

简介
在Project Zero工作室,我们收到了Chrome团队的一封电子邮件 — 他们一直在分析一个崩溃,这个崩溃在Chrome的Android版本上偶尔会发生,但没有取得太大进展。同样的崩溃随后在ClusterFuzz上短暂重现;一个测试用例引用了一个外部网站,但是它不再复现了,下一步可能要等到bug再次复现。
我们快速浏览了一下它们的详细信息,认为这个问题对我们来说非常重要,我们可以花一些时间帮助Chrome团队找出具体原因。我们在这里有一个担心:也许这个外部网站是故意触发一个易受攻击的代码路径(剧透:并非如此)。这个问题看起来也很容易被利用——ASAN trace显示了一个越界的堆写入,其中可能包含从网络读取的数据。
虽然Chrome中的网络代码已经被分割成一个新的服务进程,但该进程的沙盒实现还没有完成,因此它仍然是特权很高的攻击面。这意味着,这个bug本身就足以让初始代码执行,并打破Chrome的沙盒。
我们写这篇文章是为了说明即使是经验丰富的研究员在试图理解一段复杂代码中的漏洞时有时也会遇到的困难。这个事情有一个完美的结局,我们能够帮助Chrome团队找到并修复这个问题,但希望读者也能看到,在这里,坚持也许比能力更重要。
Chapter 1:测试用例
因此,我们有以下相当简单的测试用例:
<script>
window.open("http://example.com");
window.location = "http://example.net";</script>
细心的读者无疑会注意到,对于一个fuzzer来说,这是一个很无聊的输出:所有这些都是加载两个网页!也许这是对用户行为的一种很好的模拟,而这种测试用例也许是摆脱网络堆栈bug的一种好方法?
根据线程,此操作现在已停止复现,因此我们所拥有的只是从ClusterFuzz首次触发问题起的ASAN回溯:
=================================================================
==12590==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x8e389bf1 at pc 0xec0defe8 bp 0x90e93960 sp 0x90e93538
WRITE of size 3848 at 0x8e389bf1 thread T598 (NetworkService)
#0 0xec0defe4 in __asan_memcpy
#1 0xa0d1433a in net::SpdyReadQueue::Dequeue(char*, unsigned int) net/spdy/spdy_read_queue.cc:43:5
#2 0xa0d17c24 in net::SpdyHttpStream::DoBufferedReadCallback() net/spdy/spdy_http_stream.cc:637:30
#3 0x9f39be54 in base::internal::CallbackBase::polymorphic_invoke() const base/callback_internal.h:161:25
#4 0x9f39be54 in base::OnceCallback<void ()>::Run() && base/callback.h:97
#5 0x9f39be54 in base::TaskAnnotator::RunTask(char const*, base::PendingTask*) base/task/common/task_annotator.cc:142
...
#17 0xea222ff6 in __start_thread bionic/libc/bionic/clone.cpp:52:16
0x8e389bf1 is located 0 bytes to the right of 1-byte region [0x8e389bf0,0x8e389bf1)
allocated by thread T598 (NetworkService) here:
#0 0xec0ed42c in operator new[](unsigned int)
#1 0xa0d52b78 in net::IOBuffer::IOBuffer(int) net/base/io_buffer.cc:33:11
Thread T598 (NetworkService) created by T0 (oid.apps.chrome) here:
#0 0xec0cb4e0 in pthread_create
#1 0x9bfbbc9a in base::(anonymous namespace)::CreateThread(unsigned int, bool, base::PlatformThread::Delegate*, base::PlatformThreadHandle*, base::ThreadPriority) base/threading/platform_thread_posix.cc:120:13
#2 0x95a07c18 in __cxa_finalize
SUMMARY: AddressSanitizer: heap-buffer-overflow (/system/lib/libclang_rt.asan-arm-android.so+0x93fe4)
Shadow bytes around the buggy address:
0xdae49320: fa fa 04 fa fa fa fd fa fa fa fd fa fa fa fd fa
0xdae49330: fa fa 00 04 fa fa 00 fa fa fa 00 fa fa fa fd fd
0xdae49340: fa fa fd fd fa fa fd fa fa fa fd fd fa fa fd fa
0xdae49350: fa fa fd fd fa fa fd fd fa fa fd fd fa fa fd fd
0xdae49360: fa fa fd fd fa fa fd fa fa fa fd fd fa fa fd fd
=>0xdae49370: fa fa fd fd fa fa fd fd fa fa fd fa fa fa[01]fa
0xdae49380: fa fa fd fa fa fa fd fa fa fa fd fd fa fa fd fd
0xdae49390: fa fa fd fd fa fa fd fd fa fa fd fd fa fa fd fd
0xdae493a0: fa fa fd fd fa fa fd fa fa fa 00 fa fa fa 04 fa
0xdae493b0: fa fa 00 fa fa fa 04 fa fa fa 00 00 fa fa 00 fa
0xdae493c0: fa fa 00 fa fa fa 00 fa fa fa 00 fa fa fa 00 fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable:00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==12590==ABORTING
这看起来是一个非常严重的Bug;它是一个堆缓冲区溢出,写入的数据可能直接来自网络。然而,我们在Android上没有可用的Chrome开发环境,所以我们决定自己尝试找出具体原因,我们认为找到一个IOBuffer大小容易混淆的地方并不难。
Chapter 2: HttpCache::Transaction
由于这个bug不再在ClusterFuzz上重现,我们最初假设web服务器或网络配置中发生了一些变化,然后开始查看代码。
回溯在SpdyHttpStream::DoBufferedReadCallback中写入的IOBuffer的来源,我们可能会查找一个网站调用的HttpNetworkTransaction::Read,其中作为参数buf传递的IOBuffer的大小与作为buf长度传递的不匹配。网站调用并不多,但是没有一个看起来是立刻出错的,我们花了几天时间反复讨论那些毫无希望的理论。
也许我们的第一个错误是试图通过分析Chrome的崩溃dump来收集更多关于这个bug的信息,结果发现,有很多类似的堆栈trace崩溃,我们根本无法解释——这并不有助于解释这个bug!经过大约一周的调查,我们收集了大量相关的崩溃案例,但在找出问题根源方面却毫无进展。
当我们在HttpCache::Transaction::WriteResponseInfoToEntry中找到以下代码行时,我们越来越接近挫败感了:
// When writing headers, we normally only write the non-transient headers.
bool skip_transient_headers = true;
scoped_refptr<PickledIOBuffer> data(new PickledIOBuffer());
response.Persist(data->pickle(), skip_transient_headers, truncated);
data->Done();
io_buf_len_ = data->pickle()->size();
// Summarize some info on cacheability in memory. Don’t do it if doomed
// since then |entry_| isn’t definitive for |cache_key_|.
if (!entry_->doomed) {
cache_->GetCurrentBackend()->SetEntryInMemoryData(
cache_key_, ComputeUnusablePerCachingHeaders()
? HINT_UNUSABLE_PER_CACHING_HEADERS
: 0);
}
这看起来很可疑;在同一文件的其他位置,可以清楚地看到iobuf_len与IOBuffer readbuf的大小匹配;实际上,这个假设被用在一个调用中,它会导致Read调用:
int HttpCache::Transaction::DoNetworkReadCacheWrite() {
TRACE_EVENT0("io", "HttpCacheTransaction::DoNetworkReadCacheWrite");
DCHECK(InWriters());
TransitionToState(STATE_NETWORK_READ_CACHE_WRITE_COMPLETE);
return entry_->writers->Read(read_buf_, io_buf_len_, io_callback_, this);
}
它当然符合我们所知道的关于这个bug的所有信息,而且在这一点上,它似乎是我们所拥有的最好的线索,但是以一种特别的方式来获取此代码并不容易。HTTP缓存实现了一个状态机,有大约50个不同的状态!此状态通常在请求期间运行两次;一次是在请求启动时(HttpCache::Transaction::Start),另一次是在读取响应数据时(HttpCache::Transaction::Read)。为了找到这个Bug,我们需要一个状态转换中的循环,它可以将我们从一个读取状态,返回到一个可以调用WriteResponseInfoToEntry的状态,并在不更新读取指针的情况下返回到读取数据的状态;所以我们关注的是这个状态机的第二次运行;即可从Read调用访问。
WriteResponseInfoToEntry有4个调用站点,都在状态处理程序中:
- DoCacheWriteUpdatedPrefetchResponse
- DoCacheUpdateStaleWhileRevalidateTimeout
- DoCacheWriteUpdatedResponse
- DoCacheWriteResponse
我们首先需要确定是否存在从HttpCache::Transaction::Read到这些状态中每个状态的转换路径,否则我们将没有readbuf 和iobuf_len 的之前的值。
由于很难通过查看代码来判断状态机的转换情况,所以我们准备了一个类似的图,它将使读者能够清楚的理解。
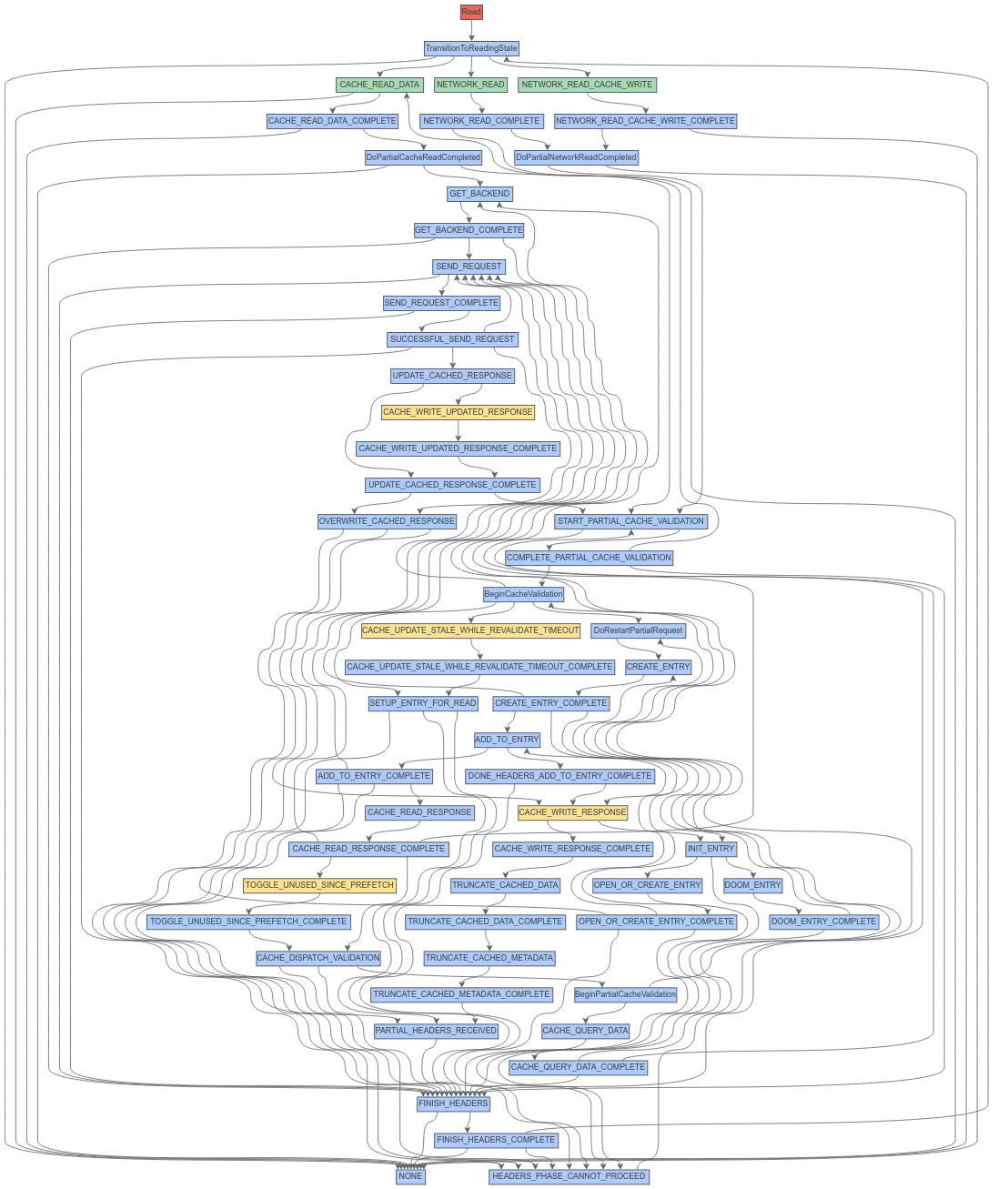
用黄色标记的四个状态是可以更改iobuf_len 值的状态,然后使用这个损坏的iobuf_len值的状态是TransitionToReadingState的三个子状态:CACHE_READ_DATA、NETWORK_READ和NETWORK_READ_CACHE_WRITE,它们用绿色标记。
我们首先可以排除TOGGLE_UNUSED_SINCE_PREFETCH,因为它应该只在预读取之后发送的第一个请求时才能达到匹配的缓存条目,这个请求将在启动期间发生,而不是在读取期间。
也可以排除CACHE_WRITE_UPDATED_RESPONSE,因为只有在我们没有处于读取状态时才能实现这个转换:
int HttpCache::Transaction::DoUpdateCachedResponse() {
TRACE_EVENT0("io", "HttpCacheTransaction::DoUpdateCachedResponse");
int rv = OK;
// Update the cached response based on the headers and properties of
// new_response_.
response_.headers->Update(*new_response_->headers.get());
response_.stale_revalidate_timeout = base::Time();
response_.response_time = new_response_->response_time;
response_.request_time = new_response_->request_time;
response_.network_accessed = new_response_->network_accessed;
response_.unused_since_prefetch = new_response_->unused_since_prefetch;
response_.ssl_info = new_response_->ssl_info;
if (new_response_->vary_data.is_valid()) {
response_.vary_data = new_response_->vary_data;
} else if (response_.vary_data.is_valid()) {
// There is a vary header in the stored response but not in the current one.
// Update the data with the new request headers.
HttpVaryData new_vary_data;
new_vary_data.Init(*request_, *response_.headers.get());
response_.vary_data = new_vary_data;
}
if (response_.headers->HasHeaderValue("cache-control", "no-store")) {
if (!entry_->doomed) {
int ret = cache_->DoomEntry(cache_key_, nullptr);
DCHECK_EQ(OK, ret);
}
TransitionToState(STATE_UPDATE_CACHED_RESPONSE_COMPLETE);
} else {
// If we are already reading, we already updated the headers for this
// request; doing it again will change Content-Length.
if (!reading_) {
TransitionToState(STATE_CACHE_WRITE_UPDATED_RESPONSE);
rv = OK;
} else {
TransitionToState(STATE_UPDATE_CACHED_RESPONSE_COMPLETE);
}
}
return rv;
}
这就给我们留下了两种可能触发bug的状态:cache_update_stale_while e_revalidate_timeout和CACHE_WRITE_RESPONSE,所以让我们看一下返回TransitionToReadingState的转换,看看如何将它们连接起来。TransitionToReadingState只有一个向后的边缘,它来自FINISH_HEADERS_COMPLETE:
// If already reading, that means it is a partial request coming back to the
// headers phase, continue to the appropriate reading state.
if (reading_) {
int rv = TransitionToReadingState();
DCHECK_EQ(OK, rv);
return OK;
}
因为我们希望望reading_在这个时候被设置(它是在Read中设置的,并且永远不会被清除)。然而,回顾一下图,在所有的正常情况下,我们实际上不应该访问这个图中的大多数状态,为了达到GET_BACKEND或START_PARTIAL_CACHE_VALIDATION,我们需要经过DoPartialCacheReadCompleted或DoPartialNetworkReadCompleted以达到以下转换:
int HttpCache::Transaction::DoPartialCacheReadCompleted(int result) {
partial_->OnCacheReadCompleted(result);
if (result == 0 && mode_ == READ_WRITE) {
// We need to move on to the next range.
TransitionToState(STATE_START_PARTIAL_CACHE_VALIDATION);
} else if (result < 0) {
return OnCacheReadError(result, false);
} else {
TransitionToState(STATE_NONE);
}
return result;
}
int HttpCache::Transaction::DoPartialNetworkReadCompleted(int result) {
DCHECK(partial_);
// Go to the next range if nothing returned or return the result.
// TODO(shivanisha) Simplify this condition if possible. It was introduced
// in https://codereview.chromium.org/545101
if (result != 0 || truncated_ ||
!(partial_->IsLastRange() || mode_ == WRITE)) {
partial_->OnNetworkReadCompleted(result);
if (result == 0) {
// We need to move on to the next range.
if (network_trans_) {
ResetNetworkTransaction();
} else if (InWriters() && entry_->writers->network_transaction()) {
SaveNetworkTransactionInfo(*(entry_->writers->network_transaction()));
entry_->writers->ResetNetworkTransaction();
}
TransitionToState(STATE_START_PARTIAL_CACHE_VALIDATION);
} else {
TransitionToState(STATE_NONE);
}
return result;
}
// Request completed.
if (result == 0) {
DoneWithEntry(true);
}
TransitionToState(STATE_NONE);
return result;
}
在最初的分析中,我们的思路已经迷失在时间中,但是我们已经度过了这一点,并陷入了泥潭,试图通过这段代码找到一条工作路径,它处理部分条目的缓存验证。我们需要引起一种无法控制情况,缓存响应一个完整的请求,而缓存中有一个先前的部分请求;然后,我们需要导致之前的部分的请求重新验证失败。不幸的是,我们试图使浏览器发送部分请求的方式都未能触发感兴趣的代码路径。
无论如何,很明显代码是错误的,因此我们建议对Chrome进行临时修复,以添加一个检查,确保如果发生这种状态转换循环,它将不再是可利用的漏洞。
Chapter 3: It lives!
最初我们都假设由于相关代码没有更改,并且测试用例引用了外部服务器,所以服务器端发生了更改,从而阻止了问题的重现。然而,在我们提供初步分析信息的同时,一位Chrome开发者发现,他们仍然可以在Android上使用与ClusterFuzz原始报告中完全相同的Chrome版本来重现这个问题!
这个bug阻止在Android上复现的原因似乎是一个不相关的更改影响了进度,足以防止问题触发。不幸的是,这个变化是在ClusterFuzz第一次遇到这个问题之后出现的。这对我们来说是一个重要的时刻,因为这是一个非常容易测试的事情,我们只是太懒了,没有建立一个构建环境来测试我们自己……我们测试了一下,又测试了一下,果然测试成功了!
在这一点上,我们对我们的决策过程提出了更彻底的质疑,并立即尝试在Linux版本上使用相同的版本进行复现。我想读者可以想象我们的感觉,这个问题也在本地用ASAN Linux版本复现…
看起来罪魁祸首是被访问的网站上的一张图片,它被加载了loading=lazy属性。这项功能刚刚在稳定的桌面Chrome中启用,并且已经在Android上运行。浏览器请求的简化说明如下:
GET /image.bmp HTTP/1.1 (1)
Accept-Encoding: identity
Range: bytes=0-2047
HTTP/1.1 206 Partial Content
Content-Length: 2048
Content-Range: bytes 0-2047/9999
Last-Modified: 2019-01-01
Vary: Range
GET /image.bmp HTTP/1.1 (2)
Accept-Encoding: gzip, deflate, br
If-Modified-Since: 2019-01-01
Range: bytes=0-2047
HTTP/1.1 304 Not Modified
Content-Length: 2048
Content-Range: bytes 0-2047/9999
Last-Modified: 2019-01-01
Vary: Range
GET /image.bmp HTTP/1.1 (3)
Accept-Encoding: gzip, deflate, br
HTTP/1.1 200 OK
Content-Length: 9999
将合理数量的混淆和篡改变得微不足道,我们就能够将触发器减少到恰好与上述请求响应序列相同的程度。这告诉我们什么?
使用Chrome的trace,我们可以看到通过状态机的路径;在这个触发器中实际上有两个HttpCache::Transaction对象。第一个请求来自第一个事务;它读取第一个2048字节并将其存储在缓存中。然后,第二个和第三个请求来自第二个事务,即请求完整数据。由于URL存在一个现有的缓存条目,它首先通过发送第二个请求来验证缓存条目是否有效。
因为条目是有效的,所以事务将开始读取——进入读取状态,就好像从缓存中读取完整的响应一样。但是,由于缓存条目不完整,因此我们需要发出第三个请求来检索其余的响应数据。在处理这第三个请求时,我们遇到了不安全的状态转换。当浏览器试图确定如何验证来自服务器的第二部分数据的响应时,就会发生这种情况,这将需要发送不同的Range标头,从而打破服务器施加的Vary约束。由于服务器没有提供强大的验证机制(如Etag),浏览器无法确定它没有将两个完全不同的响应的部分拼接在一起,因此它必须从一开始就重新启动请求;但是它已经返回到调用代码的响应头——所以它试图透明地不退出状态机来做这件事,这触发了漏洞。
注意,延迟在这里扮演了一个角色——如果第一个请求的响应到达浏览器的时间太长,那么第二个请求将从头开始,而不是执行缓存验证,并且这个漏洞将不会被触发。如果您试图使用远程服务器对此进行测试,则需要进行一些修改以保持正确的顺序——这留给读者作为练习。
为了利用这个bug,我们需要注意一些事情;为了进入可以在Read调用中循环返回而又不退出状态机的状态,我们需要触发DoRestartPartialRequest的调用。这将使当前的缓存条目失效,并截断所存储的响应数据。这意味着当我们到达CACHE_READ_RESPONSE时,我们无法控制此处使用的值:
int HttpCache::Transaction::DoCacheReadResponse() {
TRACE_EVENT0("io", "HttpCacheTransaction::DoCacheReadResponse");
DCHECK(entry_);
TransitionToState(STATE_CACHE_READ_RESPONSE_COMPLETE);
io_buf_len_ = entry_->disk_entry->GetDataSize(kResponseInfoIndex);
read_buf_ = base::MakeRefCounted<IOBuffer>(io_buf_len_);
net_log_.BeginEvent(NetLogEventType::HTTP_CACHE_READ_INFO);
return entry_->disk_entry->ReadData(kResponseInfoIndex, 0, read_buf_.get(),
io_buf_len_, io_callback_);
}
实际上,由于该条目已被截断,因此iobuf_len 将始终为0。
另一方面,在调用WriteResponseInfoToEntry时,我们对CACHE_WRITE_RESPONSE期间的值有或多或少的完全控制:
// When writing headers, we normally only write the non-transient headers.
bool skip_transient_headers = true;
scoped_refptr<PickledIOBuffer> data(new PickledIOBuffer());
response_.Persist(data->pickle(), skip_transient_headers, truncated);
data->Done();
io_buf_len_ = data->pickle()->size();
如上所述,当使用现在不正确的长度从网络读取响应数据时,在稍后发生越界写入。虽然使用的长度是非临时header的大小,但服务器在响应body中返回的字节数只会与写入的字节数相同,因此我们可以精确地写入所需的字节数,从而使我们可以完全控制要利用的内存破坏原语。
结论
这里有一些从Bug中得出的结论:
- 使用一个变量表示两个含义的代码是错误的。即使代码在编写时最初是“正确的”,但在以后的迭代中也不太可能保持正确!
- C++中的C风格编程也是一个不好的信号;IOBuffer的设计模式是将缓冲区及其大小单独存储,这本身就是不安全的。
查看状态机代码本身,其中有很多复杂性。也许这些代码可以被设计成不同的方式来减少复杂性;但这也是随着HTTP协议的发展而演变起来的代码,现在重写可能会带来不同的复杂性和bug。







发表评论
您还未登录,请先登录。
登录