

语音控制系统(VCS,voice controllable systems)的发展极大地影响了我们的日常生活,并促进了智能家居的应用。当前,大多数VCS利用自动语音验证(ASV,automatic speaker verifification)来防止各种语音攻击(例如,重放攻击)。在这项研究中提出了VMask,这是一种新颖实用的声纹模拟攻击,可以欺骗ASV智能家庭,并以伪装成合法用户的身份注入恶意语音命令。 VMask的主要观察结果是,ASV使用的深度学习模型容易受到语音输入空间中细微的干扰。为了产生这些微妙的扰动,VMask利用了对抗性样本的思想,然后通过向任意讲话者的录音中添加扰动,VMask会误导ASV将精心制作的语音样本分类,从而将之前的语音样本作为目标受害者。此外,利用心理声学中的声音掩蔽(psychoacoustic masking)在人类感知阈值以下操纵对抗性扰动,从而使受害者不知道正在进行的攻击。通过对灰盒(VGGVox)和黑盒(Microsoft Azure语音验证)ASV进行全面的实验来验证VMask的有效性。此外,在Apple HomeKit上进行的实际案例研究证明了VMask在智能家居平台上的实用性。
0x01 Introduction
随着智能家居环境的广泛部署,通过各种自动运行的家用电器(例如,加热器,门,窗户),我们的日常生活变得更加便捷和智能。在智能家居提供的各种用户接口(例如,图像,语音,运动传感器)中,语音接口起着关键作用,可以促进用户无需物理交互即可控制智能设备和服务。目前,语音接口已广泛集成在大多数流行的智能家居平台中(例如,Apple Homekit,Amazon Alexa,Microsoft Cortana),根据Grand View Research的报告,到2025年这些语音控制系统(VCS)的市场收入预计将达到318亿美元。
尽管语音接口带来了便利,但它也面临着越来越多的安全和隐私威胁。例如,重放攻击可能会通过重放预先收集的合法用户的语音样本来欺骗VCS。研究人员还试图利用麦克风电路的非线性和深度学习算法的缺陷来分别提出基于超声波的攻击或基于对抗性样本的攻击。在这些攻击中,恶意音频样本是无法察觉的,甚至可能被注入到由商用设备播放的音频中。
为了阻止这些攻击,流行的VCS广泛采用了自动说话者验证(ASV)或声纹识别技术来进行用户身份验证。借助ASV,语音可以用作唯一的生物特征签名,以反映一个人的身份。根据美国国家生物特征测试中心发布的“生物特征技术基础”,声纹是一种生物特征签名,其易于使用,准确性高,成本低。业界已广泛接受ASV作为重要的生物识别。从说话人的语音信号中提取语音特征以验证说话人身份的技术。例如,在执行任何操作之前,Apple设备要求“ Hey Siri”作为激活命令。微信和支付宝还支持声纹作为用户身份验证的重要替代解决方案。
尽管有研究正在探索VCS的语音识别组件中的漏洞,但对ASV的安全性的关注却很少。如果攻击者可以模拟受害者的声音,他就可以冒充受害者登录其帐户并进行随后的攻击,例如恶意的银行转账和下达命令,这对合法用户的安全构成了极大的威胁。但是,要向ASV发起实际攻击,它面临以下研究挑战。首先,模型设置(包括大多数ASV的体系结构建立和参数选择)保持私有状态,并且系统以黑盒子的方式工作。其次,在实践中,许多ASV在身份验证过程中添加了随机挑战,这使得重放攻击或组合攻击在智能家居环境中变得不切实际。因此,如何产生能够模拟目标用户的声纹的任意语音命令仍然是一个很大的挑战。
在本文中提出了针对智能家居环境中的ASV系统的第一种实际攻击,称为VMask,VMask的基本目标是允许源说话者(攻击者)模拟目标说话者(或受害者)的声音。对来自源说话者的一个良性语音样本进行一些精心设计的对抗性扰动,VMask能够生成攻击音频,听起来仍然像源说话者,但被ASV识别为目标说话者。为了发动这种成功的声纹攻击,攻击者仅需要目标说话者的一些录音,其中包含来自任意内容的声纹。
为了克服流行的ASV的黑盒特性,首先对灰盒系统进行了初步攻击,在灰盒攻击成功的基础上,利用了对抗性样本的可传递性,并针对实际的ASV系统发起了黑盒攻击。为了提高VMask的实用性,在对抗性音频生成过程中部署了心理声学的声音掩蔽,以使对抗性扰动保持在人类感知阈值以下,并避免引起人们的怀疑。评估结果表明,VMask可以成功突破包括灰盒VGGVox和黑盒Microsoft AzureSpeaker Recognition API在内的流行ASV。关于Apple HomeKit的真实案例研究也证明了VMask智能家庭环境的有效性。
0x02 Preliminaries
A.智能家居的语音接口
随着智能家居的广泛部署,语音接口已成为主要的用户接口。如下图所示,典型的VCS在四个阶段工作:语音捕获,用户身份验证,命令识别和命令执行。首先,在语音捕获中,对用户的语音样本进行记录和预处理。此后,基于从处理后的语音样本中提取的语音生物特征进行用户认证。仅当用户身份验证成功时,命令识别功能才能将语音转换为文本。最后,VCS根据识别的命令执行操作(例如,“开门”)。通常,用户身份验证和命令识别部分是分开的(例如,Apple Siri和Amazon Alexa要求用户在启动任何语音命令之前,分别说出激活词“ Hey Siri”和“ Alexa”)。

B.自动语音验证技术
如上图所示,用户身份验证阶段在VCS中扮演关键角色,以确保敏感操作(如短信和财务交易)的安全。最近,自动的扬声器验证(ASV)技术已被流行的VCS广泛采用,因为它只能使用讲话者的语音样本来验证讲话者的身份。大多数ASV都要求说出预定义的短语(例如“ Hey Siri”),并且仅在声纹匹配和音频内容匹配的情况下,身份验证才会成功。
ASV分三个阶段工作:开发,注册和验证。在开发阶段,将使用大型语料来训练塑造演讲者的背景模型。然后,在注册阶段,通过在背景模型的帮助下从注册话语中导出演讲者特定的信息来注册新演讲者。最后,将用户的语音样本作为验证阶段的输入,并计算输入特征与合法用户的语音样本之间的相似度。仅当相似性分数大于预定义的阈值时才通过验证。
深度学习的最新进展激发了基于神经网络的ASV的发展。它们也被称为语音嵌入系统( speaker embedding system),因为它们从说话者的话语中提取嵌入向量。借助于这些嵌入系统,可以通过测量嵌入向量的距离来进行说话人验证。本文仅研究基于深度学习的ASV,因为深度学习已成为ASV发展的主要趋势。但是,本文攻击不仅限于基于深度学习的模型,通过在不知道模型体系结构的情况下针对黑盒模型展示VMask的实现。
C.对抗性样本
对抗性样本是精心制作的数据记录,与原始记录相似,但可能导致机器学习模型的错误分类。如下图所示,给定基于机器学习的分类器F预测输入实例x的类别标签F(x),对抗性样本生成算法尝试找到满足以下条件的扰动δ:(1)x类似于x +δ按照给定的距离计算标准(例如,两个人听起来相似的音频片段); (2)F(x +δ)≠F(x)。在ASV的情况下,攻击者的目标是使用他们的语音样本x和对抗后扰动δ来操纵验证结果。
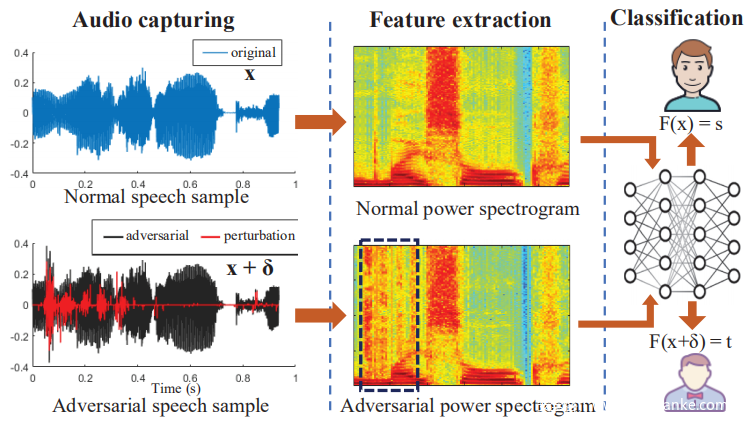
对抗性样本的根本原因在于神经网络对输入空间扰动的敏感性。在本文中,将对抗性音频的产生公式化为一个优化问题,并且可以使用基于梯度的方法来获得最佳置换δ。为流行的灰盒和黑盒ASV设计了两种不同的对抗性样本生成方案。
0x03 Threat Model
A.攻击场景
下图说明了VMask的典型攻击情形。有一个属于受害者的智能家居平台,ASV通过检查语义内容和声纹来验证输入的语音命令。 U表示一个声音不会使受害人产生怀疑的说话者。例如,U可以是受害者所熟悉的广播员。为了掩盖ASV而不引起受害者的怀疑(即无法部署重放攻击),VMask采取了三个步骤。首先,VMask通过ASV所需的语义上下文生成音频,将从U预先收集的语音片段连接起来。其次,VMask从在公共媒体上获得的受害者的语音片段中提取受害者的声纹并制作对抗性扰动,然后将扰动添加到最后,将生成的音频嵌入视频剪辑中,并使用靠近受害者的扬声器播放。受害者不会意识到这种持续的攻击,因为正在观看视频中的说话者U之类的对抗性声音,而没有将自己与声音相关联。
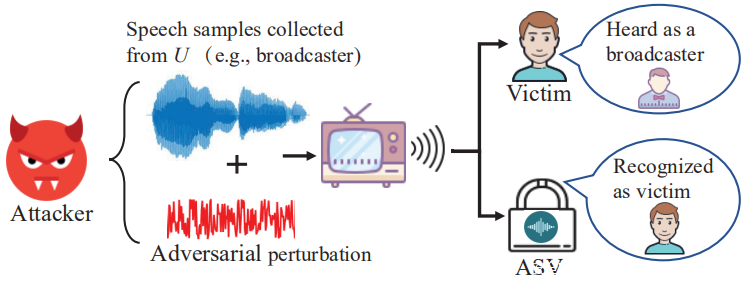
B.攻击者的能力
在这项研究中,假设VMask对用于ASV的神经网络模型(例如架构,参数和训练数据)了解为零。还假设VMask无法对商用音响和ASV的麦克风进行任何修改。但是,VMask可以劫持放置在目标ASV附近的音响以进行攻击。假设对受害者ASV模型有两种不同的访问方案:灰盒和黑盒。灰盒ASV随数字置信度值一起返回验证结果(接受或拒绝),而黑盒方案仅返回验证结果。请注意,灰盒和黑盒都没有向VMask显示模型设置信息。
0x04 Grey Box Attack
作为研究黑盒攻击之前的步骤,首先演示了对灰盒ASV进行攻击的可行性。由于灰盒ASV既返回了验证结果,又返回了置信度得分,因此灰盒攻击根据多个查询的相似性得分差异,然后动态更新生成的对抗性扰动。具体来说,利用零阶优化(zeroth order optimization)来提高匹配分数,同时保持音频内容不变。下图显示了灰盒攻击的直观图示。
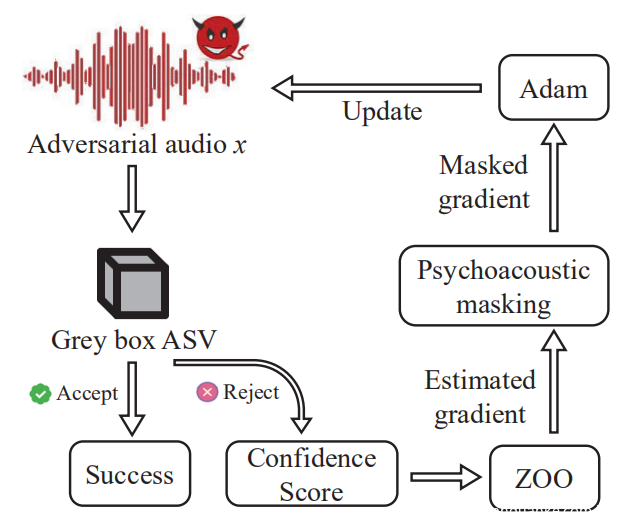
A.攻击公式
灰盒ASV系统V由两部分组成:V(x,P,t)= Vp(x,P)·Vi(x,t),其中x是要验证的音频,P是ASV要求的语义内容ASV,t声明的身份(即攻击情形中的受害者身份)。可以将Vp和Vi定义为:
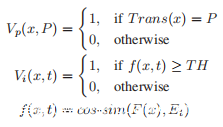
其中Trans(x)和F(x)分别是从x提取的语义内容和嵌入,Et是受害者说话者嵌入,cos-sim(·,·)计算余弦相似度,而T H是预定义的阈值。 Vp(x,P)检查x的转录是否与预定义短语P匹配,而Vi(x,t)检查x的声纹是否与目标说话者t匹配。然后,一旦提供了由源说话者s发出的音频剪辑x∈(-1,1)^ n,对手就会受到最小扰动Δx的约束,其受以下约束:
1)x被验证为受害说话人t的声音:Vi(x,t)= 1,即f(x,t)≥TH.
2)生成的音频x +Δx的语义内容保持不变:Vp(x +Δx,P)= 1 = Vp(x,P)。
3)扰动Δx很微小,人类无法察觉。
将上述问题公式化为优化问题。
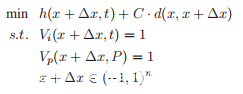
其中d(x,x +Δx)测量x和x +Δx之间的距离,h(x +Δx,t)评估攻击对f(x,t)的影响,C是d(· ,·)和h(·,·)之间的调节平衡系数。在本研究中,h(·)定义为:
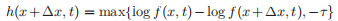
其中τ> 0是一个常数,用于指定优化的上限,作为等式中的损失函数。当log f(x +Δx,t)-log f(x,t)>τ时收敛。对于度量的距离(x,x +Δx),选择d(·,·)的L2距离度量。
请注意,Vp(x +Δx,P)= 1不包含在目标函数中,以提高攻击效率。相反,在获得最佳对抗性音频后检查音频转录。在适当的L2约束下产生的音频扰动不太可能改变音频内容。
B.零阶优化(ZOO)
VMask利用零阶优化解决了上述问题。形式上,通过对称差商技术通过两个查询h(x + zi,t)和h(x − zi,t)估计偏导数∂h(x,t)/∂xi:
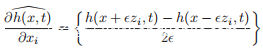
其中e是一个小常数(例如,本研究中e = 0.0001),而zi∈{0,1} ^ n是zi [i] = 1的单位向量。通过对受害人ASV进行2n次查询,可以计算所有n个坐标的偏导数。基于估计的梯度,可以执行各种基于梯度的方法来最小化h(x +Δx,t)。但是,对于单批更新而言,进行2n次查询对于对手来说太昂贵且不切实际。因此,利用加权随机坐标梯度下降方法来减少每次更新的成本。
在加权随机坐标梯度下降中,每个步骤仅更新一些坐标。考虑到坐标选择策略对优化效率的显着影响,使用加权采样策略而不是随机策略来选择更重要的坐标。权重向量是根据STFT如下计算的。
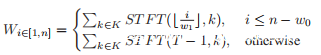
其中w0和w1表示FFT滑动窗口的跳长和窗口长度,STFT(T,K)是x的STFT。在W上进行L2归一化得到W*作为采样权重向量。
C.心理声学掩蔽
在以上公式中,L2距离用作正则化来约束对抗性扰动。在这项研究中,引入了心理声学掩蔽来改善这种正则化。心理声学研究了声音与其所引起的听力之间的关系。通过利用心理声学模型,VMask可以计算出表示不同频率之间的掩蔽阈值的听力阈值,然后利用听力阈值将对抗性扰动限制在人类感知阈值以下。
具体来说,首先在每次迭代中得出比例因子,然后将其乘以反向传播的梯度,得到最终的梯度。比例因子的作用类似于掩蔽,可抑制声音水平超过阈值的频率,同时允许对声音水平低于阈值的频率进行更多的干扰。用缩放矩阵S(x)重写梯度估计,其引入如下:
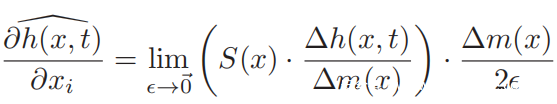
0x05 Black Box Attack
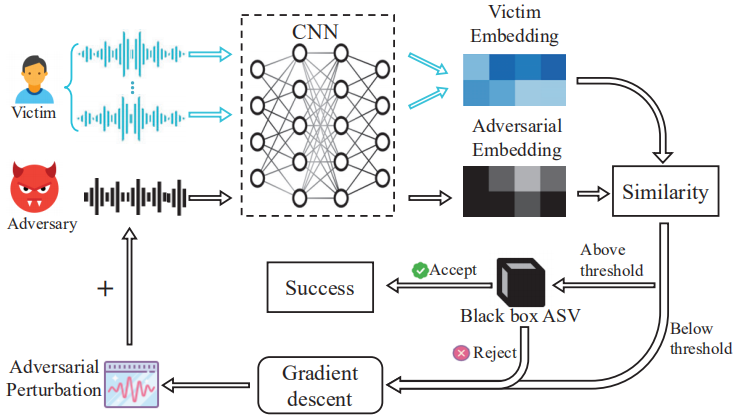
受最近在图像识别中对抗性攻击成功的启发,利用对抗性样本的可传递性来攻击黑盒ASV系统。黑盒攻击的基本思想是,尽管在ASV中使用的深度学习模型有所不同系统,它们都将高维音频空间投影到类似的低维语音空间中。结果,通过单独训练基于本地深度学习的ASV,可能能够模仿受害者黑盒系统。黑盒攻击的第一步是从嵌入有任意内容的多个受害者录音中提取嵌入的受害说话者语音。然后,从包含任意人说出的所需音频内容的音频开始,在受害人嵌入语音的指导下,仔细地向其中添加噪音。最后,能够生成包含所需内容和受害者语音记录的攻击音频。整个过程如下图所示。
A.获得说话者语音模型
本研究训练了ResNet风格的说话者嵌入系统,此CNN采用固定长度的音频作为输入。将时间平均应用于最后一个残差块的平坦输出,以计算话语级激活。此外,还利用了三重态损失,softmax预训练和难分样本挖掘。使用训练有素的说话者嵌入系统,可以通过对从受害者录音中提取的嵌入向量取任意平均值来获得512维说话者模型。
B.攻击音频生成
成功的攻击音频应同时包含必需的内容和受害人的声纹。为了满足第一个约束条件,从任意说话者对验证短语的发声中发起攻击。假设仅添加了细微的噪声,对抗性音频的内容就会发生微不足道的变化。为了满足第二个约束,首先从具有任意内容的几条录音中提取受害者嵌入Et,并使用Et作为准则来生成一些微妙的扰动,以便从对抗性音频中提取的嵌入在某种距离度量的意义上类似于受害者嵌入Et 。对黑盒攻击的表述与之前的方程式相同,不同的h(·)除外:
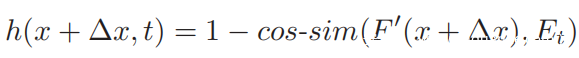
其中F’(x +Δx)表示为对抗性音频提取的嵌入矢量,而cos-sim(·,·)表示两个矢量之间的余弦相似性。当普通语音模型以声学特征为输入时,先前的攻击通过反转修改后的MFCC特征来生成攻击音频,这会带来较大的开销和信息丢失。以端到端的方式实施攻击,从而可以直接修改原始音频信号。具体来说,在说话者嵌入系统的前面实现了可区分的质谱图提取层。在说话人嵌入提取层之后添加一个损失层,以计算对抗性嵌入和受害者说话人嵌入之间的距离。这个端到端的神经网络允许应用反向传播来近似最佳对抗性扰动。
C.心理声学掩蔽
类似于前文所做的,心理声学模型被用来限制人类听觉阈值下的对抗性扰动。与灰盒攻击不同,不必估计偏导数,因为本地的说话者嵌入系统对本研究来说仍然是白盒。因此,根据链规则,可以根据以下公式计算损失函数相对于原始输入的梯度:
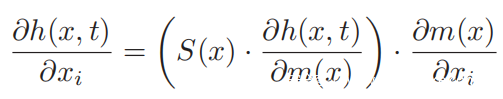
0x06 Evalution
A.评估设置
NVIDIA GeForce GTX 1070 GPU和Intel i7-8700K CPU用于生成攻击语音样本。为了验证攻击音频是否保留了所需的音频内容,使用了百度语音识别API来转录音频。使用一个独立于文本的自由语音语料库LibriSpeech作为评估集。train-clean-100包含来自251个扬声器的28539个发音,用于预训练黑盒的本地说话者嵌入系统,train-clean-360包含来自921个说话者的104014个发音,用于微调。dev-clean具有来自40个说话者的2703个发音,用作本地ASV系统和源音频的测试,为灰盒和黑盒ASV生成对抗性音频。
B.灰盒攻击
针对最先进的说话者嵌入系统之一VGGVox(在大型现实世界语料库Voxceleb2上开发)评估灰盒攻击。根据作者的说法,开源的ASV系统可以在Voxceleb2的测试集上获得3.95%的最佳EER。在python中实现了基于ZOO的攻击,使用Matlabengine API来访问灰盒matlab模型。对于参数选择,C设置为0.01,τ设置为2,以允许很大的扰动。由于VGGVox不提供阈值,因此基于VGGVox对dev-clean的评估结果确定阈值为0.45。至于STFT的计算,利用了一个FFT窗口,它的长度为0.25s,跳长为0.01s。
攻击试验是由一个测试集构建而成,该测试集由5位来自dev-clean的随机选择的说话者组成。对于每个说话者,对其他4个说话者进行对抗性扰动,从而进行了20次攻击试验。对于每个攻击试验,执行500次迭代,并且在每个迭代中,从25840个音频采样点中随机选择一批352个坐标,并使用默认参数的Adam优化器更新这些坐标,将学习速率设置为0.01。如果灰盒返回“接受”,则报告成功。最后,这20个试验的成功率达到95%。
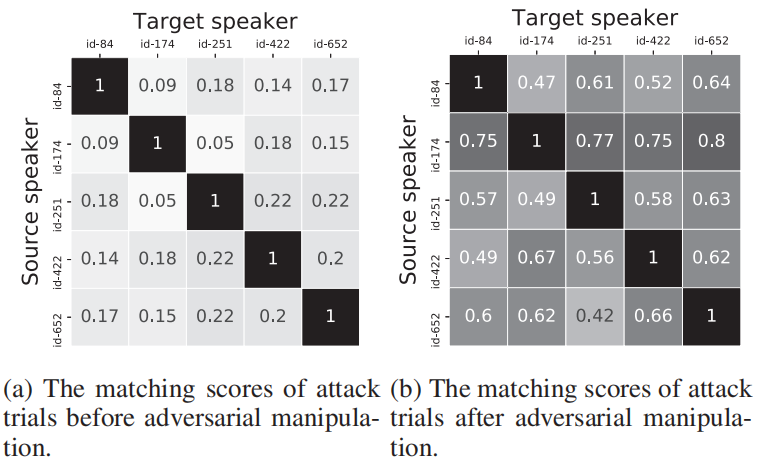
上图在两个混淆矩阵中显示了对抗性扰动前后的匹配得分。每个块中的值表示相应的源说话者话语经验证为相应的目标说话者的置信度得分。不考虑源说话者和目标说话者是同一个人的情况,因此在上图b中所有对角线元素都被设置为1。通过比较图a和b可以看到,在进行了细微的对抗操作后,置信度得分得到了显着提高,平均提高了306%。同时,由于平均SNR为13.13dB,所以对抗性扰动是可以接受的。
还检查转录结果,以查看内容是否保留在对抗性音频中。为了评估内容的扭曲程度,选择了语音识别中常用的三个度量,即WER(单词错误率),WRR(单词识别率)和SER(句子错误率)。在20个试验中进行评估,获得了9.804%的WER,90.196%的WRR和31.250%的SER,这意味着约70%的对抗音频与原始音频具有相同的转录,并且对抗音频中的单词具有相同转录的可能性转录比原始音频要大90%以上。此外,评估了λ对扰动的影响。在实验中尝试了不同的λ值0、10、20和40,最后让灰盒攻击和黑盒攻击中的λ= 10以获得相对较大的较早收敛扰动。
C.黑盒子攻击
1)说话者嵌入系统:应用VAD(语音活动检测)以消除语音样本中的非语音信号。然后将每个音频分为固定长度的音频片段,通过利用python包python speech feature提取形状为(160,64)的梅尔频谱图特征向量。
对于softmax预训练,使用0.001学习率的Adam优化器训练10个时间段后,可以达到83.12%的训练精度。然后,通过具有三重态损失的6000步微调,可以在测试集上达到大约99.2%的验证精度和大约3.5%的EER(平均错误率)。在以下实验中,利用此说话者嵌入系统进行说话者模型提取。
2)制作本地ASV系统的对抗样本:在Tensorflow平台上实施了攻击,总共进行了400次攻击试验。每个试验包含从dev-clean随机采样的两个不同的说话者,一个作为源说话者,另一个作为受害者说话者。在发起攻击之前,从5个随机选择的话语中提取每个说话者的嵌入。采用学习率为0.01的Adam优化器可最大程度地减少损失。观察到500次迭代后损耗的减少不明显,在以下实验中将迭代次数限制为500次。
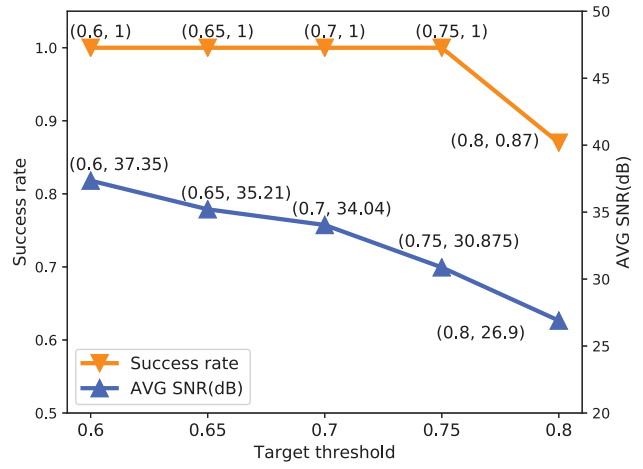
阈值是变化的,以观察在不同设置下的攻击性能。如上图所示,当目标阈值设置为0.6到0.75时,可以达到100%的成功率。即使将阈值设置为0.8,仍然可以达到87%的成功率。同时,平均SNR随着预定义阈值的增加而降低,这表明需要更大的扰动才能使得分越过更高的阈值。但是,攻击音频的平均SNR总是大于26dB,这意味着扰动太微妙,无法引起受害者的怀疑。
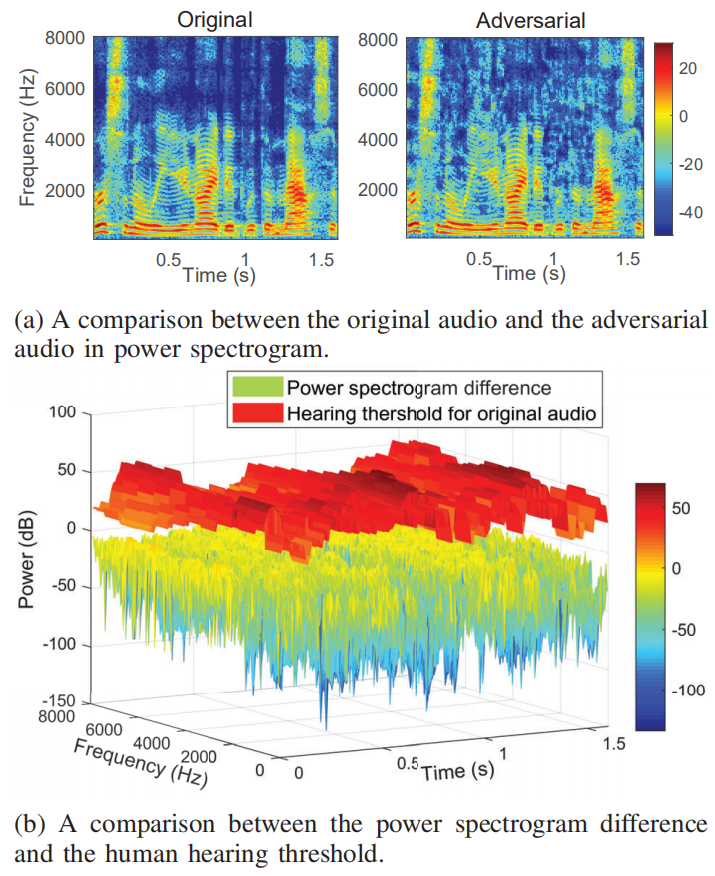
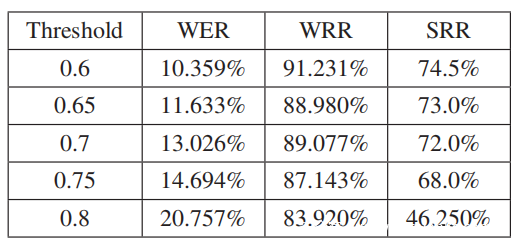
为了更好地理解对抗性扰动和心理声学掩蔽,在上图a中可视化了一个原始音频和相应对抗性音频的功率谱图,而声谱图和听力阈值的差异如图b所示。可以看到对抗性扰动得到了很好的控制,并且低于人类感知的阈值。原始音频和对抗性音频的转录之间的比较如下表所示。在最坏的情况下,攻击仍然能够达到20.757%的WER,aSRR为46.250%。当目标阈值从0.75移至0.8时,观察到WER急剧增加,SRR急剧下降。这可以归因于距离度量,其作用类似于迭代中的L2正则化器。
3)转移攻击:旨在展示VMask对黑盒子ASV系统(Microsoft Azure Speaker Verifification API(MS-ASV))的有效性。对于注册,用户必须从下表中选择一个短语,然后重复三遍。然后为了进行验证,用户必须说出相同的短语,只返回验证结果(接受/拒绝)和置信度值(正常/高/非常高)。
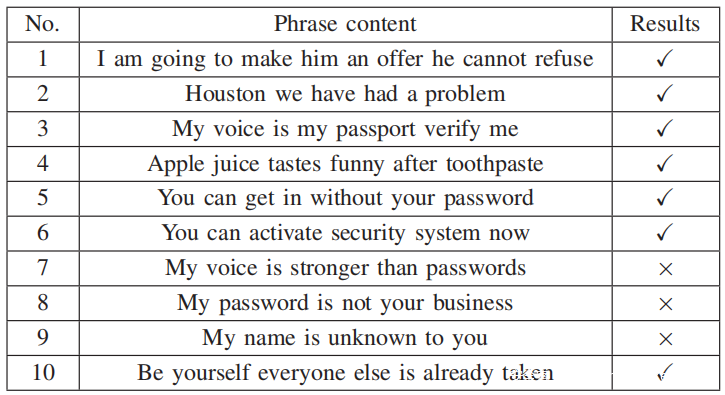
建立了一个真实的数据集,其中包含来自4个说话者的话语。对于每个说话者,从任意内容的3个语音样本中提取他们的说话者模型。还为每个说话者的10个验证短语中的每个短语收集了3个语音样本,这些样本被用作MS-ASV的注册,也被用作攻击的源音频。
对于每个短语,从一个说话者开始,与其他三个说话者进行对抗性的音频处理。最后,在黑盒MS-ASVAPI上评估制作的音频。如果至少可以绕过MS-ASV API一次,那么每个短语都会报告成功。如上表所示,攻击在欺骗MS-ASVAPI时达到了70%的短语级别成功率,这证明了VMask在黑盒设置中的有效性。值得注意的是,无法破坏3个短语。将失败归因于两个可能的原因:(1)MS-ASVAPI可能使用不同的模型架构(甚至是基于i向量的模型)。 (2)API的预处理技术可能会破坏对抗性噪声。
0x07 Case Study in Smart Home
A.系统设置
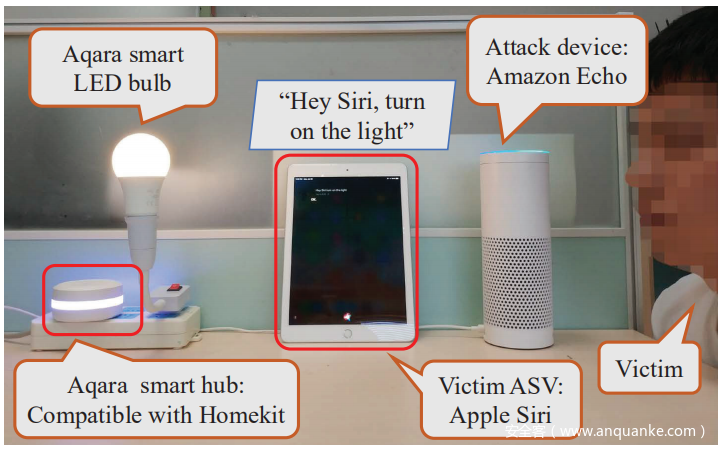
为了证明VMask的实用性,在流行的智能家居平台Apple Home Kit上进行了世界范围的语音模拟案例研究。在Apple HomeKit环境中,Siri用作语音接口并提供语音验证功能。如下图所示,家用电器(Aqara智能LED灯泡)通过与HomeKit架构兼容的Aqara智能集线器与Siri连接,允许用户通过说“嘿 Siri,打开灯”来打开灯泡。在这个实验中,招募了5名志愿者。首先,每个志愿者的说话者模型都是从包含任意内容的话语中构建的,然后在每个回合中,选择一名志愿者作为受害者。当受害者加入Siri时,要求其他4名志愿者说:“嘿Siri,打开灯光”六次,然后将这些样本用作黑盒攻击中的源音频。对抗性扰动已添加到源音频中。 音响(即Amazon Echo)用于播放对抗性音频,如果攻击成功,灯泡将变亮。继续选择不同的受害者自愿者,并在五种类型的Apple设备(即iPhone SE,iPhone 7 plus,iPhone 8,iPhone X,iPad 6)上进行了此实验,以确保VMask的通用性。
B.实验结果
首先评估VMask的攻击能力。将五台Apple设备分配给五位志愿者。然后,对于每位拿着受害者设备的志愿者,都会播放其他志愿者提供的对抗音频,对于每个受害设备,它遭受VMask攻击的次数为6×4 = 24次,成功的攻击时间如下图所示。据观察,平均成功攻击率达到81/120 = 67.5%,这意味着测试设备中的所有Siri都容易受到VMask攻击。注意到,不同的Apple设备之间的成功率是完全不同的。由于Siriis是在线ASV系统,因此出现这种现象的原因可以归因于硬件条件和设备所有者的语音配置文件的差异。
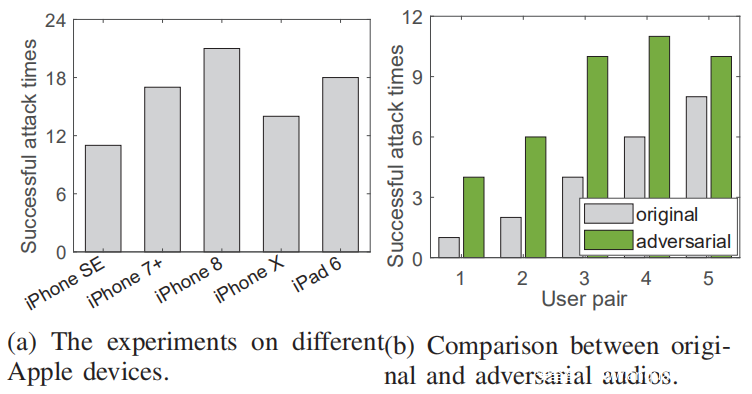
上图a中的高成功攻击率是由于Siri选择较低的验证阈值来保证用户体验这一事实引起的。现有研究表明,Siri区分说话者的能力并不理想。因此,为了证明对抗性音频的有效性,利用另一位志愿者的原始音频和对抗性音频分别攻击Siri 12次,然后在iPad 6设备上的5对志愿者中进行了这些实验。如上图b所示,在将对抗性样本添加为原始样本之后,成功的攻击时间(比率)从20(33.3%)增加到41(68.3%),这证明了VMask的攻击能力。值得注意的是,即使对于语音配置相似的第5个用户对,通过添加对抗性噪音,攻击成功时间(发生率)也从8(66.7%)增加到10(83.3%)。这进一步证明了VMask在现实世界的智能家居环境中的实用性。
0x08 Discussion
A.对策
为了防止ASV受到VMask的攻击,一种直观的策略是训练检测器以区分对抗性音频和良性音频。但是,需要大量的攻击音频。此外,此策略可能会引发ASV的错误警报,从而降低用户体验。另一种可能的防御机制可能集中在破坏对抗性干扰,可以使用降采样和降噪方法。但是,降采样和降噪可能会删除正确的用户语音信息,从而导致语音识别性能下降。活度检测(如虹膜活度检测)也可以用作防御方法。
B.局限性和今后的工作
尽管VMask具有良好的攻击性能并揭示了流行的ASV的安全漏洞,但本研究仍然存在局限性。主要限制是在现实世界的攻击环境中缺少噪声建模,这降低了VMask的成功率。建立噪声模型很困难,因为它需要考虑多种因素(例如,环境,音频硬件),这些因素已经发生了戏剧性的变化。此外,在现阶段,仍然需要提高灰盒攻击的扰动生成速度(即一次更新需要3秒)。为了解决这个问题,设计一种比加权随机梯度下降更好的算法是一种可行的解决方案。在研究的当前阶段,VMasks在不同句子上的表现各不相同。由于黑盒ASV的体系结构和参数对于攻击者是未知的,因此这仍然是一个未解决的问题。
0x09 Conclusion
在本文中提出了VMask,这是一种针对智能家居中ASV的新颖实用的声纹模拟攻击。 为了误导ASV的分类模型,VMask通过添加精心制作的噪声,使任意语音样本具有受害者的声纹。 VMask很实用,因为添加的声音太微小,无法引起受害者的怀疑。 提出针对灰盒和黑盒ASV的对抗性音频生成算法,并在VGGVox和Mi crosoft Azure平台上实施VMask。 最后,在Apple Home Kit平台上进行了攻击,实验结果证明了VMask在现实环境中的可行性。







发表评论
您还未登录,请先登录。
登录