

一、前言
之前我发表过一篇文章介绍了7-Zip的CVE-2017-17969以及CVE-2018-5996漏洞,后面我又继续花了点时间分析了反病毒软件。碰巧的是,我又发现了一个新的bug,该漏洞(与之前两个bug一样)最终会影响到7-Zip。由于反病毒软件厂商还没有发布安全补丁,因此我会在本文更新时添加受影响的产品名称。
二、简介
7-Zip的RAR代码主要基于最近版本的UnRAR代码,但代码的高层部分已经被大量修改过。我曾经在之前的一些文章中提到过,UnRAR的代码非常脆弱,因此,对这份代码的改动很有可能会引入新的问题,这一点非常正常。
从抽象层面来讲,这个问题可以简单描述如下:在解码RAR数据前,应用程序需要对RAR解码器类的一些成员数据结构进行初始化操作,而这些初始化操作需要依赖RAR处理函数来正确配置解码器。不幸的是,RAR处理函数无法正确过滤其输入数据,会将错误的配置传入解码器,导致程序使用未初始化内存。
现在你可能会认为这个问题无关痛痒。不可否认的是,我第一次发现这个问题时也存在相同的看法,然而事实证明并非如此。
接下来我会详细介绍这个漏洞,然后简单看一下7-Zip的修复措施,最后我们来看一下如何利用这个漏洞实现远程代码执行。
三、漏洞分析(CVE-2018-10115)
存在问题的代码位于solid compression处理流程中。solid compression的原理很简单:给定一组文件(比如来自于某个文件夹的一组文件),我们可以将这些文件当成一个整体,即单独的一个数据块,然后对整个数据块进行压缩(而不是单独压缩每一个文件)。这样可以达到较高的压缩率,特别是文件数非常多或类似情况时压缩率会更高。
在(版本5之前的)RAR格式中,solid compression的用法非常灵活:压缩文档中每个文件(item)都可以打上solid标记,与其他item无关。如果某个item设置了solid位,那么解码器在解码这个item时并不会重新初始化其状态,而会从前一个item的状态继续处理。
显而易见的是,程序需要确保解码器对象在一开始时(从解码第一个item开始)就初始化其状态。我们来看一下7-Zip中的具体实现。RAR处理器中包含NArchive::NRar::CHandler::Extract这样一个方法,该方法在循环中通过一个变量索引遍历所有item。在这个循环中,我们可以找到如下代码:
Byte isSolid = (Byte)((IsSolid(index) || item.IsSplitBefore()) ? 1: 0);
if (solidStart) {
isSolid = 0;
solidStart = false;
}
RINOK(compressSetDecoderProperties->SetDecoderProperties2(&isSolid, 1));
这段代码的主要原理是使用solidStart这个布尔(boolean)标志,该标志初始化为true(在循环开始前),确保在解码第一个item时,使用isSolid==false来配置解码器。此外,只要使用isSolid==false来调用解码器,那么解码器在开始解码前总会(重新)初始化其状态。
这个逻辑看上去没有问题,对吧?好吧,其实问题在于RAR支持3种不同的编码方法(版本5除外),每个item都可以使用不同的方法进行编码。更具体一点,这3种编码方法中每一种都存在不同的解码器对象。有趣的是,3种解码器对象的构造函数中并没有对一大部分成员进行初始化处理。这是因为对于非solid的item,其状态总是需要重新进行初始化,并且有一个隐含的前提,那就是解码器的调用者会确保首次调用解码器时使用isSolid==false。然而我们可以构造如下这样一个RAR压缩包,打破这个假设条件:
1、第一个item使用的是v1编码方法;
2、第二个item使用的是v2(或者v3)编码方法,并且设置了solid位。
第一个item会导致solidStart标志设置为false。对于第二个item,应用会创建一个新的Rar2解码对象,然后(由于已经设置了solid标志位)在解码器中大部分成员未经初始化的状态下,开始解码过程。
乍看之下,这可能不是个大问题。然而,许多数据没经过初始化处理可能会被恶意利用,导致出现内存损坏:
1、保存堆上缓存大小的成员变量。这些变量现在保存的大小值可能比真实的缓冲区还要大,就会出现堆缓冲区溢出现象。
2、带有索引的数组,这些数组用来索引其他数组的读写操作。
3、在我之前那篇文章中讨论过的PPMd状态。这些代码很大程度上依赖于模型状态的正确性,然而现在这个正确性很容易就会被破坏。
很显然,以上并没有覆盖所有的利用场景。
四、修复措施
实际上这个漏洞的本质是程序无法确保在第一次使用解码器类之前正确初始化解码器类的状态。相反,在解码第一个item前,程序需要依赖调用者使用isSolid==false来配置解码器。前面我们也看到过,这么做效果并不是特别好。
解决这个漏洞可以采用两种不同的方法:
1、在解码器类的构造函数中正确初始化所有的状态。
2、在每个解码器类中添加一个额外的boolean成员变量:solidAllowed(初始化为false)。如果solidAllowed==false,即便isSolid==true,解码器也会遇到错误终止处理作业(或者设置isSolid=false)。
UnRAR貌似使用的是第一种方法,而Igor Pavlov选择使用第二种方法来修复7-Zip。
如果你想自己修复7-Zip的某个分支,或者你对修复过程比较感兴趣,那么你可以参考这个文件,文件总结了具体的版本改动。
五、缓解漏洞利用
在介绍CVE-2017-17969以及CVE-2018-5996漏洞的上一篇文章中,我提到7-Zip在18.00(beta)版本之前缺少DEP以及ASLR机制。在那篇文章公布后不久,Igor Pavlov 就发布了7-Zip 18.01,该版本带有/NXCOMPAT标志,在全平台上启用了DEP。此外,所有动态库(7z.dll、7-zip.dll以及7-zip32.dll)都带有/DYNAMICBASE标志以及重定位表。因此,大部分运行代码都受到ASLR的约束。
然而,所有的主执行文件(7zFM.exe、7zG.exe以及7z.exe)并没有使用/DYNAMICBASE标志,同时剥离了重定位表。这意味着不仅这些程序不受ASLR约束,并且我们也无法使用诸如EMET或者Windows Defender Exploit Guard之类的工具强制启用ASLR功能。
显然,只有当所有的模块都正确随机化后,ASLR才能发挥作用。我之前和Igor讨论过这个问题,已经说服他在新版的7-Zip 18.05中,让主执行程序使用/DYNAMICBASE标志以及重定位表。目前64位版本的7-Zip仍在使用标准的非高熵版ASLR(大概是因为基础镜像小于4GB),但这是一个小问题,可以在未来版本中解决。
另外我想指出一点,7-Zip并不会分配或者映射其他可执行内存空间,因此可以作为Windows ACG(Arbitrary Code Guard)机制的保护目标。如果你使用的是Windows 10,我们可以在Windows Defender Security Center中添加7-Zip的主执行文件(7z.exe、7zFM.exe以及7zG.exe),为其启用保护功能(操作路径为:App & browser control -> Exploit Protection -> Program settings)。这样将会应用W^X策略,使代码执行的漏洞利用过程变得更加困难。
六、编写代码执行利用载荷
通常情况下,我并不会花太多事件来思考如何开发武器化的利用技术。然而,如果我们想知道在给定条件下,编写漏洞利用代码需要花费多少精力,那么此时我们可以考虑实际动手试一下。
我们的目标平台为打上完整更新补丁的Windows 10 Redstone 4(RS4,Build 17134.1),64位操作系统,上面运行着64位版本的7-Zip 18.01。
挑选合适的利用场景
使用7-Zip来解压归档文件时,我们主要可以采用3种方法:
1、通过GUI界面打开压缩文档,分别提取其中的文件(比如使用拖放操作)或者使用Extract按钮解压整个压缩文档。
2、右键压缩文件,在弹出的菜单种选择“7-Zip->Extract Here”或者“7-Zip->Extract to subfolder”。
3、使用命令行版本的7-Zip进行解压。
这三种方法都要调用不同的可执行文件(7zFM.exe、7zG.exe以及 7z.exe)。这些模块中缺乏ASLR,由于我们想利用这一点,因此我们需要关注文件提取方法。
第二种方法(通过上下文菜单解压文件)看起来吸引力最大,原因在于这可能是人们最常使用的方法,并且通过这种方法我们可以较为精确地预测用户的行为(不像第一种方法那样,人们会打开压缩文档,但选择提取“错误”的文件)。因此,我们选择第二种方法作为目标。
利用策略
利用前面介绍的那个问题,我们可以创建一个Rar解码器,针对(大部分)未初始化的状态执行处理过程。我们来看一下哪个Rar解码器可以让我们以攻击者期望看到的效果来破坏内存。
一种可能的方法是选择使用Rar1解码器,其NCompress::NRar1::CDecoder::HuffDecode方法包含如下代码:
int bytePlace = DecodeNum(...);
// some code omitted
bytePlace &= 0xff;
// more code omitted
for (;;)
{
curByte = ChSet[bytePlace];
newBytePlace = NToPl[curByte++ & 0xff]++;
if ((curByte & 0xff) > 0xa1)
CorrHuff(ChSet, NToPl);
else
break;
}
ChSet[bytePlace] = ChSet[newBytePlace];
ChSet[newBytePlace] = curByte;
return S_OK;
这一点非常有用,因为Rar1解码器的未初始化状态中包含uint32_t类型的数组ChSet以及NtoPl。因此,newBytePlace是攻击者可控的一个uint32_t,curByte也是如此(有个限制条件就是最低有效字节不能大于0xa1)。此外,bytePlace需要根据输入流来决定,因此这个值也是攻击者可控的一个值(但不能大于0xff)。
这样就让我们具有很好的读写利用条件。但是请注意,我们正处于64位地址空间中,所以我们不可能通过ChSet的32位偏移量来访问Rar1解码器对象的vtable指针(即便乘以sizeof(uint32_t)这个值)。因此,我们的目标是堆上位于Rar1解码器之后的那个对象的vtable指针。
为此我们可以使用一个Rar3解码器对象,与此同时我们也会使用该对象来保存我们的载荷。更具体一点,我们利用前面得到的读写条件将_windows指针(Rar3解码器的一个成员变量)与同一个Rar3解码器对象的vtable指针进行交换。_window指向的是一个4MB大小的缓冲区,该缓冲区保存着利用解码器提取出的数据(也就是说这也是攻击者可控的一段数据)。
我们将使用stack pivot技术(xchg rax, rsp)将某个地址填充到_window缓冲区中,然后跟着一个ROP链以获得可执行的内存并执行shellcode(我们也会将这段shellcode放入_windows缓冲区中)。
在堆上放置一个替代对象
为了成功实现既定策略,我们需要完全控制解码器的未经初始化的内存空间。大致做法就是分配大小为Rar1解码器对象大小的一段内存空间,将所需数据写入其中,然后在程序真正分配Rar1解码器空间之前先行释放掉这块内存。
显然,我们需要确保Rar1解码器所分配的空间的确重用了我们先前释放的同一块内存区域。想实现这个目标的一种直接方法就是激活相同大小的低碎片堆(Low Fragmentation Heap,LFH),然后使用多个替代对象来喷射LFH。这种方法的确行之有效,然而由于从Windows 8开始,在LFH分配空间会被随机化处理,因此使用这种方法再也不能让Rar1解码器对象与任何其他对象保持恒定的距离。因此,我们会尽量避免使用LFH,将我们的对象放置在常规堆上。整个空间分配策略大概如下所示:
1、创建大约18个待分配的空间,其大小小于Rar1解码器对象的大小。这样就会激活LFH,避免这类小空间分配操作摧毁我们干净的堆结构。
2、分配替代对象然后释放这个对象,确保该对象被我们前面分配的空间所包围(因此不会与其他空闲块合并)。
3、分配Rar3解码器(替代对象并没有被重用,因为Rar3解码器比Rar1解码器要大)。
4、分配Rar1解码器(重用替代对象)。
需要注意的是,在为Rar1解码器分配空间时,我们无法避免先分配一些解码器,这是因为只有通过这种方式,solidStart标志才会被设置为false,导致下一个解码器无法被正确初始化(见前文描述)。
如果一切按计划运行,Rar1解码器就会重用我们的替代对象,Rar3解码器对象在堆上将位于Rar1解码器对象之后,并且保持某个恒定的偏移距离。
在堆上分配并释放
显然,如上分配策略需要我们能够以合理可控的方式在堆上分配空间。翻遍了RAR处理函数的所有源码,我无法找到很多较好的方法来对默认进程堆动态分配空间,以满足攻击者所需的大小要求并往其中存储攻击者可控的数据。事实上,完成这种动态分配任务的貌似只能通过压缩文档item的名称来实现。接下来我们看一下具体方法。
当程序打开某个压缩文档时,NArchive::NRar::CHandler::Open2方法就会读取压缩文档的所有item,具体代码如下(经过适当简化):
CItem item;
for (;;)
{
// some code omitted
bool filled;
archive.GetNextItem(item, getTextPassword, filled, error);
// some more code omitted
if (!filled) {
// some more code omitted
break;
}
if (item.IgnoreItem()) { continue; }
bool needAdd = true;
// some more code omitted
_items.Add(item);
}
CItem类有一个AString类型的成员变量Name,该变量在一个堆分配的缓冲区中存储了对应item的(ASCII)名。
不幸的是,item的名称通过NArchive::NRar::CInArchive::ReadName来设置,代码如下:
for (i = 0; i < nameSize && p[i] != 0; i++) {}
item.Name.SetFrom((const char *)p, i);
这里我看到了一些困难,因为这意味着我们无法将任意字节为所欲为地写入缓冲区中。更具体一点,我们似乎无法写入null(空)字节。这一点非常糟糕,因为我们想放在堆上的替代对象中包含若干个0字节。那么我们该怎么办?让我们来看看AString::SetFrom:
void AString::SetFrom(const char *s, unsigned len)
{
if (len > _limit)
{
char *newBuf = new char[len + 1];
delete []_chars;
_chars = newBuf;
_limit = len;
}
if (len != 0)
memcpy(_chars, s, len);
_chars[len] = 0;
_len = len;
}
如你所见,这个方法总是会以一个null字节来结束字符串。此外,我们发现只要字符串大小大于一定值,AString就会在底层开辟一个缓冲区。这就让我产生这样一个想法:假设我们想把DEAD00BEEF00BAAD00这些十六进制字节写入堆上分配的某个缓冲区,那么我们只需要构造一个压缩包,其中item的文件名如下(按照列出的顺序来):
DEAD55BEEF55BAAD
DEAD55BEEF
DEAD
这样我们就能让SetFrom帮我们写入我们需要的所有null字节。请注意,现在我们已经将数据中的null字节替换成一些非零的字节(这里为0x55这个字节),确保将整个字符串写入缓冲区中。
这个方法非常好,我们可以写入任意字节序列,但存在两个限制。首先,我们必须要用一个null字节来结束这个序列;其次,在字节序列中我们不能使用太多个null字节,因为这样会导致压缩文档过大。幸运的是,在这个场景中我们可以轻松绕过这些限制条件。
现在请注意我们可以使用两种类型的分配操作:
1、分配带有item.IgnoreItem()==true属性的一些item。这些item不会被添加到_items列表中,因此属于临时item。这些分配的空间具备特殊属性,最终会被释放,并且我们可以(使用上述技术)往其中填充任意字节序列(几乎可以不受限制)。由于这些内存分配操作都是通过同一个栈分配对象item来完成,因此使用的是相同的AString对象,这类分配操作在大小上需要严格递增。我们主要使用这类分配操作来将替代对象放置在堆上。
2、分配带有item.IgnoreItem()==false属性的一些item。这些item会被添加到_items列表中,生成对应名称的副本。通过这种方式,我们可以获得许多待分配的、特定大小的空间,激活LFH。需要注意的是,复制的字符串中不能包含任何null字节,这对我们来说毫无压力。
综合利用上面提到的方法,我们可以构造一个压缩文档,满足我们前面描述的堆分配策略。
ROP
由于7zG.exe主执行程序不具备ASLR机制,因此我们可以使用一个ROP链来绕过DEP。7-Zip不会去调用VirtualProtect,因此我们可以从导入表(IAT)中读取VirtualAlloc、memcpy以及exit的地址,写入如下ROP链:
// pivot stack: xchg rax, rsp;
exec_buffer = VirtualAlloc(NULL, 0x1000, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
memcpy(exec_buffer, rsp+shellcode_offset, 0x1000);
jmp exec_buffer;
exit(0);
由于我们的工作环境为x86_64系统(其中大多数指令的编码长度比x86系统要长),并且二进制程序也不是特别大,因此我们无法找到特别好的gadget来执行我们所需的一些操作。这并不是一个太大的难题,但会让我们的ROP链看上去没那么完美。比如,在调用VirtualAlloc之前,为了将R9寄存器设置为PAGE_EXECUTE_READWRITE,我们需要使用如下gadget链:
0x40691e, #pop rcx; add eax, 0xfc08500; xchg eax, ebp; ret;
PAGE_EXECUTE_READWRITE, #value that is popped into rcx
0x401f52, #xor eax, eax; ret; (setting ZF=1 for cmove)
0x4193ad, #cmove r9, rcx; imul rax, rdx; xor edx, edx; imul rax, rax, 0xf4240; div r8; xor edx, edx; div r9; ret;
演示
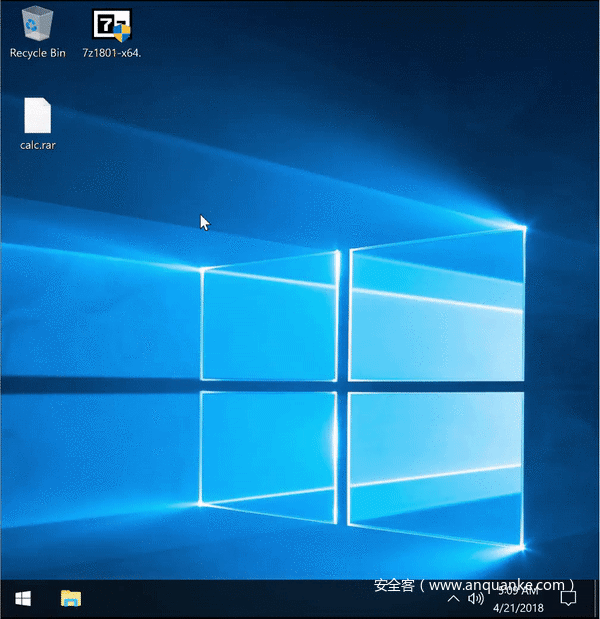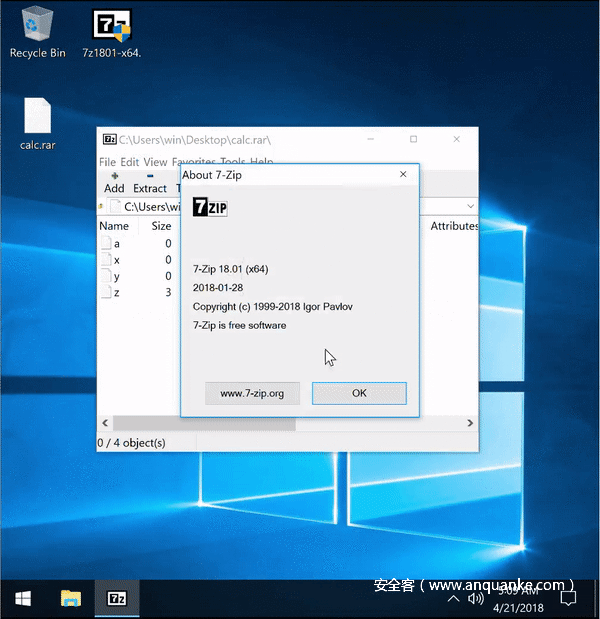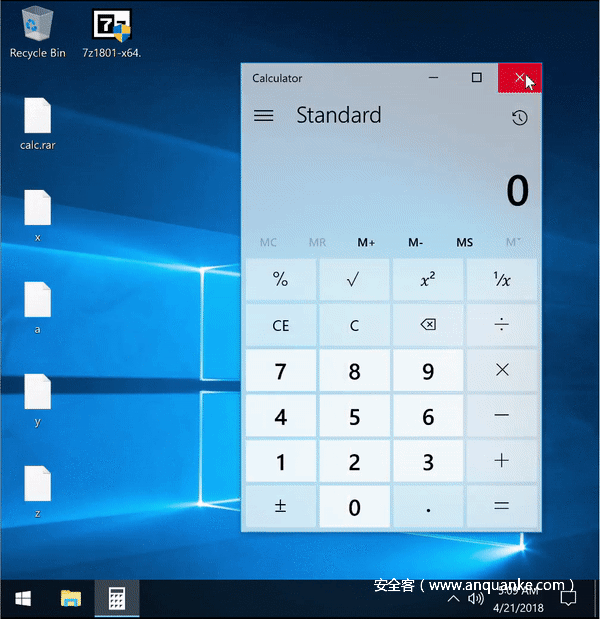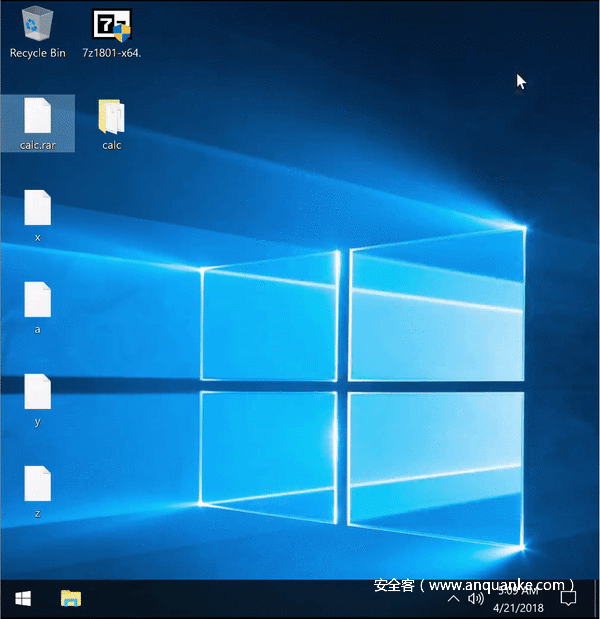
我们的演示环境为全新安装的Windows 10 RS4(Build 17134.1)64位系统,安装了7-Zip 18.01 x64,利用过程如下图所示。前文提到过,我们的利用场景使用的是右键菜单来提取压缩文件,具体菜单路径为“7-Zip->Extract Here”以及“7-Zip->Extract to subfolder”。
可靠性研究
仔细调整堆分配大小后,整个利用过程现在已经非常可靠且稳定。
为了进一步研究漏洞利用的可靠性,我编写了一小段脚本,按照右键菜单释放文件的方式重复调用7zG.exe程序来释放我们精心构造的压缩文档。此外,该脚本会检查calc.exe是否被顺利启动,并且7zG.exe进程的退出代码是否为0。在不同的操作系统上运行这个脚本后(所有操作系统均打全最新补丁),测试结果如下:
1、Windows 10 RS4(Build 17134.1)64位:100,000次利用中有17次利用失败。
2、Windows 8.1 64位:100,000次利用中有12次利用失败。
3、Windows 7 SP1 64位:100,000次利用中有90次利用失败。
需要注意的是,所有的操作系统使用的都是同一个压缩文档。整个测试结果比较理想,可能时由于Windows 7以及Windows 10在堆的LFH实现上面有些区别,因此这两个系统上的测试结果差别较大,其他情况下差别并不是特别大。此外,相同数量的待分配内存仍然会触发LFH。
不可否认的是,我们很难凭经验去判断利用方法的可靠性。不过我认为上面的测试过程至少比单纯跑几次利用过程要靠谱得多。
七、总结
在我看来,之所以出现这个错误,原因在于程序设计上(部分)继承了UnRAR的具体实现。如果某个类需要依赖它的使用者以正确方式来使用它,以避免使用未经初始化的类成员,那么这种方式注定会以失败告终。
经过本文的分析,我们亲眼见证了如何将(乍看之下)人畜无害的错误转换成可靠的、武器化的代码执行利用方法。由于主执行程序缺乏ASLR,因此利用技术上唯一的难题就是如何在受限的RAR提取场景中精心布置堆结构。
幸运的是,新版的7-Zip 18.05不仅修复了这个漏洞,也在所有主执行文件上启用了ASLR。
如果大家有意见或者建议,欢迎通过此页面上的联系方式给我发邮件。
此外,大家也可以加入HackerNews或者/r/netsec一起来讨论。
八、时间线
- 2018-03-06 – 发现漏洞
- 2018-03-06 – 报告漏洞
- 2018-04-14 – MITRE为此漏洞分配了编号:CVE-2018-10115
- 2018-04-30 – 7-Zip 18.05发布,修复了CVE-2018-10115漏洞,在可执行文件上启用了ASLR。
九、致谢
感谢Igor Pavlov修复此漏洞并且为7-Zip部署缓解措施避免被进一步攻击。







发表评论
您还未登录,请先登录。
登录