

简介
spectre是在Plaid CTF 2019中的一道666分的pwnable,涉及的主要知识点为前一段爆出的spectre幽灵漏洞。这个漏洞能够在没有权限的情况下通过侧信道获取任何地址的内容,可以说是一个大杀器。漏洞爆出时我大致浏览过漏洞的原理,但是并没有彻底弄清楚技术细节,只知道大致思路,这次Plaid CTF所设置的场景非常贴近底层,重点考察了spectre漏洞的一些关键点,正好考在了我一知半解的盲区,因此比赛时并没有拿下,赛后参考国外选手的exploit代码,修改了自己的代码后,补全了技术细节,在这里做一个简单的梳理。
spectre漏洞
spectre漏洞来源于cpu的两个重要的硬件特性:分支预测与缓存。要弄清楚spectre的原理,我们必须弄清楚这两个硬件特性到底是什么。我作为信息安全专业的研一学生,却并没有修过计算机体系结构,非常惭愧,这里正好小小地补一点体系结构的基础知识。
分支预测
与分支预测常常一起提起的概念是乱序执行,这两个机制都是为了提高cpu运行效率而被提出。
我们简单介绍乱序执行,只涉及概念,不涉及细节,更多细节可以在网上找到大量资料。
cpu的一条指令执行过程分为很多阶段,比如经典的五级流水线分为取指、译码、执行、访存、写回,在现在的cpu中,为了达到更高的效率,cpu会将要执行的指令切分成更多阶段,比如core i7处理器流水线深度为16级。在这里不多介绍流水线的原理。
如果cpu在执行指令时按照流水线中的顺序一个一个执行,那么当某一条指令的执行时间非常长的时候,比如该条指令需要访存,而访存需要一百个时钟周期,cpu就会在这个地方停顿下来等待一百个时钟周期,在等待的这段时间里cpu是没有全速工作的,甚至可以说几乎没有工作,这显然是非常没有效率的做法,因此乱序执行技术被设计了出来。所谓乱序执行,就是cpu在等待某一条指令的结果的同时进行后面指令的执行周期。为了避免乱序执行带来的逻辑上的改变,cpu会在执行后进行顺序提交(这个过程当然也会伴随着一些检查,这个后面再提),这样可以充分利用cpu在等待时的空闲时间,极大提高cpu的效率。
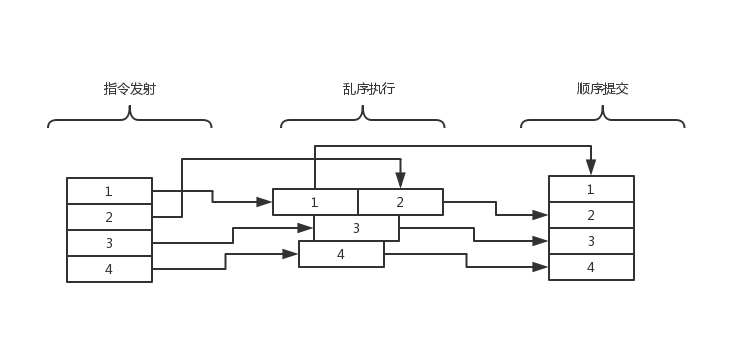
理解了上面的概念后,分支预测就相对容易理解了。如果上述执行时间非常长的指令是条件跳转指令时,cpu会面临一个选择,到底执行“真”分支还是“假”分支呢?此时cpu会进行投机执行,即随机选择一个分支进行预先执行,如果执行到某个时间点,条件判断语句返回值与预测一样,就将投机执行的部分提交,如果返回值与预测不同,就将投机执行的部分废除,错误的判断并不会影响最终执行的结果,只会让流水线呆滞一会,降低了cpu的效率。
如果只是单纯地进行随机选择,cpu的效率显然并不会有太大提升,cpu一般会有一些预测倾向或调度策略,帮助分支预测机制进行更准确的预测。比如当碰见条件跳转时,如果跳转目标比当前地址小,则认为是循环,更倾向于跳转;如果跳转目标比当前地址大,则更倾向于不跳转。当然这是第一次遇见这条语句时的策略,我们有一个更加直接的想法,如果在这条语句总是跳转(或者总是不跳转),我们在下一次就更倾向于跳转(或者不跳转)。打个比方,在0x80401C地址的一个jle语句跳转成功了100次,那么在分支预测的时候,我们更倾向于预测它在第101次还是会发生跳转,那么我们在投机执行的时候就会选择预先执行跳转后的语句。
分支预测并不会带来任何逻辑上的错误,因为这是一个cpu所应做到的底限,但是那些错误的预测是否真的不会带来任何影响呢?其实不是。
缓存
在继续讲述前,我们简单介绍一下缓存机制。这部分介绍并没有很详细,在这里够用了,但是要更详细的技术细节还是请查阅权威书籍。
cpu从内存中获取某个地址上的数据所需的时间与指令执行的时间差别非常大,直接从内存中获取一个数据的时间大约在几百个指令周期,如果碰到读写密集的程序,这种io的性能将会成为最大的瓶颈。如果我们将频繁访问的数据放在一个访问速度极快的位置,就可以大大提高运行的效率,在这里,cpu cache就是现有的解决方案。从cache中获取数据,所需时间大约在10个时钟周期以内,相比于从内存中直接获取,差距非常大。
cache的调度策略比较复杂,我们只需要知道cpu时遵循了某些策略进行内存数据与cache策略的交互即可,但是我们有一个基本的认识就是当前频繁访问的数据将会在cache空间不够时替换掉cache中原有的数据,这一点在做题时比较重要。
侧信道漏洞
上述两个机制单独看来都没有什么问题,但是将它们组合在一起,就会形成一个威力强大的侧信道攻击方式,即我们所提到的spectre漏洞。
以现有的比较经典的spectre漏洞的exploit为例:
if(idx < *length){
dummy |= array2[array1[idx] << 12]
}
这里的条件判断语句如果已经被预先训练,使得cpu认为idx有很大概率小于*length,那么cpu就会预先执行括号中的语句,这在大多数情况下都是正确的,但是如果我们构造一个idx > *length,cpu仍然会提前执行括号内的内容,将array1中的越界数据取出(假定为’f’,0x66),并以此作为索引去访问array2中的第0x66个页(一个页的大小为0x1000,0x66000属于第0x66个页)。虽然最终这个操作并没有被提交,但是array2的第0x66个页确实被放进了cache中,我们接下来只需要将array2中的所有页的访存时间都计算一遍(当然array2的大小必须大于0x100 * 0x1000, 对应一个字节的0x100种取值),就可以发现0x66000这个页的访存时间要显著小于其他页,因此array1[idx]的内容为0x66。
在上述场景中,没有任何一次非法访问,只是小小的“欺骗”了一下cpu,就能够通过侧信道取到没有访问方法的数据。
spectre的大致原理就是这样,涉及到的一些具体细节,我们结合题目来看。
pctf spectre
这道题的二进制文件和exp都在我的github中可以获取(还有一篇用英文写的write up,文笔很差敬请谅解):
https://github.com/kongjiadongyuan/myWPs/tree/master/2019-pctf/spectre
静态分析

我们可以发现这道题目很贴心地并没有去掉符号表,其实也是为我们减少了很多逆向的工作量。
主函数的逻辑如下:
int __cdecl main(int argc, const char **argv, const char **envp)
{
signed int v3; // ebx
__int64 *space_1; // rax
__int64 *space; // rbp
__int64 v6; // rdx
v3 = 1;
space_1 = (__int64 *)calloc(1uLL, 0x1030uLL);
if ( argc > 1 )
{
space = space_1;
v3 = 2;
if ( (unsigned int)load_flag(space_1, argv[1]) )
{
v3 = 3;
if ( fread(space, 8uLL, 1uLL, stdin) == 1 && (unsigned __int64)*space <= 0x1000 )
{
v3 = 4;
if ( *space == __fread_chk((__int64)(space + 1), 0x1028LL, 1LL, *space, (__int64)stdin) )
{
v3 = 5;
if ( mmap((void *)0x133700000000LL, 0x400000uLL, 3, 34, -1, 0LL) != (void *)-1LL )
{
v3 = 6;
if ( mmap((void *)0x414100000000LL, 0x2000000uLL, 3, 34, -1, 0LL) != (void *)-1LL )
{
v3 = 7;
memset((void *)0x133700000000LL, 0xCC, 0x400000uLL);
if ( (unsigned int)jit(space) )
{
v3 = mprotect((void *)0x133700000000LL, 0x400000uLL, 5);
if ( v3 )
{
v3 = 8;
}
else
{
signal(14, (__sighandler_t)alarm_handler);
the_vm = space;
space[0x201] = (__int64)builtin_bc;
space[0x202] = (__int64)builtin_time;
space[0x203] = rdtsc(0, v6);
MEMORY[0x133700000000](10LL, alarm_handler);
fwrite((const void *)0x414100000000LL, 1uLL, 0x1000uLL, _bss_start);
}
}
}
}
}
}
}
}
return v3;
}
- 申请0x1030大小的chunk(我在这里命名为space);
- 将flag放在0x1020处;
- 读取最多0x1008大小的输入(算上最开始的8字节的length);
- mmap申请 两片空间分别位于0x133700000000和0x414100000000,后面我们就会知道,0x133700000000作为我们输入的字节码的JIT代码的存放空间,我们接下来不妨叫它代码段,0x414100000000则作为load和store伪指令的访存基址,我们不妨叫它数据段;
- 将我们的输入翻译成汇编代码放入代码段;
- 将三个函数指针放入space的特定偏移;
- 执行我们的JIT代码;
- 输出数据段的前0x1000字节。
此时的space的内存布局如下:

稍微介绍一下JIT代码的转换规则,总共分为如下几种指令:
- 0x00:结束指令,将所有的寄存器依次push,并调用ret;
- 0x01:encode_cdq,就是movsvx指令,这里限制只能在寄存器r8~r15之间进行操作,下面大多数指令都是这样;
- 0x02:encode_add,就是add指令;
- 0x03:encode_sub,就是sub指令;
- 0x04:encode_and,就是and指令;
- 0x05:encode_shl,就是shl指令;
- 0x06:encode_shr,就是shl指令;
- 0x07:encode_move,就是mov指令,但是此时两个操作数都必须是寄存器;
- 0x08:encode_movec,就是mov指令,但是此时源操作数必须是立即数,目的操作数必须是寄存器;
- 0x09:encode_load,内存读指令,以0x414100000000为基址,将源操作数作为offset,把值放入目的操作数的寄存器中;
- 0x0a:encode_store,内存写指令,与上面相反;
- 0x0b:encode_builtin,这里调用两个函数,分别是builtin_bc和builtin_time,这两个函数在后面介绍。
为了处理这些比较繁琐的问题,我写了一个小工具,顺带处理与远端交互的io问题,在github中的translator.py文件中实现。
builtin_time函数如下:
__int64 __fastcall builtin_time(__int64 a1, __int64 a2, __int64 a3)
{
return *((unsigned __int8 *)the_vm + 0x1020) - the_vm[515] + rdtsc(0, a3);
}
有一个比较反常的地方在于,这个函数原本直接调用rdtsc函数即可,但是却访问了the_vm + 0x1020的位置,简单追一下数据流就会发现,the_vm就是一个指向一开始申请的space的指针,并且偏移量为0x1020的位置正好是rdtsc的函数指针。绕了一大圈用这种方式调用函数的一个直接后果就是,访问了一次flag所在的内存页,那么这个内存页就被放入了cpu的cache中,这一点在之后的利用过程中比较重要。
builtin_bc函数如下:
signed __int64 __fastcall builtin_bc(unsigned __int64 a1)
{
signed __int64 result; // rax
result = -1LL;
if ( *the_vm > a1 )
result = *((unsigned __int8 *)the_vm + a1 + 8);
return result;
}
由于给我们提供的字节码中并没有包括分支跳转指令,因此这个函数就是我们要攻击的分支跳转。这个函数的逻辑相当简单,如果我们访问的值a1没有越界,就返回space中的对应位置,而我们能够访问的区域后面就是flag。显然在合法访问的情况下我们并不能拿到flag的值,但是有了spectre漏洞就不一样了,我们可以通过返回值进行进一步操作,即以返回值为索引去访问对应的页,就能通过侧信道获取flag的值。具体的做法如下:
load(r8, builtin_bc(0x1018 + idx) << 12)
//这里的idx为flag的字节,比如我们获取第一个字节的时候,idx = 0,获取第0x10个字节时,idx = 0xf
但是简单地这样操作并不能让分支预测执行成功,关键在于,我们需要让后面的语句在条件判断语句得到结果之前尽可能多地执行。这句话稍微有点难以理解,我详细解释一下。
如果我们把自己当作cpu,那么条件判断语句之后需要执行的语句如下:
if(* the_vm > a1)
result = *((unsigned __int8 *)the_vm + a1 + 8);
return result;
load(r8, result << 12)
最后的一条语句是我们的目标语句。在到达目标语句前,我们需要*the_vm > a1的判断尽可能慢,而中间的语句尽可能快。我们注意到判断语句需要访存,因此我们最好让the_vm指向的页不在缓存中,这样可以给后面的语句更多时间预执行;而后面语句中,the_vm + a1 + 8 的地址同样发生了访存操作,而我们的目标地址为the_vm + 0x1018,因此我们需要这条语句的执行速度尽可能快,因此需要把flag所在的页提前放入缓存。这道题的小trick就在于,作为条件判断的依据的*the_vm与作为目标的 *(the_vm + a1 + 8) 并不在同一个页上,这就让我们有可能达到我们想要的效果。
同时我们还应该注意到一点,就是binary中虽然可以找到builtin_flush,但是我们却没有途径调用这个函数,因此我们需要自己想办法触发flush cache的效果。就像我们之前所提到的,我们可以通过不断地访问大量(直觉上应该超过cpu cache大小)的页面,让原来在cache中的数据被清除出去。
算法细节
这里我贴上我的主要算法:
def main(secret):
if DEBUG:
pause()
c = Translator()
c.start()
init(c)
train_bc(c)
cache_clear(c)
delay_fence(c)
# train_jle(c)
c.time()
attack(c, secret)
check_all(c)
c.complete()
if not DEBUG:
final = c.go()
result = []
for i in range(0x100):
result.append(final[i * 2])
return result
else:
p.send(c.content)
稍微解释一下main函数的几个阶段。
Translator是用来构造符合题目要求的payload的类。
init函数用来将数据段的页面赋予一个初始值,因为mmap分配的空间并不会马上分配,因此都访问一遍可以让它们都处于被分配的状态,当然这个操作也会将它们全部放入cache;
train_bc函数通过不断地调用builtin_bc函数训练它执行“正确”分支,便于我们之后的spectre attack,需要注意这里并没有使用题目中提供的循环功能,而是单纯地重复写了很多次,这样做地目的是为了防止cpu对它进行优化;
cache_clear函数不断地循环访存,偏移量为数据段的0x101000 ~ 0x1fff000,而偏移量为0x0 ~ 0x100000的部分是用来最后做测信道攻击的部分,正好0x100个页,对应0x100种字节取值;
delay_fence进行了无意义的空循环,目的是为了空耗cpu时间,让前后代码在实际执行的时候完全分开,防止cpu的乱序执行在我们cache没有完全清空的情况下执行到下面的部分。这一步比较关键,否则结果将会很奇怪;
attack就是进行了之前所提到的攻击,理想情况下应该将对应页放入了缓存中;
check_all函数则一页一页地检查目标区域地访存时间,并将它们放在了0x0~0x1000区域内,等待最后的打印。值得注意的是,这里我使用了一个 idx * 65 & 0xff 的“伪随机”访问,目的是防止cpu在进行顺序访问时预取后面的页面,影响我们最后的判断。
总结
了解了spectre漏洞的细节之后,这道题的难度显然就不是那么大了。作为一道国际赛中全场分数最高的题,如果对一些关键点一知半解就很难做出来了。所以之后我们调试漏洞时,所有的细节都必须抓住,不能有遗漏。希望下次碰到spectre可以直接秒杀。







发表评论
您还未登录,请先登录。
登录