

摘要
网络钓鱼的持续增长和钓鱼网站数量的不断增加,导致世界各地的个人和组织越来越容易受到各种网络攻击。因此,为了提高网络防御能力,需要更有效的网络钓鱼检测。因此,在本文中,我们提出了一种基于深度学习的方法,以实现对钓鱼网站的高精度检测。所提出的方法利用卷积神经网络(CNN)进行高精度分类,以区分真正的网站和钓鱼网站。我们使用从6,157个真实网站和4,898个钓鱼网站获得的数据集来评估这些模型。基于大量的实验结果,我们的基于CNN的模型被证明在检测未知钓鱼网站方面非常有效。此外,基于CNN的方法比在相同数据集上评估的传统机器学习分类器表现更好,达到了98.2%的网络钓鱼检测率,F1-score为0.976。本文提出的方法与基于深度学习的钓鱼网站检测现状相比,具有较好的优势。
第一节. 导言
网络钓鱼是一种基于社会工程的攻击,它使网络犯罪分子能够窃取凭证,传播勒索软件,进行金融欺诈和盗窃。它还能使国家行为者获得进入目标环境的战略通道。通过精心设计的假冒网站,利用网络钓鱼从毫无戒备的用户那里获取私人敏感信息,如账号和密码。2019年Phishlabs趋势和情报报告[1]指出,2018年网络钓鱼增长了40.9%,观察到的攻击中有83.9%针对金融、电子邮件、云、支付和SaaS服务的凭证。根据报告,2018年第一季度,钓鱼网站(即位于唯一完全合格域名或主机上的钓鱼内容)的数量稳步上升,并在整个第二和第三季度保持高位。此外,每月观察到的钓鱼网站总数大大超过了往年。
由于需要采取有效的应对措施,使得网络钓鱼检测成为近年来研究的热门领域。因此,出现了三大类网络钓鱼检测的方法。(a)基于黑名单和白名单的方法[2]、3基于网页视觉相似性的方法4基于URL和网站内容特征的方法[5]。黑名单方法对系统尚未更新的新钓鱼网站的检测效果不佳。基于视觉相似性的方法从钓鱼网站中提取视觉特征,然后利用这些特征来识别钓鱼网页。因此,任何网页内容的失真都会影响视觉内容的检索,导致误分类。目前大多数的钓鱼检测方法都是利用URL和网页内容特征来区分钓鱼网站和真正的网站,如[5],[6]。机器学习技术也已经与URL和网页内容特征相结合,以提高检测性能,实现零日钓鱼防御,例如[7][8]-[9]。
鉴于网络钓鱼攻击的持续增长和钓鱼网站的稳步上升,我们从未像现在这样需要更有效的手段来检测可疑网站和挫败零日钓鱼攻击。因此,在本文中,我们提出了一种基于深度学习的方法,利用卷积神经网络(CNN)进行高精度的钓鱼网站检测。我们的方法利用URL和网页内容特征来构建基于机器学习的钓鱼检测模型,该模型能够检测新的、以前未曾见过的钓鱼网站。
我们介绍了基于CNN的钓鱼网站检测模型的设计,并在从4,898个钓鱼网站和6,157个真实网站[10]、[14]中获得的数据集上评估了该模型。此外,我们还将我们的CNN模型与其他流行的机器学习分类器(包括Naïve Bayes、Bayes Net、Decision Tree、SVM、Random Forest、Random Tree和Simple Logistic)在同一数据集上的性能进行了比较。对比分析表明,基于CNN的模型最终达到了98.2%的最佳网络钓鱼检测性能,F1-score 0f 0.976。
本文其余部分的结构如下。相关工作在第二节;第三节介绍了CNN的背景;第四节介绍了方法论和所做的实验;第五节给出了实验结果,最后第六节介绍了研究结论和未来工作。
第二节. 相关工作
基于机器学习的网络钓鱼检测是一个不断发展的研究领域,人们对深度学习技术的应用越来越感兴趣。Yuan等人[9],提出了一种基于URL和网页链接的特征来检测钓鱼网站及其目标的方法。他们利用深度森林模型,使真阳率达到98.3%,误报率为2.6%。特别是他们设计了一种基于搜索算子通过搜索引擎寻找钓鱼目标的有效策略,准确率达到93.98%。
Wang等[8]提出了PDRCNN,这是一种仅利用网站的URL建立检测模型的钓鱼网站检测方法。他们的系统结合RNNs和CNN从URL字符串中提取特征。在他们的实验中,检测精度达到97%,AUC达到99%。Bahnsen等人[15]提出了一种LSTM模型来检测钓鱼网址。他们的方法首先使用一热编码对URL字符串进行编码,然后将每个编码后的字符向量输入到LSTM神经元中进行训练和测试。他们的方法在Common Crawl和PhishTank数据集上的准确率达到了0.935。Hung等人[16],提出了用于恶意网站URL检测的URLNet方法。他们基于URL字符串提取字符级和单词级特征,利用卷积神经网络进行训练和测试。作者[17]提出并评估了一种利用自然语言处理(NLP)技术从URL中提取特征的系统。他们的系统是通过检查钓鱼攻击中使用的URL并从中提取特征来实现的。作者在几种机器学习算法上测试了他们的系统,发现随机森林的性能最好,成功率为89.9%。只有URL的方法的缺点是,如果URL本身缺乏相关语义,或者URL的有效性存在问题,可能无法获得正确的分类[8]。本文提出的基于CNN的方法不仅利用了URL特征,还利用了网站其他属性的特征,提高了鲁棒性。
在[18]中,作者提出了一种混合型智能钓鱼网站预测系统,采用深度神经网络(DNN)与基于进化算法的特征选择和加权方法进行增强预测。遗传算法(GA)用于启发式地确定网站特征中最具影响力的特征和最佳权重。与[18]中的研究不同,我们的方法不需要特征选择阶段,因为这是在基于CNN的模型中隐含执行的,因为它的设计。其他基于深度学习的钓鱼检测工作包括[19]、[23],有些研究是从邮件[20][21]-[22]中提取特征,而不是URL和网页特征。
第三部分.背景
A. 卷积神经网络(CNN)
CNN属于人工神经网络家族,它是受生物神经网络特性启发的计算模型。CNN是一种深度学习技术,它能很好地识别数据中的简单模式,然后将用于在后续层中形成更复杂的模式。构建CNN通常使用两种类型的层,卷积层和池化层。卷积层的作用是检测前一层特征的局部联合,而池化层的作用是将语义相似的特征合并成一个[11]。
一般情况下,卷积层提取最优特征,池化层减少卷积层特征的维度,然后使用完全连接的层(s)进行分类。CNN的性能一般受层数和滤波器(内核)数量的影响。在CNN的更深层中提取的抽象特征越来越多,因此,所需的层数取决于被分析数据的复杂性和非线性。此外,每个阶段的过滤器数量决定了提取的特征数量。计算复杂性随着层数和滤波器数量的增加而增加。另外,随着架构的复杂化,有可能训练出一个过拟合的模型,从而导致测试集的预测精度低下。为了减少过拟合,我们在训练模型的过程中实现了 “dropout”[12]和 “批量正则化 “等技术。
B. 一维卷积神经网络
虽然CNN更常见的是以多维的方式应用,并因此在基于图像和视频分析的问题中获得了成功,但它们也可以应用于一维数据。拥有一维结构的数据集可以使用一维卷积神经网络(1D CNN)进行处理。一维CNN与二维或三维CNN之间的关键区别在于输入数据的维度以及滤波器(特征检测器)如何在数据上滑动。对于1D CNN,滤波器只在一个方向上滑动输入数据。当你希望从整个数据集的较短(固定长度)的片段中获得有趣的特征,并且片段中特征的位置相关性不高时,1D CNN是相当有效的。
1D CNN的使用可以常见于NLP应用中。同样,1D CNN也适用于包含矢量化数据的数据集,这些数据集被用来描述要预测的项目(例如一个网站)。1D CNN可用于提取潜在的更有辨别力的特征表示,这些特征表示描述了描述数据集中每个实体特征的向量的段内的任何现有模式或关系。然后,这些新的特征将被输入到分类器(例如一个完全连接的神经网络层)中,该分类器将反过来使用衍生的特征来做出最终的分类决策。因此,在这种情况下,卷积层可以被认为是一个特征提取器,它消除了对特征排序和选择的需求。本文开发的CNN模型被应用于网站特征的向量化数据,以推导出一个训练有素的模型,该模型能够以非常高的精度检测新的钓鱼网站。
C. 我们提出的CNN架构的主要内容
我们提出的CNN架构是由两个卷积层和两个最大池化层组成的1D CNN。之后是由N个单元组成的Fully Connected层,该层又连接到最后的分类层,其中包含一个具有sigmoid激活函数的神经元。
sigmoid激活函数由以下公式给出:S = 1/(1 + (e^(- x))
最后的分类会产生一个结果,对应于两个类别,即 “钓鱼 “或 “合法”。卷积层利用ReLU(Rectified Linear Units)激活函数,给出:f(x) = max(0,x)。ReLU有助于缓解消失和爆炸梯度问题[13]。已经发现,与经典的非线性激活函数(如Sigmoid或Tangent函数)相比,它在时间和成本方面对训练庞大的数据更有效[13]。我们架构的简化视图如图1所示。
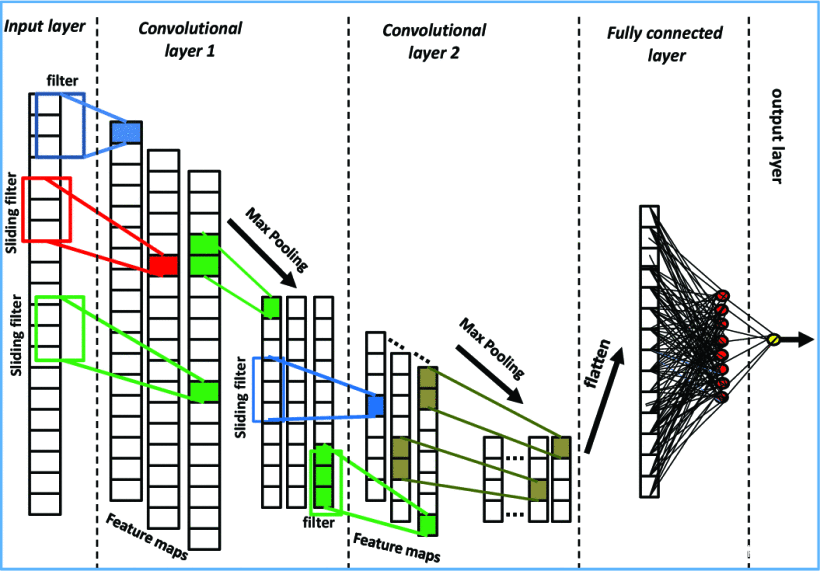
图1:实现的1D CNN模型的简化视图,用于钓鱼网站检测。
用于钓鱼网站检测的1D CNN模型的简化视图。
第四部分:方法和实验
在本节中,我们介绍了为评估本文开发的CNN模型而进行的实验。我们的模型使用Python实现,并利用了带有TensorFlow后端的Keras库。使用的其他库包括Scikit Learn、Seaborn、Pandas和Numpy。该模型是在Ubuntu Linux 16.04 64位机器上建立和评估的,内存为4GB。
A. 问题定义
让W ={w1,w2,……wn}是一组网站样本,其中每个wi用一个包含f个属性值的向量表示(如表1所示)。让wi ={a1,a2,a3 …af,cl}其中cl∈{Phishing,Legitimate}是分配给网站的类标签。因此,w可以用来训练模型,分别学习Phishing和Legitimate网站的行为。然后,训练模型的目标是通过分配一个标签cl,其中cl∈{Phishing,Legitimate},对给定的无标签网站wunknown = {a1,a2,a3 …af,?}进行分类。
B. 资料集
在我们的实验中,我们使用了[10]的基准数据集。数据集中的特征/属性的详细描述可以在[5]、[10]和[14]中找到。表1列出了属性的摘要。数据集包括从4,898个钓鱼网站和6,157个合法网站获得的11,055个实例。
表1数据集中钓鱼网站和合法网站的特征。

C. 评估所提出的基于CNN模型的实验
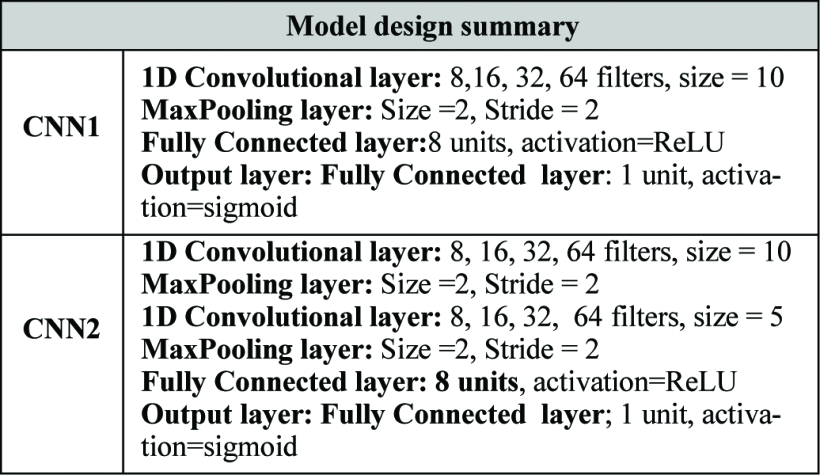
为了研究我们提出的模型的性能,我们进行了不同的实验。第一组实验旨在评估不同层数对模型性能的影响。表2显示了CNN模型的配置。CNN1由1个卷积层组成,然后是一个最大池化层。最大池化层的输出被扁平化,并传递给一个有8个单元的全连接层。这又连接到一个包含1个单元的sigmoid激活输出层。CNN2具有相同的配置,但有两组卷积层和最大池化层,如表2所示。在这组实验中,还改变了滤波器(内核)的数量,以考察对模型性能的影响。
第二组实验是在保持过滤器数量固定的情况下,改变过滤器的长度(即内核大小)。实验的结果将在下一节讨论。为了衡量模型的性能,我们使用了以下指标。准确率,精度,召回率和F1分数。这些指标定义如下。
准确度。定义为正确预测的结果和所有预测结果之和的比率。它的计算公式为 (TP+TN)/(TP+TN+FP+FN)
精确度:所有真实的阳性结果除以所有阳性预测结果。所有真正的阳性除以所有阳性预测,即模型预测阳性时是否正确?由以下公式给出。TP/(TP+FP)
召回。真正的阳性除以所有实际的阳性,即模型在所有可能的阳性中识别了多少个阳性?即模型在所有可能的阳性中识别了多少个阳性?由以下公式给出:TP/(TP+FN )
F1得分。这是精度和召回率的加权平均值,由以下公式得出: (2x Recall x Precision)/(Recall + Precision)
表2:实验中使用的模型配置汇总。
其中TP为真阳性;FP为假阳性;FN为假阴性,而TN为真阴性(与钓鱼类有关)。所有的实验结果都来自于10倍交叉验证,其中数据集被分为10等份,10%的数据集拿出来进行测试,而模型则从剩下的90%中进行训练。这样重复进行,直到10个部分全部用于测试。然后取所有10个结果的平均值,得出最终结果。另外,在CNN模型的训练过程中(对于每个折线),训练集的10%用于验证。
第五节:结果和讨论
A. 层数和滤波器数量的影响。
在本节中,我们分别考察CNN1和CNN2的结果。表3显示了运行CNN1与不同数量的过滤器的结果。表4是CNN2与不同数量的过滤器的结果。从表3可以看出,过滤器的数量对CNN1模型的性能有影响。在过滤器数量较多的情况下(32,64),可以观察到较高的准确率为96.6%。而在过滤器数量较多(32,64)时,可以观察到0.97的F1分数。如前所述,滤波器数量表示被提取的特征数量,滤波器数量越多,模型的复杂度越高,因此需要训练的参数也越多。需要注意的是,对于CNN1模型,使用32个滤波器和64个滤波器可以获得类似的性能,而分别需要训练2969个与5913个参数,从表3可以看出。8个滤波器和16个滤波器的总体准确率分别为95.8%和96.2%。每种情况下使用的滤波器长度固定为10。
表3:1层CNN结果(使用的滤波器长度=10)。
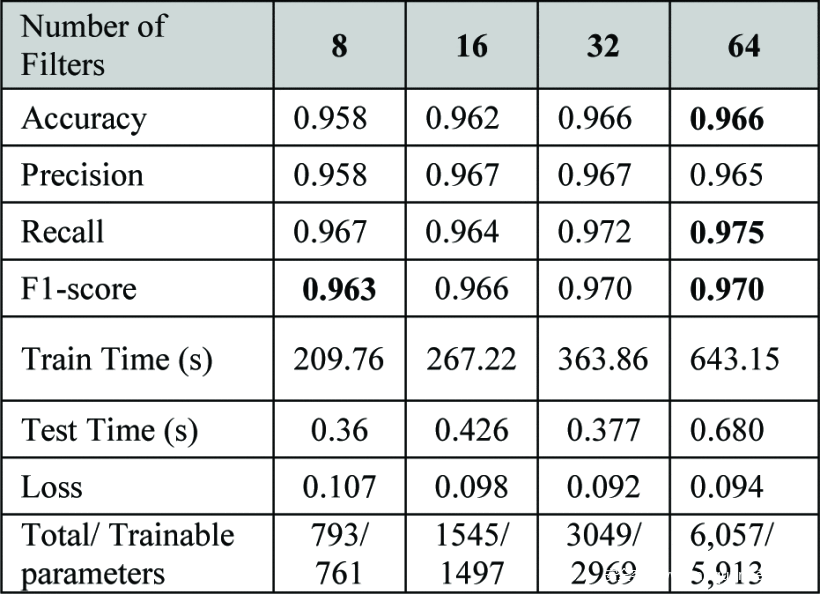
表4:2层CNN结果(第一层使用的滤波器长度=10,第二层=5)。
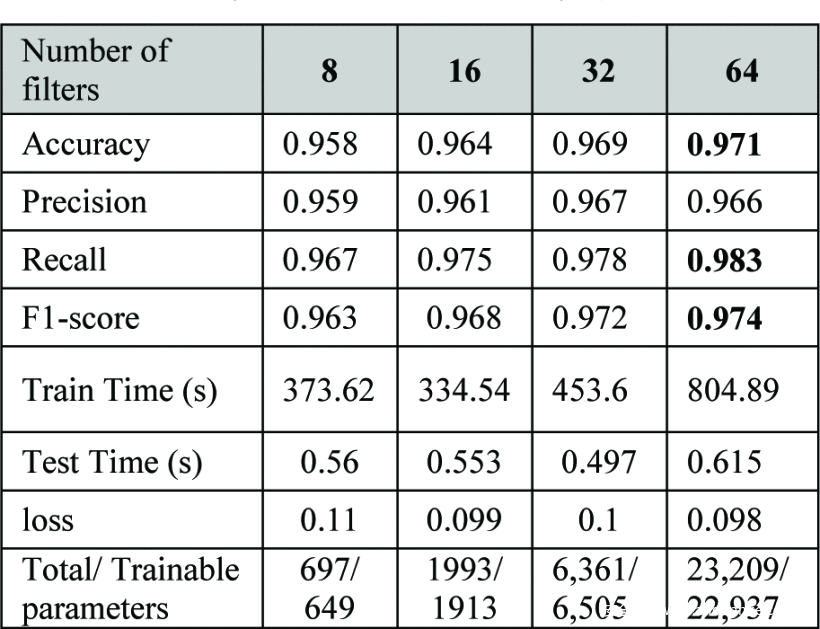
从表4可以看出,两组卷积层和最大池化层(CNN2)的结果比CNN1有所改进。然而,改进的幅度表明,再增加一个CNN层(使其成为3层CNN模型)不太可能显著提高性能,而要训练的参数数量将大幅增加。与CNN1一样,使用的滤波器数量可以提高CNN2模型的性能。使用64个滤波器后,准确率最高,达到97.1%,F1-score为0.974,而只使用8个滤波器时,准确率为95.8%,F1-score为0.963。
1)训练时长、损失和准确率图。
图2和图3显示了在训练纪元到220个纪元期间,使用验证集和训练集获得的典型输出。从图2中可以看出,训练和验证的精度匹配度相当接近,说明训练并没有对训练集的模型进行过度拟合。图3显示了实验过程中观察到的典型损失行为。训练损失和验证损失也相当紧密地相互跟随。为了增加获得 “最佳 “训练模型的可能性,并减少训练时间,我们实施了一个 “停止标准”,一旦在50个纪元内观察到性能没有改善,就会停止训练。
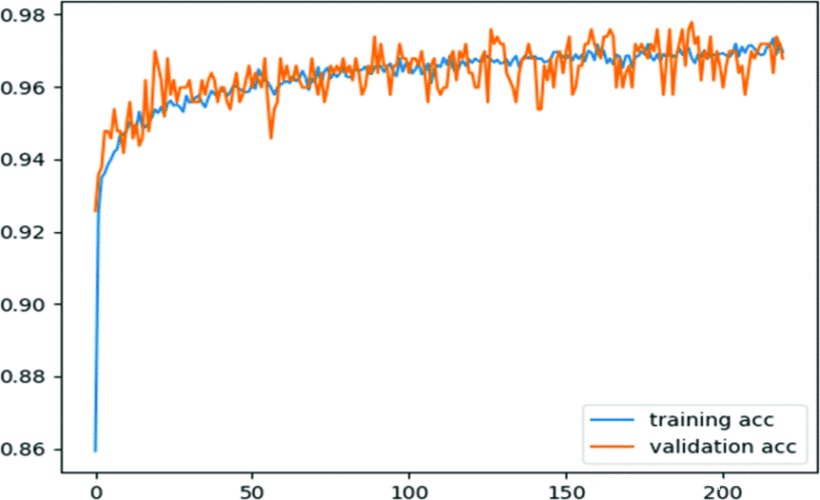
图2.CNN模型在不同时间段的训练和验证准确率,最高达220。
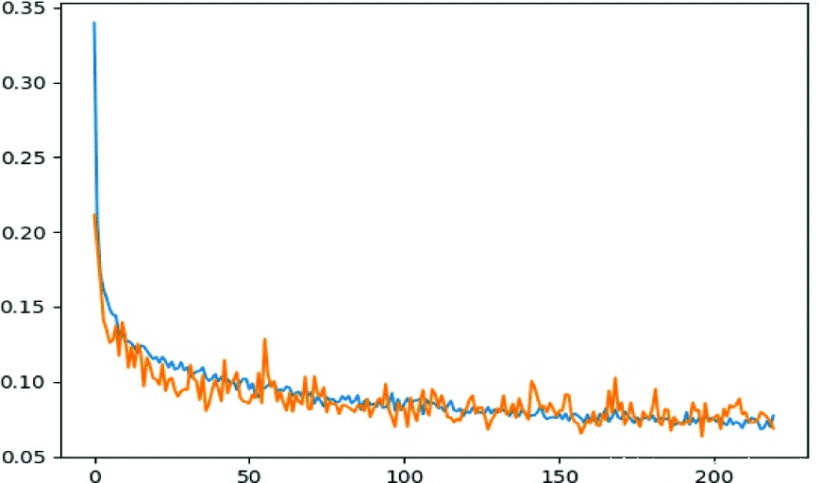
图3.CNN模型在不同时间段的训练和验证损失,最高达220次。
B. 滤波器长度对性能的影响。
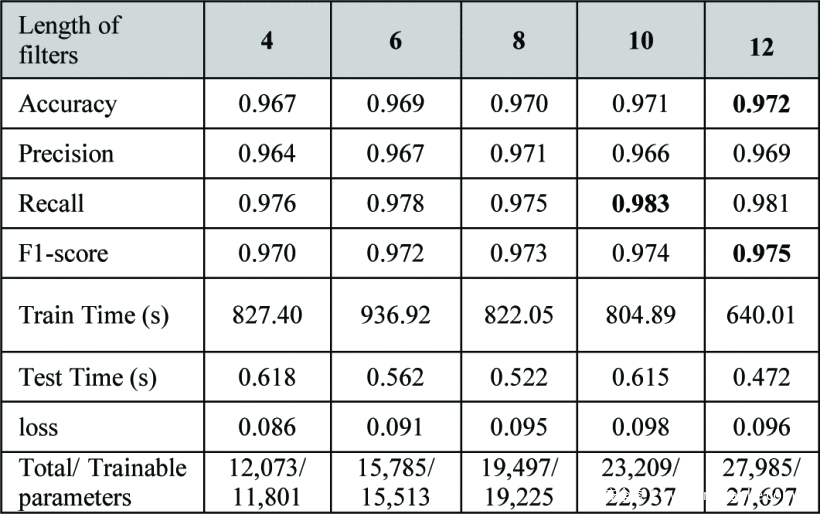
在本节中,我们通过使用CNN2模型,过滤器的数量固定为64个,来考察过滤器长度的影响。长度分别为4、6、8、10和12。结果表明,当第一卷积层的滤波器长度设置为12时,准确率最高,达到97.2%,F1-score为0.975。回顾我们的模型设计中,第二卷积层的滤波器长度设置为第一层的一半。
从表5中可以看出,滤波器长度为12(第二卷积层为6),总体准确率为97.2%,F1-score为0.975;相比之下,滤波器长度为4,总体准确率为96.7%,F1score为0.970。
表5:滤波器长度(CNN2);滤波器数量=64。
1)获得最佳性能
由于有多个参数需要调整,实现CNN模型的最佳性能点是非平凡的。我们进一步试验了全连接层中不同的单元数,将第一层的滤波器数量保持在64个,长度保持在12个,第二层为6个。得到的最佳结果(使用CNN2模型)如下。准确度:0.973;精确度:0.970;召回率:0.982。0.982;F1-score:0.976。这是通过将全连接层中的单元数从8个单元增加到32个单元而得到的。在这种配置下,可训练参数的数量只增加到29 793个。
C. CNN性能与其他机器学习分类器的比较:10倍交叉验证结果。
在表6中,本文开发的CNN架构的性能与其他机器学习分类器进行了比较。Naïve Bayes、SVM、Bayes Net、J48、随机树和随机森林。图4显示了分类器的F1-分数,其中CNN的F1-分数最高,其次是随机森林和随机树。图5描述了整体的准确率,其中CNN优于6个分类器,随机森林达到了同样的准确率。表6显示,CNN的召回率为0.982,说明与其他7个分类器相比,CNN的钓鱼网站检测率最好。
表6.CNN与其他ML分类器的比较
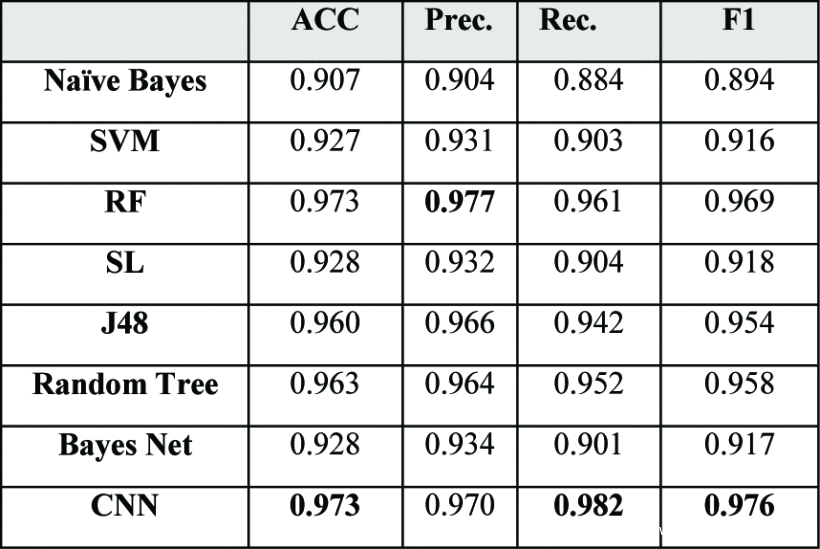
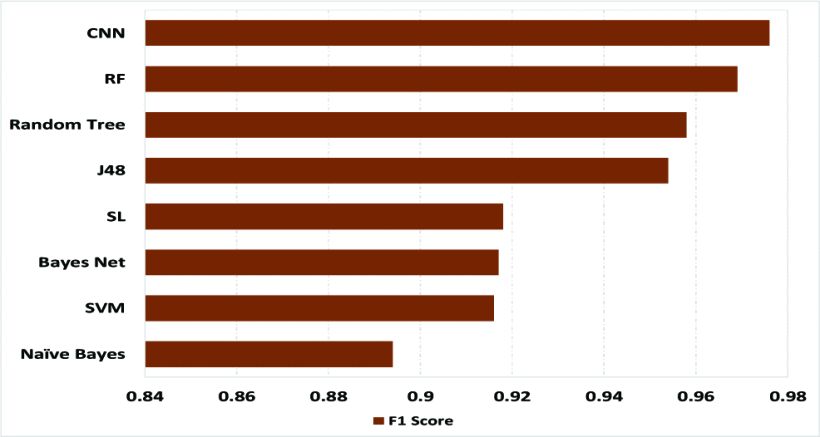
图4:F1得分
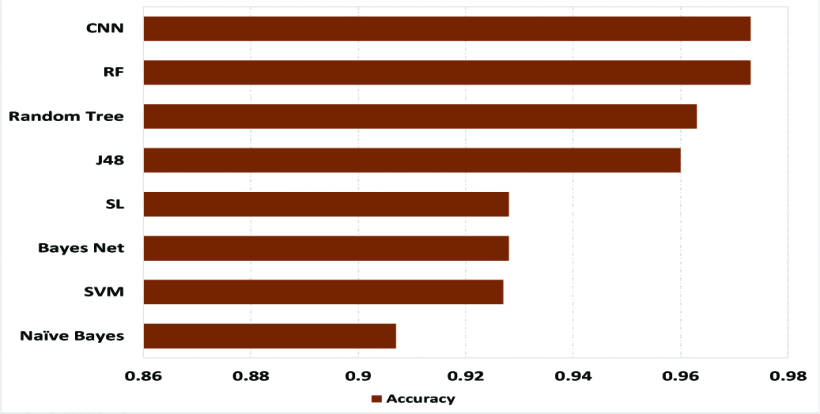
图5:整体精度。
第六节. 结论和今后的工作
在本文中,我们提出了一种基于1D CNN的深度学习模型来检测钓鱼网站。我们通过在一个基准数据集上的大量实验来评估该模型,该数据集分别包含来自钓鱼网站和合法网站的4,898个实例和6,157个实例。该模型的表现优于在同一数据集上评估的几个流行的机器学习分类器。结果表明,我们提出的基于CNN的模型可以比其他模型更准确地检测新的、以前未见过的钓鱼网站。在未来的工作中,我们将致力于通过自动搜索和选择关键影响参数(即过滤器的数量、过滤器的长度和完全连接单元的数量)来改进模型训练过程,从而共同获得性能最佳的CNN模型。
引用
- “2019 Phishing Trends and Intelligence Report: The Growing Social Engineering Threat” 2019 [online] Available: https://www.phishlabs.com/.
2.A. K. Jain and B. B. Gupta “A novel approach to protect against phishing attacks at client side using auto-updated white-list” EURASIP Journal on Information Security vol. 2016 no. 1 pp. 9 2016.
3.P. Prakash M. Kumar R. Rao Kompella and M. Gupta “Phishnet: predictive blacklisting to setect phishing attacks” Proceedings of 29th IEEE Conference on Computer Communications (Infocom) pp. 1-5 March 2010.
4.A. K. Jain and B. B. Gupta “‘Phishing Detection: Analysis of Visual Similarity Based Approaches’” Security and Communication Networks vol. 2017 pp. 1-20 2017.
5.R. M. Mohammad L. McCluskey and F. Thabtah “Intelligent rule-based phishing websites classification” IET Information Security vol. 8 no. 3 pp. 153-160 2014.
6.S. C. Jeeva and E. B. Rajsingh “Intelligent hishing URL detection using association rule minning” Human-centric Computing and Information Sciences vol. 6 pp. 10 2016.
7.R. M. Mohammad F. Thabtah and L. McCluskey “Predicting phishing websites based on self-structuring neural network” Neural Computing and Applications vol. 25 no. 2 pp. 443-458 Aug 2014 [online] Available: https://doi.org/10.1007/s00521-013-1490-z.
8.W. Wang F. Zhang X. Luo and S. Zhang “PDRCNN: Precise Phishing Detection with Recurrent Convolutional Neural Networks Security and Coomunication Networks” vol. 2019 [online] Available: https://doi.org/10.1155/2019/2595794.
9.H. Yuan X. Chen Y. Li Z. Yang and W. Liu “Detecting Phishing Websites and Targets Based on URLs and Webpage Links” 2018 24th International Conference on Pattern Recognition (ICPR) pp. 3669-3674 2018.
10.”Phishing Websites Dataset” [online] Available: https://archive.ics.uci.edu/ml/datasets/phishing+websites.
11.Y. LeCun Y. Bengio and G. Hinton “Deep learning” Nature vol. 521 no. 7553 pp. 436-444 2015.
12.N. Srivastava G. Hinton A. Krizhevsky I. Stuskever and R. Salakhutdinov “Dropout: A simple way to prevent neural networks from overfitting” The Journal of Machine Learning Research vol. 15 no. 1 pp. 1929-1958 2014.
13.X. Glorot A. Bordes and Y. Bengio “Deep sparse rectifier neural networks” Proc. 14th Int. Conf. Artif. Intell. Statist pp. 315-323 2011.
14.R. M. Mohammad F. Thabtah and L. McCluskey “Phishing Websites Features” 2015 [online] Available: http://eprints.hud.ac.uk/id/eprint/24330/6/MohammadPhishing14July2015.pdf.
15.A. Correa Bahnsen E. Contreras Bohorquez S. Villegas J. Vargas and F. A. González “Classifying phishing URLs using recurrent neural networks” Proceedings of APWG Symposium on Electronic Crime Research (eCrime) pp. 1-8 April 2017.
16.L. Hung Q. Pham D. Sahoo and S. C. H. Hoi “Urlnet: learning a URL representation with deep learning for malicious URL detection” 2018 [online] Available: https://arxiv.org/abs/1802.03162.
17.E. Buber B. Dırı and O. K. Sahingoz “Detecting phishing attacks from url by using nlp techniques” 2017 International Conference on Computer Science and Engineering (UBMK) pp. 337-342.
18.W. Ali and A. A. Ahmed “Hybrid intelligent phishing website prediction using deep neural networks with genetic algorithm-based feature selection and weighting” IET Information Security vol. 13 no. 6 pp. 659-669 2019.
19.X. Zhang D. Shi H. Zhang W. Liu and R. Li “Efficient Detection of Phishing Attacks with Hybrid Neural Networks” 2018 IEEE 18th International Conference on Communication Technology (ICCT) pp. 844-848 2018.
20.S. Bagui D. Nandi S. Bagui and R. J. White “Classifying Phishing Email Using Machine Learning and Deep Learning” 2019 International Conference on Cyber Security and Protection of Digital Services (Cyber Security) pp. 1-2 2019.
21.T. Peng I. Harris and Y. Sawa “Detecting phishing attacks using natural language processing and machine learning” 2018 IEEE 12th International Conference on Semantic Computing (ICSC) pp. 300-301 Jan 2018.
22.R. Vinayakumar H.B. Barathi M. K. Anand and KP Soman “Deep Anti-PhishNet: Applying Deep Neural Networks for Phishing Email Detection” 4th ACM International Workshop on Security and Provacy Analytics (IWSPA 2018) 21-03-2018.
23.W. Chen W. Zhang and Y. Su “Phishing detection research based on LSTM recurrent neural network” Proceedings of International Conference of Pioneering Computer Scientists Engineers and Educators pp. 638-645 September 2018.







发表评论
您还未登录,请先登录。
登录