

个人赛,最后总排名第三,AK了RE部分。
decryption-100
Try to decrypt me!
main函数
发现代码还原的很好,可以可清楚地看到整个逻辑
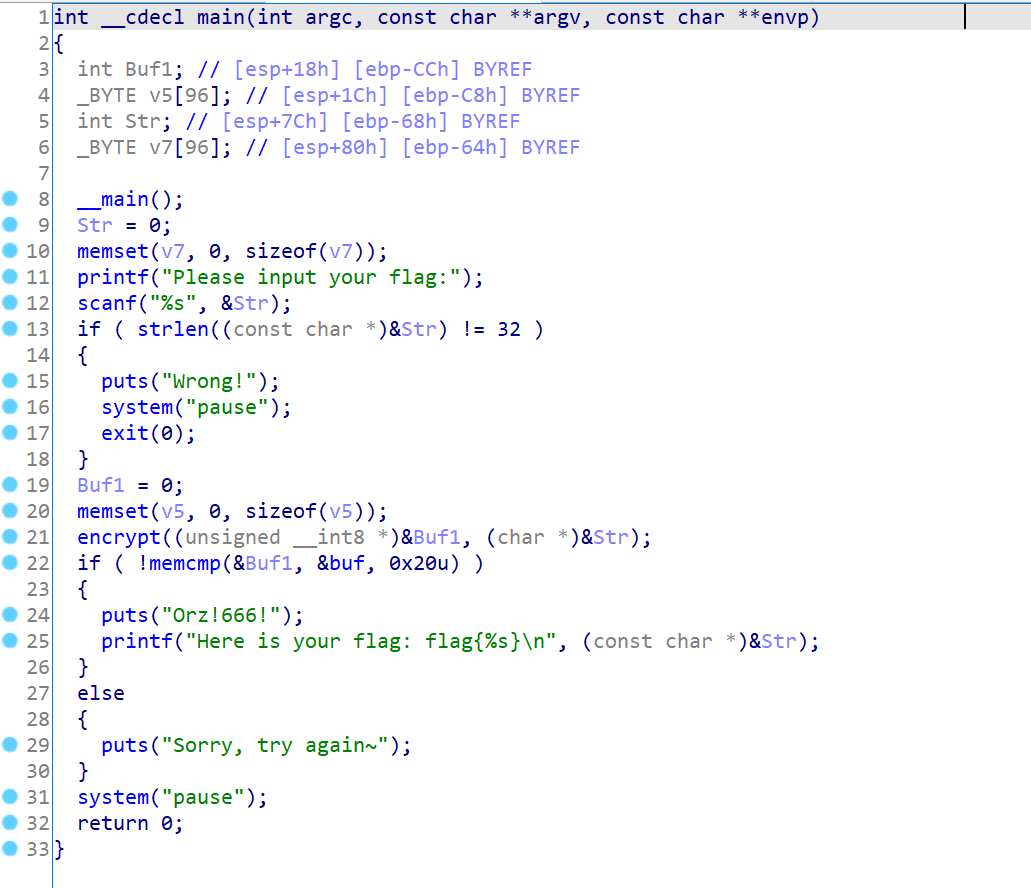
其中第一个限制就是要求输入的字符长度为32位,否则就会直接退出,然后通过一个加密函数把输入的内容加密,加密之后通过memcmp进行比对,这也是一种非常常见的RE模型,也就是让你还原encrypt的过程
encrypt函数
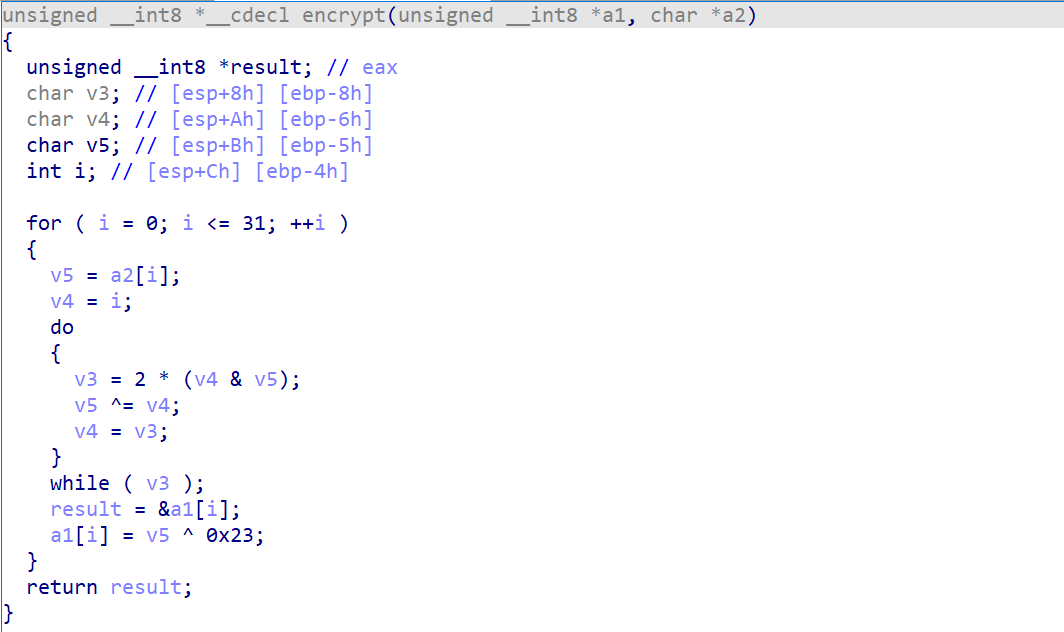
很清楚的可以发现一个特性,那么就是程序的加密过程都是单字节相关的,这意味着我们只需要逐字节的爆破比对就可以得到加密前的结果,由于这里伪代码是C的,所以我们考虑直接用C++编写爆破代码。
导出比对内容
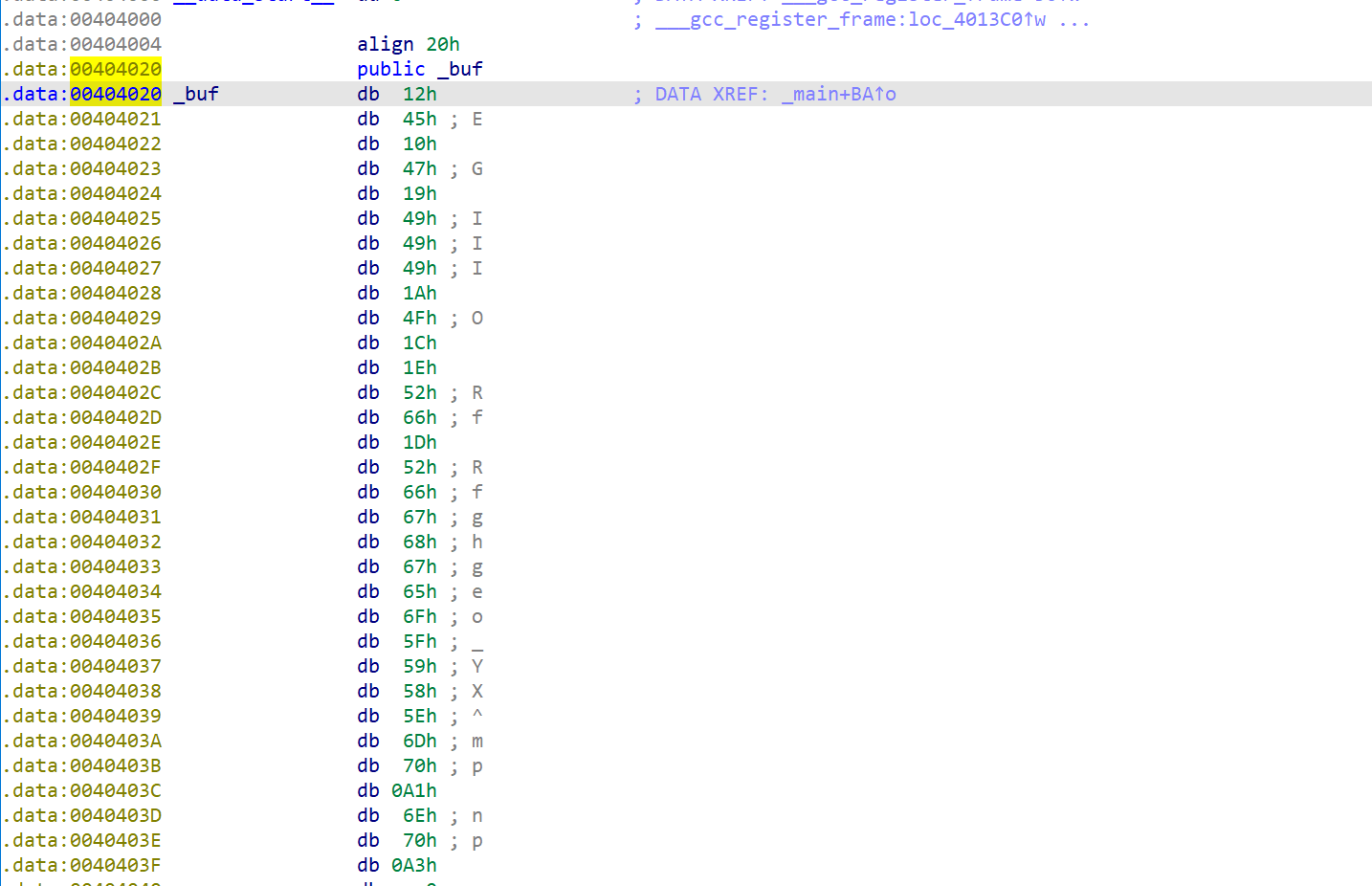
双击进入比对的内容,发现没有识别为字节数组,我们按下小键盘的*键
就可以转换为数组的形式显示
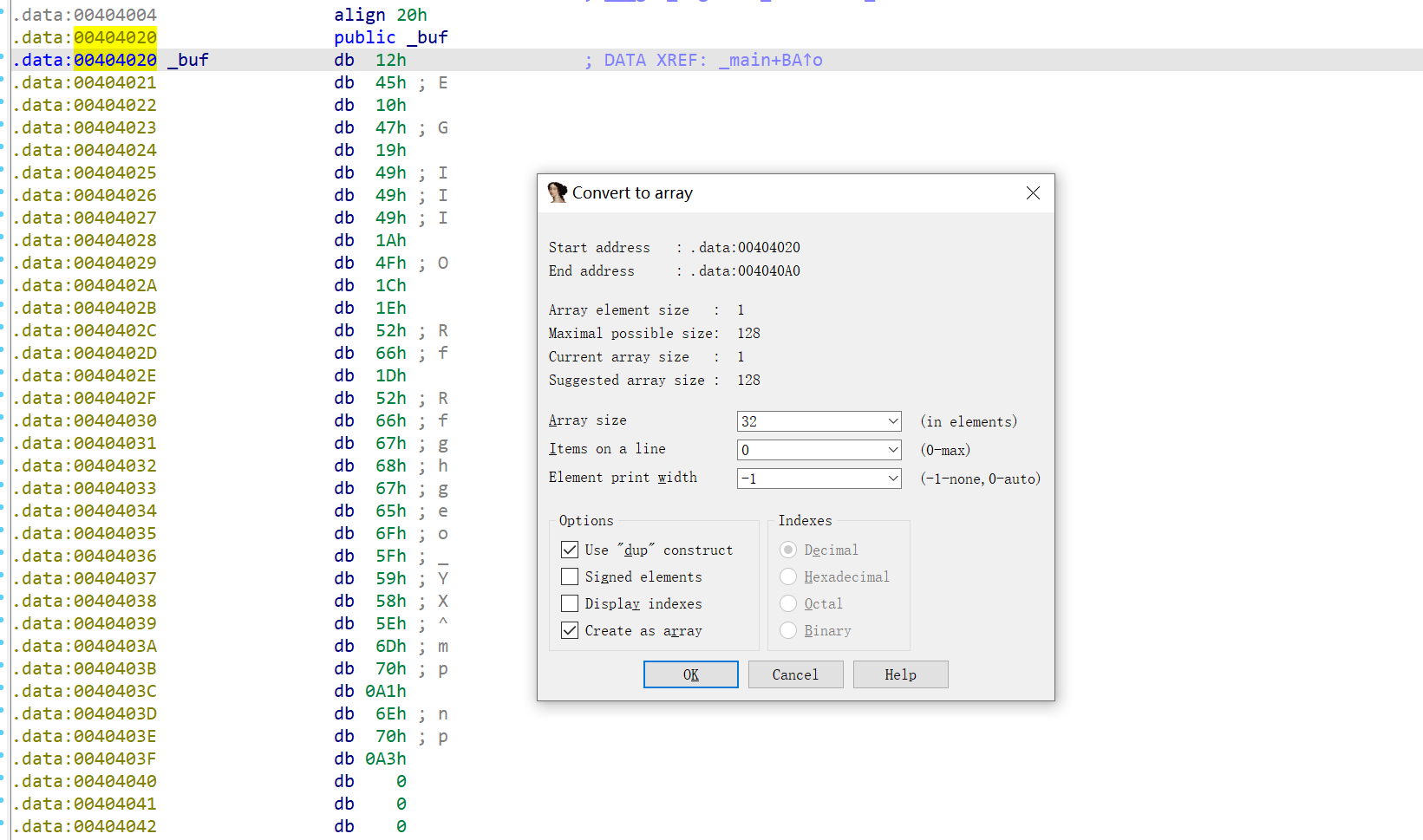
再按下Shift + E,就可以把内容都提取出来了
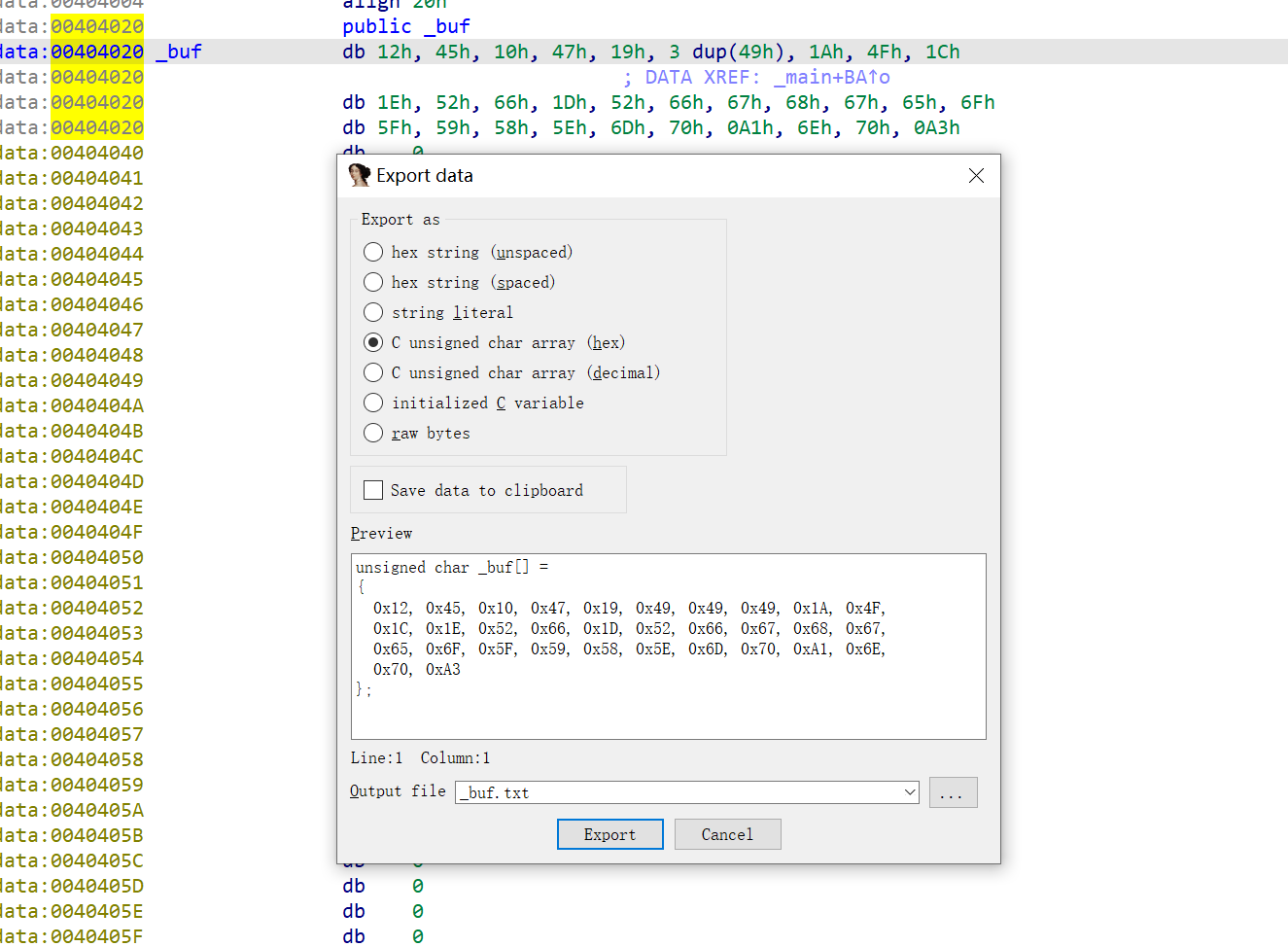
爆破程序
#include <cstdio>
unsigned char _buf[] =
{
0x12, 0x45, 0x10, 0x47, 0x19, 0x49, 0x49, 0x49, 0x1A, 0x4F,
0x1C, 0x1E, 0x52, 0x66, 0x1D, 0x52, 0x66, 0x67, 0x68, 0x67,
0x65, 0x6F, 0x5F, 0x59, 0x58, 0x5E, 0x6D, 0x70, 0xA1, 0x6E,
0x70, 0xA3
};
unsigned char ans[32];
int main()
{
unsigned char v3; // [esp+8h] [ebp-8h]
unsigned char v4; // [esp+Ah] [ebp-6h]
unsigned char v5; // [esp+Bh] [ebp-5h]
for (int i = 0; i <= 31; ++i)
{
for (int j = 0; j <= 255; j++)
{
v5 = j;
v4 = i;
do
{
v3 = 2 * (v4 & v5);
v5 ^= v4;
v4 = v3;
} while (v3);
if ((v5 ^ 0x23) == _buf[i])
{
ans[i] = j;
break;
}
}
}
printf("%s", ans);
return 0;
}
这里有一个坑点就是要注意一下在爆破比对的时候,比对的类型要一致,否则这道题就会有两个字节出不来结果。
obfu-200
小红电脑上的文件被黑客加密了,只留下了一个解密程序,但需要支付比特币购买序列号才能使用,你能帮助小红破解这个程序吗?
压缩包给出了两个文件

用IDA打开后,发现这道题的符号信息基本上都被清楚了,故尝试用字符串进行搜索

查找引用找到对应位置
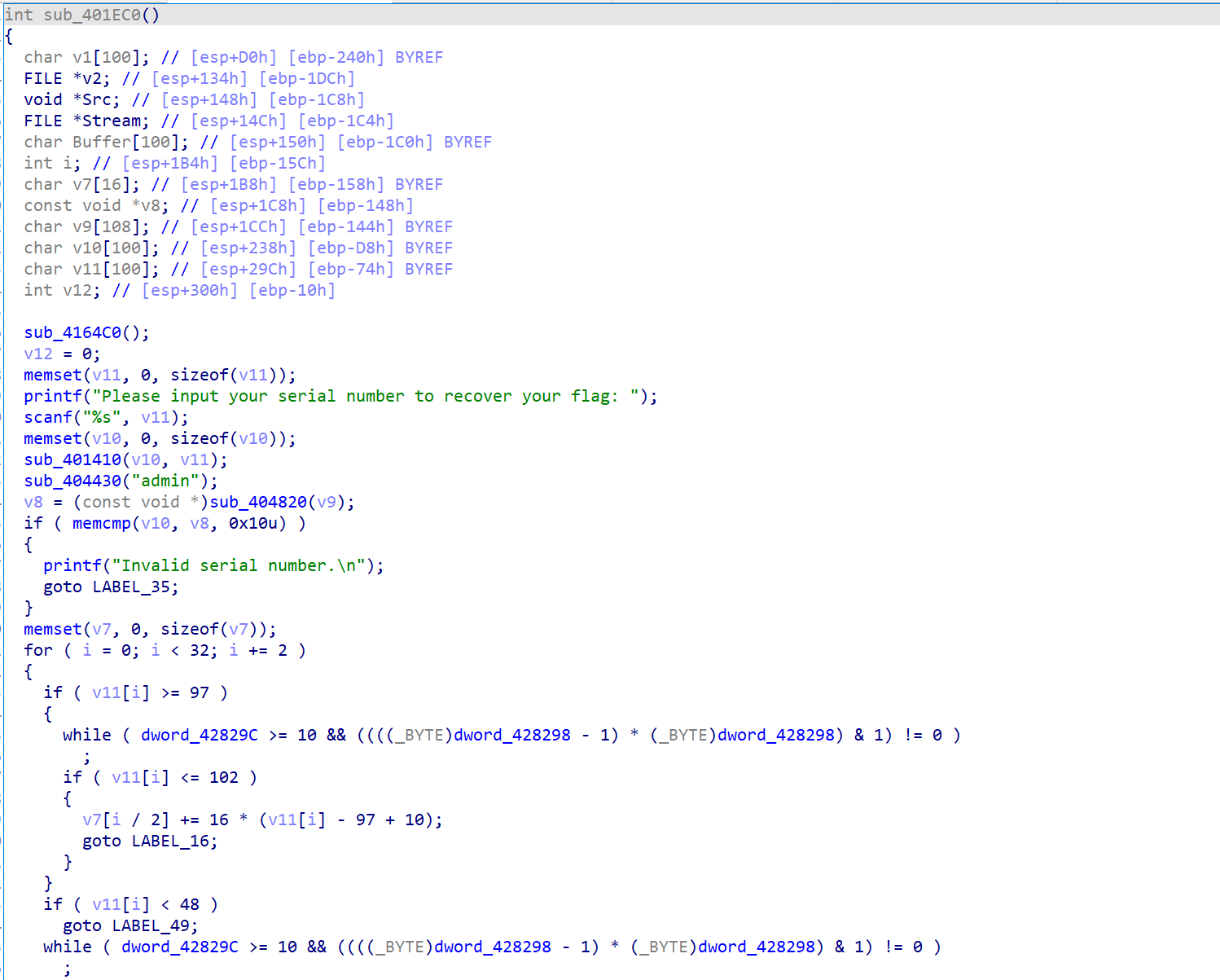
发现程序逻辑相当的复杂,但是还是大概可以看出和上一题类似的一个模型,就是通过先加密,然后再比对来进行验证。
加密函数
观察代码可以发现输入的内容都被传入了sub_401410函数进行进一步的加密。并且第一个参数接受加密后的内容,第二个参数传入要加密的内容。
对我们已知的变量名称进行重命名,并且对已知的类型进行重新操作后,我们可以得到一份比较舒服的伪代码
第一部分

虽然不知道他的那个while是在干什么,但是通过动态调试可以发现,这一段其实就在把你输入的16进制字符串转换为内部储存的字节形式。
也就是从输入内容的32位字符串,变成了16位字节。
第二部分

这里其实是一个for循环,直到idx == 16的时候结束,不过ida的伪代码识别成while循环了
也就是一个加密的过程,所做的事情就是把en1加密后的内容进行第二部分的加密,但是我也不清楚他干了啥,但是简单的一看可以发现几个特征
1.首先就是当前字节的内容和前后两个字节的内容相关,虽然单字节爆破变成了双字节,但是这个爆破范围还是能够在接受范围内的
2.通过这个代码,我们有16个未知数和16个等式,其实我们可以直接通过z3约束来解出结果。
第三部分
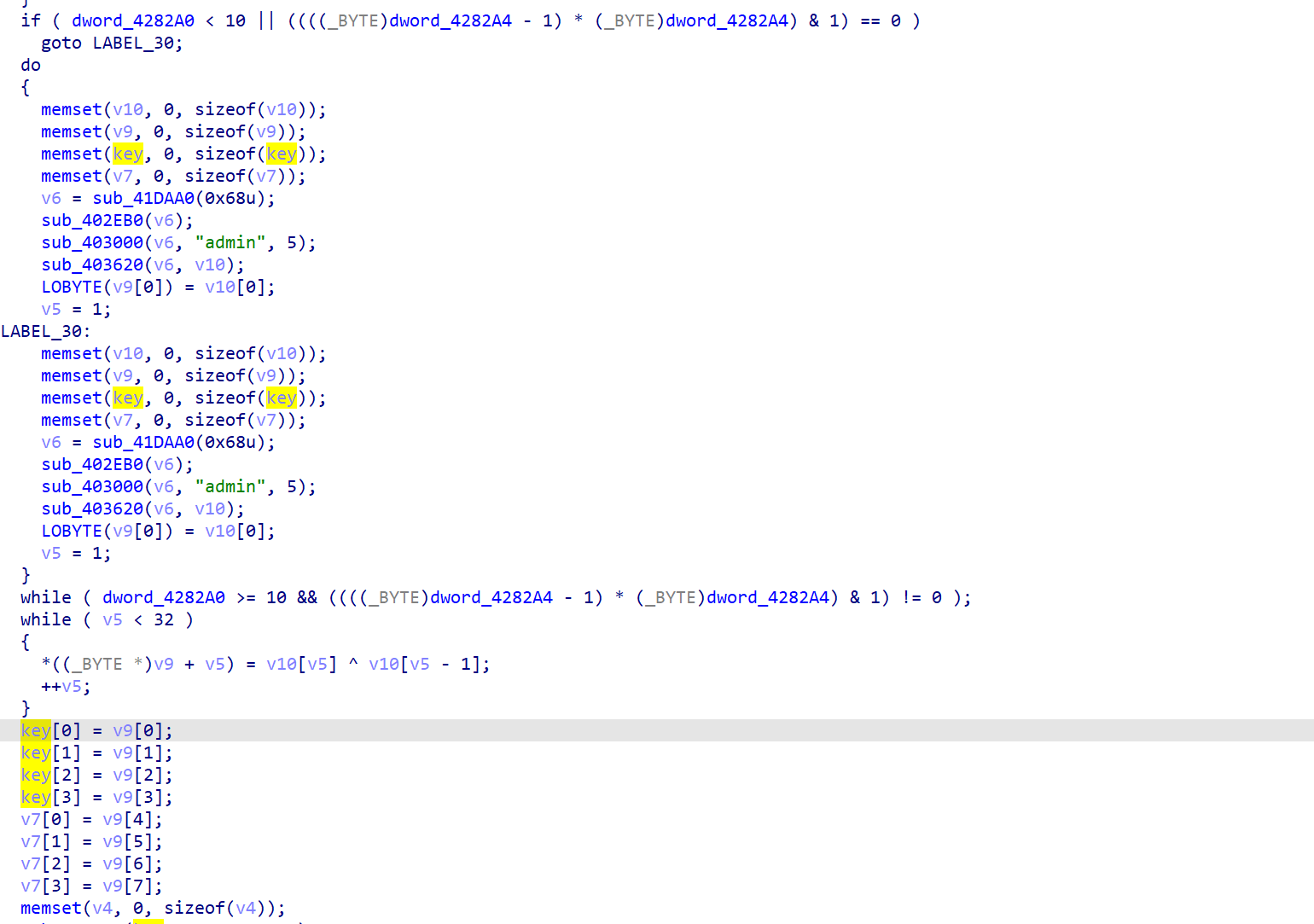
不知道这里这一块在干什么,但是经过测试可以发现这一块的内容所生成的数据都是固定的(不会受到输入数据的影响),所以我们可以不进行分析
第四部分

可以发现最后生成的key是固定的,我们所需要分析的就是sub_402B70函数了,他传入了en2,也就是我们之前加密的内容,并且传入了key(名字是我分析之后修改的)
进入分析之后发现,虽然代码相当的复杂,分析也毫无头绪

我们可以注意到这样的函数
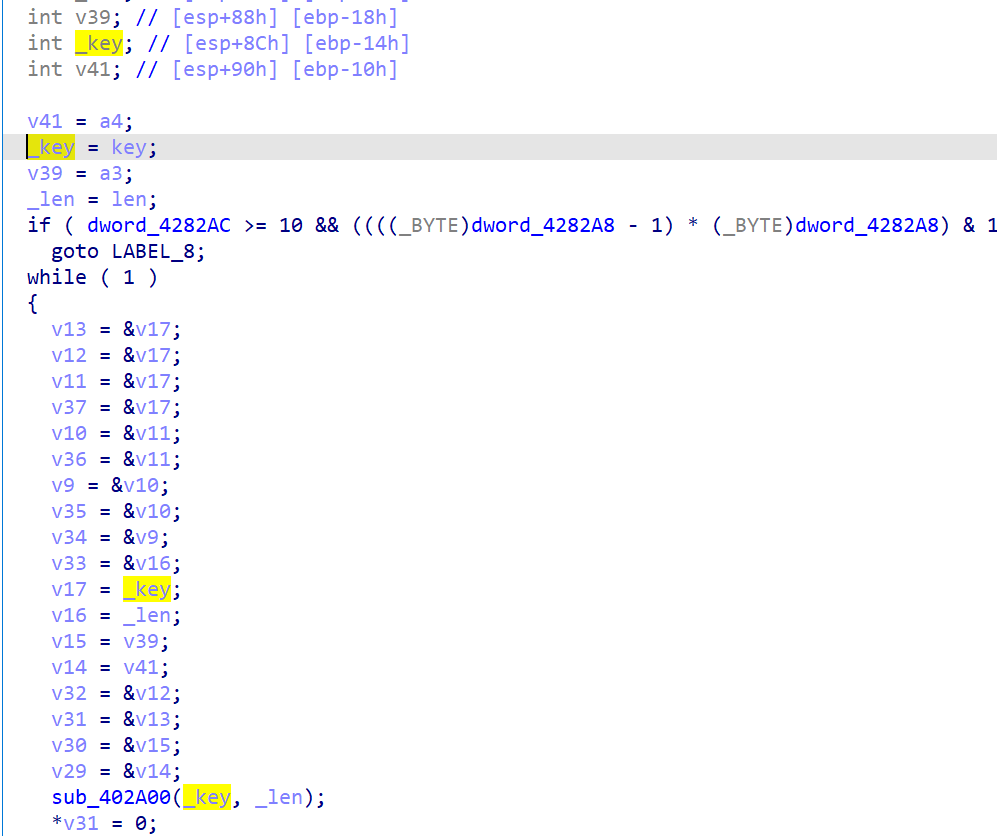
加密程序往里面传入了固定的key值和长度16,我们非常有理由怀疑这里就是加密的主要逻辑
点进去分析就可以直接发现,其实这就是一个rc4加密
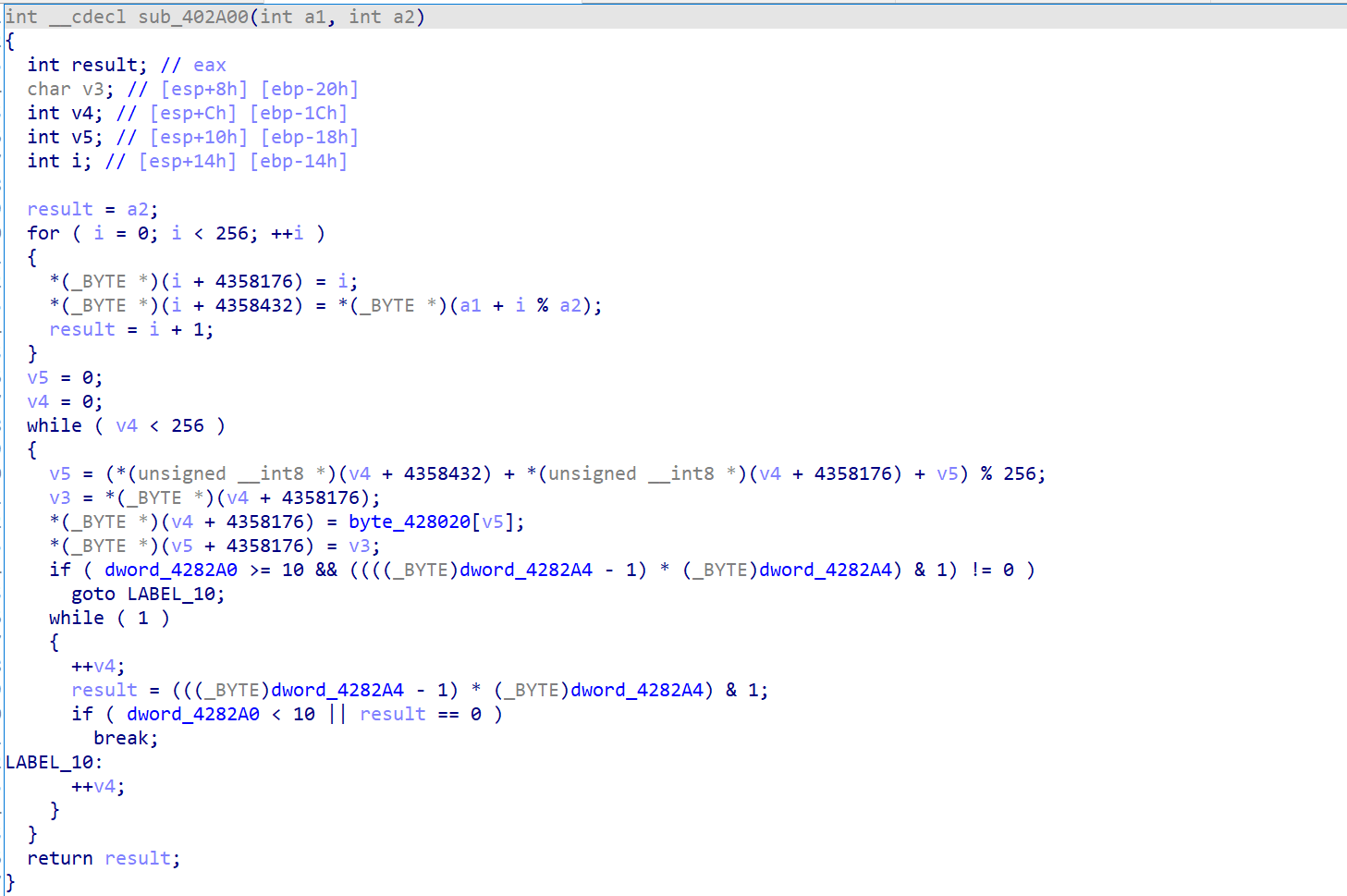
这里说一点识别的窍门,但主要还是见得多就知道了
rc4加密最显著的特征就是他的循环次数是256,在初始化的过程中会生成一个内容为0-255的数组(有些时候会直接赋值)
而这里的循环的次数和循环内所干的事情都符合,并且我们可以发现他对传入的key的信息进行处理,所以我们就可以大胆的猜测这里是rc4
本来以为分析到这里应该也就差不多了,结果发现后面居然还有一层加密
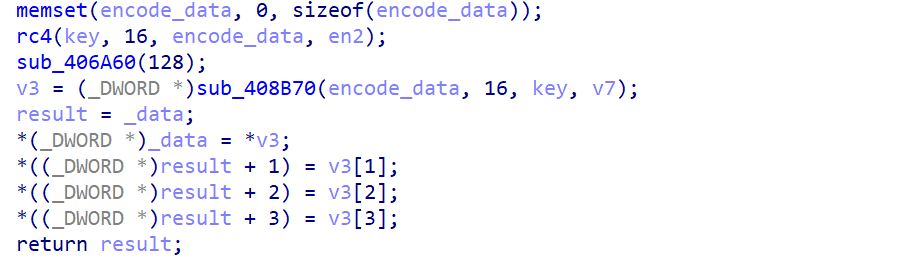
加密后的内容传回到了encode_data中,并且又传递给了下一个函数。
这个函数我显然不是很脸熟,但是我通过Findcrypt插件找到了他的关键

可以发现在这个函数的内部实际上调用了

这部分的内容,所以我们大胆猜测这里其实就是AES加密,并且key的内容和rc4的key一致(正好两者要求也都是16位),v7也就是AES加密的iv。
到此加密函数就结束了
解密程序
我们需要完全的倒推内容
1.AES加密
2.RC4加密
3.可爆破的加密
最后得到的内容就是我们要输入的字节信息
程序中直接对第三步用z3约束进行求解(是真的好用)
其他的数据内容是通过动态调试提取得到的
from Crypto.Cipher import AES, ARC4
from z3 import *
iv = bytes([0x6E, 0xD6, 0xCE, 0x61, 0xBB, 0x8F, 0xB7, 0xF3, 0x10, 0xB7, 0x70, 0x45, 0x9E, 0xFC, 0xE1, 0xB1])
key = bytes([0x8C, 0xE5, 0x1F, 0x93, 0x50, 0xF4, 0x45, 0x11, 0xA8, 0x54, 0xE1, 0xB5, 0xF0, 0xA3, 0xFB, 0xCA])
m = bytes([0x21, 0x23, 0x2F, 0x29, 0x7A, 0x57, 0xA5, 0xA7, 0x43, 0x89, 0x4A, 0x0E, 0x4A, 0x80, 0x1F, 0xC3])
aes = AES.new(key, iv=iv, mode=AES.MODE_CBC)
c = aes.encrypt(m)
rc4 = ARC4.new(key)
target = rc4.decrypt(c)
solver = Solver()
ans = [BitVec('u%d' % i, 8) for i in range(16)]
for i in range(16):
solver.add((32 * ans[(i + 15) % 16]) | (ans[i] >> 3) & 0x1F == ord(target[i:i+1]))
solver.check()
result = solver.model()
input_data = ''.join('%02x' % result[ans[i]].as_long() for i in range(16))
print(input_data)
babyre-200
IDA打开之后
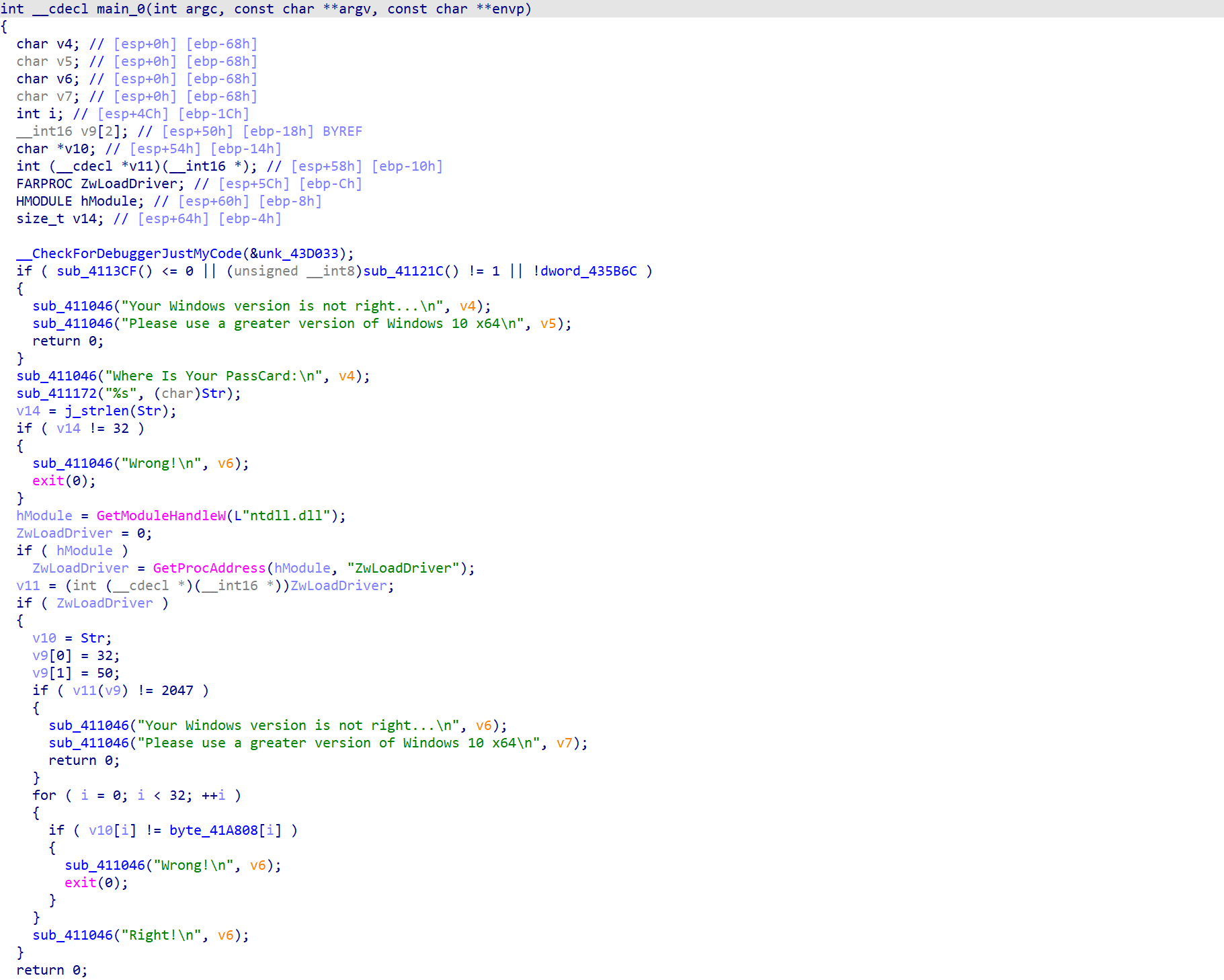
发现和一般的re题目不太一样,这道题目的加密函数似乎不是可以直接查看的,而是用了某种方式调用,但是最后的逻辑还是一样的,也就是通过比对加密后的内容最后判断是否正确
在各个函数中苦苦的寻找,最后终于找到一点可能是在加密的东西
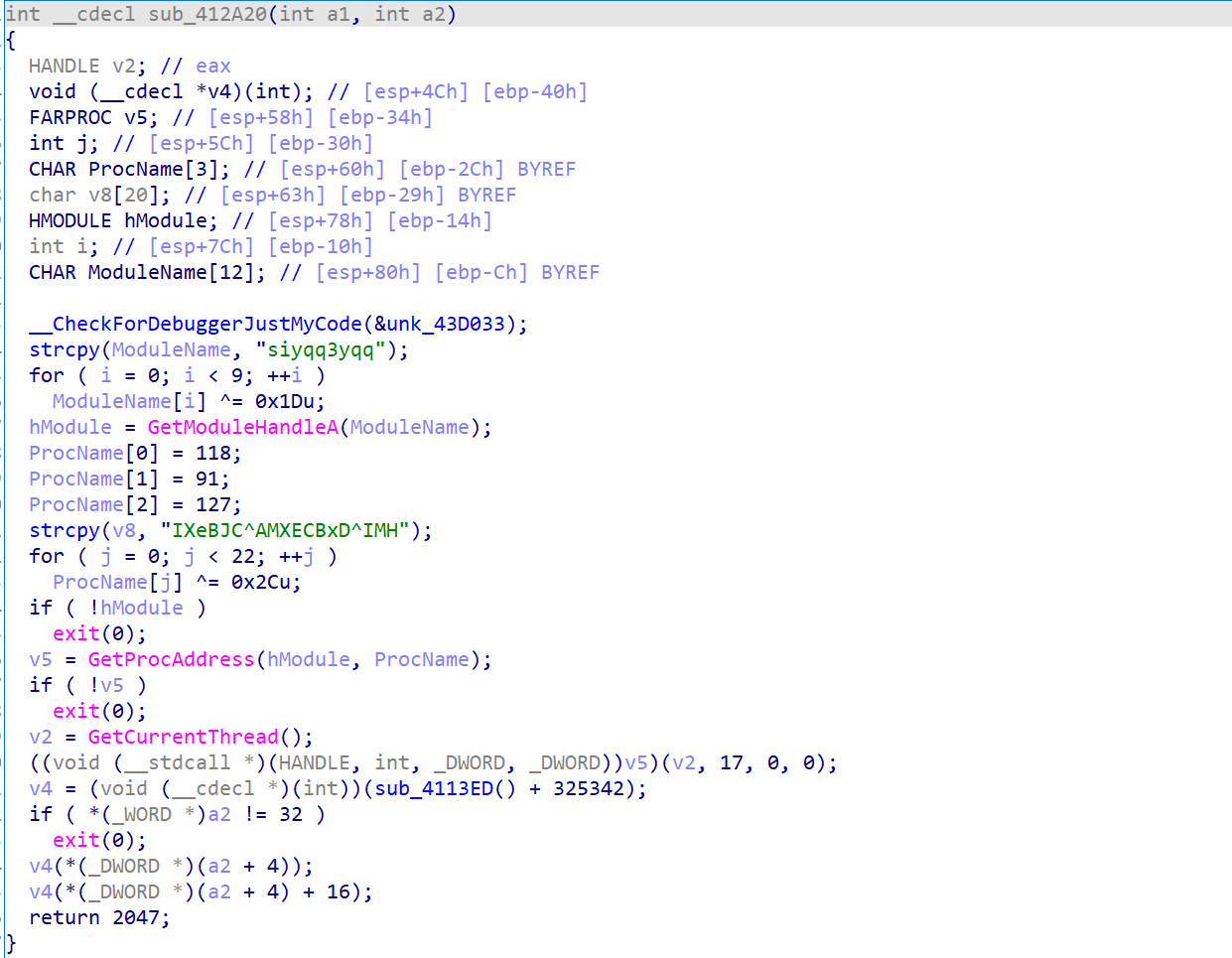
反调试
他这里特意通过异或来动态解密,似乎就是再告诉我们这里在干一些见不得人的事情。
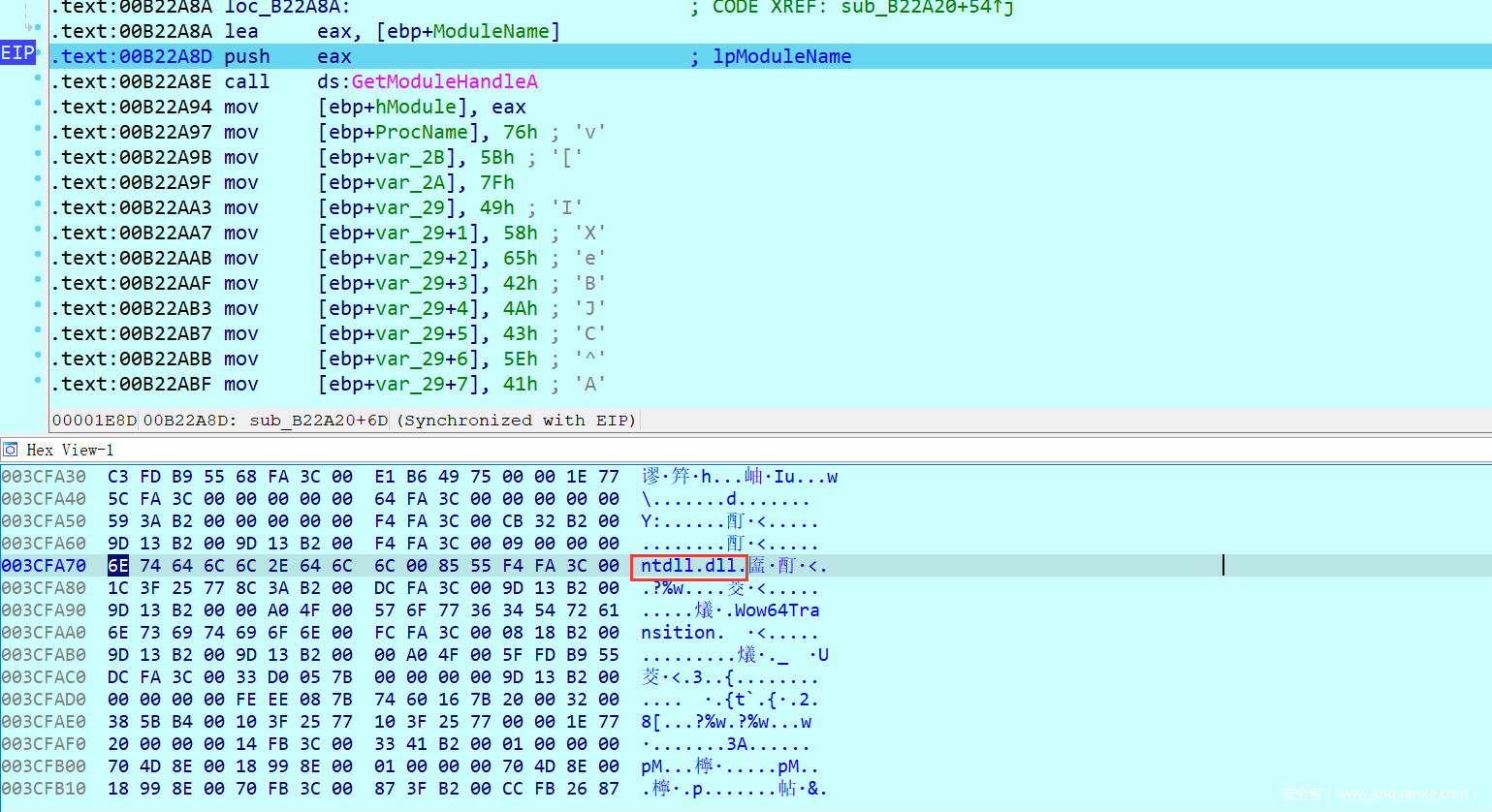
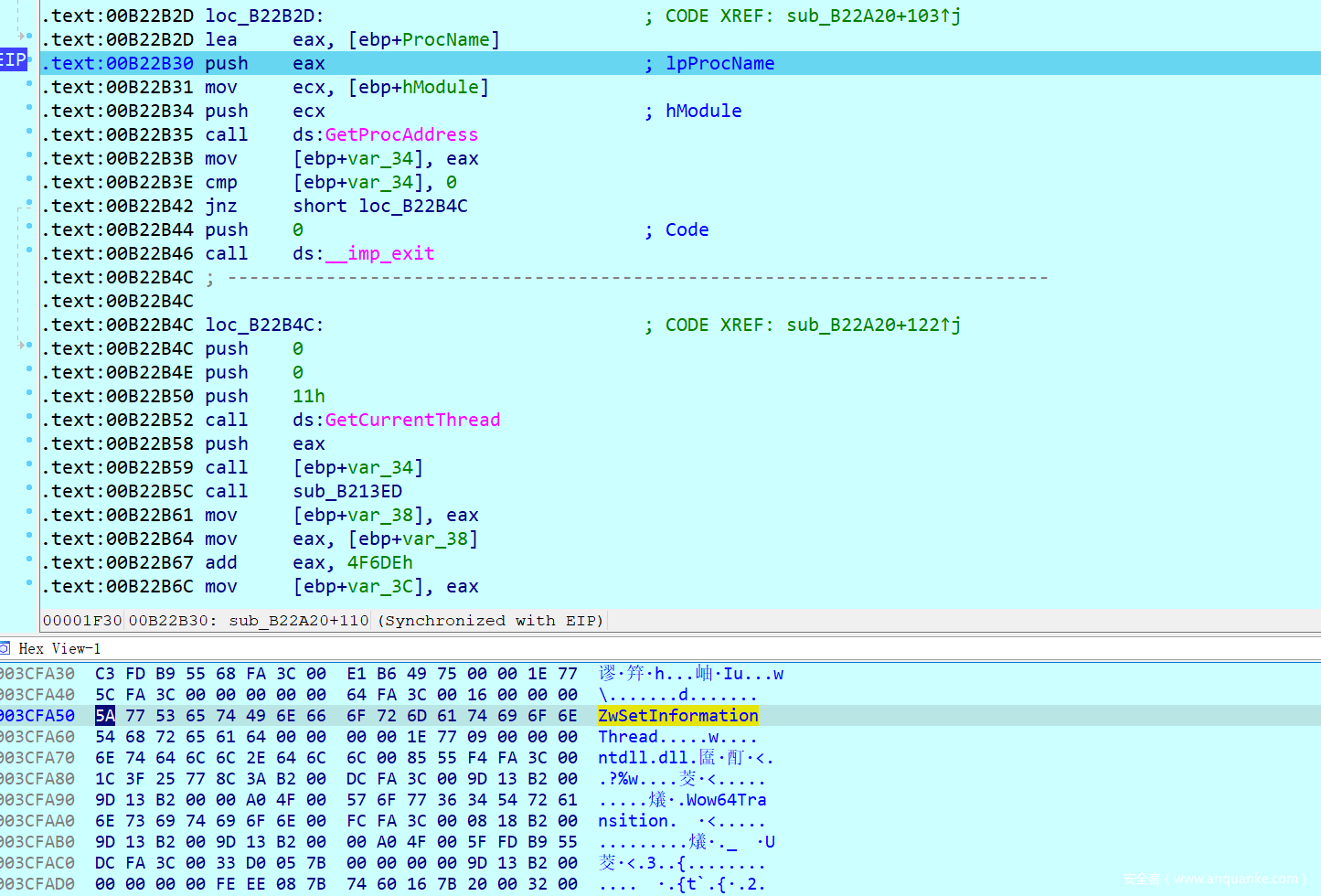
调试发现最后解密取出的地址是ZwSetInformationThreadi函数
百度搜索这个关键词发现这个似乎就是一种反调试操作
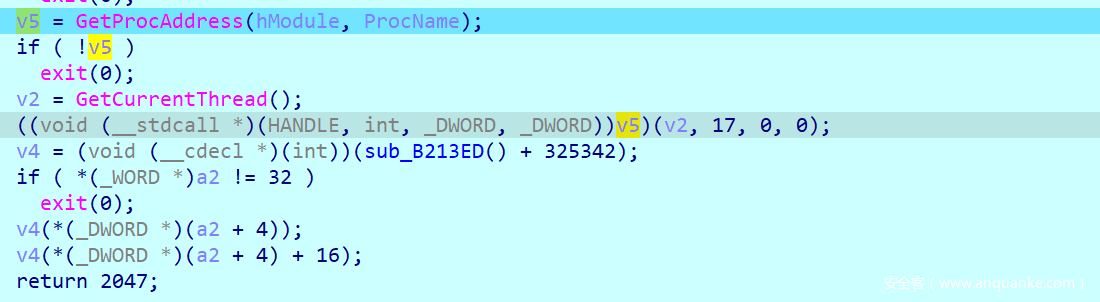
所以我们考虑把这里的调用函数操作给nop掉
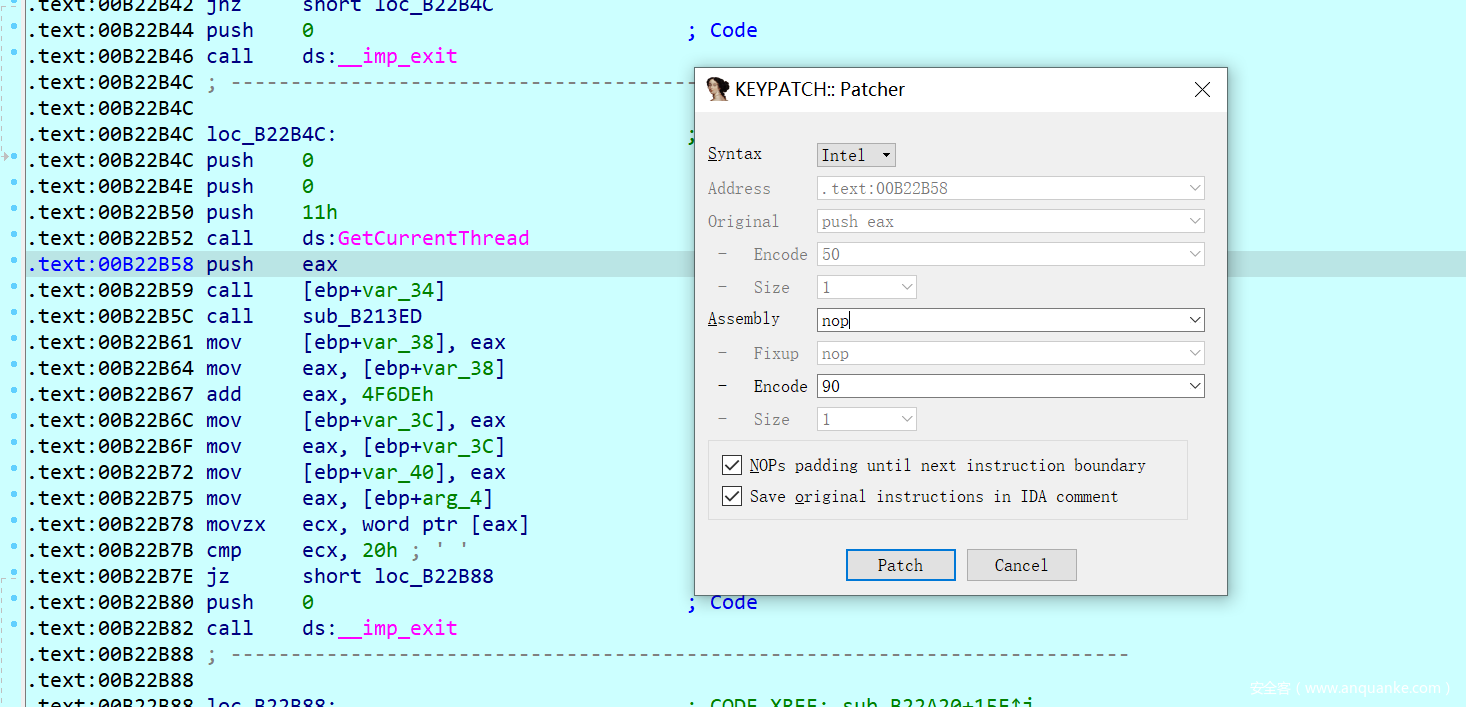
从传参开始nop,并且保存内容,之后就可以正常调试了。
动态解密
观察后面的内容发现这道题是动态解密出Cipher.dll,不过我采用动态调试的方法,其实可以不用管解密的这部分内容

加密函数
我们就直接分析调用解密后代码的这一部分的内容即可

这部分就是重要的加密函数,这里把数据前十六字节和后十六字节分段进行加密
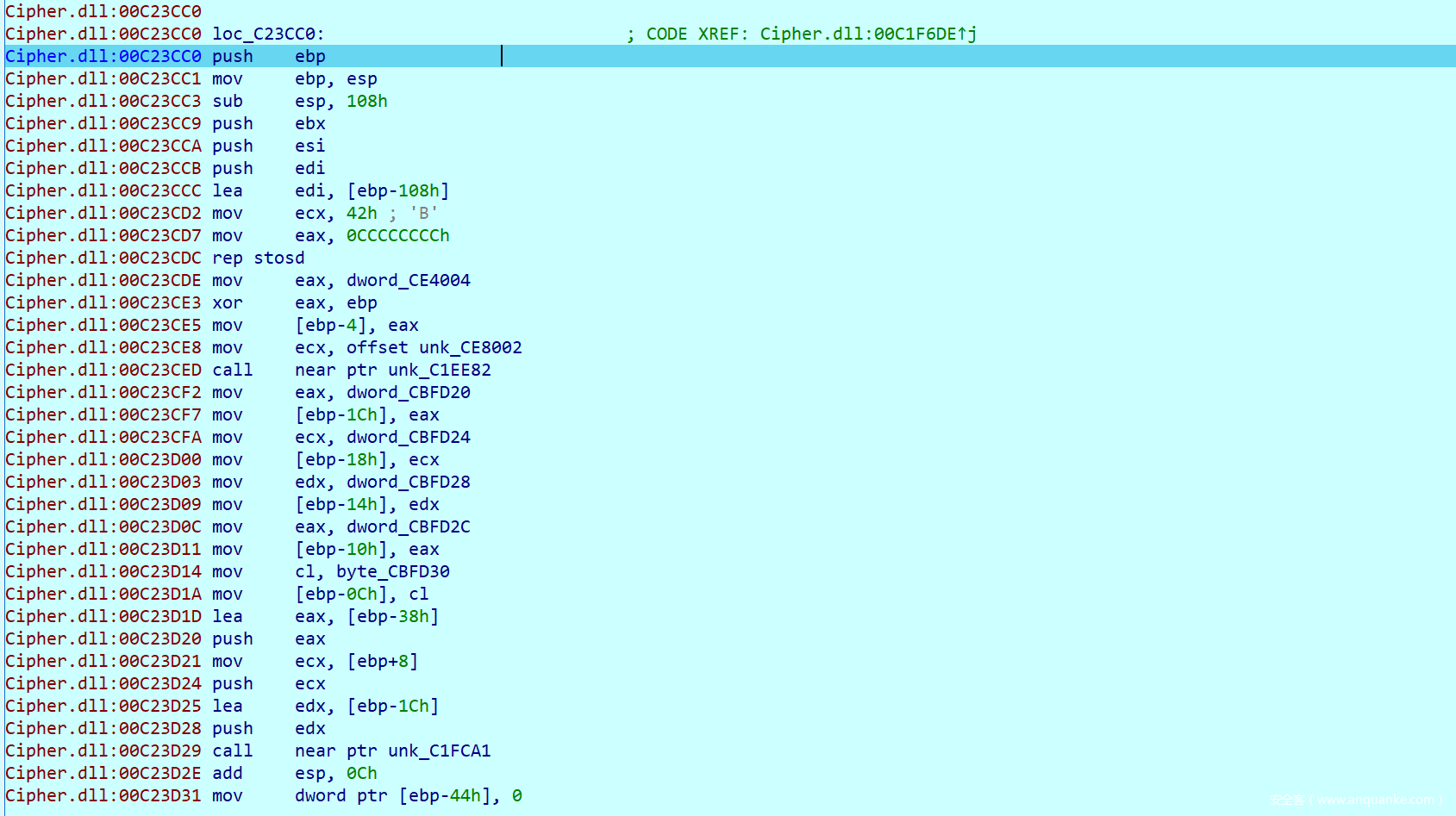
发现这一块内容因为是SMC生成的,所以IDA没有识别出来,我们按P手动转换成函数
接着不断的进入函数最后可以发现关键的内容

第一个循环
可以发现第一个循环动态生成了一个data数组,而这个数组的内容都是固定的,我们可以直接提取。
第二个循环
第二个循环的才是重要的加密内容,他通过一个循环进行不断的迭代,并且可以发现其中的
v5[0] – v5[3]的内容就是我们输入的前16个
而迭代的最后四位v5[32]-v5[35]的内容就是最后加密得到的内容,我们暂且先不管encode函数内部实现如何。
可以发现,我们encode函数传入的参数完全是已知的的内容,我们只需要有encode函数正向的计算代码,就可以从后往前推出所有的内容
encode函数

我们只需要正向的编写encode函数的代码即可,所以不需要复杂的分析,不过我这里还是说明一下吧,这个函数取出了参数的每一位bytes,并且作为下标找到相应的key数组中的内容赋值给data数组,最后又通过函数把data数组的内容转换为int,再用get函数异或一下。这个过程虽然很复杂,但是不要求逆向就无所谓了。
解密程序
#include <cstdio>
unsigned int encode_data[8] =
{
0xB75863EA, 0xE9A1E28C, 0x538F29C5, 0x593208E8, 0xAE671BAF, 0xC4CFDAD9, 0xECB1FF72, 0x06F37376
};
unsigned int data[33] =
{
0xC05103FD, 0xD1DBA4A4, 0xB693F50A, 0xB3A4E3B7, 0xA15183E9, 0x75562A4D, 0x25B5EC04, 0xC6C71137,
0x0CB9B0C9, 0xD7F95262, 0x618D8F3A, 0xB12AAC90, 0x6F024009, 0x3C317396, 0xECB905CB, 0xEBBA737B,
0x189CDA0F, 0xB35E97F2, 0xA459666D, 0x7438091C, 0x61A02896, 0xDB905062, 0xBDA9F172, 0x4531376F,
0x634C619D, 0xD37BD2FB, 0xDB3DFBC3, 0xE88EF7F2, 0x37E2C886, 0x2DF2AC0C, 0xE58F0D02, 0xF5CA718D,
0xEFE40BDF
};
unsigned char key[] =
{
0xD6, 0x90, 0xE9, 0xFE, 0xCC, 0xE1, 0x3D, 0xB7, 0x16, 0xB6,
0x14, 0xC2, 0x28, 0xFB, 0x2C, 0x05, 0x2B, 0x67, 0x9A, 0x76,
0x2A, 0xBE, 0x04, 0xC3, 0xAA, 0x44, 0x13, 0x26, 0x49, 0x86,
0x06, 0x99, 0x9C, 0x42, 0x50, 0xF4, 0x91, 0xEF, 0x98, 0x7A,
0x33, 0x54, 0x0B, 0x43, 0xED, 0xCF, 0xAC, 0x62, 0xE4, 0xB3,
0x1C, 0xA9, 0xC9, 0x08, 0xE8, 0x95, 0x80, 0xDF, 0x94, 0xFA,
0x75, 0x8F, 0x3F, 0xA6, 0x47, 0x07, 0xA7, 0xFC, 0xF3, 0x73,
0x17, 0xBA, 0x83, 0x59, 0x3C, 0x19, 0xE6, 0x85, 0x4F, 0xA8,
0x68, 0x6B, 0x81, 0xB2, 0x71, 0x64, 0xDA, 0x8B, 0xF8, 0xEB,
0x0F, 0x4B, 0x70, 0x56, 0x9D, 0x35, 0x1E, 0x24, 0x0E, 0x5E,
0x63, 0x58, 0xD1, 0xA2, 0x25, 0x22, 0x7C, 0x3B, 0x01, 0x21,
0x78, 0x87, 0xD4, 0x00, 0x46, 0x57, 0x9F, 0xD3, 0x27, 0x52,
0x4C, 0x36, 0x02, 0xE7, 0xA0, 0xC4, 0xC8, 0x9E, 0xEA, 0xBF,
0x8A, 0xD2, 0x40, 0xC7, 0x38, 0xB5, 0xA3, 0xF7, 0xF2, 0xCE,
0xF9, 0x61, 0x15, 0xA1, 0xE0, 0xAE, 0x5D, 0xA4, 0x9B, 0x34,
0x1A, 0x55, 0xAD, 0x93, 0x32, 0x30, 0xF5, 0x8C, 0xB1, 0xE3,
0x1D, 0xF6, 0xE2, 0x2E, 0x82, 0x66, 0xCA, 0x60, 0xC0, 0x29,
0x23, 0xAB, 0x0D, 0x53, 0x4E, 0x6F, 0xD5, 0xDB, 0x37, 0x45,
0xDE, 0xFD, 0x8E, 0x2F, 0x03, 0xFF, 0x6A, 0x72, 0x6D, 0x6C,
0x5B, 0x51, 0x8D, 0x1B, 0xAF, 0x92, 0xBB, 0xDD, 0xBC, 0x7F,
0x11, 0xD9, 0x5C, 0x41, 0x1F, 0x10, 0x5A, 0xD8, 0x0A, 0xC1,
0x31, 0x88, 0xA5, 0xCD, 0x7B, 0xBD, 0x2D, 0x74, 0xD0, 0x12,
0xB8, 0xE5, 0xB4, 0xB0, 0x89, 0x69, 0x97, 0x4A, 0x0C, 0x96,
0x77, 0x7E, 0x65, 0xB9, 0xF1, 0x09, 0xC5, 0x6E, 0xC6, 0x84,
0x18, 0xF0, 0x7D, 0xEC, 0x3A, 0xDC, 0x4D, 0x20, 0x79, 0xEE,
0x5F, 0x3E, 0xD7, 0xCB, 0x39, 0x48, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00
};
unsigned int get(unsigned int a, unsigned int b)
{
return (a >> (32 - b)) ^ (a << b);
}
int solve(int x)
{
unsigned int data = 0;
unsigned char a[4];
for (int i = 0; i < 4; ++i) a[i] = key[(x >> (24 - 8 * i)) & 0xFF];
for (int i = 0; i < 4; ++i) data ^= a[i] << (24 - 8 * i);
return data ^ get(data, 2) ^ get(data, 10) ^ get(data, 18) ^ get(data, 24);
}
int rev(int x)
{
unsigned int data = 0;
unsigned char a2[4];
for (int i = 0; i < 4; ++i) a2[i] = x >> (24 - 8 * i);
for (int i = 0; i < 4; i++) data ^= a2[4 - i - 1] << (24 - 8 * i);
return data;
}
unsigned int sz[36];
int main()
{
for (int i = 0; i < 8; i++) encode_data[i] = rev(encode_data[i]);
for (int i = 0; i < sizeof(encode_data) / 4; i += 4)
{
sz[35] = encode_data[i];
sz[34] = encode_data[i + 1];
sz[33] = encode_data[i + 2];
sz[32] = encode_data[i + 3];
for (int i = 31; i >= 0; i--)
{
sz[i] = sz[i + 4] ^ solve(data[i + 1] ^ sz[i + 3] ^ sz[i + 2] ^ sz[i + 1]);
}
for (int i = 0; i < 4; i++)
{
unsigned char t[4];
for (int j = 0; j < 4; ++j)
{
t[j] = sz[i] >> (24 - 8 * j);
printf("%c", t[j]);
}
}
}
/*
* encode
for (int i = 0; i < 32; ++i)
{
sz[i + 4] = sz[i] ^ solve(data[i + 1] ^ sz[i + 3] ^ sz[i + 2] ^ sz[i + 1]);
}
*/
return 0;
}
Enigma-300
1940年9月6日,英国情报部门军情六处截获了一封重要的德国电报,你能逆向分析德国使用的密码机Enigma,帮助军情六处解密这封电报吗?注:得到的flag请以MD5格式提交
main函数
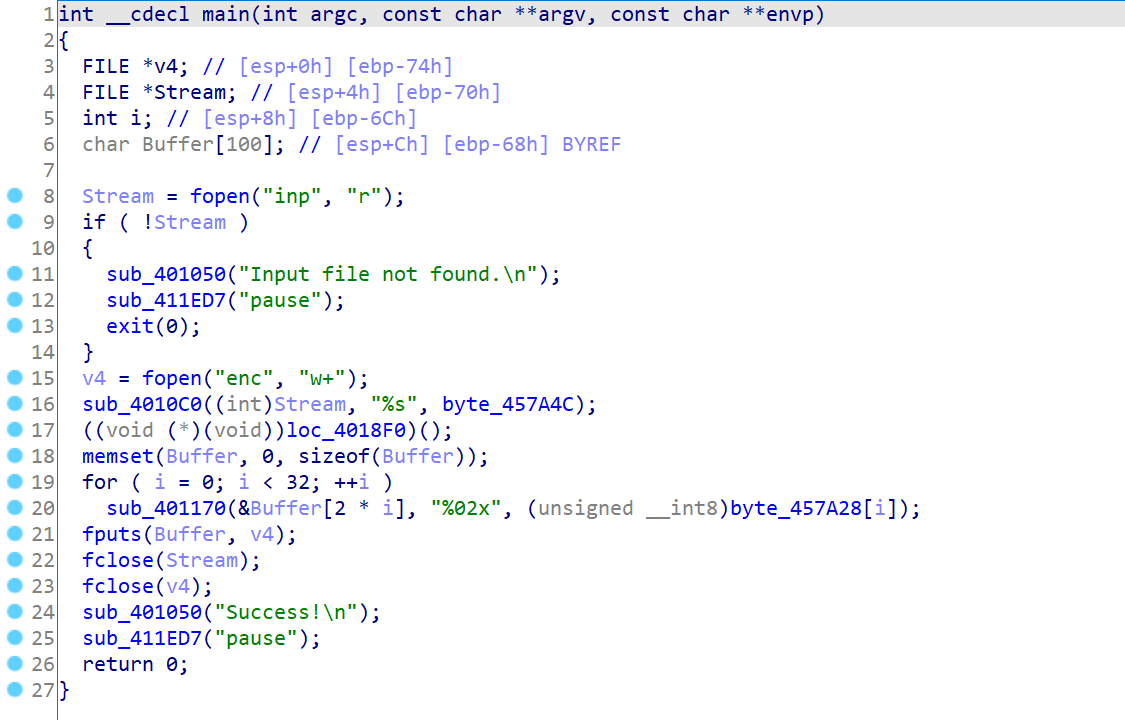
也是老样子了,读入inp中的内容进行加密后输入到enc文件中,而这道题直接给出了enc文件,要让我们求出inp文件的内容,关键的加密内容就在loc_4018F0中
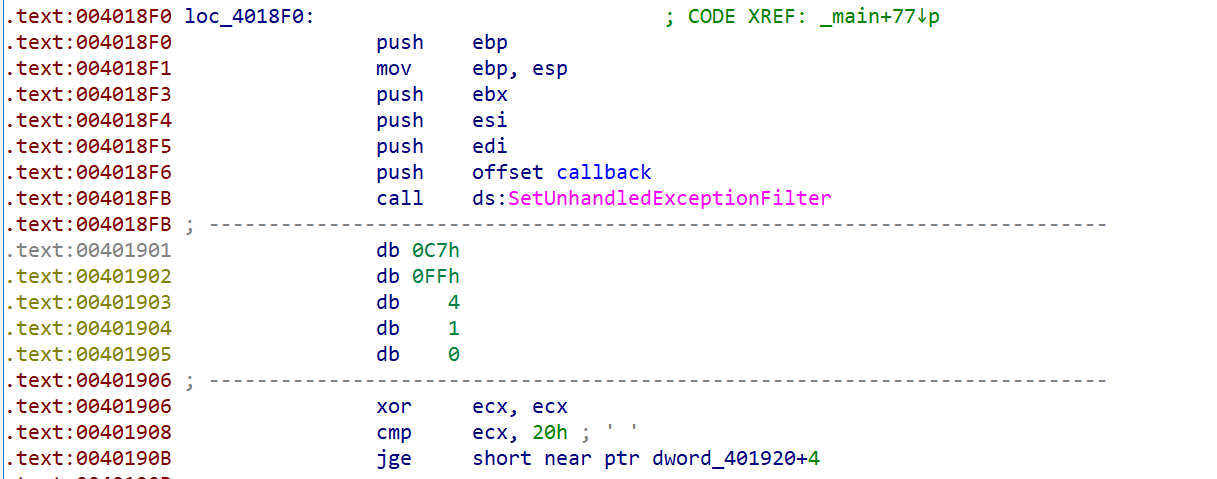
加密函数
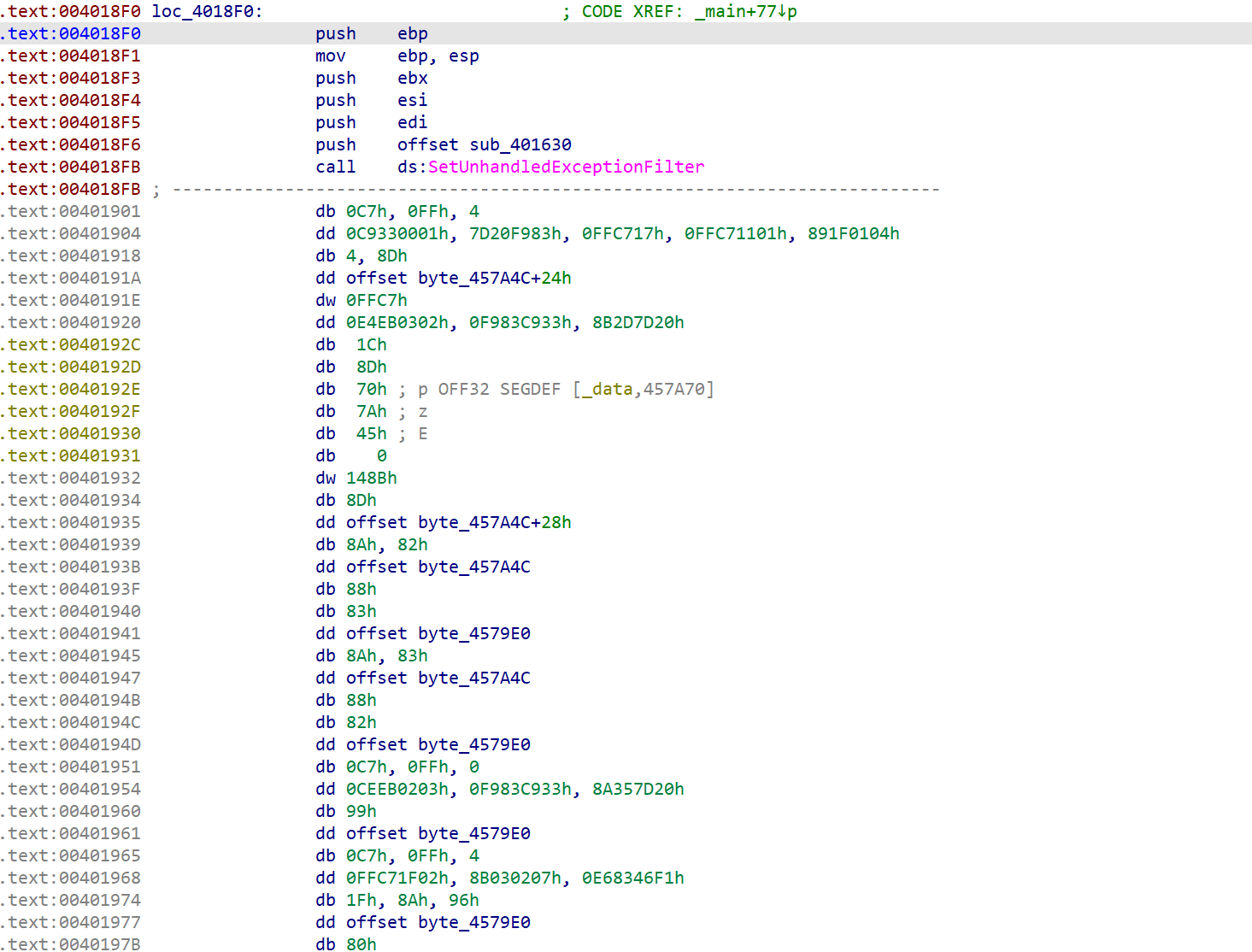
这里显然是IDA无法正常的识别出代码的内容,而0xC7这个机器码也是没有对应的汇编的,这意味程序执行到这里的时候一定会报错,所以在这段代码的开头调用了SetUnhandledExceptionFilter来进行设置异常接管函数
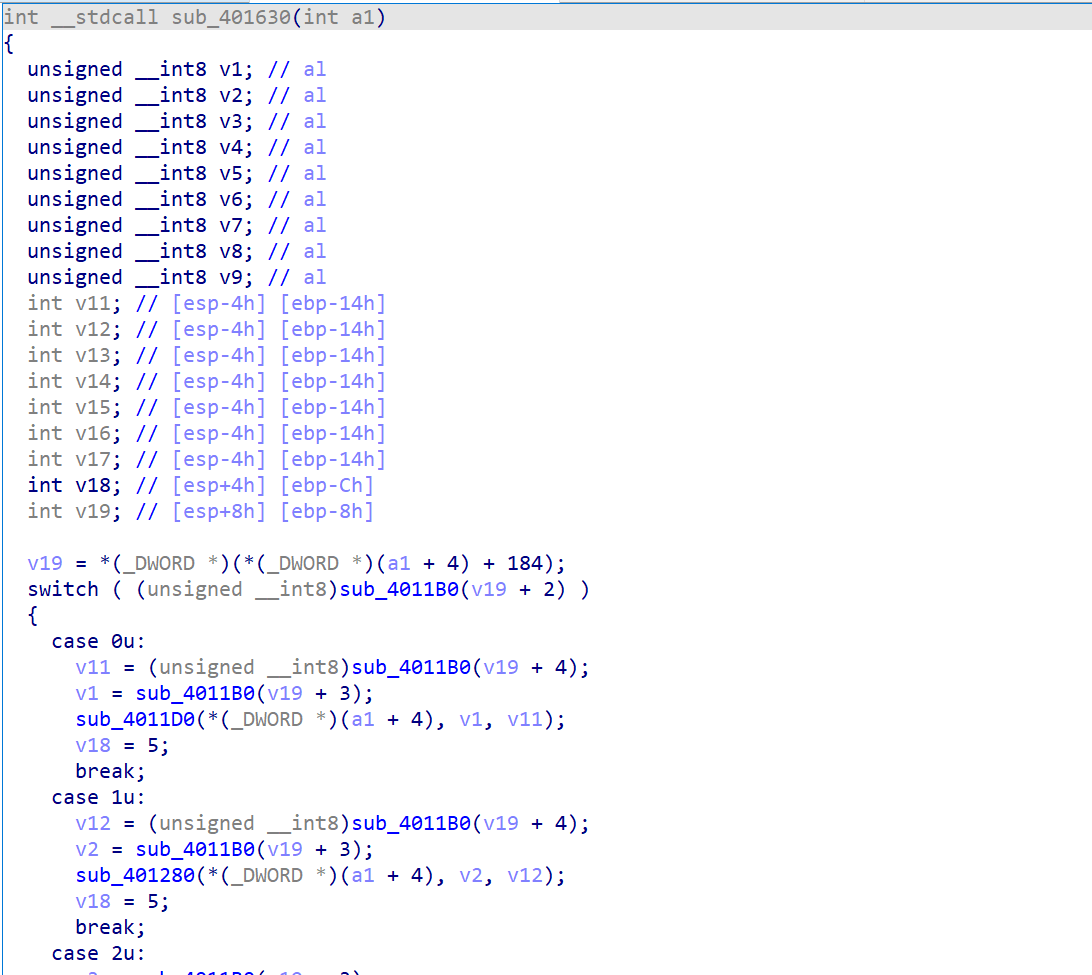
这个函数我们这样似乎看不出什么,问题就在于它的参数类型识别错误。
我们对参数类型进行修改

接下来就可以看到很清楚的代码逻辑了

分析可以得知,
实际上0xC7 0xFF开头的代码是无法执行的,到了异常处理函数这里,会对产生异常的代码附近信息进行提取,并且后几个字节的内容都是作为参数来处理
比如这里的4就会进入switch语句中调用case 4的分支,并且传入参数1和0。
我这里找了一个处理函数进行讲解(修正参数类型后就会得到比较舒服的伪代码)
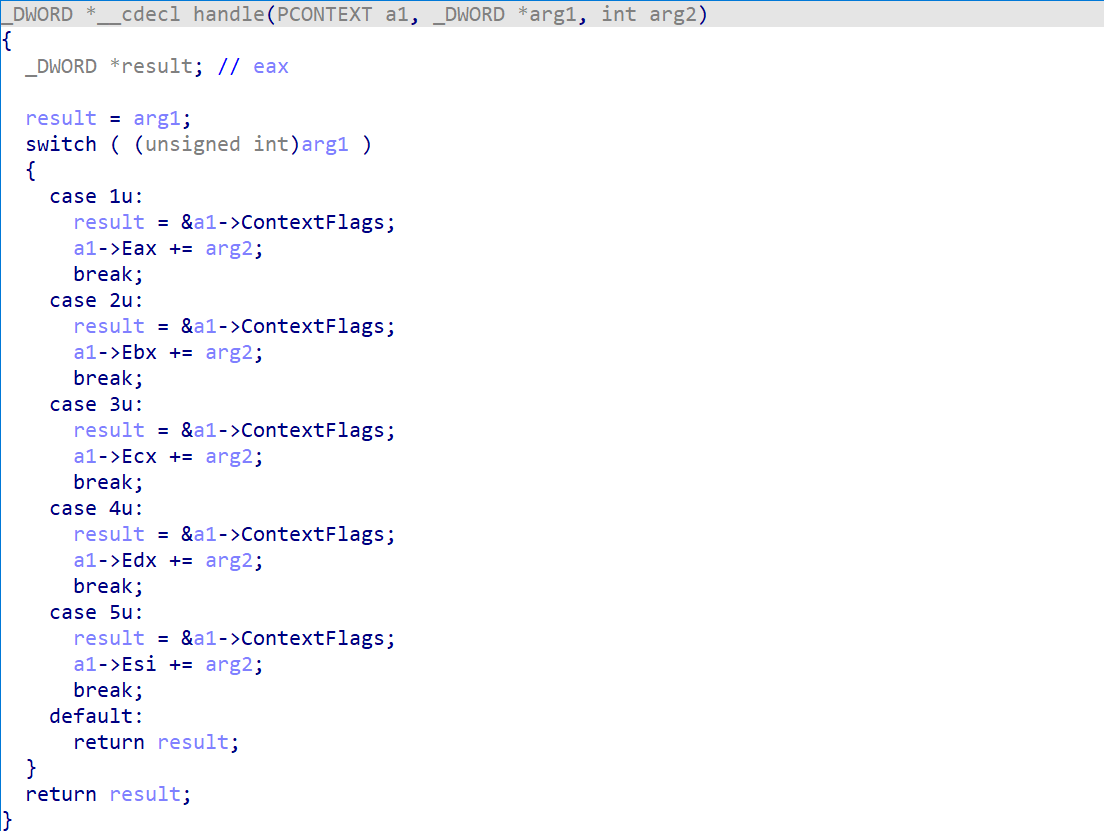
可以发现处理函数实际上就是对寄存器进行操作,也就是通过了类似opcode,和异常处理
,来达到了一个虚拟机的效果。
我这里不会IDC,所以只能尝试通过反汇编引擎来逐个读取,如果读取到错误的内容,就当做opcode进行处理,最后把所有的汇编代码输出,然后我再手动还原。
我这里使用的是od的内部反汇编引擎,并且该引擎已经开源,我对其代码进行调用,使其可以在VS上调用,修改后的github地址:https://github.com/wjhwjhn/DisAsmVS,希望师傅们能给我点个Star,嘿嘿
opcode还原代码
// Free Disassembler and Assembler -- Demo program
//
// Copyright (C) 2001 Oleh Yuschuk
//
// This program is free software; you can redistribute it and/or modify
// it under the terms of the GNU General Public License as published by
// the Free Software Foundation; either version 2 of the License, or
// (at your option) any later version.
//
// This program is distributed in the hope that it will be useful,
// but WITHOUT ANY WARRANTY; without even the implied warranty of
// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
// GNU General Public License for more details.
//
// You should have received a copy of the GNU General Public License
// along with this program; if not, write to the Free Software
// Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
/*
int Assemble(char *cmd,ulong ip,t_asmmodel *model,int attempt,int constsize,char *errtext) - 将文本命令汇编为二进制代码
int Checkcondition(int code,ulong flags) - checks whether flags met condition in the command - 检查命令中是否满足条件
int Decodeaddress(ulong addr,ulong base,int addrmode,char *symb,int nsymb,char *comment) - 用户提供的函数,将地址解码为符号名称
ulong Disasm(char *src,ulong srcsize,ulong srcip,t_disasm *disasm,int disasmmode) - 确定二进制命令的长度或将其反汇编到文本中
ulong Disassembleback(char *block,ulong base,ulong size,ulong ip,int n) - 向后走二进制代码;
ulong Disassembleforward(char *block,ulong base,ulong size,ulong ip,int n) - 向前走二进制代码;
int Isfilling(ulong addr,char *data,ulong size,ulong align) - 确定命令是否等于NOP;
int Print3dnow(char *s,char *f) - 转换3DNow!常量为文本而不触发无效操作数的FPU异常;
int Printfloat10(char *s,long double ext) - 将10字节浮点常量转换为文本而不会导致异常;
int Printfloat4(char *s,float f) - 将4字节浮点常量转换为文本而不会导致异常;
int Printfloat8(char *s,double d) - 将8字节浮点常量转换为文本而不会导致异常.
*/
#define STRICT
#define MAINPROG // Place all unique variables here
#include <windows.h>
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <math.h>
#include <float.h>
#pragma hdrstop
#include "disasm.h"
unsigned char opcode[] =
{
0x55, 0x8B, 0xEC, 0x53, 0x56, 0x57, 0x68, 0x30, 0x16, 0xAF,
0x00, 0xFF, 0x15, 0x00, 0x20, 0xB3, 0x00, 0xC7, 0xFF, 0x04,
0x01, 0x00, 0x33, 0xC9, 0x83, 0xF9, 0x20, 0x7D, 0x17, 0xC7,
0xFF, 0x00, 0x01, 0x11, 0xC7, 0xFF, 0x04, 0x01, 0x1F, 0x89,
0x04, 0x8D, 0x70, 0x7A, 0xB4, 0x00, 0xC7, 0xFF, 0x02, 0x03,
0xEB, 0xE4, 0x33, 0xC9, 0x83, 0xF9, 0x20, 0x7D, 0x2D, 0x8B,
0x1C, 0x8D, 0x70, 0x7A, 0xB4, 0x00, 0x8B, 0x14, 0x8D, 0x74,
0x7A, 0xB4, 0x00, 0x8A, 0x82, 0x4C, 0x7A, 0xB4, 0x00, 0x88,
0x83, 0xE0, 0x79, 0xB4, 0x00, 0x8A, 0x83, 0x4C, 0x7A, 0xB4,
0x00, 0x88, 0x82, 0xE0, 0x79, 0xB4, 0x00, 0xC7, 0xFF, 0x00,
0x03, 0x02, 0xEB, 0xCE, 0x33, 0xC9, 0x83, 0xF9, 0x20, 0x7D,
0x35, 0x8A, 0x99, 0xE0, 0x79, 0xB4, 0x00, 0xC7, 0xFF, 0x04,
0x02, 0x1F, 0xC7, 0xFF, 0x07, 0x02, 0x03, 0x8B, 0xF1, 0x46,
0x83, 0xE6, 0x1F, 0x8A, 0x96, 0xE0, 0x79, 0xB4, 0x00, 0x80,
0xE2, 0xE0, 0x81, 0xE2, 0xFF, 0x00, 0x00, 0x00, 0xC7, 0xFF,
0x08, 0x04, 0x05, 0x0A, 0xDA, 0x88, 0x99, 0x04, 0x7A, 0xB4,
0x00, 0x41, 0xEB, 0xC6, 0xA0, 0x04, 0x7A, 0xB4, 0x00, 0xA2,
0x28, 0x7A, 0xB4, 0x00, 0xB9, 0x01, 0x00, 0x00, 0x00, 0x83,
0xF9, 0x20, 0x7D, 0x28, 0x8A, 0x99, 0x04, 0x7A, 0xB4, 0x00,
0x8B, 0xF1, 0xC7, 0xFF, 0x03, 0x05, 0x32, 0x9E, 0x04, 0x7A,
0xB4, 0x00, 0x8B, 0xF1, 0xC7, 0xFF, 0x04, 0x05, 0x03, 0x32,
0x9E, 0xF0, 0x68, 0xB4, 0x00, 0x88, 0x99, 0x28, 0x7A, 0xB4,
0x00, 0x41, 0xEB, 0xD3, 0x5F, 0x5E, 0x5B, 0x5D, 0xC3
};
char s[10][10] = {
"",
"eax",
"ebx",
"ecx",
"edx",
"esi"
};
int main(main)
{
int idx = 0, eip = 0xAF18F0;
t_disasm da = { 0 };
da.code_format = 0;
da.lowercase = 0;
da.ideal = 0;
da.putdefseg = 0;
for (int idx = 0; idx < 229; )
{
da.index = idx;
unsigned int l = Disasm32(opcode, &da, eip + idx, 4);
printf("%08X ", eip + idx);
if (!strcmp(da.comment, "Unknown command"))
{
int reg = opcode[idx + 3];
switch (opcode[idx + 2])
{
case 0:
printf("add %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 1:
printf("add %s, -%x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 2:
printf("add %s, %x\n", s[reg], 1);
idx += 4;
break;
case 3:
printf("add %s, -%x\n", s[reg], 1);
idx += 4;
break;
case 4:
printf("and %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 5:
printf("or %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 6:
printf("xor %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 7:
printf("shl %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
case 8:
printf("shr %s, %x\n", s[reg], opcode[idx + 4]);
idx += 5;
break;
default:
idx += 2;
break;
}
}
else
{
printf("%s\n", da.result);
idx += l;
}
}
return 0;
}
还原之后,就可以直接查看
伪代码
#include <cstdio>
#include "defs.h"
int swap_data[36];
unsigned char encode_data[36];
unsigned char input_data[36] = "c4ca4238a0b923820dcc509a6f75849b";
unsigned char tmp_data[36];
unsigned char data[36];
char aBier[] = "Bier";
void encode()
{
int v0; // eax
int i; // ecx
int j; // ecx
int v3; // ebx
int v4; // edx
int k; // ecx
char result; // al
int l; // ecx
v0 = 0;
for (i = 0; i < 32; ++i)
{
v0 = ((_BYTE)v0 + 0x11) & 0x1F;
swap_data[i] = v0;
}
for (j = 0; j < 32; j += 2)
{
v3 = swap_data[j];
v4 = swap_data[j + 1];
encode_data[v3] = input_data[v4];
encode_data[v4] = input_data[v3];
}
for (k = 0; k < 32; ++k)
tmp_data[k] = ((unsigned __int8)(encode_data[((_BYTE)k + 1) & 0x1F] & 0xE0) >> 5) | (8 * (encode_data[k] & 0x1F));
result = tmp_data[0];
data[0] = tmp_data[0];
for (l = 1; l < 32; ++l)
data[l] = aBier[l & 3] ^ tmp_data[l - 1] ^ tmp_data[l];
}
int main()
{
encode();
return 0;
}
直接用z3写正向代码约束求解。
解密程序
from z3 import *
data = list(bytes([0x93, 0x8B, 0x8F, 0x43, 0x12, 0x68, 0xF7, 0x90, 0x7A, 0x4B, 0x6E, 0x42, 0x13, 0x01, 0xB4, 0x21, 0x20, 0x73, 0x8D, 0x68, 0xCB, 0x19, 0xFC, 0xF8, 0xB2, 0x6B, 0xC4, 0xAB, 0xC8, 0x9B, 0x8D, 0x22]))
xor_key = "Bier"
for i in range(1, 32):
data[i] ^= ord(xor_key[i & 3]) ^ data[i - 1]
solver = Solver()
encode_data = [BitVec('u%d' % i, 8) for i in range(32)]
input_data = [BitVec('i%d' % i, 8) for i in range(32)]
for i in range(32):
solver.add((encode_data[(i + 1) & 0x1F] & 0xE0) >> 5 | (8 * (encode_data[i] & 0x1F)) == data[i])
swap_data = list(range(32))
t = 0
for i in range(32):
t = (t + 0x11) & 0x1F
swap_data[i] = t
for i in range(0, 32, 2):
v3 = swap_data[i]
v4 = swap_data[i + 1]
solver.add(encode_data[v3] == input_data[v4])
solver.add(encode_data[v4] == input_data[v3])
solver.check()
res = solver.model()
data = ''.join(chr(res[input_data[i]].as_long()) for i in range(32))
print(data)
Childre-300
双进程保护
这道题就是典型的双进程保护(Debug Blocker)
双进程保护,实际上是程序本身作为一个进程或一个调试器,并且在调试模式下运行自身程序。所以这种保护通常就会存在两个进程。
这种程序的技术特点是
1.无法被调试,因为程序本身也是一个调试器。我们又知道一般情况下一个程序只能被一个调试器所调试,如果他的程序先抢占作为了调试器,那么就无法进行调试。所以解决办法只能是在他的调试器附加之前你先开始调试。
2.一般来说,为了防止你直接抢占调试来绕过,他还会加一个异常处理函数,程序中原本存在一些不合理的代码或者INT3断点,当他的调试器处理的时候会去做一些指定的流程,而你作为调试者,在调试过程中就无法处理那些代码。
不过好在他是一道题目,那么就一定是能做的,也就是一般来说这个异常处理函数不会很复杂,手动模拟也可以操作,或者编写简单的脚本也可以进行解密,比如有些题目就是会直接在异常处理函数里面对代码进行解密后再返回运行。
异常处理函数(调试器部分)
这道题我们尝试直接从start开始下断,并且找到他处理调试器异常的逻辑部分,然后再手动跳转来执行加密过程
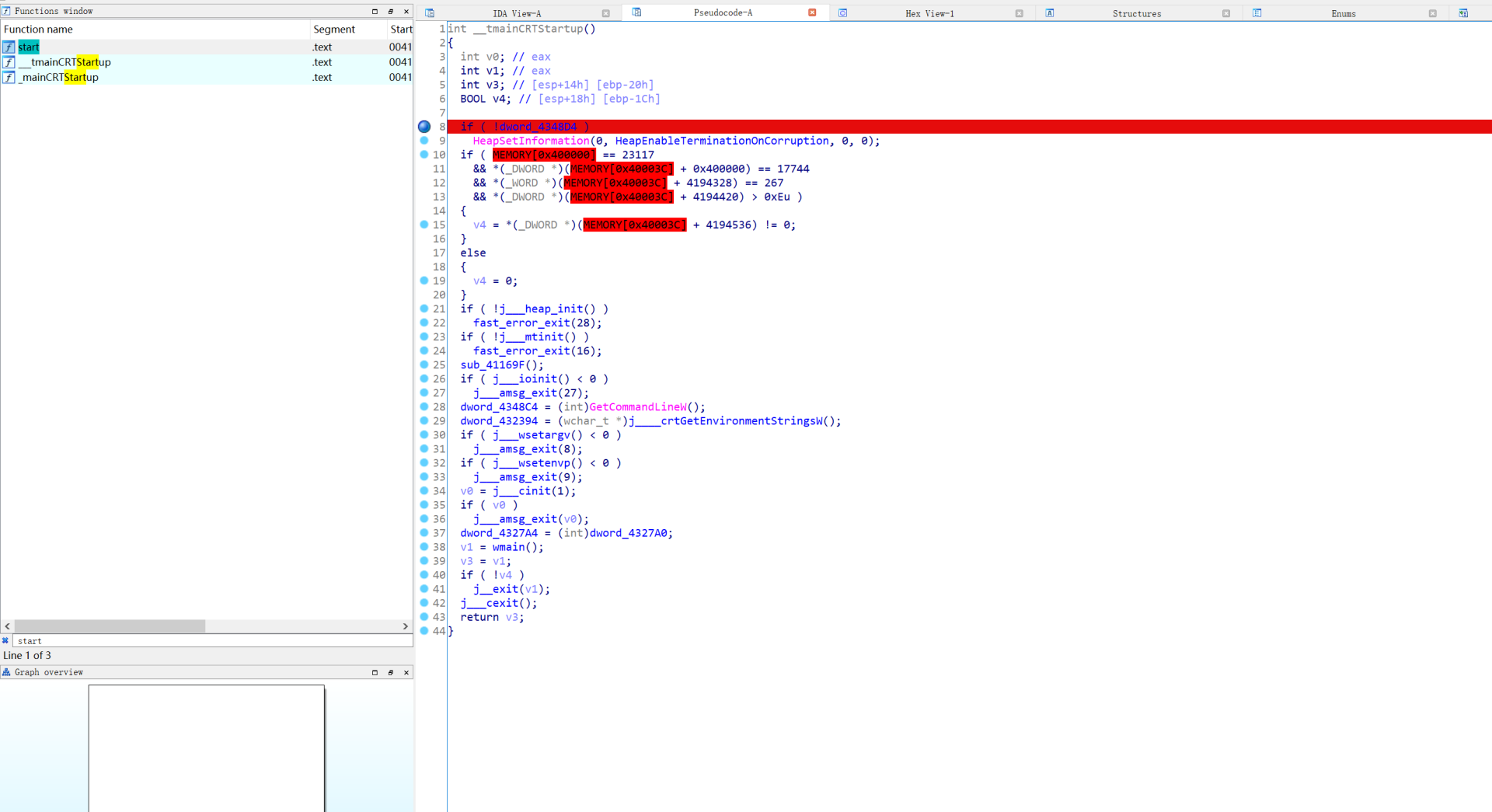
不断单步可以发现,这里开始分配函数执行
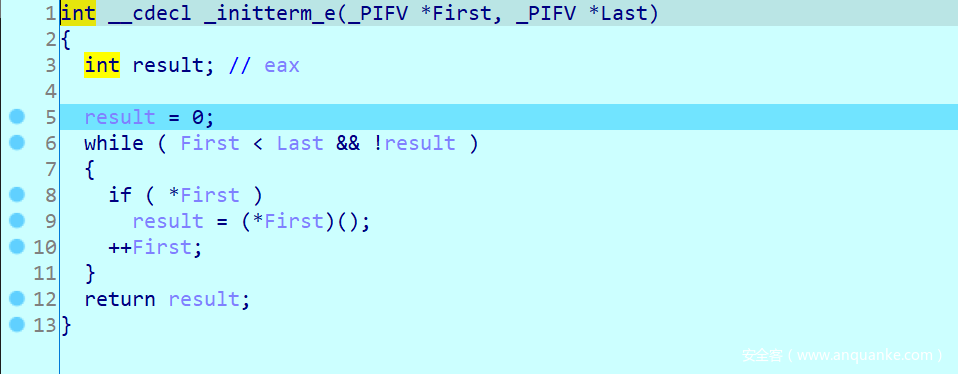
不难发现这部分就是创建了互斥体,并且通过互斥体来判断当前进程是调试器还是被调试的函数,并且通过dword_432350来记录,然后创建进程。
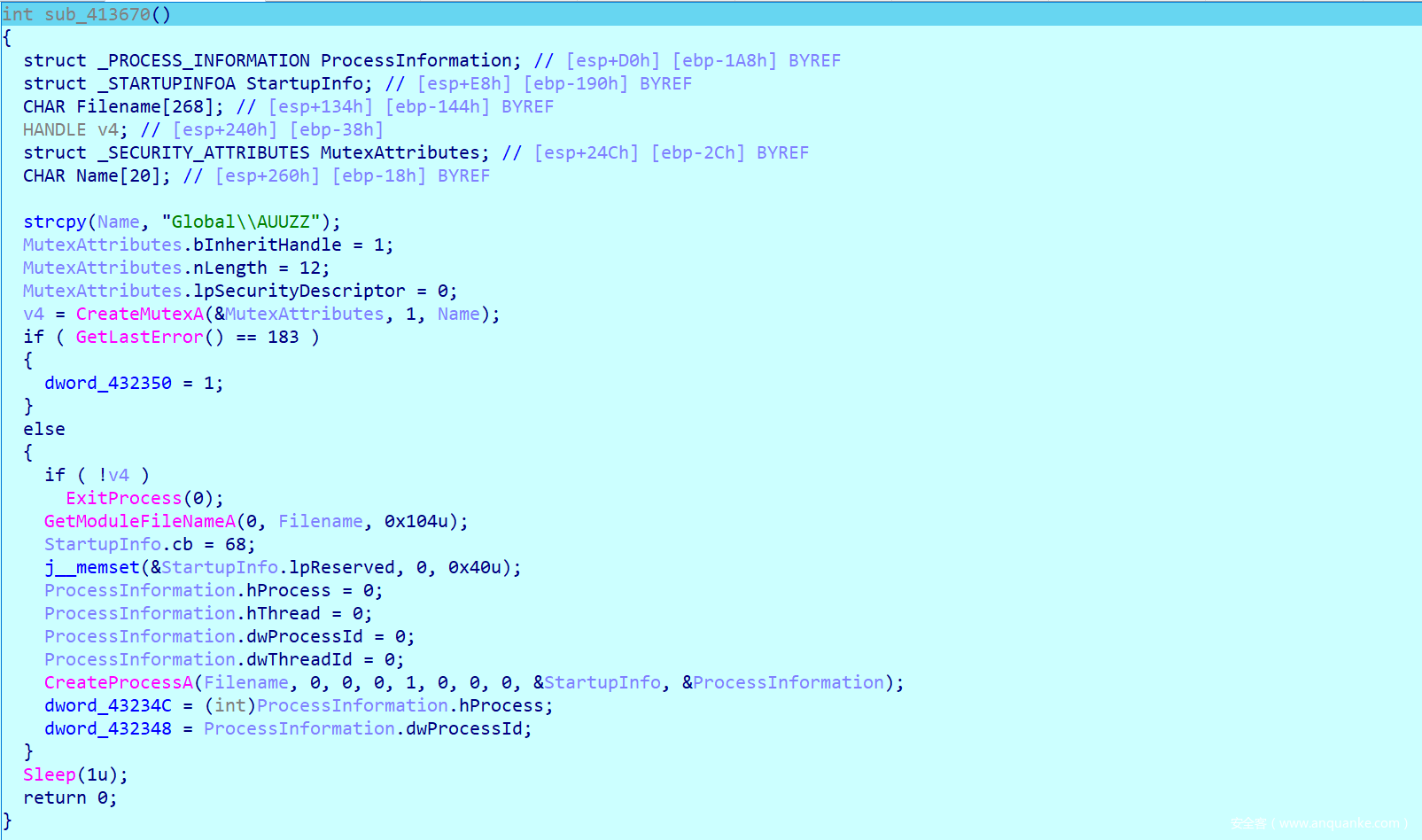
接着跟踪就发现了调试器处理的代码,这部分内容如果看过《加密与解密》的师傅应该会很清楚,里面有对编写调试器的函数信息详细的解释。
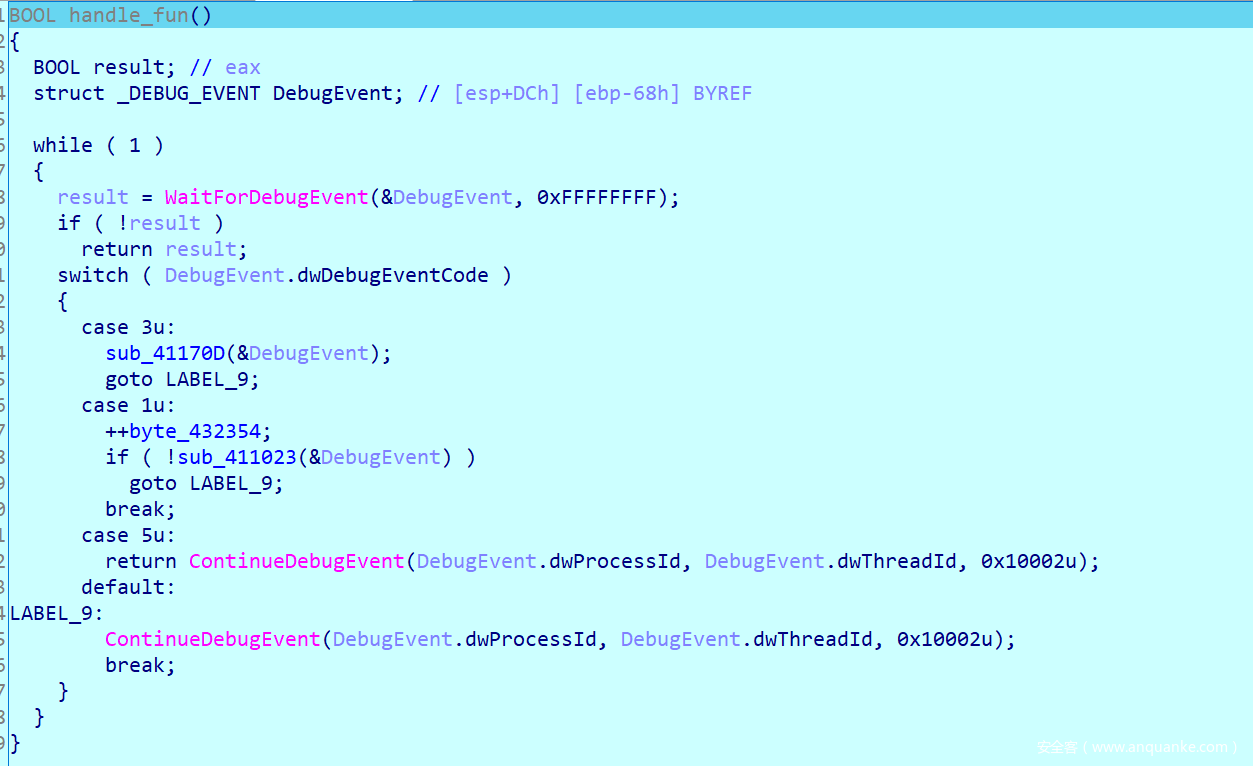
接下来进入到case 1分支中的函数,就可以很清楚的看到处理逻辑
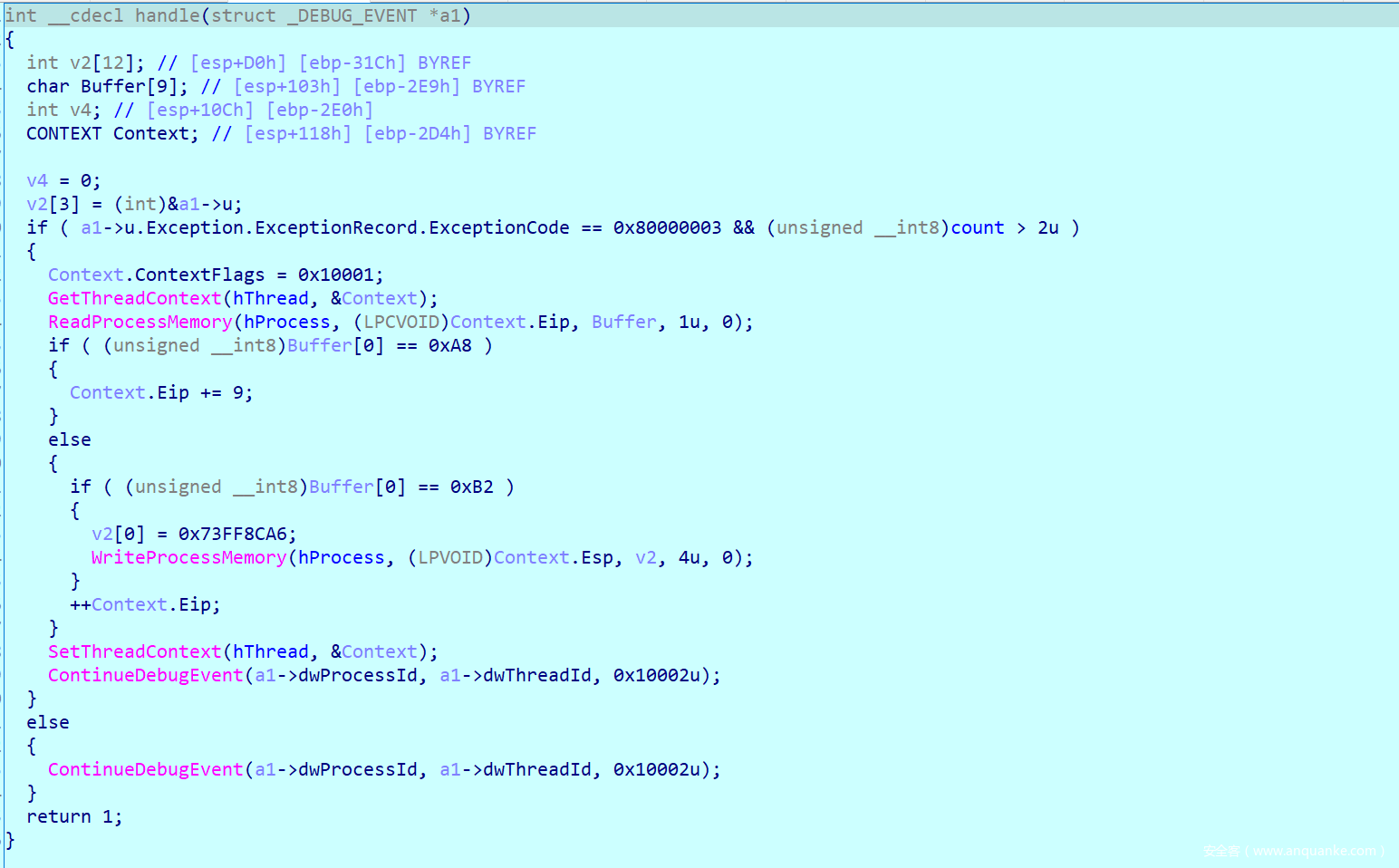
普通程序流程
我们目前知道了调试逻辑之后,接下来就是按照调试器的逻辑手动去执行代码。
我们手动创建一个进程,然后再次调试的时候,当前程序就会被认为是要被调试的程序,也就会去执行加密的流程了。

接下来就去wmain函数手动模拟,很快就遇到了第一个int3断点,我们模拟他的调试器逻辑,跳到下面去执行
紧接着又遇到第二个int3
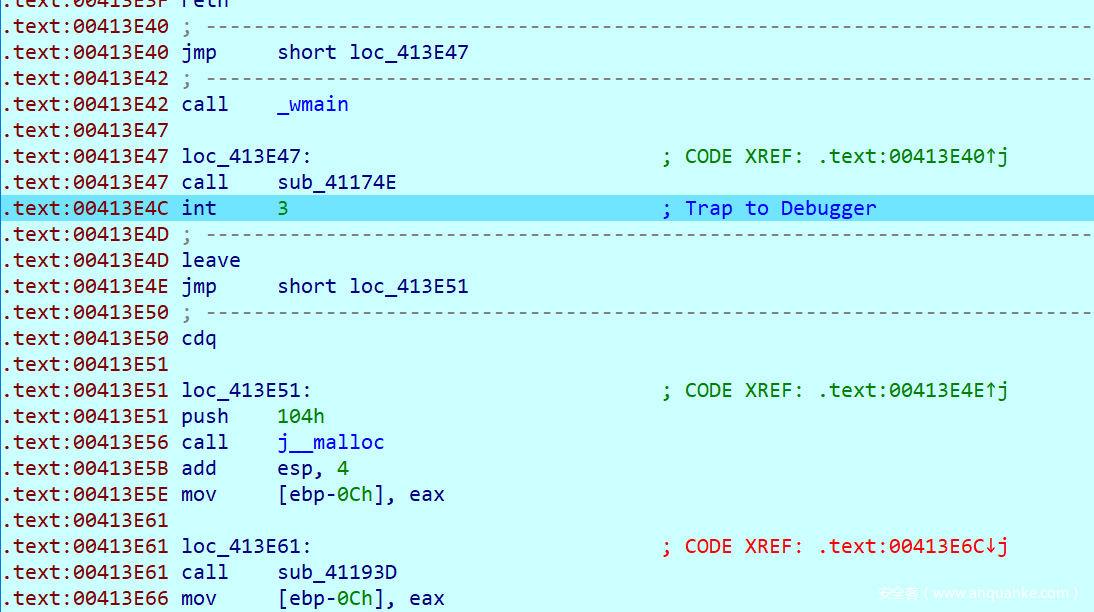
并且在这之前的call函数输出了
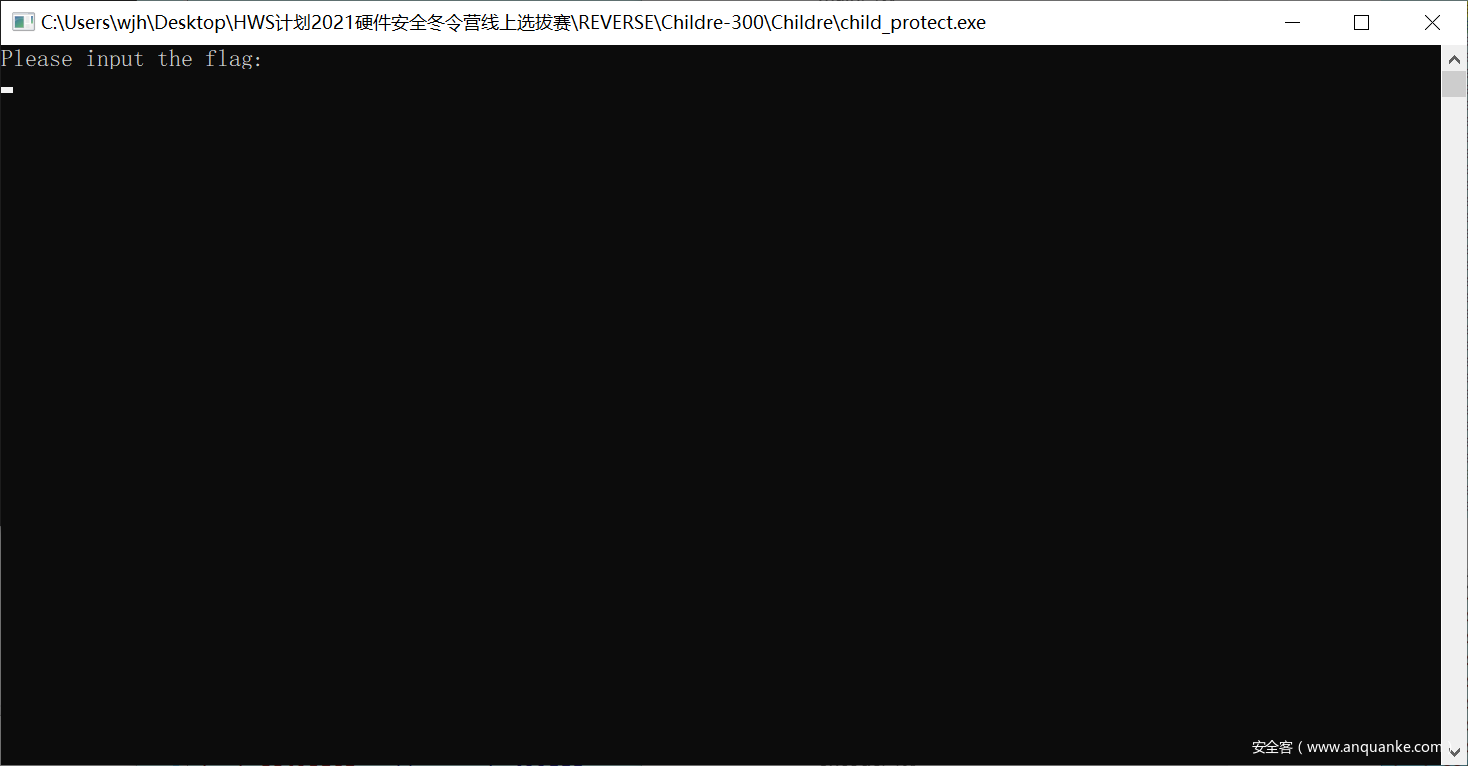
于是我们又手动修改EIP,跳到下面去执行
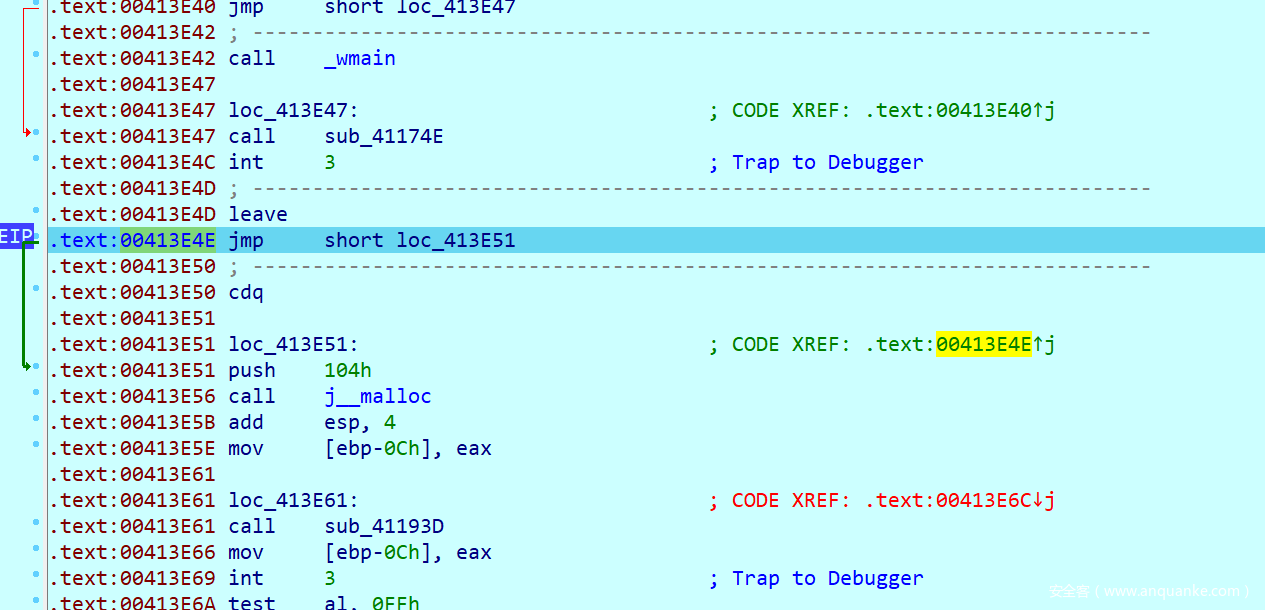
紧接着发现程序停在了这里,要我们输入flag的信息
输入后继续执行
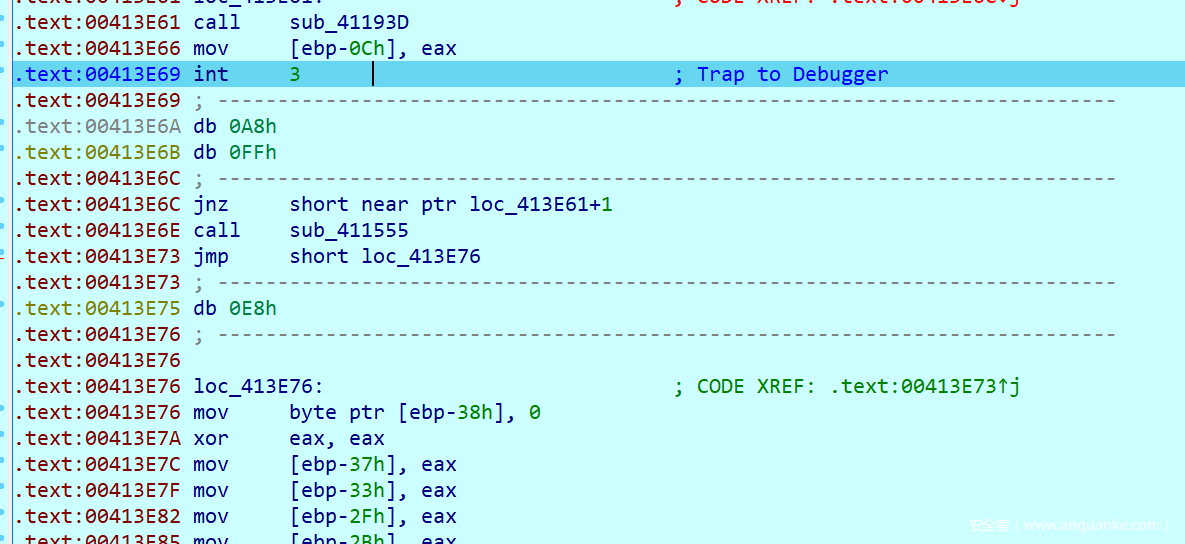
然后又到了一处int3,并发现这里的数据0xA8在调试器处理函数中需要让Eip + 9,我们计算后重新修改EIP
加密函数
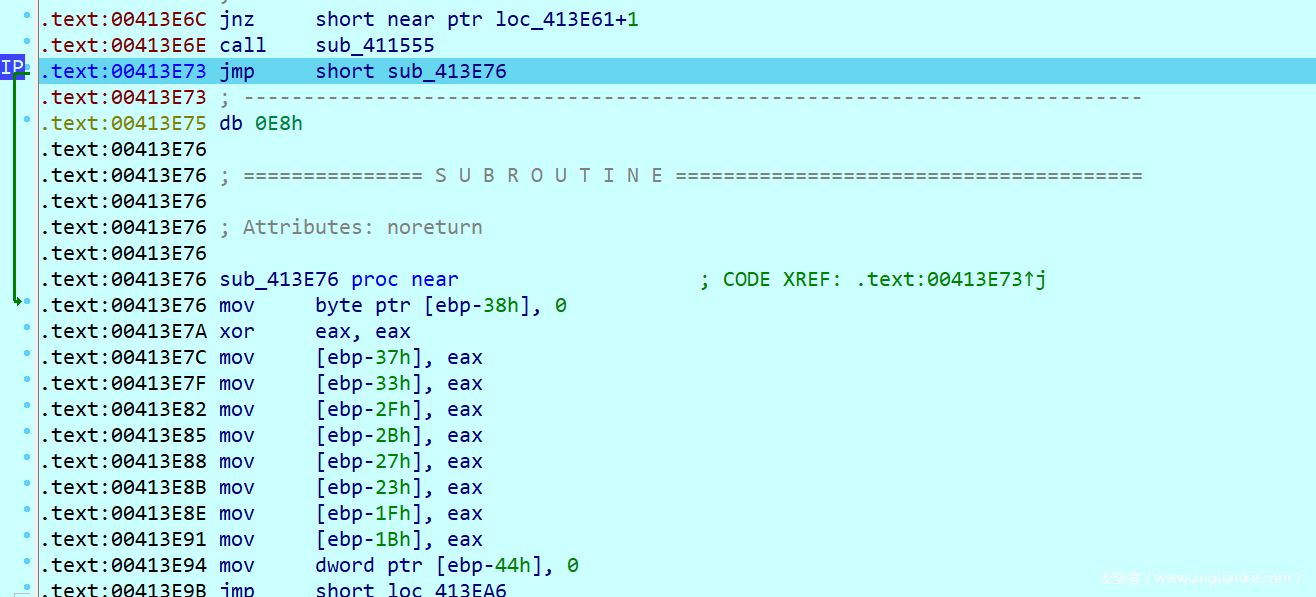
发现直接跳到下面的函数执行,我们查看伪代码发现伪代码非常的难看,没有识别出各个变量的信息
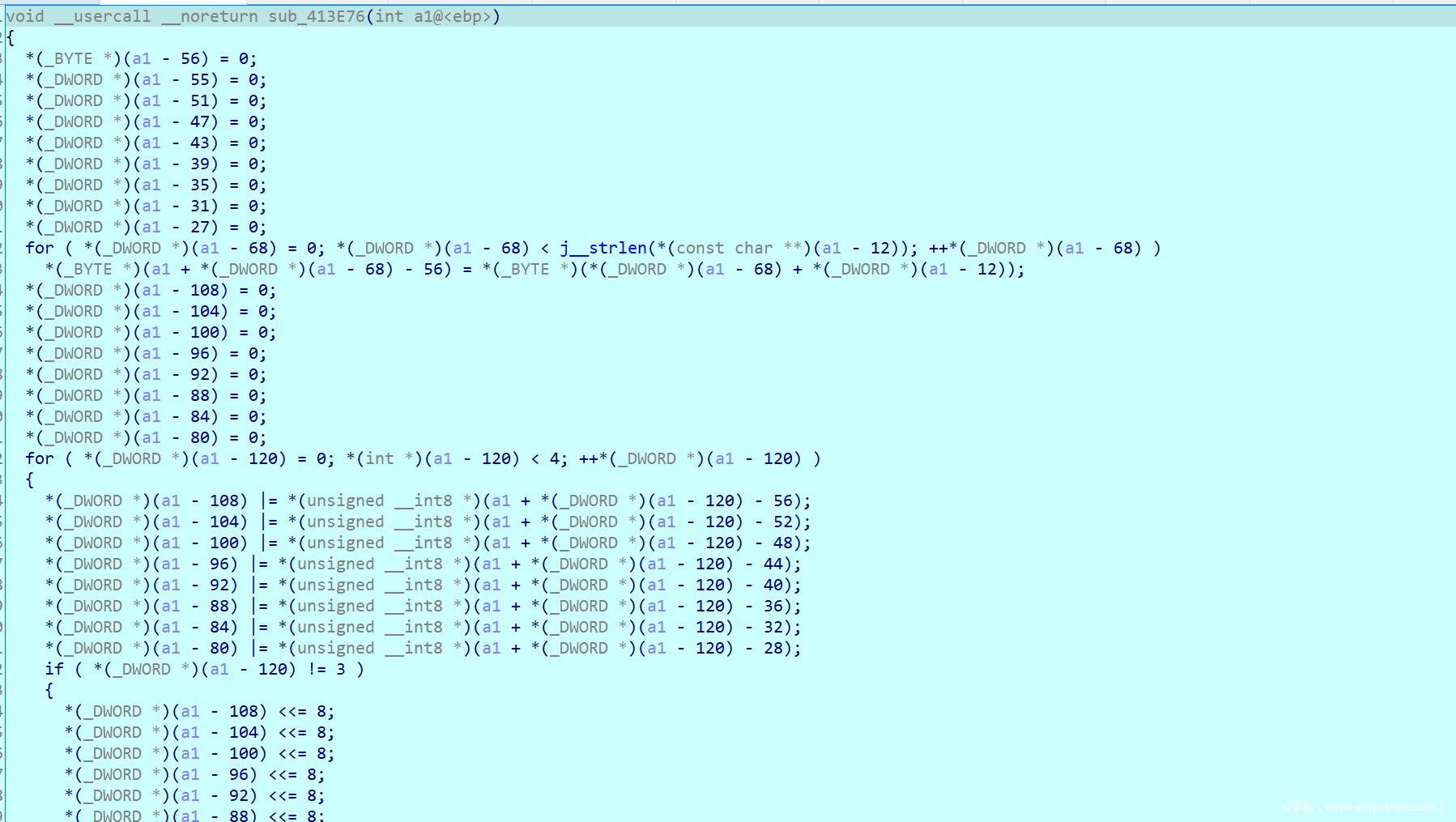
这里就要用到另一个技巧了,我们需要修补一下这里开头存栈的信息(实际上开头的信息是有的,但是被垃圾代码干扰了)
用Keypatch添加信息
push ebp
mov ebp,esp

虽然因为空间的原因覆盖了一行汇编代码,但是无所谓,我们这样修改只是为了伪代码能够识别出变量
接下来的伪代码就有变量信息了,接着我们修改一些能够直接看出来的变量类型,就可以得到一份比较舒服的伪代码了
我们接下来逐个分析
第一部分
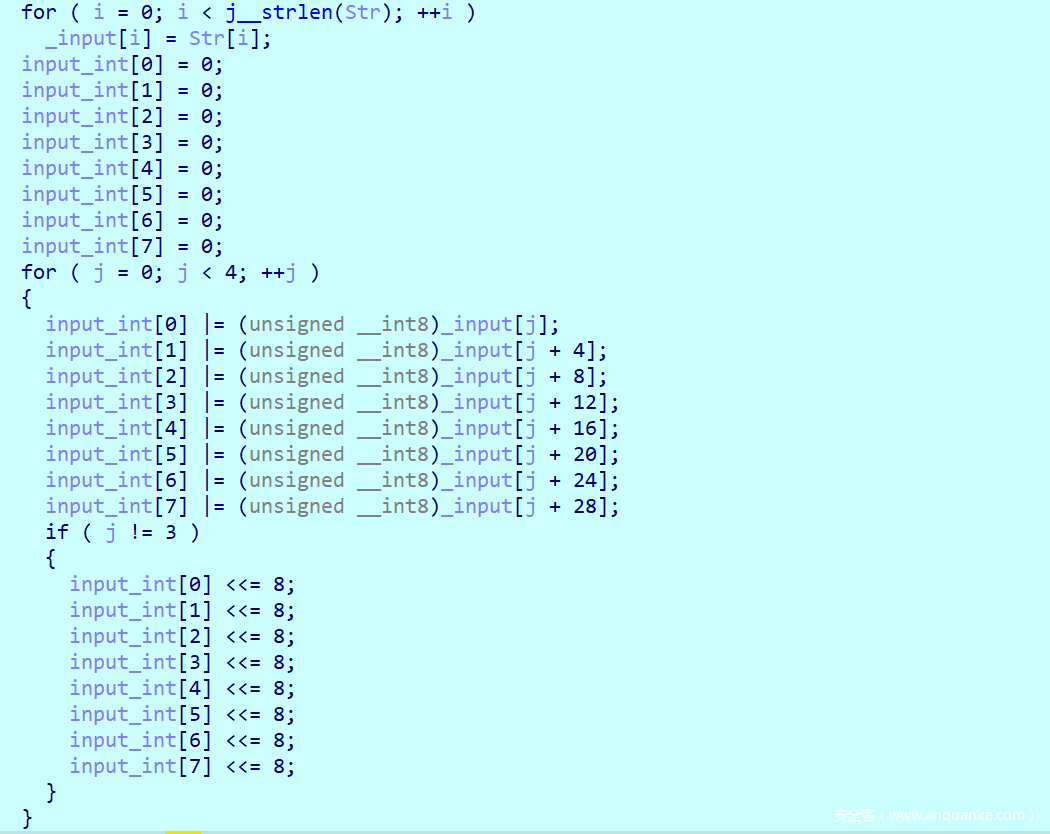
把Str的信息都赋值给input,其中Str就是我们输入的flag信息,然后通过循环把input的内容都转换为int数据储存给input_Int,大家可以眼熟一下这个模块,所干的事情就是把字符四字节的储存。
第二部分

把之前处理的input_int传入到这个函数中进行加密,并且把加密后的结果又转回字符形式

这里就是另一个坑点了,可以发现这个函数中存在一个int3断点,而其对应的内容是0xB2,按照之前所说的调试处理的逻辑,我们要替换ESP中的内容,并且让EIP + 1,查看汇编不难发现,他替换的内容就正好是传入push的一个值8E32CDAAh并且把他替换成0x73FF8CA6,这里我刚开始因为没有注意,死活解不出来。
这里因为inc ebp的原因导致IDA伪代码识别错误,而这行汇编是并不会执行的,所以我们把他nop掉之后再看伪代码。
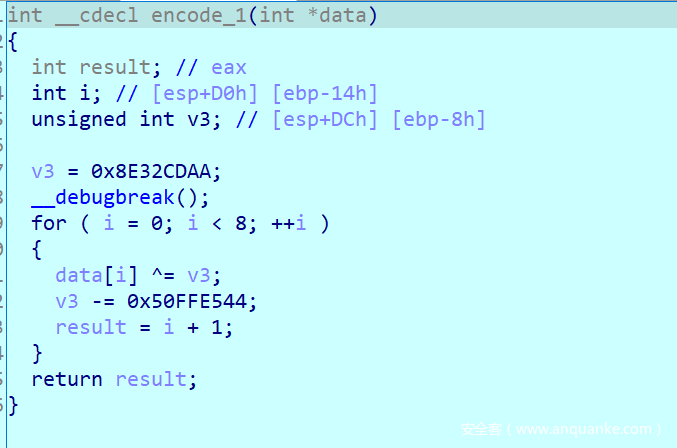
我们这里要替换的就是8E32CDAAh,否则加密后的结果和实际运行的不一致
第三部分

通过gen函数生成一些int的内容,具体啥过程并不重要,因为这些字符的内容都是固定的,并且把结果都放在gen_data中,然后又放到gen_data_char中
第四部分

最后加密一次后,与内部储存字符串比对,如果一致就输出right.
这里不知道为啥,明明只要比对32字节,数组却开到了36字节,并且计算过程也是循环了五次。
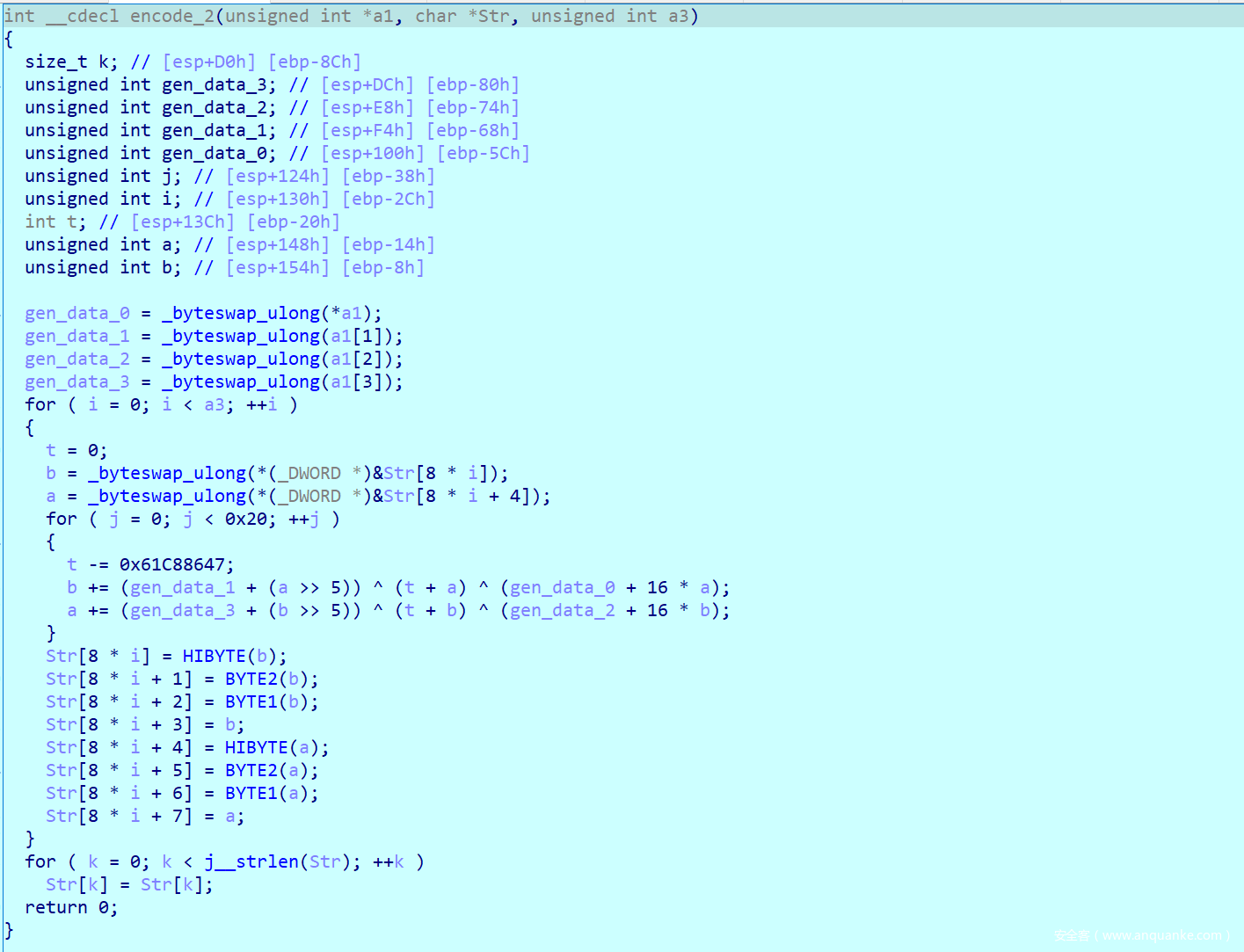
_byteswap_ulong函数实际上就是把char的内容转换成int,感觉挺无语了,前面刚刚转成char,现在又要转回int。
接下来通过一个for循环来对内容加密32次,加密之后又储存回去,这里gen_data的数据都是固定的,所以我们可以直接当做常数来计算
通过分析,发现这个循环的内容是可以完全逆向的,我们只需要循环32次来反向推,就可以得到原文的内容
总感觉有点奇怪,感觉有点像是某种加密算法,但是我也没看出来,就只能硬推了。
而且感觉他这个几个char和int的变换,总觉得是为了套函数模块来写的。
解密程序
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include "defs.h"
unsigned char data[32] =
{
0xED, 0xE9, 0x8B, 0x3B, 0xD2, 0x85, 0xE7, 0xEB,
0x51, 0x16, 0x50, 0x7A, 0xB1, 0xDC, 0x5D, 0x09,
0x45, 0xAE, 0xB9, 0x15, 0x4D, 0x8D, 0xFF, 0x50,
0xDE, 0xE0, 0xBC, 0x8B, 0x9B, 0xBC, 0xFE, 0xE1
};
int __cdecl encode_run(unsigned int* a1)
{
int i; // [esp+D1h] [ebp-13h]
unsigned int v3; // [esp+DCh] [ebp-8h]
v3 = 0x8E32CDAA;
for (i = 0; i < 8; ++i)
{
a1[i] ^= v3;
v3 -= 0x50FFE544;
}
return 0;
}
int decode_run(unsigned int* a1)
{
unsigned int v3 = 0x73FF8CA6;
//unsigned int v3 = 0x8E32CDAA;
for (int i = 0; i < 8; ++i) v3 -= 0x50FFE544;
for (int i = 8 - 1; i >= 0; i--)
{
v3 += 0x50FFE544;
a1[i] ^= v3;
}
return 0;
}
int decode_run3(unsigned int* Str, unsigned int cnt)
{
for (int i = 0; i < cnt; i++)
{
unsigned int t = 0;
unsigned int a = Str[i * 2], b = Str[i * 2 + 1];
for (int j = 0; j < 0x20; j++) t += 0x9E3779B9;
for (int j = 0; j < 0x20; j++)
{
b -= (0xA2394568 + (a >> 5)) ^ (t + a) ^ (0x87EC6B60 + 16 * a);
a -= (0xAC1DDCA8 + (b >> 5)) ^ (t + b) ^ (0x82ABA3FE + 16 * b);
t -= 0x9E3779B9;
}
Str[i * 2] = a;
Str[i * 2 + 1] = b;
}
return 0;
}
int __cdecl encode_run3(unsigned __int8* Str, unsigned int cnt)
{
size_t k; // [esp+D0h] [ebp-8Ch]
unsigned int v5; // [esp+DCh] [ebp-80h]
unsigned int v6; // [esp+E8h] [ebp-74h]
unsigned int v7; // [esp+F4h] [ebp-68h]
unsigned int v8; // [esp+100h] [ebp-5Ch]
unsigned int j; // [esp+124h] [ebp-38h]
unsigned int i; // [esp+130h] [ebp-2Ch]
int v11; // [esp+13Ch] [ebp-20h]
unsigned int v12; // [esp+148h] [ebp-14h]
unsigned int v13; // [esp+154h] [ebp-8h]
for (i = 0; i < cnt; ++i)
{
v11 = 0;
v13 = _byteswap_ulong(*(_DWORD*)&Str[8 * i]);
v12 = _byteswap_ulong(*(_DWORD*)&Str[8 * i + 4]);
for (j = 0; j < 0x20; ++j)
{
v11 += 0x9E3779B9;
v13 += (0xAC1DDCA8 + (v12 >> 5)) ^ (v11 + v12) ^ (0x82ABA3FE + 16 * v12);
v12 += (0xA2394568 + (v13 >> 5)) ^ (v11 + v13) ^ (0x87EC6B60 + 16 * v13);
}
Str[8 * i] = HIBYTE(v13);
Str[8 * i + 1] = BYTE2(v13);
Str[8 * i + 2] = BYTE1(v13);
Str[8 * i + 3] = v13;
Str[8 * i + 4] = HIBYTE(v12);
Str[8 * i + 5] = BYTE2(v12);
Str[8 * i + 6] = BYTE1(v12);
Str[8 * i + 7] = v12;
}
return 0;
}
void encode_all(char* a)
{
unsigned char s[36] = { 0 };
unsigned int data[8] = { 0 }, t1[8] = { 0 };
for (int i = 0; i < 32; i++)
s[i] = a[i];
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 8; j++)
{
data[j] |= a[j * 4 + i];
if (i != 3) data[j] <<= 8;
}
}
encode_run(data);
for (int i = 0; i < 8; i++)
{
s[4 * i + 0] = (data[i] & 0xFF000000) >> 24;
s[4 * i + 1] = (data[i] & 0xFF0000) >> 16;
s[4 * i + 2] = (data[i] & 0xFF00) >> 8;
s[4 * i + 3] = (data[i]);
}
encode_run3(s, 4);
for (int i = 0; i < 32; i++)
a[i] = s[i];
}
int rev(int x)
{
unsigned int data = 0;
unsigned char a2[4];
for (int i = 0; i < 4; ++i) a2[i] = x >> (24 - 8 * i);
for (int i = 0; i < 4; i++) data ^= a2[4 - i - 1] << (24 - 8 * i);
return data;
}
int main()
{
//char s[33] = {0};
//scanf("%s", s);
//encode_all(s);
unsigned int d[8];
for (int i = 0; i < 8; i++) d[i] = rev(((unsigned int*)data)[i]);
decode_run3(d, 4);
decode_run(d);
for (int i = 0; i < 8; i++) d[i] = rev(d[i]);
for (int i = 0; i < 32; i++)
printf("%c", ((char*)d)[i]);
return 0;
}







发表评论
您还未登录,请先登录。
登录