

4.实验
我们从威胁情报源和Sophos的内部系统中收集了约500万封电子邮件和相关元数据的数据集。该数据集由407,161封恶意邮件和3,842,772封良性邮件组成,这些邮件是从一个庞大的邮件集合中随机抽取的。我们根据首次看到的时间将样本分为训练、验证和测试数据集,以防止数据泄漏问题。分别使用70%、15%和15%的样本进行训练、验证和测试。训练数据集有285,021个恶意样本和2,697,499个良性样本,测试数据集有122,140个良性样本和1,145,273个良性样本。在所有的实验中,我们提取单词token,邮件文本数据的最大token长度为128。
我们利用Pytorch框架使用Adam优化器和128大小的迷你批次来训练神经网络模型。我们对DistilBERT的实现是基于Huggingface[21]的。我们还训练了一个非神经网络模型,逻辑回归使用的是scikit-learn[20]框架。每个神经网络模型都使用相同的多语言BERT tokenizer来处理内容特征,并使用相同大小的嵌入层,这是为了让每个模型具有相似的学习能力来处理token输入。模型的训练时间为5个迭代次数,这足以让结果收敛。
4.1 分类性能
我们首先进行了实验,将我们提出的模型与两个非BERT模型,长短期记忆(LSTM)[7]和逻辑回归(LR)[22]进行比较。所有基于BERT的模型都是用Adam优化器进行训练的,平衡的批次大小为128。由于恶意样本的数量小于良性样本,我们对不平衡数据集采用平衡批次采样。平衡批分配的前64个样本来自合法样本,其余64个样本来自恶意样本。
我们所提出的模型CatBERT有三个具有内容和上下文特性的Transformer块。DistilBERT包含的6个Transformer块,在DistilBERT论文中使用。LSTM模型接受单词序列作为输入,包含一个带有嵌入层的单一LSTM层,该嵌入层与BERT的嵌入层具有相同的768维。神经网络模型采用Adam优化器进行训练,平衡批次为128。LR模型使用来自一元或二元语法词的TF-IDF特征。
图4比较了ROC(Receiver Operating Characteristic)曲线,使我们能够评估四种模型在不同假阳性率下的表现。结果表明,基于BERT的模型以较大的优势优于非BERT模型,而CatBERT的性能最好。我们将邮件样本分为三组:商务邮件样本(Business Email Compromise)、英文样本和非英文样本。右上角为所有测试样本的ROC曲线,左上角为商务邮件样本(BEC),左下角为英文样本,右下角为非英文样本。我们提出的模型在所有四种情况下都优于基线模型。我们的钓鱼样本包括BEC样本,这些是手工的社交工程电子邮件。为了提高BEC样本的检测率,我们为目标样本分配的样本权重为100。该方法可以让我们的模型专注于这些样本,因为当这些样本在训练过程中被错误分类时,会产生很大的误差。
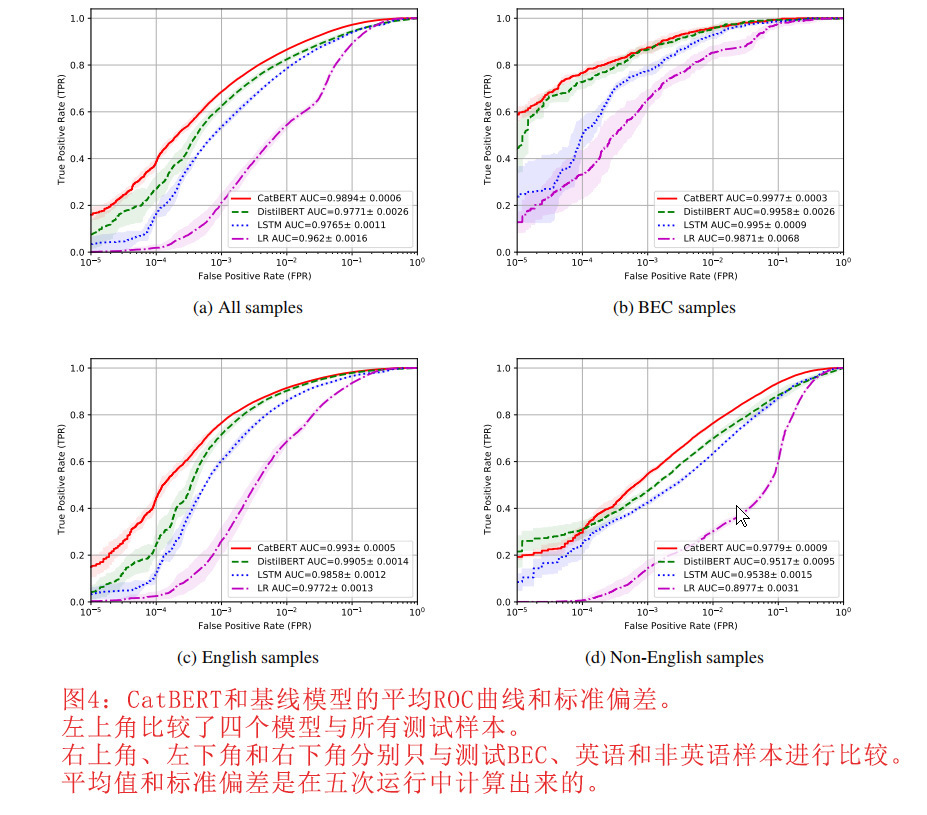
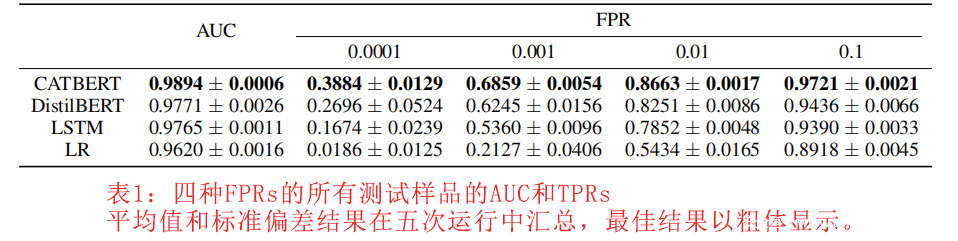
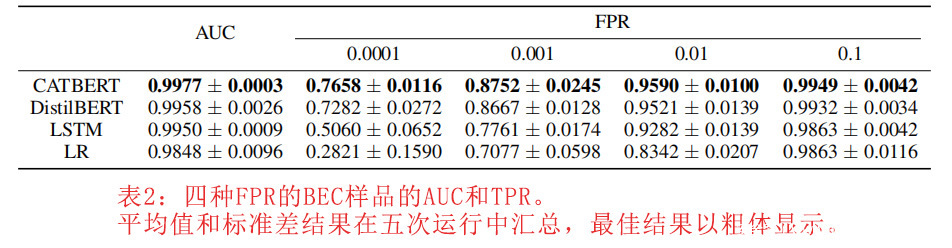
我们比较了四种模型在不同FPR(假阳性率)和AUC(曲线下面积)下的TPR(真阳性率)。表1和表2分别是所有测试样品和测试BEC样品的结果。CatBERT通过三个基线模型得出了最佳的性能。
我们还进行了一项消融研究,以调查CatBERT中其他组件的影响。图5比较了CatBERT模型与两个修改后的模型。绿色的CatBERT_noAdapter没有适配器层,蓝色的CatBERT_noContext没有上下文相关层。当从CatBERT中去掉其中一个适配器或上下文层时,有一个可衡量的性能下降。

4.2 运行时性能
将基于全尺寸Transformer的模型应用于实时检测系统的主要障碍之一是全模型的运行时性能。由于在生产环境中每天需要处理数以百万计的电子邮件,任何将分析电子邮件的机器学习模型的推理速度是模型部署的关键性能指标。
表3比较了神经网络模型的模型大小和推理速度。DistilBERT有1.35亿个参数,是最大的模型,有6个Transformer块,推理时间也相应较长。具有3个Transformer块的CatBERT有1.17亿个参数,比DistilBERT小15%左右,在CPU推理时间上获得1.6倍的提速(使用AWS m5.large实例类型),在GPU上获得1.3倍的提速(AWS g3s.xlarge实例类型)。
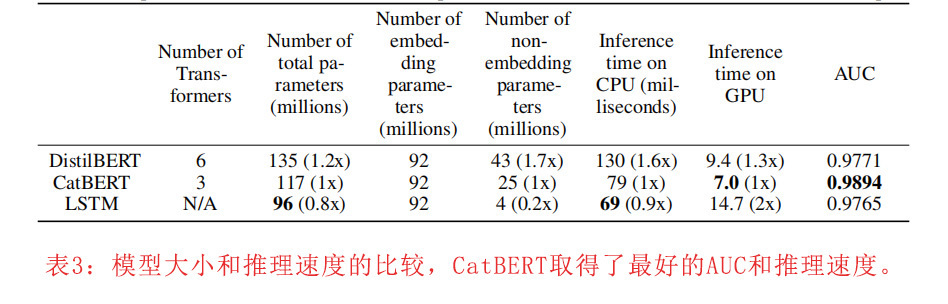
虽然LSTM模型在CPU推理中获得最快的推理速度,只有9600万个参数,但其在AUC方面表现最差。LSTM模型在GPU上的运行速度比CatBERT慢,因为循环神经网络不能并行运行。对CatBERT来说,参数大小的相对适度的减小是由于三个模型都使用了一个包含9200万个参数的大嵌入层,占所有参数的70%左右。当我们考虑检测性能和推理速度的结果时,CatBERT的性能最好。
4.3 对抗攻击的鲁棒性
对手经常故意使用错别字和同义词来变形恶意邮件,以规避机器学习模型,因为众所周知,机器学习模型很容易受到敌对行为的攻击[16]。我们的方法不太容易受到对手的攻击,因为我们的模型已经用大量的文本数据集进行了预训练,即使有些词被排版错误或同义词替换,也能理解邮件的主要意图。此外,我们来自邮件头标题字段的上下文特征有助于CatBERT抵御这些攻击。
为了检查我们模型的鲁棒性,我们用LIME[3]来检测CatBERT,它通过围绕预测局部学习一个可解释的模型来解释模型。BERT模型复杂且难以解释,而LIME可以学习一个具有邻域样本的线性回归模型,并通过学习的权重提供模型的可解释性,尽管这只是针对单个特定样本。然后可以通过检查其对局部线性模型的预测概率的影响来解释各个tokens。例如,在图6中,橙色表示正权重高的可疑词,而蓝色表示良性词。支付词的权重最高,并在邮件文本中被高亮显示。通过LIME的分析,证明我们的模型可以识别邮件内容中的可疑信号。上面的例子是LIME对原始样本的权重,下面的例子是修改后的样本的权重。修改后的样本是通过增加错别字、用同义词替换单词、删除部分单词或改变词序生成的。如表4所示,它列出了来自原始样本和修改样本的高权重可疑标记,我们的模型能够通过识别相关标记来检测修改后的样本。攻击者经常采用Unicode攻击,就是用Unicode字符混淆关键字[15]。例如,原始样本中的 “Payment “一词被替换为 “P@yment”。然而,我们的模型能够将该词识别为 “P”,”yment “为可疑词。BERT tokenizer将复杂的词划分为子词,并将这两个tokens列在高权重token中。


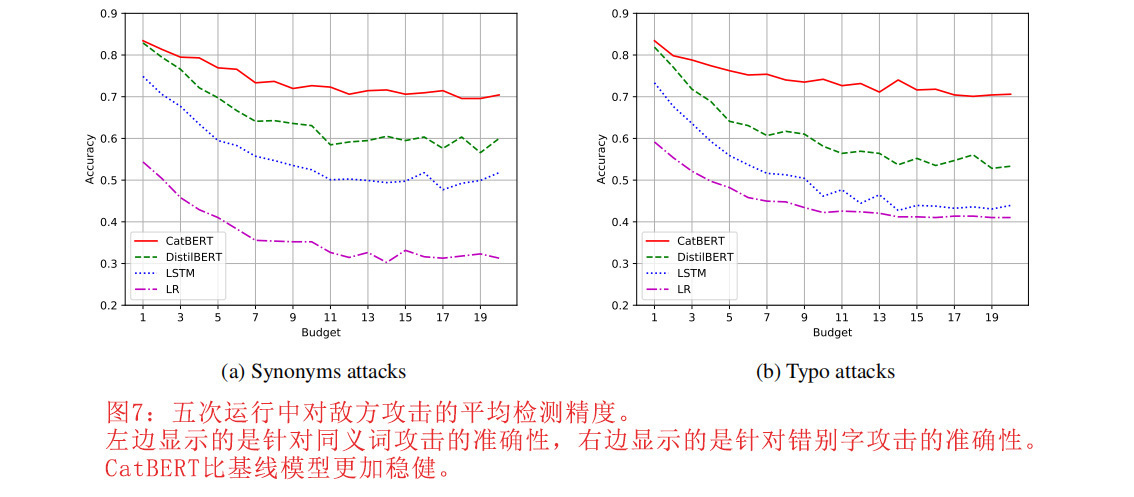
为了进一步分析模型的鲁棒性,我们从测试数据集中的BEC样本中使用简单的同义词和错别字创建了对抗性样本。修改后的样本是通过用同义词或错别字替换一个词生成的。图7比较了CatBERT和基线模型与对抗性样本的准确性。左图显示了用同义词替换单词的同义词攻击的结果。右图是修改有错别字的单词的错别字攻击结果。虽然CatBERT在两次攻击中都获得了最好的准确度,但基线模型产生的准确度却因攻击而显著降低,这表明CatBERT对这种对抗性攻击更为稳健。
5.结论
手工社交工程邮件对传统的签名和ML检测技术构成了巨大的挑战,因为一封单独的目标邮件可能与之前看到的攻击没有共同的词序或词语选择。我们通过微调一个预先训练好的、高度修剪的BERT模型,引入了一个高效的缩减BERT模型,该模型具有来自邮件标题的附加上下文特征,即使在存在故意拼写错误和试图逃避的情况下,也可以检测到有针对性的钓鱼邮件。我们的方法优于带有适配器和上下文层的强基线模型。CatBERT比DistilBERT小15%,速度快160%,而DistilBERT已经比vanilla BERT小40%。我们的模型对随机引入的单词选择、单词排序和其他组合的变化也很有弹性。
参考文献:
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In arXiv preprint arXiv:1810.04805, 2018.
【下略】







发表评论
您还未登录,请先登录。
登录