

最近在研究yara文件,想着拿到yara编译文件以后,是否可以直接反编译呢?猜测已经有现成的工具可以使用了,但是网上没有找到相关 的工具,github上也没有找到反编译相关的工具,只能自己动手亲自实践,也算是一个学习的过程了。网上也有一篇相关的文章可以学习,我也学习了其中部分内容,文章链接:https://bnbdr.github.io/posts/swisscheese/。
首先我们要分清楚yara源代码和yara编译之后的文件,很简单,如果你打开一个文件,看到的是如下所示类似格式的代码,那么它就是yara源代码,在使用yara源代码扫描文件时需要先转换为字节码文件,再执行。
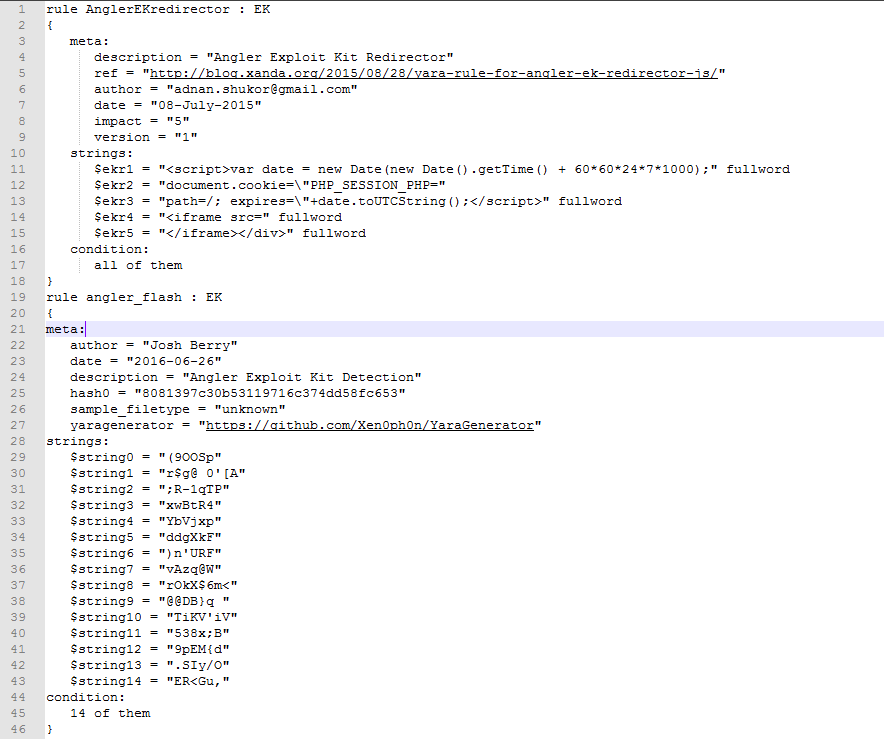
以下这张图是yara文件编译之后的二进制格式,编译之后在你使用时它会加载更快,扫描更快,并且防止源码泄露,并且不再需要编译成字节码的形式了,因为你编译之后就已经变成了字节码文件了,相比源代码扫描文件来说就少了一步了,所以更快一些,还有出于商业角度的考虑,各大杀软厂商也会通过使用编译后的yara规则提高扫描速度。
我的思路呢,其实也很简单,因为yara本身就是开源的,而且网上没有相关工具,只能自己硬啃yara编译源码,什么时候都是官方的最权威,所以以yara官方的源码为出发点,开始分析源码中是如何一步一步进行扫描文件和内存的?流程是怎样的?逻辑是怎样的?
执行流程
yara.c—> main—> yr_rules_scan_file—> yr_rules_scan_mem—> yr_rules_scan_mem_blocks —> yr_rules_foreach—> callback —> handle_message
在callback处下断点单步进入后会到 handle_message(重点函数)处,函数定义如下所示:
static int callback(
int message,
void* message_data,
void* user_data)
{
YR_MODULE_IMPORT* mi;
YR_OBJECT* object;
MODULE_DATA* module_data;
switch(message)
{
case CALLBACK_MSG_RULE_MATCHING:
case CALLBACK_MSG_RULE_NOT_MATCHING:
return handle_message(message, (YR_RULE*) message_data, user_data);
case CALLBACK_MSG_IMPORT_MODULE:
mi = (YR_MODULE_IMPORT*) message_data;
module_data = modules_data_list;
while (module_data != NULL)
{
if (strcmp(module_data->module_name, mi->module_name) == 0)
{
mi->module_data = (void*) module_data->mapped_file.data;
mi->module_data_size = module_data->mapped_file.size;
break;
}
module_data = module_data->next;
}
return CALLBACK_CONTINUE;
case CALLBACK_MSG_MODULE_IMPORTED:
if (show_module_data)
{
object = (YR_OBJECT*) message_data;
mutex_lock(&output_mutex);
yr_object_print_data(object, 0, 1);
printf("\n");
mutex_unlock(&output_mutex);
}
return CALLBACK_CONTINUE;
}
return CALLBACK_ERROR;
}可以看到不管是否匹配规则都会到这个消息处理函数处,这个函数中会根据传入的参数决定输出显示哪些信息,我主要就是修改了这个函数中一些处理逻辑。
static int handle_message(
int message,
YR_RULE* rule,
void* data)
{
const char* tag;
int show = TRUE;
if (tags[0] != NULL)
{
// The user specified one or more -t <tag> arguments, let's show this rule
// only if it's tagged with some of the specified tags.
show = FALSE;
for (int i = 0; !show && tags[i] != NULL; i++)
{
yr_rule_tags_foreach(rule, tag)
{
if (strcmp(tag, tags[i]) == 0)
{
show = TRUE;
break;
}
}
}
}
if (identifiers[0] != NULL)
{
// The user specified one or more -i <identifier> arguments, let's show
// this rule only if it's identifier is among of the provided ones.
show = FALSE;
for (int i = 0; !show && identifiers[i] != NULL; i++)
{
if (strcmp(identifiers[i], rule->identifier) == 0)
{
show = TRUE;
break;
}
}
}
int is_matching = (message == CALLBACK_MSG_RULE_MATCHING);
show = show && ((!negate && is_matching) || (negate && !is_matching));
if (show && !print_count_only)
{
mutex_lock(&output_mutex);
if (show_namespace)
printf("%s:", rule->ns->name);
printf("%s ", rule->identifier);
if (show_tags)
{
printf("[");
yr_rule_tags_foreach(rule, tag)
{
// print a comma except for the first tag
if (tag != rule->tags)
printf(",");
printf("%s", tag);
}
printf("] ");
}
// Show meta-data.
if (show_meta)
{
YR_META* meta;
printf("\n{\n meta:\n");
yr_rule_metas_foreach(rule, meta)
{
if (meta != rule->metas)
printf("\n");
if (meta->type == META_TYPE_INTEGER)
{
printf(" %s=%" PRId64, meta->identifier, meta->integer);
}
else if (meta->type == META_TYPE_BOOLEAN)
{
printf(" %s=%s", meta->identifier, meta->integer ? "true" : "false");
}
else
{
printf(" %s=\"", meta->identifier);
print_escaped((uint8_t*) (meta->string), strlen(meta->string));
putchar('"');
}
}
printf("\n");
}
// Show matched strings.
if (show_strings || show_string_length)
{
YR_STRING* string;
printf("\n strings:\n");
yr_rule_strings_foreach(rule, string)
{
YR_MATCH* match;
int result = 1;
//这里把每次取到的字符串传入做匹配,匹配成功并打印
yr_string_matches_foreach(string, match)
{
result = 0;
if (show_string_length)
printf(" %d:%s" , match->data_length , string->identifier);
else
printf(" %s" , string->identifier);
if (show_strings)
{
printf("= ");
if (STRING_IS_HEX(string))
print_hex_string(match->data, match->data_length);
else
print_string(match->data, match->data_length);
}
else
{
printf("\n");
}
}
if (result)
{
//这里打印所有未匹配到的strings
print_all_no_match_string(string);
}
}
}
mutex_unlock(&output_mutex);
printf("\n}\n");
}
if (is_matching)
{
((CALLBACK_ARGS*) data)->current_count++;
total_count++;
}
if (limit != 0 && total_count >= limit)
return CALLBACK_ABORT;
return CALLBACK_CONTINUE;
}我这里简单说明下吧,其实有耐心多调试几次,就可以发现你想要的信息都保存在YR_RULE类似的结构体中,只不过官方把这些信息全部都封装起来了,它并没有提供输出反编译后的信息,这个就需要自己手动调试,修改一些处理逻辑,将这些所谓“隐藏“的信息全部打印出来即可。
以上我说的只是匹配中规则以后,那么就可以获取到你想要的信息,都可以打印,那还有一些没有匹配中规则的,我们也需要将它反编译出来,这里我们稍微修改一下代码,让它在循环遍历匹配时,不成功也打印,这里就时套用它的一些代码风格,就可以正确打印出一些未匹配成功的规则。print_all_no_match_string函数代码如下:
static void print_all_no_match_string(YR_STRING* string)
{
if (STRING_IS_HEX(string))
{
printf(" %s= {", string->identifier);
for (int i = 0; i < string->length; i++)
printf("%s%02X", (i == 0 ? "" : " "), string->string[i]);
printf("}");
}
else
printf(" %s=\"%s\"\n", string->identifier, string->string);
}源代码的修改基本完成了,编译下就可以使用了,那么我这里还需要说一下,我的逻辑是,我提供一个空规则txt文件,然后使用已编译的yara规则去扫描,并且带-nms参数扫描,此时就会打印出所有反编译的规则了,先看下效果:
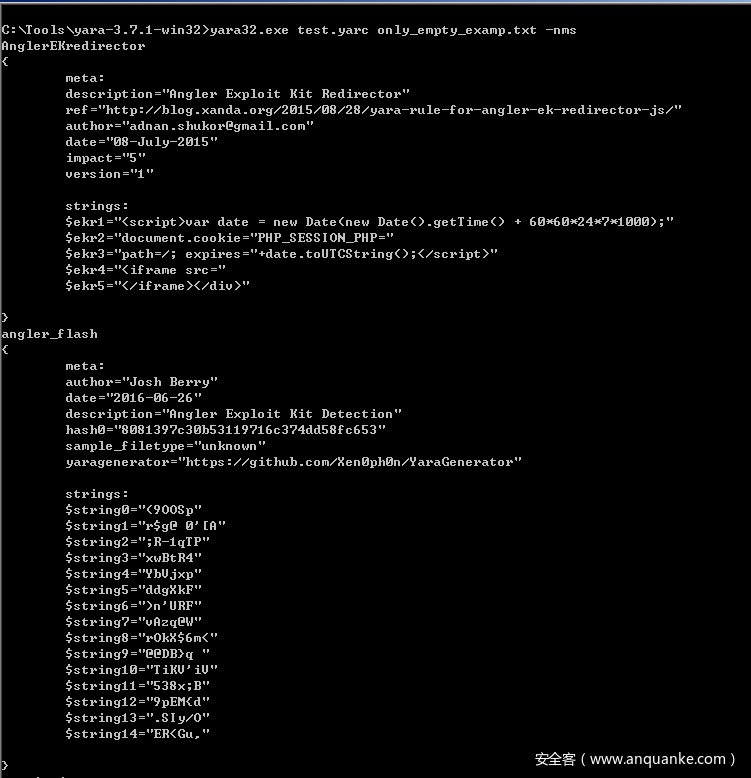
这里重点解释下为什么是-nms参数,先看下帮助信息,对于nms参数的介绍:
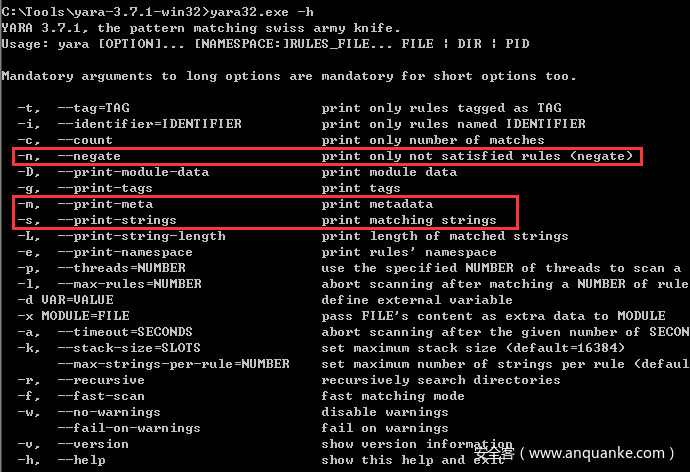
-n 仅打印不满足条件的规则
-m 打印元数据
-s 打印匹配的字符串
所以 -nms参数的意思就是打印所有不满足条件规则的元数据和字符串
使用方法:yara32.exe 已编译的规则.yarc 空规则.txt -nms







发表评论
您还未登录,请先登录。
登录