

5 一个说明性的例子
在本节中,我们介绍了一个针对文本文件格式的文件片段分类的例子。我们采用了[43]中提出的数据集。考虑了DOC、DOCX、PDF、RTF和TXT五种文件格式。为了简单起见,我们只考虑英文文本文件的片段。所以,这五种格式对应的数据文件分别是DOC-EN.dat、DOCX-EN.dat、PDFEN.dat、RTF-EN.dat和TXT-EN.dat。每个数据文件包含1500个片段。所有片段的长度为1024字节。
5-1 生成特征数据集
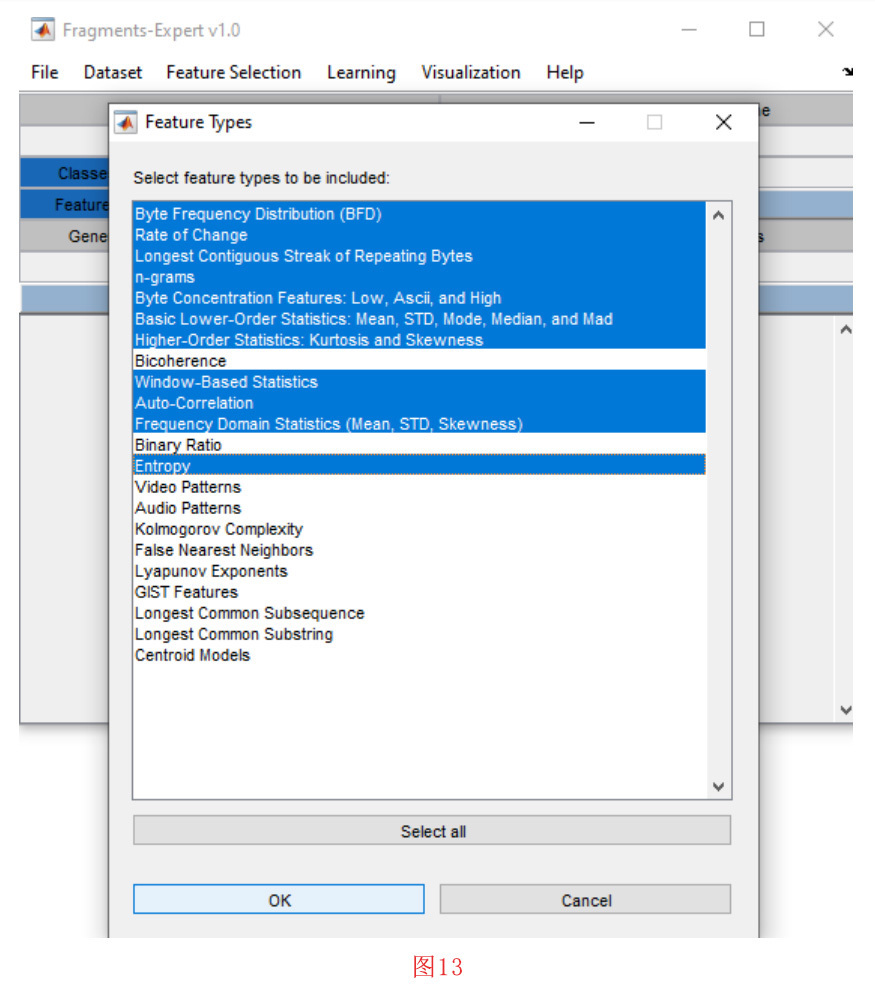
为了从上述通用的二进制数据文件中生成特征数据集,我们将点击”Dataset “菜单中的 “Generate Dataset from Generic Binary Files of Fragments”子菜单 。然后,如图13所示,打开一个窗口。在这个窗口中,将显示功能类型的列表。我们选择以下功能,然后按 “确定 “按钮。BFD, RoC, 最长连续的重复字节,n-grams,字节集中特征,基本低阶统计、高阶统计、基于窗口统计、自相关、频域统计和熵。
然后,如图14所示,打开另一个窗口,填写n-grams、基于窗口的统计、频域统计和自动相关四类特征的参数。对于n-gram,我们选择提取2-grams和3-grams特征。对于基于窗口的统计,我们选择的窗口大小为256字节。对于频域统计,子带的数量设置为4。 此外,对于自相关特征,最大滞后值设置为5。设置好特征提取的参数后,我们按确定按钮。

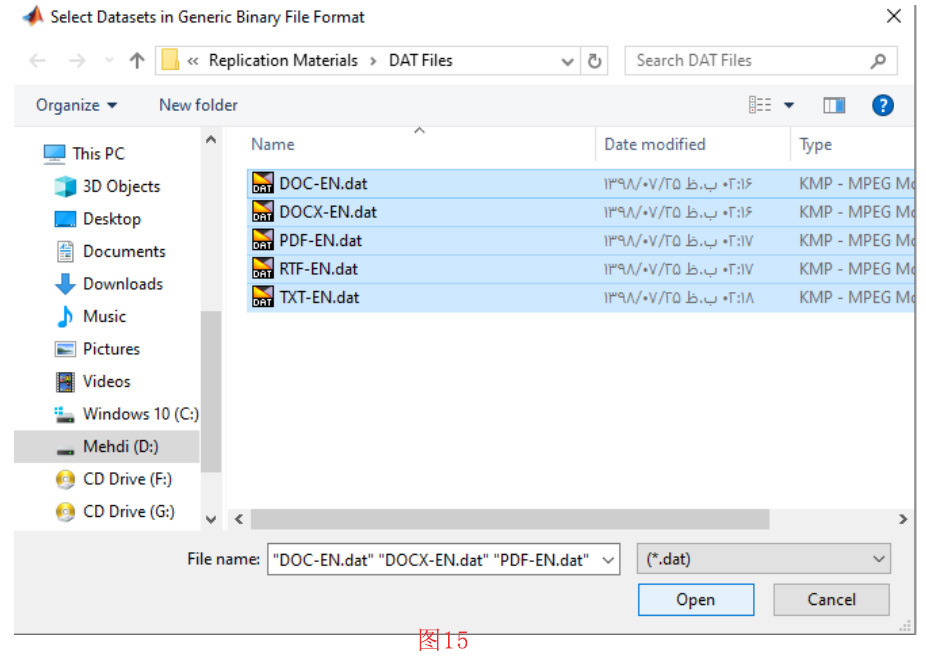
之后,如图15所示,打开一个窗口来获取片段的数据文件。在这个阶段,我们选择以下文件:DOC-EN.dat、DOCX-EN.dat、PDF-EN.dat、RTF-EN.dat和TXT-EN.dat,并按 “确定 “按钮。读取完片段后,如图16所示,工具箱显示出一个文本框,确认五个类标签对应的变量名。我们确认默认的变量名为DOC_EN、DOCX_EN、PDF_EN、RTF_EN和TXT_EN。

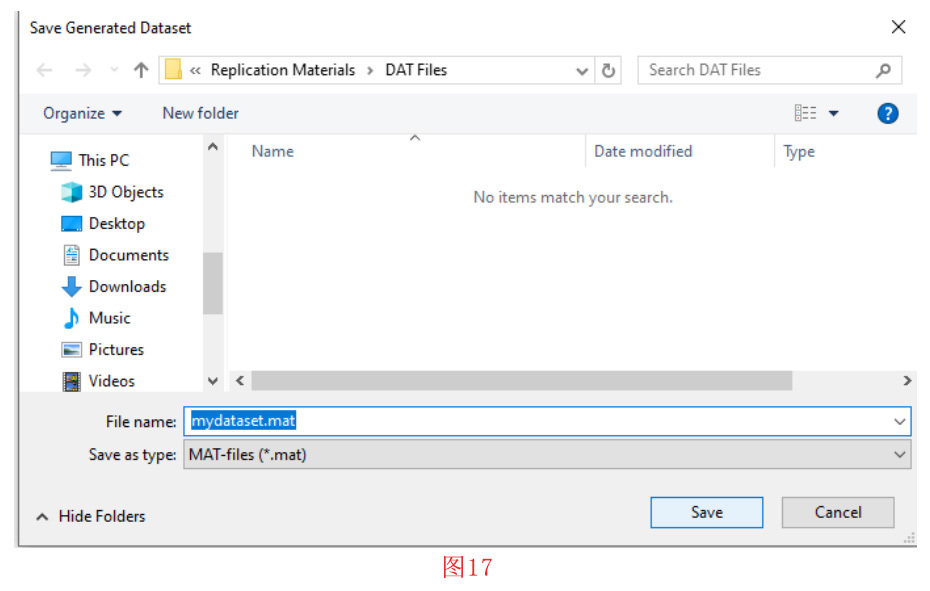
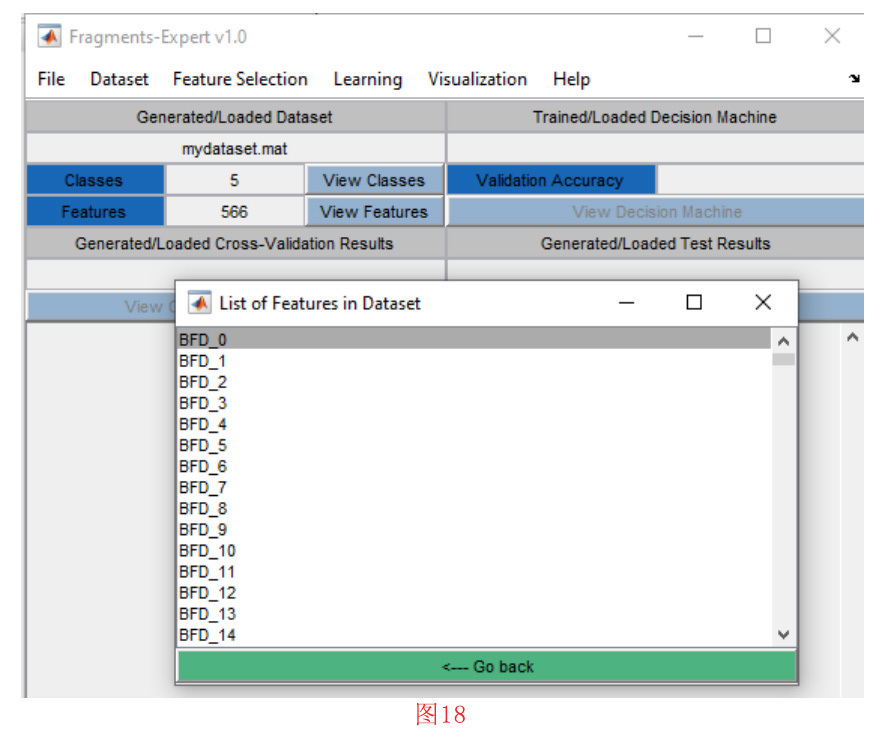
确认变量名称后,开始特征提取过程。一旦,这个过程完成,就会提示用户保存生成的数据集(见图17)。我们选择 默认名称 “mydataset.matˮ,然后按保存按钮。现在,数据集也被加载到了 的工具箱环境。在 “Generated/Loaded Datasetˮ 部分,我们可以看到。数据集由5个类和566个特征组成。通过按 “View Featuresˮ 按钮,可以看到特征列表(见图18)。
5-2训练决策树
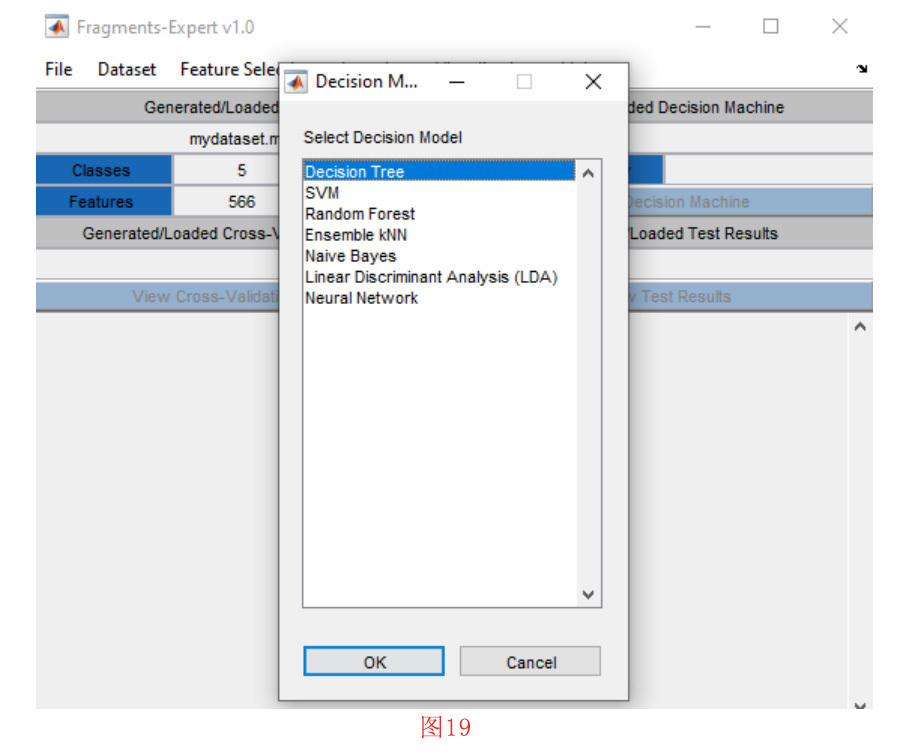
为了给我们的数据集训练决策树,我们点击 “Learning “菜单中的 “Train Decision Machine “子菜单。如图19所示,打开了一个窗口,我们在其中选择 “Decision Tree”,并按下 “确定 “按钮。如图20所示,我们应该在下一个窗口中设置训练参数。在这个阶段,选择 “balancedˮ “的加权方法。同时,将数据集中的训练/验证的开始和结束设置为[0 1],这表示使用所有可用的样本进行训练/验证。训练和验证百分比分别选择为80%和20%。最后,叶子节点观察值占总样本的最小相对数设置为0.001。由于80%的总样本(即6000个样本)用于训练,因此叶节点观察值的最小数量被认定是6。为了防止过拟合,使用1500个验证数据样本(即所有样本的20%)对决策树进行删减。

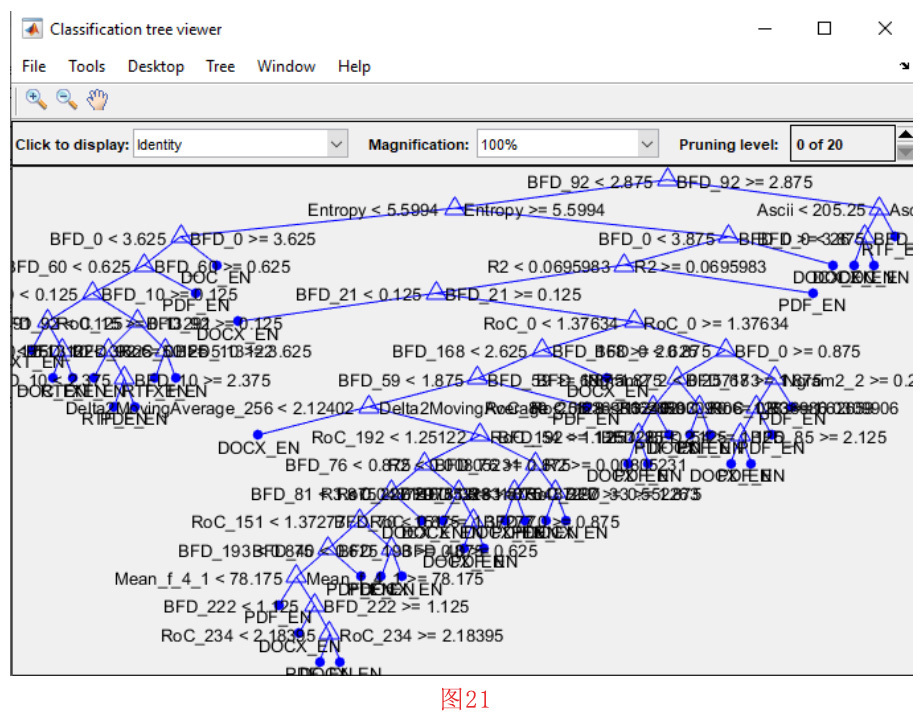
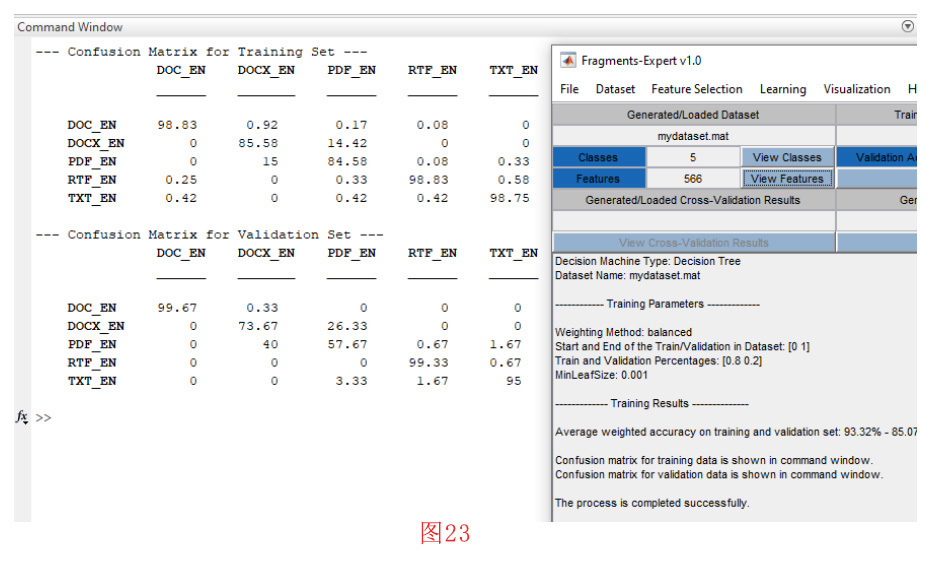
设置好训练参数并按下 “确定 “按钮后,会有进度条提示决策树训练过程的进度。在完成训练阶段之后,显示出训练好的决策树(见图21)。此外,还会提示用户保存决策模型(见图22)。在保存决策模型后,将在工具箱环境中加载决策模型。同时,训练参数和结果显示在工具箱的主文本窗口中。如图23所示,训练集和验证集的平均准确率分别在93%和85%左右。用于训练和验证的混淆矩阵也显示在命令窗口中。从图23中可以看出,DOC和RTF格式的准确度是最高的。
5-3 用可视化的方式来观察特征的效果
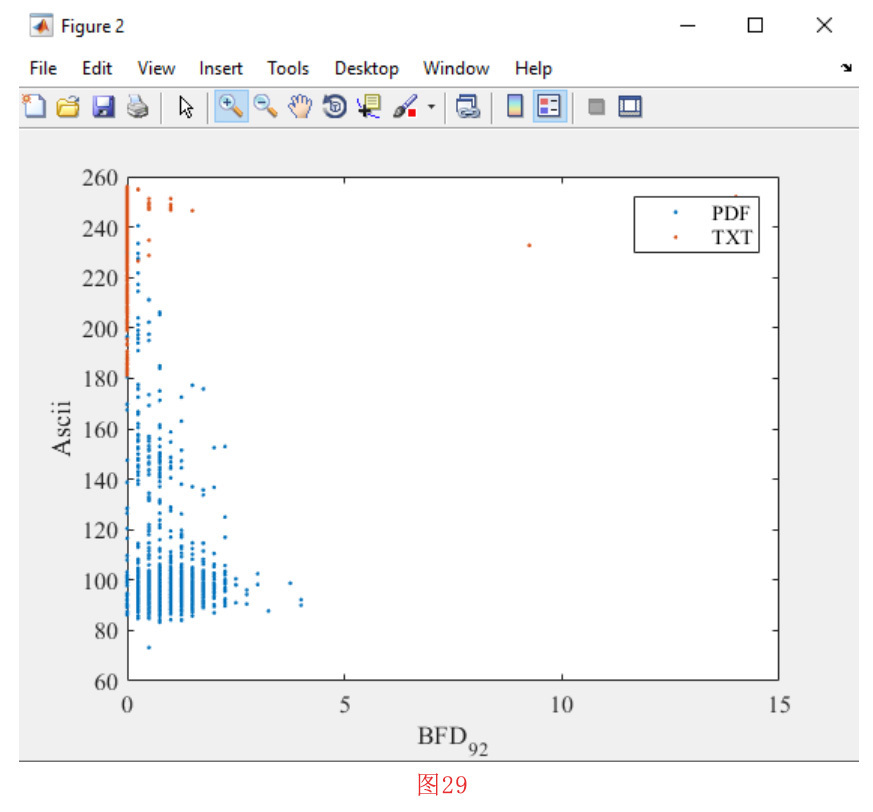
从图21中可以看出,BFD92,它相当于ASCII字符“\”,在我们的文本文件格式的分类中起着重要的作用。此外,第2-5节中描述的ASCII特性出现在树根附近。这个观察结果表明了ASCII特性的重要性。作为一个例子,假设我们需要观察PDF和TXT样本的二维空间BFD92和ASCII。这种观察有助于我们理解这些特性在对这两个类进行分类时的效果。
首先,我们点击 “Visualization”菜单中的 “Display Samples in Feature Space”子菜单。在接下来的窗口中,我们选择两个特征BFD92和ASCII(见图24),并按下 的 “确定 “按钮。然后,如图25所示,我们应该设置标签BFD92和ASCII 轴。做完这些工作并按下 “确定 “按钮,就会打开一个列表。在这个列表中,我们应该选择要在二维空间中显示的类。如图26和图27所示,我们将选择PDF和TXT类。选择第二个类,即TXT,并按下确定键后,列表再次显示。在这一阶段,因为我们不需要包含另一个类,所以我们要按取消按钮。然后,如图28所示,我们应该在二维图中为每个类选择显示的标题,然后按 “确定 “按钮。在按下确定按钮后,就会绘制出如图29所示的二维图。
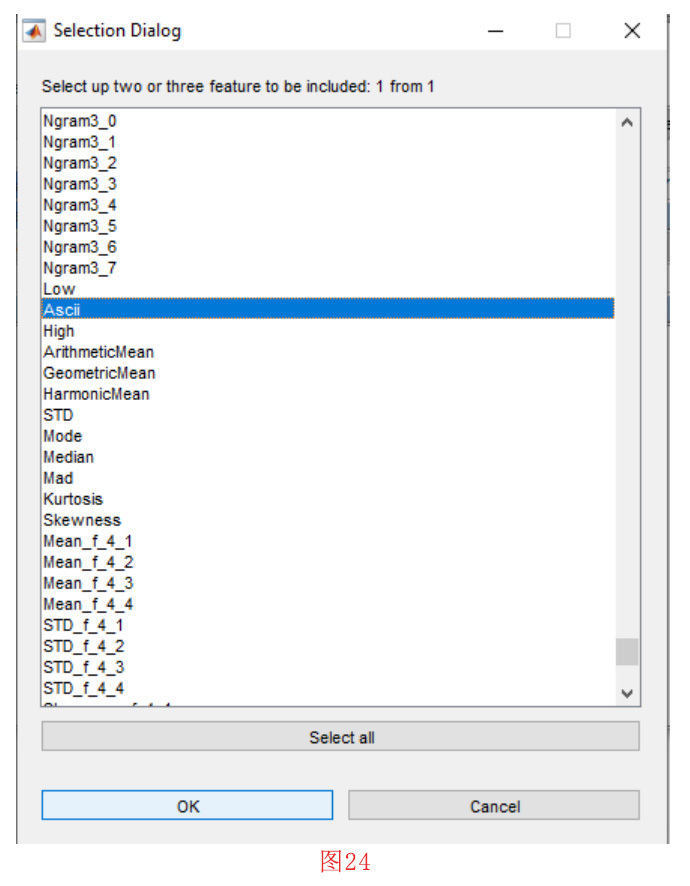
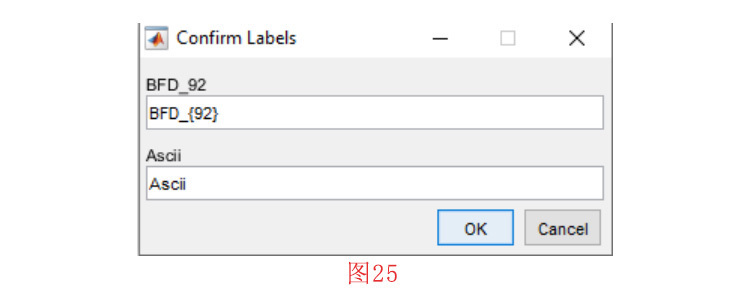
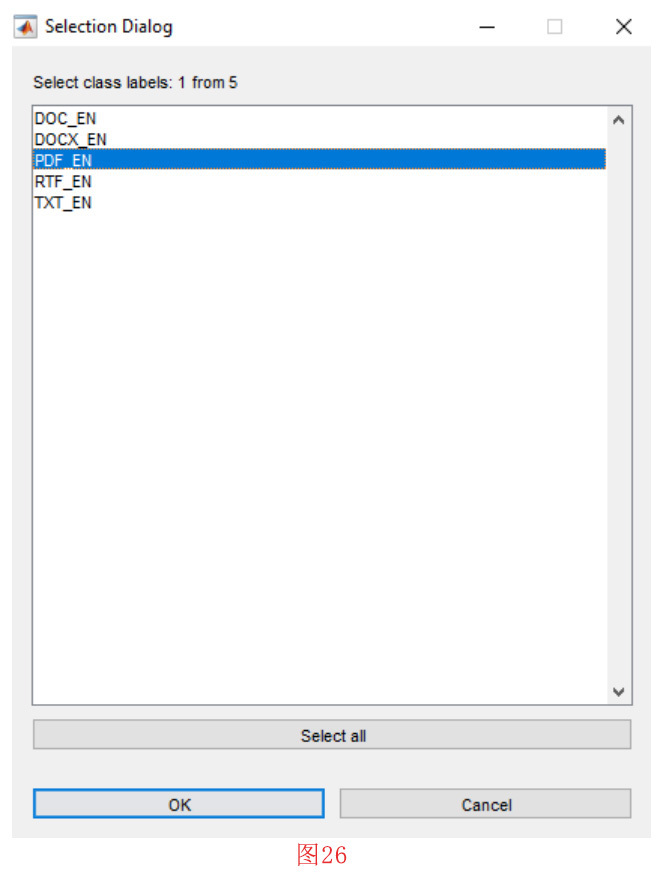
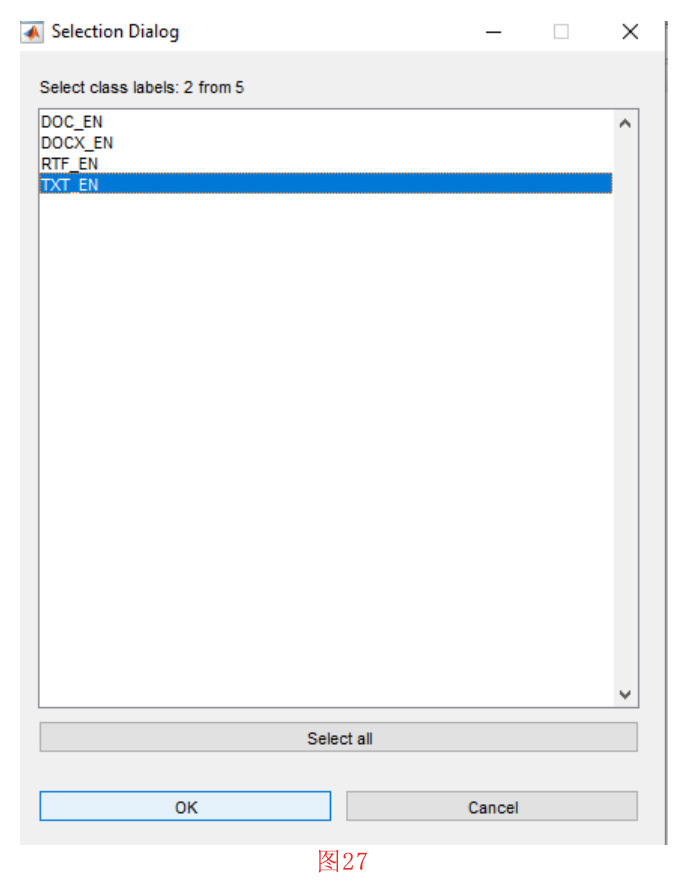
注意,在类选择的每个阶段,我们可以选择多个类。通过这样做,我们表明所选类的示例应该显示为统一项。
5-4 特征选择
许多经典的机器学习模型在高维空间中表现不佳。当特征数量过高时,训练过程的计算复杂性可能难以接受。此外,过度拟合的风险也会增加。
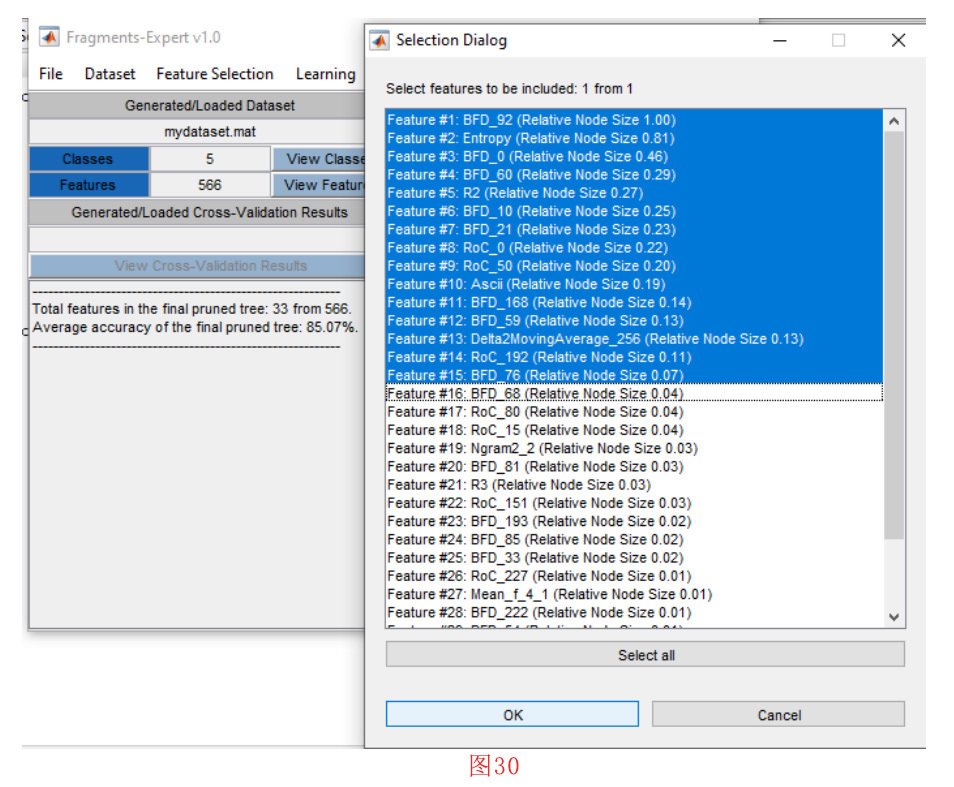
在本节中,我们将展示如何使用Fragments-Expert的 “feature selection “功能。在这种情况下,我们使用嵌入式的决策树学习方法。为此,我们点击 “feature selection “菜单中的 “Embedded: Decision Tree”子菜单。由于在本例中,工具箱训练的是一棵决策树,因此会提示我们输入与第4-6节中描述的用于训练决策树的参数类似的参数。设置好参数后,按确定按钮,训练开始。完成此步骤后,如图30所示。我们看到一个包含33个特征的列表,这些特征是根据相对节点大小排序。我们手动选择15个相对节点大小大于0.05的特征。按下 “确定 “按钮后,将创建具有15个特征的新数据集。然后,如图31所示,提示我们保存这个新数据集。保存数据集后,将特征选择的数据集加载到工具箱环境中。
5-5 使用选定特征进行交叉验证
在本节中,我们使用交叉验证来评估朴素贝叶斯方法在我们的特征选择数据集上的性能,该数据集包含15个选定的特征。为此,我们点击 “Learning”菜单中的 “Cross-Validation of Decision Machine”子菜单。在下一个窗口中,我们选择 “Naive Bayes”,然后按 “确定 “按钮。
下一步,我们应该设置交叉验证的参数。如图32所示,我们选择了加权方法 “balanced”。同时,数据集中的训练/验证/测试的开始和结束都设置为等于[0 1],表示使用所有可用样本进行训练/验证/测试。训练和验证的百分比也被分别选择为100%和0%。这意味着我们在这种情况下不使用任何验证数据。此外,我们选择z-score来对特征进行缩放。最后,K=5设置为K-fold交叉验证。

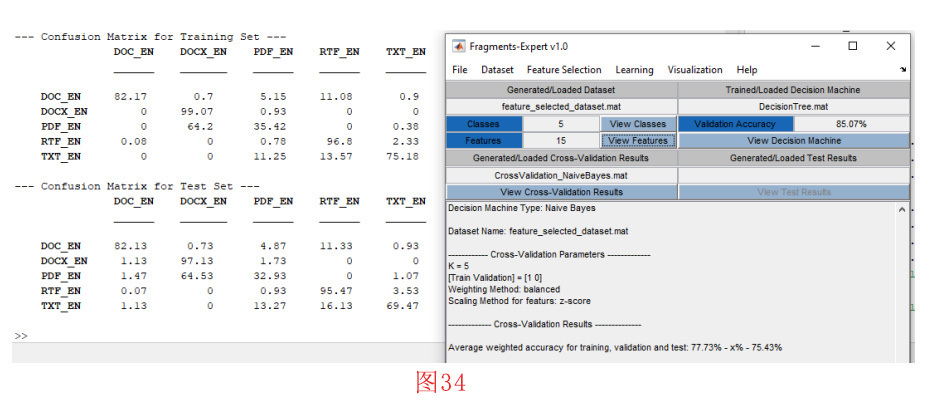
设置好参数并按下 “确定 “按钮后,交叉验证过程开始。并显示进度条,直到该过程结束。当交叉验证过程完成后,会提示我们保存结果(见图33)。保存结果后,交叉验证结果将显示在工具箱的主文本窗口中。另外,如图34所示,交叉验证混淆矩阵如图显示在MATLAB的命令窗口。从图34中可以看出,朴素贝叶斯模型对特征选择数据集的平均性能约为75%。
6 程序的可用性和限制
本文介绍的Fragments-Expert工具箱v1.0版本,可以在https://github.com/mehditeimouri-UT/Fragments-Expert/releases/tag/1.0 下载。要运行Fragments-Expert,您需要安装64位MATLAB R2015b或更新版本的Windows。
对数据集的大小没有具体限制。然而,对于大型数据集,工具箱功能的速度会降低。所降低的数量取决于您计算机的硬件规格。
该工具箱不兼容OCTAVE。然而,在未来的工作中,我们计划使这个工具箱与Octave兼容。
缩略语
2-D:2-Dimensional
3-D:3-Dimensional
BFD:Byte Frequency Distribution
BRO:Binary Ratio
COTS:Commercial Off-The-Shelf
FNF:False Neighbors Fraction
GUI:Graphical User Interface
k-NN:k-Nearest Neighbors
LDA:Linear Discriminant Analysis
LE:Lyapunov Exponent
MAD:Mean Absolute Deviation
RMS:Root Mean Squared
RoC:Rate of Change
STD:Standard Deviation
SVM:Support Vector Machine
参考文献
[1] M. C. Amirani, M. Toorani, and A. Beheshti, “A new approach to content-based file type detection,” in IEEE Symp. Computers and Communications, 2008, pp. 1103-1108.
[2] M. Karresand and N. Shahmehri, “Oscar—file type identification of binary data in disk clusters and ram pages,” in Securityand privacy in dynamic environments, ed: Springer, 2006, pp. 413-424.
[3] S. Gopal, Y. Yang, K. Salomatin, and J. Carbonell, “Statistical learning for file-type identification,” in 10th Int. Conf. Machine Learning and Applications and Workshops, 2011, pp. 68-73.
[4] S. Axelsson, “Using normalized compression distance for classifying file fragments,” in 2010 International Conference onAvailability, Reliability and Security, 2010, pp. 641-646.
[5] Q. Li, A. Ong, P. Suganthan, and V. Thing, “A novel support vector machine approach to high entropy data fragment classification,” in South African Information Security Multi-Conference, 2011, pp. 236-247.
[6] S. Fitzgerald, G. Mathews, C. Morris, and O. Zhulyn, “Using NLP techniques for file fragment classification,” Digital Investigation, vol. 9, pp. S44-S49, 2012.
[7] K. Karampidis and G. Papadourakis, “File Type Identification for Digital Forensics,” in International Conference onAdvanced Information Systems Engineering, 2016, pp. 266-274.
[8] I. Tzanellis, “A Specialized Approach for Document-Type Fragment Classification in Digital Forensics,” M.S. thesis, University of Amsterdam, Amsterdam, Netherlands, 2013.
[9] W. C. Calhoun and D. Coles, “Predicting the types of file fragments,” Digital Investigation, vol. 5, pp. S14-S20, 2008.
[10] J. De Bock and P. De Smet, “JPGcarve: an Advanced Tool for Automated Recovery of Fragmented JPEG Files,” 2015.
[11] W. Qiu, R. Zhu, J. Guo, X. Tang, B. Liu, and Z. Huang, “A New Approach to Multimedia Files Carving,” in IEEE Int. Conf. Bioinformatics and Bioengineering 2014, pp. 105-110.
[12] R. K. Pahade, B. Singh, and U. Singh, “A Survey ON MULTIMEDIA FILE CARVING,” 2015.
[13] S. Hicsonmez, H. T. Sencar, and I. Avcibas, “Audio codec identification from coded and transcoded audios,” Digital SignalProcessing, vol. 23, pp. 1720-1730, 2013.
[14] P. Tripathi, K. P. Raju, and V. R. Chandra, “A Novel Technique for Detection of CVSD Encoded Bit Stream,” International Journal of Innovative Research in Computer and Communication Engineering, vol. 2, pp. 6035-6040, 2014.
[15] K. Nguyen, D. Tran, W. Ma, and D. Sharma, “Decision tree algorithms for image data type identification,” Logic Journal of IGPL, pp. 67-82, 2016.
[16] W.-J. Li, K. Wang, S. J. Stolfo, and B. Herzog, “Fileprints: Identifying file types by ngram analysis,” in 6th Annu. IEEE SMC Information Assurance Workshop, 2005, pp. 64-71.
[17] AstronSoftware. (19 July 2020). LibMagic. Available: http://ftp.astron.com/pub/file/
[18] M. Pontello. (19 July 2020). TrID – File Identifier Available: http://mark0.net/soft-tride.html
[19] Oracle. (19 July 2020). Outside In Technology. Available: https://www.oracle.com/middleware/technologies/webcenter/outside-in-technology.html
[20] D. Underdown. (19 July 2020). DROID. Available: http://droid.sourceforge.net/
[21] OpenPreservation. (19 July 2020). JHOVE. Available: https://jhove.openpreservation.org/
[22] BasisTechnology. (19 July 2020). Autospy. Available: https://www.autopsy.com/
[23] CGSecurity. (19 July 2020). PhotoRec. Available: https://www.cgsecurity.org/wiki/PhotoRec
[24] P. Harvey. (19 July 2020). ExifTool. Available: https://exiftool.org/
[25] AccessData. (19 July 2020). Forensics Toolkit (FTK). Available:https://accessdata.com/products-services/forensic-toolkit-ftk
[26] OpenText. (19 July 2020). EnCase. Available: https://www.guidancesoftware.com/encase-forensic
[27] ShockingSoft. (19 July 2020). AnalyzeIt. Available: https://www.shockingsoft.com/AnalyzeIt.html
[28] Toolsley. (19 July 2020). File Identifier. Available: https://www.toolsley.com/file.html
[29] K. Konstantinos, “File type identification–a computational intelligence approach to digital forensics,” Technological educational institute of Crete, 2015.
[30] S. J. Moody and R. F. Erbacher, “Sádi-statistical analysis for data type identification,” in 2008 Third international workshop on systematic approaches to digital forensic engineering, 2008, pp. 41-54.
[31] P. Matousek, O. Rysavy, and M. Kmet, “Fast RTP detection and codecs classification in internet traffic,” Journal of Digital Forensics, Security and Law, vol. 9, pp. 101-112, 2014.
[32] N. L. Beebe, L. A. Maddox, L. Liu, and M. Sun, “Sceadan: Using Concatenated NGram Vectors for Improved File and Data Type Classification,” Information Forensics and Security, IEEE Transactions on, vol. 8, pp. 1519-1530, 2013.
[33] G. Mittal, P. Korus, and N. Memon, “FiFTy: Large-scale File Fragment Type Identification using Convolutional Neural Networks,” IEEE Transactions on Information Forensics and Security, 2020.
[34] G. Conti, S. Bratus, A. Shubina, B. Sangster, R. Ragsdale, M. Supan, et al., “Automated mapping of large binary objects using primitive fragment type classification,” Digital Investigation, vol. 7, pp. S3-S12, 2010.
[35] A. Swami, J. M. Mendel, and C. L. Nikias, “Higher-order spectral analysis toolbox,” The Mathworks Inc, vol. 3, pp. 22-26, 1998.
[36] R. F. Erbacher and J. Mulholland, “Identification and localization of data types within large-scale file systems,” in Second International Workshop on Systematic Approaches to Digital Forensic Engineering (SADFE’07), 2007, pp. 55-70.
[37] J. Goubault-Larrecq and J. Olivain, “Detecting Subverted Cryptographic Protocols by Entropy Checking,” Laboratoire Spécification et Vérification, ENS Cachan, France, Research Report LSV-06-13, 2006.
[38] X. Jin and J. Kim, “Video fragment format classification using optimized discriminative subspace clustering,” Signal Processing: Image Communication, vol. 40, pp. 26-35, 2016.
[39] X. Jin and J. Kim, “Audio Fragment Identification System,” International Journal of Multimedia and UbiquitousEngineering, vol. 9, pp. 307-320, 2014.
[40] F. Kaspar and H. Schuster, “Easily calculable measure for the complexity of spatiotemporal patterns,” Physical Review A,vol. 36, p. 842, 1987.
[41] T. Xu, M. Xu, Y. Ren, J. Xu, H. Zhang, and N. Zheng, “A File Fragment Classification Method Based on Grayscale Image,” Journal of Computers, vol. 9, pp. 1863-1870, 2014.
[42] A. Oliva and A. Torralba, “Modeling the shape of the scene: A holistic representation of the spatial envelope,” International journal of computer vision, vol. 42, pp. 145-175, 2001.
[43] F. M. Hanis and M. Teimouri, “Dataset for file fragment classification of textual file
formats,” BMC Research Notes, vol. 12, pp. 1-3, 2019.







发表评论
您还未登录,请先登录。
登录