

摘要
对各种文件格式的文件碎片(片段)进行分类是防火墙、入侵检测系统、杀毒软件、web内容过滤、数字取证等各种应用程序中必不可少的任务。然而,界内缺乏一种合适的软件工具,能够整合主要方法从文件碎片中提取特征,并在各种文件格式中进行分类。本文介绍的Fragments-Expert是一个用于文件碎片分类的图形用户界面MATLAB工具箱。它为用户提供了22类从文件碎片中提取的特征。这些特征可以被7类机器学习算法所采用,以完成各种文件格式间的分类任务。
关键词:文件类型、文件碎片(片段)、文件碎片分类、基于内容的分类、特征提取、MATLAB
1.介绍
识别文件格式的最快方法是检查文件扩展名。这种方法很不可靠,很容易被欺骗。另一种识别文件格式的方法是通过魔术字节(magic bytes)。魔法字节是存在于文件头中的预定义序列。大多数情况下,审查员处理的是一个文件片段,而不是整个文件本身。因此,检查文件扩展名或魔法字节在实际情况下是没什么作用的。
在许多实际情况下,识别文件片段的文件类型的能力是很必要的。文件片段分类在防火墙、入侵检测系统、反病毒、web内容过滤和数字取证中发挥着重要作用[1]。例如,在网络入侵检测中,文件片段分类被用来过滤掉任何可疑的数据[2,3]。文件片段分类的另一个实际应用是计算机取证和调查。在这种情况下,在给定证据的恢复和检查过程中,检查人员可能会处理一个没有可用文件系统信息的碎片集合[2,4-9]。第三个实际例子是文件恢复过程中,文件系统结构被破坏或删除[10-12]。
该领域的研究项目大多集中在基于内容的文件片段分类上。许多基于内容的文件片段分类的研究项目,提取一些特征,如字节频率分布(BFD)、香农熵、科尔莫戈洛夫(Kolmogorov)复杂度、最长公共子字符串和最长公共子序列[9][13]。然后,利用这些特征训练一个决策机模型(如朴素贝叶斯、k-最近相邻、决策树、随机森林和支持向量机)。在较早的研究项目中,研究人员利用特征阈值比较方案来对碎片的类型进行决策[11,14]。通常,这些基于阈值的方法没有采用任何学习算法。
一些基于内容的方法采用了聚类来达到研究目的。Nguyen等人研究了图像类型数据[15]的识别。他们根据熵的度量将未压缩的分块数据聚类为三类,然后对每一类数据采用基于字节频率分布的决策树。Li等人介绍了三种基于质心模型(centroid models)的算法:单中心点(每种文件类型的对应一个模型)、多中心点(每种文件类型对应多个模型)和示例文件(每种文件类型的文件集)[16]。将每种文件类型的字节频率分布的平均值和标准差作为质心模型。然后,采用Mahalanobis和Manhattan距离来识别文件类型。
有各种用于文件类型识别的商用现成(COTS)软件。这些解决方案大多作为取证或文件恢复工具的一部分。一些著名的COTS工具有LibMagic[17]、TrID[18]、Oracle Outside In Technology[19]、DROID[20]、JHOVE[21]、Autospy[22](使用PhotoRec[23]进行类型检测)、ExifTool[24]、FTK[25]、EnCase[26]、AnalyzeIt[27]和Toolsley[28]。这些软件包依靠signature字节进行文件类型检测。所以,它们不适合文件片段分类。Gopal等人评估了几款软件包的性能。他们报告说,当signature字节丢失时,大多数解决方案都失败了[3]。Konstantinos使用其中的一些恢复工具进行了几次实验。结果表明,当signature字节被改变时,大多数signature字节都对文件格式进行了错误分类[29]。
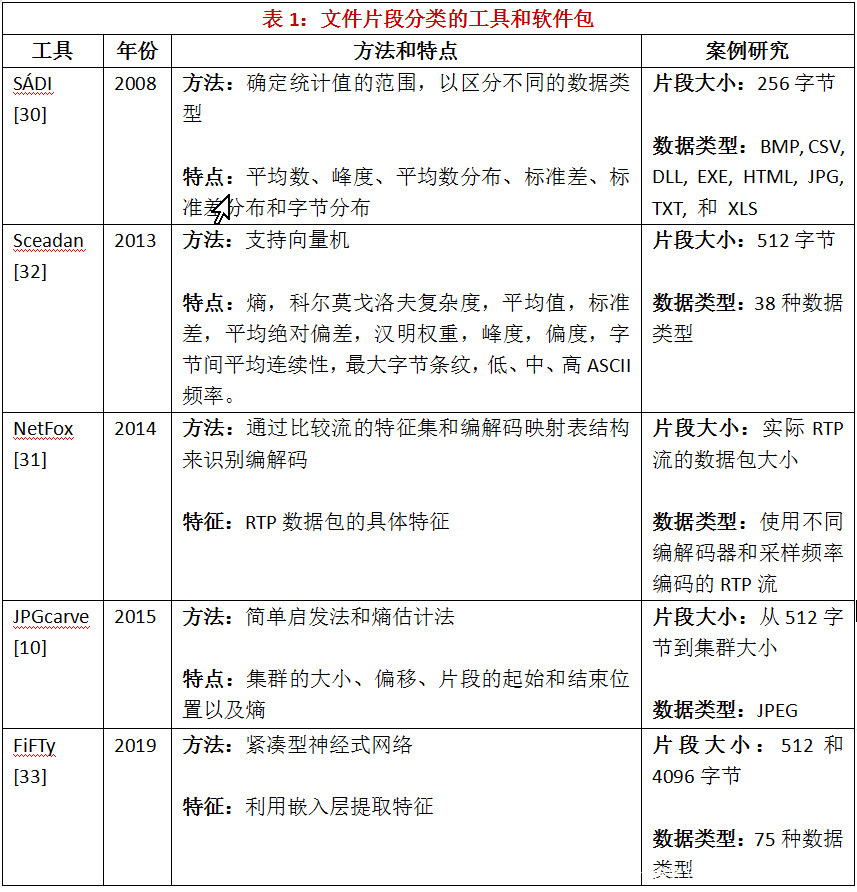
已经开发了一些工具用于文件片段分类。表1显示了这些方法的概要。SÁDI采用的特征数量有限,分类方法简单。该工具为每个文件类型找到每个特征的最小值和最大值[30]。然后,它检查一个实例是否属于这些范围。NetFox是另一个工具箱,它是作为网络取证框架的一部分来实现的。NetFox的一部分具有检测RTP流内编解码器的能力[31]。JPGcarve是一个专门用于从硬盘数据转储中恢复JPG图像的文件雕刻(file carving)工具。该方法依赖于集群大小和在硬盘空间中的位置[10]。它在数据转储中进行搜索空间,利用熵阈值进行识别。一个比较好的开源软件是Sceadan。Sceadan使用SVM和一组统计特征进行识别。作者已经报告了在38种不同文件类型中的准确率为73.4%[32]。一个几乎是新的方法是FiFTy[33],它是一个用于文件类型识别的开源工具。FiFTy使用一个紧凑的神经式网络与嵌入空间进行自动特征提取。作者报告了他们对两种不同片段大小和75种文件类型的结果。
由上可见,这方面的公开计算机代码数量不多,而且大多采用小的特征集和有限的机器学习方法。在本文中,我们将介绍Fragments Expert。Fragments-Expert是一个开源的图形用户界面(GUI)MATLAB工具箱,它试图填补这一空白,为研究人员提供许多文件片段分类领域的特征提取方法和机器学习算法。Fragments-Expert使研究人员能够直接重复使用我们的实现来完成文件片段分类的任务。他们也可以对我们的实现进行适当的修改,以测试采用不同的创新特征的效果。
本文的其余部分安排如下:
在第2节中,我们介绍了文献中广泛使用的22类特征来描述文件碎片。第3节介绍了Fragments-Expert的架构。对于一个使用MATLAB编码的专家用户来说,本节为修改工具箱以实现进一步的功能提供了见解。另一方面,本节可以帮助普通用户了解工具箱的结构。
在第4节,介绍了工具箱的功能。生成片段、特征提取和特征选择在本节中都有介绍。本节中还介绍了可用机器学习方法的训练、测试和交叉验证的过程。本节中还介绍了数据可视化工具。最后,本节解释了加载之前生成的数据集和结果的过程。
第5节提供了一个说明性的例子。这个例子展示了如何在实际问题中运用工具箱功能。
最后,在第6节中,讨论了程序的可行性和局限性。
2.文件片段分类中使用的特征
在本节中,我们将介绍文献中提出的最常见的特征类别。这些特征被包含在Fragments-Expert中。因此,当我们描述这些特征时,我们对实现的选择也会进行解释。
2-1 字节频率分布
这个特征类型会向你展示一个长度为260的向量。前256个值是BFD值。这些值显示了字节值0到255的归一化频率。BFDi是字节值i = 0,1,…,255的归一化频率。
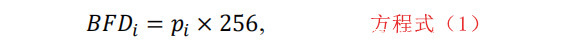
其中pi是每个字节值的估计概率,计算方式为:

其中,fi为第i个字节值的频率,L为该片段的长度,单位为字节。
与BFD一起计算的其他四个特征如下。前三个特征的定义见[9]。
- SdFreq:字节频率的标准偏差。
- ModesFreq:四个最高字节频率之和。
- CorNextFreq:字节值j和j+1的频率相关。
- ChiSq:契合度测试的chi-square goodness是对随机性的一种测量。在这里,我们使用这个测量方法来比较观察到的字节值分布与均匀随机分布。对于每个字节值,我们计算片段中字节值的观察频率与均匀随机分布中字节值的期望频率之间的平方差之和除以期望频率,如下[34]。

然后我们用chi2cdf (T,255,’upper’)命令来计算本次测试的p-value。
2-2 变动率
变动率(RoC)是由文件片段中连续字节值之间差异的绝对值的频率组成的向量。如果我们将长度为L的字节片段用x=[x1,x2,…,xL]来表示,则RoC向量的第j个元素j=1,2,…,L-1,计算如下:
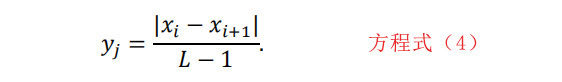
然后对RoC向量的每个元素进行如下归一化处理。

当用户在特征提取过程中包含这种特征类型时,变动率的平均值也被计算为特征。所以,在这种情况下,特征向量是一个长度为257的向量。
2-3 最长的重复字节的连续序列
这个特征是片段中最长的连续重复字节的归一化长度。例如,对于向量[12 123 123 123 43 123 43 43 43 43 43 123 43 76 54 54 54 54],字节值43连续重复了5次。所以,在这种情况下,输出特征是5/18。
2-4 n-grams
在这种情况下,计算长度为n的比特序列的频率。这个功能是针对比特流定义的。因此,首先将字节的片段转换为其等效的二进制形式。作为一个例子,考虑长度为16的二进制向量[1 0 1 1 1 0 0 1 0 1 1 0 1 0 0 0]。要计算这个向量的2-grams,首先,必须计算长度为2的所有可能的0和1的组合。例如,比特模式0 0重复三次。所以,这个模式的归一化2-gram值等于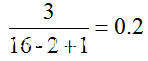 。
。
当您将该特征类型包含在特征提取过程中时,您必须在GUI的下一个窗口中选择n值。你可以输入一个n的整数值的向量,在这种情况下,将计算这个向量中所有值的n-grams。在当前版本中,n值可以是1到13的任何整数值。
2-5字节集中功能
从2-1节中描述的BFD值,计算出三个特征[9]:
- 低:0≤i<32的BFDi值之和
- ASCII:32≤i<128的BFDi值之和
- 高:192≤i<256的BFDi值之和
2-6 基本低阶统计
通过选择该特征类型,计算出以下七种不同的统计数据。首先,计算三种不同的平均值,即算术值、几何值和谐波值,具体如下:

和

此外,标准差(STD)的计算方法如下:
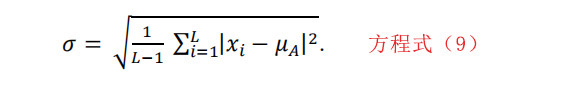
同时还计算了模式值,即x中出现频率最高的值。中间值,即x的所有值的中间值,也被计算出来。最后,MAD值,也就是数值的平均绝对偏差,以平均值(abs(x–mean(x)))计算。
2-7 高阶统计
Fragments-Expert中采用了无偏估计峰度和偏度的方法。峰度估计的计算方法如下:
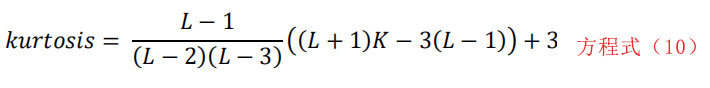
其中K是:
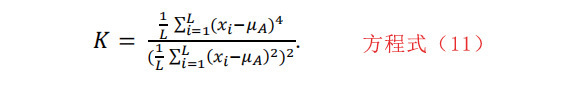
此外,偏度估计的计算方法如下:
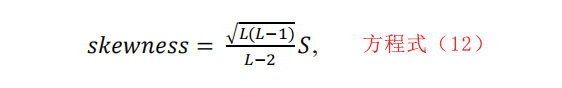
其中S是:
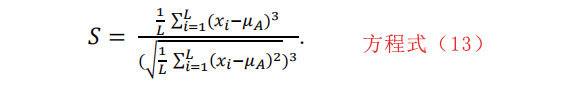
2-8 双相干
双相干是一个高阶统计量,它可以衡量给定字节值片段的非线性和非高斯性。这里我们根据[35]计算了平均双相干性。
2-9 基于窗口(Window)的统计
选择一个窗口大小W。使用非重叠和连续的窗口,从文件片段中的值中获得五个统计量,包括delta移动平均数、delta2移动平均数、delta标准差、delta2标准差和标准差的偏差。
移动平均数的计算方法是取所有窗口中字节值的平均值。如果μj; j= 1,2,…,j=L/W表示第j个窗口中字节值的平均值,则delta移动平均数的计算方法如下所示:
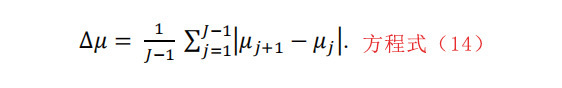
此外,delta2移动平均值的计算方法如下:
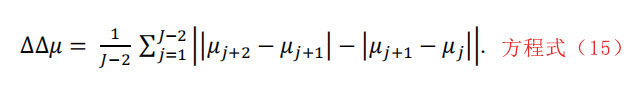
同理,如果σj;j=1,2,…,J表示窗口j中字节值的标准差,delta标准差和delta2标准差分别计算如下:
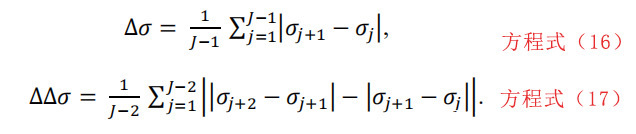
最后,标准差的偏差值计算如下:
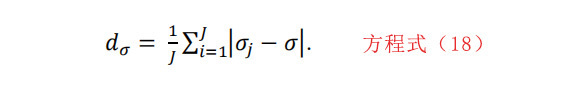
2-10 自相关性
这个特征是输入数据片段在特定滞后值ℓ之前的样本自相关。样本自相关测量的是xt和xt+k之间的相关性,其中k=1,…,ℓ。滞后k的样本自相关是:

其中
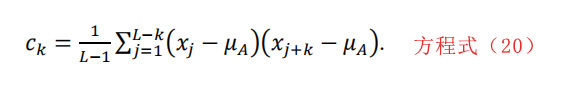
注意,c0 = σ2是片段的样本方差。选择该功能,就必须在GUI的下一个窗口中指定最大滞后值。
2-11 频域统计
根据[13]的定义,一个向量(在此或上下文中,一个片段)的频谱可以被划分为相等的子带,然后提取每个子带的均值、方差和偏离度特征。然后提取每个子带的均值、方差和偏度等特征。例如,如果子带的数量等于4个,则会提取12个频域统计量。您可以将子带的数量从1到8设置。
2-12 二进制比率
二进制比(BRO)的定义来自[14],是在比特流(即片段的等效二进制形式)上计算的。每一个字节值都被转换为8位表示。如果b=[b1,b2,…,b8×L]表示片段的等效二进制形式,则二进制比的定义如下:
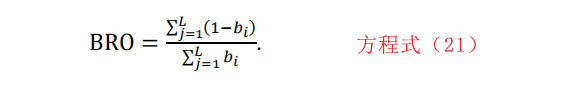
2-13 熵值
在这种情况下,可以得到片段的两个统计量:熵和均匀分布的L-截断熵[37]与得到的熵值之差。
信息理论中的熵可以衡量一个序列的不确定性。在我们的例子中,我们有一个长度为L的片段,香农熵被定义为:
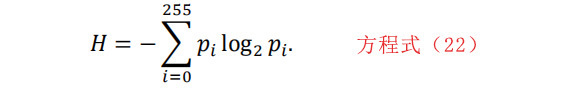
均匀分布的L-截断熵可以近似为[37]:
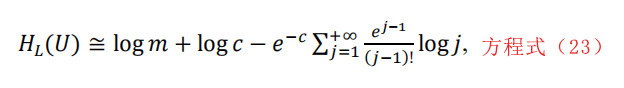
其中,m是可能的字节值的数量(在本例中,是256),c=L/m
2-14 视频模式
一些视频格式在其有效载荷中具有重复的模式。这些模式的出现率可以用来确定文件片段的格式。在这里,我们对这些模式的出现率进行统计,为了使所得的数字与片段的长度和模式的长度无关,我们将其归一化,如下所示:
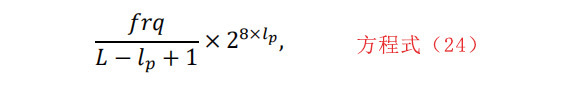
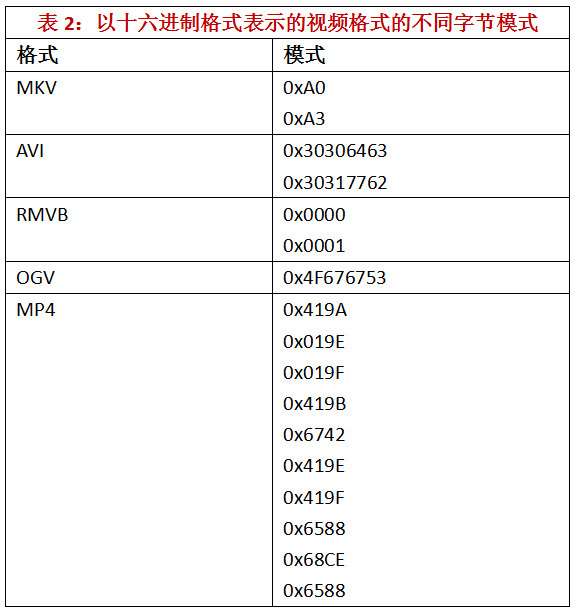
其中frq是该模式在片段中的出现次数,lp是该模式的长度,单位是字节。这里考虑了17种模式。这些图案对应于五种不同的视频格式。因此,在这种情况下,特征向量包含17个归一化模式频率。在表2中,所采用的视频模式被提出。MKV、AVI、RMVB和MP4的模式是在[38]中提出的。
2-15 音频模式
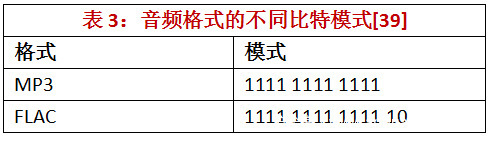
该特征类型计算文件片段中特定音频位模式(即同步字)的归一化频率。首先,每个字节值被转换为8位表示。然后,类似于视频模式的计算,归一化被应用于使出现的计数独立于片段的长度和模式的长度。在表3中,列出了所采用的音频模式。
2-16科尔莫戈洛夫(Kolmogorov)复杂度
一个片段的Kolmogorov复杂度是对指定该片段所需计算资源的衡量。但是,没有一般的算法可以确定这个复杂度。我们采用[40]的方法来估计这个复杂度。为了运行时的速度,这个函数以C-MEX格式编写。
2-17 假最近邻和Lyapunov指数
在Fragments Expert中实现了两个混沌特征假近邻分数(FNF)和Lyapunov指数(LE)。Hicsonmez等人采用混沌特征来识别音频编解码器[13]。混沌特征的概念是基于信号向量的邻域。我们定义信号向量si=[xi,xi+1,…,xi+(D-1)],其中D是相位空间的嵌入维度。两个最近邻之间的距离定义为:
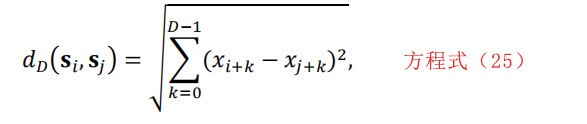
其中sj是si在附近轨迹上的最近邻位。如果dD(si,sj)与dD+1(si,sj)显著不同,则认为si和sj是一对假近邻。在将所有近邻标记为真或假后,将FNF定义为假邻居与所有近邻的比值[13]。因此,我们可以将特征向量FD定义为三个部分:假近邻的分数、邻域的平均大小和邻域的均方根(RMS)大小。
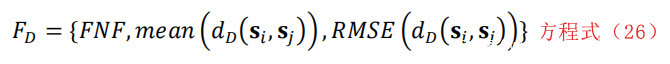
Lyapunov指数是一种量化信号可预测性的混沌特征。LE值越大的系统被称为越不可预测[13]。每个嵌入维度D的LE计算为:
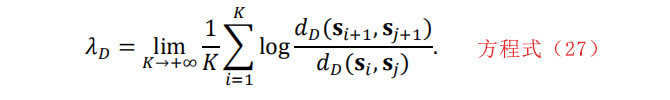
当你选择这个特征类型时,你必须提供三个参数:比值因子,用于确定假近邻,以及嵌入维度的最小值和最大值。为了运行时的速度,该函数以C-MEX格式编写。
2-18 GIST特征
徐明等人表示,一个字节值的向量(即一个片段)可以被重塑为一个矩阵,并视为一个灰度图像[41]。因此,他们采用了在场景和对象分类中表现非常好的 GIST Descriptor[42]。为了将一个片段转化为灰度图像并提取GIST特征,需要设置一些参数。图像行的大小,每个维度上非重叠窗口的数量,我们用M表示,以及每个尺度的方向数。最后一个参数是一个整数值的向量,我们用以下方法表示 [O1,O2,…]。这种类型的特征提取的结果是一个长度为M2∑iOi的特征向量。
2-19 最长公共子串(子字符串)和最长公共子序列
我们将两个片段的最长公共子串定义为两个片段中存在的最长字节模式。一个字节流的子序列是指从原始字节流中删除得到的任何字节序列。据此,我们可以定义两个片段的最长公共子串。
为了定义最长的共同子串和最长的共同子序列特征,我们需要某些片段,这些片段就是calle代表。对于数据集中的每个片段,计算该片段和每个代表之间的最长公共子串和最长公共子序列。当使用这些特征时,你必须选择你想从哪个类中获得代表,以及代表应该在数据集中的什么位置被采取(即从数据集的开始,数据集的结束,或数据集的随机位置)。另外,你必须输入所选类的代表样本数。对应于每个代表类,计算出一个片段的两个特征:最长公共子串的平均长度和最长公共子句的平均长度。为了运行时的速度,该函数以C-MEX格式编写。
2-20质心(中心)模型
使用一类代表,可以获得该类实例的字节频率分布与被调查片段之间的相似性度量。然后可以将相似度的值作为分类的特征。
在Fragments-Expert中,我们已经实现了两种相似度测量:余弦相似度和马哈拉诺比斯(Mahalanobis)距离。当您选择这种特征类型时,您被要求在所有类标签中选择中心点模型的代表类。然后,您必须输入每个类的代表数量以及代表在数据集中的位置。
参数设置好后,计算代表实例的BFD。然后对每个字节的BFD值,计算出平均值和标准差值。这个均值和标准差值就形成了一个中心点模型。通过用μci和σci(i=0,1,…,255)表示代表实例的平均数和标准差BFD值,我们用:计算每个被调查片段的相似度特征。
余弦相似度=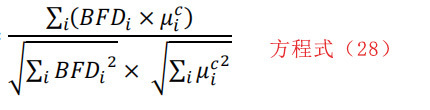
和马哈拉诺比斯距离= 其中BFDi为被检片段中字节值i=0,1,…,255的归一化频率。
其中BFDi为被检片段中字节值i=0,1,…,255的归一化频率。
参考文献:
[1] M. C. Amirani, M. Toorani, and A. Beheshti, “A new approach to content-based file type detection,” in IEEE Symp. Computers and Communications, 2008, pp. 1103-1108.
下略







发表评论
您还未登录,请先登录。
登录