

https://github.com/tech-srl/Nero
ida处理
处理的关键命令为
'cd /tmp/tmpfs/tower/indexer/tmpgk_ba2pk;TVHEADLESS=1 /opt/ida-6.95/idal64 -B -S"/home/tower/10t-net/tower/Nero/datagen/ida/py2/bin_extract.py" gcc-5__Ou__adns__adnsresfilter_record > /dev/null'
这里创建了临时目录在临时目录下进行操作,这个目录下好像是比较快的。
用windows下ida7.0运行对应的idapython脚本得到了具体的文件文件结构为一个bin_extract.log,一个extern.json还有一堆类似print_pacct_record.bindump.json文件。
前面print_pacct_record为函数名。
extern.json
每个文件一个,导入函数信息,,全局字符串等信息,段信息
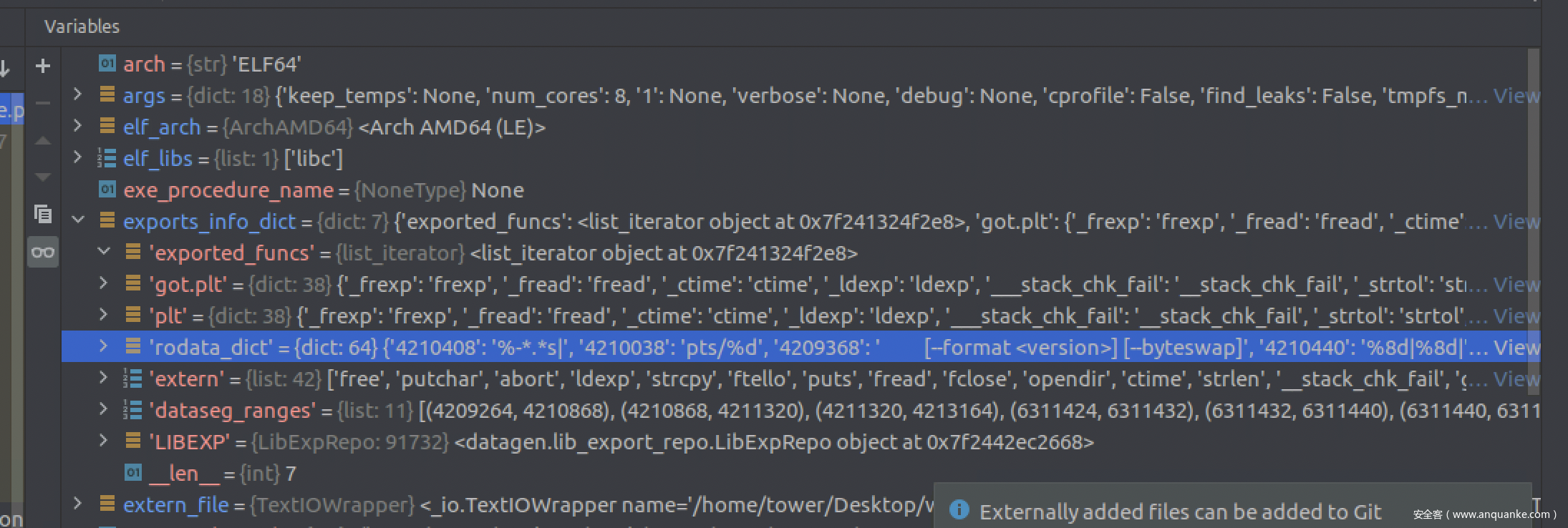
文件格式如下
- exported_funcs为导出函数的迭代器对象
- got.plt 为got表下的名称:真实名称键值对。
- plt和got类似。
- extern为导入函数名列表
- data_ranges 为段地址的范围
.bindump.json
每个函数包含一个.bindump.json

在用windows下ida7.0获取了分析结果之后我们把文件搬到了linux下更改了几个目录继续运行下面的分析
生成VEX
取出每个块对应的汇编指令结构(包括汇编指令,每条汇编指令的地址,对应的字节码)
对mips32和arm中的call指令一块切割成多块,mips需要对函数调用指令的下一个指令放到函数调用前(mips流水线机制)
对每个块获取二进制字节码索引,开始地址后继反汇编,结束地址(对arm和mips是需要对call进行切割的)
以块为单位转化为中间语言
转中间语言
作者实现了汇编语言专为vex的实现过程bytes_to_irsbs
中间语言转化过程会分割下面这些指令类型
VMOV', 'VMVN', 'VSHR', 'VSHL', 'VSTR', 'VLDR',
'VLDM', 'VSTM', 'VPOP', 'VPUSH',
'VADD', 'VSUB',
'VMUL', 'VMLA', 'VMLS', 'VNMUL', 'VNMLA', 'VNMLS'
ARM {LDM,STM}
call
'REP', 'REPE', 'REPZ', 'REPNE', 'REPNZ' 表示重复字符串操作前缀x86 / AMD64命令
Ist_Intrinsic 不能在llvm中建模指令
对amd64的call指令特殊处理create_call_inst
获取函数调用类型,参数寄存器(个数传参类型等)offset,参数类型,返回值(rax寄存器)offset。
获取参数信息的方法是分析ida的注释部分(实际上作者还有其他获取参数信息的方法:用里面的一个json文件下文会提到)
如下代码为ida对参数的注释
text:000000000040138E mov edi, 0 ; timer
# .text:0000000000401393 call _time
elif num_insts >= 90 or num_bytes >= 350:块中指令数量不能超过90,指令字节数不能超过350
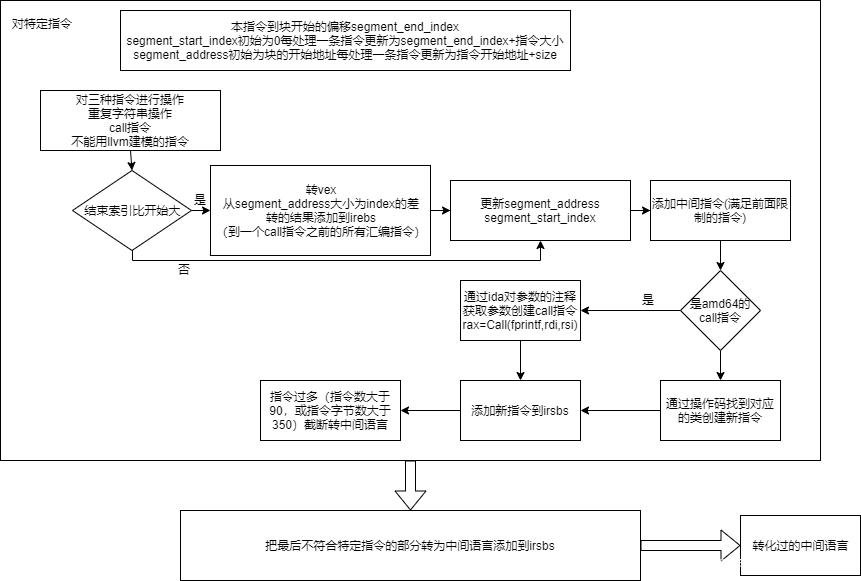
转化过的call指令跳转类型为Ijk_Boring意为跳转到一个地址,并且具有参数来源信息(但是ida的注释部分没有充分利用)
然后整合到一个块,整合方式为直接添加指令(call的跳转类型丢失了,跳转类型是一个块的属性)
生成llvm
初始化
translate_vex_whole_proc_to_llvm
proc_translator.py 文件的LLVMProcedure类的init函数
对从寄存器获取值赋值给临时变量的指令取出来寄存器名
创建函数对象。
# create the llvm function for the strand
self._function = ir.Function(self._llvm_module, ir.types.FunctionType(llvm_module._register_type, []),
vex_procedure[IndexedProcedure.name])#创建llvm函数类 模块,类型,名字 name为二进制文件函数名
创建参数对象。把上面寄存器名字变为arg.reg_name 作为函数的参数
转化
添加基本块“ob-1.initialize”作为第一个基本块
分配所有参数寄存器寄存器。(寄存器命名如”sr.rdi”)
添加所有基本块 命名为obi(i为块的索引)
倒着遍历每个块,把vex块转化为llvm块,翻译过程中去掉vex指令中的临时变量
对几条指令的翻译过程如下
汇编指令 (4204616, 'mov rax, [rbp+ho]', 4)
vex等号右边为源,左边为目的(都在等号右边第一个参数为源第二个为目的)
t21 = GET:I64(offset=56) -->获取offset寄存器名字,从寄存器56取数据赋值给t21(%"ob5.t21" = load i64, i64* %"sr.rbp") 保存到相应的临时变量(self._last_tmp字典)
t20 = Add64(t21,0xffffffffffffffe8) ---> 如果是寄存器获取最后一次为临时变量赋值的寄存器,如果是常数返回常数,之后进行加操作( "ob5.t20" = add i64 %"ob5.t21", 18446744073709551592)保存到相应的临时变量
t0 = t20 ---->直接取临时变量对应的值%"ob5.t20" = add i64 %"ob5.t21", 18446744073709551592 保存到相应的临时变量
t22 = LDle:I64(t0)---> 转化t0为对应的指针类型从指针load(%".74" = inttoptr i64 %"ob5.t20" to i64* %"ob5.t22" = load i64, i64* %".74")
PUT(offset=16) = t22(读取临时变量的值赋值给寄存器)--->t22保存到对应寄存器(rax)
每个块遇到退出指令(如if (t47) { PUT(offset=184) = 0x4028a7; Ijk_Boring })结束分析 对应汇编指令(4204651, 'jz short loc_4028A7', 2)
在vex中并不是最后一条指令

(4204614, 'jmp short loc_4028AC', 2)
对应vex为 t14 = GET:I64(offset=184)
块信息的is_terminated会被置为false。作者判断是否有后继进行操作,有后继无条件跳转到下一个块
llvm_proc的_init_bb_builder里面存放被翻译指令的信息以及块的连接信息_function保存原始的块以及参数信息_tmps保存临时变量的赋值链
优化
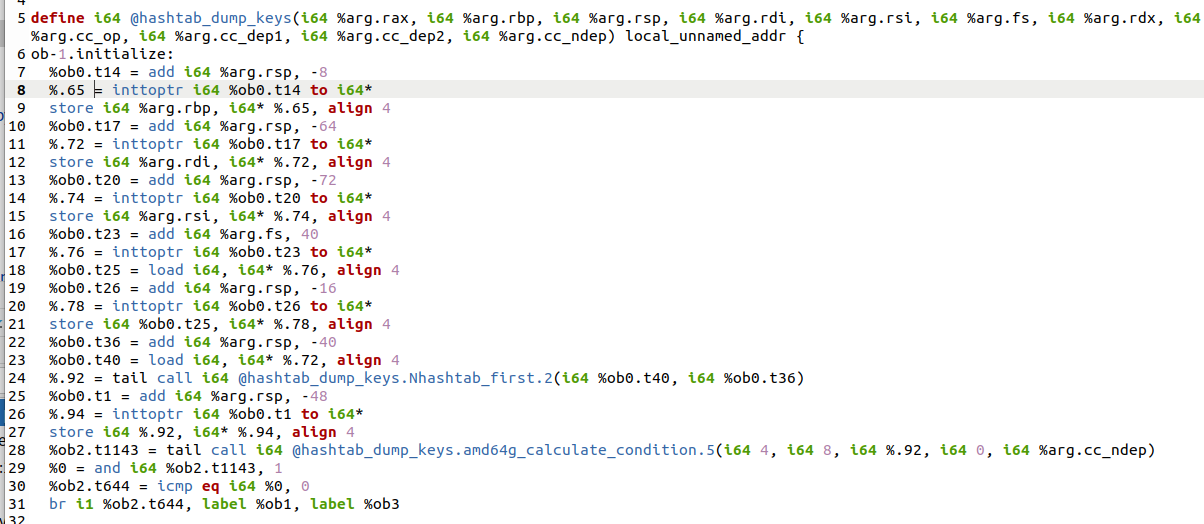
/home/tower/Desktop/work/tower/Nero/my_test/llvm__whole_hashtab_dump_keys/hashtab_dump_keys.ll为llvm保存的文件
opt -O2 /home/tower/Desktop/work/tower/Nero/my_test/llvm__whole_hashtab_dump_keys/hashtab_dump_keys.ll -S -o=/home/tower/Desktop/work/tower/Nero/my_test/llvm__whole_hashtab_dump_keys/hashtab_dump_keys.O2.ll
下面图展示了优化前后的对比,指令会简化很多
优化前

优化后
对llvm的处理
Kaleidoscope
生成一个文件内容如下
; ModuleID = '/home/tower/Desktop/work/tower/Nero/my_test/llvm__whole_hashtab_dump_keys/hashtab_dump_keys.ll'
source_filename = "/home/tower/Desktop/work/tower/Nero/my_test/llvm__whole_hashtab_dump_keys/hashtab_dump_keys.ll"
target triple = "unknown-unknown-unknown"
define i64 @hashtab_dump_keys(i64 %arg.rax, i64 %arg.rbp, i64 %arg.rsp, i64 %arg.rdi, i64 %arg.rsi, i64 %arg.fs, i64 %arg.rdx, i64 %arg.rip, i64 %arg.cc_op, i64 %arg.cc_dep1, i64 %arg.cc_dep2, i64 %arg.cc_ndep) local_unnamed_addr {
ob-1.initialize:
%ob0.t14 = add i64 %arg.rsp, -8
%.65 = inttoptr i64 %ob0.t14 to i64*
store i64 %arg.rbp, i64* %.65, align 4
%ob0.t17 = add i64 %arg.rsp, -64
%.72 = inttoptr i64 %ob0.t17 to i64*
store i64 %arg.rdi, i64* %.72, align 4
%ob0.t20 = add i64 %arg.rsp, -72
%.74 = inttoptr i64 %ob0.t20 to i64*
store i64 %arg.rsi, i64* %.74, align 4
%ob0.t23 = add i64 %arg.fs, 40
%.76 = inttoptr i64 %ob0.t23 to i64*
%ob0.t25 = load i64, i64* %.76, align 4
%ob0.t26 = add i64 %arg.rsp, -16
%.78 = inttoptr i64 %ob0.t26 to i64*
store i64 %ob0.t25, i64* %.78, align 4
%ob0.t36 = add i64 %arg.rsp, -40
%ob0.t40 = load i64, i64* %.72, align 4
%.92 = tail call i64 @hashtab_dump_keys.Nhashtab_first.2(i64 %ob0.t40, i64 %ob0.t36)首先从本函数开始
%ob0.t1 = add i64 %arg.rsp, -48
%.94 = inttoptr i64 %ob0.t1 to i64*
store i64 %.92, i64* %.94, align 4
%ob2.t1143 = tail call i64 @hashtab_dump_keys.amd64g_calculate_condition.5(i64 4, i64 8, i64 %.92, i64 0, i64 %arg.cc_ndep)
%0 = and i64 %ob2.t1143, 1
%ob2.t644 = icmp eq i64 %0, 0
br i1 %ob2.t644, label %ob1, label %ob3
ob1: ; preds = %ob-1.initialize, %ob1
%ob1.t16 = load i64, i64* inttoptr (i64 6312992 to i64*), align 32
%.54 = tail call i64 @hashtab_dump_keys.Efprintf.2(i64 %ob1.t16, i64 4210379)
%.59 = tail call i64 @hashtab_dump_keys.Nhashtab_next.1(i64 %ob0.t36)
store i64 %.59, i64* %.94, align 4
%ob2.t11 = tail call i64 @hashtab_dump_keys.amd64g_calculate_condition.5(i64 4, i64 8, i64 %.59, i64 0, i64 %arg.cc_ndep)
%1 = and i64 %ob2.t11, 1
%ob2.t6 = icmp eq i64 %1, 0
br i1 %ob2.t6, label %ob1, label %ob3
ob3: ; preds = %ob1, %ob-1.initialize
%ob3.t7 = load i64, i64* %.78, align 4
%ob3.t2 = load i64, i64* %.76, align 4
%ob3.t1 = xor i64 %ob3.t2, %ob3.t7
%ob3.t15 = tail call i64 @hashtab_dump_keys.amd64g_calculate_condition.5(i64 4, i64 20, i64 %ob3.t1, i64 0, i64 %arg.cc_ndep)
%2 = and i64 %ob3.t15, 1
%ob3.t10 = icmp eq i64 %2, 0
br i1 %ob3.t10, label %ob4, label %ob5
ob4: ; preds = %ob3
%.22 = tail call i64 @hashtab_dump_keys.Estack_chk_fail.0()
ret i64 %.22
ob5: ; preds = %ob3
ret i64 %ob3.t1
}
declare i64 @hashtab_dump_keys.Estack_chk_fail.0() local_unnamed_addr
declare i64 @hashtab_dump_keys.amd64g_calculate_condition.5(i64, i64, i64, i64, i64) local_unnamed_addr
declare i64 @hashtab_dump_keys.Efprintf.2(i64, i64) local_unnamed_addr
declare i64 @hashtab_dump_keys.Nhashtab_next.1(i64) local_unnamed_addr
declare i64 @hashtab_dump_keys.Nhashtab_first.2(i64, i64) local_unnamed_addr
对控制流的处理
添加FakeRoot和FakeSink作为图的开始和结束顶点
添加每个顶点,对函数调用进行统计(这里的统计包含知道名字的内部调用,外部调用。不包含编译器生产函数这里只有stack_chk_fail)
添加图的边,为顶点添加元素pred_names表示该顶点的前继节点添加的两个伪造块链入图。
遍历从开始到结束的所有简单路径(简单路径是没有重复节点的路径)。对子路径节点序列进行操作。(子路径取节点的方式为['ob-1.initialize', 'ob1', 'ob3', 'ob4']中的[‘ob-1.initialize’],['ob-1.initialize', 'ob1'],['ob-1.initialize', 'ob1', 'ob3'],['ob-1.initialize', 'ob1', 'ob3', 'ob4'])
进行数据流操作,获取数据标签和值(如[('Nhashtab_first', ('ARG', 'arg.rdi'), ('CONST', -40))]),然后为定点添加特征标签集合callers_graph.nodes[bb_in_question]['kind_data'].add((key, tuple(val)))(bb_in_question为定点名)
数据流操作
对一个块,得到这个块调用的函数对该函数的参数来源进行追踪
遍历参数对参数处理(追踪参数来源)
%.92 = tail call i64 @hashtab_dump_keys.Nhashtab_first.2(i64 %ob0.t40, i64 %ob0.t36)
获取( %ob0.t40 = load %.72, 'value_strand')这是参数t40的来源(一层)
该指令不是函数调用(如果是结束该流的追踪)
对不同的指令进行不同操作,上面是load取出来每个操作数确定非常熟或整个函数的参数

最终得到[(-64, 'ptr_strand'), (%arg.rsp, 'ptr_strand'), ( %ob0.t17 = add %arg.rsp, -64, 'ptr_strand'), ( %.72 = inttoptr %ob0.t17, 'value_strand'), ( %ob0.t40 = load %.72, 'value_strand')]
(实际上这是一个错误的结果,对代码错误修改后纠正为[(%arg.rdi, 'value_strand'), ( store %arg.rdi, %.72, 'value_strand'), (-64, 'ptr_strand'), (%arg.rsp, 'ptr_strand'), ( %ob0.t17 = add %arg.rsp, -64, 'ptr_strand'), ( %.72 = inttoptr %ob0.t17, 'value_strand'), ( %ob0.t40 = load %.72, 'value_strand')])
通过指令获取指令里面读操作数
extract_reads(cur, True)
获取指令操作码名字,对不同指令进行处理
data_only默认开启
- store:store i64 %arg.rdi, i64* %.72, align 4 把rdi存储到%.72,这里的读寄存器为rdi
- br : br i1 %ob2.t644, label %ob1, label %ob3 i1表示条件分支无条件分支没有i1,i1为true跳转label1否则跳label2 定义了data_only选项为True只分析数据流(返回空)否则返回i1的来源。
- ret: ret i64 %ob3.t1 返回 返回有值,返回对应值
- switch: 开启data_only返回空获取每个操作数
- select:指令根据条件选择一个值。有点像br指令,只不过这个是选择一个值。如%X = select i1 true, i8 17, i8 42 这里data_only返回两个值,也就是遇到分支就取两个分支不开启data_only返回三个值
- phi: %indvar = phi i32 [ 0, %LoopHeader ], [ %nextindvar, %Loop ] 如果当前block之前执行的是LoopHeader,则该 phi 指令的值是 0,而如果是从Loop label 过来的,则该 phi 指令的值是 %nextindvar 返回对应block对应的值
- load以及算数操作等:直接返回所有操作数
该指令写的参数
extract_writes(non_const_read) 参数为指令
-
inttoptr指令
![]()
%.74 = inttoptr i64 %ob0.t20 to i64*
获取该指针参数变成指针的所有指令,对每个变成的指针取出对其的store操作获取最近的store操作。
返回值为对该指令参数作为值得指令和上面得到的指令[ (%ob0.t17 = add i64 %arg.rsp, -64 ) , (store i64 %arg.rdi, i64* %.72, align 4)]指针的双重身份(指针从哪来,指针指向的内容从哪来) -
load指令
如%ob0.t40 = load i64, i64* %.72, align 4
本子路径中所有使用load指令参数的store指令,load指令前面最接近load指令的store。(store i64 %arg.rdi, i64 %.72, align 4)
返回值为两个元素的列表:用本指令参数作为值的指令,上面得到的指令
`[(%.72 = inttoptr i64 %ob0.t17 to i64),(store i64 %arg.rdi, i64* %.72, align 4)]`

- **store 指令** 直接获取store指令(指令的第二个参数非函数调用或常量)
- **算术指令**直接返回该指令
标签追踪
初始call指令传输为value_strand标签(这个值可能不够准确,很多函数的参数是作为指针的)
在extract_writes如果指令操作数是inttoptr或load会返回指针来源和指针的值来源。
如果本指令的标签为ptr_strand那么它的值(双层指针)和它的来源都是ptr_strand
如果本指令标签为value_strand那么它的第一个标签为ptr_strand(指针来源)第二个为value_strand(指针内容来源)
获取和传递标签
数据流操作结束后需要对标签进行传播,
对一个序列(如[(%arg.rsi, 'value_strand'), ( store %arg.rsi, %.19, 'value_strand'), (-24, 'ptr_strand'), (%arg.rsp, 'ptr_strand'), ( %ob0.t21 = add %arg.rsp, -24, 'ptr_strand'), ( %.19 = inttoptr %ob0.t21, 'value_strand'), ( %ob0.t43 = load %.19, 'value_strand')])
首先收集深度优先树的叶子节点的类型然后按照上面序列匹配下面的标签,匹配到任意一个就返回VAL_CAT, ARG_CAT, GLOBAL_CAT, CONST_CAT(先匹配的是指针指向内容的信息)。
对于外部调用使用一个内存dump文件获取函数信息,参数信息等。
对一个read函数的识别结果如下
CRITICAL:root:Repo has 91732 records
{'unspecified_params': False, 'source_file': 'gcc-5__Ou__pcp-4.0.0__pmda_linux.json',
'params': [{'type_name': 'int', 'name': '__fd', 'type_type': 'base'},
{'type_name': 'no_type', 'name': '__buf', 'type_type': 'pointer'},
{'type_name': 'size_t', 'name': '__nbytes', 'type_type': 'typedef'}]}
这里只是用了参数类型。
问题
- 得到的变量追踪序列的源头为
(%arg.rsp, 'ptr_strand')是临时变量操作,对是否能追踪到准确的临时变量有怀疑
测试文件gcc-5Ouacct__dump-acct,测试函数hashtab_dump_keys
实际的序列[(-64, 'ptr_strand'), (%arg.rsp, 'ptr_strand'), ( %ob0.t17 = add %arg.rsp, -64, 'ptr_strand'), ( %.72 = inttoptr %ob0.t17, 'value_strand'), ( %ob0.t40 = load %.72, 'value_strand')]
在ida里面看到区别还是很大的

对应llvm中看到的

可以看出实际上是没有分析store指令得到了错误的结论
在inttoptr指令的处理中load指令应该在inttoptr指令后面,解决方案:添加一个处理inttoptr指令的get_closest_write_inttoptr把小于改为大于
另一方面ida中ht为-0x38在llvm中ht为-64(即-0x40)两个偏移量是不一样的






发表评论
您还未登录,请先登录。
登录