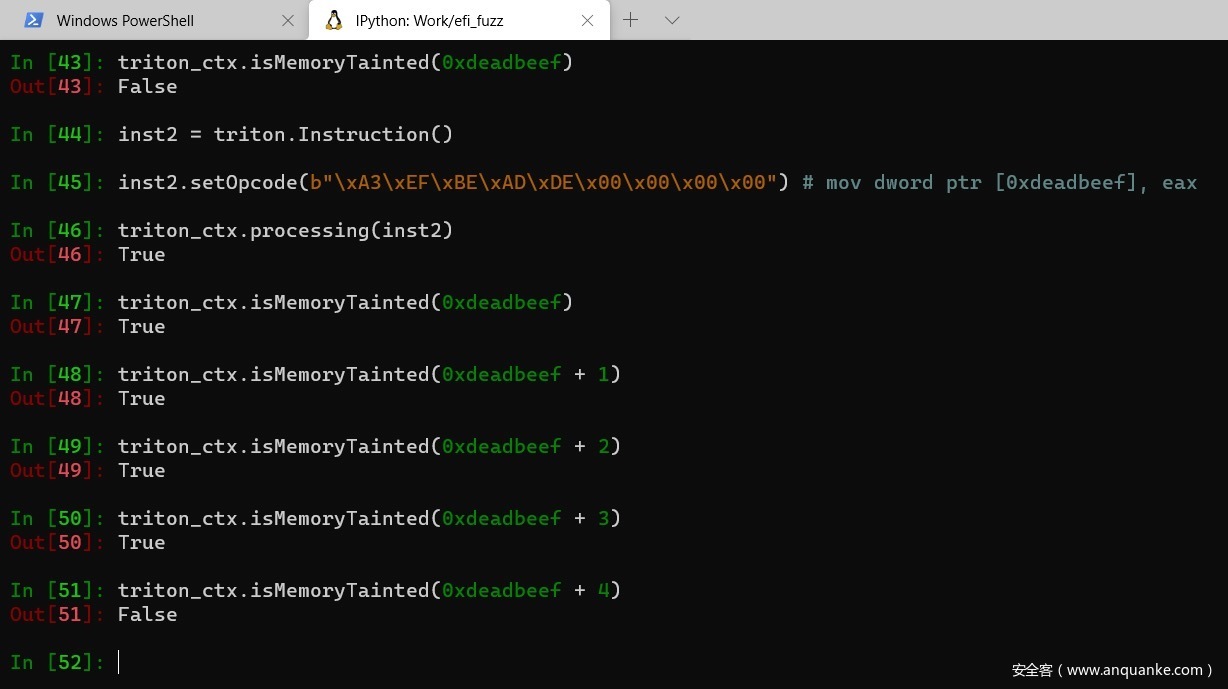
未初始化内存的来源:
和许多其他环境一样,UEFI中未初始化的内存主要来自两个方面:
- 内存池:正如第二篇文章提到的,内存池分配器的主要接口是一个名为AllocatePool()的引导服务,出于性能的考虑,它不会将缓冲区的内容初始化为零值。EDK2是UEFI的参考实现,它包含了一些更高级别的函数,比如AllocateZeroPool,并将其作为自己MemoryAllocationLib的一部分。然而,UEFI驱动程序可以(并且经常这样做)直接使用内存池相关的服务。
为了跟踪未初始化的内存池,我们在AllocatePool()上放置了一个post-op hook,并对缓冲区的地址范围进行了污染。

图12 AllocatePool()的污点传播
- 栈缓冲区:正如前面的例子所展示的,除非程序员明确初始化或者使用了InitAll等编译器标志,否则所有的栈缓冲区基本上都是未初始化的。为了污染栈内存,我们可以使用Qiling的hook_code函数来注册一个回调函数,这个回调函数针对每一条指令进行调用。通过该回调函数,我们可以使用Capstone引擎等反汇编程序库对指令进行反汇编和剖析。
基本上,为了检测未初始化堆栈缓冲区的“创建”,我们需要识别以固定字节数递减堆栈指针(x64平台中的rsp)的指令。通常,这些指令的形式是:sub rsp, imm,尽管我们注意到有时GCC会输出add rsp, -imm这样的代码。为了识别这两种情况,我们创建了一个名为is_rsp_decrement的小型实用函数,这里给出了这个函数。这段代码非常简单,这里就不做解释了。

图13 识别未初始化的栈缓冲区
遇到这样的指令并确定了递减量后,我们可以简单地将当前rsp和rsp-decrement之间的堆栈中的所有数据全部污染:
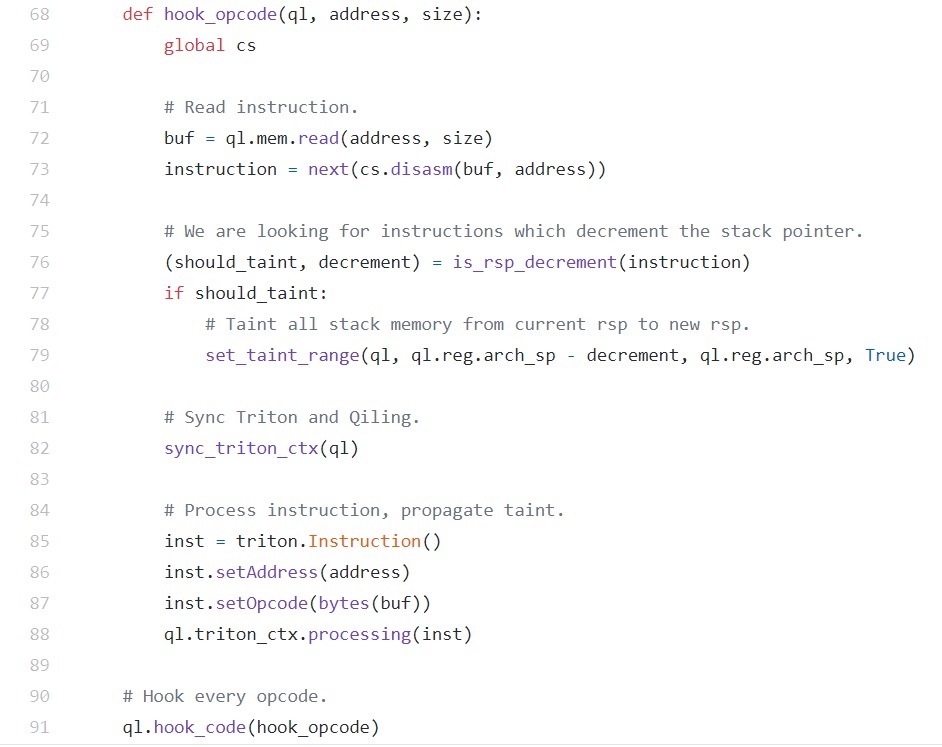
图14 我们使用per-instruction hook来污染未初始化的堆栈内存
最后一个难题是实际检查未初始化的内存是否被泄露。为此,我们在SetVariable()上放置了另一个post-op hook,然后检测数据缓冲区以查看其是否包含至少一个被污染的字节。如果是的话,我们会故意使该进程崩溃,以通知fuzzer刚刚发现了潜在的信息泄漏。
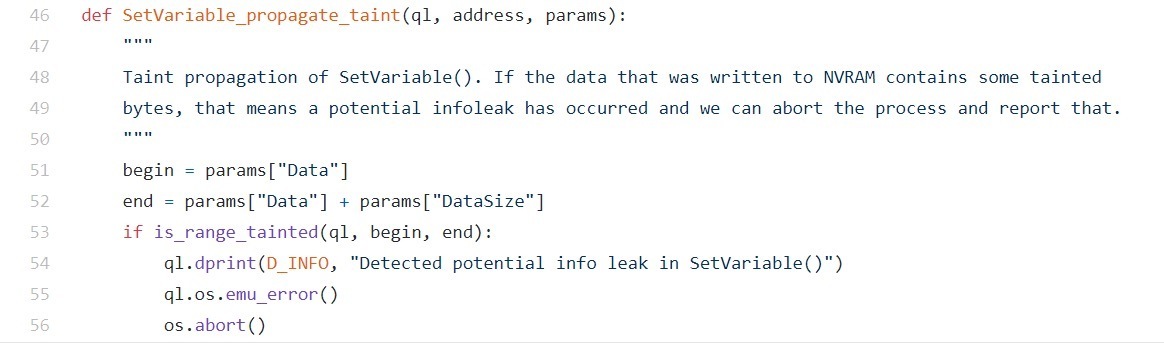
图15 将SetVariable()调用用作触发器来检查是否有污染(即未初始化)的数据将被泄露
小结
在本文中,我们为读者讲解了如何检测未初始化的内存泄露,接下来,我们将为读者详细介绍Efi-Fuzz与NotMyUefiFault方面的知识。
(未完待续)







发表评论
您还未登录,请先登录。
登录