
前言
本人也是刚刚入门虚拟化的小白,如果文章出现什么错误恳请各位师傅斧正,文章中使用的qemu版本为2.8.1,后期我会在自己的github上发一个自己注释过的qemu-2.8.1的源码,tips:阅读源码,调试和阅读本文,同时进行才能更好的理解本文
内存虚拟化简述
在之前我们使用qemu进行操作的时候都会加一个-m的选项,-m后面对应着我们给虚拟机分配的内存。并且我们也可以在动调的时候查找到这块内存,如图所示:

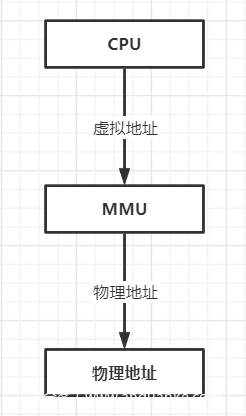
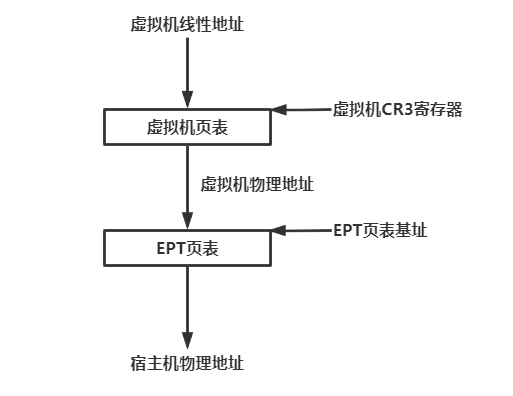
在物理机上,CPU对内存的访问在保护模式下是通过分段分页实现的,在该模式下,CPU访问时使用的是虚拟地址,必须通过硬件MMU进行转换,将虚拟地址转换成物理地址才能够访问到实际的物理内存,如图所示:
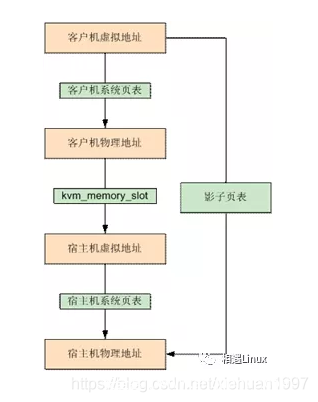
对应在虚拟机中和物理机一样也需要有从虚拟地址到物理地址的转换,这里有一点需要注意的是虚拟机的物理地址,其实对应的是qemu的虚拟地址。所以说如果想从虚拟机中访问或者读取数据,地址需要经过下面这样的转换:
GVA(虚拟机虚拟地址) -> GPA(虚拟机物理地址) -> HVA(宿主机虚拟地址) -> HPA(宿主机物理地址)
为了实现上述的转换过程,就需要虚拟化软件来提供这样的功能,也就是虚拟MMU,在使用EPT之前是通过影子页表来实现这个功能的,下面来简述一下影子页表,影子页表可以直接实现从GVA到HPA的转换,如下图所示,但是由于它效率很低,就被替换掉了,现再使用的就是EPT
关于影子页表,它的具体细节就是会在初始化写入cr3寄存器的时候,把宿主机针对虚拟机生成的一张页表放进cr3寄存器中,然后把原本想要写入cr3寄存器的值保存起来,当虚拟机读cr3寄存器值的时候,就会把之前保存的cr3的值返回给虚拟机。这样做的目的是,在虚拟机内核态中虽然有一张页表,但是虚拟机在访问内存的时候,MMU不会走这张页表,MMU走的是以填入到cr3寄存器上的真实的值为基地址(这个值是vmm写的宿主机的物理地址)的影子页表,经过影子页表找到真实的物理地址,影子页表时刻与客户端的页表保持同步。
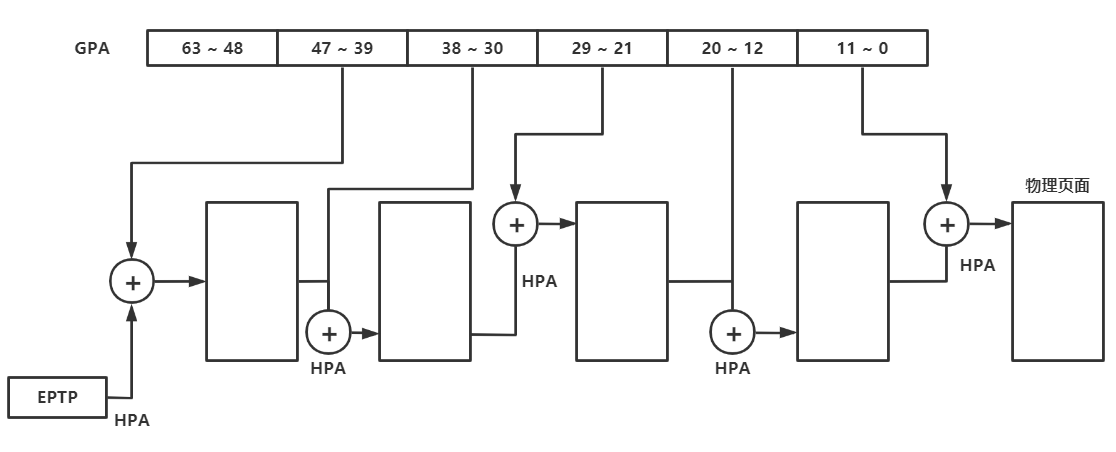
EPT方案中,CPU的寻址模式会在vm non root下发生变化,变化就是对于在发生vm entry时就会开启ept机制,也就是进入虚拟机状态时就会开启ept机制,对应的ept机制可以用下面的图来表示,然后如果说发生vm exit时就会关闭ept基址,也就是退出虚拟机状态。
EPT使用的是IA-32e的分页模式,也就是48位物理地址,分为4级页表,每级页表使用9位物理地址定位,最后12位表示一个页(4kb)内的偏移,如下图所示:
从源码分析内存初始化
涉及到的变量以及数据结构
内存初始化也是在pc_init1函数下面的,我们按顺序先来分析一下pc_init1函数
static void pc_init1(MachineState *machine,
const char *host_type, const char *pci_type)
{
PCMachineState *pcms = PC_MACHINE(machine);
PCMachineClass *pcmc = PC_MACHINE_GET_CLASS(pcms);
MemoryRegion *system_memory = get_system_memory();
MemoryRegion *system_io = get_system_io();
int i;
PCIBus *pci_bus;
ISABus *isa_bus;
PCII440FXState *i440fx_state;
int piix3_devfn = -1;
qemu_irq *i8259;
qemu_irq smi_irq;
GSIState *gsi_state;
DriveInfo *hd[MAX_IDE_BUS * MAX_IDE_DEVS];
BusState *idebus[MAX_IDE_BUS];
ISADevice *rtc_state;
MemoryRegion *ram_memory;
MemoryRegion *pci_memory;
MemoryRegion *rom_memory;
ram_addr_t lowmem;
................................................................
}
函数最开始的部分介绍了会使用的变量,这里我们把与内存相关的变量单拿出来,依次介绍一下
- system_memory:虚拟机的内存地址空间
- system_io:虚拟机的I/O地址空间
- ram_memory:主机在自己的虚拟内存上给虚拟机分配的物理内存
- pci_memory:给PCI设备分配的内存
- rom_memory:主机在自己的虚拟内存上给虚拟机分配的物理内存,但是这块内存只可读不可写入
- lowmem:因为一些有传统设备的虚拟机,其设备必须使用一些地址空间在4GB以下的内存,所以设置了这个变量,源代码中关于lowmem的注释如下
英文原版: /* * Calculate ram split, for memory below and above 4G. It's a bit * complicated for backward compatibility reasons ... * * - Traditional split is 3.5G (lowmem = 0xe0000000). This is the * default value for max_ram_below_4g now. * * - Then, to gigabyte align the memory, we move the split to 3G * (lowmem = 0xc0000000). But only in case we have to split in * the first place, i.e. ram_size is larger than (traditional) * lowmem. And for new machine types (gigabyte_align = true) * only, for live migration compatibility reasons. * * - Next the max-ram-below-4g option was added, which allowed to * reduce lowmem to a smaller value, to allow a larger PCI I/O * window below 4G. qemu doesn't enforce gigabyte alignment here, * but prints a warning. * * - Finally max-ram-below-4g got updated to also allow raising lowmem, * so legacy non-PAE guests can get as much memory as possible in * the 32bit address space below 4G. * * - Note that Xen has its own ram setp code in xen_ram_init(), * called via xen_hvm_init(). * * Examples: * qemu -M pc-1.7 -m 4G (old default) -> 3584M low, 512M high * qemu -M pc -m 4G (new default) -> 3072M low, 1024M high * qemu -M pc,max-ram-below-4g=2G -m 4G -> 2048M low, 2048M high * qemu -M pc,max-ram-below-4g=4G -m 3968M -> 3968M low (=4G-128M) */ 个人翻译版本(可能会含有错误,如有错误请提出XD): 为了获取超过4g的内存需要计算ram分割的大小。目的是为了与老版本兼容并且这有点复杂 传统的内存分布是3.5g(lowmem = 0xe0000000),这也是现再max_ram_below_4g的默认值 然后为了内存对齐,我们切割成了3g(lowmem = 0xc0000000)。但是我们只有在需要切割的时候才切割 比如说ram_size大于传统的lowmem的时候才进行切割。使新的机器类型是唯一的,目的是为了确保移植性 紧接着添加了max-ram-below-4g选项,它允许你使用更小的lowmem,以让你可以在4g以下使用一个更大的PCI I/O窗口 qemu不会强制你对齐,但是会提示一个警告 最后max-ram-below-4g可以来增大lowmem,所以说传统的non-PAE虚拟机可以获得在低于4g的32位地址空间中获得更多的内存 例子: qemu -M pc-1.7 -m 4G (old default) -> 3584M low, 512M high 传统的模式即3.5g qemu -M pc -m 4G (new default) -> 3072M low, 1024M high 新的模式即3g qemu -M pc,max-ram-below-4g=2G -m 4G -> 2048M low, 2048M high 使用max-ram-below-4g选项来设置,即2g qemu -M pc,max-ram-below-4g=4G -m 3968M -> 3968M low (=4G-128M) 还是使用max-ram-below-4g选项来设置不过可以获得更多的内存了
MemoryRegion
对应上面的变量涉及到了一个数据结构MemoryRegion,下面来说一下这个数据结构:
struct MemoryRegion {
Object parent_obj;
/* All fields are private - violators will be prosecuted */
/* The following fields should fit in a cache line */
bool romd_mode;
bool ram;
bool subpage;
bool readonly; /* For RAM regions */
bool rom_device;
bool flush_coalesced_mmio;
bool global_locking;
uint8_t dirty_log_mask;
RAMBlock *ram_block;
Object *owner;
const MemoryRegionIOMMUOps *iommu_ops;
const MemoryRegionOps *ops;
void *opaque;
MemoryRegion *container;
Int128 size;
hwaddr addr;
void (*destructor)(MemoryRegion *mr);
uint64_t align;
bool terminates;
bool ram_device;
bool enabled;
bool warning_printed; /* For reservations */
uint8_t vga_logging_count;
MemoryRegion *alias;
hwaddr alias_offset;
int32_t priority;
QTAILQ_HEAD(subregions, MemoryRegion) subregions;
QTAILQ_ENTRY(MemoryRegion) subregions_link;
QTAILQ_HEAD(coalesced_ranges, CoalescedMemoryRange) coalesced;
const char *name;
unsigned ioeventfd_nb;
MemoryRegionIoeventfd *ioeventfds;
QLIST_HEAD(, IOMMUNotifier) iommu_notify;
IOMMUNotifierFlag iommu_notify_flags;
};
我们选择几个重要的数据结构来说明一下:
- ram_block:表示实际分配的物理内存
- iommu_ops和ops:一组回调函数
- contaniner:表示该MemoryRegion所处的上一级MemoryRegion
- hwaddr addr:表示该MemoryRegion所在的虚拟机的物理地址
- terminates:用来表示是否是叶子节点
- proiority:用来表示这个MemoryRegion的优先级
- subregions:将该MemoryRegion所属的子MemoryRegion连接起来
- subregions_link:用来连接同一个父MemoryRegion下的相同兄弟
- MemoryRegion *alias:指向实体MR
- hwaddr alias_offset:起始地址 (GPA) 在实体 MemoryRegion 中的偏移量
MemoryRegion 表示在 Guest memory layout 中的一段内存,可将 MemoryRegion 划分为以下三种类型:
- 根级 MemoryRegion: 直接通过 memory_region_init 初始化,没有自己的内存,用于管理 subregion。如 system_memory
- 实体 MemoryRegion: 通过 memory_region_init_ram 初始化,有自己的内存 (从 QEMU 进程地址空间中分配),大小为 size 。如 ram_memory(pc.ram) 、 pci_memory(pci) 等。 这种MemoryRegion中真正的分配物理内存,最主要的就是pc.ram和pci。分配的物理内存的作用分别是内存、PCI地址空间以及fireware空间。QEMU是用户空间代码,分配的物理内存返回的是hva,hva保存至RAMBlock的host域。通过实体MemoryRegion对应的RAMBlock可以管理HVA。
- 别名 MemoryRegion: 通过 memory_region_init_alias 初始化,没有自己的内存,表示实体 MemoryRegion(如 pc.ram) 的一部分,通过 alias 成员指向实体 MemoryRegion,alias_offset 代表了该别名MemoryRegion所代表内存起始GPA相对于实体 MemoryRegion 所代表内存起始GPA的偏移量。如 ram_below_4g 、ram_above_4g 等。
AddressSpace
AddressSpace是另一个特别重要的数据结构,个人对他的理解是,他负责把memoryregion和flatview联系起来,如果memoryregion发生了变化,对应的flatview也就会发生变化,然后就会通过addressspace来找到这个memoryregion对应的flatview,然后通过结构体的函数来修改flatview
struct AddressSpace {
/* All fields are private. */
struct rcu_head rcu;
char *name;
MemoryRegion *root;
int ref_count;
bool malloced;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
struct AddressSpaceDispatch *dispatch;
struct AddressSpaceDispatch *next_dispatch;
MemoryListener dispatch_listener;
QTAILQ_HEAD(memory_listeners_as, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
- root:地址空间对应的树型的内存模型
- AddressSpaceDispatch:具体作用不是特别清除,不过简单的了解了一下,在虚拟机退出时,能够顺利根据物理地址找到对应的HVA地址,qemu会有一个AddressSpaceDispatch结构,用来在AddressSpace中进行位置的找寻,继而完成对IO/MMIO地址的访问。
- dispatch_listener:在虚拟机物理内存发生改变时,调用对应的回调函数,并且把更改了的内容提交给kvm,然后修改对应的flatview,其中包含很多回调函数
RAMBlock
struct RAMBlock {
struct rcu_head rcu;
struct MemoryRegion *mr;
uint8_t *host;
ram_addr_t offset;
ram_addr_t used_length;
ram_addr_t max_length;
void (*resized)(const char*, uint64_t length, void *host);
uint32_t flags;
/* Protected by iothread lock. */
char idstr[256];
/* RCU-enabled, writes protected by the ramlist lock */
QLIST_ENTRY(RAMBlock) next;
int fd;
size_t page_size;
};
一个RAMBlock表示一段虚拟内存,host域指向申请的ram的虚拟地址,即hva。所有的RAMBlock通过next字段连接起来,表头保存在全局RAMList中,offset表示当前RAMBlock在RAMList中的偏移。每个RAMBlock都有一个唯一的MemoryRegion对应,但需要注意的是不是每个MemoryRegion都有RAMBlock对应。
涉及到的函数
get_system_memory() and get_system_io()
在最开始的部分就涉及到了两个函数MemoryRegion *system_memory = get_system_memory();和 MemoryRegion *system_io = get_system_io();
我们先来看一下前两个函数get_system_memory()和get_system_io():
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
memory_region_init(system_memory, NULL, "system", UINT64_MAX);
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
65536);
address_space_init(&address_space_io, system_io, "I/O");
}
MemoryRegion *get_system_memory(void)
{
return system_memory;
}
MemoryRegion *get_system_io(void)
{
return system_io;
}
我们可以看到函数get_system_memory()和get_system_io()都是只返回了指向对应内容的指针,并且给system_memory和system_io赋值的语句只存在于memory_map_init函数中,所以我首先猜测memory_map_init函数是先于get_system_memory和get_system_io函数执行的,为了验证我的猜测,我分别在memory_map_init函数和pc_init1函数两个地方下断点,看qemu会先在哪里断下。

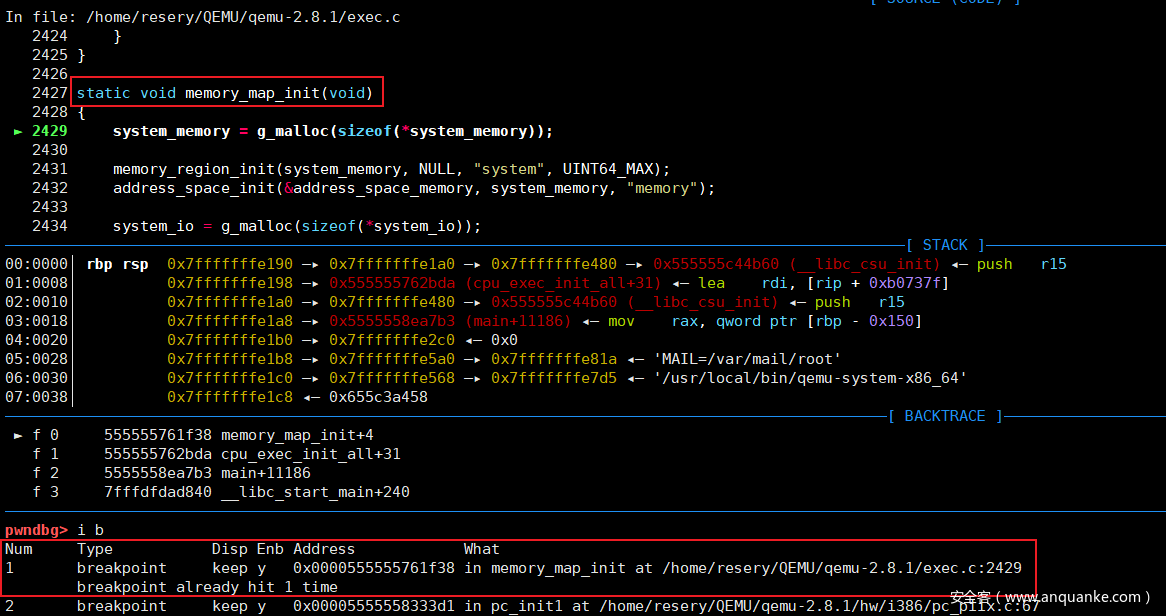
根据返回的结果可以看出来我的猜想是正确的,所以我们就可以确定system_memory和system_io是由memory_map_init函数来进行赋值的,然后再继续观察一下memory_map_init函数,可以看到函数内先使用g_malloc分配一块内存然后把返回的地址当成参数传给另外的两个函数memory_region_init和address_space_init,对应的我们来看一下这两个函数
memory_region_init()
void memory_region_init(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size)
{
object_initialize(mr, sizeof(*mr), TYPE_MEMORY_REGION);
mr->size = int128_make64(size);
if (size == UINT64_MAX) {
mr->size = int128_2_64();
}
mr->name = g_strdup(name);
mr->owner = owner;
mr->ram_block = NULL;
if (name) {
char *escaped_name = memory_region_escape_name(name);
char *name_array = g_strdup_printf("%s[*]", escaped_name);
if (!owner) {
owner = container_get(qdev_get_machine(), "/unattached");
}
object_property_add_child(owner, name_array, OBJECT(mr), &error_abort);
object_unref(OBJECT(mr));
g_free(name_array);
g_free(escaped_name);
}
}
可以看到函数定义的参数里面,对第一个参数使用的是*,在c语言中如果说传入的参数是一个地址,然后在函数定义里面参数定义的为指针,这样可以达到和C++里面传引用一样的效果,所以说memory_region_init函数也对system_memory进行了修改。然后我们继续看一下内部的代码,首先是进行了一个类型和对象初始化,初始化之后,给mr->size赋值,int128_make64的功能是给一个128的有符号数赋值,只赋低64位,然后高64位赋值为0,对应于我们参数传的size(memory_map_init —- UINT64_MAX)是0xffffffffffffffff,然后检测size是不是0x0000000000000000ffffffffffffffff,如果是的话就给mr->size赋值,int128_2_64的功能是低64位赋值为0,高64为赋值为1,所以经过这两处之后,mr->size的值就应该是0x00000000000000010000000000000000,再根据传进来的参数,给对应的成员变量赋值,最后检测一下name是否存在,如果name存在的话,还需要进行一些操作,首先是把name进行一下过滤,需要过滤掉这几个字符’/‘ 、’[‘ 、’\\‘ 、’]’,然后是把这个system_memory进行实例化,然后free掉多余的内容;
所以memory_region_init函数主要做的功能就是初始并且实例化system_memory(这里仅仅是使用system_memory来举例子,不止system_memory使用memory_region_init来进行初始化)
address_space_init()
void address_space_init(AddressSpace *as, MemoryRegion *root, const char *name)
{
memory_region_ref(root);
memory_region_transaction_begin();
as->ref_count = 1;
as->root = root;
as->malloced = false;
as->current_map = g_new(FlatView, 1);
flatview_init(as->current_map);
as->ioeventfd_nb = 0;
as->ioeventfds = NULL;
QTAILQ_INIT(&as->listeners);
QTAILQ_INSERT_TAIL(&address_spaces, as, address_spaces_link);
as->name = g_strdup(name ? name : "anonymous");
address_space_init_dispatch(as);
memory_region_update_pending |= root->enabled;
memory_region_transaction_commit();
}
对地址空间进行初始化,第3行的memory_region_ref在这里是没有发挥作用的,然后初始化flatview,给他的成员变量全部赋初值,然后初始化他的listeners(回调函数),初始化对应的addressspace链表,然后初始化dispatch(后期通过它来实现GPA到HVA的转换),最后通知kvm我们修改了这块region
memory_region_allocate_system_memory()
void memory_region_allocate_system_memory(MemoryRegion *mr, Object *owner,
const char *name,
uint64_t ram_size)
{
uint64_t addr = 0;
int i;
if (nb_numa_nodes == 0 || !have_memdevs) {
allocate_system_memory_nonnuma(mr, owner, name, ram_size);
return;
}
memory_region_init(mr, owner, name, ram_size);
for (i = 0; i < MAX_NODES; i++) {
uint64_t size = numa_info[i].node_mem;
HostMemoryBackend *backend = numa_info[i].node_memdev;
if (!backend) {
continue;
}
MemoryRegion *seg = host_memory_backend_get_memory(backend,
&error_fatal);
if (memory_region_is_mapped(seg)) {
char *path = object_get_canonical_path_component(OBJECT(backend));
error_report("memory backend %s is used multiple times. Each "
"-numa option must use a different memdev value.",
path);
exit(1);
}
host_memory_backend_set_mapped(backend, true);
memory_region_add_subregion(mr, addr, seg);
vmstate_register_ram_global(seg);
addr += size;
}
}
这个函数有两个分支,第一个分支就是如果说我们没有设置numa选项,那么就直接调用allocate_system_memory_nonnuma然后返回,第二个分支就是如果说设置了numa选项,那么就需要再做一些其它操作,但是此篇文章里我们只分析allocate_system_memory_nonnuma,关于numa暂且不过多的分析
tips:
numa相关概念(来源:维基百科)
非统一内存访问架构(英语:Non-uniform memory access,简称NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
allocate_system_memory_nonnuma()
static void allocate_system_memory_nonnuma(MemoryRegion *mr, Object *owner,
const char *name,
uint64_t ram_size)
{
if (mem_path) {
#ifdef __linux__
Error *err = NULL;
memory_region_init_ram_from_file(mr, owner, name, ram_size, false,
mem_path, &err);
if (err) {
error_report_err(err);
if (mem_prealloc) {
exit(1);
}
/* Legacy behavior: if allocation failed, fall back to
* regular RAM allocation.
*/
memory_region_init_ram(mr, owner, name, ram_size, &error_fatal);
}
#else
fprintf(stderr, "-mem-path not supported on this host\n");
exit(1);
#endif
} else {
memory_region_init_ram(mr, owner, name, ram_size, &error_fatal);
}
vmstate_register_ram_global(mr);
}
这个函数里如果说参数中设置了mem_path的话就会多做几步操作,然后再开始初始化ram.mem_path主要的功能是在 guest OS 的内存中创建一个文件,来达到共享内存的目的;这里我们没有设置这个选项就会直接调用memory_region_init_ram来进行初始化ram
memory_region_init_ram()
void memory_region_init_ram(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size,
Error **errp)
{
memory_region_init(mr, owner, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
mr->ram_block = qemu_ram_alloc(size, mr, errp);
mr->dirty_log_mask = tcg_enabled() ? (1 << DIRTY_MEMORY_CODE) : 0;
}
首先调用memory_region_init来初始化ram,完成初始化之后,设置对应的mr的一些值,设置完成之后调用qemu_ram_alloc来给ram分配内存
qemu_ram_alloc() and qemu_ram_alloc_internal()
RAMBlock *qemu_ram_alloc(ram_addr_t size, MemoryRegion *mr, Error **errp)
{
return qemu_ram_alloc_internal(size, size, NULL, NULL, false, mr, errp);
}
static
RAMBlock *qemu_ram_alloc_internal(ram_addr_t size, ram_addr_t max_size,
void (*resized)(const char*,
uint64_t length,
void *host),
void *host, bool resizeable,
MemoryRegion *mr, Error **errp)
{
RAMBlock *new_block;
Error *local_err = NULL;
size = HOST_PAGE_ALIGN(size);
max_size = HOST_PAGE_ALIGN(max_size);
new_block = g_malloc0(sizeof(*new_block));
new_block->mr = mr;
new_block->resized = resized;
new_block->used_length = size;
new_block->max_length = max_size;
assert(max_size >= size);
new_block->fd = -1;
new_block->page_size = getpagesize();
new_block->host = host;
if (host) {
new_block->flags |= RAM_PREALLOC;
}
if (resizeable) {
new_block->flags |= RAM_RESIZEABLE;
}
ram_block_add(new_block, &local_err);
if (local_err) {
g_free(new_block);
error_propagate(errp, local_err);
return NULL;
}
return new_block;
}
qemu_ram_alloc没有做什么别的操作仅仅就是把参数传给了qemu_ram_alloc_internal函数并且调用它;qemu_ram_alloc_internal会先把参数中传进来的size进行页对齐处理,处理之后初始化一个RAMBlock结构,赋一下对应的处置以及标志位,然后调用ram_block_add来分配内存
ram_block_add()
static void ram_block_add(RAMBlock *new_block, Error **errp)
{
RAMBlock *block;
RAMBlock *last_block = NULL;
ram_addr_t old_ram_size, new_ram_size;
Error *err = NULL;
old_ram_size = last_ram_offset() >> TARGET_PAGE_BITS;
qemu_mutex_lock_ramlist();
new_block->offset = find_ram_offset(new_block->max_length);
if (!new_block->host) {
if (xen_enabled()) {
xen_ram_alloc(new_block->offset, new_block->max_length,
new_block->mr, &err);
if (err) {
error_propagate(errp, err);
qemu_mutex_unlock_ramlist();
return;
}
} else {
new_block->host = phys_mem_alloc(new_block->max_length,
&new_block->mr->align);
if (!new_block->host) {
error_setg_errno(errp, errno,
"cannot set up guest memory '%s'",
memory_region_name(new_block->mr));
qemu_mutex_unlock_ramlist();
return;
}
memory_try_enable_merging(new_block->host, new_block->max_length);
}
}
new_ram_size = MAX(old_ram_size,
(new_block->offset + new_block->max_length) >> TARGET_PAGE_BITS);
if (new_ram_size > old_ram_size) {
migration_bitmap_extend(old_ram_size, new_ram_size);
dirty_memory_extend(old_ram_size, new_ram_size);
}
/* Keep the list sorted from biggest to smallest block. Unlike QTAILQ,
* QLIST (which has an RCU-friendly variant) does not have insertion at
* tail, so save the last element in last_block.
*/
QLIST_FOREACH_RCU(block, &ram_list.blocks, next) {
last_block = block;
if (block->max_length < new_block->max_length) {
break;
}
}
if (block) {
QLIST_INSERT_BEFORE_RCU(block, new_block, next);
} else if (last_block) {
QLIST_INSERT_AFTER_RCU(last_block, new_block, next);
} else { /* list is empty */
QLIST_INSERT_HEAD_RCU(&ram_list.blocks, new_block, next);
}
ram_list.mru_block = NULL;
/* Write list before version */
smp_wmb();
ram_list.version++;
qemu_mutex_unlock_ramlist();
cpu_physical_memory_set_dirty_range(new_block->offset,
new_block->used_length,
DIRTY_CLIENTS_ALL);
if (new_block->host) {
qemu_ram_setup_dump(new_block->host, new_block->max_length);
qemu_madvise(new_block->host, new_block->max_length, QEMU_MADV_HUGEPAGE);
/* MADV_DONTFORK is also needed by KVM in absence of synchronous MMU */
qemu_madvise(new_block->host, new_block->max_length, QEMU_MADV_DONTFORK);
}
}
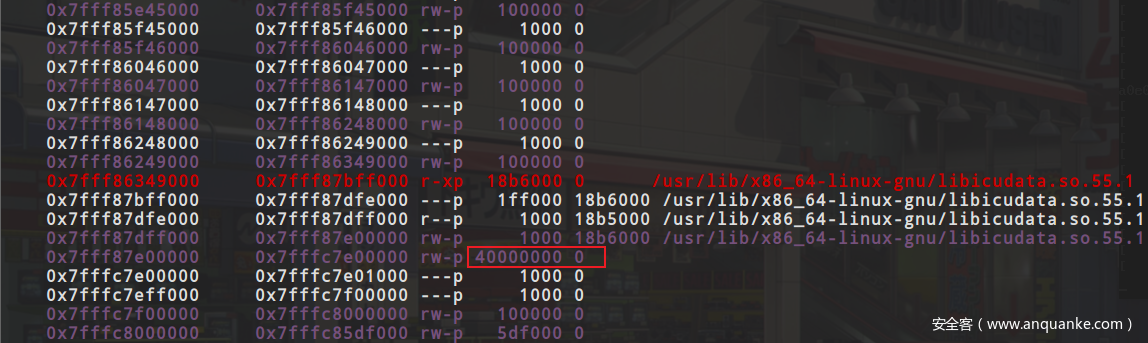
在13行之前都是在ram_list中找对对应的新ram_block应该存放的位置,找到之后检测是否开启了xen,如果说没有开启的话那么就调用phys_mem_alloc来分配实际的内存出来,在这里我们可以动调一下,看一下实际分配出来的内存在哪里,根据下面的两张图可以看出来在调用了phys_mem_alloc之后多出来一块40000000大小的内存(启动参数里我设置的内存大小为1g),对应这里就是guest OS的ram内存空间,
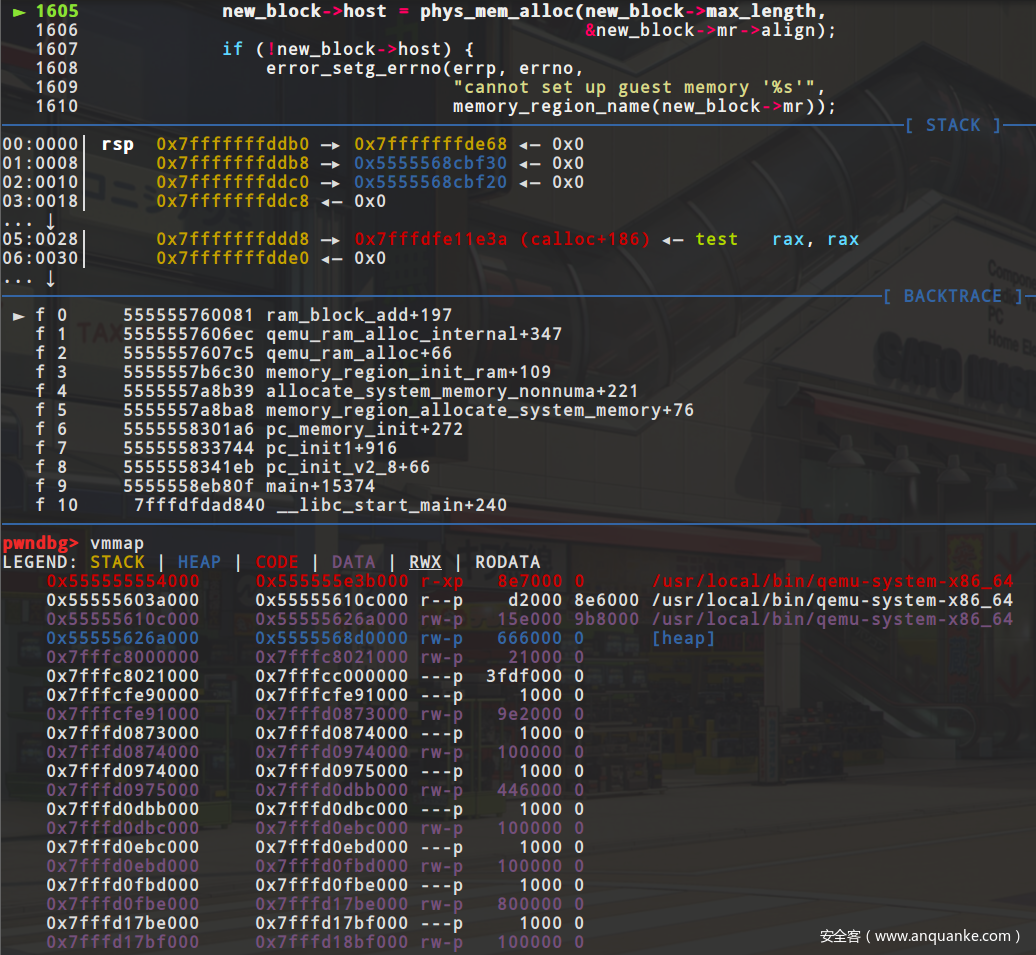
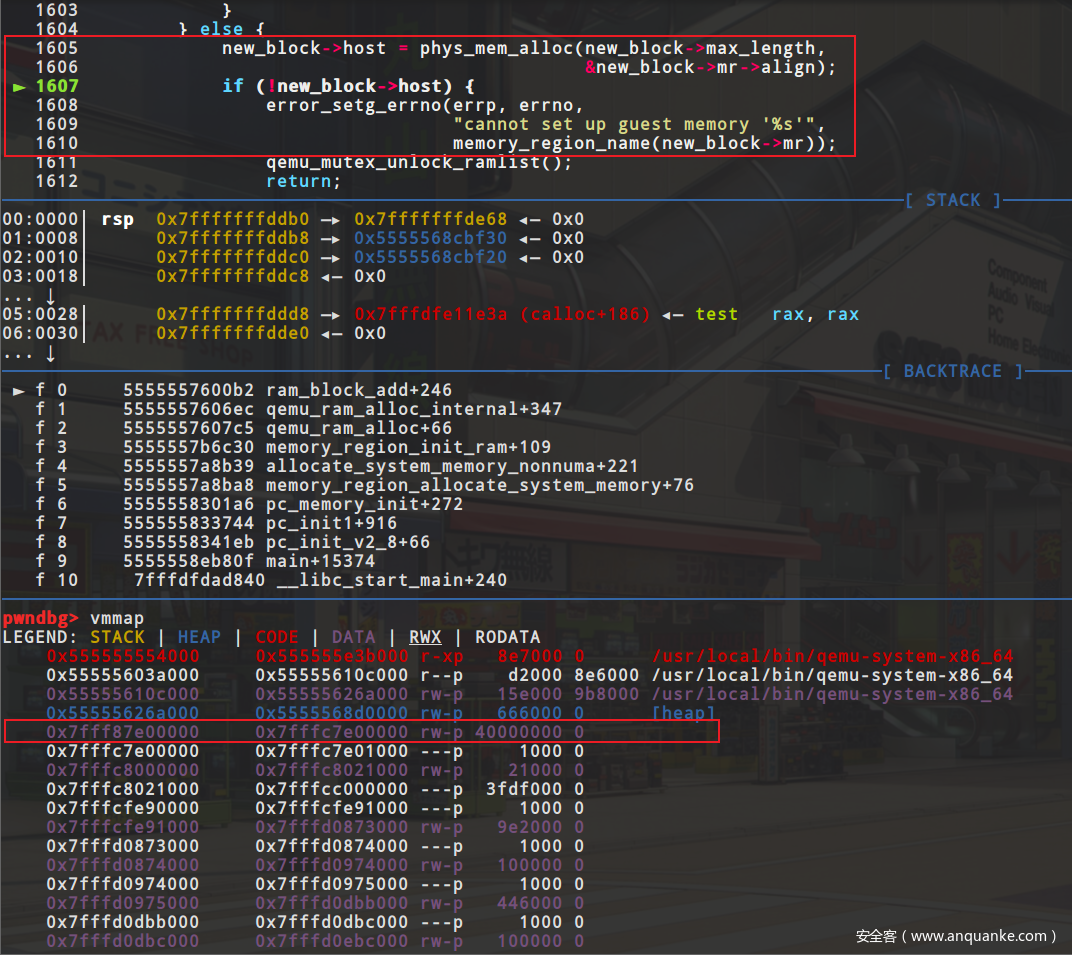
分配完对应的内存之后,就把这块block添加到ram_list链表中,这里采用的是rcu机制,关于rcu机制就略过了,然后更新ram_block的offset和used_length
pc_system_firmware_init()
void pc_system_firmware_init(MemoryRegion *rom_memory, bool isapc_ram_fw)
{
DriveInfo *pflash_drv;
pflash_drv = drive_get(IF_PFLASH, 0, 0);
if (isapc_ram_fw || pflash_drv == NULL) {
/* When a pflash drive is not found, use rom-mode */
old_pc_system_rom_init(rom_memory, isapc_ram_fw);
return;
}
if (kvm_enabled() && !kvm_readonly_mem_enabled()) {
/* Older KVM cannot execute from device memory. So, flash memory
* cannot be used unless the readonly memory kvm capability is present. */
fprintf(stderr, "qemu: pflash with kvm requires KVM readonly memory support\n");
exit(1);
}
pc_system_flash_init(rom_memory);
}
如果说没有添加过多的参数,我们在这个函数里会首先调用old_pc_system_rom_init函数,来进行rom的初始化
old_pc_system_rom_init()
static void old_pc_system_rom_init(MemoryRegion *rom_memory, bool isapc_ram_fw)
{
char *filename;
MemoryRegion *bios, *isa_bios;
int bios_size, isa_bios_size;
int ret;
/* BIOS load */
if (bios_name == NULL) {
bios_name = BIOS_FILENAME;
}
filename = qemu_find_file(QEMU_FILE_TYPE_BIOS, bios_name);
if (filename) {
bios_size = get_image_size(filename);
} else {
bios_size = -1;
}
if (bios_size <= 0 ||
(bios_size % 65536) != 0) {
goto bios_error;
}
bios = g_malloc(sizeof(*bios));
memory_region_init_ram(bios, NULL, "pc.bios", bios_size, &error_fatal);
vmstate_register_ram_global(bios);
if (!isapc_ram_fw) {
memory_region_set_readonly(bios, true);
}
ret = rom_add_file_fixed(bios_name, (uint32_t)(-bios_size), -1);
if (ret != 0) {
bios_error:
fprintf(stderr, "qemu: could not load PC BIOS '%s'\n", bios_name);
exit(1);
}
g_free(filename);
/* map the last 128KB of the BIOS in ISA space */
isa_bios_size = bios_size;
if (isa_bios_size > (128 * 1024)) {
isa_bios_size = 128 * 1024;
}
isa_bios = g_malloc(sizeof(*isa_bios));
memory_region_init_alias(isa_bios, NULL, "isa-bios", bios,
bios_size - isa_bios_size, isa_bios_size);
memory_region_add_subregion_overlap(rom_memory,
0x100000 - isa_bios_size,
isa_bios,
1);
if (!isapc_ram_fw) {
memory_region_set_readonly(isa_bios, true);
}
/* map all the bios at the top of memory */
memory_region_add_subregion(rom_memory,
(uint32_t)(-bios_size),
bios);
}
这个函数被用来加载bios,前面的部分就是在读取bios的相关信息,然后调用memory_region_init_ram来分配出一块内存,然后初始化一个isa_bios为bios的别名,然后把bios添加为rom_memory的子节点,最后再把完整的bios添加为rom_memory的子节点
具体的流程
初始化system_memory和system_io
首先初始化system_memory和system_io,对应代码如下:
MemoryRegion *system_memory = get_system_memory(); //虚拟机的内存地址空间
MemoryRegion *system_io = get_system_io(); //虚拟机的I/O地址空间
内存切割
正如我在上文所注释的那样,为了兼容以致我们可以模拟老版本的机器,所以说我们需要对内存进行切割,分成below_4g和above_4g,对应的代码如下:
if (!pcms->max_ram_below_4g) {
pcms->max_ram_below_4g = 0xe0000000; /* default: 3.5G */
}
lowmem = pcms->max_ram_below_4g;
if (machine->ram_size >= pcms->max_ram_below_4g) {
if (pcmc->gigabyte_align) {
if (lowmem > 0xc0000000) {
lowmem = 0xc0000000;
}
if (lowmem & ((1ULL << 30) - 1)) {
error_report("Warning: Large machine and max_ram_below_4g "
"(%" PRIu64 ") not a multiple of 1G; "
"possible bad performance.",
pcms->max_ram_below_4g);
}
}
}
if (machine->ram_size >= lowmem) {
pcms->above_4g_mem_size = machine->ram_size - lowmem;
pcms->below_4g_mem_size = lowmem;
} else {
pcms->above_4g_mem_size = 0;
pcms->below_4g_mem_size = machine->ram_size;
}
可以看到首先会检测我们在参数中设置的内存是不是大于3.5g如果说是大于3.5g的话,再检测我们设置没设置内存对齐,如果设置了内存对齐那就把lowmem设置成3g,然后比较我们设置的内存和lowmem,把比lowmem大的部分设置成above_4g_mem_size,把比lowmem小的部分设置成below_4g_mem_size
初始化pci_memory
if (pcmc->pci_enabled) {
pci_memory = g_new(MemoryRegion, 1);
memory_region_init(pci_memory, NULL, "pci", UINT64_MAX);
rom_memory = pci_memory;
} else {
pci_memory = NULL;
rom_memory = system_memory;
}
这里会首先检测pci_enabled是不是为1,如果是的话就初始化pci_memory,也是利用memory_region_init函数,和初始化system_memory没啥区别就是对应的名字不一样了,如果说pci_enabled不为1,那么就给pci_memory赋一个空值
分配真正的内存
/* allocate ram and load rom/bios */
if (!xen_enabled()) {
pc_memory_init(pcms, system_memory,
rom_memory, &ram_memory);
} else if (machine->kernel_filename != NULL) {
/* For xen HVM direct kernel boot, load linux here */
xen_load_linux(pcms);
}
调用pc_memory_init函数来完成内存的初始化,接下来就是一直围绕着pc_memory_init函数来展开
检测ram_size 是否等于 below_4g+above_4g
assert(machine->ram_size == pcms->below_4g_mem_size +
pcms->above_4g_mem_size);
给ram分配真正的内存
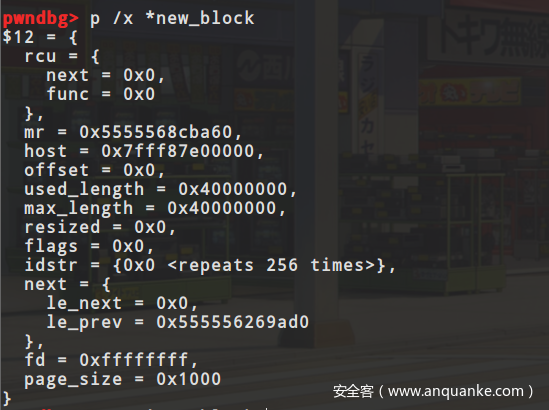
memory_region_allocate_system_memory(ram, NULL, "pc.ram",
machine->ram_size);
调用这个函数来给ram分配真正的内存,对应的会生成一个ram_block结构,这个结构里指明了生成的内存的地址,在ram_list中的偏移,以及它对应的memoryregion,我们可以看一下最后生成的ram_block结果,如下图所示
生成内存树
memory_region_init_alias(ram_below_4g, NULL, "ram-below-4g", ram,
0, pcms->below_4g_mem_size);
memory_region_add_subregion(system_memory, 0, ram_below_4g);
e820_add_entry(0, pcms->below_4g_mem_size, E820_RAM);
if (pcms->above_4g_mem_size > 0) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, NULL, "ram-above-4g", ram,
pcms->below_4g_mem_size,
pcms->above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL,
ram_above_4g);
e820_add_entry(0x100000000ULL, pcms->above_4g_mem_size, E820_RAM);
}
这部分代码对应会生成一个内存树,深度为1,也就是在system_memory下面有一个子节点(ram_below_4g),其中ram_below_4g是ram的别名,如果说我们设置的内存超过了4g,那么还会有另一个子节点(ram_above_4g),同样ram_above_4g也是ram的别名
加载bios
pc_system_firmware_init(rom_memory, !pcmc->pci_enabled);
调用这个函数之后就成功的加载了bios,并且在ram_list中会增加一个bios的节点,并且rom和ram在内存树中属于同级节点,然后bios是在rom之下,但是bios是以别名形式来存储的,它有一个isa-bios的别名和一个完整的bios
给rom分配真正的内存
option_rom_mr = g_malloc(sizeof(*option_rom_mr));
memory_region_init_ram(option_rom_mr, NULL, "pc.rom", PC_ROM_SIZE,
&error_fatal);
vmstate_register_ram_global(option_rom_mr);
memory_region_add_subregion_overlap(rom_memory,
PC_ROM_MIN_VGA,
option_rom_mr,
1);
这里就是给rom分配真正的内存,然后会把rom添加为rom_memory的子节点
其它
fw_cfg = bochs_bios_init(&address_space_memory, pcms);
rom_set_fw(fw_cfg);
if (pcmc->has_reserved_memory && pcms->hotplug_memory.base) {
uint64_t *val = g_malloc(sizeof(*val));
PCMachineClass *pcmc = PC_MACHINE_GET_CLASS(pcms);
uint64_t res_mem_end = pcms->hotplug_memory.base;
if (!pcmc->broken_reserved_end) {
res_mem_end += memory_region_size(&pcms->hotplug_memory.mr);
}
*val = cpu_to_le64(ROUND_UP(res_mem_end, 0x1ULL << 30));
fw_cfg_add_file(fw_cfg, "etc/reserved-memory-end", val, sizeof(*val));
}
if (linux_boot) {
load_linux(pcms, fw_cfg);
}
for (i = 0; i < nb_option_roms; i++) {
rom_add_option(option_rom[i].name, option_rom[i].bootindex);
}
pcms->fw_cfg = fw_cfg;
/* Init default IOAPIC address space */
pcms->ioapic_as = &address_space_memory;
后面就是给fw_cfg设备分配内存,如果说选项里你选择了linux内核的化,就会把内核添加到内存里面,还有一些其它的工作
结论
如果说我们使用下面这条命令来启动虚拟机的化,ram_list链表里的内容就会是这样的
gdb --args x86_64-softmmu/qemu-system-x86_64 --enable-kvm -m 1G -hda Resery.img -vnv :0 -smp4
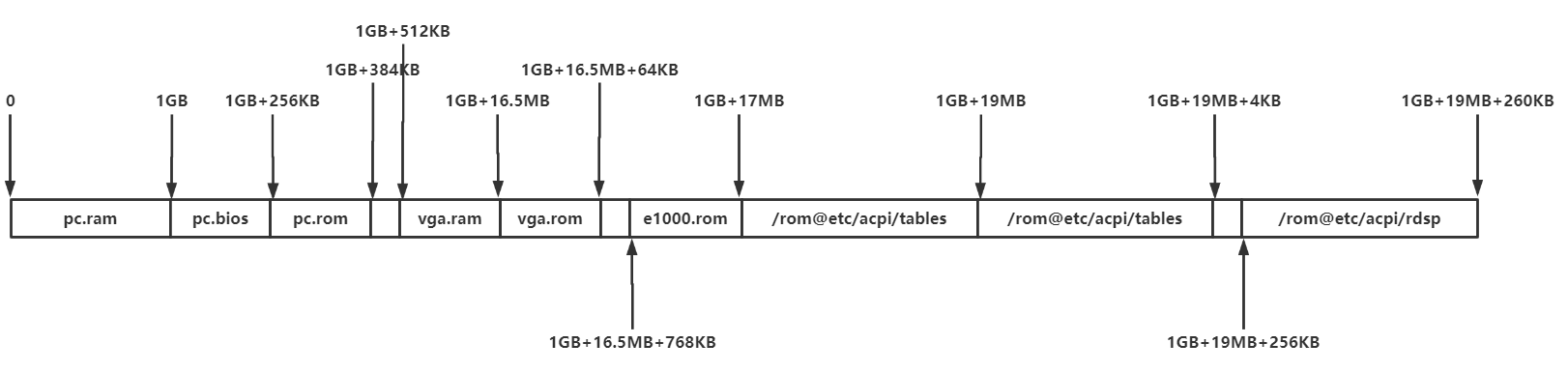
参考资料
https://www.cnblogs.com/ccxikka/p/9477530.html
https://www.anquanke.com/post/id/86412
《QEMU/KVM源码解析与应用》







发表评论
您还未登录,请先登录。
登录