


<?php
var_dump($_GET);
var_dump($_POST);
var_dump($_COOKIE);
var_dump($_REQUEST);
?>
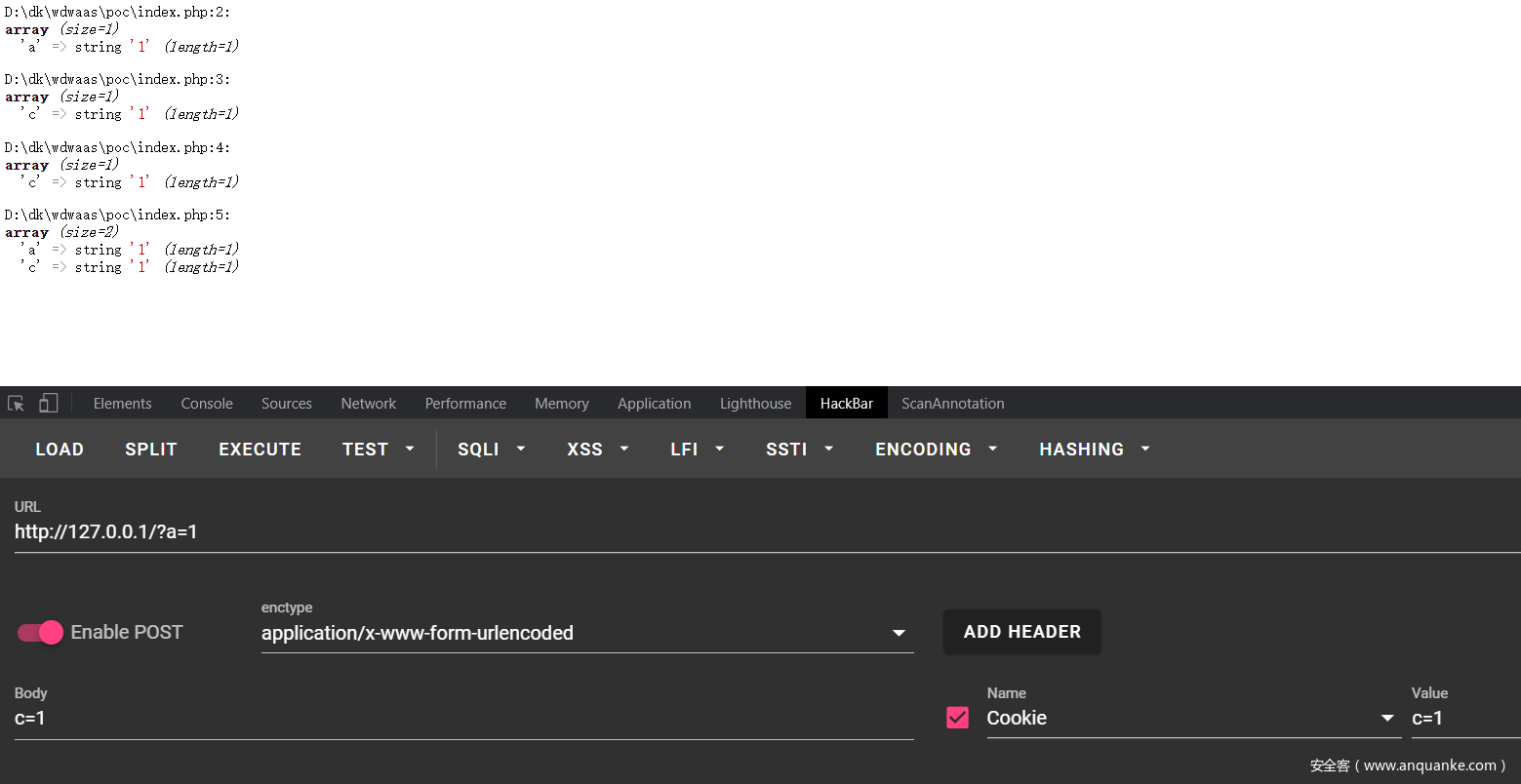

<a name=”然后看看php.ini里面的默认值是多少,由于首先会选择赋值为request_order的值,所以就只有GP了” class=”reference-link”>然后看看php.ini里面的默认值是多少,由于首先会选择赋值为request_order的值,所以就只有GP了

<a name=”好了,现在就明白了$_REQUEST的值是根据request_order的值来先后合并的,所以这里就会出现$_REQUEST里面的key先被$_GET赋值,再被$_POST赋值,这样就post的值就覆盖了get在request里面注册的值了,这个点印象中已经考过几次了” class=”reference-link”>好了,现在就明白了$_REQUEST的值是根据request_order的值来先后合并的,所以这里就会出现$_REQUEST里面的key先被$_GET赋值,再被$_POST赋值,这样就post的值就覆盖了get在request里面注册的值了,这个点印象中已经考过几次了
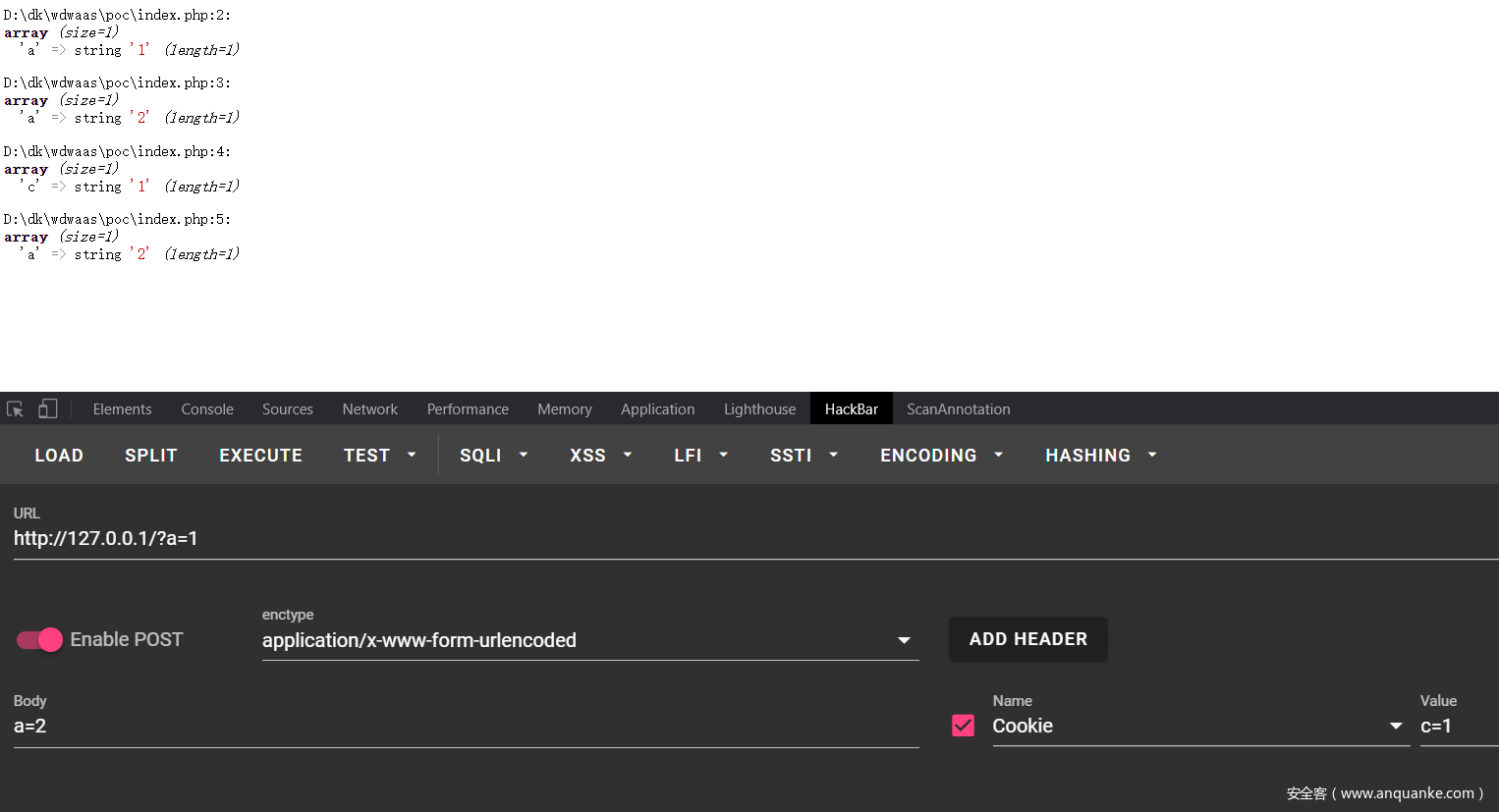
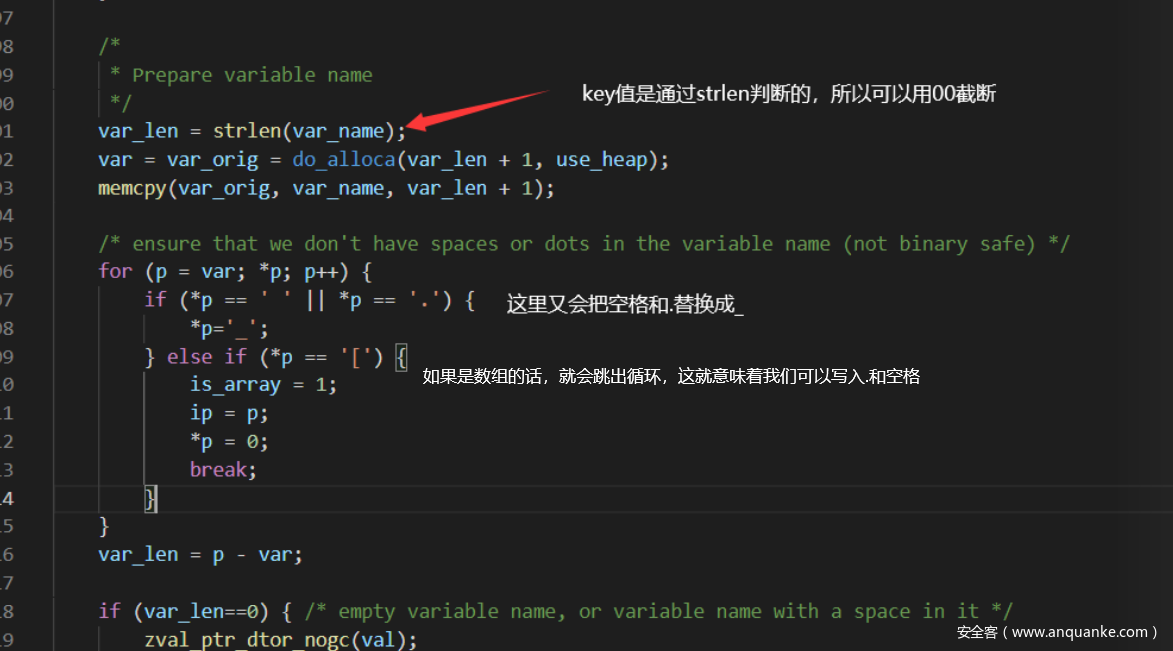

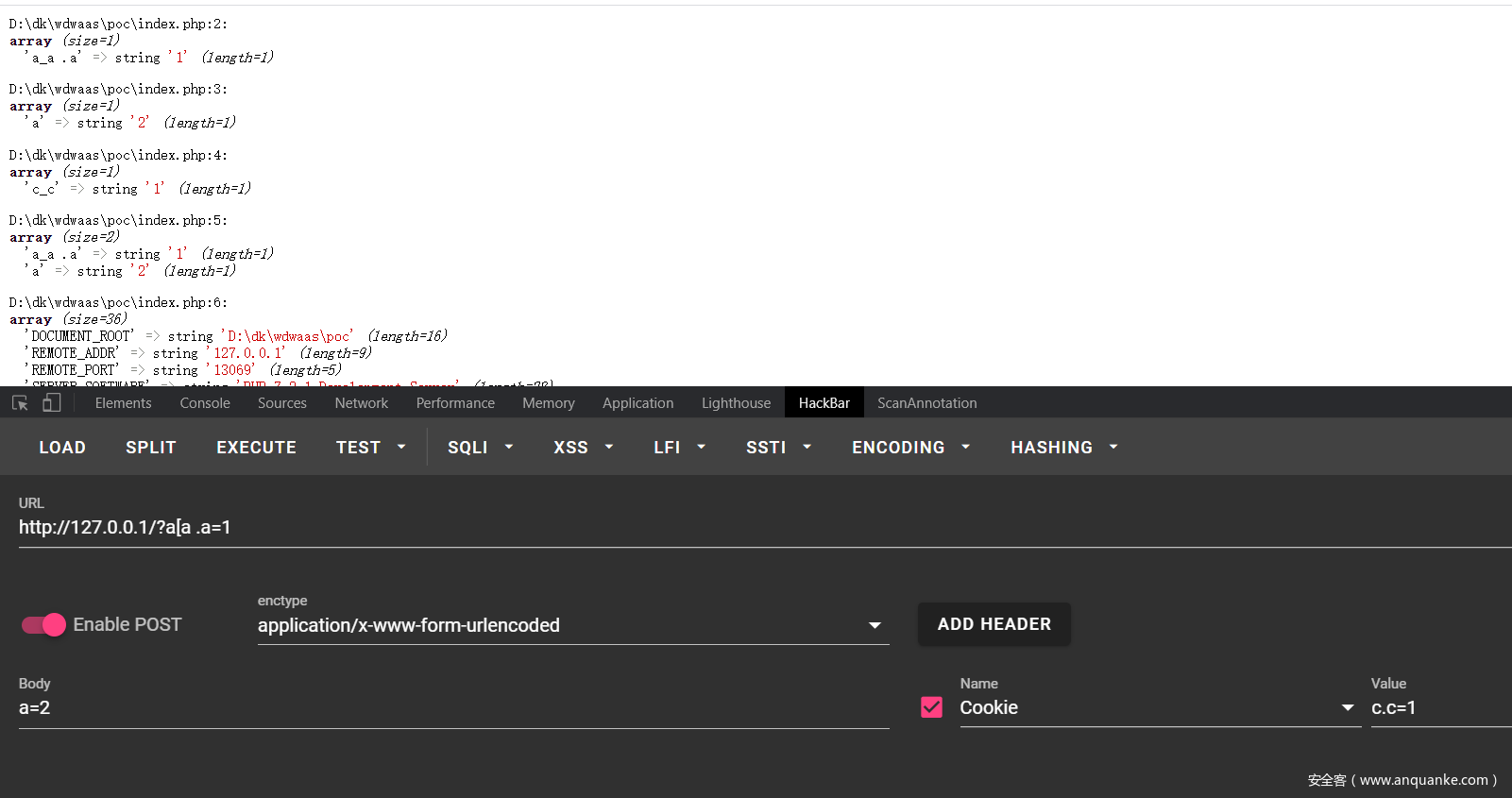
那么怎么才能获取到$_GET真正的变量名呢?那就是通过$_SERVER来获取
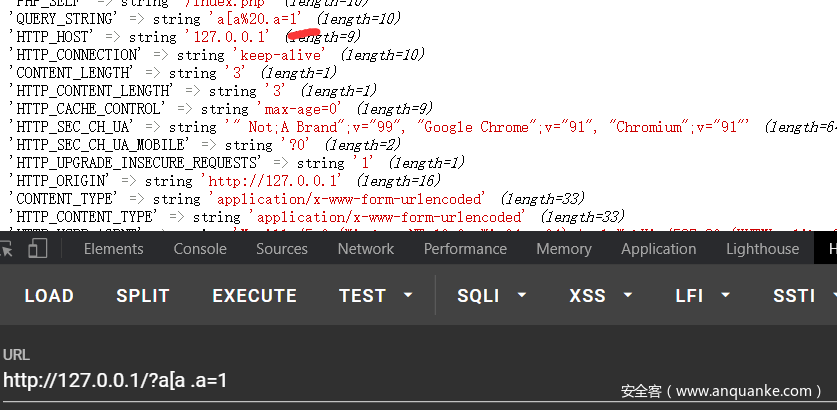
post的可以通过伪协议来得到真正的变量名,php://input
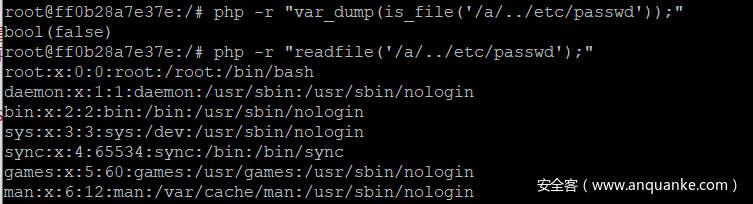
<a name=”先说一下php底层对于处理获取文件数据流是用的2个不同的方法,所以导致了readfile("/e/../../etc/passwd")可以成功,而is_file("/e/../../etc/passwd")为false” class=”reference-link”>先说一下php底层对于处理获取文件数据流是用的2个不同的方法,所以导致了readfile("/e/../../etc/passwd")可以成功,而is_file("/e/../../etc/passwd")为false
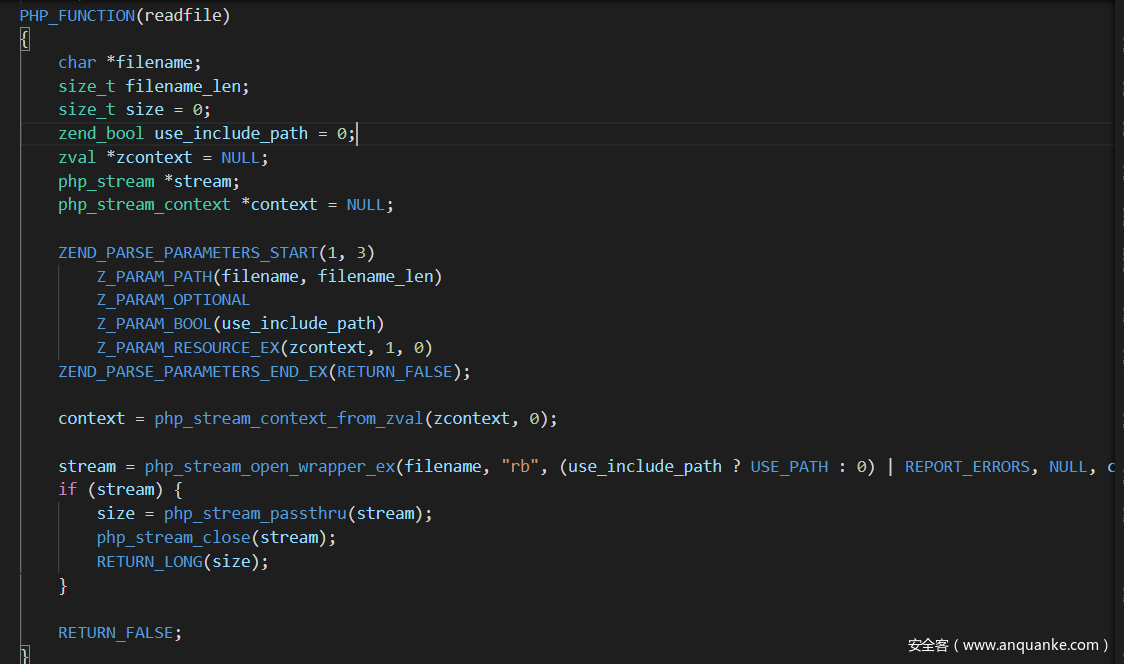
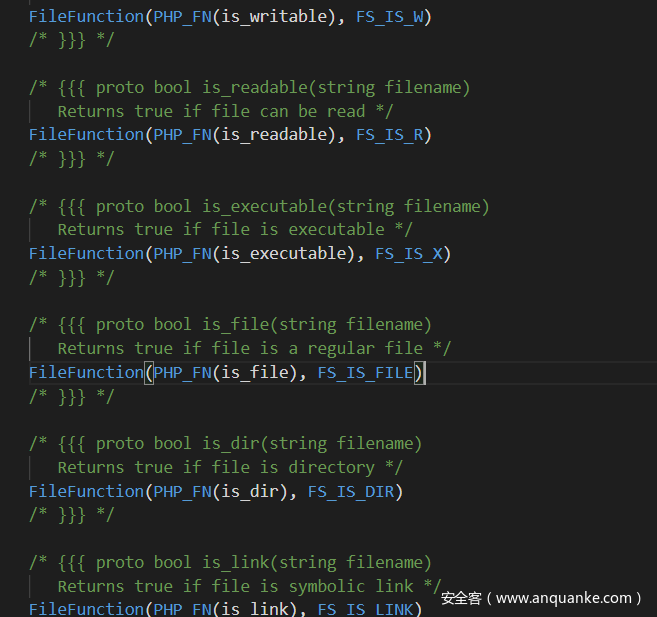
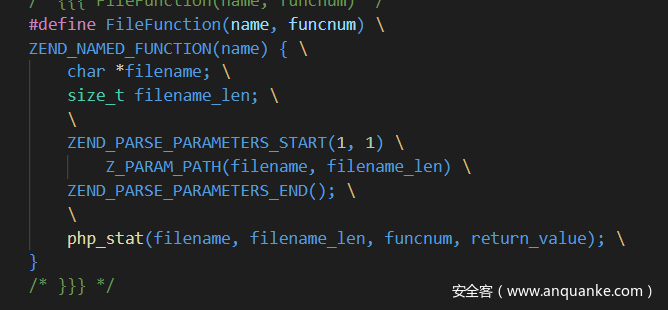
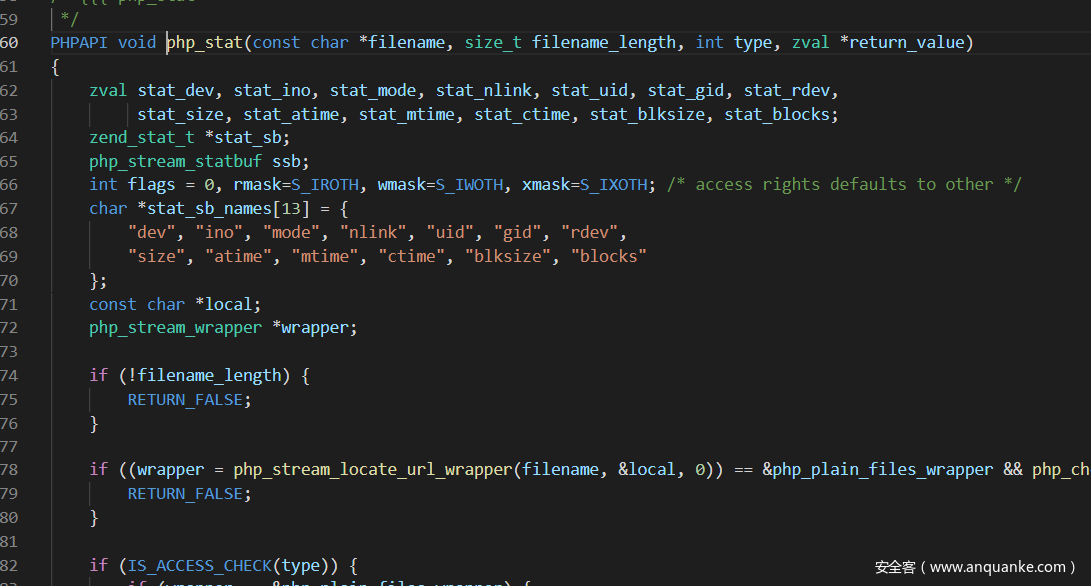
然后就是php的伪协议了:php://stdin,php://stdout,php://stderr,php://input,php://output,php://fd,php://memory,php://temp,php://filter,这些里面最常用到的就是php://filter了,关于这个的一系列trick网上一大把,这里主要讲一下include,require,include_once,require_once,这4个语法关键词实际上都是调用的同一个函数,只是选择的模式不同

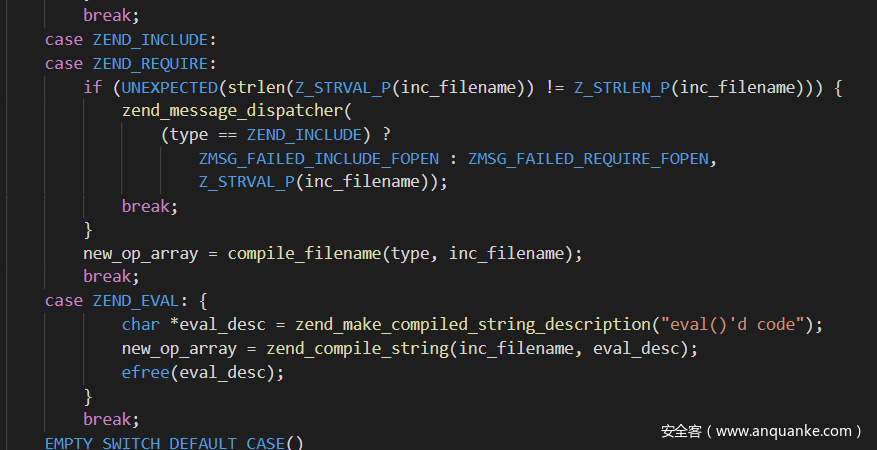
可以发现include和readfile这些文件读取的函数又是走的不同路线,那这样会不会出现什么差异呢?跟着源码看了一下发现,是否解析data://和http://实现的文件包含关键代码如下:
if (wrapper && wrapper->is_url &&
(options & STREAM_DISABLE_URL_PROTECTION) == 0 &&
(!PG(allow_url_fopen) ||
(((options & STREAM_OPEN_FOR_INCLUDE) ||
PG(in_user_include)) && !PG(allow_url_include)))) {
if (options & REPORT_ERRORS) {
/* protocol[n] probably isn't '\0' */
if (!PG(allow_url_fopen)) {
php_error_docref(NULL, E_WARNING, "%.*s:// wrapper is disabled in the server configuration by allow_url_fopen=0", (int)n, protocol);
} else {
php_error_docref(NULL, E_WARNING, "%.*s:// wrapper is disabled in the server configuration by allow_url_include=0", (int)n, protocol);
}
}
return NULL;
}
拆开来理解一下,第一层是wrapper && wrapper->is_url就是判断这个数据流是否有url模式,第二层(options & STREAM_DISABLE_URL_PROTECTION) == 0通过运算判断数据流是否是url,第三层!PG(allow_url_fopen)判断php的配置里面是否启用了allow_url_fopen,((options & STREAM_OPEN_FOR_INCLUDE) ||PG(in_user_include))大概是判断数据流是不是用于include,!PG(allow_url_include)判断php是否配置了allow_url_include,所以可以发现这里对include和readfile这些文件操作函数处理流程是不一样的,写个测试代码:
<?php
readfile($_GET[‘file’]);
include $_GET[‘file’];
?>
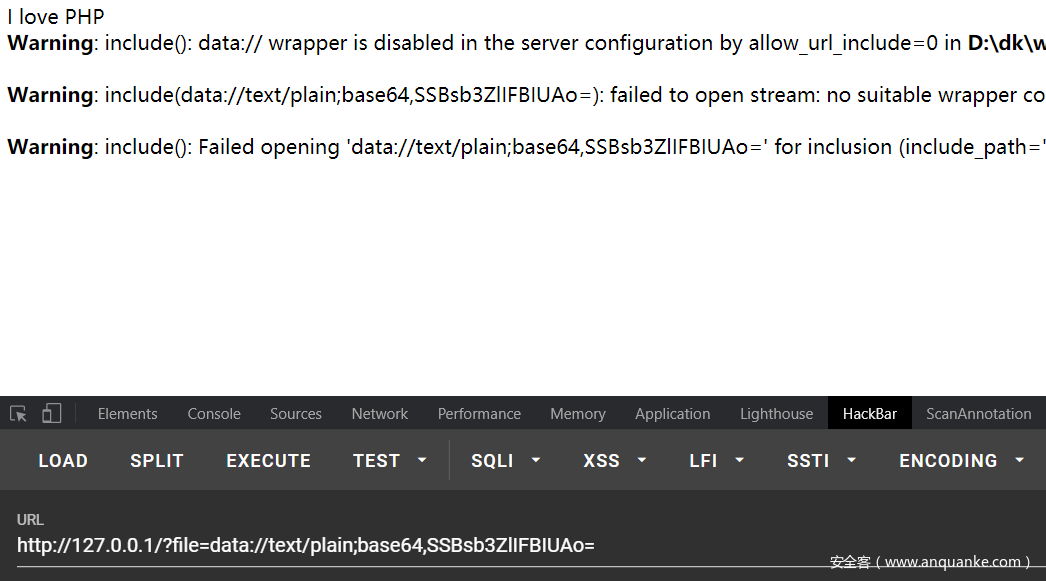
可以发现爆了3个错误,第一个是说配置文件里面禁用了data的数据流,第二是不能打开data的数据流,第三个是显示的不能打开文件,在include_path下面没有发现文件,所以就很明显在linux下面可以利用readfile不能读取文件,而include可以包含文件的特性了
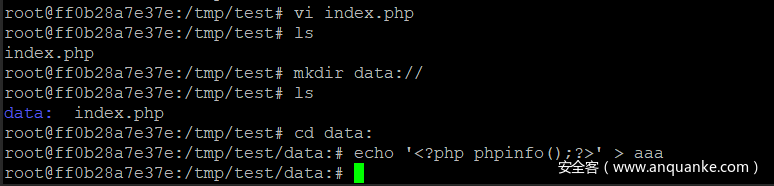
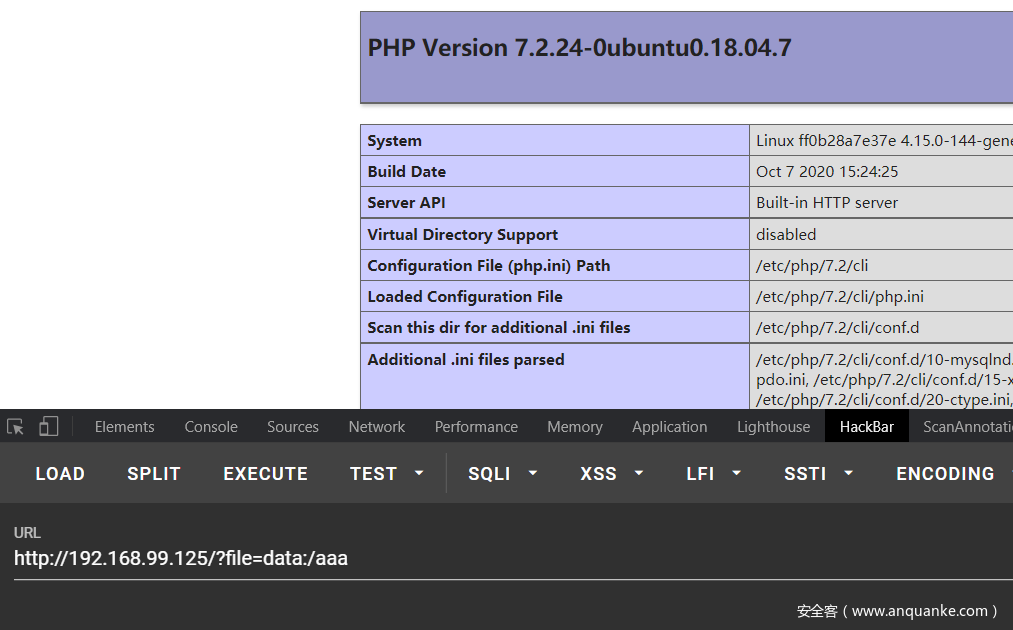

phar的一些特性和底层处理可以参考(因为之前和师傅套路过,所以就不在写了):
https://guokeya.github.io/post/uxwHLckwx/
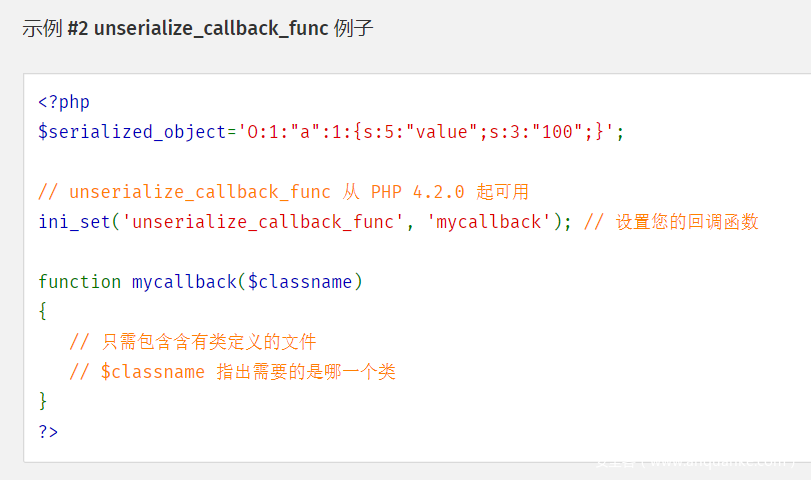
先看看文档,这里写了就接受一个字符串的参数,但是实际上是2个参数,还有一个callback的例子也不错

<?php
class A{
function __destruct(){
echo "ok\n";
}
}
var_dump(unserialize('O:1:"A":0:{}',["allowed_classes"=>true]));
var_dump(unserialize('O:1:"A":0:{}',["allowed_classes"=>false]));
var_dump(unserialize('O:1:"A":0:{}',["allowed_classes"=>["A"]]));
var_dump(unserialize('O:1:"A":0:{}',["allowed_classes"=>["B"]]));
?>
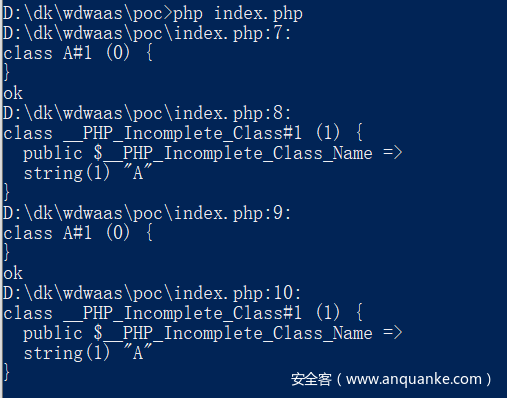
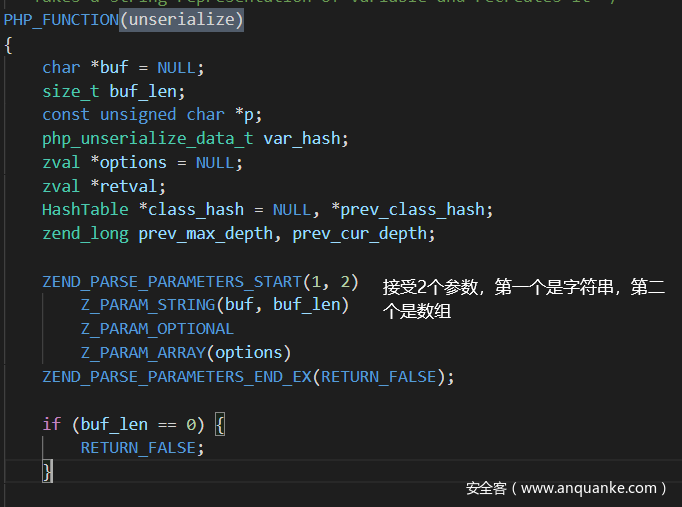
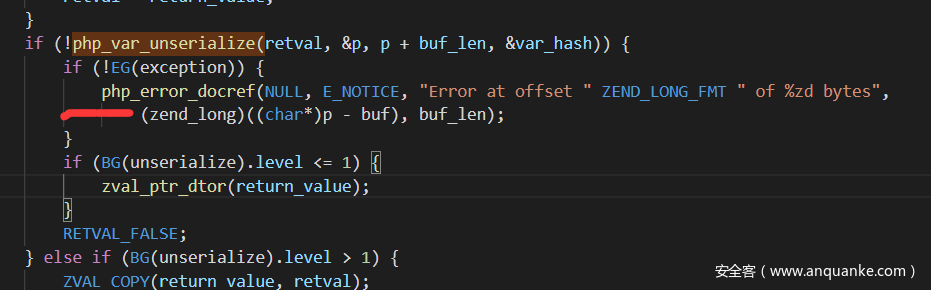
<a name=”然后看看php处理反序列化的细节吧,具体流程在php_var_unserialize里面,而且可以发现反序列化失败后直接抛的error,而不是异常,抛error就不会继续后面的代码了” class=”reference-link”>然后看看php处理反序列化的细节吧,具体流程在php_var_unserialize里面,而且可以发现反序列化失败后直接抛的error,而不是异常,抛error就不会继续后面的代码了
这个开启动态调试方便一点,首先配置vscode解析.re后缀的为c
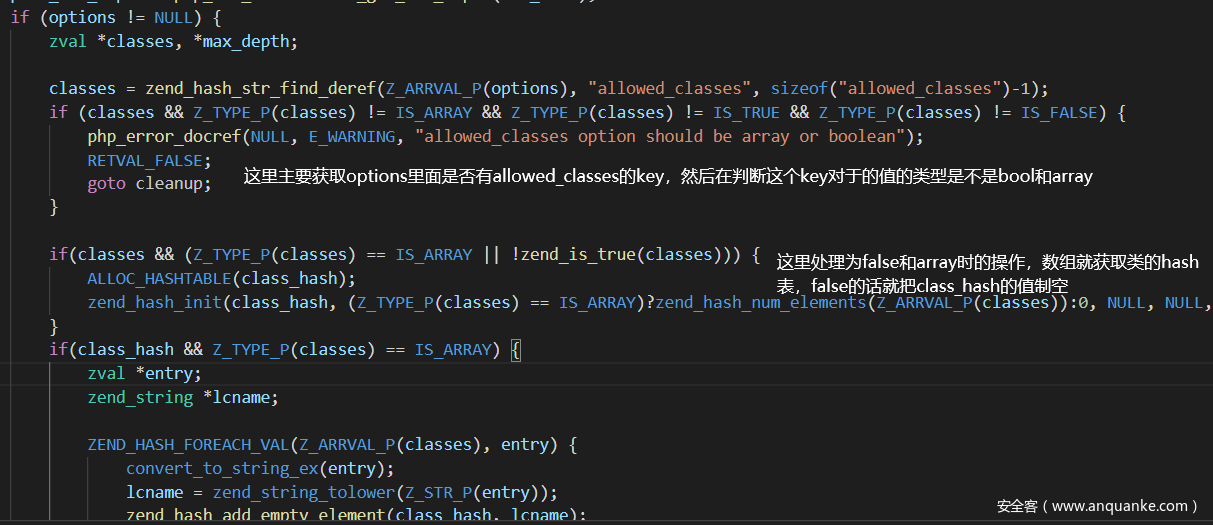
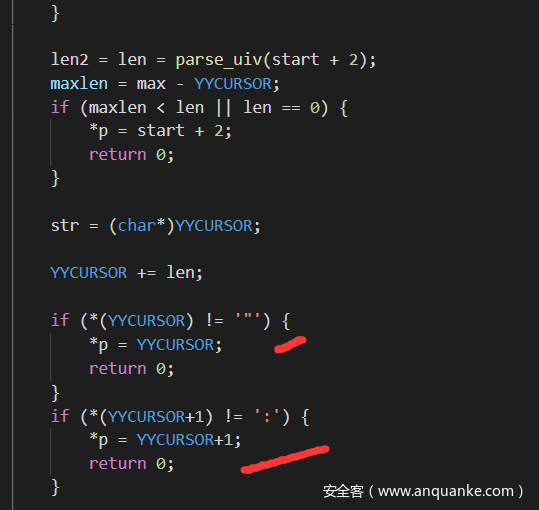
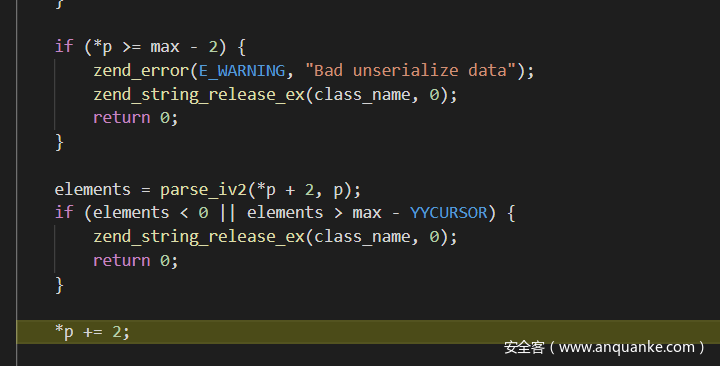
先看看解析的时候,可以发现开始对”和:作为结尾进行了验证,但是取出类名后对于:和{没有验证,所以可以直接不写,也可以成功反序列化
<?php
class A{
function __destruct(){
echo "ok";
}
}
unserialize('O:1:"A":0:{}');
unserialize('O:1:"A":0aa}');
?>

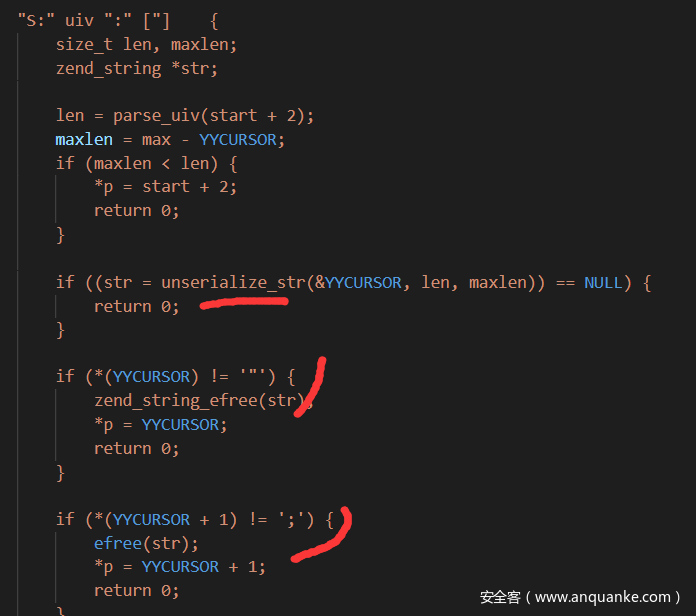
然后看看字符串的s判断吧,就验证了后面2个字符是不是”和;所以字符这里就没有什么问题了

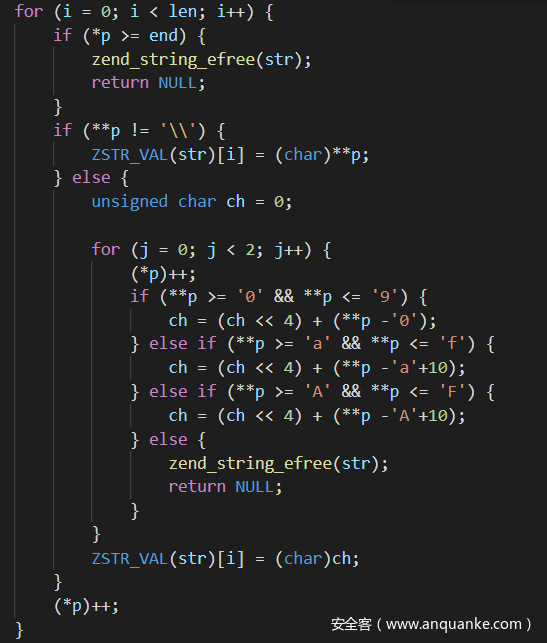
然后看看unserialize_str的主要处理逻辑,其实这里就是为了把\74变为t,其实大概的思想就是利用16进制和2进制的特性,因为16进制的第一个数字只影响对应二进制的前4位,第二个数字就只影响后4位
<a name=”其他几个类型的判断也没有什么特别的了,然后就是在类解析的最后还有一个解析类似魔术方法的东西__unserialize,而且当__unserialize存在时__wakeup是不会触发的” class=”reference-link”>其他几个类型的判断也没有什么特别的了,然后就是在类解析的最后还有一个解析类似魔术方法的东西__unserialize,而且当__unserialize存在时__wakeup是不会触发的
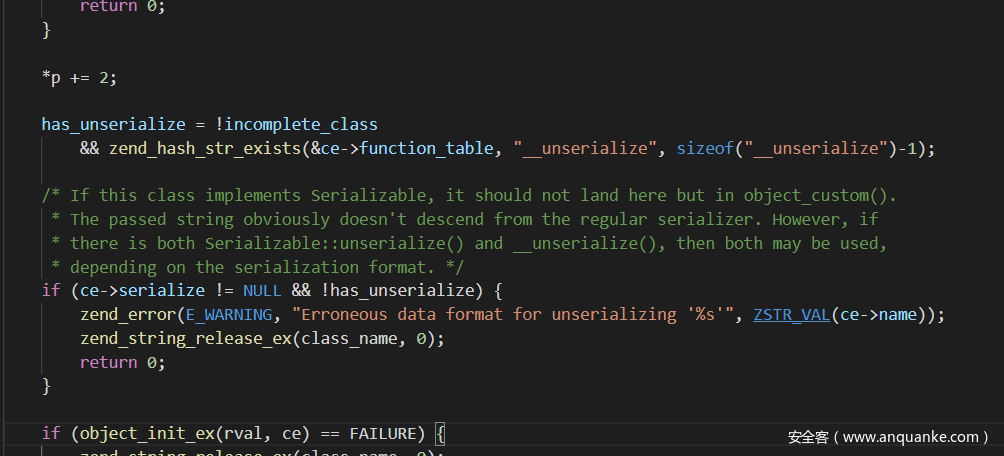
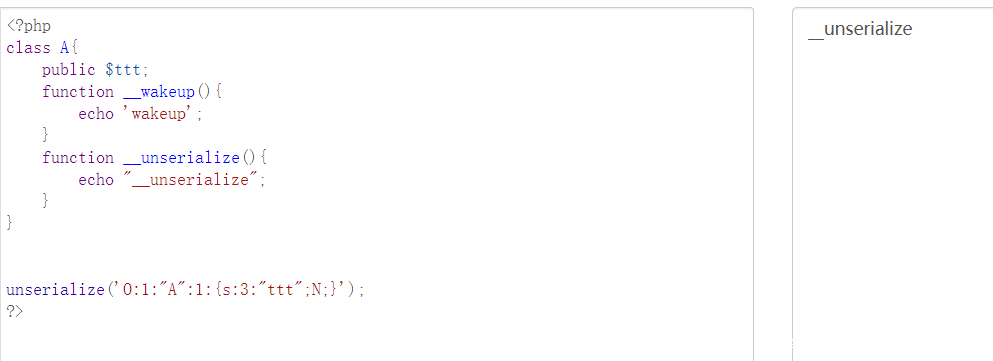
<a name=”然后就是__destruct的魔术方法调用了,即使反序列化失败,但是还是会触发cleanup,来进行清理,所以也就可以触发__destruct的魔术方法了” class=”reference-link”>然后就是__destruct的魔术方法调用了,即使反序列化失败,但是还是会触发cleanup,来进行清理,所以也就可以触发__destruct的魔术方法了
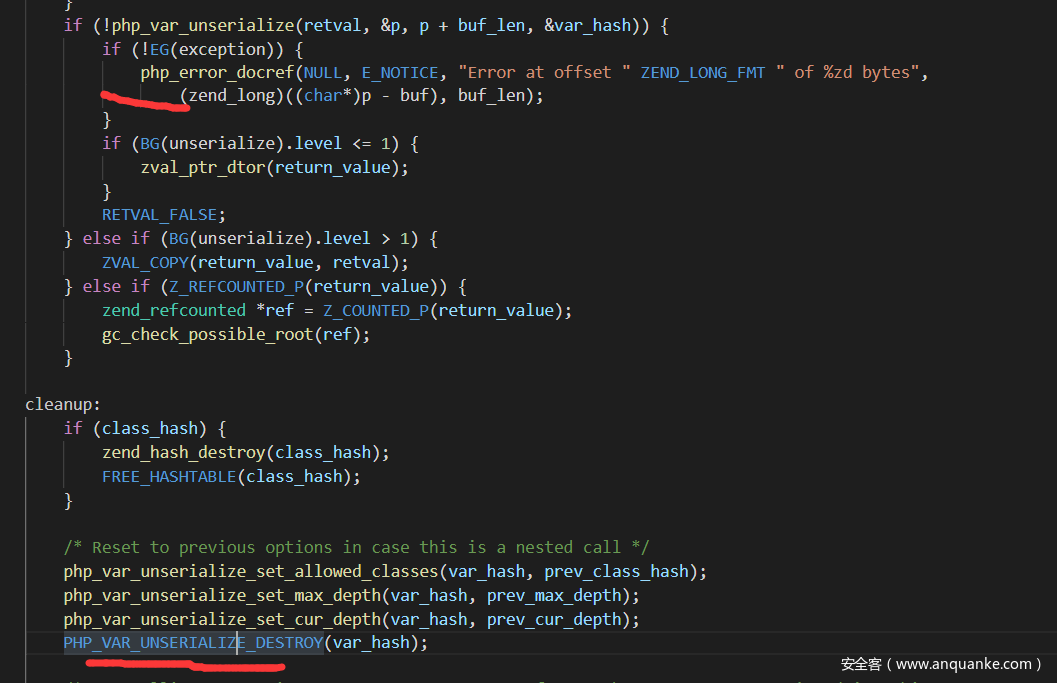
还有就是当__wakeup里面出现了zend级别的错误,__destruct也不会触发了
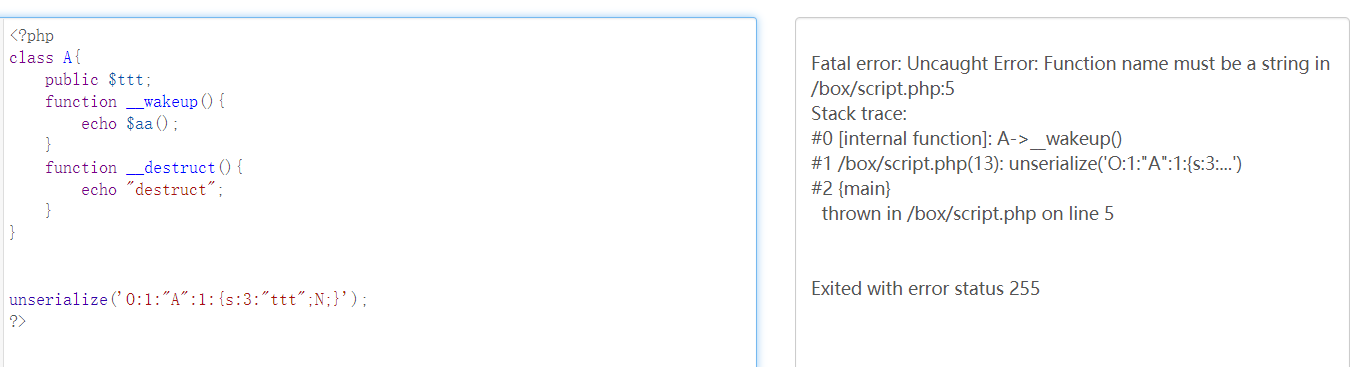
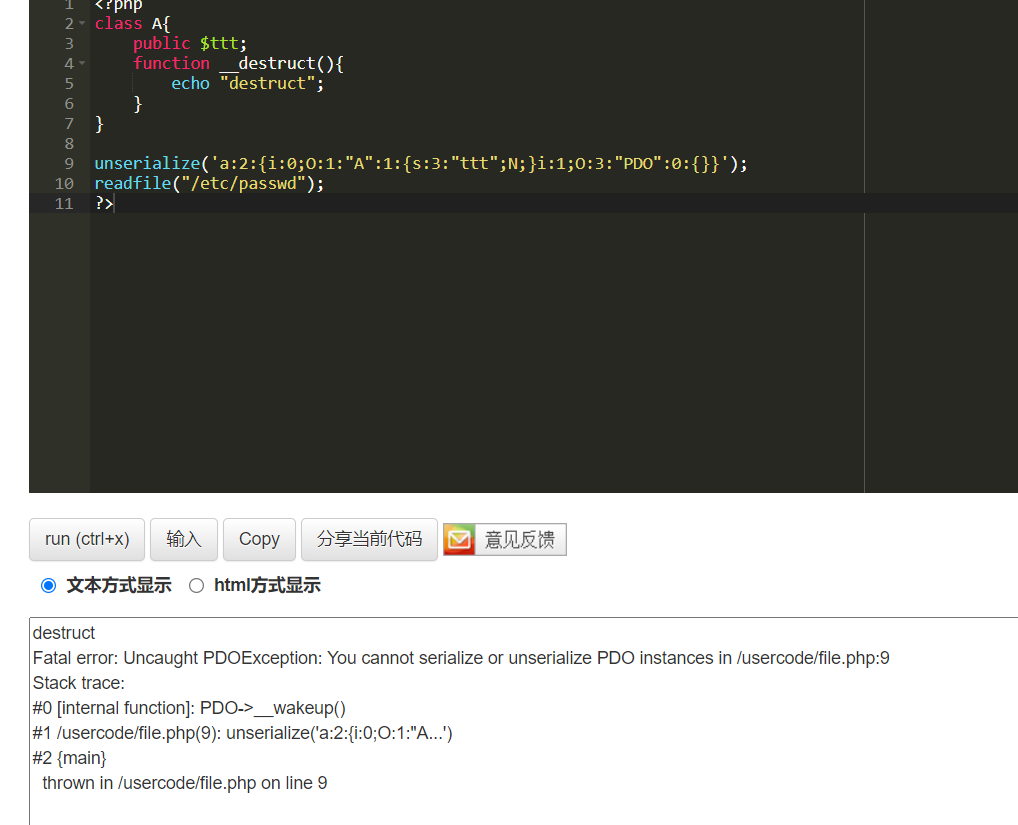
所以我们也就可以适当的利用unserialize的报错来即执行了__destruct,但是又不执行后面的代码
<?php
class A{
public $ttt;
function __destruct(){
echo "destruct";
}
}
unserialize(‘a:2:{i:0;O:1:”A”:1:{s:3:”ttt”;N;}i:1;O:3:”PDO”:0:{}}’);
readfile(“/etc/passwd”);
?>






发表评论
您还未登录,请先登录。
登录