

背景
一次一密的流密码被证明是完全理想化的不可破解的完美安全的加密方式。但是在现实生活中我们没法做到真正的伪随机的密密钥流。对于这种情况,想到的措施就是设计出攻击者优势可忽略的伪随机生成器,然后利用极短的密钥来近似的生成一次一密的密钥流。当然这篇文章不是讨论这些理论的证明和伪随机数生成器如何应用到安全的留密码,而是想介绍一些流密码的攻击思路,这些思路经常出现在ctf的密码题中,虽说攻击手段不新鲜,但是其指导意义和对思维的锻炼是一点不含糊。
不安全的流密码使用举例
其中的一道题是coursa 密码学课程上的课后编程题,另一道题目是crypto chanllege set1 的一道流密码密钥重用的题。 在之后我们将尝试用两种方法来对其进行统计学以及英语特性上的攻击。,这些攻击相当的犀利,准确率极高,只要捕获的密文足够多就能够实现对密钥的无差别猜解。以下是题目:
coursa
这道题目的大概意思说,我们捕获了一连串的密文,已知这些密文的加密方式为i抑或,并且抑或的密码本被多次使用了,我们能否通过这些捕获的存在不合理抑或利用方式的加密密文来还原出明文。读者可以点进连接去自己看看原题。不过这篇文章打算以下一个题目作为例子进行讲解,二者的解体思路和方法大同小异,核心思路一致。
crypto chanllege set1 question6
这道题目和上一道题目其实十分的相似,都是流密码重用的类型,但是根据题目的提示,我们可以了解到一种利用汉明距离来进行密钥长度的猜接手段——汉名距离,在解除密钥长度后,我们可以采取两个方法来获取明文信息,具体细节稍后进行阐述。读者可以先看看原题进行一些初步理解,这里就不对题目做过多的解释。
攻击细节
整个的攻击流程其实可以分为两个步骤:密钥长度猜解,其次是解出明文。接下来就对这两个部分进行是的剖析。
首先猜测密钥长度
密钥长度的猜解其实比较直观的是进行暴力破解,在密钥长度比较短的时候比较奏效,但是随着密钥长度的增加,我们会发现暴力的方式会让效率相当的低下。甚至是根本解不出。但是在这两个编程实践中,涉及到的密钥长度还是比较短的,不超过40位,暴力猜解的方法在思维上并没有什么难度。然后根据一番搜索,得知有这么一种利用Hamming distance(汉明距离)来猜解密钥长度的方法。以下将对其进行进一步的阐述:
首先解释一下什么是汉明距离?汉明距离其实是在二进制层面观测两个等长字符串的比特位差异。可以看以下几个例子:
hamming("1010", "1111") == 2
hamming("1111", "0000") == 4
hamming("1111", "1111") == 0
可以看到,1010与1111有两个比特位存在差异,所以汉明距离为2。有一种快速的求解汉明距离的方法就是将等长字符串的方法,那就是异或。将两个二进制的字符异或后计算值为1的比特位个数,就是最后的汉明距离。具体的代码如下:
def bxor(a, b): # xor two byte strings of different lengths
if len(a) > len(b):
return bytes([x ^ y for x, y in zip(a[:len(b)], b)])
else:
return bytes([x ^ y for x, y in zip(a, b[:len(a)])])
def hamming_distance(b1, b2):
differing_bits = 0
for byte in bxor(b1, b2):
differing_bits += bin(byte).count("1")
return differing_bits
知道了汉明距离和汉明距离代码实现后,我们应该思考,汉明距离和密钥长度的猜解有什么联系?通过阅读题干和相关拓展资料,我们知道,两个以ascii编码的英文字符的汉明距离是2-3之间,也就是说正常英文字母的平均汉明距离为2-3(每比特),任意字符(非纯字母)的两两汉明距离平均为4。另外我们也容易知道,正确分组的密文与密文的汉明距离等于明文与明文的汉明距离(可以通过按正确密钥长度分组的密文与密文异或等于明文与明文异或证明)。这样,我们可以知道,当我们使用了正确的密钥长度后,两两字母进行计算汉明距离,那么这个值应该是趋于最小。为了增加效率,我们不需要对每一对分组都计算汉明距离,只需取出前几对就可说明问题。当然为了排除偶然误差,结果不应该只取最小的那一个密钥长度,而是酌情多取几组。以下是crypto chanllege set1 question6这道题的密钥长度猜解代码示例:
import base64
def bxor(a, b): # xor two byte strings of different lengths
if len(a) > len(b):
return bytes([x ^ y for x, y in zip(a[:len(b)], b)])
else:
return bytes([x ^ y for x, y in zip(a, b[:len(a)])])
def hamming_distance(b1, b2):
differing_bits = 0
for byte in bxor(b1, b2):
differing_bits += bin(byte).count("1")
return differing_bits
text = ''
with open("6.txt","r") as f:
for line in f:
text += line
b = base64.b64decode(text)
normalized_distances = []
for KEYSIZE in range(2, 40):
#我们取其中前6段计算平局汉明距离
b1 = b[: KEYSIZE]
b2 = b[KEYSIZE: KEYSIZE * 2]
b3 = b[KEYSIZE * 2: KEYSIZE * 3]
b4 = b[KEYSIZE * 3: KEYSIZE * 4]
b5 = b[KEYSIZE * 4: KEYSIZE * 5]
b6 = b[KEYSIZE * 5: KEYSIZE * 6]
normalized_distance = float(
hamming_distance(b1, b2) +
hamming_distance(b2, b3) +
hamming_distance(b3, b4) +
hamming_distance(b4, b5) +
hamming_distance(b5, b6)
) / (KEYSIZE * 5)
normalized_distances.append(
(KEYSIZE, normalized_distance)
)
normalized_distances = sorted(normalized_distances,key=lambda x:x[1])
print(normalized_distances)
#以下是运行结果:
[(5, 2.96), (2, 3.0), (3, 3.3333333333333335), (29, 3.413793103448276), (31, 3.5935483870967744), (16, 3.7), (18, 3.7111111111111112), (14, 3.742857142857143), (15, 3.7466666666666666), (13, 3.753846153846154), (6, 3.7666666666666666), (19, 3.768421052631579), (8, 3.8), (20, 3.82), (37, 3.827027027027027), (39, 3.8666666666666667), (11, 3.8727272727272726), (33, 3.8727272727272726), (26, 3.8923076923076922), (12, 3.9), (17, 3.9176470588235293), (30, 3.92), (34, 3.9352941176470586), (22, 3.9454545454545453), (28, 3.95), (32, 3.95), (7, 3.9714285714285715), (27, 3.977777777777778), (21, 3.9904761904761905), (35, 3.994285714285714), (38, 4.021052631578947), (25, 4.024), (24, 4.033333333333333), (9, 4.044444444444444), (23, 4.069565217391304), (10, 4.1), (36, 4.188888888888889), (4, 4.2)]
[Finished in 0.1s]
可以看到,正确的密钥长度29排得比较靠前。这样我们从前往后取作为密钥长度来进行后面的密钥的猜解就可以大大增加我们的效率,相对于暴力遍历来说。这点在后面可以进一步看到。
根据猜出的密钥长度进行密文的解密
在密文的解密部分,根据笔者的总结,发现有两种行之有效的办法。
这种方法其实是利用了一个抑或的规律和一个小技巧。使用到的抑或定律其实相当的简单:在使用异或加密的形式下,使用相同密钥加密的明文和秘文间存在这个规律,密文和密文异或等于明文和明文异或。可以通过简单的数学公式加以证明,这里就不展开叙述。另一个小技巧就是:空格和所有小写字母异或结果是相应的大写字母,空格和所有大写字母异或是相应的小写字母。为了证明这个小技巧,可以使用一个python脚本来遍历输出。
results = []
value = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
for asc1 in value:
print(asc1,"^0x20---->",chr(ord(asc1)^0x20))
这样当两个密文按照字节异或后的结果处于字母表的ascii值之间,我们就可以有很大的概率认为异或的明文字符之一是空格,那么根据这个规律,我们可以依次遍历出密钥的每个字节,当捕获的密文组足够多,我们就可以有相当大的概率解出整个密钥,因为当密文组够多,我们有很大的概率得到每个密钥对应异或的字节位上的明文为空格,然后依次异或出密钥。
当然读者可能会问,ascii码那么多,两两异或的结果处于字母区间的可能情况不是有很多种吗?这样说是一点没错的,我曾经尝试写过一个常用英文符号两两异或的脚本,遍历输出非空格下,两者异或的结果是字母表区间的python脚本,如下:
results = []
verifycode = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
value = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,/."'?! :'
for asc1 in value:
for asc2 in value:
result = ord(asc1) ^ ord(asc2)
if chr(result) in verifycode and asc1 != ' ' and asc2 != ' ':
results.append((asc1, asc2))
filtedresult = []
setresult = set(results)
for i in setresult:
for j in setresult:
if set(i) != set(j) and set(i) not in filtedresult:
filtedresult.append(set(i))
print("verify len:", len(filtedresult))
print("result:", filtedresult)
运行这个脚本,会发现有349种可能的情况,那么是不是说明运用空格这个点来破解不合理?其实不然,要知道,这349中可能性里面,没有哪一个字符可以满足与任何一个字母异或都是字母区间,这就是说,空格及有无可挑剔的最大可能。这样一来,我们可以分别按照密钥将密文重新分组,将异或用一个密钥字节的密文合并成一组,这样一来我们就可以拥有密钥长度个组,每个组都是明文异或同一个密钥字节得来的密文。取其中一个分组,将里面的字符两两异或,记录每个字符与其他每一个字符异或出现结果是字母的次数,取最大次数(因为根据概率学,明文空格情况下,该次数应该是最大的,当然不排除极小概率的特俗情况)的字符我们将推断其明文为空格,然后异或出该分组的密钥字节。说来可能有点绕,做出相应的图示如下:
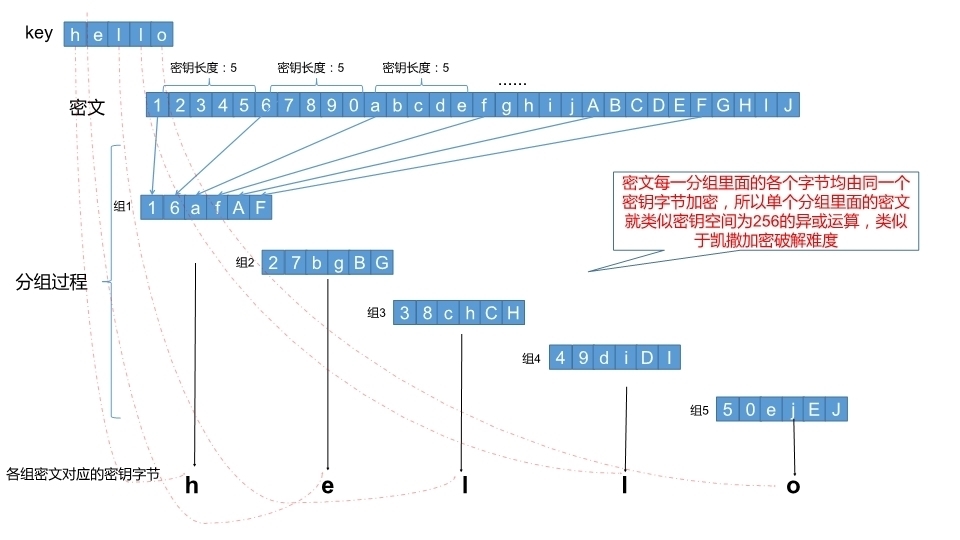

以下是具体的实现的步骤:
1. 使用取模运算把密文分成n个分组(其中n是密钥长度),如此以来,我们就有了n个独立的凯撒加密式的密文组(因为每个分组里面的值是使用同一个密钥字节明文异或)。这样就把问题简化成了破解n个独立的凯撒加密模式的单字节抑或密码方式。这一步可以直接使用爆破,但是效率不高。我们采取另一种姿势。
2. 将2中的每个分组做如下的操作:每个分组做嵌套循环,内循环,外循环。设置外循环计数值possible_space=0,max_possible=0,设置内循环计数值maxpossible=0,依次取出每个分组中的每一个字节做与其他字节两两抑或进行内循环,如果结果是字母,我们就把内循环计数值maxpossible+1,在每个内循环结束后进行max_possible的更新(与内循环maxpossible做对比),并记录当前字节的位置到possible_space,然后外循环继续。直至遍历完所有的字节。取出max_possible对应的字节位置possible_space处的字节码,我们把它对应的明文假设成空格(根据之前的讨论)然后将该位置的字节和0x20(空格)异或;找出相应位置的密钥字节。
3. 重复2中的步骤,依次根据每个分组找出每位的密钥字节,至此密钥破解完毕
4. 将找出的密钥用于破解密文。当密文足够多,可以发现破解的准确率很高,基本可以做到无差别破解。
可能读者对上述步骤仍旧存在一些疑问,这里以例题作为进一步的说明(crypto chanllege set1 question6),下面是解题代码:
def break_single_key_xor(text):
key = 0
possible_space=0
max_possible=0
letters = string.ascii_letters.encode('ascii')
for a in range(0, len(text)):
maxpossible = 0
for b in range(0, len(text)):
if(a == b):
continue
c = text[a] ^ text[b]
if c not in letters and c != 0:
continue
maxpossible += 1
if maxpossible>max_possible:
max_possible=maxpossible
possible_space=a
key = text[possible_space]^ 0x20
return chr(key)
text = ''
with open("6.txt","r") as f:
for line in f:
text += line
b = base64.b64decode(text)
for KEYSIZE in range(2, 40):
# KEYSIZE=29
block_bytes = [[] for _ in range(KEYSIZE)]
for i, byte in enumerate(b):
block_bytes[i % KEYSIZE].append(byte)
keys = ''
try:
for bbytes in block_bytes:
keys += break_single_key_xor(bbytes)
key = bytearray(keys * len(b), "utf-8")
plaintext = bxor(b, key)
print("keysize:", KEYSIZE)
print("key is:", keys, "n")
s = bytes.decode(plaintext)
print(s)
except Exception:
continue
在之前的讲述上,理解这段代码并不难,读者试着输出所有可能的结果,我们可以看到有40种不同的结果,当密钥长度爆破到29的时候,明文清晰可见。但是这里是采用爆破的方式猜解密钥长度,不是很智能。当我们使用之前汉明距离猜解密钥长度的方法,可以更加快速的得出结果,以下是改进版:
import base64
import string
def bxor(a, b): # xor two byte strings of different lengths
if len(a) > len(b):
return bytes([x ^ y for x, y in zip(a[:len(b)], b)])
else:
return bytes([x ^ y for x, y in zip(a, b[:len(a)])])
def hamming_distance(b1, b2):
differing_bits = 0
for byte in bxor(b1, b2):
differing_bits += bin(byte).count("1")
return differing_bits
def break_single_key_xor(text):
key = 0
possible_space=0
max_possible=0
letters = string.ascii_letters.encode('ascii')
for a in range(0, len(text)):
maxpossible = 0
for b in range(0, len(text)):
if(a == b):
continue
c = text[a] ^ text[b]
if c not in letters and c != 0:
continue
maxpossible += 1
if maxpossible>max_possible:
max_possible=maxpossible
possible_space=a
key = text[possible_space]^ 0x20
return chr(key)
text = ''
with open("6.txt","r") as f:
for line in f:
text += line
b = base64.b64decode(text)
normalized_distances = []
for KEYSIZE in range(2, 40):
#我们取其中前6段计算平局汉明距离
b1 = b[: KEYSIZE]
b2 = b[KEYSIZE: KEYSIZE * 2]
b3 = b[KEYSIZE * 2: KEYSIZE * 3]
b4 = b[KEYSIZE * 3: KEYSIZE * 4]
b5 = b[KEYSIZE * 4: KEYSIZE * 5]
b6 = b[KEYSIZE * 5: KEYSIZE * 6]
normalized_distance = float(
hamming_distance(b1, b2) +
hamming_distance(b2, b3) +
hamming_distance(b3, b4) +
hamming_distance(b4, b5) +
hamming_distance(b5, b6)
) / (KEYSIZE * 5)
normalized_distances.append(
(KEYSIZE, normalized_distance)
)
normalized_distances = sorted(normalized_distances,key=lambda x:x[1])
for KEYSIZE,_ in normalized_distances[:5]:
block_bytes = [[] for _ in range(KEYSIZE)]
for i, byte in enumerate(b):
block_bytes[i % KEYSIZE].append(byte)
keys = ''
try:
for bbytes in block_bytes:
keys += break_single_key_xor(bbytes)
key = bytearray(keys * len(b), "utf-8")
plaintext = bxor(b, key)
print("keysize:", KEYSIZE)
print("key is:", keys, "n")
s = bytes.decode(plaintext)
print(s)
except Exception:
continue
改进后我们可以更加快速的破解出明文,而且最后的人工搜索阶段也会减少很多的对比,十分友好。
当然除了利用空格来猜测密钥这种方法外,我们还有另外一种比较大众化的思路,那就是是利用了字母出现的频率统计规律进行权重赋值。其实说白了就是字频攻击。在methon one中的第一部以后,我们就有了一组组类似凯撒加密的密文,只不过他们组不成完整的词或句子,如果我们单单暴力遍历256种密钥可能,那么结果我们也缺少一个衡量的指标,别说256中可能够你看的,而且没有一种是成词成句的。所以这样解出密钥很费力。我们需要一个评判的指标实现高可用和高效性。这时词频攻击的优势就体现出来了。我们可以给英文中的字母根据百分比附一个权重,然后依次计算256组解密后的“明文”总权重,当总权值最高时,我们有理由相信这时的密钥字节是正确的。因为当截获的密文足够多,我们可以得到分布十分贴近字频规律的明文,这样算出来的总权值就越大。关于字频的统计特性,我们可以在网上搜到很多权重赋值版本。以下是对the cryptopals crypto challenges question6的解题样例:
import base64
import string
def bxor(a, b): # xor two byte strings of different lengths
if len(a) > len(b):
return bytes([x ^ y for x, y in zip(a[:len(b)], b)])
else:
return bytes([x ^ y for x, y in zip(a, b[:len(a)])])
def hamming_distance(b1, b2):
differing_bits = 0
for byte in bxor(b1, b2):
differing_bits += bin(byte).count("1")
return differing_bits
def score(s):
freq = {}
freq[' '] = 700000000
freq['e'] = 390395169
freq['t'] = 282039486
freq['a'] = 248362256
freq['o'] = 235661502
freq['i'] = 214822972
freq['n'] = 214319386
freq['s'] = 196844692
freq['h'] = 193607737
freq['r'] = 184990759
freq['d'] = 134044565
freq['l'] = 125951672
freq['u'] = 88219598
freq['c'] = 79962026
freq['m'] = 79502870
freq['f'] = 72967175
freq['w'] = 69069021
freq['g'] = 61549736
freq['y'] = 59010696
freq['p'] = 55746578
freq['b'] = 47673928
freq['v'] = 30476191
freq['k'] = 22969448
freq['x'] = 5574077
freq['j'] = 4507165
freq['q'] = 3649838
freq['z'] = 2456495
score = 0
string=bytes.decode(s)
for c in string.lower():
if c in freq:
score += freq[c]
return score
def break_single_key_xor(b1):
max_score = 0
english_plaintext = 0
key = 0
for i in range(0,256):
b2 = [i] * len(b1)
try:
plaintext = bxor(b1, b2)
pscore = score(plaintext)
except Exception:
continue
if pscore > max_score or not max_score:
max_score = pscore
english_plaintext = plaintext
key = chr(i)
return key
text = ''
with open(r"c:/Users/lyy18291855970/Desktop/密码学/密码题/the cryptopals crypto challenges/6.txt", "r") as f:
for line in f:
text += line
b = base64.b64decode(text)
normalized_distances = []
for KEYSIZE in range(2, 40):
# 我们取其中前6段计算平局汉明距离
b1 = b[: KEYSIZE]
b2 = b[KEYSIZE: KEYSIZE * 2]
b3 = b[KEYSIZE * 2: KEYSIZE * 3]
b4 = b[KEYSIZE * 3: KEYSIZE * 4]
b5 = b[KEYSIZE * 4: KEYSIZE * 5]
b6 = b[KEYSIZE * 5: KEYSIZE * 6]
b7 = b[KEYSIZE * 6: KEYSIZE * 7]
normalized_distance = float(
hamming_distance(b1, b2) +
hamming_distance(b2, b3) +
hamming_distance(b3, b4) +
hamming_distance(b4, b5) +
hamming_distance(b5, b6)
) / (KEYSIZE * 5)
normalized_distances.append(
(KEYSIZE, normalized_distance)
)
normalized_distances = sorted(normalized_distances, key=lambda x: x[1])
for KEYSIZE, _ in normalized_distances[:5]:
block_bytes = [[] for _ in range(KEYSIZE)]
for i, byte in enumerate(b):
block_bytes[i % KEYSIZE].append(byte)
keys = ''
for bbytes in block_bytes:
keys += break_single_key_xor(bbytes)
key = bytearray(keys * len(b), "utf-8")
plaintext = bxor(b, key)
print("keysize:", KEYSIZE)
print("key is:", keys, "n")
s = bytes.decode(plaintext)
print(s)
反思回顾
通过这一番折腾,对流密码的重用的不安全性有了更加深入的理解,同时也是对ctf密码题这类异或题型的解题思路的一次总结升华。在文章的最后想把这篇文章里用到的几个不错的思路或者说想法做一个总结性摘录:
1. 在异或加密中,明文和明文异或等于密文和密文异或,并且二者的汉明距离一样。
2. 空格和所有小写字母异或结果是相应的大写字母,空格和所有大写字母异或是相应的小写字母。除了空格以外,仍旧有一些组合可以出现异或结果是大小写字母,但是空格出现时,结果在大小写字母间的概率最大。
3. 两个以ascii编码的英文字符的汉明距离是2-3之间,也就是说正常英文字母的平均汉明距离为2-3(每比特),任意字符(非纯字母)的两两汉明距离平均为4。
4. 在破解这类问题的三步走:猜解密钥长度;根据密钥长度分组,依次求解密钥每个字节得出密钥;最后根据密钥还原出明文。
参考文献
https://crypto.stackexchange.com/questions/8115/repeating-key-xor-and-hamming-distance
https://cypher.codes/writing/cryptopals-challenge-set-1







发表评论
您还未登录,请先登录。
登录