

3 工具箱架构
图1显示了Fragments Expert的四大模块:片段生成、特征提取/选择、碎片分类和数据可视化。在每个模块中,都提供了多种工具,方便研究人员考察不同特征类型和分类方法的效果。
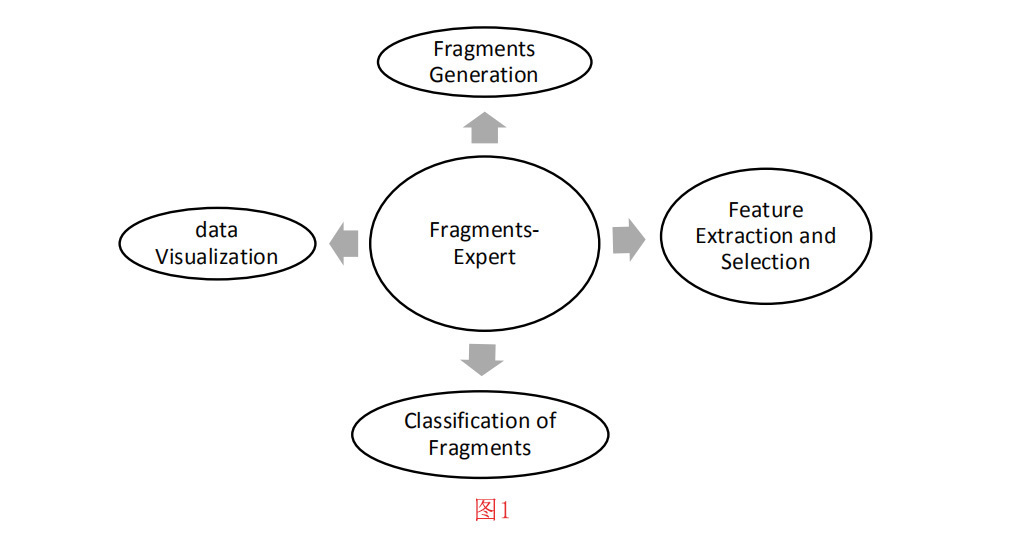
- 片段生成:使用Fragments-Expert,您可以从原始多媒体文件中生成具有特定参数的片段。此过程将在第4-1节中解释。
- 特征提取/选择:大多数常见的特征类型在Fragments-Expert中都有。在第4-2节中,介绍了生成特征的数据集。将在第2节中讨论这些特征的细节。在4-3节中,讨论了为已经训练好的决策机生成数据集。Fragments-Experts中还实现了两种常见的特征选择算法,这将在4-4节中进行了描述。Fragments-Expert中还提供了对数据集的各种操作(如数据集的随机化)。这些操作将在4- 5节中解释。
- 片段的分类:为了将文件碎片分类为文件格式,用户可以采用各种常见的机器学习方法。每个方法都提供了训练、测试和交叉验证。训练、测试和交叉验证的过程分别在第4-6、4-7和4-8节中解释。
- 数据可视化:本模块提供了一些可视化数据示例的工具。可视化工具将在第4-9节中解释。
从图2中可以看出,工具箱源文件夹包括7个子文件夹和一个名为Main_FFC.m的mfile,通过运行Main_FFC,将打开工具箱的GUI。所有工具箱的功能都可以通过这个GUI来实现。这些功能将在第4节中讨论。普通用户只需要与这个图形用户界面进行交互。
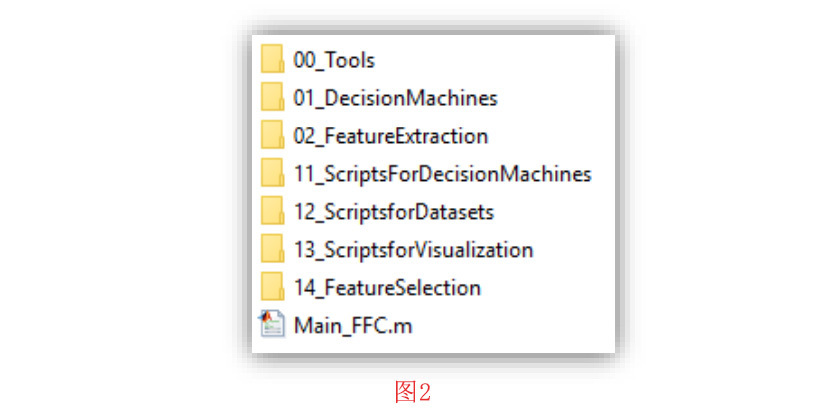
工具箱源文件夹中的七个子文件夹如下。了解这些子文件夹的结构,有助于MATLAB的专家用户对工具箱进行进一步的功能修改。
00_Tools:这个子文件夹包含各种工具。这些工具如下:
- 这类工具中,有一类被称为 “数据集工具”,是提供数据集加载、扩展、随机排列和分区等功能的工具。此外,合并数据集中的标签或从数据集中提取子数据集的工具也在这些工具之列。另一个工具是用于将数据集中的特征扩展到一个范围的工具。
- 另一类工具称为 “决策机器工具”,是提供加载决策机器功能的工具,同时也提供决策机器的测试和交叉验证结果。这一类工具中的另外两个工具是用于构建分类结果的混淆矩阵的工具,也是将混淆矩阵的行缩放为百分比值的工具。另一个工具是根据加权策略给数据集的样本分配权重的工具。
- 另一类工具是 “文件和片段工具”。这类工具可以帮助确定给定文件夹中子文件夹和文件的数量,以及 以及它们的名称和大小。此外,还有一个有用的工具,它被写成一个m-file。命名为TakeRandomFragments_FFC,实现了这个函数的功能。从文件中提取随机片段。另一个有用的工具,它是由 作为一个名为SetVariableNames_FFC的mfile,提供了一个GUI来指导。用户将有效的MATLAB变量名分配给一组标签。
- 另一类工具称为 “用户界面工具”,是为工具箱GUI提供功能的工具,如显示决策机器、展示交叉验证和测试结果、从用户处获取可调参数的值、检查用户对参数的赋值等。
01_DecisionMachines:该文件夹包含了用于训练和测试七种决策机器模型的各种函数:决策树、支持向量机(SVM)、随机森林、集合k-最近邻(k-NN)、线性判别分析(LDA)、朴素贝叶斯和神经网络。这些功能采用MATLAB机器学习工具箱,为文件片段提供简单的、随时可用的功能。的分类。换句话说,学习算法的核心是取自于 MATLAB机器学习工具箱,为了方便用户,参数设置为在Fragments-Expert的图形用户界面内。
02_FeatureExtraction: 这个文件夹包含了第2节中描述的用于提取特征的函数。如前所述,为了提高运行时的速度,其中一些函数是以C-MEX格式编写的。这些特征被分为九个子类别,分别位于九个子文件夹中,具体如下:
- 低阶统计:基本低阶统计(第2-6节所述)、基于窗口的统计(第2-9节所述)和自相关(第2-10节所述)属于这一类。
- 高阶统计:这些特征在第2-7节中描述。
- 频域特征:这些特征在第2-11节和第2-8节中描述。
- 二进制模式:音频模式和n-grams是这一类的特征类型。这些特征分别在第2-15节和第2-4节中描述。
- 字节分布特点:BFD、RoC、重复字节的最长连续条纹和字节集中特征是这一类的特征类型。这些特征在第2-1、2-2、2-3和2-5节中描述。
- 字节模式:第2-14节中介绍的视频模式属于这一类。
- 随机性特征:二进制比率、熵、假最近邻、Lyapunov指数和Kolmogorov复杂性是这一类的特征类型。这些特征在第2-12、2-13、2-17和2-16节中描述。
- 相似性特征:最长公共子串、最长公共子序列和质心模型是这一类的特征类型。这些特征在2-19节和2-20节中描述。
- 纹理特征:这些特征在第2-18节中描述。
11_ScriptsForDecisionMachines:这个子文件夹包含了用于训练、测试和交叉验证决策机器的MATLAB脚本文件。这个子文件夹包含用于决策机器训练、测试和交叉验证的MATLAB脚本文件。这些脚本是由GUI回调函数调用的。此外,用于加载决策机器的脚本以及决策机器的测试和交叉验证结果也放在这个文件夹中。
12_ScriptsforDatasets:这个子文件夹包含用于生成和处理数据集的MATLAB脚本文件,其中包括从原始多媒体文件中生成片段,生成特征数据集,为先前训练的决策机器生成特征数据集,以及加载先前生成的数据集。另外,用于扩展、随机排列和分割数据集的脚本也放在这个子文件夹中。此外,合并数据集中的标签或从数据集中提取子数据集的脚本也可以放在这个子文件夹中。所有这些脚本都可以从 GUI回调功能。
13_ScriptsforVisualization:这个子文件夹包含两个MATLAB脚本文件。这些脚本是由GUI回调函数调用的。这些脚本的细节在第4-9节中介绍。
- 脚本 Script_Plot_FeatureHistogram_FFC 绘制一个或多个样本类的特征值直方图。
- 脚本Script_Plot_Samples_in_FeatureSpace_FFC显示数据样本在二维(2-D)或三维(3-D)特征空间的分布。
14_FeatureSelection:这个子文件夹包含两个MATLAB脚本文件。这些脚本也是从GUI回调函数中调用的。这些脚本的细节在第4-4节中展示。
- 脚本Script_SequentialForward_FeatureSelection_FFC实现了一个连续的前向特征选择策略。
- 脚本Script_SequentialForward_FeatureSelection_FFC利用决策树模型实现了嵌入式特征选择策略。
4 工具箱功能
运行Main_FFC,就会打开Fragments-Expert的GUI。GUI的整体外观如图3所示。在下面的小节中,我们将介绍工具箱的功能。所有这些功能都可以从设计的GUI中获得。

4-1 生成文件碎片的数据集
要从原始多媒体文件中提取片段,点击 “数据集 “菜单中的 “将原始多媒体转换为片段数据集 “子菜单。通过点击该项,将打开一个新窗口,如图4所示。在这个阶段,你应该选择生成片段的参数,如下所示。

- 第一个输入是一个整数(或整数向量),以字节为单位表示生成的片段大小。如果你指定了一个向量,生成的片段长度是随机的,并且独立于这个向量。
- 第二个输入决定了从文件开始的片段中应该被丢弃的百分比。
- 第三个输入决定了文件末尾应被丢弃的片段的百分比。
- 最后一个输入是指从每个文件中获取的最大片段数。
填入参数并点击 “确定 “按钮后,系统会提示你选择包含多媒体文件的主文件夹。注意,这应该是包含一些文件夹的目录,原始文件就存放在这个目录中。假设每个子文件夹中的文件类型都是一样的。之后,您必须选择您想要存储片段的文件夹。注意,您选择的第二个文件夹不应该是第一个文件夹的子文件夹。换句话说,您必须选择一个完全不同的目录,否则该操作将是 终止。之后,开始生成文件碎片。对应于每个子文件夹,会有一个 创建了以.dat为扩展名的通用二进制数据文件,该文件包含了来自于 该子文件夹的文件。每个类(即每个子文件夹)的片段总数是 显示在工具箱的主文本窗口中。
数据集的生成和操作是Fragments-Expert的主要能力。您可以以通用二进制数据文件的形式从原始多媒体文件中生成一个碎片数据集。之后,这些二进制文件可以用来生成文件片段特征的数据集。工具箱中提供了许多特征类型,包括所有常用的特征。你也可以为已经训练好的决策机器生成一个数据集。
4-2 生成特征数据集
要从通用二进制数据文件生成特征数据集,请点击 “Dataset “菜单中的 “从通用二进制文件的片段生成数据集Generate Dataset from Generic Binary Files of Fragments “子菜单。在下一个窗口中,特征类型列表显示如下。
- Byte Frequency Distribution字节频率分布
- Rate of Change变化率
- Longest Contiguous Streak of Repeating Bytes最长的重复字节的连续序列
- n–grams
- Byte Concentration Features: Low, ASCII, and High字节集中功能:低、ASCII和高
- Basic Lower-Order Statistics: Mean, STD, Mode, Median, and MAD基本低阶统计:平均数、STD、模式、中位数和MAD。
- Higher-Order Statistics: Kurtosis and Skewness 高阶统计:峰度和偏度
- Bicoherence双相干性
- Window-Based Statistics基于窗口的统计
- Auto-Correlation自动相关
- Frequency Domain Statistics (Mean, STD, Skewness)频域统计(平均数、STD、偏度)
- Binary Ratio二进制比率
- Entropy熵
- Video Patterns视频模式
- Audio Patterns音频模式
- Kolmogorov Complexity卡尔莫哥洛夫复杂度
- False Nearest Neighbors假的最近邻
- Lyapunov Exponents李雅普·诺夫指数
- GIST特点
- Longest Common Subsequence最长共同序列
- Longest Common Substring最长通用子串
- Centroid Model质心模型
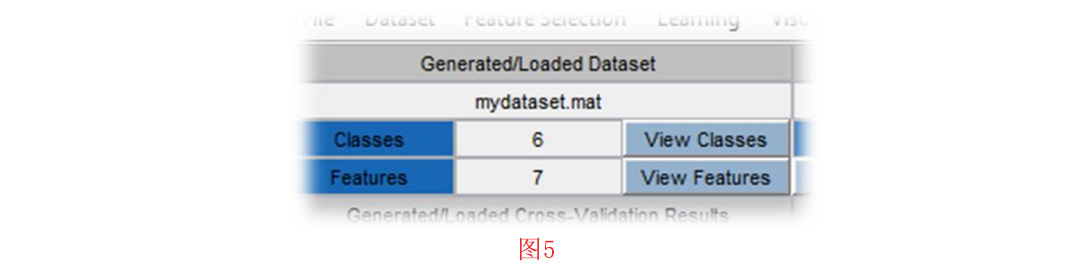
从显示的列表中,选择您要从片段中提取的特征。您可以使用Ctrl键从列表中进行多选。之后,点击 “确定 “按钮。如果您选择的特征需要任何参数,将打开另一个窗口来填写参数。然后您必须选择包含片段的通用二进制数据文件。每个.dat格式的文件代表一个类别(即一个类标签)。在读取片段的过程中,会显示一个进度条。读取片段后,工具箱希望您确认对应于类标签的变量名称。在这里,您可以为每个类别选择任何需要的名称。确认名称后,开始特征提取过程。一旦,这个过程完成,你应该保存生成的特征数据集。该数据集将在工具箱环境中的 “Generated/Loaded Dataset生成/加载的数据集”部分下加载(见图5);从那里,你可以查看类和特征。每个类中的数据样本数等同于 相应的.dat文件中的片段数量。
4-3 为决策机器生成数据集
你可能有一个之前训练过的决策机,现在你想生成一个新的数据集,使其特征集与这个已经训练过的决策机相匹配。要做到这一点,首先必须在工具箱中加载之前训练好的机器(见第4-10节)。然后点击 “Dataset “菜单中的 “Generate Dataset (for Decision Machine) from Generic Binary Files of Fragments “子菜单。
接下来的步骤与第4-2节中解释的步骤很相似;只不过现在你不需要选择任何特征类型。数据集是自动生成的,然后,在保存到磁盘上后,它被加载到工具箱环境中。
4-4 特征选择
当你创建一个特征数据集时,你可能会有很多特征,其中大部分可能在分类过程中是无用的。在训练决策机器时,为了获得更多的相关特征,以及实现更少的计算成本,我们需要采用一些特征选择方法。有时,作为该领域的专家,你可以确定对您的分类场景贡献最大的特性。然而,手动选择特征可能非常困难或耗时。在Fragments-Expert中,我们已经实现了两个有用且简单的特征提取方法。
嵌入式方法
嵌入式方法是指在训练阶段选择特征的技术。学习算法本身选择特征作为学习的一个步骤。最典型的嵌入式方法是决策树。
在每一个训练步骤中,决策树都会根据优度度量选择最佳特征。所以,当我们在经过训练的树中越往上走,决策就会基于更多的相关而得出。我们可以利用这个特性,把决策树变成一个特征选择器。
要使用这种方法,首先,必须在工具箱中加载数据集(见第4-10节)。然后 点击 “Feature Selection “菜单中的 “Embedded: Decision Tree “子菜单。因为您要训练一棵决策树,你必须输入与第4-6节中描述的参数类似的参数。设置好参数并完成训练阶段后,您将看到一个根据相对节点大小排序的选定特征列表。您可以在这些特性中进行选择。最后,在将新特性集保存到磁盘后,其会被创建并加载到工具箱中。
封装方法
封装方法通过特征集的不同可能子集进行搜索。这些方法通过学习算法的准确性来评估每个子集。请注意,对于大型问题,这种方法非常耗时。
在 Fragments-Expert 中,我们采用了 LDA 作为这类特征选择方法的核心学习算法。要应用这种方法,首先在工具箱环境中加载数据集。然后,点击“Feature Selection”菜单中的“Wrapper: Sequential Forward Selection with LDA”子菜单。在正向选择场景中,LDA与交叉验证一起用于选择特征。要了解LDA和交叉验证,请参考以下 4-6节和4-8节的内容。在特征选择过程中,在工具箱中列出所包含的特征和相应的精度。流程完成后,您看到所选特征的列表。您可以在这些特征中选择最终选定的特征。
4-5 数据集的操作
在Fragments-Expert环境中,你可以对数据集应用一些操作,包括数据集中样本的随机排列、合并两个数据集、合并数据集内的类标签,以及从数据集生成子数据集。
数据集的随机排列
这个过程将数据集中的样本随机排列。每个样本都包含描述特定片段的特征。请注意,排列的方式是以单个文件的片段保持在一起的方式进行的。
要对数据集中的样本进行重新排列,首先,必须在工具箱中加载数据集。接着,你应该点击 “Dataset “菜单中的 “Random Permutation of Dataset “子菜单。然后,你必须保存被篡改的数据集。
合并两个数据集
Fragments-Expert的这一部分可以帮助您将特征添加到已经创建的数据集中。在这种情况下,必须在工具箱中加载具有相同片段的新特征集的数据集。要将这个加载的数据集的特征添加到已经保存的数据集中,点击 “Dataset “菜单中的 “Expand Dataset “子菜单。然后你必须选择旧的数据集。请注意,两个数据集必须有匹配的数据集大小、输出标签和文件标识符。
合并数据集中的标签
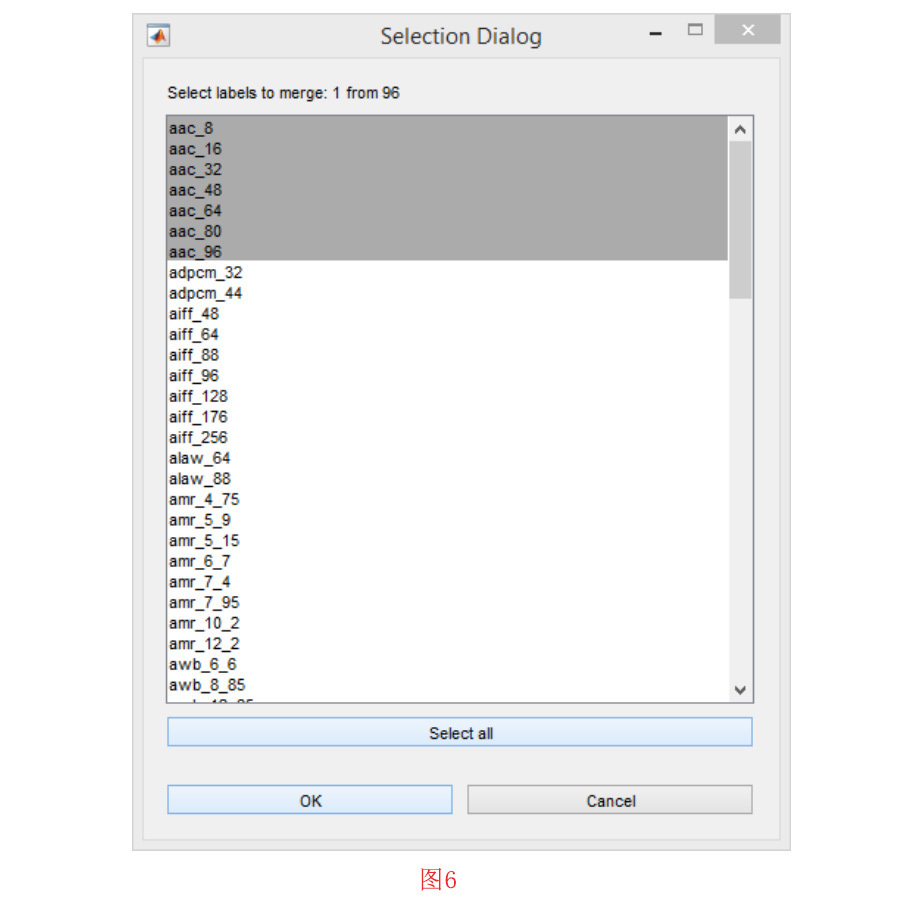
有时,您可能希望合并数据集中的标签,以形成更通用的类标签。要做到这一点,必须先加载数据集。然后点击 “Dataset “菜单中的 “Merge Labels in Dataset “子菜单。这时会打开一个窗口。在那里,你可以多选要合并标签的类。如果需要对其他类进行合并,请点击“确定”按钮,如果不需要,请点击 “取消 “按钮。在图6中展示了一个例子。在这个例子中,我们是将不同比特率的AAC编解码器样本合并成一个通用标签AAC。经过选择合并的标签,需要确认合并后的类的标签。在图7中举了一个示例。
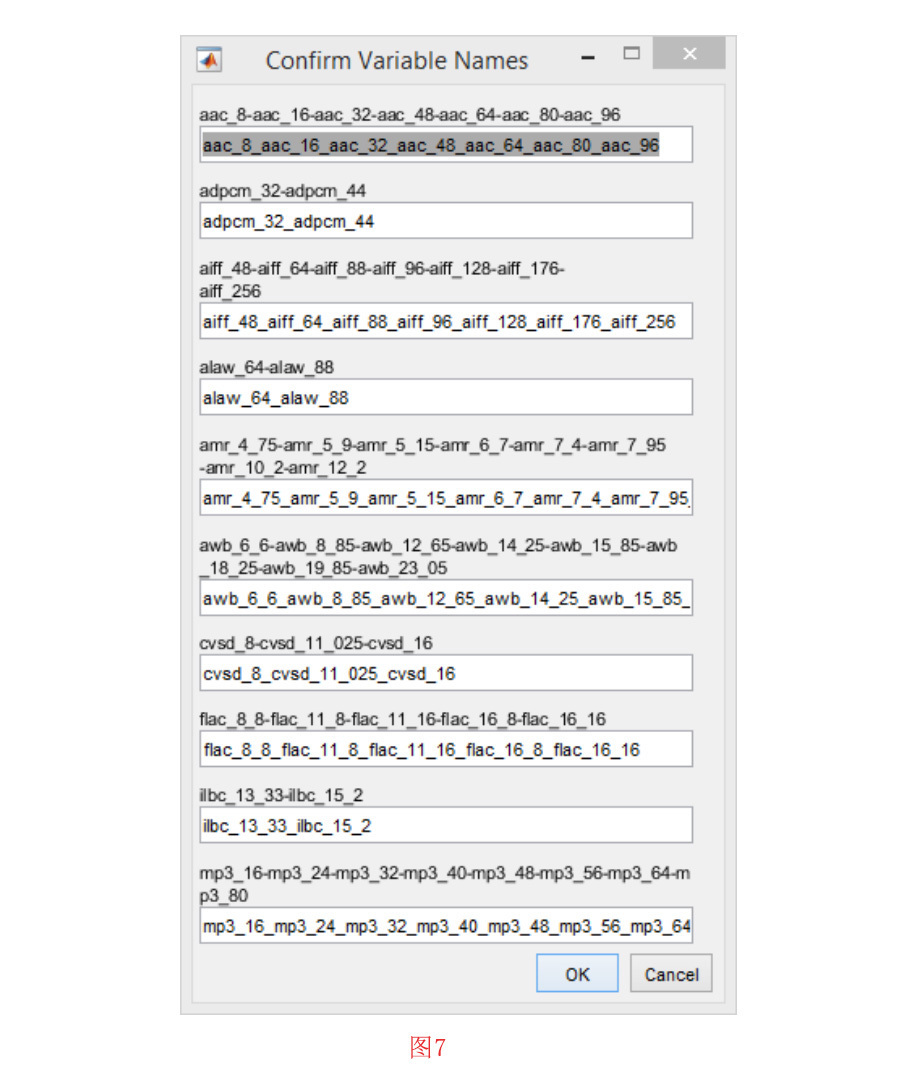
从数据集生成子数据集
Fragments-Expert的这个功能可以帮助您选择数据集类和/或特征的子集。当原始数据集加载完毕后,点击 “Dataset”菜单中的 “Select Sub-Dataset “子菜单。在下一个窗口中,你可以多选你想保留的类。然后,你可以在特征中进行选择。对于类和特征,如果你想保留所有的类和特征,请选择全部。
4-6 训练文件碎片分类的决策机器
使用Fragments-Expert,您可以在您的数据集上应用几种机器学习算法和方法。你可以训练、测试和交叉验证一个模型。目前可用的机器有决策树、SVM、随机森林、合集k-NN、线性判别分析、朴素贝叶斯和神经网络。在下面的章节中,将详细介绍。
要训练一个决策模型,首先必须在工具箱环境中加载你的数据集。然后,你应该点击 “Learning “菜单中的 “Train Decision Machine “子菜单。在下一个窗口中,你应该在决策机器中选择一个决策模型。选择决策模型后,你必须提供一些参数。对于每个模型,都会设置一些默认的参数。但是,你可能希望将它们修改为最适合你实验的参数。
所有决策机器都需要三个一般参数:
- 加权法:该参数决定是否应考虑每个类标签的实例频率。如果选择 “balancedˮ “的加权方法,则样本权重的设置意味着所有类在学习过程中的重要性相似。另一方面,如果选择加权方法 “uniformˮ,则样本数量较多的类被认为是更重要的类。
- 数据集中的训练/验证的开始和结束:这个参数是一个长度为2的向量,元素范围为[0 1],决定数据集中训练/验证开始和结束的相对位置。注意,0对应于数据集中的第一个样本,1对应于数据集中的最后一个样本。
- 从数据集中提取的训练和验证百分比:这个参数是一个长度为2的向量,元素总和等于100。第一个元素决定了训练/验证集中训练数据的百分比。根据工具箱的设置,至少70%的训练/验证集应专门用于训练阶段。
对于大多数决策模型,还提示了特征缩放的方法。缩放方法可以是标准化(也叫z-score),也可以是最小-最大标准化。假设我们在训练阶段有S个样本,其中每个样本都被定义为F。例如,假设fi,j;j =1,2,…,S是所有样本上特征fi;i =1,2,…,F的值。如果我们用fi,j来表示缩放后的特征值,对于z-score缩放,我们可以得到:
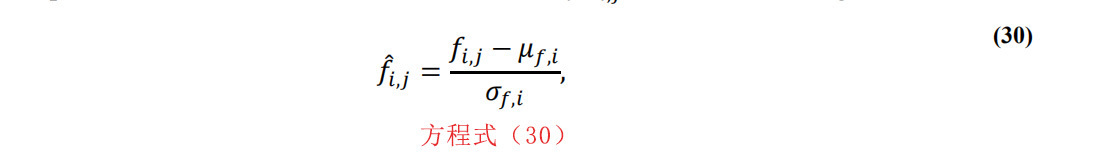
其中μf,i和σf,i分别为值fi,j;j=1,2,…,S的均值和标准差,此外,对于最小-最大归一化,我们可以得到:
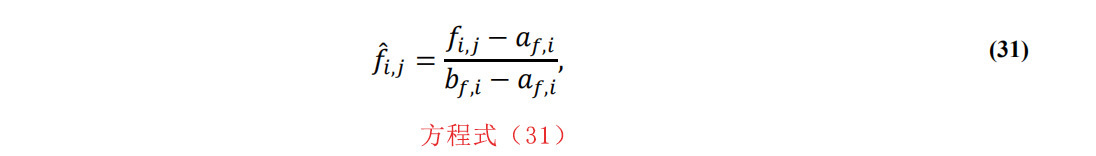
其中af,i和bf,i分别为fi,j;j=1,2,…,S中的最小值和最大值。
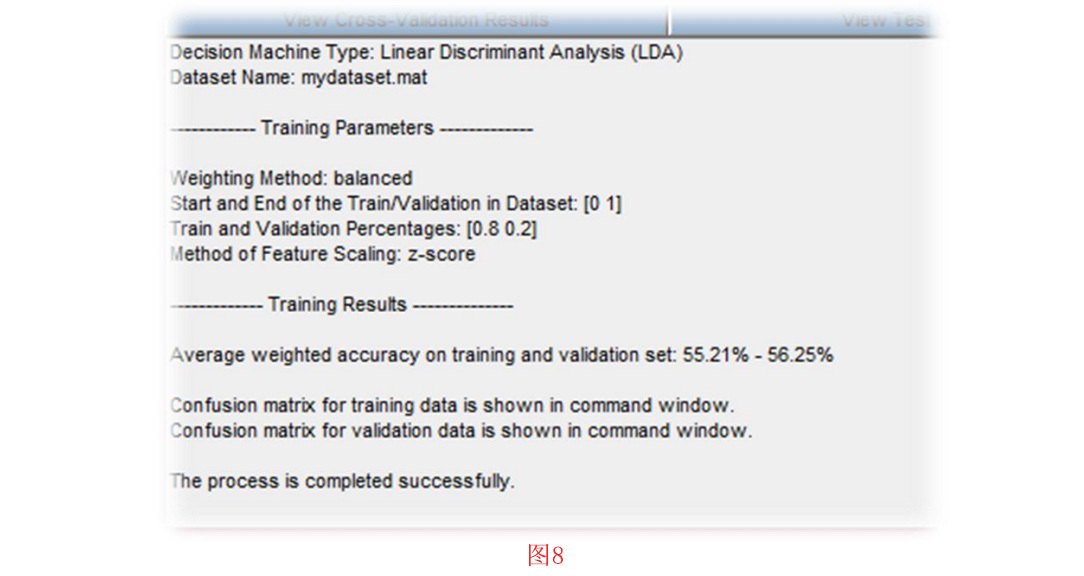
设置好所有的训练参数后,按 “确定 “键,会有一个进度条显示训练过程的进度和剩余时间。训练阶段结束后,将已训练的模型加载到工具箱环境中。同时,训练参数和结果显示在工具箱的主文本窗口中。用于训练和验证的混淆矩阵也显示在命令窗口中。图8显示了 LDA决策模型的示例结果。
训练决策树
要训练一棵决策树,除了一般参数外,还需要输入叶节点观察值占总样本的最小相对数。然后将这个相对数乘以训练集的大小。结果就是每个叶的最小观察次数。需要注意的是,决策树的验证百分比至少要达到15%。
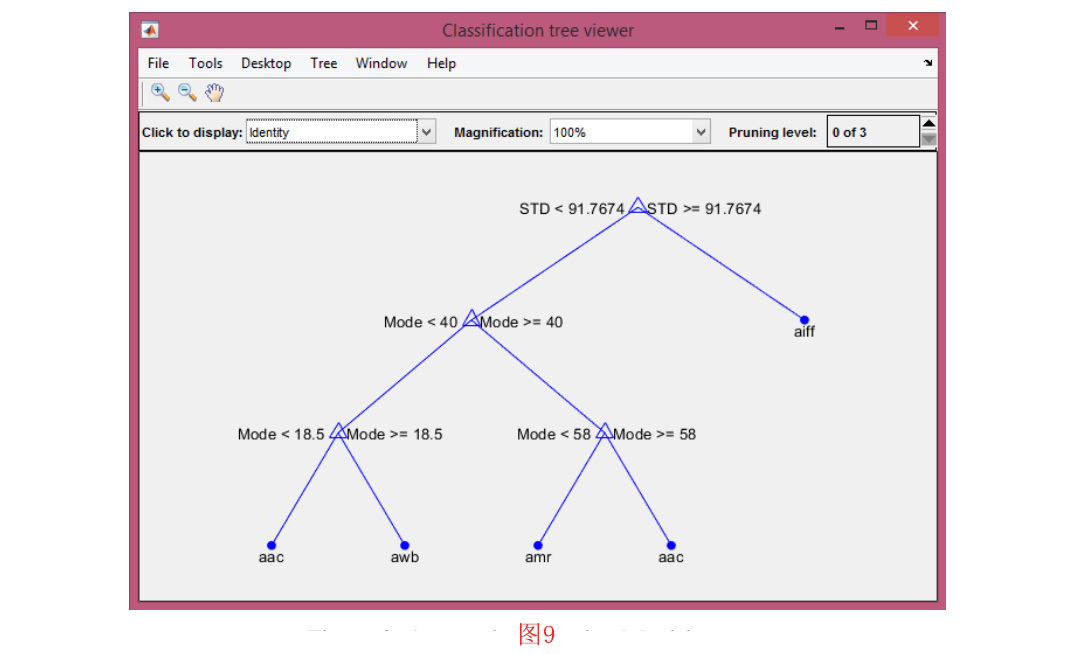
训练完成后,会打开一个图窗口,显示经过训练的树。同时,会提示你保存经过训练的模型。在图9中显示了一个示例。
训练一个多类支持向量机分类器
在Fragments-Expert中,多类SVM分类器的训练采用的是运用基于一对多(one-versus-all)策略,即每个类训练一个二进制分类器。要训练一个多类SVM,除了一般参数外,还需要提供一些其他参数。这些参数如下:
- SVM中框式约束的值:这个数字应该是一个正实数。
- SVM的内核函数:你可以选择rbf,线性或多项式。
- 多项式核函数的多项式次方:这个数字用q表示,应该是1到7的整数。
- SVM的尺度核的值:这个数字用c表示,应该是一个正实数。
SVM算法为训练数据中的每个观察值分配一个框式约束。框式约束是一个参数,控制对违反边际的观察值施加的最大惩罚。核函数用于计算Gram矩阵的元素。Gram矩阵的每一个元素都是使用内核函数转化的预测因子(即特征)的内积。假设G(fj,fk)是Gram矩阵的元素(j,k),其中fj=[f1,j,f2,j,…,fF,j]和fk=[f1,k,f2,k,…,fF,k]是F维归一化特征向量,代表训练集中的样本j和k。在表4中,给出了核函数的简要描述。
训练一个随机森林
要训练一个随机森林,除了一般的参数外,还需要选择随机森林中的树的数量,以及每棵树的叶节点观察值占总样本的最小相对数。然后将这个相对数乘以训练集的大小。结果就是每棵树叶的最小观察数。
训练k-最近邻分类器的组合
要训练一个集合k-NN分类器,除了一般参数外,还需要提供一些其他参数。这些参数如下:
- 每个k-NN学习者的随机选择的特征数量。
- k-NN学习者的数量。
- 以及对每个样本进行分类的最近邻数。
训练一个朴素贝叶斯分类器
对于这个分类器,工具箱不要求额外的输入参数。朴素贝叶斯模型使用以下默认参数进行训练:
- 数据分布:用核平滑密度估计来建立数据模型。
- 核平滑器类型:高斯(Gaussian)被设置为核平滑器类型。
训练线性判别分析分类器
你可以使用LDA分类器根据碎片的特征分布进行分类。该模型假设数据具有高斯混合分布。由于当前版本的Fragments-Expert中的判别器是伪线性的,所以模型假设每个类的协方差矩阵相同,只有平均值不同。
训练神经网络
你可以训练一个神经网络来对训练数据进行分类。在当前版本的Fragments-Expert中,考虑的是两层模式识别神经网络模型。所以,除了一般参数外,你还需要输入隐藏层的维度。
训练函数根据量化共轭梯度法更新权重和偏差值。此外,交叉熵被用作衡量网络性能的标准。
4-7 测试一个训练过的决策机器
要测试任何训练过的模型,必须在工具箱环境中加载已经训练好的机器和兼容的数据集。请注意,数据集必须是兼容的;即数据集的特征集必须与用于训练模型的特征集相同。你必须提供数据集中测试样本的开始和结束,还必须提供加权方法。
测试程序完成后,可以保存测试结果。测试参数和结果显示在工具箱的主文本窗口中。
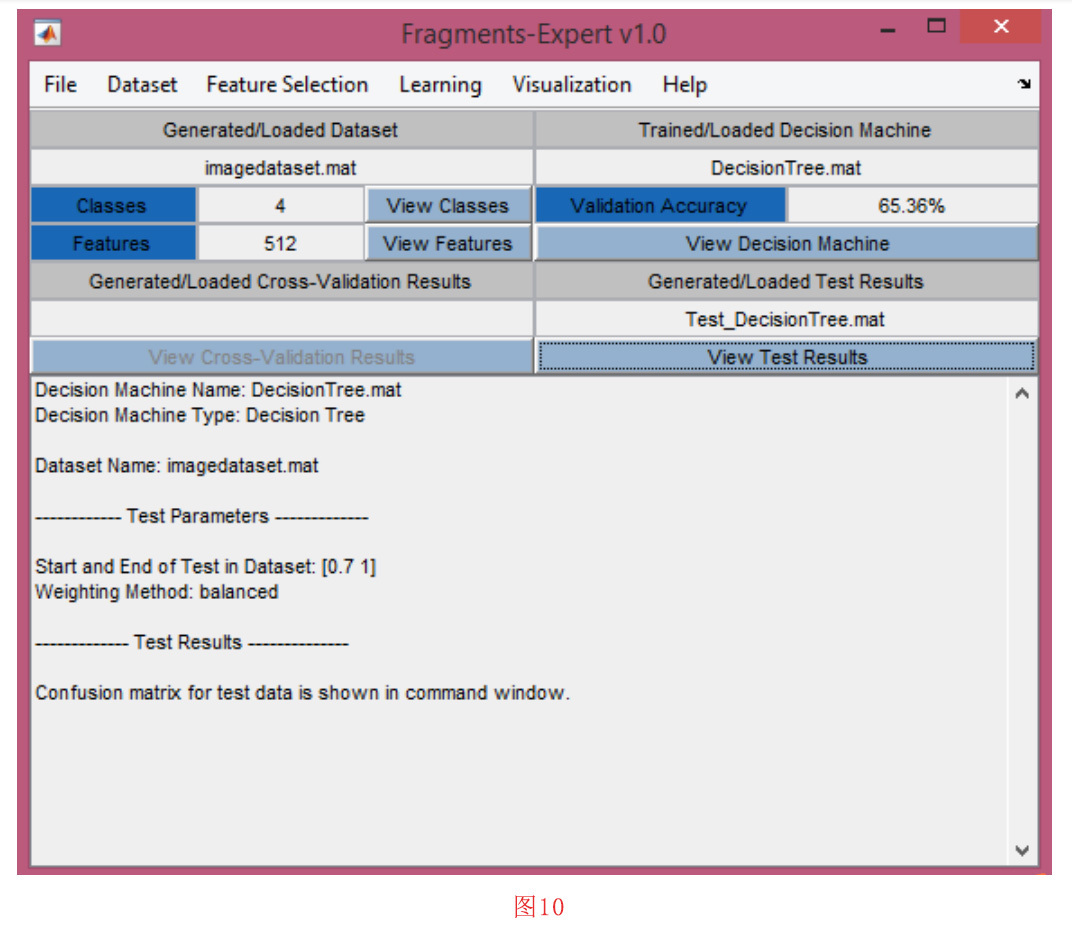
图10显示了一个示例。在这个例子中,我们为一个音频编解码器数据集训练了一棵决策树。数据集包含20个音频文件格式和第一个256个BFD特征连同第一个256个RoC特征被认为是特征。现在我们想测试这棵经过训练的树用于分类图像文件格式的性能。我们使用第4-3节中解释的程序为四种图像文件格式生成特征数据集。运行测试过程结束后,将显示测试结果。此外,您还可以保存这些结果。
4-8决策模型的交叉验证
为了获得决策模型的最佳参数或评估学习方法的平均性能,你可以使用交叉验证。要使用交叉验证,首先,必须在工具箱环境中加载你的数据集。然后,你应该点击 “Learning “菜单中的 “Cross-Validation of Decision Machine “子菜单。在下一个窗口中,你可以在决策机器中进行选择。除了每台机器的参数外,你还必须选择K值进行K倍交叉验证。当程序完成后,交叉验证结果会显示在工具箱的主文本窗口中。在MATLAB的命令窗口中也会显示交叉验证的混淆矩阵。
4-9数据可视化
可视化工具可以让人更好地了解数据样本中特征值的分布。在当前版本的Fragments-Expert中,您可以绘制特征直方图或显示数据样本在特征空间中的分布。
绘制特征直方图
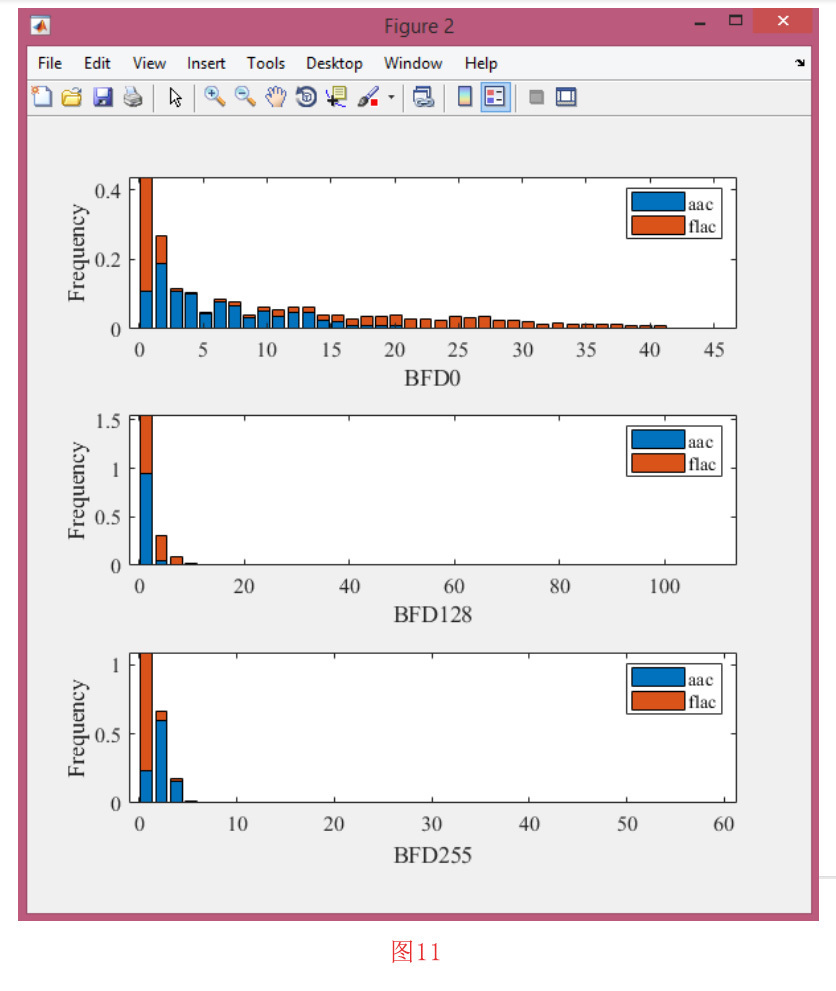
您可以为一个或多个选定的类标签绘制一个或多个特征直方图。要这样做,请单击 “Visualization “菜单中的 “Plot Feature Histogram “子菜单。在下一个窗口中,在特征中进行选择。对于每个选定的特征,将绘制一个单独的直方图。确认特征标签后,您必须选择所需的类别标签。您可以选择一个以上的类别。现在您必须再次确认类标签。在下一个窗口中,您应该为直方图和子图组织设置容器的数量。之后,按 “确定 “按钮。图11是一个直方图的示例。
在特征空间中显示样本
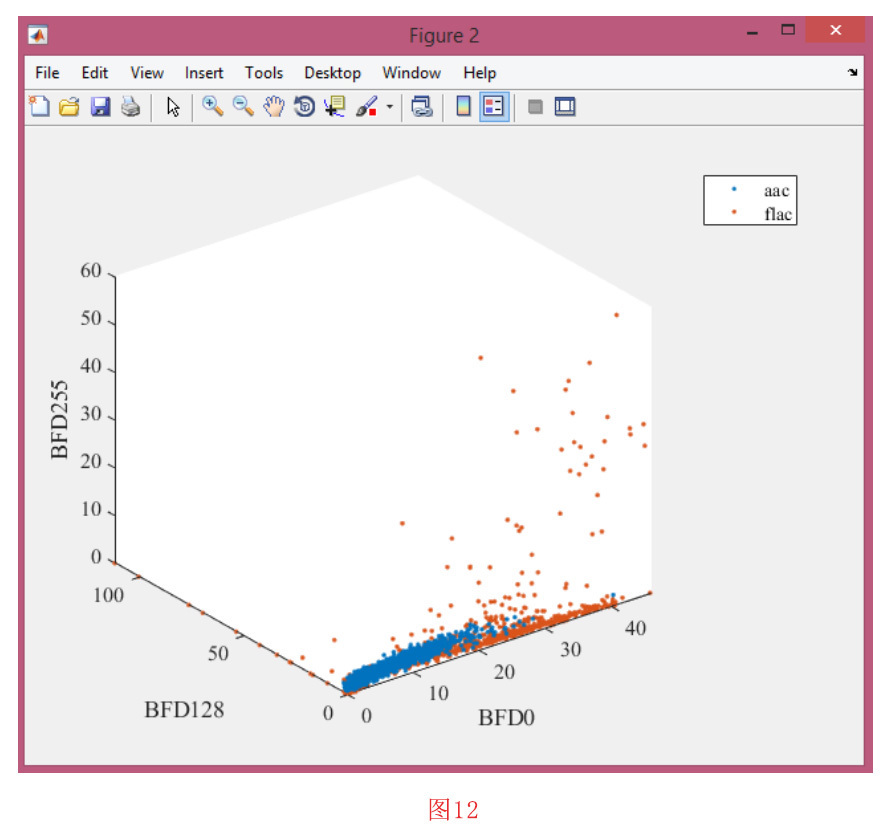
您可以在一个特性空间中显示多个类标签的示例。您可以选择两个或三个特征以形成一个2-D或3-D特征空间,在这个空间中,数据集的每个样本都表示为一个数据点。
为此,点击 “Visualization “菜单中的 “Display Samples in Feature Space”子菜单。在下一个窗口中选择两到三个特征。此外,您还应该选择一些类。在这个过程中,你还必须确认特征和类的标签。之后,你可以看到所选特征空间中的样本分布。在图12中,显示了一个三维特征空间表示的例子。
4-10 加载之前生成的数据和结果
如果保存了数据集、决策机器、测试结果或交叉验证结果,则可以在工具箱中再次加载它们。
加载数据集
要加载数据集,请单击“File”菜单中的“Load Dataset”子菜单。选择设备中的数据集。加载数据集完毕后,可以查看类标签和特性。
加载决策机器
要加载决策机器,点击“File”菜单中的“Load Decision Machine”子菜单。选择训过的机器。在加载决策机器完毕后,您可以看到验证的准确性。
加载测试结果
要加载测试结果,点击 “File “菜单中的 “Load Test Results “子菜单。选择测试结果。加载完毕后,可点击 “View Test Results “查看测试结果。
加载交叉验证结果
要加载交叉验证结果,点击 “File “菜单中的 “Load Cross-Validation Result”子菜单。选择交叉验证结果。加载完成后,可以点击 “View Cross-Validation Results”,查看交叉验证结果。在这种情况下,你可以在命令窗口中看到混淆矩阵。







发表评论
您还未登录,请先登录。
登录