
社交网络是一个新兴的平台,在该平台上可以获取大量数据,而不会在网络上隐藏个人或人群的敏感信息。第三方或外部攻击者可以将这种高度敏感的数据用于无法确保隐私的社交目标。匿名化数据是保护隐私的模型之一,它有助于减少隐私泄漏,并且还增加了数据实用性。但是,攻击者试图使用新方法来识别个人数据。新方法中的一种是配对攻击(Couplet Attack),它具有一些背景知识,可以通过使用一对节点属性来找到个体的身份。现有方法中k配对匿名(k-couplet anonymity)在属性配对攻击下可以实现隐私。在本文中使用因素分析(factor analysis)来减少这种攻击。
0x01 Absert
社交网络是当今世界上流行的平台,在该平台上,大量用户正在增加,并加入该社交网络以结交新朋友和组以分享他们的兴趣。该网络解释了群体,人,组织和其他交互系统之间的关系。在社交网络中,人作为节点,链接作为边,这指定了网络中人之间的关系。每个节点和边在网络中也具有属性。行为者之间的属性和联系是特殊的,并由其他方直接检索,这可能导致不适当的数据。
有几种类型的社交网络可用,例如电话网络,电子邮件网络。但是,近年来,在线社交网络(OSN)在有限的时间内激增并吸引了众多用户。最受欢迎的OSN是Facebook,Twitter和LinkedIn,等等。这些网络通过电子邮件或互联网收集了大量信息。社交网络的服务提供商拥有大量数据,从而有机会分析这些网络以及隐私问题。
近年来,社交网络应用迅速增长,前提是隐私已成为主要问题之一,并在当今的社交数据中引起了广泛关注。这种数据隐私将在两个方面进行区分:
(i)通过网络的标准使用,满足在线社交网络访问控制的独特要求。
(ii)使用已发布的数据,通过向半信任的第三方提供清理数据的方法。
确定了三类隐私威胁以保留社交网络隐私信息:
(i)身份公开,有关每个个人身份的信息与节点一起链接。
(ii)属性公开,在图形中公开顶点敏感标签。它应用于顶点标记的网络。
(iii)链接公开,这是一种属性公开。
它仅公开了两个人之间的敏感或委托连接关系。社交网络上存在各种隐私问题。发布社交网络数据是主要的隐私问题之一,它不能保证其隐私。保护和保证隐私的一种方法是,在社交网络中,无法从任何节点或从图中识别出对方的身份是匿名的,这有可能大于1 / k。因此,对社交网络中的数据进行匿名化是一种流行的方法,并且在保持社交网络数据发布方面更具挑战性。
社交网络中有不同类型的易受攻击,加解密方法是原始数据保护的常见解决方案。即使开发了许多隐私方法,黑客或攻击者也可以基于不同的背景知识来识别个人数据。其中一些是顶点度,邻域,嵌入子图,链接关系和顶点属性。还有另一种新的攻击类型,称为属性配对攻击,它利用节点的属性来推断匿名网络中的身份。在现有方法中,k-couplet anonymity通过使用以下三种方法来实现属性对联攻击下的隐私:排名,属性概括(AG)和属性聚类匿名化(ACA)。在本文中使用因素分析方法来减少针对社交网络中节点的属性配对攻击。
即使在删除了有关个人的敏感信息之后,攻击者仍可以借助他们对剩余属性的有限背景知识以及与网络中称为属性配对攻击的节点对之间的关系的了解,来披露个人数据。考虑一个在原始网络中具有名称和其他属性的社交网络。借助某些属性对的背景信息,可以显示有关用户的信息。让我们假设约翰在社交网络中以属性对({Lawyer,LA},{Doctor,CA})与Mary连接。由于此属性对在原始网络中是唯一的,因此攻击者可以通过匿名网络中的一对属性对({Lawyer,LA},{Doctor,CA})轻松识别John与Mary的关系。
通过用网络中至少k-1个节点中存在的相同对联属性来满足k配对匿名性,可以最小化此属性对。概括网络中的属性是保护网络中敏感标签和属性的另一种方法。
0x02 Literature Review
在好友关系攻击(Friendship attack)中,攻击者使用通过边连接的顶点度对,从而可以重新识别个人。提出了k匿名概念来防止好友关系攻击。
近邻攻击(neighborhood attack),其中与近邻有联系的个人引用邻域。分两步满足k-匿名性概念:邻域分量编码技术-邻域表示和顶点的贪婪组织并使邻域匿名。
邻域对攻击(neighbourhood-pair attack),该攻击使用背景知识作为邻域的结构信息对来识别用户。邻域对中的攻击者比邻域攻击了解更多信息。邻域系数以将邻域信息转换为更简单的查询方式。邻域对攻击也称为顶点识别攻击(vertex-identification attack)。
一种称为共同朋友攻击(mutual friend attack)的攻击模型中,攻击者可以在可用的共同朋友的帮助下重新识别一对朋友。一种保护共同朋友上的新方法称为k-NMF匿名,该方法可确保至少k-1对另一对朋友共享相同数量的共同朋友。该算法维护原始顶点。它还允许通过逐个添加边来在组中添加顶点。但是图中没有删除顶点。这种方法确保了k-NMF在原始社交网络中保留了效用。
针对基于数据挖掘隐私保护的数据掩盖的调查中,有关为数据持有者建立分类模型以发布数据类别以保护推断敏感信息的问题。在每个迭代中,链接中最多存在单个属性的每个代。
一种在属性图中的子图挖掘算法称为MISAGA。它使用概率方法来度量属性对的值,该属性对与属性图中的子图发现问题具有很强的关联性。该算法考虑了边的结构以及与图中连接的节点有关的属性值。
0x03 Methodology
A.因素分析
因素分析的工作原理是将其对数据集庞大项目的主要支配性转化为少量因素。因素的识别取决于数据集项定义的最高相关性。该因素标识的命名取决于数据集中具有最高相关因素的项。此因素分析从相关数据集中删除重复项。因素形成是相互独立的。潜伏的也称为因素,观察到的变量是不同类型的变量。
遵循三个主要步骤进行因素分析:
(i)如果潜在相关性很高,则最初的潜在或因子加载计算以及两个过程主轴因素分解和主成分方法都将给出接近的结果。
(ii)因素轮换:轮换可确保数据集中的所有变量是否在单个因素上具有膨胀的负荷。该旋转可以是旋转因素不相关的正交旋转,也可以是旋转因素相关的倾斜旋转。
(iii)因素得分计算:此计算基于称为回归的方法。因素分析可用于许多研究方向:基因组,确定饮食模式,社交网络等。
用于调查变量是否在不可观察因素方面线性相关的统计过程。用于那些线性函数的参数表示为载荷。每个变量的方差背后的理论方法称为负载,每个变量对和每对变量的协方差称为误差项的方差。
因素分析涉及两个阶段。首先,计算一个载荷集,该加载集根据某些条件提供与观察到的协方差和方差接近的协方差和方差。其次,旋转第一个载荷集以获得与方差和观察到的方差相等但比先前期望更一致的另一个载荷集。
主成分法是最广泛用于第一个载荷集的方法。它试图找到载荷集合的值,使估计值与总的可能观测方差密切相关。如果没有以相同的单位来度量变量,则在将变量应用于主成分方法之前应先对其进行标准化,以使所有变量的均值和方差等于零。
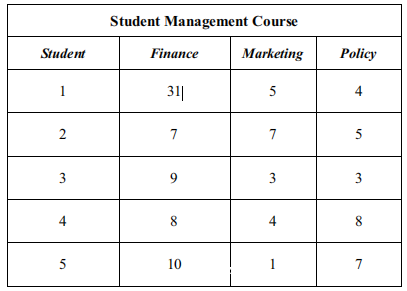
上表中的一个示例说明了因素分析。选择管理计划的学生必须选择金融,商业营销和政策等特定课程。令X1,X2和X3代表学生的课程成绩。以下数据由10分及格以上的5名学生的成绩组成。
令F1和F2为两个因素,可以定义为定量和言语能力。该关系线性表示为:
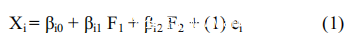
β1和β2在这里称为载荷。误差项e1表示假设关系不精确,以致E(e1)= 0 。
在本文中,因素是Author和 Publication。数据集A和数据集B表示Author和 Publication之间的关系,并且Publication的数量被视为载荷。这些因素在数据集C和数据集D中是相反的,并且在Publication和Author之间形成了关系。反转载荷因素变量,找到计算的平均值和方差,反之亦然。在这里,Author数量构成了载荷。对于数据集中的每个Author和 Publication,下面的两个方程式被表示,忽略了表格中用于计算各个Author和 Publication的均值和方差的每一行。假定的关系为:
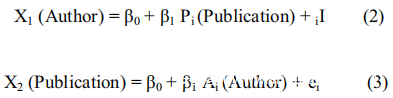
每个Author的Publication统计数据是整个数据集的基础度量。它是通过将数据中所有Author的标识符按发生它们的Publication计数以及每个集群的大小进行聚类计算得出的。这在下表中给出。一份Publication准确显示了数据集中包含的1200位不同Author中的440位(== 37%)。同样,通过保留每组Publication来找到均值和方差,并找到剩余数据集A的计算出的均值和方差。为网络中的Author的Publication计算所有剩余数据集B,C和D的均值和方差。
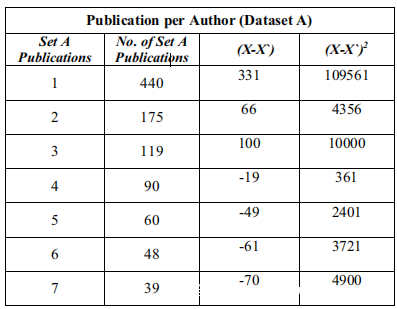
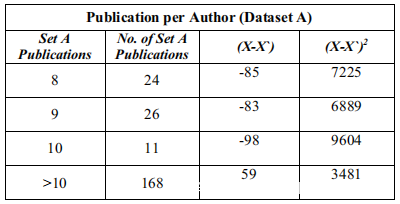
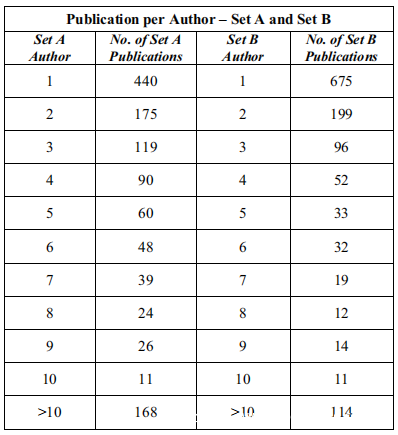
下面的表显示了Author的Publication之间的关系。有四组数据:A,B,C和D组。表III。指每个Author的Publication集A和B。鉴定为“ n”种出版物的Author。
每个Author的发布统计信息是数据集范围的基本度量,方法是将数据集中Author的标识符按存在于它们中的总Publication和每个簇的大小进行聚类。这在上表中给出。要提供表中数据集的第1列中的值,指定该值。数据集中包含的1200个不同Author中的440个(== 37%)由第1列和第2列中的一个Publication准确引用。最初计算集合A和集合B的总体方差。
然后,再次通过以下方式计算集合的方差:删除集合A和集合B中Author的属性。然后计算节点数并找到所有Author的均值。然后与许多Author计算均值偏差的平方和,以找到方差。对于具有确定的Publication且作者为n个Author的集合C和集合D。与Set A和B相似,忽略每个Author和Publication,计算Set C和Set D的均值和方差,并找到下表中存在的整个数据集的剩余均值和方差。
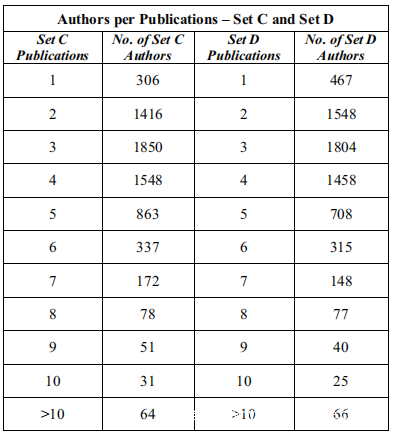
每个Publication的Author统计量示数据集中每个Publication中Author信息的数量。通过按Author对数据集中Publication的总数进行聚类,并按每个聚类的大小进行聚类。表示第三行中的值意味着该数据集中6716个出版物中的1850个(= 28%)有3个Author。
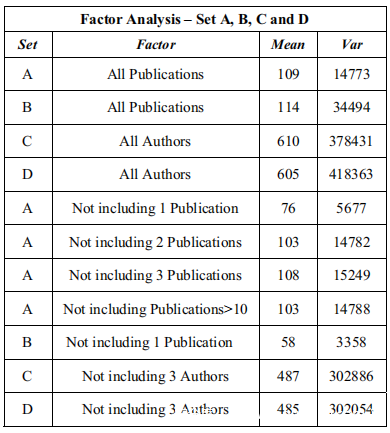
在上面的表(基于每个Author的中Publication、基于每个Publication的Author)中,Author和Publication的数量为n,A,B,C和D四组的因素分析显示在下表及其在数据集中表示的每个Author和每个Publication的计算均值和方差。

0x04 Evaluation
首先使用关键字“Publications per Author”对数据集执行因素分析。在这里,Author以n个Publication标识,n个假设值为1,2,3,4,5,6,7,8,9,10和>10。这显示在集合A中。平均值是109,方差是14773对于为不同Author标识的集合B,总节点为1257,几乎与集合A(1200)相似,均值为114,方差为34494。尽管均值相近,但集合B的方差大于集合B的两倍。对于集合A和集合B,载荷量为Publication数量。
交换Publication和Author时,会发现在集合C和集合D中给出的新数据集。这里的载荷是Author人数。集C的平均值为610,集D的平均值为605,几乎相同。集C的方差为378431,集D的方差为418363,相当接近。
使用因素分析的概念,可以计算所有载荷变化对方差的影响,并且在下面指定的很少,例如Not including 1 publication,Not including 2 publication,Not including 3 publication,最后Not including n> 10。集A的方差为:
No Restrictions:14773
Not including 1 Publication:5677
Not including 2 Publication:14782
Not including 3 Publication:15249
Not including n> 10 :14788。
可以看到,在“Not including 1 Publication”的情况下,方差的影响显示减少了近62%。可以安全地推断出,为减少社交网络中配对攻击的影响,加载“Not including 1 Publication”可以带来预期的效果。将在集A中获得的结果扩展到集B的方差,”Not including 1 Publication“显示出更大的结果。与无限制的总方差相比,减少了近90%。使用条件“不包括3个Author”计算的集合C和集合D的因素分析,均值和方差如下。
可以看到,在”Not including 1 Publication“的情况下,方差的影响显示减少了近62%。可以安全地推断出,为减少社交网络中配对攻击的影响,加载“Not including 1 publication” 可以带来预期的效果。将在集A中获得的结果扩展到集B的方差,“Not including 1 publication” 显示出更大的结果。与“No Restrictions”的总方差相比,减少了近90%。使用条件”Not including 3 Authors”计算的集合C和集合D的因素分析,均值和方差如下。
均值:487和485
方差:302886和302054,与没有限制的原始方差分别减少了20%和28%。
因此,为了在减少社交网络中对节点的配对攻击方面产生更大的影响,使用因素分析的概念,建议使用Publication作为负载因素,最好的是“Not including 1 publication” 。通过将Publication和Author旋转为载荷(不包括n = 1),减少对节点的配对攻击的效率在28%到62%之间。
0x05 Conclution
本文讨论了社交网络中的属性配对攻击。使用关键字“Publications per Author”和“Author per Publications”对数据集实施了因素分析,并计算了数据集的方差。可以看到,在“Not including 1 publication” 的情况下,方差的影响显示减少了近62%。因此,为了在减少对节点的配对攻击方面产生更大的影响,使用因素分析的概念,建议使用Publication作为载荷因素,最好的是“Not including 1 publication” 。
在本文中,因素分析的概念被用于识别可以帮助减少配对攻击对社交网络中的节点的影响的参数。结果可以认真研究这一点,并且通过添加更多因素并修改载荷,通过增强因素分析的应用来清楚地表明进一步增强。







发表评论
您还未登录,请先登录。
登录