

前言
已发现对空域信息的改变同时能影响频域的信息分布,基于此,本人在前述隐写分析模型的基础上,尝试模拟频域特征提取的方法,并获得了新的隐写分析模型,它具有良好的性能。
频域隐写术相关内容
隐写算法分为空域和频域两大领域。空域前述文章已做介绍。
在频域方面,隐写算法的特点是将消息隐藏在通过变换域技术变换后的载体图像空间中。应用广泛的算法有J-UNIWARD、F5、UED和UERD等,它们通过离散余弦变换(DCT)、离散小波变换(DWT)或奇异值分解(SVD)等将消息隐藏在载体图像中,只要载体图像不被破坏到无法使用的程度,隐藏的信息都能被保留。
2017年,出现了一些频域的隐写分析成果。例如,Zeng等人提出了一个基于JPEG域的隐写分析模型,它使用了Discrete Cosine Transform(DCT)提取JPEG格式图像的特征,取得良好的结果。
分析可知对图像空域信息的操作同样会影响频域等信息,因此认为结合空域、频域等信息更有利于检测空域的隐写信息,本文尝试实现这一想法。
本文的模型模拟了频域的DCTR特征的提取方法。
DCTR
在频域中,残差图像的离散余弦变换(DCTR)是一种通用的隐写检测算法,它特征处理的步骤如下:
(1)计算获得64个8×8的DCT patterns,将解压后的JPEG图像与DCT基做卷积运算得到特征图,这些特征图有效地抑制了图像内容,即提高了信噪比。
(2)将特征图量化、截断得到子特征图,这些子特征图在拥有多样性特征的同时,还具有较低的维度,从而有效地降低了计算的复杂度。
(3)通过对称性原则压缩子特征图为8000维的特征向量。
DCTR较于一般的通用隐写检测算法,最大的优势在于效率非常高,提取出的特征的维数也相对较低。
上述步骤中,DCT basic patterns是8×8的矩阵,即下图。
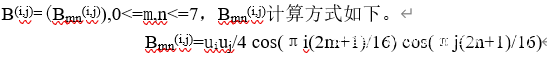
其中,当k>0时,u0=1/√2,k取其他值时uk=1。
DCT被定义为图像与64个DCT basic patterns B(i,j) 的卷积运算,为了方便理解,设定所有图像的长宽为8的倍数。给定一个大小为MxN(M,N均为8的倍数)的灰度图像I,DCT的运算方法如下。
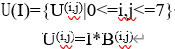
其中,‘*’表示无填充的卷积运算。
新的隐写分析模型
目前卷积神经网络模型已经通过模拟线性和非线性残差隐写信息充分提取了嵌入秘密信息后空域中的变化,但没有考虑隐写造成的频域中信息的变化。为了适应现有模型,本文在模拟频域DCTR特征提取方式时对其做了一些修改。
模型频域特征提取的设计
根据通用性和隐写检测效率,本文选择了DCTR。传统的DCTR中使用了64个8×8的DCT Patterns,如果将它加入到网络的预处理层,加之前述的30个HPFs,则一共需要94个卷积核被它们初始化并参与计算,这是一个非常大的数据规模了。根据领域知识,小的卷积核能有效地减少网络的参数规模,同时矩阵运算可充分利用GPU并行计算的优势。因此,本文设计卷积核为一个通道数为94、大小是5×5的矩阵,使用DCT Patterns和HPFs初始化该卷积核,这样即有效地减少了参数规模,加快了运算速度。此时,新的DCT patterns的计算公式修改如下:
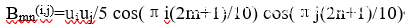
其中,当k>0时,u0=1,k取其他值时uk=√2,0<=m,n<=4,0<=i,j<=7。
模型频域特征提取的实现
使用Python实现,如下:
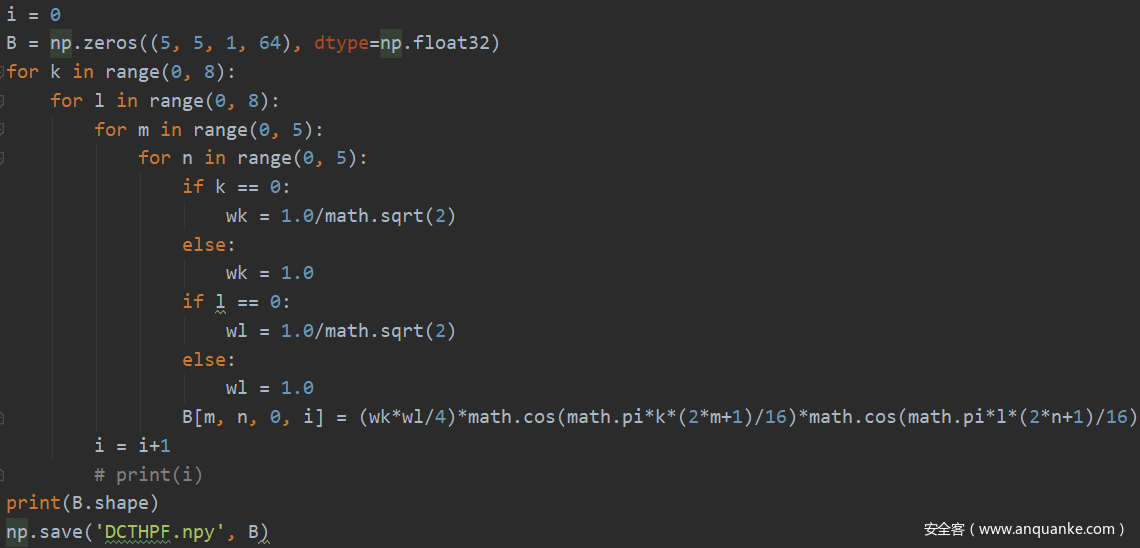
这样即得到DCT Patterns,将它和HPFs初始化的矩阵与图像直接做卷积运算即可获得频域和空域的隐写特征信息。
模型性能比较
本文称结合了频域隐写特征的新模型为‘our model’,将仅模拟空域线性和非线性隐写特征的模型称为‘空域模型’,使用Bossbase数据集,经过实验得出在经典自适应隐写算法下的隐写分析准确率。如下图。
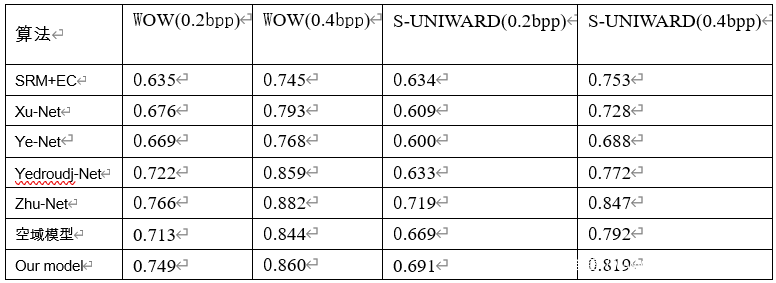
根据结果可知,联合了频域特征提取的优势后,‘our model’对于WOW和S-UNIWARD的隐写分析准确率比‘空域模型’高约2%~3%。这说明联合空域和频域线性、非线性特征提取的优势后,隐写分析模型的隐写效果会得到很大的提升。
其中,SRM+EC是传统的手工特征提取的隐写分析模型,Xu-Net、Ye-Net、Yedroudj-Net、Zhu-Net是效果良好的新型卷积神经网络隐写分析模型。根据结果可知,‘our model’性能优于SRM+EC、Xu-Net、Ye-Net、Yedroudj-Net,比Zhu-Net的隐写分析检测准确率稍微低约2%~3%。
改进模型训练方式提升隐写术检测性能
目前的隐写分析模型的训练方式过于老套,没有充分利用隐写的特性。基于此,本文研究了隐写术的特性,受迁移学习思想的启发,并根据模型的特点,提出了一个自适应模型特点的训练方式,从而使得最终的模型具有良好的隐写分析效果。
迁移学习历史
在2016年,人们发现在隐写分析过程中,低嵌入率载密图像较难训练,不易收敛,检测性能差。经分析,低嵌入率图像的检测难点在于嵌入信息量小,从而对图像统计特性的改变相对较小,因此正常图像和载密图像间的差异很小,更难区分。因此,Qian等人建议利用迁移学习的思想,通过迁移高嵌入率载密图像数据集上学到的特征信息,增强低嵌入率载密图像数据集上的特征学习,来改善网络训练不收敛的问题。作者认为尽管高嵌入率和低嵌入率隐写操作在对图像的统计特性会分别造成不同的影响,但是其对图像邻近像素相关性的影响模式具有相似之处,同时这些影响模式在高嵌入率载密图像中很容易被捕获,进而可以通过迁移这些信息来促进对低嵌入率载密图像的检测。其具体的做法是首先将CNN模型在由正常图像和高嵌入率载密图像组成的训练集上进行预训练,然后在由正常图像和低嵌入率载密图像组成的训练集上进行微调训练(Fine tuning),最后将模型用于低嵌入率载密图像检测。这种方法有效地提升了隐写分析模型的检测性能。
新型训练模式下的模型
已知不同嵌入率隐写操作对图像邻近像素相关性的影响模式具有相似之处,则认为具备足够高学习能力的网络模型通过低嵌入率隐写数据集训练的模型,对高嵌入率隐写数据集的检测应该更敏感。
模型的学习能力高体现在模型复杂度高,容易过拟合。本文在训练过程中已经明显发现验证集的准确率会低于训练集的准确率,这是典型的过拟合现象。下面通过分析模型的结构呈现它的复杂情况。
模型结构的分析
模型中一共有10层,其中包括一个图像预处理层、八个卷积层用于特征提取,一个全连接层用于结果分类。它接收大小为256×256的图像,输出两类标签表示检测结果。
在第一层中,主要模拟了空域和频域特征提取的方式。使用了1个通道数为94、大小为5×5卷积核来计算获得特征信息,该卷积核由SRM滤波器和DCT Patterns初始化得到。这里的参数规模大约是5x5x94=2350。
在第二至九层中,模型使用了3×3、5×5的卷积核,其中3×3卷积核居多。3×3卷积核能降低参数的规模,增强网络的非线性,这有效地提升了特征的表达能力,但计算量较大。因此在2、3、4、8、9层均使用3×3卷积核,在5、6、7层使用5×5卷积核。单纯卷积的参数规模大约是3x3x104x3+5x5x106x104+5x5x106x2+5x5x106x53+5x5x53=425483。
并且在第二至九层,还存在BN、非线性激活函数、池化的操作。下面详细介绍。
(1)BN。BN通常被用于正则化样本特征,使它符合0均值、单位方差的特征,这有效地避免了梯度爆炸、梯度消失和过拟合的产生,并加速网络的汇聚。因此在每个卷积层中都加入了BN。
(2)非线性激活函数。使用的非线性激活函数主要是TLU和rectifying linear unit(ReLU),它们能有效地增强网络的特征表达的能力。其中,ReLU是一个效果显著的选择,在卷积神经网络中,它可以表示为:
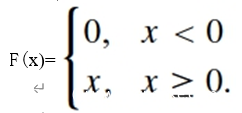
ReLU激活函数广泛地被应用于计算机视觉的任务中,例如目标分类等。在一些具有较高信噪比的任务中,应用ReLU更能节省计算成本,输出信息具有稀疏的特性,而稀疏表示更容易被线性分离,从而具备良好的泛化能力。对于隐写分析任务,嵌入载体图像的隐秘信息可被看作是在图像上添加了低幅度噪声,研究表明ReLU仍然能够很好地适应噪声的分布并从中获取特征信息,因此在第2至9层皆使用ReLU激活函数。
TLU激活函数表示为:
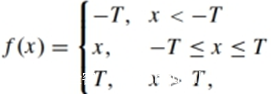
使用TLU激活函数适应了隐写信息的嵌入分布,并迫使网络学习更有效的特征信息。根据Ye-Net可知,在网络前几层使用TLU激活函数会有比ReLU更好的结果,但TLU不能像ReLU一样被CuDNN library加速。折中考虑后,只在第1层使用TLU激活函数。
(3)池化。池化能下采样特征图,更好地抽象特征信息,减小特征图大小的同时减少了参数和计算量,能有效地防止过拟合现象的出现,同时它具有不变性的特点,这能显著增强网络的泛化能力,但过度使用池化层会弱化隐写噪声的特征信息。因此只在第4、5、6、7卷积层中加入池化。池化的卷积核大小是3×3,单纯池化的参数规模大约是3x3x(104+106+106+106)=3798。
在全连接层中,参数规模为53×2=106。
因此,总模型的参数规模大约是429483+3798+106=429387,到达试完级别,参数规模很大,网络的复杂度很大。
模型训练方法的设计
已确定模型复杂度过高,学习能力较强。已知不同嵌入率隐写操作对图像邻近像素相关性的影响模式具有相似之处,受Transfer Learning思想的启发,本文根据模型情况提出了新的训练方式。
即:在训练模型时,使用了低嵌入率图像集,在验证和测试时,使用了高嵌入率图像集。通过这种方式训练出的模型的检测更灵敏,性能更优。
新训练方式下的模型结果比较
记使用新训练方式的模型为‘our model’,并将它与现有卷积神经网络隐写分析模型作比较,结果如下。
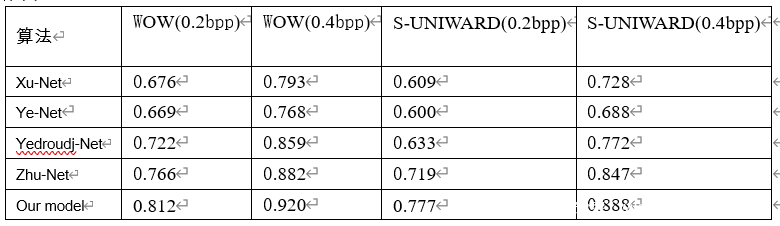
可知,改进了模型的训练方式后,其隐写分析检测性能更优。








发表评论
您还未登录,请先登录。
登录