

本系列文章分为两个部分,第一部分的翻译在2018年7月18日已经在安全客上发表过了,当我看完它觉得意犹未尽,想要看第二部分的时候,发现原译者并没有进行翻译。文章第二部分原作者早在2018年11月20日就已经发表了的,时间已经过去2年多了,估计不会再翻译了吧,出于学习的目的,自己就所它翻译了一下,以便学习。自己动手,丰衣足食。
如果想看第一部分,这里是传送门:https://www.anquanke.com/post/id/151898
概述
上一篇文章我们回顾如何使用IDAPython挖掘二进制漏洞的一些基础技术,在这篇文章里我们会继续展开之前的工作并且拓展上一次的IDAPython脚本以检测一个最近在野发现的Microsoft Office漏洞,这个漏洞就是存在于Microsoft Office EQNEDT32.exe中的一个远程代码执行漏洞,也就是我们熟知的Microsoft Office公式编辑器。因为这个公式编辑器发现了许多漏洞,在1月份的时候它上了新闻。微软已经在一次安全更新中删除了这个程序的所有功能。这个程序被修掉的漏洞跟我们上一篇文章中编写脚本识别的漏洞类型完全相同,只不过公式编辑器里对strcpy的调用被编译器优化了,导致我们之前用来探测strcpy的脚本不再适用了。
虽然上一篇文章中我们学习的技术在发现广泛的危险函数中很有用,但是在一些情况下这个脚本无法检测到那些危险的程序结构,这在编译优化中最常见,它会把字符串操作函数(比如strcpy和strcat)替换成内联汇编以提高程序性能。一旦编译优化移除了我们之前文章中依赖的call指令,我们之前的检测方法就不再有效。在这篇文章中,我们将讨论如何识别危险函数调用,即使这个函数调用本身已经被优化内联。
在能够识别strcpy的内联call之前,我们需要先了解内联strcpy是什么样子的。我们来看看下面的图,显示了strcpy内联调用的反汇编以及F5伪C代码。
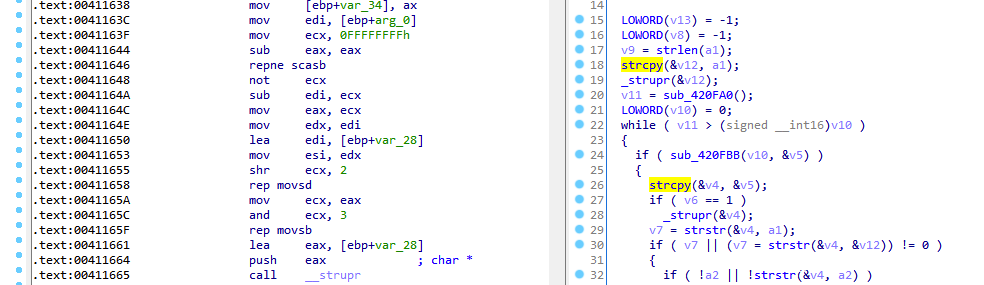
在上面的截图中,我们可以看到右侧的反编译输出显示调用了strcpy,但是我们在左侧的反汇编视图中并没有看到相应的strcpy调用。在查找内联字符串函数时,需要注意的是,内联的一个共同特性是在执行字符串操作时使用“重复”汇编指令(rep、repnz、repz)。了解了这一点,让我们开始深入反汇编,看看编译器在上面的反汇编中使用了什么来替换strcpy。
首先,我们观察0x411646处的指令,这个指令通常用于获取字符串的长度(通常在编译器内联strlen()时使用),查看用于设置repne scasb调用的参数,我们可以看到它正在获取字符串“arg_0”的长度,由于执行strcpy需要知道源字符串的长度(并因此知道要复制的字节数),因此这通常是执行strcpy的第一步。
接下来,我们继续往下看,在rep movsd和rep movsb中看到两个类似的说明,这些指令将ESI寄存器中的字符串复制到EDI寄存器中。这两条指令之间的区别在于rep movsd指令将双字从ESI移动到EDI,而rep movsb只复制字节。这两条指令根据ECX寄存器中的值重复复制指令多次。
查看上面的代码,我们可以观察到代码使用 repne scasb 指令找到的字符串长度来确定要复制的字符串的大小,我们可以通过0x41164C处的指令看到,字符串的长度存储在eax和ecx中。在执行rep movsd指令之前,我们可以看到ECX右移了2。这会导致仅将源字符串中的完整DWORD复制到目标。接下来,我们看到,在指令0x41165A处,存储的字符串长度被移回ECX,然后按位与3。这会导致将rep movsd指令中未复制的任何剩余字节复制到目的缓冲。
使用内联strcpy()自动查找漏洞
既然我们了解了编译器如何优化strcpy函数调用,我们就能够增强漏洞搜索脚本,使我们能够找到出现内联strcpy的实例。为了帮助我们做到这一点,我们将使用IDAPython API和它为我们提供的搜索功能。看看上面的部分,strcpy或多或少唯一的主要指令是rep movsd,紧接着是rep movsb指令,用于复制任何剩余的未复制字节。
因此,使用IDAPython API搜索rep movsd的所有实例,后跟rep movsb7个字节,得到以下代码片段:
ea = 0
while ea != BADADDR:
addr = FindText(ea+2,SEARCH_DOWN|SEARCH_NEXT, 0, 0, "rep movsd");
ea = addr
if "movsb" in GetDisasm(addr+7):
print "strcpy found at 0x%X"%addr
如果我们对EQNEDT32.exe运行此命令,则会在IDA Pro中获得以下输出:
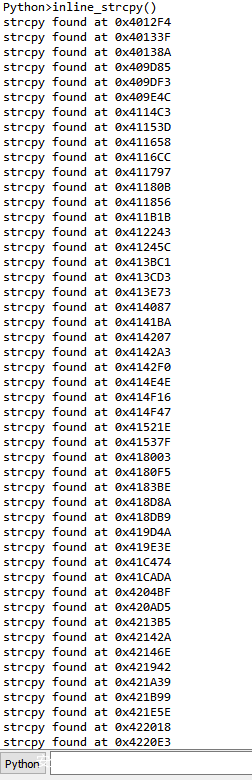
我们查看脚本检测到的内联strcpy的所有实例,我们会发现几个实例,在这些实例中,此脚本找到的不是strcpy而是类似的函数,这个函数就是strcat()。一旦我们考虑到这些函数在功能上的相似性,这就很有意思了,strcat和strcpy都是危险的字符串复制函数,它们将源字符串的整个长度复制到目标字符串中,而不考虑目标缓冲区的大小。此外,strcat在程序中引入了与strcpy同样的危险,使用相同的脚本找到这两个函数是一举两得的方法。
现在我们有了在代码中查找内联strcpy和strcat的代码,我们可以将其与前面的代码一起添加,以便专门搜索将数据复制到堆栈缓冲区的内联strcpy和strcat,这为我们提供了如下所示的代码片段:
# Check inline functions
info = idaapi.get_inf_structure()
ea = 0
while ea != BADADDR:
addr = FindText(ea+2,SEARCH_DOWN|SEARCH_NEXT, 0, 0, "rep movsd");
ea = addr
_addr = ea
if "movsb" in GetDisasm(addr+7):
opnd = "edi" # Make variable based on architecture
if info.is_64bit():
opnd = "rdi"
val = None
function_head = GetFunctionAttr(_addr, idc.FUNCATTR_START)
while True:
_addr = idc.PrevHead(_addr)
_op = GetMnem(_addr).lower()
if _op in ("ret", "retn", "jmp", "b") or _addr < function_head:
break
elif _op == "lea" and GetOpnd(_addr, 0) == opnd:
# We found the origin of the destination, check to see if it is in the stack
if is_stack_buffer(_addr, 1):
print "0x%X"%_addr
break
else: break
elif _op == "mov" and GetOpnd(_addr, 0) == opnd:
op_type = GetOpType(_addr, 1)
if op_type == o_reg:
opnd = GetOpnd(_addr, 1)
addr = _addr
else:
break
运行上述脚本并分析结果后,我们可以看到结果中包含了32个位置,编译器在这些位置内联了strcpy()或strcat()调用,并使用它们将字符串复制到堆栈缓冲区中。
改进堆栈缓冲区检查
此外,既然我们对IDA Python有了一些额外的经验,让我们改进以前的脚本,以便编写与所有最新版本的IDA Pro兼容的脚本,在不同版本的IDA上运行的脚本非常有用,因为目前许多IDA用户仍在使用IDA6 API,而其他许多用户已经升级到较新的IDA7。
当IDA7发布时,它对API进行了大量不向后兼容的更改,因此,我们需要执行一些修改,以使我们的is_stack_buffer()函数与IDA Python API的IDA6和IDA7版本兼容。更糟糕的是,IDA不仅修改了IDA6和IDA7之间的get_stkvar()函数签名,而且似乎还引入了一个bug(删除了功能),使得get_stkvar()函数不再自动处理具有负偏移量的堆栈变量。
更新一下内容,我在下面包含了is_stack_buffer()函数:
def is_stack_buffer(addr, idx):
inst = DecodeInstruction(addr)
return get_stkvar(inst[idx], inst[idx].addr) != None
首先,我们通过添加try-catch来包围对get_stkvar()的调用,并引入一个变量来保存get_stkvar()的返回值,从而开始引入此功能。因为我们上一篇文章是基于IDA6的,所以我们的“try” 异常块将处理在IDA6中的兼容问题,它将抛出一个异常,导致我们在“catch”异常块中处理IDA7 API。
现在,为了正确处理IDA7 API,在catch异常块中,我们必须向get_stkvar()调用传递一个额外的“指令”参数,并检查inst[idx].addr的值。我们可以将“inst[idx].addr”视为已转换为无符号整数的带符号整数。不幸的是,由于IDA7 API中的错误,get_stkvar()不再对该值执行所需的转换,因此,对负值“inst[idx].addr”不能正常工作。此错误已报告给Hex-Rays团队,但在编写本文时,尚未打补丁,需要我们在将负数传递给函数之前将负数转换为正确的Python表示形式。为此,我们检查是否设置了值的带符号位,如果设置了,则使用2的补码将其转换为正确的负数表示。
def twos_compl(val, bits=32):
"""compute the 2's complement of int value val"""
# if sign bit is set e.g., 8bit: 128-255
if (val & (1 << (bits - 1))) != 0:
val = val - (1 << bits) # compute negative value
return val # return positive value as is
def is_stack_buffer(addr, idx):
inst = DecodeInstruction(addr)
# IDA < 7.0
try:
ret = get_stkvar(inst[idx], inst[idx].addr) != None
# IDA >= 7.0
except:
from ida_frame import *
v = twos_compl(inst[idx].addr)
ret = get_stkvar(inst, inst[idx], v)
return ret
Microsoft Office漏洞
公式编辑器应用程序是一个很好的示例程序,因为直到最近,它还是一个广泛分布的真实世界应用程序,我们可以使用它来测试我们的IDAPython脚本。此应用程序对攻击者来说是极具吸引力的目标,因为除了广泛分发之外,它还缺乏常见的漏洞利用缓解措施,包括DEP、ASLR和堆栈Cookie。
运行我们刚刚编写的IDA Python脚本可以查找并标记许多地址,包括地址0x411658。进一步分析发现,这正是导致CVE2017-11882(公式编辑器中发现的远程代码执行漏洞)的代码片段。
此外,在CVE2017-11882公开发布后的一段时间里,安全研究人员开始将重点转向EQNEDT32.exe,这是因为微软做了创造性的工作手动修补补丁(这引发了传言,微软不知何故将源代码丢失到了EQNEDT32.exe)]。安全界对此越来越感兴趣,导致随后在EQNEDT32.exe中发现了许多其他漏洞(其中大部分是堆栈缓冲区溢出)。这些漏洞包括:CVE-2018-0802、CVE-2018-0804、CVE-2018-0805、CVE-2018-0806、CVE-2018-0807、CVE-2018-0845和CVE-2018-0862。虽然围绕大多数漏洞的详细信息相对较少,但考虑到我们执行的IDAPython脚本的结果,我们不用对在此应用程序中发现许多其他漏洞感到奇怪。
参考
[1].Introduction to IDAPython for Vulnerability Hunting – Part 2






发表评论
您还未登录,请先登录。
登录