

一、前言
到目前为止,针对Meltdown以及Spectre漏洞的利用技术仍然停留在PoC阶段,或者只是处于实验阶段,然而对于攻击者来说,想要完成这种技术的武器化只是一个时间问题。Meltdown以及Spectre漏洞的影响范围非常广泛,甚至可以影响1995年生产的主机。另一方面,如果某些企业处于欧盟的一般数据保护条例(GDPR)范围内,那么这两个漏洞对他们来说也是非常棘手的一个问题。
除了打上补丁、更新系统以外,企业或组织还需要制定更多的主动策略,来搜索、检测和响应这一安全威胁,这些策略对诸如Meltdown以及Spectre这样的大规模威胁来说尤为重要。
利用Intel处理器中的性能计数器我们成功研究出一种检测技术,可以检测利用Meltdown以及Spectre漏洞的攻击行为。这种技术可以测量缓存丢失情况(即应用程序所请求的数据没有位于缓存中),根据这些信息来检测利用Meltdown和Spectre漏洞的攻击行为。
现代CPU为了提升工作效率,会以推测方式来执行指令,以避免CPU等待较长时间,充分利用处理器性能,而这种设计中存在一些缺陷,会被一些攻击方法加以利用。
我们希望本文提出的技术可以作为一种补充策略,帮助系统管理员以及信息安全专业人员修复漏洞,也可以作为替代性缓解方法。如果某些系统打上补丁后会出现稳定性以及性能方面的问题,可以考虑采用我们提出的这种技术。
需要注意的是,检测缓存测信道攻击可以作为检测MeltdownPrime以及SpectrePrime的技术基础。虽然实际参数有所不同,这种技术可以检测Flush + Reload、Prime以及Probe攻击。然而,这种方法需要在Linux上操作,我们还没有在Mac系统上测试PoC。
Spectre SGX(SgxPectre)的目标是从受保护的enclave(飞地)中窃取信息。根据Intel SGX编程参考手册中的描述,性能计数器可能会在SGX enclave中受到抑制。然而,由于缓存时序攻击(timing attack)会在SGX enclave之外的不可信代码中执行,性能计数器就会包含缓存命中以及缓存丢失的相关信息。这种情况下依然可能进行检查,但因为还没有经过完全测试,因此我们不能妄下结论。具体参数(如采样率、阈值)会根据具体环境情况有所区别。
二、Meltdown及Spectre如何利用推测执行缺陷
CPU在推测执行访问内存的指令时,如果没有具备正确的访问权限,那么缓存测信道攻击就可以获取实际的值,这就是Meltdown漏洞的大致原理。CPU随后会意识到用户没有具备正确的访问权限,丢弃计算结果。然而,最后一级缓存(LLC)依然保留有一些蛛丝马迹,攻击者可以借此获取内存中的值。
比如,以如下语法/指令为例:
mov rax, [forbiddenAddress]
…
在这种情况下,访问“被禁止”的内存会引发页面错误(page fault),导致出现SIGSEGV错误信号,默认情况下会结束相关进程。然而,攻击者可以自己注册SIGSEGV(Segmentation Violation)信号处理函数,在不至于引发主应用崩溃的前提下读取内存数据块。这些信号会在操作系统(OS)中留下一些脚印。
我们可以使用Intel的Transactional Synchronization Extensions(TSX)来消除这些脚印,TSX扩展可以方便处理器检测进程是否需要进行序列化处理。攻击者基本上都会滥用Restrictive Transactional Memory(RTM)接口。比如,攻击者可以编写如下形式的Meltdown攻击代码,这段代码由xbegin以及xend指令进行封装,可以抑制异常信号(不会引发页面错误)。实际上这种方法可以更加隐蔽地利用Meltdown漏洞:
xbegin
mov rax, [forbiddenAddress]
…
xend
Spectre漏洞利用的是指令推测执行中存在的缺陷。与Meltdown漏洞不同,Spectre会读取条件分支内被禁止的内存。需要注意的是执行过程本不应该进入这个分支。然而,现代CPU会使用分支预测器(branch predictor)来计算应该进入哪个分支,然后推测执行该分支内的指令。
比如,非常简单的Spectre攻击代码如下所示:
…
mov rax, [rbp-10] // rax eq. 5
mov rbx, [rbp-18] // rbx eq. 4
xor rax, rbx
je no_way
…
ret
no_way:
mov rax, [forbiddenAddress]
攻击者的目标是“训练”分支预测器,使负责判断是否进入条件分支的指令结果出现错误(这里涉及到的指令为XOR指令),从而让处理器推测执行代码中的no-way语句。CPU会发现自己预测错误,然后丢弃执行结果。然而,攻击者可以刺探缓存,获取相关数值。这个场景会在CPU内部中处理,因此不会生成任何页面错误。
与前一种情况类似,现在攻击者可以使用缓存测信道攻击获取正确数值。这种情况下操作系统不会收到任何异常信息。需要注意的是,由于分支预测器存在差异,Spectre漏洞比较难利用,更加依赖具体的CPU。
三、利用缓存丢失率检测Meltdown及Spectre攻击
由于存在page_fault,因此Meltdown会在系统中留下一些蛛丝马迹,我们可以使用内核跟踪技术,捕捉漏洞利用攻击涉及到的相关信号。这种机制可以捕获OS内部的SIGSEGV信号(segfaults)。如果某个进程产生太多的segfaults,那么就会触发警告。
我们使用Linux kprobe工具来捕捉force_sig_info事件来测试这种方法的有效性。可以确认的是,我们可以使用自定义的信号处理函数来检测Meltdown攻击行为。这种情况下误报率非常低,因为一个进程出现太多SIGSEGV信号的确是非常特殊且可疑的情况。然而,如果攻击者使用TSX指令集,不引发SIGSEV信号,那么这种检测方法就无法成功触发警告。
由于CPU的微架构设计存在缺陷,因此Meltdown以及Spectre都可能使用缓存测信道攻击技术来获取实际的值。那么我们能发现这些漏洞攻击行为吗?CPU会使用缓存来减少内存负载的延迟,现代CPU会使用多层缓存结构,从L1缓存开始(最快的缓存),到L3缓存为止(最慢的缓存)。多层缓存带有包含性质,也就是说Li⊂Li+1。
此外,L3缓存也会在多个核心之间共享,其中包含数据以及指令,因此也更加容易受到攻击影响。L3缓存是DRAM(动态随机存取存储器)前的最后一个高速缓存,可以提供到DRAM的映射关系。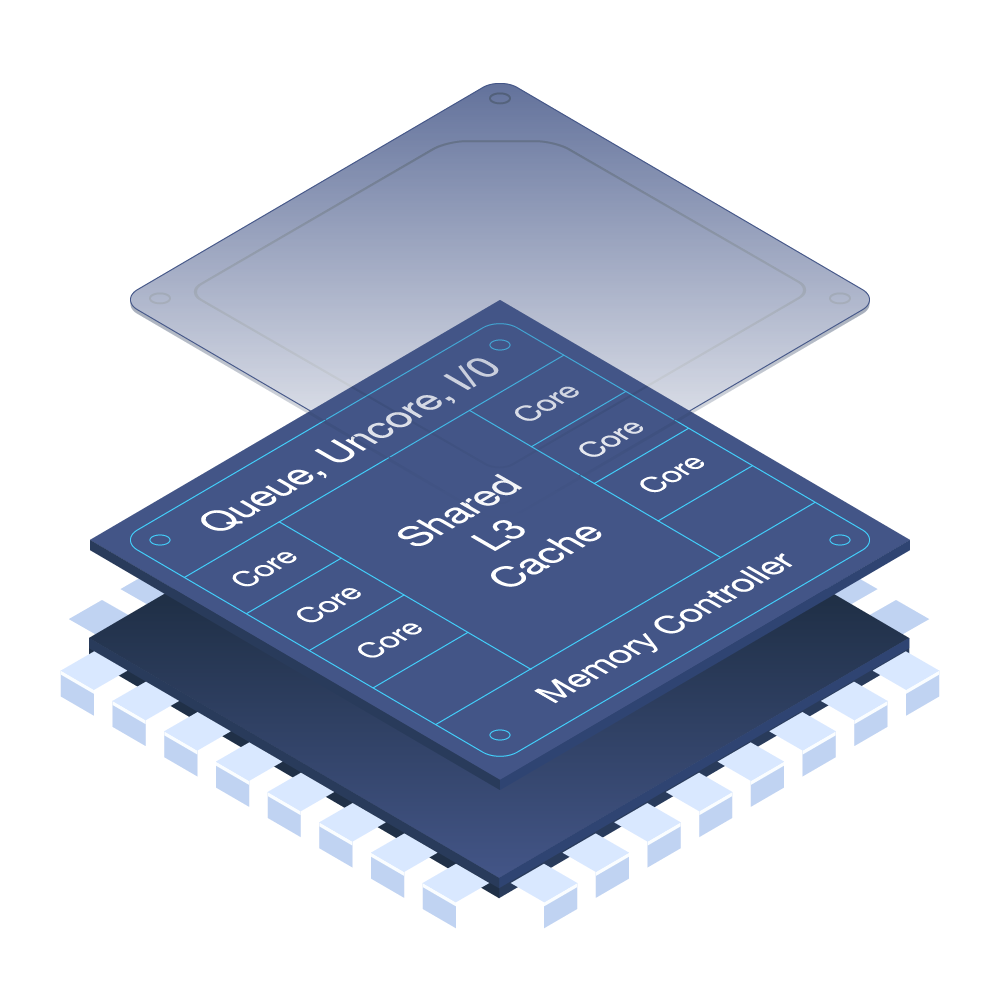
图1. 现代CPU的组件,包含多个核心以及L3缓存
如果计算机获取位于内存以及缓存中的值时(缓存命中),所需的访问时间会比从DRAM加载的时间快得多(此时缓存未命中)。攻击者可以借此区分缓存命中以及缓存未命中的情况,这也是这类攻击实现信息传输的基本原理。从逻辑上讲,在攻击过程中缓存未命中的次数会有所增加。然而,我们是否可以测量缓存丢失率来检测这类攻击呢?如何区分恶意行为以及正常行为,避免出现假阳性(false positive,FP)结果呢?
我们可以通过硬件性能计数器来测量缓存未命中率。在Intel处理器中有两类性能计数器(PMC):架构型(architectural)PMC以及特定型号型(model-specific)PMC。架构型PMC在微架构中表现一致,自Intel Core Solo以及Intel Core Duo处理器开始引入这种性能计数器。
我们可以执行cupid指令来判断是否存在架构型PMC(eax=0x7, ecx=0x0),这条指令可以告诉我们这些计数器的相关信息。在我们的测试案例中,我们使用intel_cpu_info工具,配合-arch参数得到如下输出结果:
Printing architectural CPU Information:
Version ID of architectural performance monitoring = 4
Number of general-purpose performance monitoring counter per logical processor = 4
Bit width of general-purpose, performance monitoring counter = 48
Length of EBX bit vector to enumerate architectural performance monitoring events = 7
Core cycle event available: yes
Instruction retired event available: yes
Reference cycles event available: yes
Last-level cache reference event available: yes
Last-level cache misses event available: yes
Branch instruction retired event available: yes
Branch mispredict retired event available: yes
Number of fixed-function performance counters ((if Version ID > 1) = 3
Bit width of fixed-function performance counters (if Version ID > 1) = 48
对于与LLC有关的计数器,我们需要注意LLC引用(Last Level Cache References)以及LLC未命中(LLC misses)事件。Intel的定义如下:
1、Last Level Cache References事件:Event Select编码为2EH, Umask为4FH。这个事件会统计来自于核心的请求数,这些请求引用的是最后一级缓存中的数据。
2、Last Level Cache Misses事件:Event Select编码为2EH,Umask为41H。这个事件会统计引用最后一级缓存时的缓存未命中情况。
在测量缓存未命中情况时,我们需要了解哪种PMC可用,尤其是在虚拟环境中更要了解这个信息。我们还需要CPU以及内核支持才能获取这些值,因为我们无法在用户模式下执行读取这些值的指令。我们需要一个应用程序从内核中读取这些值。
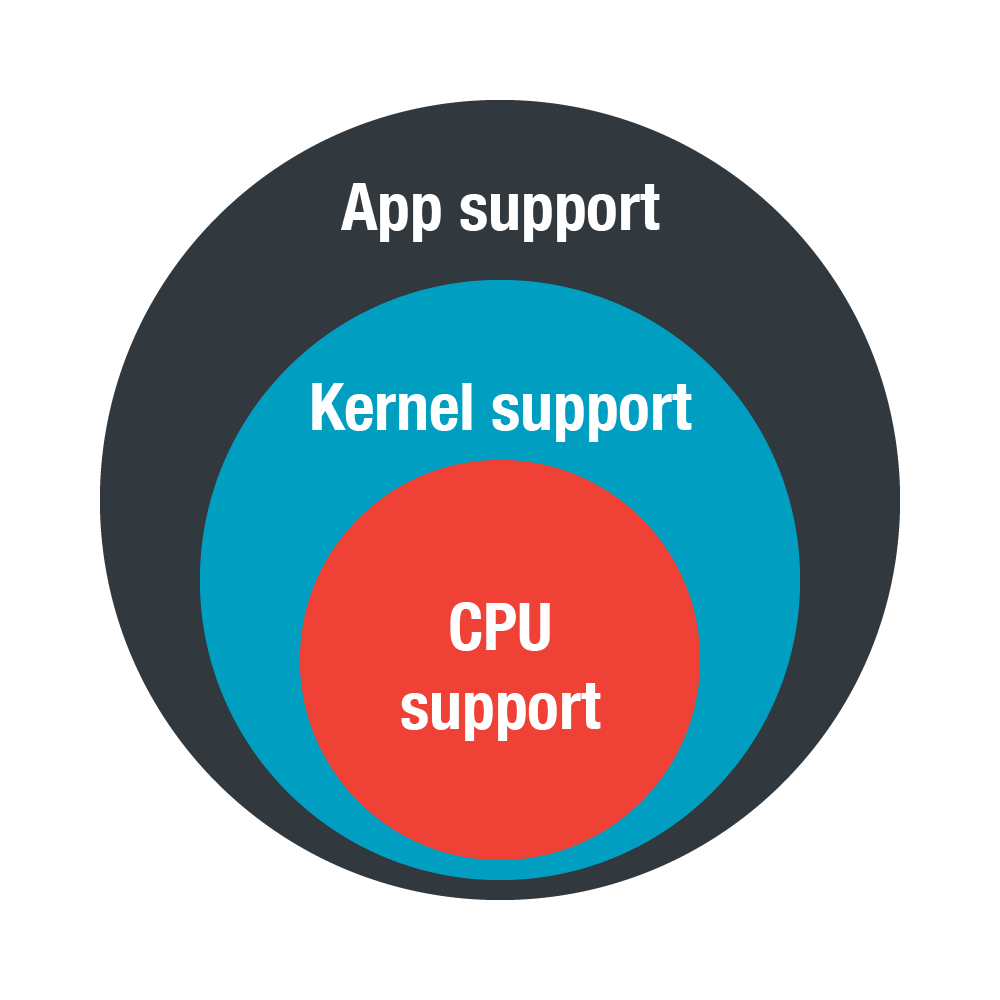
图2. 确定哪种PMC可用时所需的组件
在Linux环境中我们可以使用性能分析工具(perf tools)来完成这个任务。其他平台可能需要特殊的驱动程序才能实现。
我们可以执行perf list命令列出可用的事件。Last Level Cache References事件以及Last Level Cache Misses事件的别名分别为cache-references以及cache-misses。根据Intel提供的资料,我们也可以使用perf stat -e r4f2e,r412e命令获取LLC引用以及LLC未命中情况。
此外,我们还可以选择使用LLC-loads以及LLC-load-misses计数器,因为这两者都与LLC有关。然而,需要注意的是这些计数器都是特定型号型计数器,在某些环境中可能无法使用。比如,我们无法在基于Sandy Bridge微架构运行的物理机上获取LLC-load-misses信息,然而却可以获取LLC-loads信息。
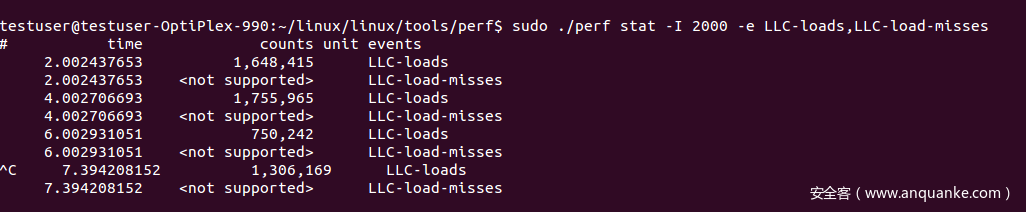
图3. 在物理机上无法访问某些计数器
即使VMware启用了Virtual CPU Performance Monitoring Counters(虚拟CPU性能监控计数器)功能,我们也无法在虚拟机中获取这些计数器信息。然而,我们还是可以获取到LLC References以及LLC-miss事件。
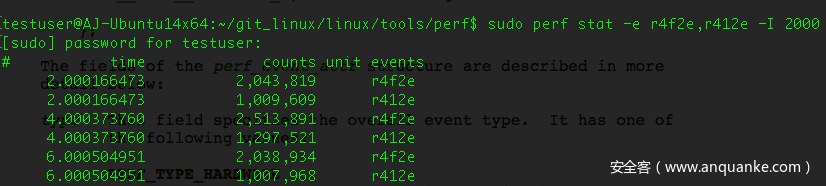
图4. 虚拟机中相关事件情况
我们建议大家使用perf stat命令来测试这些计数器的可用性。如果条件允许,我们会使用LLC references、LLC misses事件以及LLC-loads、LLC-load-misses计数器。我们也测试了现在常用的云解决方案中这些指标的可用性,结果发现计数器要么处于不可用状态,要么处于不支持状态。
四、测试检测机制
为了验证缓存未命中是否可以作为侧信道攻击的检测机制,我们使用了与LLC相关的性能计数器,具体设置如下:
1、我们为每个逻辑CPU设置了两个perf事件(LLC-references以及LLC-misses),测量了每个CPU上的所有进程/线程。在超过采样周期P之后才读取计数器值。我们使用如下公式计算LLC丢失率:
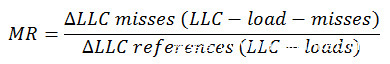
2、当MR > 0.99时我们触发检测机制。
3、我们测试了P1=10 000以及P2=20 000这两个采样周期。
使用物理机时,我们实验了如下测试场景:
1、运行stress命令,每次运行2分钟,具体命令如下(其中#为逻辑CPU的数量):
stress -c #
stress -i #
stress -m #
stress -d #
stress -c #
stress -c # -i # -d #
stress -c # -I # -d # -m #
2、使用VLC播放4K视频。
3、部署Meltdown PoC程序。
4、部署Spectre PoC程序。
在上述场景中,利用LLC-references以及LLC-misses事件我们得到了如下结果:
1号物理主机:
采样周期P1=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发假阳性(FP)结果;
2、播放4k视频时会出现FP结果;
3、可以检测Meltdown PoC程序;
4、可以检测Spectre PoC程序。
采样周期P2=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发FP结果;
2、播放4k视频时没有出现FP结果;
3、可以检测Meltdown PoC程序;
4、可以检测Spectre PoC程序。
1号虚拟机:
采样周期P1=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发假阳性(FP)结果;
2、N/A;
3、可以检测Meltdown PoC程序;
4、可以检测Spectre PoC程序。
采样周期P2=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发FP结果;
2、N/A;
3、可以检测Meltdown PoC程序;
4、无法检测Spectre PoC程序。
对于LLC-loads以及LLC-load-misses事件,有如下结果:
1号物理机:无法使用相关计数器。
2号物理机:
采样周期P1=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发假阳性(FP)结果;
2、播放4k视频时不会出现FP结果;
3、可以检测Meltdown PoC程序;
4、可以检测Spectre PoC程序。
采样周期P2=10,000时,结果如下:
1、只有使用-m参数时stress命令才会触发FP结果;
2、播放4k视频时没有出现FP结果;
3、可以检测Meltdown PoC程序;
4、可以检测Spectre PoC程序。
1号虚拟机:无法使用相关计数器。
我们所测试的主机环境如下:
1号物理机:Core i5-2430M @2.40GHz,Sandy Bridge,Ubuntu 14.04
2号物理机:Core i7-4600U @2.10GHz,Haswell,Ubuntu 14.04
1号虚拟机:VMware ESX VM,Intel Xeon E5-2660 @2.2GHz,Sandy Bridge,Ubuntu 16.04
vpmc.enable = “TRUE”
vpmc.freezeMode = “vcpu”
五、假阳性结果
我们发现采样周期会影响结果中出现的FP情况,并且使用stress -m命令时,我们总是可以观察到FP现象。查阅stress官方文档后,我们可以看到如下说明:
-m, –vm N
使用N个工作单元持续执行malloc()/free()操作
这种结果在我们预料之中,因为前面我们提到过,LLC与物理内存有关系。因此,如果实际环境中会频繁进行内存分配操作,我们检测起来要更加小心谨慎一些。
根据我们的观察,LLC-loads以及LLC-load-misses计数器能得到更加精确的结果,然而我们还是可以使用LLC references(cache-references)以及LLC misses(cache-misses)事件进行检测。
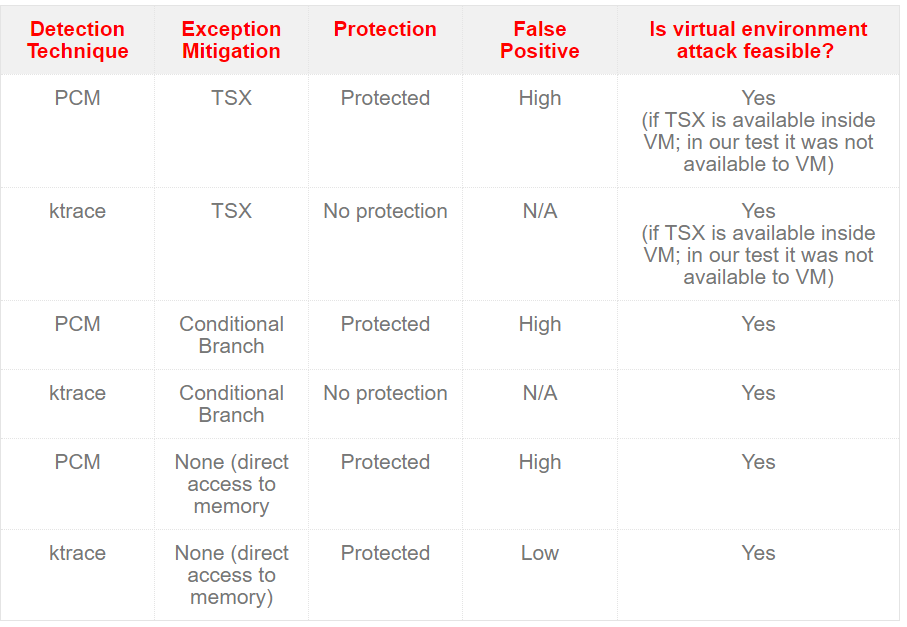
图6. 使用ktrace以及性能计数器监视器(PCM)时的测量结果,每种技术所使用的侧信道攻击技术均为Flush-Reload
上图中需要注意的是:Spectre以及Meltdown的PoC代码可以使用“Conditional Branch(条件分支)”方法避免出现异常,这种情况下ktrace无法检测或者防护此类攻击方式。
六、总结
在实际环境中,如果无法使用TSX-NI指令集扩展,那么基于内核追踪以及SIGSEV信号的检测技术可以防护Meltdown攻击行为(这种方法与主机具体的CPU有关,比如基于Haswell微架构的Intel微处理器)。
有一些工具能够检测Intel TSX-NI是否可用。其中有一种工具使用的是cpuid指令,大家可以翻阅Intel的64位架构以及IA-32架构的软件开发者手册了解详细信息。
如果实际环境中可以使用CPU性能计数器,那么我们可以采用针对缓存侧信道攻击的通用检测方法。在Linux系统上安装perf-tools工具后,我们可以运行perf stat -e -a cache-references,cache-misses,LLC-loads,LLC-load-misses命令检查这些计数器的可用性。默认情况下,大多数虚拟环境中都没有提供硬件性能计数器(如Amazon AWS、Azure、Virtual Box),然而我们可以在VMware上启用这一功能。
如果想在其他平台上(如Windows以及macOS上)访问性能计数器则需要付出更多精力,因为我们无法在用户模式下访问这些计数器。我们需要一个合适的内核驱动才能读取计数器数值、采样率,有些时候想获取导致缓存丢失率上升的那个进程ID(PID)也需要内核驱动。
此外,我们建议大家在实际环境中可以调整检测参数,我们会根据用户的情况来决定是否需要出发警报。这种方法会向用户提供PID以及任务ID(TID),这样用户就可以对标记的进程或者线程采取操作。
采样周期也会影响结果的敏感程度:更高的采样率会出现更少的误报率,然而如果黑客的时机把握得非常好,我们还是有可能检测不到这种攻击行为。这种方法需要读取少量字节,然后休眠一段时间。检测技术可以迟滞攻击行为,因为按行读取一大块内存会触发警告。另一方面,较低的采样率会导致出现多个误报。据我们观察,物理主机的性能计数器会比VMware中的性能计数器更加准确。
我们可以证实,如果硬件计数器可用的话,这种检测技术可以用来检测FLUSH+RELOAD类型的缓存侧信道攻击。然而,在实际环境中我们需要多加测试、细调参数。
事实上,我们没办法找到包治百病的一种药,检测和阻止利用Meltdown以及Spectre漏洞的所有攻击行为。不同参数会带来不同的缓解效果,比如,如果某种检测机制需要依赖于特定环境中组件的可用性,那么情况就有所不同。
对于不断变化的安全威胁,警觉性以及主动检测能力是非常重要的一个方面,但我们也需要重视深度防御机制。采用主动的事件响应策略可以帮助单位或组织挖掘攻击链路的可见性,因此可以更好地实施补救措施,这对于Meltdown及Spectre之类的大规模安全风险来说更是如此。







发表评论
您还未登录,请先登录。
登录