

〇.
最近做一些堆利用的题目时感觉基础掌握的不是很牢靠,之前没有仔细的研究过 glibc 中的内存管理策略,导致遇到某些题目的时候总是会忽略掉重要的细节(libc 层面),所以这次就来仔细研究一下 malloc 和 free 的实现。
内存管理
动态内存管理是很重要的功能,内存一直都是很宝贵的资源,一个好的内存管理策略可以极大地提升系统性能,就 C 内存管理而言,主要的管理程序有
Doug Lea Malloc
BSD Malloc
Hoard
TCMalloc
ptmalloc
目前主流 Linux 系统所使用的都是 ptmalloc,由 Wolfram Gloger 基于 Doug Lea Malloc 修改而来。ptmalloc 包括 malloc free 等一组函数,实现了动态的内存管理,区别一个内存管理器好坏的重要标准就是 分配和释放内存的速度。
当 Linux 加载了一个可执行程序时,会先将程序从硬盘上映射到内存中, 以 32 位程序为例,映射的顺序为 .text段、.data段、.bss段,接着会生成 stack 区域以及 heap 区域、mmap 区域。一个典型的 32 位程序的内存布局大致如下
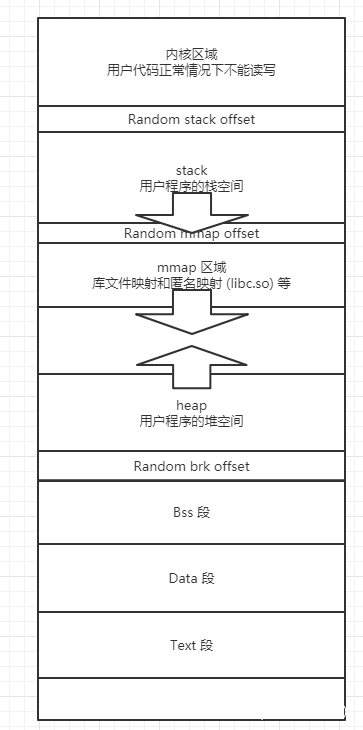
其中,内核区域占据 1GB 空间,用户程序占据 3GB 空间,但是同一时间可以运行多个程序,如果整个内存被一个程序全部占据的话,其他程序是不是就无法运行了呢?其实不然,可以参考 windows 的实现方法,系统为每个程序分配了虚拟内存,只是在逻辑上每个程序占据着整块内存,但实际上物理内存中同时存在很多程序,操作系统通过虚拟内存管理器将虚拟地址映射到物理地址上面,保证系统正常工作。
实现内存管理主要有三个层面,分别是用户管理层、C 运行时库层以及操作系统层,操作系统层提供了最底层的内存管理方案如 syscall,linux 操作系统提供了 brk() 函数来实现内存的分配,而 C 运行时库则提供了 sbrk() 函数,我们常用的 malloc free 等类似的函数就是使用了 C 运行库提供的函数。
当程序向操作系统申请动态内存时,系统会调用相应的函数分配内存,但是这种分配并不是实时的,首先内核会给程序分配一个线性区(虚拟内存),只有当用户开始使用这块内存时,才会分配物理页面。当释放一块内存时,会通过线性区找到物理页面,然后才执行释放操作。
为了提高内存管理效率,ptmalloc 设置了一些缓冲区,当用户分配内存时,ptmalloc 会优先检查缓冲区中是否存在合适的空间,如果存在就直接返回给用户,这样大大降低了向内核申请空间的次数。同样的,当用户释放某块内存时,ptmalloc 会将这块内存插入对应的缓冲区内,以便于下一次分配使用,这些缓冲区就是所谓的 fastbin、smallbin 等等链表。
ptmalloc 的几个特性
1. 需要长时间保存、使用的内存(存活期长)的分配使用 mmap
2. 很大的内存分配使用 mmap
3. 存活期短的内存块使用 brk 分配
4. 尽量只缓存较小的内存块,很大的内存块在释放之后立即归还操作系统
5. 空闲的内存块(处于缓冲区中)只在 malloc 和 free 时进行合并
malloc
本部分根据 malloc.c 代码注释以及逻辑对 malloc 进行了简要分析。
代码可以在 woboq 找到。
ptmalloc 的适应性
一个内存管理器最理想的情况是针对项目进行专门的优化,也就是说,每个项目针对自身情况开发出的内存管理器才是最优的,但是这样做的成本太高,而且开发一个内存管理器难度也是很高的,既要考量和内核的兼容性,又要可移植,效率要高并且稳定,所以,最好的办法是有一个折中的内存管理机制,各方面不需要很突出,但是适用性广,可以很好地兼容在各种大型项目中。
ptmalloc 的设计思想就是这样,它具有良好的兼容性、可移植性、稳定性,并且兼具效率,这样一个内存管理器对于开发一些正常的项目足够了。
main_arena and non_main_arena
又称为主分配区和非主分配区,main_arena 是一个结构体,定义在 malloc.c 中的 malloc_state
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
结构体对每一个成员给出了解释,第一个成员是 linux 下的锁,Doug Lea 实现的内存分配器只有一个主分配区,为了兼容多线程,每次分配内存之前都要对主分配区加锁,防止多线程对内存分配造成影响,这样就导致多线程锁的激烈竞争,降低了内存分配效率,而 ptmalloc 支持多线程,增加了 non_main_arena (非主分配区),所谓 non_main_arena 其结构和主分配区相同,很多分配区通过环形链表相互串联,这样,多个线程就无需争夺同一个分配区了。但是分配区的数量毕竟是有限的,在极端情况下多个线程还是会竞争同一个分配区,所以锁依旧有用,先加锁的进程可以优先使用分配区,如果全部分配区都被加锁,那么后面的进程就会进入阻塞状态。对于 32 位系统来说,arena 最多为核心数量的 2 倍,64 位系统下 arena 最多为核心数量的 8 倍。
第二个成员是标志位,第三个成员用来标识最近是否有新的内存块被插入 fastbin 链表。
第四个成员是 fastbin 链表,第五个成员是 top chunk 的地址,在堆利用中可能会用到。第六个成员标识最后一次拆分 top chunk 得到的剩余部分,第七个成员是 smallbin、largebin 和 unsortedbin 的集合体,一共有 126 个表项。
补:为什么有 126 个表项?这是由于 bin[0] 和 bin[127] 没有被使用,并且 bin[1] 是整个 bin 的头部。 注意 bin 定义的数量为 NBINS * 2 – 2 = 254,为什么是 254? 这是由于缓冲区链表主要有 fd 和 bk 两个指针,smallbin 62 个、largebin 63 个,加在一起是 125 个,再加上一个头结点 bin[1] 共 126 个表项,换算成 index 一共有 252 个,所以 254 个指针空间是完全足够的!
第八个成员可以视为一张地图,标识链表是否为空。第九个成员是 next 指针,指向下一个 arena。
第十个成员指向下一个为空的 arena。第十一个成员用来标识绑定在当前 arena 线程的总量。
最后两个成员用来跟踪当前被系统分配的内存总量。
这个 glibc 版本比较新的,有一些新加入的定义。
chunk
chunk 称为堆块,是堆的重要组成部分,当用户申请内存块时,系统就会将空间以堆块的形式返回,堆块具有一定的结构,且按照大小分为 4 类,堆块的结构定义在 malloc.c 中,代码如下
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
基本结构包含 6 个成员,首先是 mchunk_prev_size,如果当前堆块的前一个堆块是空闲的,那么此字段就是前一个堆块的 size。
接着是当前堆块的 size,然后有两个指针,由于各种 bin 的存在,当堆块被释放后会进入对应的缓冲区中,并且以链表的形式存在,这里的 fd 和 bk 就是链表的前向后向指针,最后两个也是指针,但是它们只会出现在 largebin chunk 中,具体会在后面提到。
一个堆块可能会是下面的状态
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
需要注意 size 标志位的最低三位 A、M、P,由于对齐的原因,如果把 size 转换成二进制,它的最低三个 bit 始终都是 0,所以它们就有了新的用途。
A(NON_MAIN_ARENA) 用来表示当前堆块是否属于 main_arena,M(IS_MAPPED)用来表示当前堆块是否由 mmap 分配,P(PREV_INUSE)是最为常用的标志位,用来表示当前堆块的前一个堆块是否空闲。
bins
接下来是链表的分类,前面提到为了加快内存分配效率,ptmalloc 引入了缓冲区,把较小的堆块保存在缓冲区中,这样就可以减少和操作系统申请内存的次数,提高效率。缓冲区有一定的格式,按照堆块的大小分成了 4 类即 fastbin、smallbin、largebin、unsortedbin。
第一类是 fastbin chunk,它的基本结构如下
+-----------------+-----------------+
| | |
| prev_size | size |
| | |
+-----------------------------------+
| | |
| fd | |
| | |
+-----------------+ |
| |
| user data |
| |
+-----------------------------------+
fastbin chunk 的大小限制在 0x10 ~ 0x40(0x20 ~ 0x80 if OS is 64 bit),这些 chunk 通过 fd 连接成一条单向链表,在主分配区中定义了 fastbins 指针,我们可以将它展开
index size
fastbinY[0] 0x20
fastbinY[1] 0x30
fastbinY[2] 0x40
fastbinY[3] 0x50
fastbinY[4] 0x60
fastbinY[5] 0x70
fastbinY[6] 0x80
fastbinY[7] N/A
fastbinY[8] N/A
fastbinY[9] N/A
最后三个是保留项,暂时没有使用。
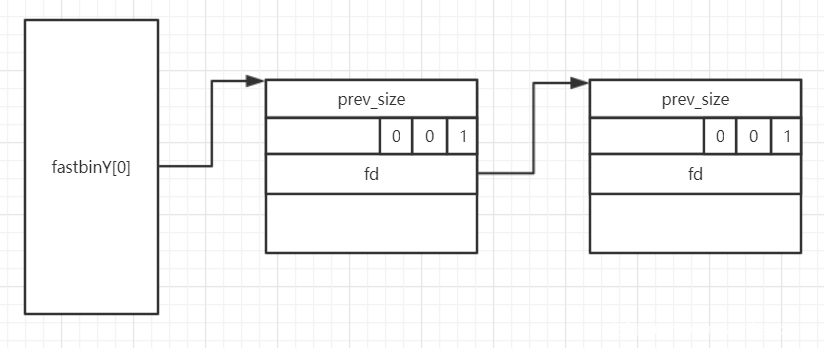
fastbin 顾名思义,它分配堆块的速度很快,且仅仅保存很小的堆块,fastbin chunk 的两个特点是没有 bk 指针并且 PREV_INUSE 标志位一定是 1,也就是说 fastbin chunk 不会和其他堆块合并(在特殊情况下还是会发生合并)。另外,fastbin 采用 LIFO 策略,从头部插入,头部取出,这样可以进一步提高分配效率。
附:fastbin 链表大致结构
第二类是 smallbin,这也是很常用的链表,smallbin chunk 近似于一个标准格式的 chunk,结构如下
+-----------------+-----------------+
| | |
| prev_size | size |
| | |
+-----------------------------------+
| | |
| fd | bk |
| | |
+-----------------------------------+
| |
| |
| user data |
| |
| |
+-----------------+-----------------+
相比于 fastbin chunk,这里多出了 bk 指针,需要注意的是 fd 和 bk 指针(以及 fd_nextsize、bk_nextsize 指针)都是可以作为用户数据被覆盖的,它们只会在堆块空闲时发挥作用。
smallbin 的范围在 0x10 ~ 0x1f0(0x20 ~ 0x3f0 if OS is 64 bit),smallbin 和 fastbin 有一部分是重合的,其实 fastbin 中的堆块在一定情况下可以进入到 smallbin 中(当发生 consolidate 时)。一些 smallbin chunk 相互串联形成了一条双向链表
附:smallbin 链表大致结构
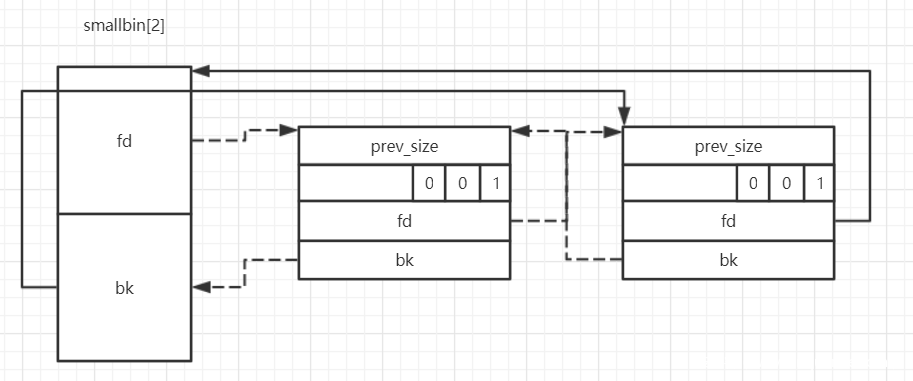
smallbin 链表从头部插入,尾部取出。
第三类是 largebin,专门用来保存一些较大的堆块,范围从 0x200 开始。一个 largebin chunk 结构可能如下
+---------------+---------------+
| | |
| prev_size | size |
| | |
+-------------------------------+
| | |
| fd | bk |
| | |
+-------------------------------+
| | |
| fd_nextsize | bk_nextsize |
| | |
+---------------+---------------+
| |
| |
| user_data |
| |
+-------------------------------+
largebin共63个,组织方法如下:
32个bin 每64个字节一个阶层,比如第一个512-568字节,第二个576 – 632字节……
16个bin 每512字节一个阶层
8个bin每4096字节一个阶层
4个bin每32768字节一个阶层
2个bin每262144字节一个阶层
最后一个bin包括所有剩下的大小。不同于其他链表,largebin 每一个表项保存的是一个范围,所以会用到 fd_nextsize & bk_nextsize 指针。fd 和 bk 指针的功能和 smallbin 的相同,但是 fd_nextsize & bk_nextsize 就有些复杂,fd_nextsize 指向第一个比当前堆块大的堆块,bk_nexisize 反之。
第四类是 unsortedbin,这个链表比较特殊,它没有针对大小进行排序,这一点从名字也能看出来,它可以被视为 smallbin 和 largebin 的缓冲区,当用户释放一个堆块之后,会先进入 unsortedbin,再次分配堆块时,ptmalloc 会优先检查这个链表中是否存在合适的堆块,如果找到了,就直接返回给用户(这个过程可能会对 unsortedbin 中的堆块进行切割),若没有找到合适的,系统会清空这个链表,将堆块插入对应的链表中。下面引用 malloc.c 中的注释
Unsorted chunks
All remainders from chunk splits, as well as all returned chunks,
are first placed in the "unsorted" bin. They are then placed
in regular bins after malloc gives them ONE chance to be used before
binning. So, basically, the unsorted_chunks list acts as a queue,
with chunks being placed on it in free (and malloc_consolidate),
and taken off (to be either used or placed in bins) in malloc.
The NON_MAIN_ARENA flag is never set for unsorted chunks, so it
does not have to be taken into account in size comparisons.
内存分配流程
前置基础知识大概就那些,还有一部分关于多线程的东西会放在后面,下面看一下 malloc 的分配流程,当程序第一次启动起来,heap 尚未初始化,这时如果去访问 heap 位置的内存会触发段错误,具体原因和上面说的类似,还没有绑定物理地址。
首先找到 malloc 函数的入口,在 glibc 的源代码中是找不到 malloc 这个函数的,当执行 malloc 时核心函数是 _int_malloc,新版本的 glibc 修改了 malloc 的外壳函数。为了方便,暂时不分析新版本,切换 glibc 到老版本 (2.12.1),外壳函数为 public_mALLOc()
Void_t* public_mALLOc(size_t bytes)
{
mstate ar_ptr;
Void_t *victim;
__malloc_ptr_t (*hook) (size_t, __const __malloc_ptr_t)
= force_reg (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0)); // 检查是否存在 hook
arena_lookup(ar_ptr);
arena_lock(ar_ptr, bytes); // 尝试获取分配区并加锁
if(!ar_ptr)
return 0; // 失败退出
victim = _int_malloc(ar_ptr, bytes); // 加锁成功,调用核心函数分配内存
if(!victim) { // 如果分配失败,可能是 mmap 区域用光了
/* Maybe the failure is due to running out of mmapped areas. */
if(ar_ptr != &main_arena) { // 判断当前分配区是不是主分配区
(void)mutex_unlock(&ar_ptr->mutex); // 不是主分配区, 将当前分配区解锁
ar_ptr = &main_arena;
(void)mutex_lock(&ar_ptr->mutex); // 尝试锁定主分配区
victim = _int_malloc(ar_ptr, bytes); // 再次尝试分配内存
(void)mutex_unlock(&ar_ptr->mutex); // 解锁主分配区
} else { // 当分配区是主分配区,并且内存分配失败,可能是 sbrk 出了问题
#if USE_ARENAS
/* ... or sbrk() has failed and there is still a chance to mmap() */
ar_ptr = arena_get2(ar_ptr->next ? ar_ptr : 0, bytes); // 检查是否还有非主分配区
(void)mutex_unlock(&main_arena.mutex); // 解锁主分配区
if(ar_ptr) { // 如果成功找到了一个非主分配区,就继续尝试分配内存
victim = _int_malloc(ar_ptr, bytes);
(void)mutex_unlock(&ar_ptr->mutex); // 解锁非主分配区
}
#endif
}
} else
(void)mutex_unlock(&ar_ptr->mutex); // 分配结束,解锁分配区。
assert(!victim || chunk_is_mmapped(mem2chunk(victim)) ||
ar_ptr == arena_for_chunk(mem2chunk(victim)));
return victim;
}
#ifdef libc_hidden_def
libc_hidden_def(public_mALLOc)
#endif
外壳函数逻辑比较简单,主要是处理分配区的问题,尽量成功分配内存给用户,接下来是核心函数 _int_malloc()
补: 关于 arena 的问题,ptmalloc 可以有多个 arena,用来给不同的线程使用,外壳代码中调用了 arena_lookup 来寻找一个可用的 arena,其流程大概是首先判断一下当前线程最后一次使用的 arena 是否空闲(先查看线程私有对象中是否已经存在一个分配区),如果不是,就循环遍历 arena 链表,尝试找到一个空闲的 arena,如果找不到,就判断一下当前 arena 的总数,若小于最大值,就创建一个新的 arena,并且把新的 arena 插入到全局分配区循环链表并且加锁。新建的分配区一定是 non_main_arena,因为主分配区是从父进程继承的。
核心函数很长,就不贴所有代码了,有兴趣的同学可以去官网下载 glibc 的源代码。
首先是声明必要的变量,将所有要用的变量声明在函数头部可以方便后续的修改(此处代码不涉及逻辑)。
接着调用了函数
checked_request2size(bytes, nb);
bytes 是用户传入的数字,nb 是真实 chunk 的大小,调用这个函数的目的是通过用户的输入计算出需要分配的 chunk 大小。这是由于对齐的原因,正常分配的 chunk 并不是输入的大小是多少就分配多少,而是会 SIZE 字节对齐,例如在 64 位系统下 malloc(1),系统返回给我们的堆块实际上最多能容纳 16 个字节。
从这里开始 malloc 会分成 3 条路。
第一条: 当 nb 属于 fastbin chunk 时
/*
If the size qualifies as a fastbin, first check corresponding bin.
This code is safe to execute even if av is not yet initialized, so we
can try it without checking, which saves some time on this fast path.
*/
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) { // 判断是否在 fastbin 范围内
idx = fastbin_index(nb); // 根据 nb 计算出在 fastbin 中的 index
mfastbinptr* fb = &fastbin (av, idx); // 根据 index 取一个堆块(无论是否为空)
#ifdef ATOMIC_FASTBINS
mchunkptr pp = *fb;
do
{
victim = pp;
if (victim == NULL)
break;
}
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim))
!= victim);
#else
victim = *fb; // 将取出的堆块给 victim
#endif
if (victim != 0) { // 判断取出的堆块是否为空
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) // 检查堆块的 size
{
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr (check_action, errstr, chunk2mem (victim));
return NULL;
}
#ifndef ATOMIC_FASTBINS
*fb = victim->fd;
#endif
check_remalloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 返回给用户
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
}
利用 fastbin,首先检查 nb(上面计算出的真实 chunk 大小)是否小于等于 fastbin 的最大值,如果是,会进入到上面的代码逻辑中。这里分为两种情况,如果没有开启 ATOMIC_FASTBINS 优化则分配过程很简单,首先根据 nb 找到对应的 fastbin index,接着从对应的链表中取出一个堆块(可能为空),判断取出的是否为空,如果不为空,进一步判断此堆块的 size 是否和 index 对应。如果这些检查都通过,就会把堆块返回给用户。
当开启了 ATOMIC_FASTBINS 情况就变得复杂起来,这个优化选项是新版本 libc 添加的,虽然 ptmalloc 支持多线程操作,但是当在分配区中申请很多小内存时,会使得内存碎片化,ptmalloc 会尝试清理这些碎片,在清理碎片的时候就不可避免的要对分配区进行加锁操作,每一次加锁要消耗大约 100ns 的时间,这就导致了当很多线程进行动态内存申请时,ptmalloc 的效率大幅下降。
于是 ptmalloc 在新版本中对锁进行了优化,添加 PER_THREAD 和 ATOMIC_FASTBINS 两个优化选项,但是默认情况下这些选项是不会开启的。
结合华庭的文章可以大致了解一下优化的策略,ATOMIC_FASTBINS 用到了一种叫做 lock-free 的技术实现单向链表删除第一个节点的操作(和数据结构很类似,但是要考虑多线程的影响),多线程安全在 《程序员的自我修养》这本书中有简要的介绍,线程(又称为 轻量级进程)是进程的一部分,一个进程中可以包含多个线程,这些线程共享进程的资源,这就隐藏着一个问题,资源只有一份,如果两个线程同时去修改这份资源,就有可能会引发未定义的行为。例如下面的代码
线程1 线程2
i=1; --i;
++i;
++i 这种代码的一种实现方法可能是
将 i 读取到某一个寄存器中
寄存器自增 1
将寄存器中的值存回 i
但是现在涉及到一个多线程的问题,如果程序的执行顺序是
X1 表示线程 1 的寄存器 X2 表示线程 2 的寄存器
序号 指令 线程
1 i = 1 1
2 X1 = i 1
3 X2 = i 2
4 X1++ 1
5 X2-- 2
6 i = X1 1
7 i = X2 2
从逻辑上看,i 的最终结果应该是 1,但是现在它的结果是 0。实际上 i 的结果可能是 0、1 或 2,这就是一个典型由于没有注意线程问题引发的未定义行为。
回到 malloc 的代码中,支持多线程的基础就是保证线程安全,于是加锁成为了一种重要方式,当某个线程取得资源的锁之后,其他线程如果想要访问资源,就需要等待加锁线程完成它的工作并解锁,但是加锁会导致一些问题,首当其冲的就是性能问题,这一点在上文提到过,如果加锁不当的话还会引起死锁(dead lock)等等。
于是人们就提出了另一种思路,即无锁算法(lock-free),又叫做 CAS,CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉我V的值实际为多少”,CAS是乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。 CAS 的效率相较于锁来说提升了很多,并且更加安全了,这是因为其操作指令都是原子指令(可以在一个 CPU 周期中运行完毕,不会受其他线程影响)。
CAS 的 ABA 问题:如果有三个线程 A、B、C,若 B 线程先取得了锁,修改目标值,但是 C 线程先于 A 取得了锁,将目标值修改回最初的值,这时如果 A 取得锁,就不会发现原始值已经被修改了一次,这时可能会引发一些未定义的行为,但是在 malloc 的代码中并不会出现这种问题。
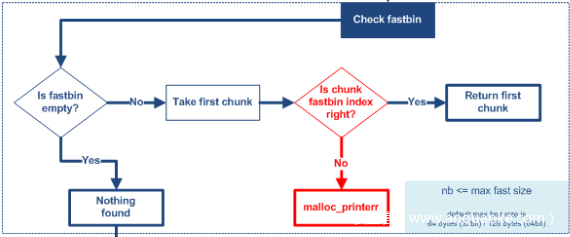
第一条路大致就是这些内容,不难发现,fastbin 是最简单、最快的一种缓冲区,有关于从 fastbin 中分配堆块的思路可以参考下面这张图片
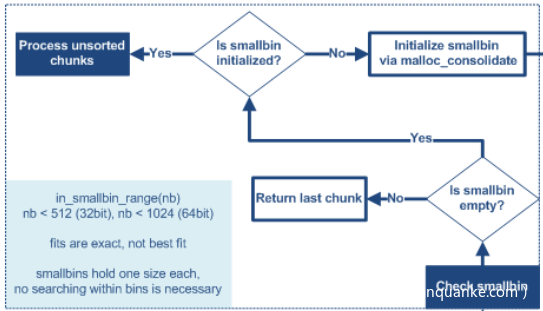
第二条: 当 nb 属于 smallbin 范围时
if (in_smallbin_range(nb)) { // 判断 nb 是否处于 smallbin 范围
idx = smallbin_index(nb); // 通过 nb 计算出其所属的 smallbin index
bin = bin_at(av,idx); // 通过上一步计算出的 index 在 arena 中找到对应链表的表头
if ( (victim = last(bin)) != bin) { // 判断 smallbin 是否为空,并且把链表中最后一个堆块给 victim
if (victim == 0) /* 初始化检查 */
malloc_consolidate(av); // 合并 fastbin 中的堆块并放置在 smallbin
else {
bck = victim->bk; // 获取当前堆块的前一个堆块
if (__builtin_expect (bck->fd != victim, 0)) // 检查 bck -> fd 是否指向 victim (链表完整性检查)
{
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
set_inuse_bit_at_offset(victim, nb); // 将 victim 下一个相邻的堆块的 P 标志位置 1
bin->bk = bck;
bck->fd = bin; // 将最后一个堆块从 smallbin 中卸下,注意这里没有清空 fd、bk 指针,pwn 题中的信息泄露一般是基于此处
if (av != &main_arena) // 检查当前分配区是否为主分配区
victim->size |= NON_MAIN_ARENA;
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 返回堆块
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
}
}
引用 malloc.c 给出的注释如下
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
首先要判断 nb 是否在 smallbin 范围内,如果是,则计算其在 smallbin 中的 index 并根据 index 找到链表的表头,接着是一个关键判断,通过 if (victim == 0) 进行初始化检查,这是由于 (victim = last(bin)) != bin 执行后 victim 有两种情况,一是 smallbin 不为空,即找到了一个合适的堆块,二是 smallbin 还没有初始化成双向循环链表,这时就要调用 malloc_consolidate 来合并 fastbin chunk 到 smallbin 中(后面会提到)。
如果找到了一块合适的内存,先找到它的上一个堆块 bck(victim -> bk),然后进行一次完整性判断,要求 bck 的 fd 指针指向 victim,如果检查通过,会将 victim 物理上相邻的下一个堆块的 P 标志位(PREV_INUSE)置 1,最后把 victim 从链表中卸下(通常使用 unlink 函数,但是为了效率这里没有使用)并返回。 通过分析代码也能发现 smallbin 的分配方式的确是尾部取出。
若 smallbin 为空会移交到下一部分代码处理。
有关于从 smallbin 中分配堆块的思路可以参考下面这张图片
第三条: nb 属于 largebin 范围 or 之前的分配请求失败
else {
idx = largebin_index(nb);
if (have_fastchunks(av))
malloc_consolidate(av);
}
首先判断 nb 在 large bin 中的 index,接着判断 fastbin 中是否存在 chunk,若存在,调用 malloc_consolidate 将 fastbin chunk 进行合并。引用 malloc.c 中的注释如下
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
大概意思是如果 nb 是一个分配大片内存的申请,首先会合并 fastbin 中的 chunk,这样做的目的是避免内存碎片化过于严重。
为什么不直接去 largebin 中取堆块,而是要先进行堆块合并?如果代码运行到这里,就说明用户申请的内存一定是 largebin 或者更大,如果在获取了 largebin index 之后直接搜索 largebin,很可能在对应位置上并不存在合适的堆块,这样,就需要向操作系统申请另一片空间来实现内存分配,当用户申请的堆块确实很大时这样做并没有什么问题,但是当用户申请的内存并不是那么大,将其他链表中(主要是 fastbin)的堆块合并之后恰好能够满足空间要求,那么就可以避免向操作系统申请内存,提升效率的同时还降低了堆的碎片化程度。
注意!只有当 nb 是一个 largebin request 时,才会执行上面的代码,其他情况(例如上面两条路中分配失败的情况)会下沉到下面的代码中处理,接下来的代码属于 malloc 的核心部分,使用了很多循环嵌套,其实这些复杂的算法主要目的就是处理之前没有分配成功的 smallbin、fastbin、largebin 等请求。
引用 malloc.c 的注释如下
Process recently freed or remaindered chunks, taking one only if
it is exact fit, or, if this a small request, the chunk is remainder from
the most recent non-exact fit. Place other traversed chunks in
bins. Note that this step is the only place in any routine where
chunks are placed in bins.
The outer loop here is needed because we might not realize until
near the end of malloc that we should have consolidated, so must
do so and retry. This happens at most once, and only when we would
otherwise need to expand memory to service a "small" request.
最后一句说明了进行堆块合并的原因,避免由一个较小的内存请求去向操作系统申请新的内存。
for(;;) { // 主循环开始
int iters = 0;
while ( (victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) { // 反向循环遍历 unsorted bin
bck = victim->bk; // 找到 unsorted bin 链表最后一个堆块的前一个堆块
if (__builtin_expect (victim->size <= 2 * SIZE_SZ, 0)
|| __builtin_expect (victim->size > av->system_mem, 0)) // 判断 size 是否合法
malloc_printerr (check_action, "malloc(): memory corruption",
chunk2mem (victim));
size = chunksize(victim); // 如果合法,就把 victim -> size 赋给 size
上面这段代码主要在遍历搜索 unsorted bin,引用 malloc.c 的注释如下
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
当遍历到一个堆块后,会继续执行下面的代码
if (in_smallbin_range(nb) &&
bck == unsorted_chunks(av) &&
victim == av->last_remainder &&
(unsigned long)(size) > (unsigned long)(nb + MINSIZE)) { // 是否切割的判断条件
/* split and reattach remainder */
remainder_size = size - nb; // 计算切割后剩余的堆块大小
remainder = chunk_at_offset(victim, nb); // 切割堆块
unsorted_chunks(av)->bk = unsorted_chunks(av)->fd = remainder; // 将剩余的堆块重新链接到 unsorted bin 中
av->last_remainder = remainder; // 重新设置分配区的 last_remainder
remainder->bk = remainder->fd = unsorted_chunks(av); // 更新 remainder 的 fd、bk 指针
if (!in_smallbin_range(remainder_size)) // 如果 remainder 是 largebin chunk,由于不在 larbebin 链表中,先清空fd_nextsize和bk_nextsize
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
set_foot(remainder, remainder_size); // 设置堆块的结构
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 返回堆块
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
重点在于判断条件,nb 在 smallbin 范围内,并且 unsorted bin 中只有一个堆块,并且这个堆块是当前分配区的 last_remainder,并且 nb 小于这个堆块的 size,只有满足了以上四个条件,才能对 unsortedbin 中的堆块进行切割,形成 remainder。
如果上述条件不满足,就不会对 unsortedbin chunk 进行切割,而是运行下面的代码
/* remove from unsorted list */
unsorted_chunks(av)->bk = bck;
bck->fd = unsorted_chunks(av); // 这两句代码实现了将 unsortedbin 最后一个堆块卸下的操作,注意没有使用标准的 unlink,这是 pwn 题中比较常见的 unsortedbin attack 实现基础
/* Take now instead of binning if exact fit */
if (size == nb) { // 判断这个堆块是否精确匹配
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena)
victim->size |= NON_MAIN_ARENA;
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 精确匹配的情况,直接返回给用户
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
unsortedbin chunk 精确匹配的情况,和 smallbin 一样,也是从尾部取出堆块。
如果取出的堆块不能精确匹配 nb 的话,就会将这个堆块放置在对应的 bin 中,所以遍历 unsortedbin 的过程也是清空它的过程。
unsorted bin 分配堆块的过程可以用下面的图片表示
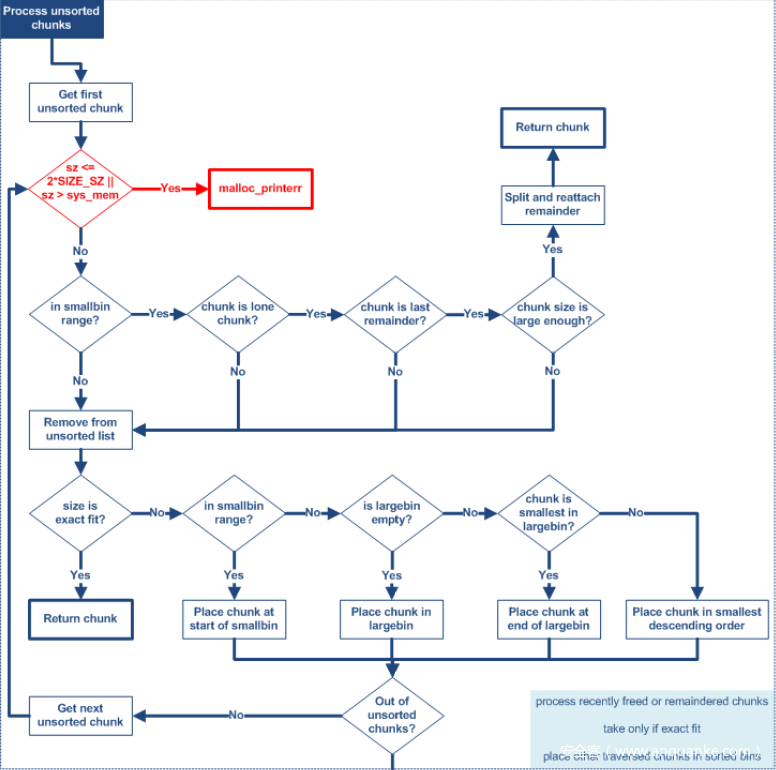
如果取出的堆块不能精确匹配 nb,就会执行下面的代码
/* place chunk in bin */
if (in_smallbin_range(size)) {
victim_index = smallbin_index(size);
bck = bin_at(av, victim_index);
fwd = bck->fd;
}
else {
victim_index = largebin_index(size);
bck = bin_at(av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck) {
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert((bck->bk->size & NON_MAIN_ARENA) == 0);
if ((unsigned long)(size) < (unsigned long)(bck->bk->size)) {
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else {
assert((fwd->size & NON_MAIN_ARENA) == 0);
while ((unsigned long) size < fwd->size)
{
fwd = fwd->fd_nextsize;
assert((fwd->size & NON_MAIN_ARENA) == 0);
}
if ((unsigned long) size == (unsigned long) fwd->size)
/* Always insert in the second position. */
fwd = fwd->fd;
else
{
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
}
} else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin(av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
#define MAX_ITERS 10000
if (++iters >= MAX_ITERS)
break;
上面的代码实现了很简单的功能,如果 size 在 smallbin 范围内,先确定 size 属于哪一条链表,由于 smallbin 的头部插入、尾部取出的特性,所以把表头作为 bck,表头的下一个堆块作为 fwd,最下面的几句代码负责将堆块插入双向链表(学过数据结构的同学应该很熟悉了)。
不过对于 largebin 范围内的 size 情况就不那么简单了,由于 largebin 特殊的结构,想把一个堆块插入到合适的位置是比较复杂的,所以要判断很多的条件来保证效率和正确性。
在遍历 unsorted bin 的循环中有一个 iter 变量,它用来记录当前已经处理了多少个 unsortedbin chunk,为了防止链表中的 chunk 过多导致程序一直处理 unsortedbin,当 iter 超过 10000 时就会跳出循环。
如果前面的代码都不能分配出合适的堆块,那就说明用户的请求可能是 large request,或者 fastbin、smallbin、unsortedbin 都不存在合适的堆块,接下来 ptmalloc 就会开始搜索 largebin,尝试匹配一个合适的堆块。
if (!in_smallbin_range(nb)) { // 判断 nb 是不是 smallbin
bin = bin_at(av, idx); // 获取链表 (idx 是之前计算的 nb 在 largebin 链表的 index)
/* skip scan if empty or largest chunk is too small */
if ((victim = first(bin)) != bin &&
(unsigned long)(victim->size) >= (unsigned long)(nb)) { // 检查对应的链表是否为空,或者其中最大的堆块比 nb 还小?
victim = victim->bk_nextsize;
while (((unsigned long)(size = chunksize(victim)) <
(unsigned long)(nb))) // 开始遍历 largebin,尝试找到一个合适的堆块
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
if (victim != last(bin) && victim->size == victim->fd->size)
victim = victim->fd;
remainder_size = size - nb; // 找到一个合适的堆块,计算一下切割后剩余的堆块大小
unlink(victim, bck, fwd); // 将这个堆块从 largebin 卸下
/* Exhaust */
if (remainder_size < MINSIZE) { // 如果切割后剩下的堆块大小 小于最小的堆块(16 or 32) 这个堆块会直接返回给用户,例如 64 位系统,切割剩余的大小为 16,那么用户拿到的堆块中有16 个字节是多出来的(或者说是浪费掉的)
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena)
victim->size |= NON_MAIN_ARENA;
}
/* Split */
else { // 如果切割剩余的堆块大小大于 MINSIZE
remainder = chunk_at_offset(victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__builtin_expect (fwd->bk != bck, 0))
{
errstr = "malloc(): corrupted unsorted chunks";
goto errout;
}
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder; // 将切割剩余的部分插入到 unsortedbin 中
if (!in_smallbin_range(remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL; // 如果剩下的大小是 largebin,清除它的 fd_nextsize、bk_nextsize 指针(因为它们在 uunsortedbin 中无用)
}
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
set_foot(remainder, remainder_size);
}
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 返回堆块
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
}
上面的代码用来搜索 largebin 尝试找到合适的堆块,注意 largebin 每个链表所存储的是一定范围的堆块,当找到一个合适大小的堆块时,为了不调整 chunksize 链表,需要避免将 chunk size 链表中的节点取出,所以取 victim->fd 节点对应的 chunk 作为候选 chunk。由于 large bin 链表中的 chunk 也是按大小排序,同一大小的 chunk 有多个时,这些 chunk 必定排在一起,所以 victim->fd 节点对应的 chunk 的大小必定与 victim 的大小一样。
如果切割后剩下的堆块大小 小于最小的堆块(16 or 32) 这个堆块会直接返回给用户,例如 64 位系统,切割剩余的大小为 16,那么用户拿到的堆块中有16 个字节是多出来的(或者说是浪费掉的)。
++idx;
bin = bin_at(av,idx);
block = idx2block(idx);
map = av->binmap[block];
bit = idx2bit(idx);
如果当前链表没有堆块能够满足,就将 idx 加一,目的是移动到下一个 largebin 链表,并且获取这个链表对应的 binmap 中的值,binmap 是分配区当中的一个成员,它用来标识相应的链表中是否存在空闲 chunk,利用 binmap 可以加快查找 chunk 的速度。 这段代码用来查询比 nb 大的链表中是否存在可用的 chunk。
for (;;) { // 进入循环
/* Skip rest of block if there are no more set bits in this block. */
if (bit > map || bit == 0) { // 首先判断 bit 是否大于 map,或者 bit 等于 0?
do { // 循环遍历每个 block,尝试找到一个符合条件的 block
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
} while ( (map = av->binmap[block]) == 0);
bin = bin_at(av, (block << BINMAPSHIFT));
bit = 1;
}
/* Advance to bin with set bit. There must be one. */
while ((bit & map) == 0) { // 在 block 中寻找一个不为零的 bit,这个 bit 对应的 bin 中就存在空闲 chunk
bin = next_bin(bin);
bit <<= 1;
assert(bit != 0);
}
/* Inspect the bin. It is likely to be non-empty */
victim = last(bin); // 将上一步找到的 bin 的最后一个堆块取出
/* If a false alarm (empty bin), clear the bit. */
if (victim == bin) { // 判断取出的是不是表头,如果是,说明 bit 命中失败,需要进行调整。
av->binmap[block] = map &= ~bit; /* Write through */ // 清除之前设置的标志位
bin = next_bin(bin); // 获取当前 bin 的下一个 bin,
bit <<= 1; // 将 bit 转移到下一个 bin 的 bit 范围
}
else {
size = chunksize(victim);
/* We know the first chunk in this bin is big enough to use. */
assert((unsigned long)(size) >= (unsigned long)(nb)); // 如果上面取出的 chunk 不是表头,那么这个 chunk 的大小一定大于 nb!
remainder_size = size - nb; // 和之前的代码一样,计算切割后的 chunk 大小
/* unlink */ // 下面的注释省略
unlink(victim, bck, fwd);
/* Exhaust */
if (remainder_size < MINSIZE) {
set_inuse_bit_at_offset(victim, size);
if (av != &main_arena)
victim->size |= NON_MAIN_ARENA;
}
/* Split */
else {
remainder = chunk_at_offset(victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__builtin_expect (fwd->bk != bck, 0))
{
errstr = "malloc(): corrupted unsorted chunks 2";
goto errout;
}
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
/* advertise as last remainder */
if (in_smallbin_range(nb))
av->last_remainder = remainder;
if (!in_smallbin_range(remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
set_foot(remainder, remainder_size);
}
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); // 返回堆块
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
}
以上的代码用来处理三种情况,一是 nb 在 smallbin 范围内,二是之前的 largebin 为空,三是之前的 largebin 不为空,但是其中最大的堆块都要比 nb 小。
代码的后半部分和前面的代码类似,区别在于头部引入了 binmap,它是定义在分配区中的成员,具体介绍在上面写过,这段代码的主要功能是遍历剩下的 largebin,直到找到一个包含满足要求的堆块的 bin,并且取出这个 chunk 进行切割,比较难以理解的是针对 binmap 的操作,之所以引入这个东西,是为了加快遍历 largebin 的速度。
补: binmap 的大致原理。binmap 一共 128 bit,16 个字节,分成 4 个 int 变量,每一个 int 变量称为一个 block,每个 block 有 32 个 bit,最多可以表示 32 个 bin 的状态,使用宏 idx2block 可以计算出一个 index(bin) 在 binmap 中属于哪个 block。 idx2bit 宏取第 i 位为1,剩下的置 0,例如 idx2bit(2) 会生成 “00000000000000000000000000000100”
其实利用 binmap 来遍历 largebin 和正常遍历效果是一样的,但是利用 binmap 可以很大的提升效率。
当这一步操作也不能满足 nb 时,就需要动用 top chunk 了。
victim = av->top;
size = chunksize(victim);
if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE)) {
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder;
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
流程还是一样的,如果 top chunk size 大于 nb,就从 top chunk 中切割下来 chunk 返回给用户。如果 top chunk 大小也不够了,会先执下面的代码
else if (have_fastchunks(av)) {
assert(in_smallbin_range(nb));
malloc_consolidate(av);
idx = smallbin_index(nb); /* restore original bin index */
}
引用 malloc.c 注释如下
If there is space available in fastbins, consolidate and retry,
to possibly avoid expanding memory. This can occur only if nb is
in smallbin range so we didn't consolidate upon entry.
如果存在 fastbin chunk,就执行 malloc_consolidate 合并 fastbin chunk,然后再尝试
为什么还要检查 fastbin? 两个原因,一是如果开启了 ATOMIC_FASTBINS ,由于 free fastbin chunk 的时候不需要加锁,所以 malloc 走到这一步的时候可能已经有其他线程向 fastbin 中注入了新的 chunk,另外一个原因是如果 nb 是一个 smallbin chunk,走到这一步说明之前所有的分配操作都失败了,但是在分配 smallbin chunk 的时候始终都没有调用过 malloc_consolidate,所以在 malloc 尾声的时候可以尝试合并 fastbin chunk 构造出符合要求的 chunk。
如果 fastbin 链表是空的,那么无论那一个缓冲区都无法提供合适的堆块了(甚至 top chunk 的空间也不够),这时就需要映射另一片内存(也就是所谓的 mmap)。
/*
Otherwise, relay to handle system-dependent cases
*/
else {
void *p = sYSMALLOc(nb, av);
if (p != NULL && __builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
注意调用的依旧是一个外壳函数,叫做 sYSMALLOc。
large bin 的分配逻辑应该是 malloc 中最为复杂的,可以参考下面这张图片
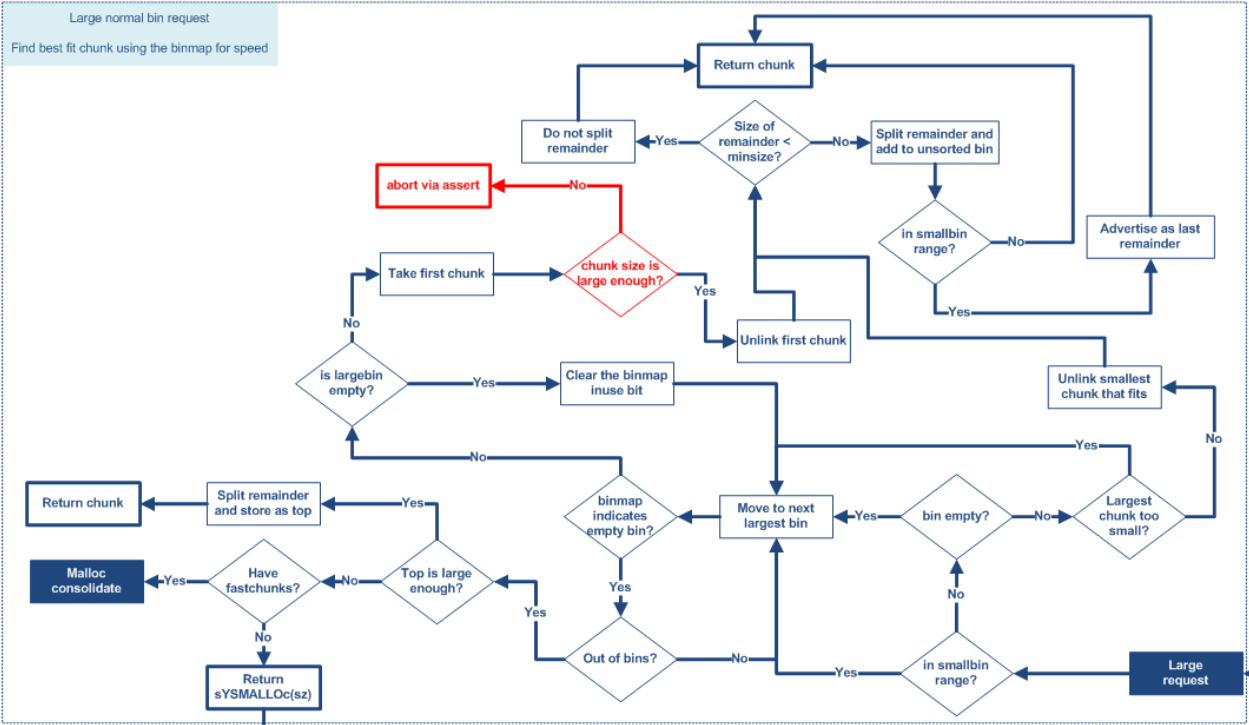
复杂的主要原因是前面尝试通过 fastbin、smallbin、unsortedbin 分配堆块都失败了,但是经过各种切割合并 chunk 的操作之后这些缓冲区中又很有可能出现合适的 chunk ,为了尽量减少向操作系统申请内存的次数,就要极大限度的利用好缓冲区的 chunk。
malloc 的流程总结
- 获取分配区的锁。
- 将用户的请求大小转换为实际需要分配的 chunk 空间大小。
- 判断所需分配 chunk 是否在 fastbin 区域,如果是的话, 则转下一步,否则跳到第 5 步。
- 首先尝试在 fastbins 中取一个所需大小的 chunk 分配给用户。 如果可以找到, 则分配结束。 否则转到下一步。
- 判断所需大小是否处在 small bins 中,如果 chunk 大小处在 smallbins 中,则转下一步,否则转到第 7 步。
- 根据所需分配的 chunk 的大小, 找到具体所在的某个 smallbin,从该 bin 的尾部摘取一个恰好满足大小的 chunk。 若成功,则分配结束,否则转到下一步。
- 到了这一步, 说明需要分配的是一块大的内存,或者 small bins 中找不到合适的chunk。于是,ptmalloc 首先会遍历 fastbins 中的 chunk,将相邻的 chunk 进行合并,并链接到 unsorted bin 中, 然后遍历 unsorted bin 中的 chunk,如果 unsorted bin 只有一个 chunk,并且这个 chunk 在上次分配时被使用过,并且所需分配的 chunk 大小属于 small bins,并且 chunk 的大小大于等于需要分配的大小,这种情况下就直接将该 chunk 进行切割,分配结束,否则将根据 chunk 的空间大小将其放入 smallbins 或是 large bins 中,遍历完成后,转入下一步。
- 到了这一步,说明需要分配的是一块大的内存,或者 small bins 和 unsorted bin 中都找不到合适的 chunk,并且 fast bins 和 unsorted bin 中所有的 chunk 都清除干净了。 从 large bins 中按照“smallest-first, best-fit”原则, 找一个合适的 chunk, 从中划分一块所需大小的 chunk, 并将剩下的部分链接回到 bins 中。 若操作成功, 则分配结束, 否则转到下一步。
- 如果搜索 fast bins 和 bins 都没有找到合适的 chunk, 那么就需要操作 top chunk 来进行分配了。 判断 top chunk 大小是否满足所需 chunk 的大小, 如果是, 则从 topchunk 中分出一块来。 否则转到下一步。
- 到了这一步, 说明 top chunk 也不能满足分配要求, 所以, 于是就有了两个选择: 如果是主分配区, 调用 sbrk(), 增加 top chunk 大小; 如果是非主分配区,调用 mmap来分配一个新的 sub-heap,增加 top chunk 大小; 或者使用 mmap()来直接分配。 在这里, 需要依靠 chunk 的大小来决定到底使用哪种方法。 判断所需分配的 chunk大小是否大于等于 mmap 分配阈值, 如果是的话, 则转下一步, 调用 mmap 分配,否则跳到第 12 步, 增加 top chunk 的大小。
- 使用 mmap 系统调用为程序的内存空间映射一块 chunk_size align 4kB 大小的空间。然后将内存指针返回给用户。
- 判断是否为第一次调用 malloc, 若是主分配区, 则需要进行一次初始化工作, 分配一块(chunk_size + 128KB) align 4KB 大小的空间作为初始的 heap。 若已经初始化过了, 主分配区则调用 sbrk()增加 heap 空间, 分主分配区则在 top chunk 中切割出一个 chunk, 使之满足分配需求, 并将内存指针返回给用户。
Reference
https://bbs.pediy.com/thread-223283.htm
https://blog.csdn.net/qq_29343201/article/details/59614863
http://www.cnblogs.com/Mainz/p/3546347.html
https://blog.csdn.net/sinat_19596835/article/details/81665095
https://mqzhuang.iteye.com/blog/1064803
华庭 《Glibc 内存管理 Ptmalloc2 源代码分析》







发表评论
您还未登录,请先登录。
登录