

看玄武的公众号的时候看到了这篇文章。二进制工具分析的主要是程序的各种信息,比如格式、体系结构、编译器标识、指令、助记符等。
反汇编
概览
IDA是HexRays公司的商业产品,这个也是大家最熟悉的了。不过我是真的用不起,羡慕那些有钱的实验室还有土豪们啊。过去几年还有其他的工具出现,比如Binary Ninja(二进制忍者,一看就知道是日本人的东西,貌似他们CTF战队也叫这个名字), radare, Ghidra(NSA出品最近又爆出有RCE洞,不知道是不是故意留的后门)等。Angr,Shellphish的东西,这个做漏洞自动化挖掘利用的应该都知道。
插个题外话,这些真正的大牛们,是真的在做研究搞技术,他们玩的CTF才是真的CTF吧。二进制分析软件还是很多的,文章中没有讲Windows下的OD和WinDbg,做Windows安全的,肯定会用到这两个。
反汇编结果
下图是这些反汇编工具的特性比较:
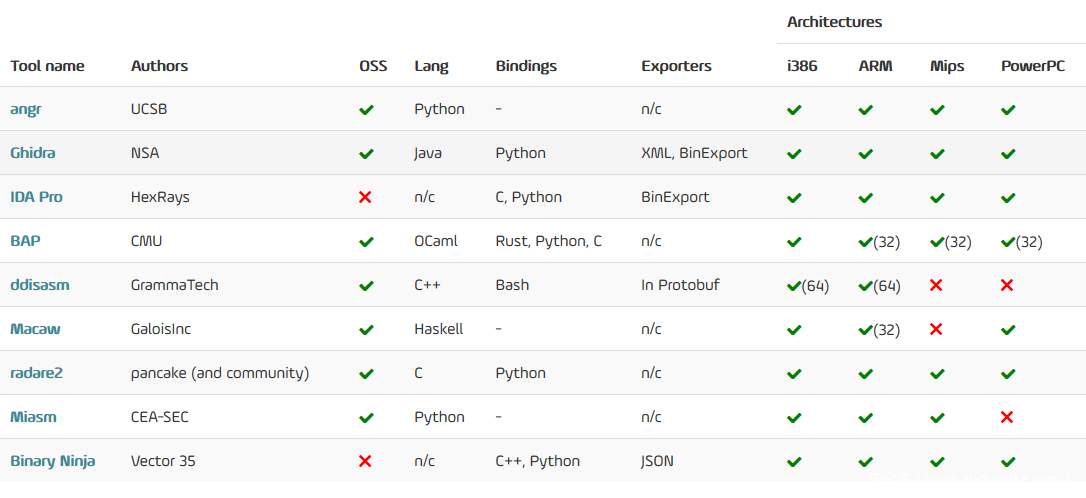
文章选取了三个ELF文件:小于900KB的elf-Linux-x64-bash、17MB的delta_generator 34MB的llvm-opt,分别作为小、中、大程序。
这三个程序是随机选择的,没有什么特别的地方,也都是开源项目中的常规程序。
使用的机器是Dell XPS 15,处理器是 Intel® Core™ i7-6700HQ CPU @ 2.60GHz,内存16G,操作系统使用的是Debian 10 (Buster)。
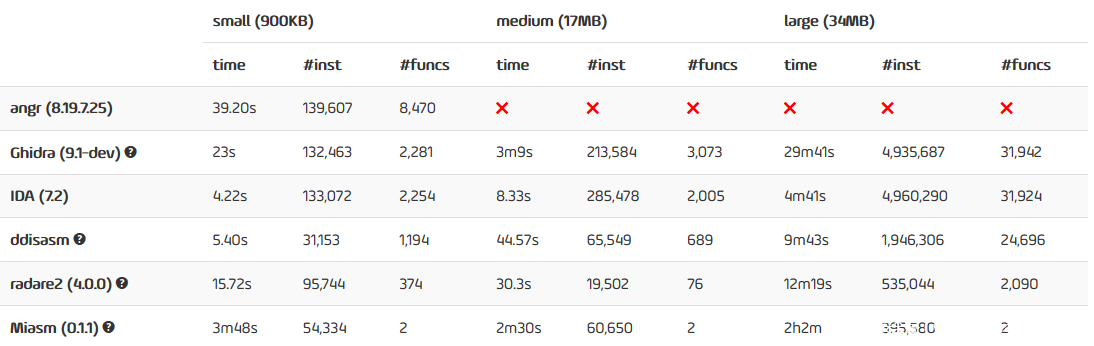
对这个表进行下说明:
反汇编,肯定不能把程序的“真实面貌”给展示出来,IDA和Ghidra的分析结果可以认为是“近似真实”。
Angr通过代码模拟执行来做控制流分析,进而对二进制文件进行正确的反汇编。不过它只能适用于小程序,对于大型程序的分析还是很困难的。当然前景还是非常好的。
Miasm需要获得程序的入口点来进行反汇编。它递归地从一个入口点执行反汇编,直到找不到任何的指令为止。它的效率不是很高,对小程序,反汇编花费了近4分钟,对大程序的反汇编用了2个小时。从设计角度来讲,这个工具是面向指令的,所以在发现函数方面的表现可以说是非常差的。
Delta_Generator程序的x86_64版本用于DDISAM,因为工具不支持x86。
IDA和Ghidra都能检索到足够的指令和函数,这是其他的工具不能比的。不过Ghidra的反汇编速度要差不少。
导出器
概览
下面将反汇编程序导出到独立文件中,主要目的是在初始化反编译步骤后关闭反编译器,因为后面就不需要这个功能了。下图是上节测试的工具可使用的导出器:
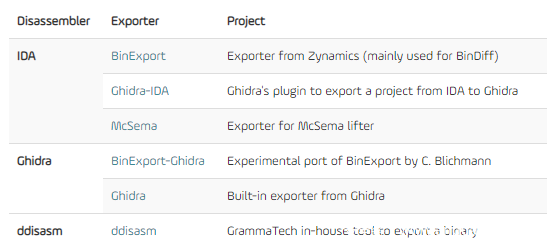
从上表中可以看出:
Ghidra提供了IDA插件来生成XML文件和原始数据文件,可以将IDA的反汇编结果导入到其中。
BinDiff使用BinExport从IDA导出反汇编结果。BinExport的作者之一已经在Ghidra上开了一个导出的功能端口(POC可以在他的GitHub中找到,工作的还是不错的)。
ddisasm能够分析二进制文件,并通过Protobuf文件导出大量信息,用于实现二进制重写。因此导出的特征集中在对task有用的专有信息上。这部分信息只是所有有用信息的一个真子集。
还有不错的导出器:
Diaphora: 把二进制文件导出到Sqlite数据库,并用Python编写。不过Sqlite文件比i64大出4到6倍,实用性要差一些。
Yaco:不导出任何低于基本颗粒度的信息(仅导出hash),这个工具也是生成FlatBuffers文件的唯一工具。
bnida:是用于将projec从IDA移植到Binary Ninja的插件。它导出到一个json文件并用python编写。它不会导出任何关于函数内容的数据,只有它们的名称和地址。
导出特性
下表详细列出了不同导出器导出的各种信息:
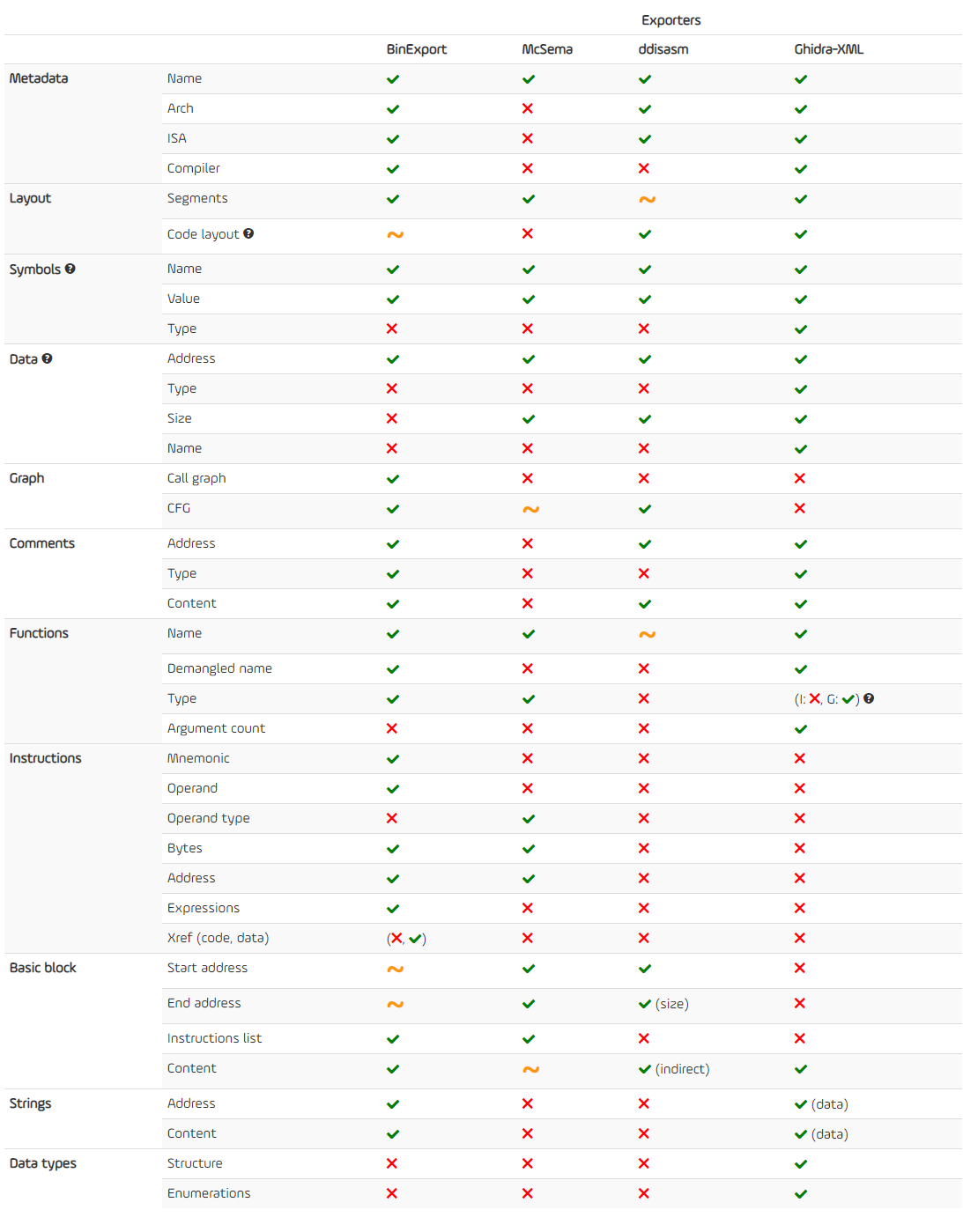
不同导出器的目的不一样,从二进制文件中导出的信息类型也就不一样。BinExport设计的是作为diffing引擎的一部分,ddisasm则是作为二进制重写工具链的一部分。注意下Ghidra-XML一列,这些导出信息在IDA和GHIDRA的实现结果会有不同,比如函数的类型。
导出器有两个主要策略:第一种策略是导出反汇编指令及其内容信息(助记符、操作数、操作数内的表达式等)。使用此策略,导出过程是独立的,不需要其他工具来分析它;第二种策略是只导出原始字节(指令)本身,并将剩余的反汇编工作留给另一个反汇编程序(例如capstone)。该策略更加紧凑,但需要一个辅助工具来理解导出的内容。策略的选择取决于工具的最终目标,Ghidra不导出反汇编指令是有道理的,因为它们有自己的反汇编程序;binexport导出所有指令也是有道理的,因为bindiff是自治的(并且尽可能快)工具。
全基准
重点研究选择性能最强大的两个:IDA和Ghidra。对他们的导出器的细节进行比较。BinExport的接口处于实验阶段,性能还不够,不做深入探讨。
数据集
文章收集了来自不同来源的各种二进制文件的数据集,包括各种体系结构、文件格式、大小和比特数的二进制文件:
二进制样本:Jonathan Salwan的二进制分析工具的测试套件。
AOSP(Android开源项目):一种用于移动设备的开源操作系统。
llvm:编译器基础设施项目。
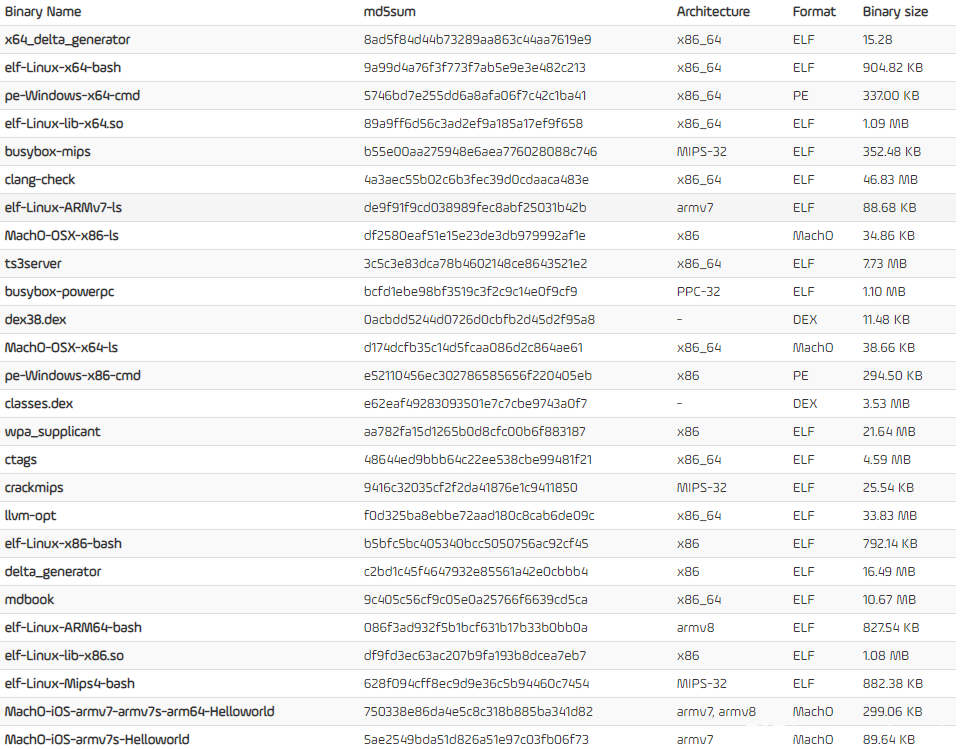
对上图做几点说明:
上图显示的是数据集中每个程序的指令数。
由于图纵轴的跨越范围很大(从0到8百万),所以除了后面四个的点,前面的点几乎都是在一条直线上。
如果要对百万条以上指令的程序分析能力进行比较的话,还要增加一些大型程序的用例,上图中使用最大的程序是46.83 MB的clang-check。按第一节的标准,只能算做一个中型程序。
反汇编时间
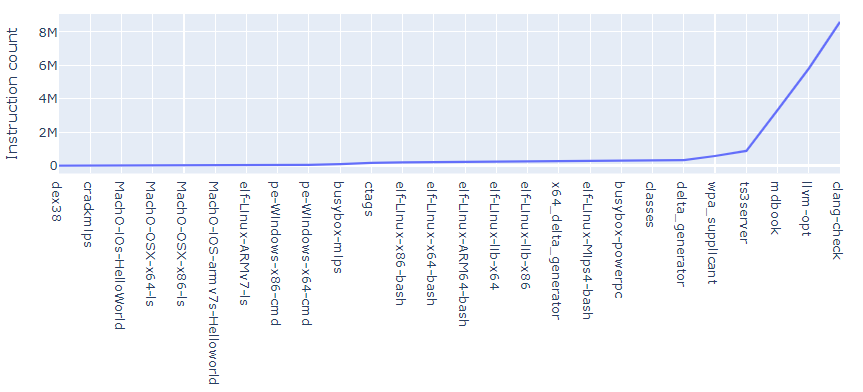
感兴趣的第一个指标是反汇编的时间,也就是自动分析的持续时间。IDA比Ghidra快,那快多少呢?
从上图的结果来看,Ghidra比IDA慢得多,对测试的大型二进制程序,慢了有13倍。不过有点得注意,这个结果是有偏差的,因为Ghidra会执行一个额外的反编译步骤。当然从使用者角度来讲,肯定是IDA的体验更好了。
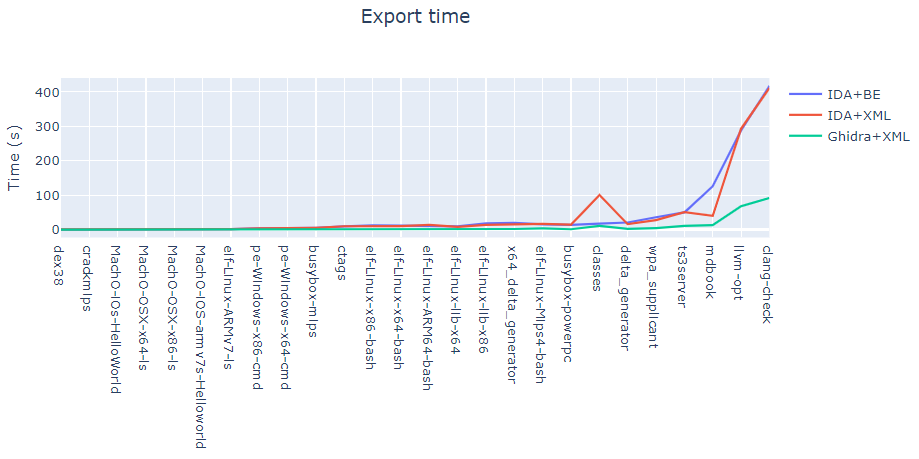
导出时间和大小
另一个重要的指标是反汇编程序+导出器组合的导出时间,主要研究三种组合:
IDA + BinExport
IDA + Ghidra XML
Ghidra + XML
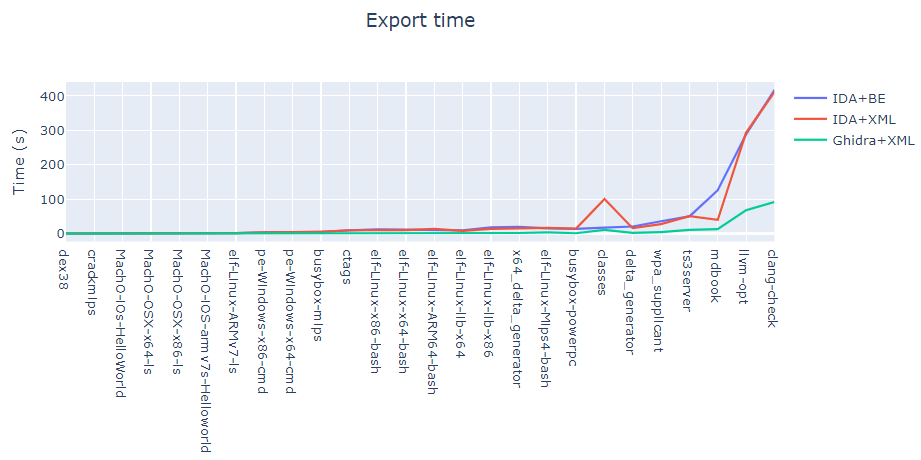
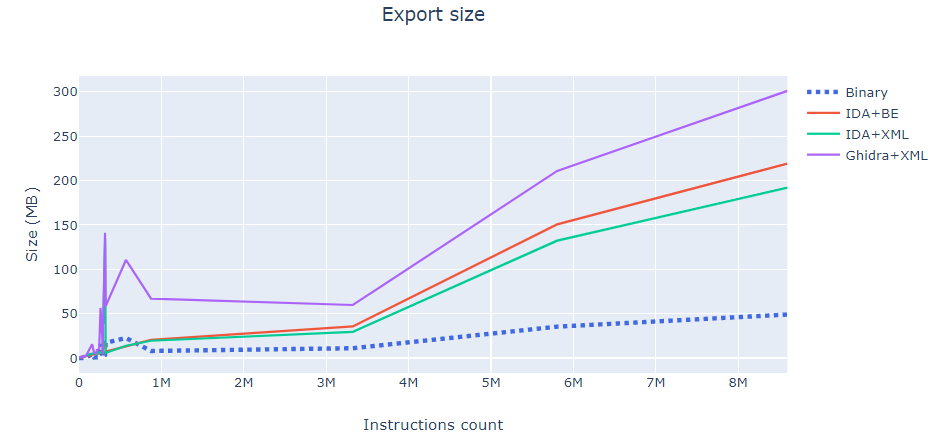
对IDA和Ghidra,程序的导出大小都远远大于程序本身。当BinExport生成一个Protobuf文件时,Ghidra会生成两个文件——一个是带有所有信息的XML文件,一个是原始字节文件。这其中包含所有导出的二进制代码。图上坐标的数字表示这两个文件的大小之和。

可以看出,BinExport和XML的导出大小大致相同。不过,BinExport比Ghidra导出了更多的二进制文件信息。要注意的是,除了原始字节外,Ghidra不会导出指令本身的任何信息,也不会导出基本块的任何信息。导出文件的格式采用了紧凑性设计(例如,重复删除表的广泛使用),导出文件使用二进制序列化协议Protobuf。这将在下文中进一步讨论。
上表还包括IDA生成的数据库的大小,即i64文件。它比本研究中考虑的任何导出文件都大得多。
全导出
为总结先前测试的结果,文章绘制了下面的图表,用于说明导出过程的三个阶段中所花费的时间:
反汇编阶段:反汇编二进制文件;
导出阶段:生成导出文件;
反序列化/加载阶段:在Python中导入导出的文件。
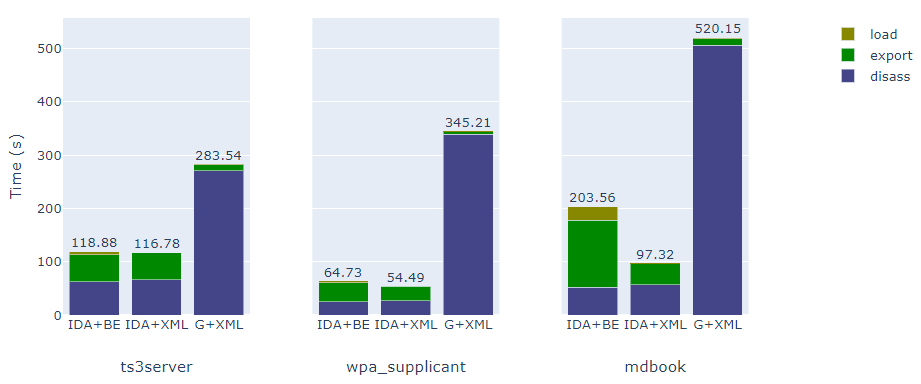
可以看出,对大型二进制文件的Protobuf格式(这里是MdBook),反序列化时间是不可忽略的。
二进制序列化格式的实验
由于持久存储、RPC通信、数据传输等功能的需求,所以会有很多不同的序列化格式。我们自然希望以“人类可读”的方式存储数据(即文本,如JSON,XML)。这种格式可以快速访问,存储也比较紧凑。但对于程序序列化而言,需要在磁盘开销、反序列化时间和内存占用之间进行权衡,显然二进制序列化格式更合适。
二进制序列化格式
本节主要关注三种二进制序列化格式:
Protobuf:由谷歌开发并广泛使用的一种格式,用于结构化数据的串行化。
FlatBuffers:谷歌开发的另一种格式来序列化数据。主要用于特别重视性能的应用程序。
Cap’n Proto:由Kenton Varda(在谷歌工作期间是Protobuf的技术主管)为沙暴(SandStorm)开发的格式。沙暴是一个个人云服务系统,使用者可以使用一个简单的APP 商店安装一些像邮箱、文件编辑、博客软件等。
在这里只能佩服下谷歌的技术实力。
所有这些格式都使用自定义的模式语言来解释数据如何格式化。简单看下三种协议的基本代码:
Protobuf:
message Meta {
optional string executable_name = 1;
optional string executable_id = 2;
optional string architecture_name = 3;
optional int64 timestamp = 4;
}
FlatBuffers:
table Meta {
executable_name:string;
executable_id:string;
architecture_name:string;
timestamp:long;
}
Cap’n Proto:
struct Meta {
executableName @0 :Text;
executableId @1 :Text;
architectureName @2 :Text;
timestamp @3 :UInt64;
}
这些格式之间的主要区别在于它们如何在线路上存储数据。Protobuf是最老的一个,它使用编码/打包的步骤来转换线路上的输入。这使得Protobuf更加紧凑,因为编码步骤减少了存储对象所需的字节量(参见Protobuf文档中的编码)。FlatBuffers和Cap’n Proto则都使用“零拷贝”策略,这意味着线路上数据的结构与存储器中数据的结构相同。这种技术的主要优点是没有解码的步骤。
Flatbuffers/Cap’n proto和Protobuf之间的另一个巨大区别是随机访问读取的能力,即在不读取整个消息之前读取消息的特定部分的能力。对于Protobuf来说,这是不可能的,因为消息需要在前面进行解析以及内存分配。而Flatbuffers和Cap’n proto都使用指针实现了这个特性,允许快速访问消息的一部分。
对于FlatBuffers ,分配(即如何编写消息)必须从下到上进行。因为消息必须在另一个消息开始之前完成。Protobuf没有这个限制,因为所有消息都在结尾写入。Cap’n Proto也没有这个限制,因为分配时知道对象的大小。
最后一个区别是如何将未设置的字段(即没有此特定消息值的字段)存储在线路上。Protobuf和Flatbuffer都不分配它们,而Cap’n Proto仍然分配它们。这就浪费了Cap’n Proto的空间。
基准
对于这些基准,我们将BinExport Protobuf翻译成FlatBuffers和Cap’n Proto模式。对于Cap’n Proto,翻译是手动完成的,并使用了选项—flatc proto for Flatbuffer,并加上一些小的修改。接着进行比较。
首先要比较导出的文件与二进制文件本身相比有多大。
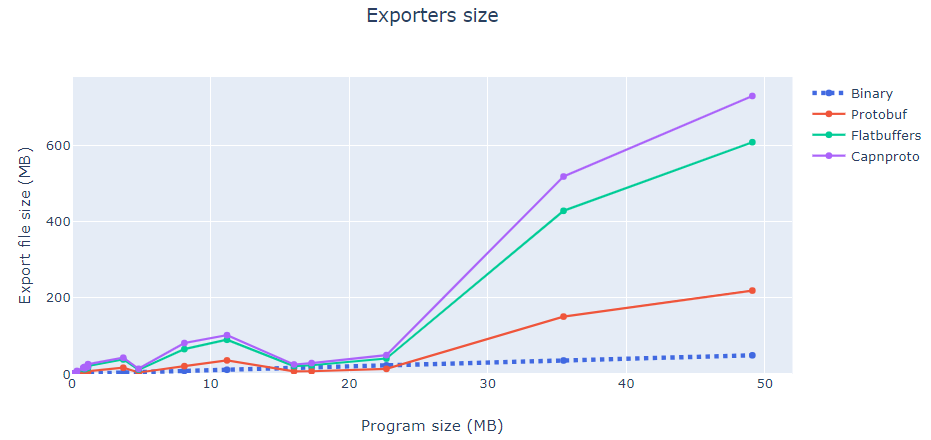
从图中可以看出导出文件的大小与二进制文件的大小成非线性增长。下图显示了导出文件大小与二进制文件大小之间的比例。
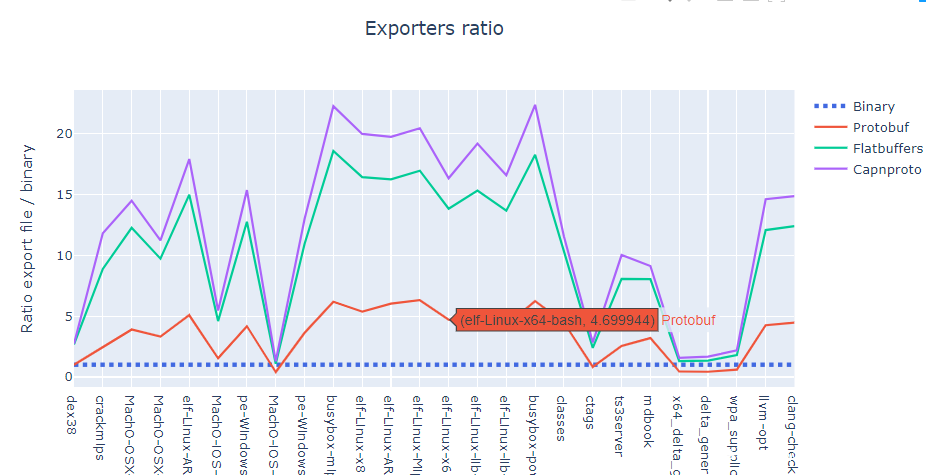
可以看出,Protobuf比其他两种更紧凑,因为编码步骤是至关重要的这一部分。其他两个协议的导出大小仍有改进的余地,主要是通过更好地理解不同值的范围。使用Protobuf,可以将每个整数声明为64位的宽整数,序列化算法只写入数字的varint编码值。但是,对于Cap’n Proto和Flatbuffers,这个值无论如何都需要64位长。
另一个研究点是用多少内存来加载Python中的序列化文件。需要注意的是,要使用MexyyPrPosiror模块检索内存使用情况。
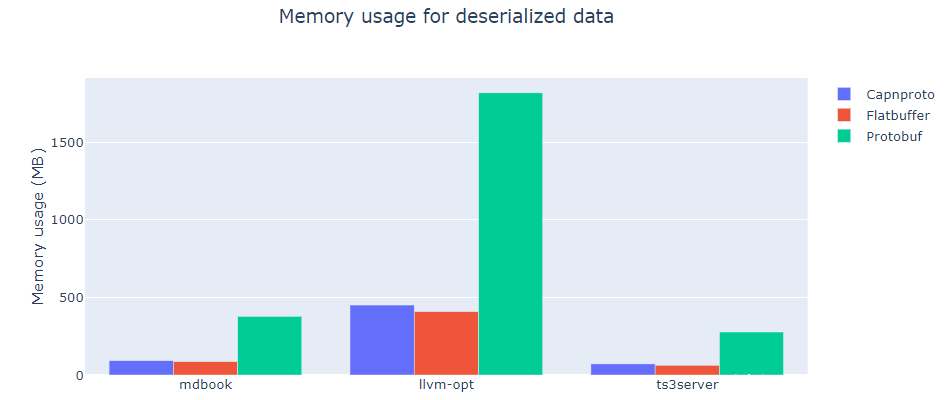
不出所料,加载二进制文件的导出所需的内存对于Protobuf来说要重要得多。例如,对于llvm-opt,Protobuf文件大约为150mb,但要占用1.8G的内存。
最后一个指标是,从三个文件格式加载python格式的导出文件需要多长时间。
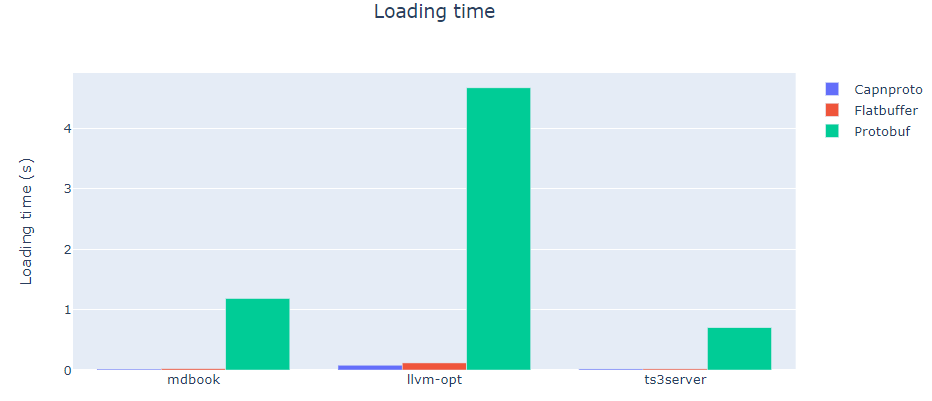
不出所料,Protobuf需要大量的时间来进行反序列化。Cap’n Proto和Flatbuffers具有相似的性能,主要是因为它们基于相同的模式。
还有两点需要注意的地方:
可以通过应用它们的“打包”算法来缩小Cap’n Proto输出文件的大小。但是,这会删除“零拷贝”协议的属性。这是否比Protobuf更好,还需要更多的实验来了解。
使用熟知的算法压缩导出的文件,也是Cap’n Proto和Flatbuffers的可行策略,因为它也会减少导出文件的大小。但这会增加一些时间,因为需要在使用之前解压缩文件。这一点不适用于Protobuf,因为格式已经很紧凑了。
结论
从二进制输出尽可能多数据的过程本身并没有意义,但却是其他工作的基础,如机器学习算法的特征提取、图形遍历算法、或基于用户定义标准地对函数/块/指令的快速访问。
这篇文章探讨了使用导出器从反汇编程序导出反汇编程序的不同选项。总来的来看,功能最全的导出器是BinExport,它可导出大量的信息。同时由于使用的序列化格式Protobuf,能够保持紧凑。不过所有的二进制导出器仍有改进的空间,在可伸缩性方面还有很大不足。
结尾
老外的文章学术性很强,有很多数据和实验支撑。这篇文章我开始觉得没有啥“意义”,不像那些工具的介绍、攻击手法的讲解、漏洞的分析利用这类的文章。但是后面一想,这样的文章是非常值得学习的,一种探索研究的过程,不单是技巧方面的研究,这些枯燥的内容恰恰是我们欠缺的吧。






发表评论
您还未登录,请先登录。
登录