
0x00 前言
在本文中,我将与大家分享如何绕过DOMPurify。DOMPurify是一款常用的HTML过滤库,可以处理(来自用户的)不受信任的HTML片段,删除可能导致XSS的所有元素及属性。
简而言之,最终的绕过方法如下:
<form>
<math><mtext>
</form><form>
<mglyph>
<style></math><img src onerror=alert(1)>
以上代码没有任何冗余元素。为了理解具体的绕过原理,我们需要了解一下HTML规范中的一些有趣功能。
0x01 DOMPurify用法
我们先从基础开始,看一下DOMPurify的通常用法。假设我们在htmlMarkup中包含一段不可信的HTML,并且需要将其赋值给某个div,此时我们可以使用DOMPurify来过滤这段内容,赋值给div:
div.innerHTML = DOMPurify.sanitize(htmlMarkup)
在解析、序列化HTML以及处理DOM树时,这行代码背后实际上会执行如下操作:
1、htmlMarkup被解析成DOM树;
2、DOMPurify过滤DOM树(简而言之,这个过程中DOMPurify会遍历DOM树中的所有元素以及属性,删除不在允许列表中的所有节点);
3、DOM树被序列化回HTML内容;
4、赋值给innerHTML后,浏览器会再次解析HTML内容;
5、经过解析的DOM树会被附加到文档的DOM树中。
来看个简单例子。假设我们初始的内容的A<img src=1 onerror=alert(1)>B。在第1个步骤中,该片段会被解析成如下树结构:

随后,经过DOMPurify过滤后,得到如下DOM树:

序列化后的结果为:
A<img src="1">B
这也是DOMPurify.sanitize的返回结果。随后这段内容会由浏览器再次解析,赋值给innerHTML:

DOM树与DOMPurify处理的DOM树一致,随后会被附加到目标文档中。
因此,以上过程可以按顺序简单总结成:解析->序列化->解析。大家从直觉上会认为DOM树经过序列化、再次解析后,应该会返回初始的DOM树,但事实并非如此。在HTML规范中,关于序列化HTML片段方面有如下警告信息:
这种算法(序列化HTML)的输出结果如果交给HTML解析器进行解析时,则可能不会返回原始的树结构。HTML解析器本身也有可能输出经过序列化、重解析操作后无法复原的树结构,虽然这种情况下通常不符合要求。
这里要划重点的是,这种序列化、重新解析的往复操作并不一定能返回原始的DOM树(这也是造成mutation XSS(突变型XSS)的根源)。通常情况下,这类情况由某些解析器、序列化器的错误而导致,但有两种情况比较特殊,符合上述警告信息所描述的场景。
0x02 嵌套FORM元素
其中有种场景与FORM元素有关。这是HTML中非常特殊的一个元素,该元素无法嵌套到自身中。在HTML规范中,明确说明FORM元素不可以是某个FORM元素的后继:

我们可以使用如下标记语言,通过各种浏览器来验证:
<form id=form1>
INSIDE_FORM1
<form id=form2>
INSIDE_FORM2
这个片段会生成如下DOM树:

第2个form在DOM树中会被完全忽略,就像从来没存在过一样。
接下来是比较有趣的部分。如果我们继续阅读HTML规范,会发现其中给出了一个示例,通过较不规范以及错误嵌套的标记成功创建了一个嵌套式表单。如下所示(直接摘抄自规范文档):
<form id="outer"><div></form><form id="inner"><input>
结果会生成如下DOM树,其中包含一个嵌套式表单元素:

这并不是特定浏览器的bug,直接来自于HTML规范,在解析HTML的算法中也有描述。通常的原理为:
1、当我们打开<form>标签时,浏览器需要使用表单元素指针(标准中就是这么称呼)来记录该标签已被打开。如果该指针不为null,那么form元素就无法被创建。
2、当我们结束<form>标签时,表单元素指针始终会设置为null。
因此,回到这个片段:
<form id="outer"><div></form><form id="inner"><input>
首先,表单元素指针会指向id="outer"的元素,然后开始解析div,碰到</form>结束标签后,表单元素指针会被设置为null。由于指针为null,因此id="inner"的下一个表单可以被创建。由于目前我们位于div内,因此可以成功创建一个嵌套式form。
现在,如果我们尝试序列化生成的DOM树,会得到如下标记语言:
<form id="outer"><div><form id="inner"><input></form></div></form>
需要注意的是,这次其中并没有包含任何错误嵌套的标记。当这个片段再次被解析时,会创建如下DOM树:

以上可以表明,经过序列化、重解析后,我们并不一定能返回原始的DOM树。更有趣的是,这是符合标准的一种突变情况。
当我发现到这一点后,意识到有可能滥用这种特性来绕过HTML过滤器。经过长时间思索后,我偶然发现了在HTML规范中存在另一个异常点。在继续讨论这个问题前,我们先来聊聊HTML规范中我最喜欢的一个潘多拉魔盒:外部内容(foreign content)。
0x03 外部内容
外部内容就像一把瑞士军刀,可以用来破坏解析器及过滤器。我之前曾在DOMPurify的绕过方式以及Ruby过滤库的绕过方式中用过这种方法。
HTML解析器可以使用3个命名空间元素来创建DOM树:
- HTML命名空间(http://www.w3.org/1999/xhtml)
- SVG命名空间(http://www.w3.org/2000/svg)
- MathML命名空间(http://www.w3.org/1998/Math/MathML)
默认情况下,所有元素都位于HTML命名空间中。然而,如果解析器遇到了<svg>或者<math>元素,就会“切换到”SVG以及MathML命名空间。这些命名空间都会产生外部内容。
在外部内容中,标记语言的解析过程与普通的HTML不一样。在解析<style>元素时能更清晰地看到这种不同点。在HTML命名空间中,<style>只能包含文本,没有后继,并且HTML实体不会被解码。而在外部内容中并非如此:外部内容的<style>可以包含子元素,实体也会被解码。
考虑如下标记语言:
<style><a>ABC</style><svg><style><a>ABC
会被解析成如下DOM树:
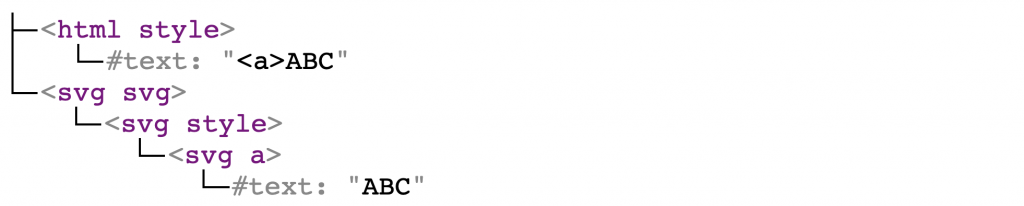
备注:从现在开始,本文中DOM树内的所有元素都将包含一个命名空间。因此,
html style表示HTML命名空间中有个style元素,而svg style表示SVG命名空间中有个<style>元素。
生成的DOM树也验证了我的分析:html style只包含文本内容,而svg style在会像普通元素一样被解析。
继续分析,我们很自然就会猜想:如果我们位于<svg>或者<math>中,那么所有元素也会位于非HTML命名空间中,然而事实并非如此。HTML标准中包含名为MathML text integration point(MathML文本集成点)以及HTML integration point(HTML集成点)的元素,这些元素的子元素都具有HTML命名空间(但某些情况除外,下面我会列出来)。
考虑如下示例:
<style></style>
<mtext><style></style>
以上内容会被解析成如下DOM树:

请注意观察,在MathML命名空间中,style元素是math的直接子元素,而mtext中的style元素则处于HTML命名空间中。这是因为mtext属于MathML文本集成点,因此解析器会切换命名空间。
MathML文本集成点包括:
math mimath momath mnmath ms
HTML集成点包括:
-
math annotation-xml,如果其包含encoding属性,并且属性值等于text/html或者application/xhtml+xml svg foreignObjectsvg descsvg title最后
我曾经坚信MathML文本集成点或者HTML集成点的所有子元素默认情况下都具有HTML命名空间,事实狠狠打了我的脸。HTML规范指出,默认情况下,MathML文本集成点的子元素都位于HTML命名空间中,但有两种情况除外:mglyph以及malignmark。只有当这两者是MathML文本集成点的直接子元素时才会触发例外情况。
来考虑如下标记语言:
<mtext>
<mglyph></mglyph>
<a><mglyph>

请注意,mglyph为mtext的直接子元素,位于MathML命名空间中,而另一个mglyph则为html的子元素,位于HTML命名空间中。
假设我们面对的是一个“当前元素”,想确定其命名空间。此时我已经制定了一些经验法则:
1、当前元素位于其父元素的命名空间中,除非满足如下条件。
2、如果当前元素为<svg>或者<math>,并且其父元素位于HTML命名空间中,那么当前元素则位于SVG或者MathML命名空间中。
3、如果父元素或者当前元素为HTML集成点,那么除非当前元素为<svg>或者<math>,否则将位于HTML命名空间中。
4、如果父元素或者当前元素为MathML集成点,那么除非当前元素为<svg>、<math>、<mglyph>或者<malignmark>,否则将位于HTML命名空间中。
5、如果当前元素为<b>、<big>、<blockquote>、<body>、<br>、<center>、<code>、<dd>、<div>、<dl>、<dt>、<em>、<embed>、<h1>、<h2>、<h3>、<h4>、<h5>、<h6>、<head>、<hr>、<i>、<img>、<li>、<listing>、<menu>、<meta>、<nobr>、<ol>、<p>、<pre>、<ruby>、<s>、<small>、<span>、<strong>、<strike>、<sub>、<sup>、<table>、<tt>、<u>、<ul>、<var>或者<font>,并且定义了color、face或者size属性,那么栈上的所有元素都会被闭合,直至碰到MathML文本集成点、HTML集成点或者HTML命名空间中的元素为止。然后,当前元素也会位于HTML命名空间中。
当我在HTML规范中找到mglyph这个瑰宝时,马上就意识到这是滥用html form突变来绕过过滤器的绝佳方法。
0x04 绕过DOMPurify
现在让我们回到绕过DOMPurify的payload上来:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
这个payload用到了错误嵌套的html form元素,也包含mglyph元素,会生成如下DOM树:

这个DOM树人畜无害,所有元素都位于DOMPurify的允许列表中。要注意的是,mglyph位于HTML命名空间中,而看上去像是XSS的payload则是html style中的一个文本。由于这里有个嵌套html form,因此在重解析时会出现突变。
因此这里DOMPurify不会执行任何操作,会返回经过序列化的HTML:
<form><math><mtext><form><mglyph><style></math><img src onerror=alert(1)></style></mglyph></form></mtext></math></form>
这个片段包含嵌套form标签,因此当被赋值给innerHTML时,会被解析成如下DOM树:

因此现在第二个html form没有被创建,mglyph为mtext的直接子元素,意味着其位于MathML命名空间中。因此,style同样位于MathML命名空间中,其内容也不会被当成文本来解析。随后,</math>会闭合<math>元素,现在img会在HTML命名空间中创建,导致XSS。
0x05 总结
总结一下,这种绕过方式主要结合了以下几点:
1、DOMPurify的典型使用场景导致HTML标记语言被解析两次。
2、HTML规范中包含特殊情况,可以用来创建嵌套form元素。然而在重新解析时,第二个form会被忽略。
3、mglyph以及malignmark是HTML标准中的特殊元素。如果这两者为MathML文本集成点的直接子元素,那么即使其他标签默认情况下位于HTML命名空间中,这两者也将处于MathML命名空间中。
4、结合上述几点,我们可以创建一段标记语言,其中包含2个form元素以及初始位于HTML命名空间的mglyph元素,在重新解析时,后者将位于MathML命名空间中,使后续的style标签采用不同方式解析,导致XSS。
当Cure53针对我的绕过方式进行更新后,大家又找到了另一种绕过方式:
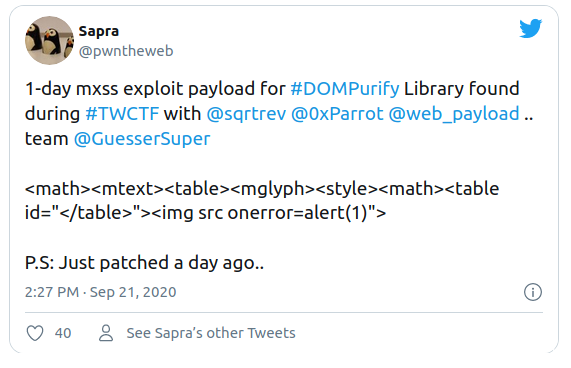
大家可以研究下为什么这个payload能行之有效。我提示一下:其原理与我在本文中找到的bug一样。
这种绕过方式也让我意识到,如下模式很容易造成XSS突变:
div.innerHTML = DOMPurify.sanitize(html)
这由整体的设计思路所决定,因此找到另一个例子也只是时间问题。这里我强烈建议大家在使用DOMPurify时,传入RETURN_DOM或者RETURN_DOM_FRAGMENT选项,这样就不会执行序列化、再解析的过程。







发表评论
您还未登录,请先登录。
登录