

作者:9ian1i@0keeTeam
0x00 简介
动态爬虫作为漏洞扫描的前提,对于web漏洞发现有至关重要的作用,先于攻击者发现脆弱业务的接口将让安全人员占领先机。即使你有再好的payload,如果连入口都发现不了,后续的一切都无法进行。这部分内容是我对之前开发动态爬虫经验的一个总结,在本文将详细介绍实践动态爬虫的过程中需要注意的问题以及解决办法。
在Chrome的Headless模式刚出现不久,我们当时就调研过用作漏洞扫描器爬虫的需求,但由于当时功能不够完善,以及无法达到稳定可靠的要求。举个例子,对于网络请求,无法区分导航请求和其它请求,而本身又不提供navigation lock的功能,所以很难确保页面的处理不被意外跳转中断。同时,不太稳定的CDP经常意外中断和产生Chrome僵尸进程,所以我们之前一直在使用PhantomJS。
但随着前端的框架使用越来越多,网页内容对爬虫越来越不友好,在不考虑进行服务端渲染的情况下,Vue等框架让静态爬虫彻底失效。同时,由于JS的ES6语法的广泛使用,缺乏维护(创始人宣布归档项目暂停开发)的PhantomJS开始变的力不从心。
在去年,puppeteer和Chromium项目在经历了不断迭代后,新增了一些关键功能,Headless模式现在已经能大致胜任扫描器爬虫的任务。所以我们在去年果断更新了扫描器的动态爬虫,采用Chromium的Headless模式作为网页内容解析引擎,以下示例代码都是使用pyppeteer 项目(采用python实现的puppeteer非官方版本),且为相关部分的关键代码段,如需运行请根据情况补全其余必要代码。
0x01 初始化设置
因为Chrome自带XSS Auditor,所以启动浏览器时我们需要进行一些设置,关闭掉这些影响页面内容正常渲染的选项。我们的目的是尽可能的去兼容更多的网页内容,同时在不影响页面渲染的情况下加快速度,所以常见的浏览器启动设置如下:
browser = await launch({
"executablePath": chrome_executable_path,
"args": [
"--disable-gpu",
"--disable-web-security",
"--disable-xss-auditor",# 关闭 XSS Auditor
"--no-sandbox",
"--disable-setuid-sandbox",
"--allow-running-insecure-content",# 允许不安全内容
"--disable-webgl",
"--disable-popup-blocking"
],
"ignoreHTTPSErrors": True # 忽略证书错误
})
接下来,创建隐身模式上下文,打开一个标签页开始请求网页,同样,也需要进行一些定制化设置。比如设置一个常见的正常浏览器UA、开启请求拦截并注入初始的HOOK代码等等:
context = browser.createIncognitoBrowserContext()
page = await context.newPage()
tasks = [
# 设置UA
asyncio.ensure_future(page.setUserAgent("...")),
# 注入初始 hook 代码,具体内容之后介绍
asyncio.ensure_future(page.evaluateOnNewDocument("...")),
# 开启请求拦截
asyncio.ensure_future(page.setRequestInterception(True)),
# 启用JS,不开的话无法执行JS
asyncio.ensure_future(page.setJavaScriptEnabled(True)),
# 关闭缓存
asyncio.ensure_future(page.setCacheEnabled(False)),
# 设置窗口大小
asyncio.ensure_future(page.setViewport({"width": 1920, "height": 1080}))
]
await asyncio.wait(tasks)
这样,我们就创建了一个适合于动态爬虫的浏览器环境。
0x02 注入代码
这里指的是在网页文档创建且页面加载前注入JS代码,这部分内容是运行一个动态爬虫的基础,主要是Hook关键的函数和事件,毕竟谁先执行代码谁就能控制JS的运行环境。
包含新url的函数
hook History API,许多前端框架都采用此API进行页面路由,记录url并取消操作:
window.history.pushState = function(a, b, url) { console.log(url);}
window.history.replaceState = function(a, b, url) { console.log(url);}
Object.defineProperty(window.history,"pushState",{"writable": false, "configurable": false});
Object.defineProperty(window.history,"replaceState",{"writable": false, "configurable": false});
监听hash变化,Vue等框架默认使用hash部分进行前端页面路由:
window.addEventListener("hashchange", function() {console.log(document.location.href);});
监听窗口的打开和关闭,记录新窗口打开的url,并取消实际操作:
window.open = function (url) { console.log(url);}
Object.defineProperty(window,"open",{"writable": false, "configurable": false});
window.close = function() {console.log("trying to close page.");};
Object.defineProperty(window,"close",{"writable": false, "configurable": false});
同时,还需要hook window.WebSocket 、window.EventSource 、 window.fetch 等函数,具体操作差不多,就不再重复贴代码了。
定时函数
setTimeout和setInterval两个定时函数,在其它文章里都是建议改小时间间隔来加速事件执行,但我在实际使用中发现,如果将时间改的过小,如将 setInterval 全部设置为不到1秒甚至0秒,会导致回调函数执行过快,极大的消耗资源并阻塞整个页面内javascript的正常执行,导致页面的正常逻辑无法执行,最后超时抛错退出。
所以在减小时间间隔的同时,也要考虑稳定性的问题,个人不建议将值设置过小,最好不小于1秒。因为这些回调函数一般都是相同的操作逻辑,只要保证在爬取时能触发一次即可覆盖大部分情况。就算是设置为1秒,部分复杂的网页也会消耗大量资源并显著降低爬取时间,如果你发现有一些页面迟迟不能结束甚至超时,说不定就是这两个定时函数惹的祸。
收集事件注册
我们为了尽可能获取更多的url,最好能将页面内注册过的函数全部触发一遍,当然也有意见是触发常见的事件,但不管什么思路,我们都需要收集页面内全部注册的事件。
除了内联事件,事件注册又分DOM0级和DOM2级事件,两种方式都可以注册事件,使用的方式却完全不相同,Hook点也不同。许多文章都提到了Hook addEventListener的原型,但其实是有遗漏的,因为 addEventListener 只能Hook DOM2级事件的注册,无法Hook DOM0 级事件。总之就是,DOM0级事件与DOM2级事件之间需要不同的方式处理。
测试如下:

可以看到,在注册事件时并没有打印出 name 的值。
DOM0 级事件
这是JavaScript指定事件处理程序的传统方式,将一个函数赋值给一个事件处理程序属性。这种方式目前所有浏览器都支持,使用简单且广泛。下面的代码就是一个常见的DOM0级事件注册:
let btn = document.getElementById("test");
btn.onclick = function() {
console.log("test");
}
那如何Hook DOM0级事件监听呢?答案就是修改所有节点的相关属性原型,设置访问器属性。将以下JS代码提前注入到页面中:
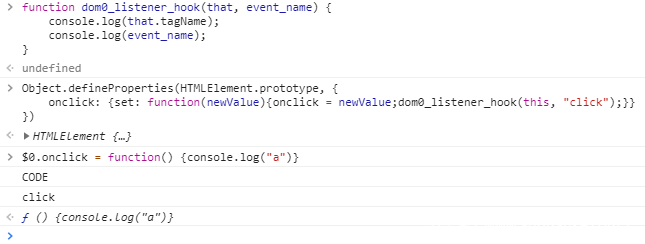
function dom0_listener_hook(that, event_name) {
console.log(that.tagName);
console.log(event_name);
}
Object.defineProperties(HTMLElement.prototype, {
onclick: {set: function(newValue){onclick = newValue;dom0_listener_hook(this, "click");}},
onchange: {set: function(newValue){onchange = newValue;dom0_listener_hook(this, "change");}},
onblur: {set: function(newValue){onblur = newValue;dom0_listener_hook(this, "blur");}},
ondblclick: {set: function(newValue){ondblclick = newValue;dom0_listener_hook(this, "dblclick");}},
onfocus: {set: function(newValue){onfocus = newValue;dom0_listener_hook(this, "focus");}},
... ... // 略 继续自定义你的事件
})
// 禁止重定义访问器属性
Object.defineProperty(HTMLElement.prototype,"onclick",{"configurable": false});
这样我们就完成了对DOM0级事件的Hook收集。效果如下:
DOM2 级事件
DOM2级事件定义了两个方法,用于处理指定和删除事件处理函数的操作:addEventListener() 和 removeEventListener(),所有的DOM节点中都包含了这两个方法。下面是一个简单的示例:
let btn = document.getElementById("test");
btn.addEventListener("click", function() {
console.log("test");
}, true)
其中第三个参数,true表示在捕获阶段调用事件处理函数,false表示在冒泡阶段调用。
Hook DOM2 级事件这部分比较简单,大多数文章也都有提到,通过Hook addEventListener的原型即可解决:
let old_event_handle = Element.prototype.addEventListener;
Element.prototype.addEventListener = function(event_name, event_func, useCapture) {
let name = "<" + this.tagName + "> " + this.id + this.name + this.getAttribute("class") + "|" + event_name;
console.log(name);
old_event_handle.apply(this, arguments);
};
锁定表单重置
爬虫在处理网页时,会先填充表单,接着触发事件去提交表单,但有时会意外点击到表单的重置按钮,造成内容清空,表单提交失败。所以为了防止这种情况的发生,我们需要Hook表单的重置并锁定不能修改。
HTMLFormElement.prototype.reset = function() {console.log("cancel reset form")};
Object.defineProperty(HTMLFormElement.prototype,"reset",{"writable": false, "configurable": false});
0x03 导航锁定
爬虫在处理一个页面时,可能会被期间意外的导航请求中断,造成漏抓。所以除了和本页面相同url的导航请求外,其余所有的导航请求都应该取消。面对重定向需要分多种情况对待:
- 前端重定向全部取消,并记录下目标链接放入任务队列
- 后端重定向响应的body中不包含内容,则跟随跳转
- 后端重定向响应的body中含有内容,无视重定向,渲染body内容,记录下location的值放入任务队列
虽然有请求拦截的相关API(setRequestInterception),但导航请求其实已经进入了网络层,直接调用 request.abort 会使当前页面抛出异常(aborted: An operation was aborted (due to user action)),从而中断爬虫对当前页面的处理。所以下面会介绍相关的解决办法。
Hook前端导航
前端导航指由前端页面JS发起的导航请求,如执行 location.href 的赋值、点击某个a标签等,最后的变化都是location的值发生改变。如何优雅的hook前端导航请求之前一直是个难题,因为location是不可重定义的:
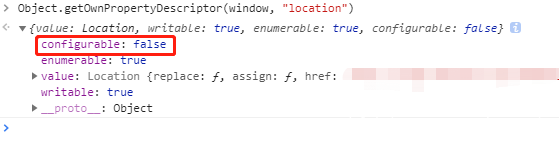
意味着你无法通过Object.defineProperty 方法去重定义访问器属性,也就无法hook window.location的相关赋值操作。PhantomJS中有个navigationLocked选项可以很容易的锁定当前导航,但很遗憾这个特性在Chromium中并没有。一旦导航请求进入网络层,整个页面进入阻塞状态。
在说我的做法之前,先介绍一下目前已知的两种解决方案。
修改Chromium源码
这是fate0师傅提出的方案,既然Chromium默认location属性的configurable选项是false,那直接修改源码将它设置为true就解决了,具体操作见其博客文章。优点是直接从底层修改源码支持,但维护成本较高,每次都得自己编译Chromium。
加载自定义插件
这是由猪猪侠在去年的先知白帽大会上提出的,通过hook网络层的API来解决。但问题是,Chromium的headless模式是无法加载插件的,官方也明确表示目前没有对headless模式加载插件功能的开发计划,也就是说,只要你开启了headless模式,那么就无法使用插件 。
这是个很关键的问题,因为我们的爬虫几乎都是在服务器上运行,不可能去使用图形化的桌面版本,更不可能使用windows server,这会极大降低速度和稳定性。这是一个非常好的思路,但很遗憾不能在实际环境中大规模运用。
不稳定的onbeforeunload
在之前,我想通过设置onbeforeunload访问,当触发确认弹窗时自动执行dialog.dimiss()来取消当前的前端导航请求,如在页面中注入以下代码:
window.onbeforeunload = function(e){
console.log("onbeforeunload trigger.")
};
设置自动dimiss弹窗:
import asyncio
from pyppeteer import dialog
async def close_dialog(dialog_handler: dialog):
await dialog_handler.dismiss()
page.on("dialog", lambda dialog_handle: asyncio.ensure_future(close_dialog(dialog_handle)))
按照理想中的情况,每一次离开当前页面的导航都会弹窗询问(是否离开当前页面),如果点击取消,那么此次导航请求就会被取消,同时当前页面不会刷新。
但这个方法有个严重的问题,无法获取即将跳转的url,即onbeforeunload回调函数中无法拿到相关的值。并且经过一段时间的测试,这个方法并不可靠,它的触发有一些前置条件,官方说需要用户在当前页面存在有效的交互操作,才会触发此回调函数。即使我已经尝试用各种API去模拟用户点击等操作,但最后依旧不是百分百触发。
To combat unwanted pop-ups, some browsers don't display prompts created in beforeunload event handlers unless the page has been interacted with. Moreover, some don't display them at all.
所以这个方法最后也被我否决了。
204状态码
这是我目前找到的最优雅的解决方案,不用修改源码,不用加载插件,在拦截请求的同时返回状态码为204的响应,可以让浏览器对该请求不做出反应,即不刷新页面,继续显示原来的文档。
在RFC7231中我们可以看到如下说明:
The 204 response allows a server to indicate that the action has been successfully applied to the target resource, while implying that the user agent does not need to traverse away from its current "document view" (if any)
意思是,服务端说明操作已经执行成功,同时告诉浏览器不需要离开当前的文档内容。
以下示例代码是拦截当前页面top frame的导航请求并返回204状态码:
import asyncio
from pyppeteer.network_manager import Request
async def intercept_request(request: Request):
if request.isNavigationRequest() and not request.frame.parentFram:
await request.respond({
"status": 204
})
# 保存 request 到任务队列
page.on('request', lambda request: asyncio.ensure_future(
intercept_request(request)))
这样,我们成功的Hook住了前端导航,并将目标请求保存到了任务队列。
处理后端重定向
许多时候,后端会根据当前用户是否登录来决定重定向,但其实响应的body中依旧包含了内容。最常见的情况就是未登录的情况下访问某些后台管理页面,虽然body中不包含任何用户的信息,但多数情况都会有许多接口,甚至我们能找到一些未授权访问的接口,所以对于重定向的body内容一定不能忽略。
在解决了前端的导航请求问题之后,处理后端重定向响应就很简单了。当后端重定向响应的body中不包含内容,则跟随跳转或者返回location的值然后退出。如果后端重定向响应的body中含有内容,则无视重定向,渲染body内容,并返回location的值。
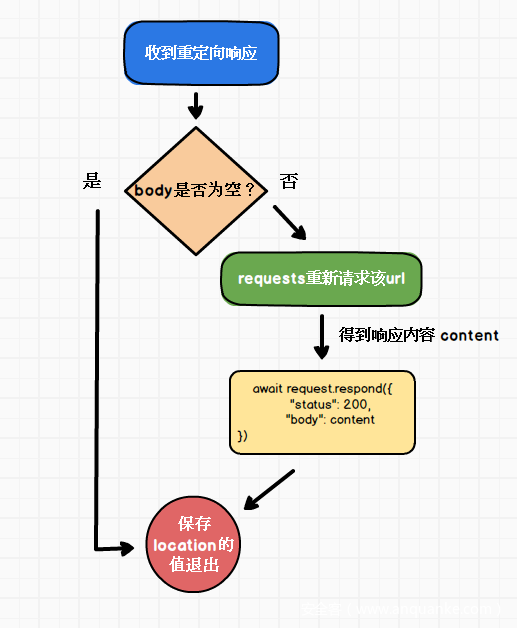
目前puppeteer并没有拦截修改响应的接口,所以这需要我们思考如何手动完成这个操作。具体方法不再赘述,思路是用requests等库请求该url,并用 request.respond手动设置响应状态码为200。
0x04 表单处理
过去静态爬虫通过解析form节点手动构造POST请求,放到现在已经显得过时。越来越复杂的前端处理逻辑,从填写表单到发出POST请求,期间会经过复杂的JS逻辑处理,最后得到的请求内容格式和静态构造的往往差别较大,可以说静态爬虫现在几乎无法正确处理表单的提交问题。
所以我们必须模拟正常的表单填写以及点击提交操作,从而让JS发送出正确格式的请求。
表单填充
填充数据虽然很简单,但需要考虑各种不同的输入类型,常见的输入类型有:text、email、password、radio、file、textarea、hidden等等。我们分为几种类型来单独说明需要注意的问题。
文本
这部分包括text、mail、password等只需要输入文本的类型,处理较为简单,综合判断 id 、name 、class 等属性中的关键字和输入类型来选择对应的填充文本。如包含mail关键字或者输入类型为email,则填充邮箱地址。如果包含phone、tel等关键字或输入类型为tel,则填充手机号码。具体不再赘述。
选择
这部分包括radio、checkbox和select,前面两个比较简单,找到节点后调用 elementHandle.click() 方法即可,或者直接为其设置属性值checked=true。
对于select 稍微复杂一些,首先找到select节点,获取所有的option子节点的值,然后再选择其中一个执行page.select(selector, ...values) 方法。示例代码如下:
def get_all_options_values_js():
return """
function get_all_options_values_sec_auto (node) {
let result = [];
for (let option of node.children) {
let value = option.getAttribute("value");
if (value)
result.push(value)
}
return result;
}
"""
async def fill_multi_select():
select_elements = await page_handler.querySelectorAll("select")
for each in select_elements:
random_str = get_random_str()
# 添加自定义属性 方便后面定位
await page_handler.evaluate("(ele, value) => ele.setAttribute('sec_auto_select', value)", each, random_str)
attr_str = "sec_auto_select="%s"" % random_str
attr_selector = "select[%s]" % attr_str
value_list = await page_handler.querySelectorEval(attr_selector, get_all_options_values_js())
if len(value_list) > 0:
# 默认选择第一个
await page_handler.select(attr_selector, value_list[0])
文件
表单中常见必须要求文件上传文件,有时JS还限制了上传的文件后缀和文件类型。我们无法覆盖所有的文件类型情况,但可以准备几种常见的文件类型,如:png、doc、xlsx、zip等。当然,对于一些简单的限制,我们还是可以去掉的,比如找到文件上传的dom节点并删除 accept 和 required 属性:
input_node.removeAttribute('accept');
input_node.removeAttribute('required');
这样可以尽可能的让我们的文件上传成功。
这里有个问题需要注意一下,在过去版本的Chromium headles模式下上传文件时,request intercept 抓取到的postData内容将为空,这是个Chromium的BUG,官方在新版本已经修复了这个问题,请在开发时避开相应的版本。
表单提交
提交表单也有一些需要注意的问题,直接点击form表单的提交按钮会导致页面重载,我们并不希望当前页面刷新,所以除了Hook住前端导航请求之外,我们还可以为form节点设置target属性,指向一个隐藏的iframe。具体操作的话就是新建隐藏iframe然后将form表单的target指向它即可,我在这里就不赘述了。
要成功的提交表单,就得正确触发表单的submit操作。不是所有的前端内容都有规范的表单格式,或许有一些form连个button都没有,所以这里有三种思路可供尝试,保险起见建议全部都运行一次:
- 在form节点的子节点内寻找
type=submit的节点,执行elementHandle.click()方法。 - 直接对form节点执行JS语句:
form.submit(),注意,如果form内有包含属性值name=submit的节点,将会抛出异常,所以注意捕获异常。 - 在form节点的子节点内寻找所有button节点,全部执行一次
elementHandle.click()方法。因为我们之前已经重定义并锁定了表单重置函数,所以不用担心会清空表单。
这样,绝大部分表单我们都能触发了。
0x05 事件触发
关于事件触发这部分其实有多种看法,我在这里的观点还是觉得应该去触发所有已注册的事件,并且,除了允许自身的冒泡之外,还应该手动进行事件传递,即对触发事件节点的子节点继续触发事件。当然,为了性能考虑,你可以将层数控制到三层,且对兄弟节点随机选择一个触发。简单画图说明:

ID为parent的节点存在onclick的内联事件,对其子节点,同一层随机选择一个触发。上图中彩色为触发的节点。
事件冒泡是指向父节点传递,事件传递指向子节点传递,遗憾的是我在CustomEvent中没有找到传递方式指定为事件传递的参数选项,所以简单手动实现。
内联事件
对于内联事件,因为无法通过Hook去收集注册事件,所以需要查询整个DOM树,找出包含关键字属性的节点,常见的内联事件属性如下:
inline_events = ["onabort", "onblur", "onchange", "onclick", "ondblclick", "onerror","onfocus", "onkeydown","onkeypress", "onkeyup", "onload", "onmousedown","onmousemove", "onmouseout", "onmouseover","onmouseup", "onreset", "onresize", "onselect", "onsubmit", "onunload"]
然后遍历每个事件名,找出节点并自定义触发事件:
def get_trigger_inline_event_js():
return """
async function trigger_all_inline_event(nodes, event_name) {
for (let node of nodes) {
let evt = document.createEvent('CustomEvent');
evt.initCustomEvent(event_name, false, true, null);
try {
node.dispatchEvent(evt);
}
catch {}
}
}
"""
for event_name in ChromeConfig.inline_events:
await self.page_handler.querySelectorAllEval("[%s]" % event_name, get_trigger_inline_event_js(), event_name.replace("on", ""))
至于DOM事件,将收集到的事件依次触发即可,不再赘述。
0x06 链接收集
除了常见的属性 src和href, 还要收集一些如 data-url 、longDesc、lowsrc等属性,以及一些多媒体资源URI。以收集src属性值举例:
def get_src_or_href_js():
return """
function get_src_or_href_sec_auto(nodes) {
let result = [];
for (let node of nodes) {
let src = node.getAttribute("src");
if (src) {
result.push(src)
}
}
return result;
}
"""
links = await page_handler.querySelectorAllEval("[src]", get_src_or_href_js())
当然这里你也可以使用 TreeWalker。
同时在拼接相对URL时应该注意base标签的值。
<HTML>
<HEAD>
<TITLE>test</TITLE>
<BASE href="http://www.test.com/products/intro.html">
</HEAD>
<BODY>
<P>Have you seen our <A href="../cages/birds.gif">Bird Cages</A>?
</BODY>
</HTML>
相对url "../cages/birds.gif" 将解析为http://www.test.com/cages/birds.gif。
注释中的链接
注释中的链接一定不能忽略,我们发现很多次暴露出存在漏洞的接口都是在注释当中。这部分链接可以用静态解析的方式去覆盖,也可以采用下面的代码获取注释内容并用正则匹配:
comment_elements = await page_handler.xpath("//comment()")
for each in comment_elements:
if self.page_handler.isClosed():
break
# 注释节点获取内容 只能用 textContent
comment_content = await self.page_handler.evaluate("node => node.textContent", each)
# 自定义正则内容 regex_comment_url
matches = regex_comment_url(comment_content)
for url in matches:
print(url)
0x07 去重
说实话这部分是很复杂的一个环节,从参数名的构成,到参数值的类型、长度、出现频次等,需要综合很多情况去对URL进行去重,甚至还要考虑RESTful API设计风格的URL,以及现在越来越多的伪静态。虽然我们在实践过程中经过一些积累完成了一套规则来进行去重,但由于内容繁琐实在不好展开讨论,且没有太多的参考价值,这方面各家都有各自的处理办法。但归结起来,单靠URL是很难做到完美的去重,好在漏洞扫描时即使多一些重复URL也不会有太大影响,最多就是扫描稍微慢了一点,其实完全可以接受。所以在这部分不必太过纠结完美,实在无法去重,设定一个阈值兜底,避免任务数量过大。
但如果你对URL的去重要求较高,同时愿意耗费一些时间并有充足的存储资源,那么你可以结合响应内容,利用网页的结构相似度去重。
结构相似度
一个网页主要包含两大部分:网页结构和网页内容。一些伪静态网页的内容可能会由不同的信息填充,但每个网页都有自己独一无二的结构,结构极其相似的网页,多半都属于伪静态页面。每一个节点它的节点名、属性值、和父节点的关系、和子节点的关系、和兄弟的关系都存在特异性。节点的层级越深,对整个DOM结构的影响越小,反之则越大。同级的兄弟节点越多,对DOM结构的特异性影响也越小。可以根据这些维度,对整个DOM结构进行一个特征提取,设定不同的权值,同时转化为特征向量,然后再对两个不同的网页之间的特征向量进行相似度比较(如伪距离公式),即可准确判断两个网页的结构相似度。
这方面早已有人做过研究,百度10年前李景阳的专利《网页结构相似性确定方法及装置》 就已经很清楚的讲述了如何确定网页结构相似性。全文通俗易懂,完全可以自动手动实现一个简单的程序去判断网页结构相似度。整体不算复杂,希望大家自己动手实现。
大量网页快速相似匹配
这里我想讲一下,在已经完成特征向量提取之后,面对庞大的网页文档,如何做到在大量存储文档中快速搜索和当前网页相似的文档。这部分是基于我自己的摸索,利用ElasticSearch的搜索特性而得出的简单方法。
首先,我们在通过一系列处理之后,将网页结构转化为了特征向量,比如请求 https://www.360.cn/的网页内容经过转化后,得到了维数为键,权值为值的键值对,即特征向量:
{
5650: 1.0,
5774: 0.196608,
5506: 0.36,
2727: 0.157286,
1511: 0.262144,
540: 0.4096,
1897: 0.4096,
972: 0.262144,
... ...
}
一般稍微复杂点的网页全部特征向量会有数百上千个,在大量的文档中进行遍历比较几乎不可能,需要进行压缩,这里使用最简单的维数取余方式,将维数压缩到100维,之后再对值进行离散化变成整数:
{ 50: 13, 75: 8, 92: 18, 33: 12, 2: 15, 86: 10, 9: 9, 95: 10, 55: 14, 42: 12, 35: 15, 82: 10, 17: 7, 54: 14, 22: 11, 10: 16, 77: 11, 44: 17, 60: 9, 26: 19, ... ... }
现在,我们得到了一个代表360主站网页结构的100维模糊特征向量,由0-99为键的整数键值对组成,接下来,我们按照键的大小顺序排列,组成一个空格分割的字符串:
0:2 1:10 2:15 3:9 4:4 5:7 6:10 7:15 8:11 9:9 10:16 11:4 12:12 ... ...
最后我们将其和网页相关内容本身一起存入ElasticSearch中,同时对该向量设置分词为whitespace:
"fuzz_vector": {
"type": "text",
"analyzer": "whitespace"
}
这样,我们将模糊特征向量保存了下来。当新发现一个网页文档时,如何查找?
首先我们需要明白,这个100维特征向量就代表这个网页文档的结构,相似的网页,在相同维数上的权值是趋于相同的(因为我们进行了离散化),所以,如果我们能计算两个向量在相同维数上权值相同的个数,就能大致确定这两个网页是否相似!
举个例子,对于安全客的两篇文章,https://www.anquanke.com/post/id/178047 和 https://www.anquanke.com/post/id/178105 ,我们分别进行以上操作,可以得到以下的两组向量:
0:6 1:5 2:3 3:7 4:5 5:1 6:9 7:2 8:4 9:6 10:4 11:4 12:6 13:2 14:10 15:10 16:8 ...
0:6 1:6 2:3 3:7 4:5 5:1 6:9 7:2 8:3 9:6 10:4 11:4 12:6 13:2 14:10 15:8 16:8 ...
相同的键值对占到了70个,说明大部分维度的DOM结构都是相似的。通过确定一个阈值(如30或者50),找出相同键值对大于这个数的文档即可。一般会得到个位数的文档,再对它们进行完整向量的相似度计算,即可准确找出和当前文档相似的历史文档。
那么如何去计算两个字符串中相同词的个数呢?或者说,如果根据某个阈值筛选出符合要求的文档呢?答案是利用ElasticSearch的match分词匹配。
"query": {
"match": {
"fuzz_vector": {
"query": "0:6 1:5 2:3 3:7 4:5 5:1 6:9 7:2 8:4 ... ...",
"operator": "or",
"minimum_should_match": 30
}
}
}
以上查询能快速筛选出相同键值对个数为30及以上的文档,这种分词查询对于亿级文档都是毫秒返回。
0x08 任务调度
我这里谈论的任务调度并不是指链接的去重以及优先级排列,而是具体到单个browser如何去管理对应的tab,因为Chromium的启动和关闭代价非常大,远大于标签页Tab的开关,并且如果想要将Chromium云服务化,那么必须让browser长时间驻留,所以我们在实际运行的时候,应当是在单个browser上开启多个Tab,任务的处理都在Tab上进行。
那么这里肯定会涉及到browser对Tab的管理,如何动态增减?我使用的是pyppeteer,因为CDP相关操作均是异步,那么对Tab的动态增减其实就等价于协程任务的动态增减。
首先,得确定单个browser允许同时处理的最大Tab数,因为单个browser其实就是一个进程,而当Tab数过多时,维持了过多的websocket连接,当你的处理逻辑较复杂,单个进程的CPU占用就会达到极限,相关任务会阻塞,效率下降,某些Tab页面会超时退出。所以单个的browser能同时处理的Tab页面必须控制到一定的阈值,这个值可以根据观察CPU占用来确定。
实现起来思路很简单,创建一个事件循环,判断当前事件循环中的任务数与最大阈值的差值,往其中新增任务即可。同时,因为开启事件循环后主进程阻塞,我们监控事件循环的操作也必须是异步的,办法就是创建一个任务去往自身所在的事件循环添加任务。
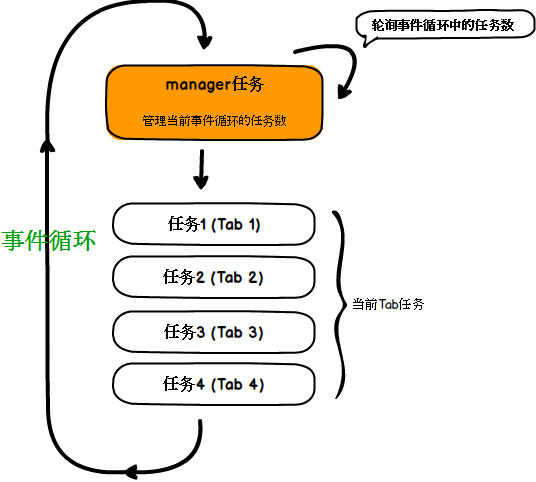
当然,真实的事件循环并不是一个图中那样的顺序循环,不同的任务有不同占用时间以及调用顺序。
示例代码如下:
import asyncio
class Scheduler(object):
def __init__(self, task_queue):
self.loop = asyncio.get_event_loop()
self.max_task_count = 10
self.finish_count = 0
self.task_queue = task_queue
self.task_count = len(task_queue)
def run(self):
self.loop.run_until_complete(self.manager_task())
async def tab_task(self, num):
print("task {num} start run ... ".format(num=num))
await asyncio.sleep(1)
print("task {num} finish ... ".format(num=num))
self.finish_count += 1
async def manager_task(self):
# 任务队列不为空 或 存在未完成任务
while len(self.task_queue) != 0 or self.finish_count != self.task_count:
if len(asyncio.Task.all_tasks(self.loop)) - 1 < self.max_task_count and len(self.task_queue) != 0:
param = self.task_queue.pop(0)
self.loop.create_task(self.tab_task(param))
await asyncio.sleep(0.5)
if __name__ == '__main__':
Scheduler([1, 2, 3, 4, 5]).run()
运行结果如下:
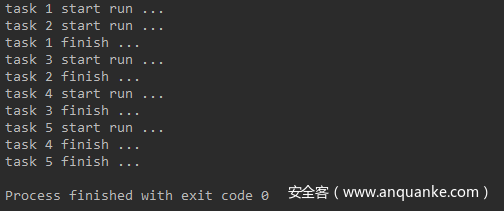
Chromium 的相关操作必须在主线程完成,意味着你无法通过多线程去开启多个Tab和browser。
0x09 结语
关于爬虫的内容上面讲了这么多依旧没有概括完,调度关系到你的效率,而本文内容中的细节能够决定你的爬虫是否比别人发现更多链接。特别是扫描器爬虫,业务有太多的case让你想不到,需要经历多次的漏抓复盘才能发现更多的情况并改善处理逻辑,这也是一个经验积累的过程。如果你有好的点子或思路,非常欢迎和我交流!
微博:@9ian1i
0x10 参考文档
@fate0: 爬虫基础篇[Web 漏洞扫描器],爬虫 JavaScript 篇[Web 漏洞扫描器], 爬虫调度篇[Web 漏洞扫描器]
@Fr1day: 浅谈动态爬虫与去重,浅谈动态爬虫与去重(续)
@猪猪侠: 《WEB2.0启发式爬虫实战》
https://peter.sh/experiments/chromium-command-line-switches/
https://miyakogi.github.io/pyppeteer/
关于我们
0Kee Team隶属于360信息安全部,360信息安全部致力于保护内部安全和业务安全,抵御外部恶意网络攻击,并逐步形成了一套自己的安全防御体系,积累了丰富的安全运营和对突发安全事件应急处理经验,建立起了完善的安全应急响应系统,对安全威胁做到早发现,早解决,为安全保驾护航。技术能力处于业内领先水平,培养出了较多明星安全团队及研究员,研究成果多次受国内外厂商官方致谢,如微软、谷歌、苹果等,多次受邀参加国内外安全大会议题演讲。目前主要研究方向有区块链安全、WEB安全、移动安全(Android、iOS)、网络安全、云安全、IOT安全等多个方向,基本覆盖互联网安全主要领域。







发表评论
您还未登录,请先登录。
登录