

要写这篇文章的原因,主要是因为自己想在内核这块稍微多了解一点,再多了解一点,谈到内核提权漏洞,“dirty cow”是入门内核漏洞绕不开的一个点,这里我怀着敬畏的态度以一个新手的角度,来对脏牛进行简单的分析。
一、”dirty cow” 简介
脏牛漏洞之所以如此著名,主要在于其历史悠久且影响范围较广,根据 wiki 百科上的描述,脏牛漏洞自2007年9月 linux kernel 2.6.22 被引入,直到2018年linux kernel 4.8.3, 4.7.9, 4.4.26 之后才被彻底修复,影响在此之间的所有基于其中版本范围的Linux发行版。
二、相关概念
1. COW
COW 全名为 Copy-on-write,cow技术的应用范围很广泛,比较常见的是在 fork() 中的应用:
fork() creates a new process by duplicating the calling process.
The new process is referred to as the child process. The calling
process is referred to as the parent process.
The child process and the parent process run in separate memory
spaces. At the time of fork() both memory spaces have the same
content. Memory writes, file mappings (mmap(2)), and unmappings
(munmap(2)) performed by one of the processes do not affect the
other.
以上一段是从man手册中截取出来的对fork的描述,从该描述中可知 fork 在创建子进程时,会对自身进程空间进行复制, fork 完成时,父子进程具有完全相同的进程空间。
从编码的角度来看,一般情况下在 fork 之后会存在一个 execve 或其他 exec 系列的函数来执行一个新的程序,在调用 execve 的时候,内核会将新程序的代码段、数据段……映射到子进程的内存中。
上述创建子进程的过程,父进程将自身的内存空间完全拷贝给了子进程后,子进程很快就执行 execve 将新程序装载进入自己的内存中,覆盖了大部分父进程拷贝的内存,那么实际上大部分的父进程拷贝的数据是无用的。
因而内核引入了 Copy-on-write 技术,即当 fork 创建完子进程后,父子进程实际上共享物理内存,当父子进程中发生了对内存写入的操作时,内核再为子进程分配新的内存页并将改动写入新内存页中,也就是在 fork 之后,execve 之前的过程。
fork之后,内核将父进程中所有内存页的权限都设置为 read-only,之后子进程内存指向父进程,当父进程或子进程执行了写入操作时,因为内存页是 read-only 的,就会触发 page-fault,进而进入内核中断例程中,在中断例程中内核将触发异常的页复制一份,至此,父子进程就拥有了各自的内存。2. linux 虚拟内存
这一步我最开始的思路是想要在 qemu 里通过手动完成 PTE 寻址后置零 PTE 页面属性来代替 madvise 函数的功能,但是在最后一步置零的操作上因为 qemu monitor 无法对内存进行写入而放弃。
(1). VMA简介(Virtual Memory Area)
虚拟内存概念的引入,以32位系统为例,进程可以“独享”3G大小的用户空间,且进程之间的操作是互相隔离的,对相同虚拟地址的操作并不会产生冲突。只有当进程开始操作申请到的内存时,内核才会触发缺页异常将指定的物理页面换入内存中。
进程的虚拟内存会被分成若干区域,这些区域就是 VMA,VMA的各种属性由 vm_area_struct 结构来描述:
struct vm_area_struct {
struct mm_struct * vm_mm; /* 所属的内存描述符 */
unsigned long vm_start; /* vma的起始地址 */
unsigned long vm_end; /* vma的结束地址 */
/* 该vma的在一个进程的vma链表中的前驱vma和后驱vma指针,链表中的vma都是按地址来排序的*/
struct vm_area_struct *vm_next, *vm_prev;
pgprot_t vm_page_prot; /* vma的访问权限 */
unsigned long vm_flags; /* 标识集 */
struct rb_node vm_rb; /* 红黑树中对应的节点 */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
/* shared联合体用于和address space关联 */
union {
struct {
struct list_head list;/* 用于链入非线性映射的链表 */
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;/*线性映射则链入i_mmap优先树*/
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
/*anno_vma_node和annon_vma用于管理源自匿名映射的共享页*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
/*该vma上的各种标准操作函数指针集*/
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* 映射文件的偏移量,以PAGE_SIZE为单位 */
struct file * vm_file; /* 映射的文件,没有则为NULL */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
这里首先介绍一下 Linux 四级页表的基本知识点,当我们需要实际操作一个页面的时候,ring3 程序使用的是虚拟地址,ring0 需要对虚拟地址进行转换,对应到物理地址后才能对内存进行操作。
为什么要存在页表呢?
真实的物理内存只有固定的大小,但是操作系统给每个进程都会提供同样大小的虚拟内存,那么问题来了,物理内存只有固定的大小,想要让所有的进程都感觉自己使用了所有的物理内存应该怎么做呢?—> 将每个进程活跃的页面放到物理内存中,不活跃的就从物理内存中换出,等到需要的时候再从外存中调入,同一时刻进程真正活跃的页面相对于其整个占用的内存空间来说是比较小的。此时,就引出了另外一个问题,我怎么知道我要访问的虚拟内存页面是哪个物理内存页面?—> 此时页表(分页机制)就闪亮登场了,通过虚拟地址以及 cr3 提供的信息进行转换后,就可以找到虚拟地址对应的物理地址。
通常来说,需要多级页表来完成映射关系,级数越高,页表所占的内存就越小,效率就越低。
以 32位 系统为例,ring3 可用的虚拟内存大小为 3G,一页内存大小为 4k,即 32^30 / 42^10 = 786432 个页面,一个页面需要 4 byte 的页表,也就是一个进程就需要 768 个物理页来存储页表,对于动辄几十上百个进程的操作系统来说这样的开销是不可容忍的。
Linux 中采用的是四级页表的存储方式

因此需要根据虚拟地址和 cr3 的信息进行四次寻址才能拿到 pte 的地址。
在 __get_user_pages 函数处断下来
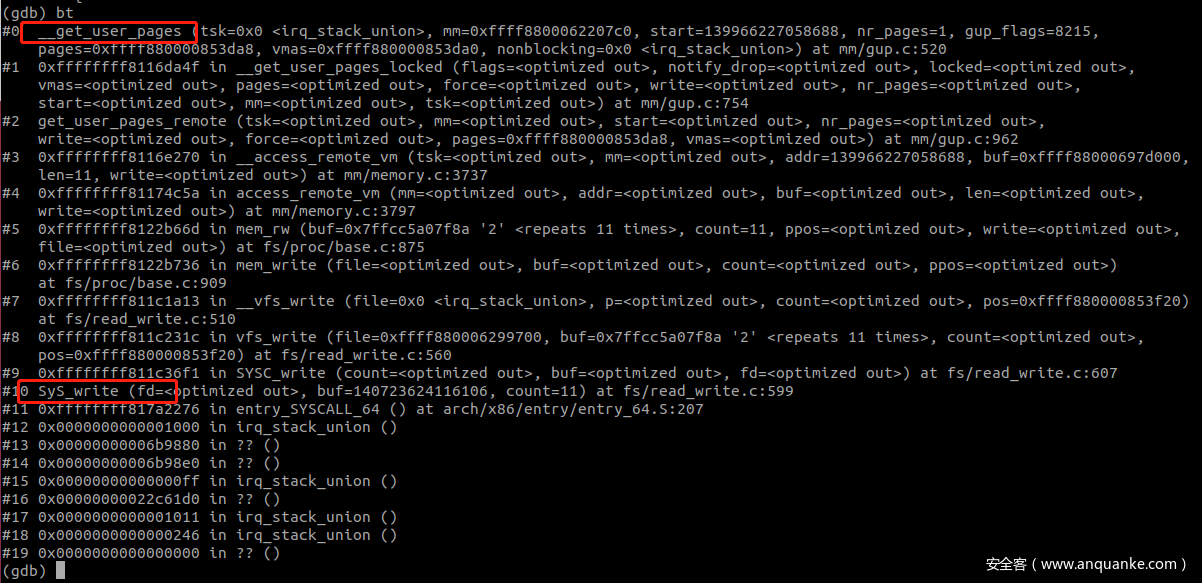
根据打印出的虚拟地址进行换算

偏移如下:
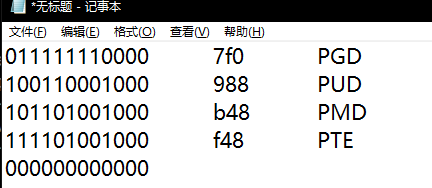
得到换算结果后,qemu Ctrl+A - C 进入 qemu command interface 调用 info registers 获取 cr3 寄存器,根据 cr3 寄存器的数值进行寻址,此处需要注意获取的地址的低 12bit 为页面属性。

(qemu) xp 0x00000000062e8000+0x7f0 PGD
00000000062e87f0: 0x00000000062dc067
(qemu) xp 0x00000000062dc000+0x140 PUD
00000000062dc140: 0x00000000062e9067
(qemu) xp 0x00000000062e9000+0x458 PMD
00000000062e9458: 0x00000000062e7067
(qemu) xp 0x00000000062e7000+0xb30 PTE
00000000062e7b30: 0x8000000007294865
(qemu)
此时算出来的 00000000062e7b30 就是 PTE 的地址了,此时只要将 PTE 清零即可完成 madvise 的工作,这里卡了很久,最后是从看雪的 r0Cat 师傅的文章中学到通过 gpa2hva 命令:
gpa2hva addr
Print the host virtual address at which the guest’s physical address addr is mapped.
获取到 qemu 地址后通过 gdb attach qemu进程修改该地址的内容即可。
三、调试
1. __get_user_pages
因为正常 dirtycow 的 poc 是竞争来触发漏洞的,而此时我只需要对 __get_user_pages 函数的处理逻辑进行熟悉,因此不需要使用竞争的 poc ,只需要使用能够触发缺页异常的代码即可。
第一次断点下在了 get_user_pages 上,没有断下来,第二次下在 __get_user_pages 上成功断下

此时可以对着源码进行调试分析了~
首先把参数相关定义熟悉一下:
* __get_user_pages() - pin user pages in memory
* @tsk: task_struct of target task
* @mm: mm_struct of target mm // 描述虚拟内存的结构
* @start: starting user address // 请求的虚拟地址
* @nr_pages: number of pages from start to pin // 需要换入的内存页数量
* @gup_flags: flags modifying pin behaviour // 期望得到的页的权限
* @pages: array that receives pointers to the pages pinned.
* Should be at least nr_pages long. Or NULL, if caller
* only intends to ensure the pages are faulted in.
* @vmas: array of pointers to vmas corresponding to each page.
* Or NULL if the caller does not require them.
* @nonblocking: whether waiting for disk IO or mmap_sem contention
*
...
* Returns number of pages pinned. This may be fewer than the number // 返回值为换入物理内存中页的数量。
* requested. If nr_pages is 0 or negative, returns 0. If no pages
* were pinned, returns -errno. Each page returned must be released
* with a put_page() call when it is finished with. vmas will only
* remain valid while mmap_sem is held.
...
* __get_user_pages walks a process's page tables and takes a reference to
* each struct page that each user address corresponds to at a given
* instant. That is, it takes the page that would be accessed if a user
* thread accesses the given user virtual address at that instant.
通过上述这段注释可以大概了解 __get_user_pages 的作用,即当用户层程序访问虚拟内存时,如果要操作的虚拟内存页面不在物理内存中,__get_user_pages 负责将所需的内存页面换入物理内存中。
同时在注释中也不建议直接使用 __get_user_pages
* In most cases, get_user_pages or get_user_pages_fast should be used
* instead of __get_user_pages. __get_user_pages should be used only if
* you need some special @gup_flags.
在 __get_user_pages 中有两个关键的函数,第一个是 follow_page_mask,通过函数开头的注释可以大概了解 follow_page_mask 主要用于判断 VMA 是否已经被换入到了物理内存中。
/**
* follow_page_mask - look up a page descriptor from a user-virtual address // 在虚拟内存中寻找指定的 page descriptor
* @vma: vm_area_struct mapping @address
* @address: virtual address to look up
* @flags: flags modifying lookup behaviour
* @page_mask: on output, *page_mask is set according to the size of the page
*
* @flags can have FOLL_ flags set, defined in <linux/mm.h>
*
* Returns the mapped (struct page *), %NULL if no mapping exists, or
* an error pointer if there is a mapping to something not represented
* by a page descriptor (see also vm_normal_page()).
* 如果已经寻找的内存页已经被映射进入物理内存中则返回该页的 page 结构,否则返回 NULL。
*/
根据 follow_page_mask 的返回情况,如果 VMA 没有被换入,则触发缺页中断,经由第二个关键函数 faultin_page 进行处理。
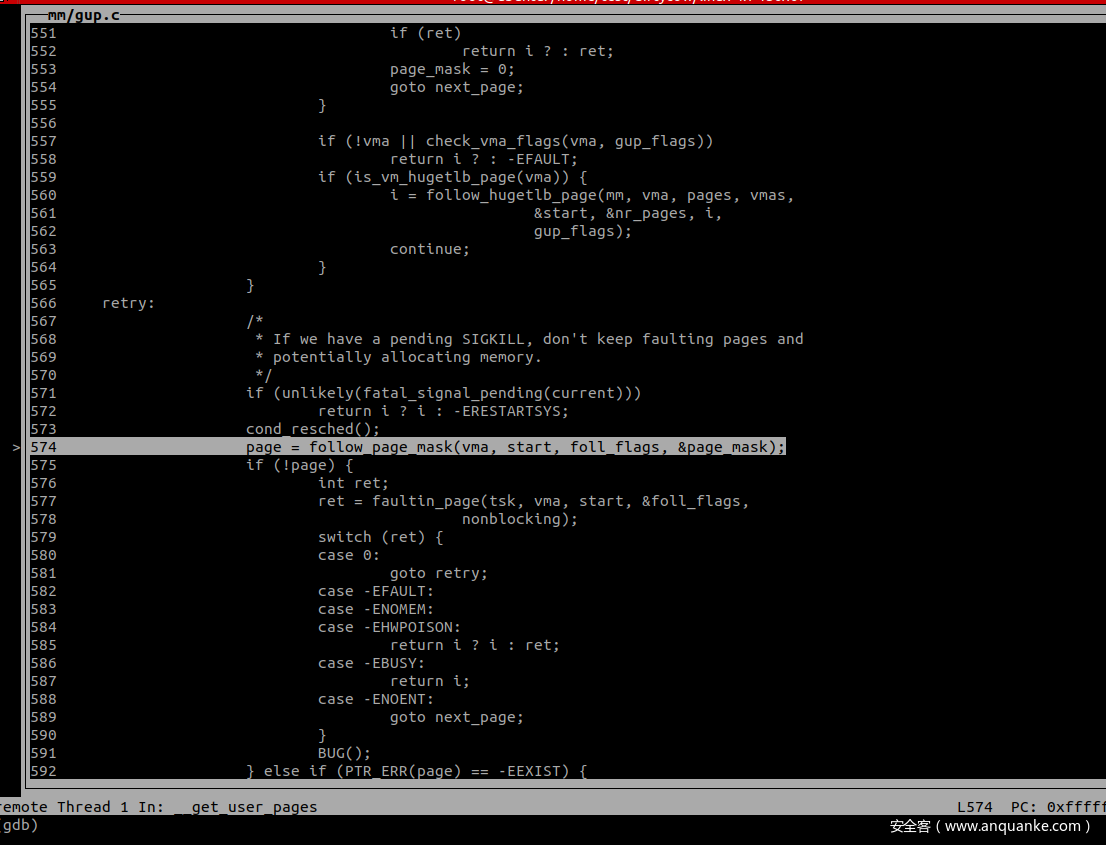
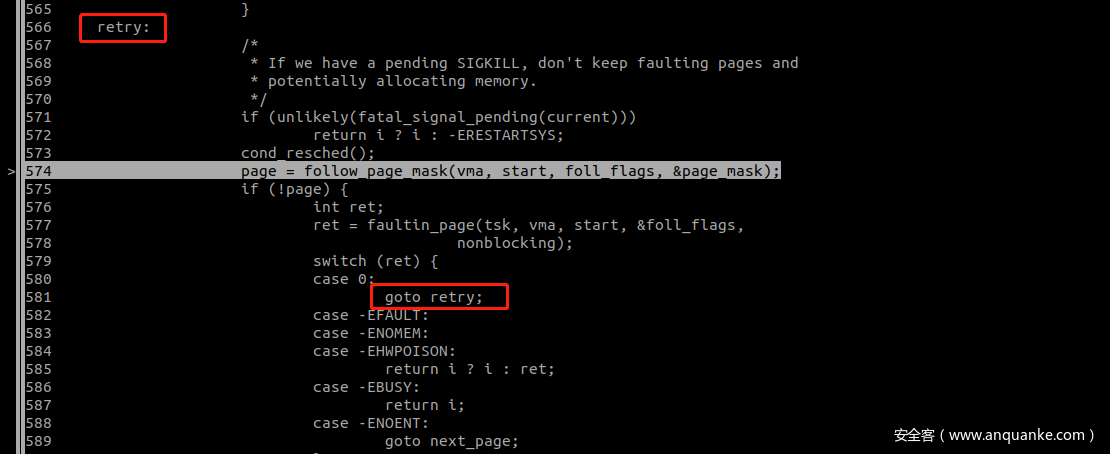
对 private 的处理正常会经历 三次 follow_page_mask 和两次 faultin_page,主要完成两件事:缺页处理、COW。
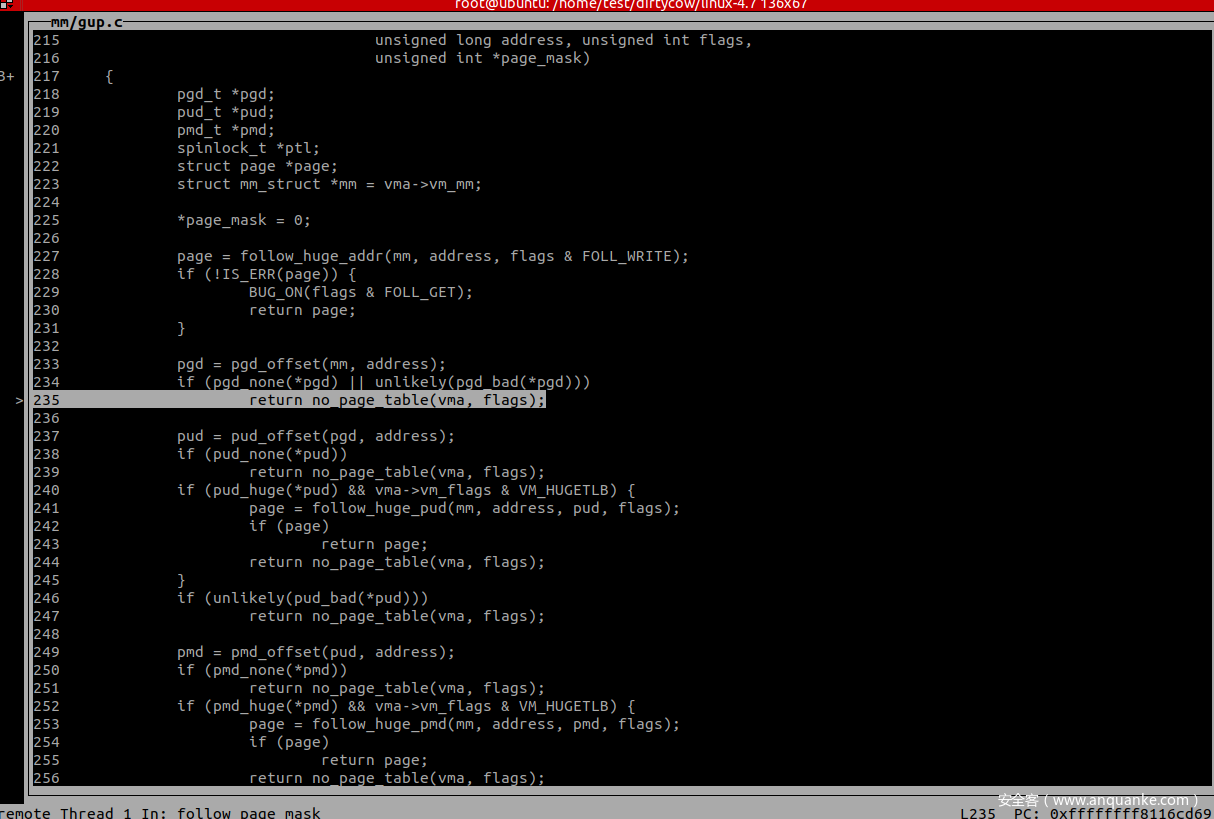
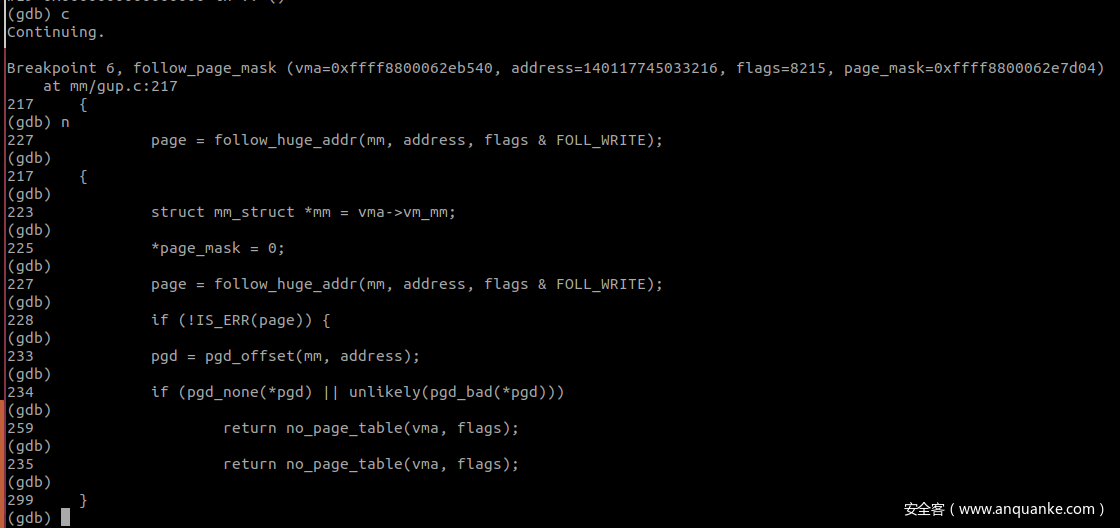
第一次调用会因为访问的page不在物理内存中返回 no_page_table 函数而引发缺页异常,第一次调用 faultin_page 处理,处理完毕后再次进入 follow_page_mask 中。
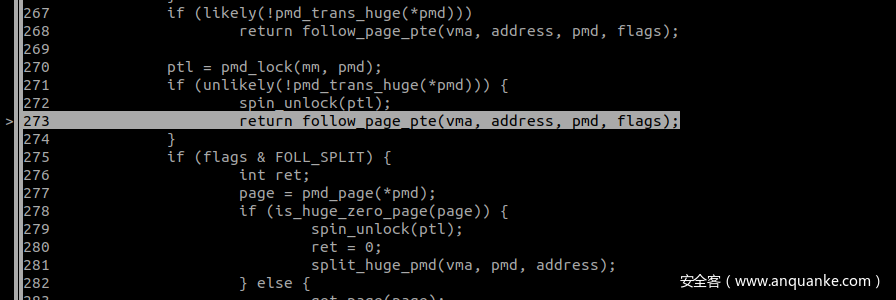
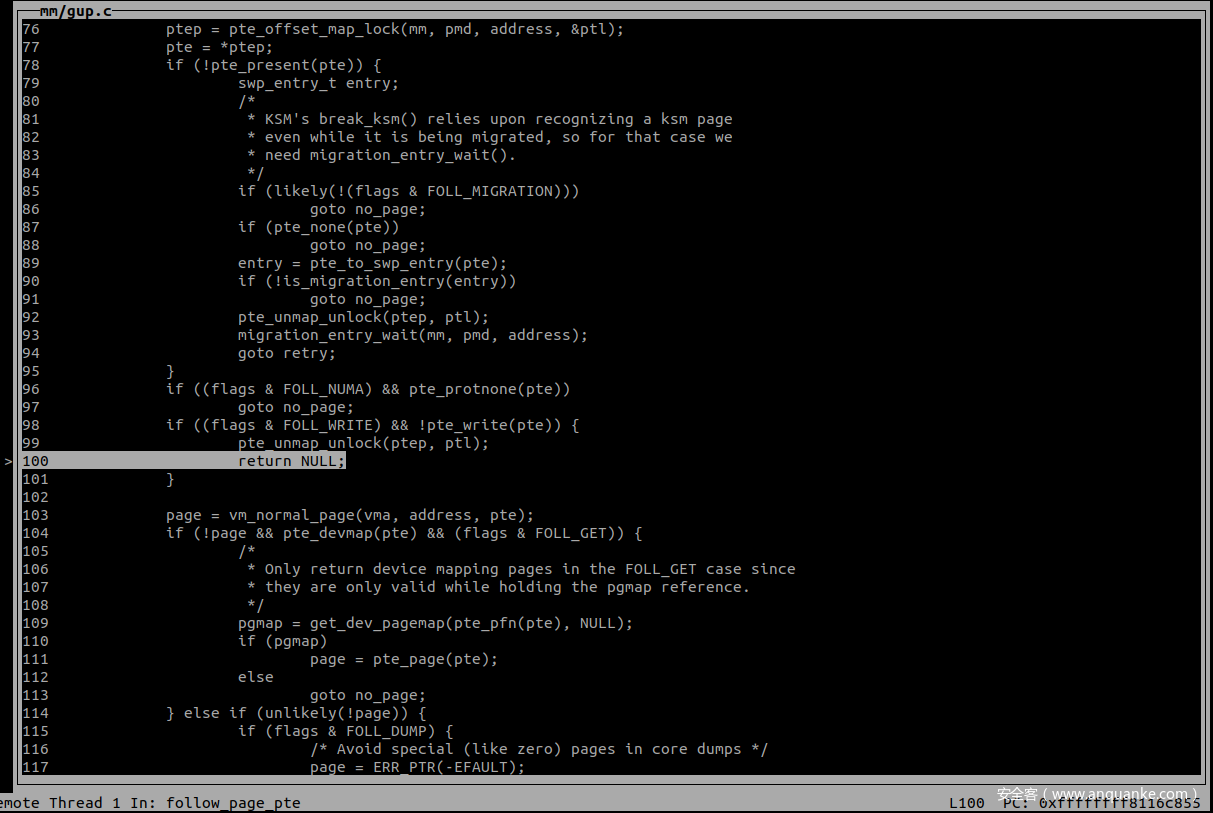
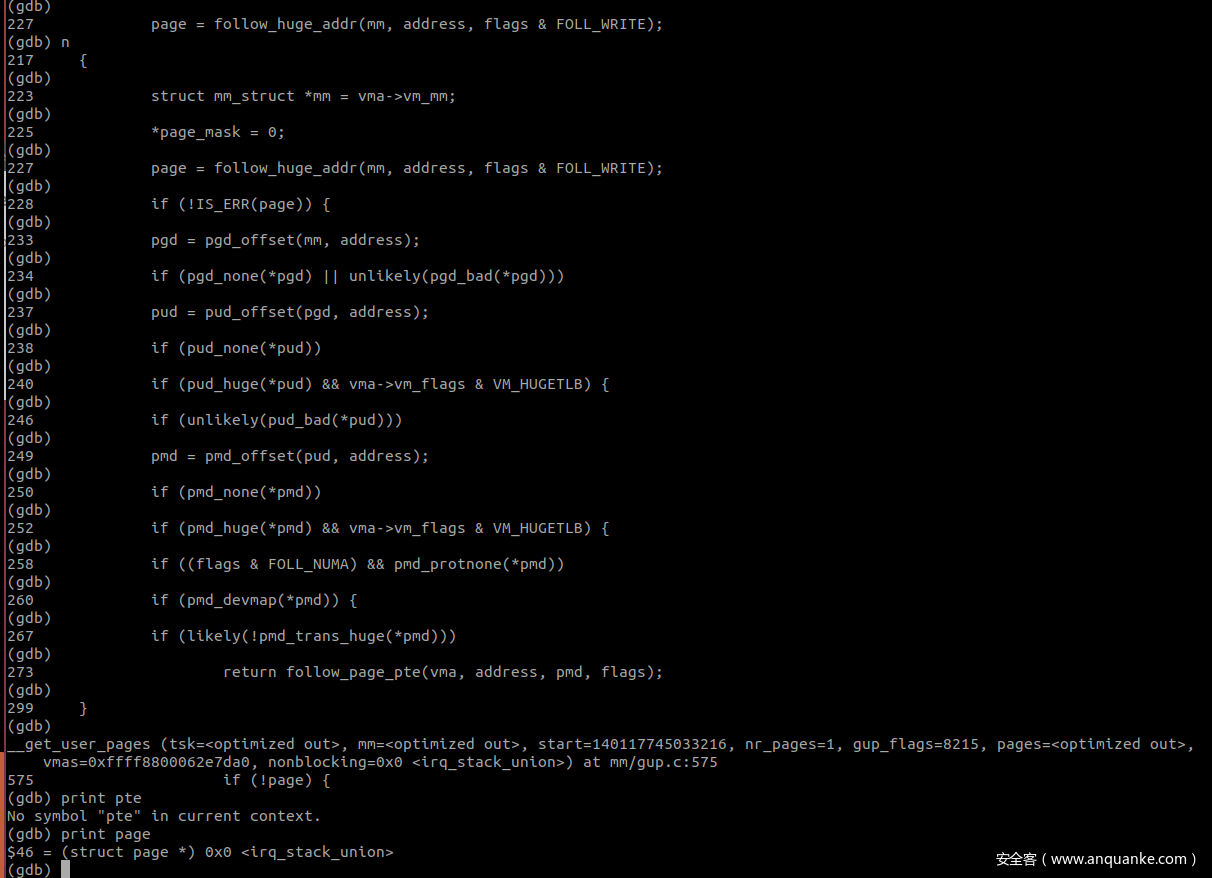
在 follow_page_pte 中判断 FOLL_WRITE 被置位且 pte 不可写,因为mmap的时候以 MAP_PRIVATE 进行的映射,因此 pte 肯定是不可写的,第二次调用返回值 page 为 0。
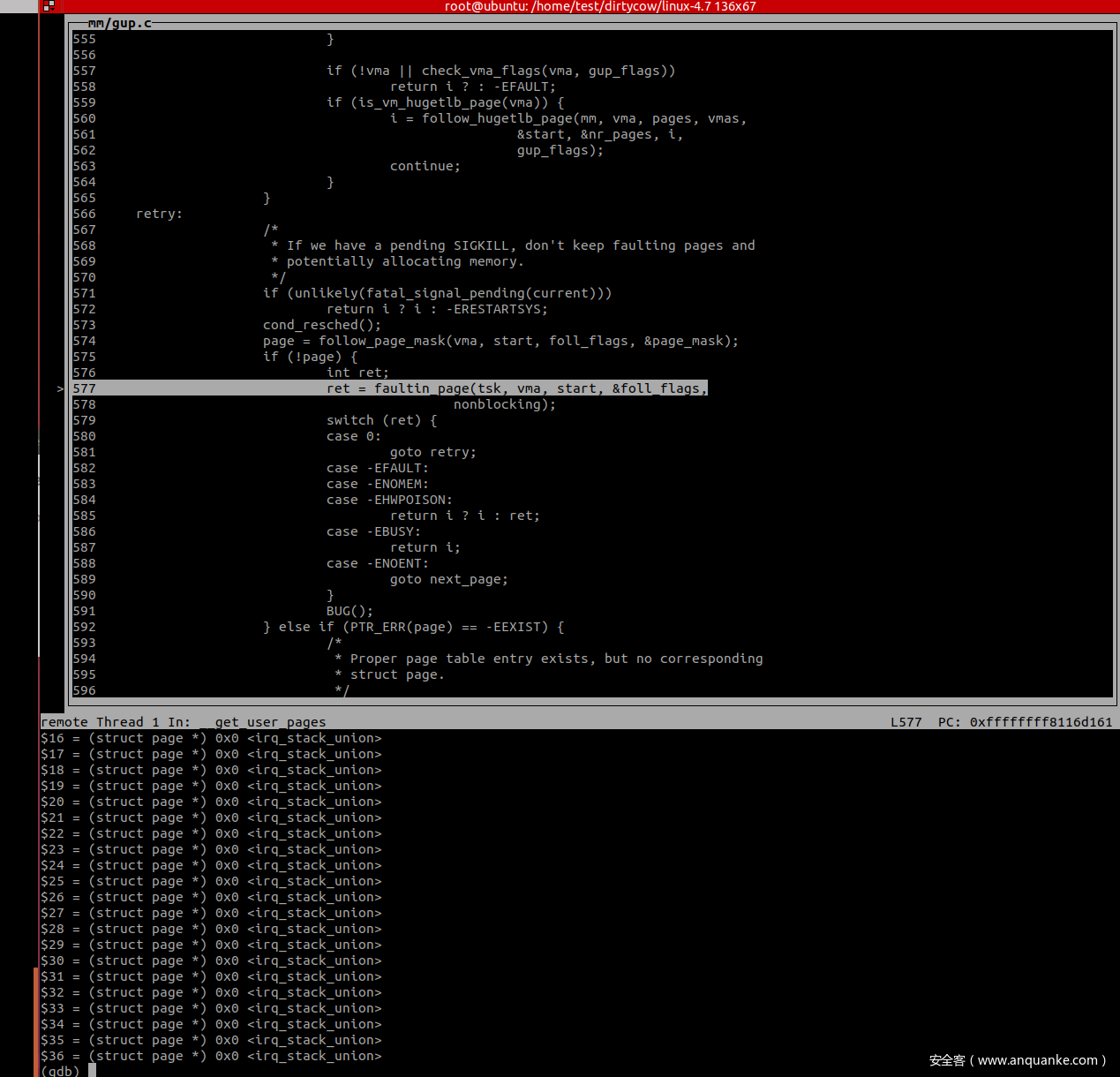
因为没有获取到 page,再次进入 faultin_page 处理后进行第三次调用
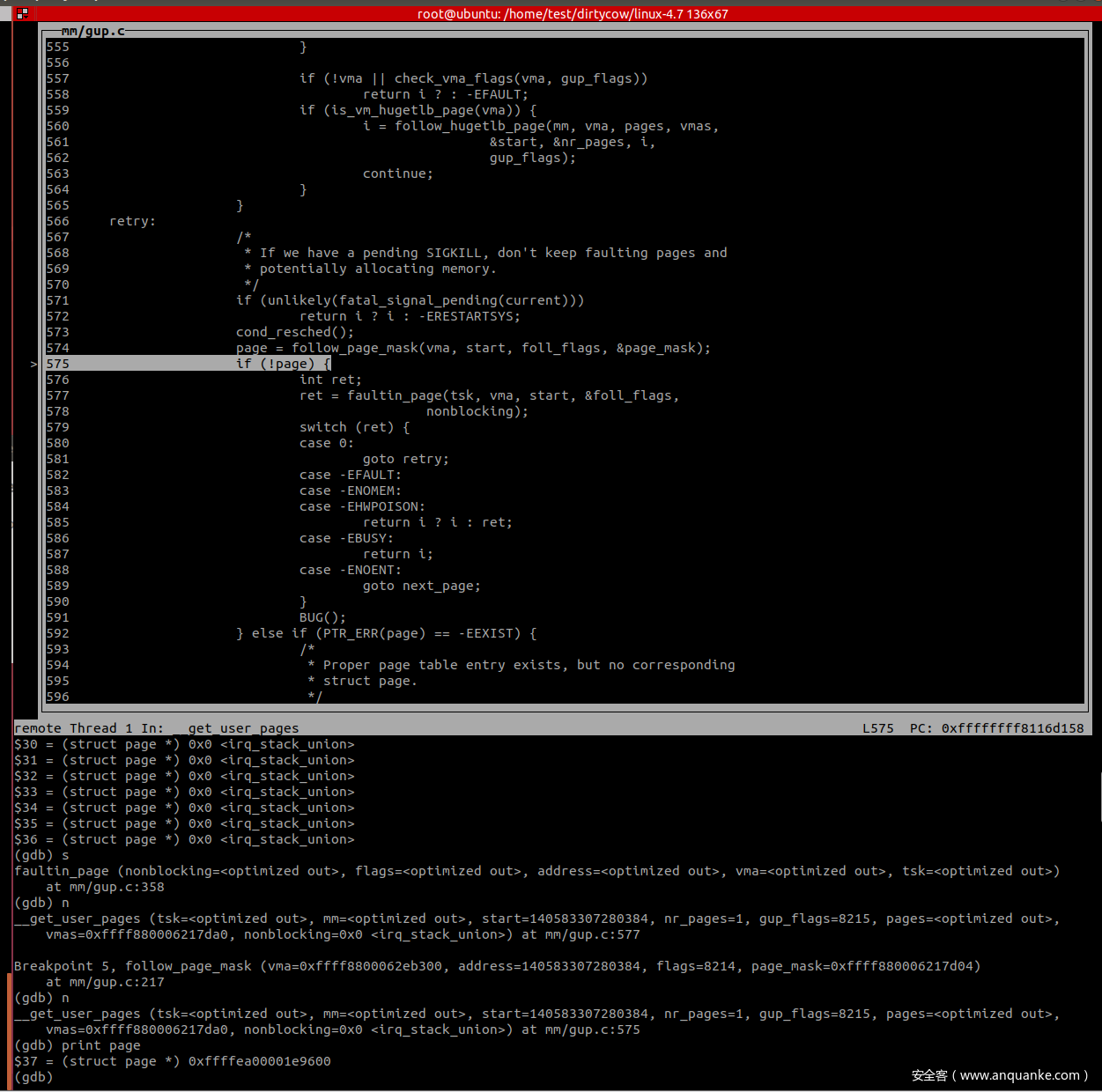
第三次调用完了后才获取到了 page 信息。
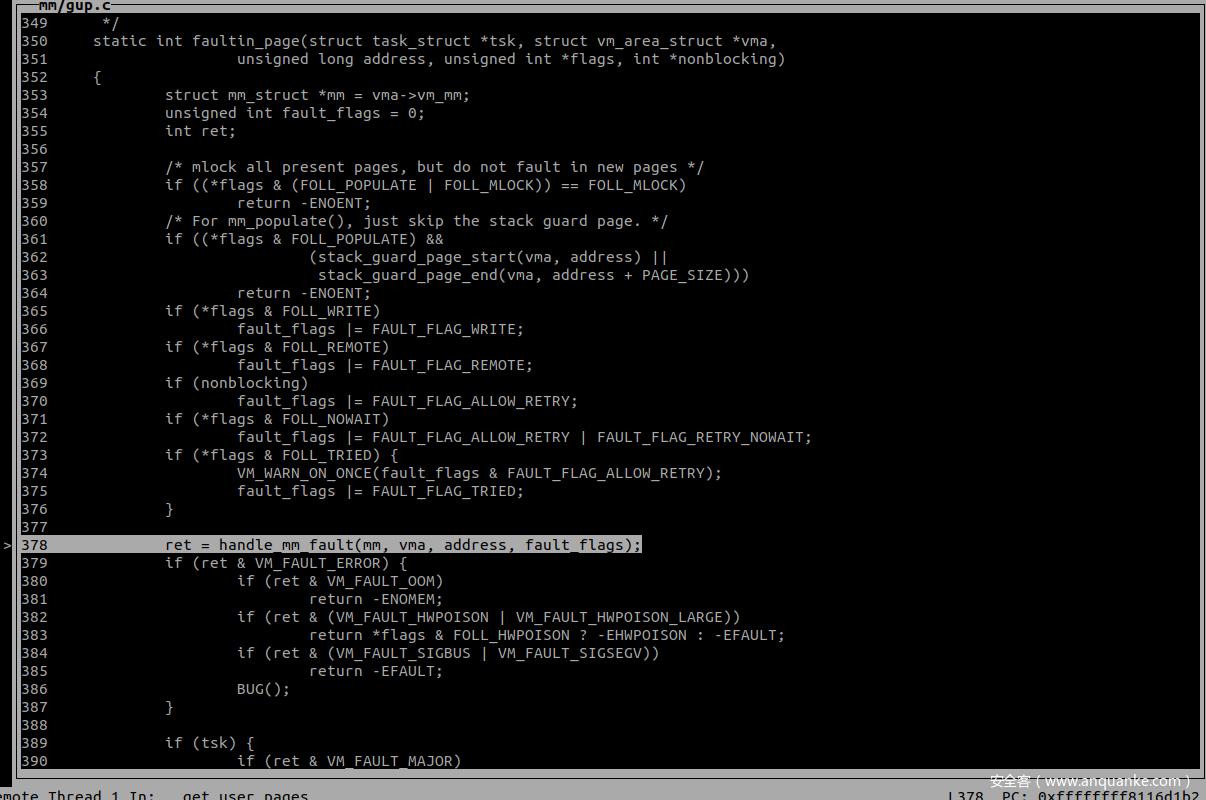
第一次调用 faultin_page 主要完成了缺页处理的工作
第一次缺页处理完了之后,因为换入物理内存中的 PTE 不可写,因此会再次调用 faultin_page 进行 cow
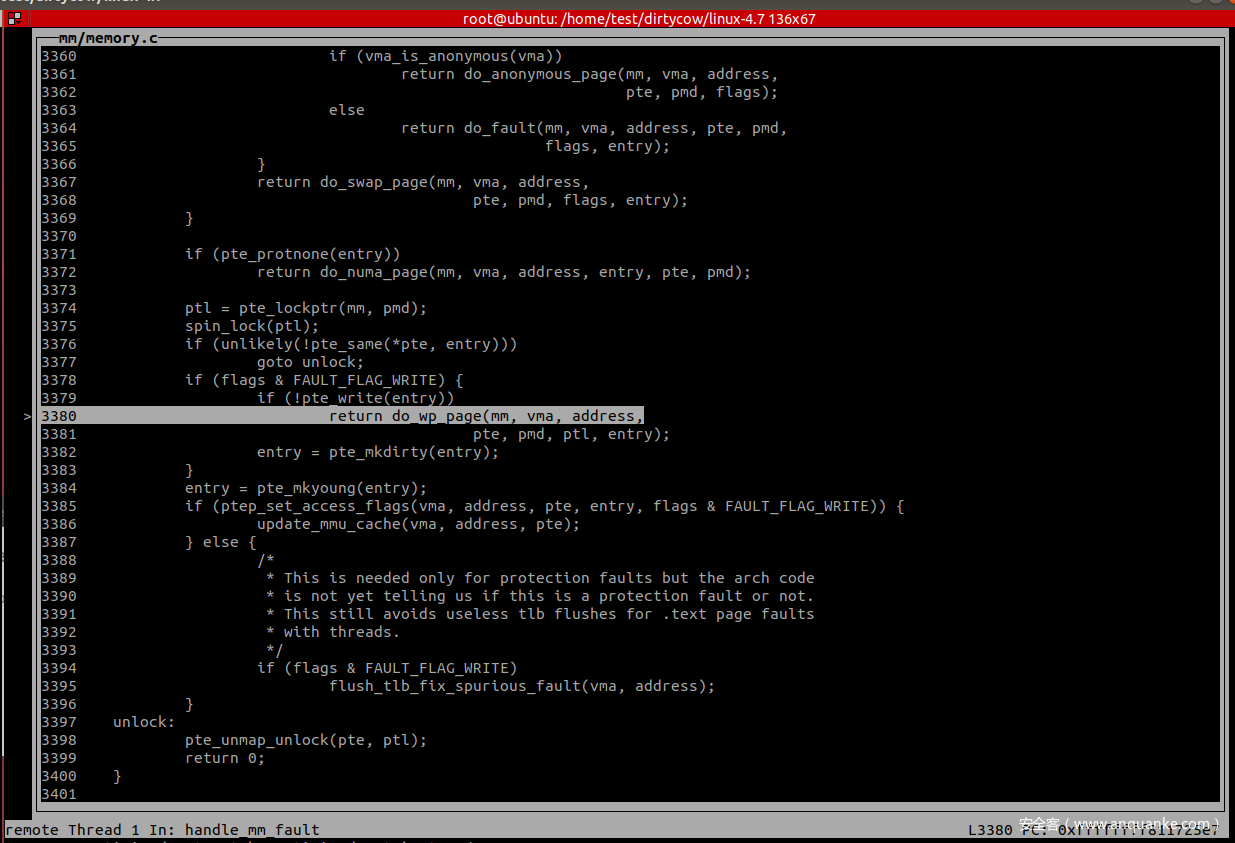
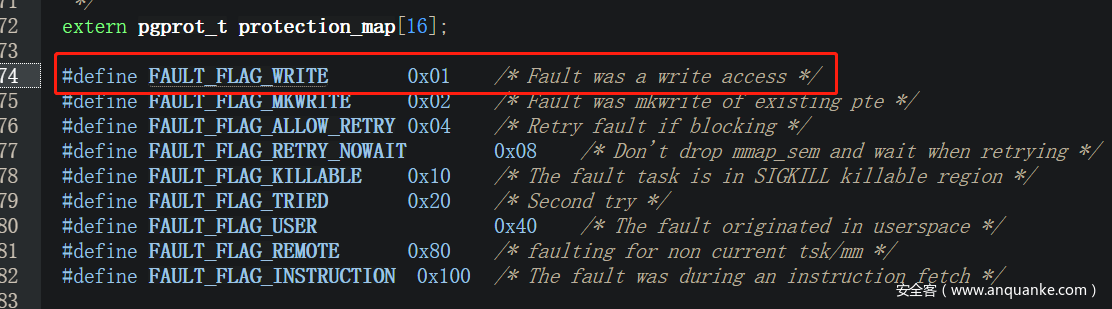
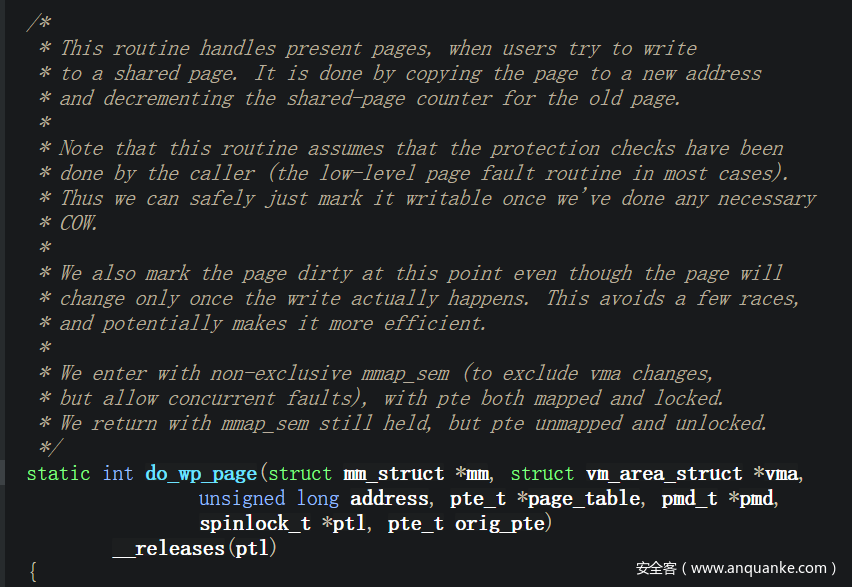
最终会调用 do_wp_page 来完成 cow
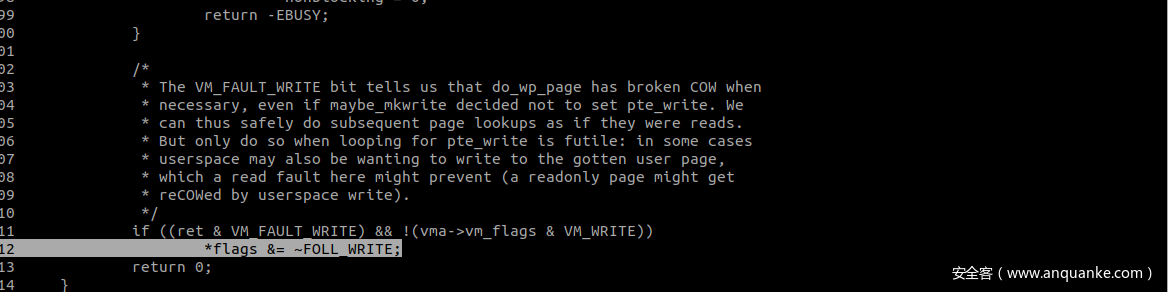
在cow结束后清除page的 FOLL_WRITE 标记,从而在第三次 follow_page_mask 的时候能够正常返回 pte 信息。
2. madvise
/*
* The madvise(2) system call.
*
* Applications can use madvise() to advise the kernel how it should
* handle paging I/O in this VM area. The idea is to help the kernel
* use appropriate read-ahead and caching techniques. The information
* provided is advisory only, and can be safely disregarded by the
* kernel without affecting the correct operation of the application.
*
* behavior values:
* MADV_NORMAL - the default behavior is to read clusters. This
* results in some read-ahead and read-behind.
* MADV_RANDOM - the system should read the minimum amount of data
* on any access, since it is unlikely that the appli-
* cation will need more than what it asks for.
* MADV_SEQUENTIAL - pages in the given range will probably be accessed
* once, so they can be aggressively read ahead, and
* can be freed soon after they are accessed.
* MADV_WILLNEED - the application is notifying the system to read
* some pages ahead.
* MADV_DONTNEED - the application is finished with the given range, 关键参数
* so the kernel can free resources associated with it.
* MADV_FREE - the application marks pages in the given range as lazy free,
* where actual purges are postponed until memory pressure happens.
* MADV_REMOVE - the application wants to free up the given range of
* pages and associated backing store.
* MADV_DONTFORK - omit this area from child's address space when forking:
* typically, to avoid COWing pages pinned by get_user_pages().
* MADV_DOFORK - cancel MADV_DONTFORK: no longer omit this area when forking.
* MADV_HWPOISON - trigger memory error handler as if the given memory range
* were corrupted by unrecoverable hardware memory failure.
* MADV_SOFT_OFFLINE - try to soft-offline the given range of memory.
* MADV_MERGEABLE - the application recommends that KSM try to merge pages in
* this area with pages of identical content from other such areas.
* MADV_UNMERGEABLE- cancel MADV_MERGEABLE: no longer merge pages with others.
* MADV_HUGEPAGE - the application wants to back the given range by transparent
* huge pages in the future. Existing pages might be coalesced and
* new pages might be allocated as THP.
* MADV_NOHUGEPAGE - mark the given range as not worth being backed by
* transparent huge pages so the existing pages will not be
* coalesced into THP and new pages will not be allocated as THP.
* MADV_DONTDUMP - the application wants to prevent pages in the given range
* from being included in its core dump.
* MADV_DODUMP - cancel MADV_DONTDUMP: no longer exclude from core dump.
*
* return values:
* zero - success
* -EINVAL - start + len < 0, start is not page-aligned,
* "behavior" is not a valid value, or application
* is attempting to release locked or shared pages.
* -ENOMEM - addresses in the specified range are not currently
* mapped, or are outside the AS of the process.
* -EIO - an I/O error occurred while paging in data.
* -EBADF - map exists, but area maps something that isn't a file.
* -EAGAIN - a kernel resource was temporarily unavailable.
*/
madvise原始的用途是当程序明确了解指定内存的访问模式的情况下,向内核提供特定内存的相关信息,内核利用这些信息来优化这段内存的处理和维护过程,本质上是用于提高系统性能的。
但是在 dirtycow 中 madvise 指定的 MADV_DONTNEED 参数会将内存标记为可释放的内存,从而会导致内核释放该内存区和对应的物理页。
四、环境搭建及复现
基础环境需要的有 qemu、busybox和漏洞范围内的 linux 源码一份。
1. 环境搭建
主要涉及两步操作,分别为 busybox的编译和 linux 源码的编译,busybox 直接下载最新版本的编译即可,这里主要记录几个编译 kernel 比较常见的坑点。
高版本的 gcc 默认在编译时默认开启 pie,然而在我测试环境的内核是不支持 pie 的,因此需要在 make menuconfig 后自行在 Makefile 中的 KBUILD_CFLAGS 后添加 -fno-pie
在编译过程中报了一个跟 -mfentry 相关的支持问题,此处直接在 Makefile 中搜索,仅有一处相关的内容,直接删掉即可。
这个问题的误导性比较强,最初报错的时候,通过google将问题指向了 -pg 选项的 link 问题,经过大佬的指导后得知,实际的情况是部分版本的内核对 tracer 模块的支持不是很好,因此在 make menuconfig 的时候需要将整个 tracer 模块禁用。
下面就是静态编译 poc 并打包文件系统了,poc 静态编译的命令不再记录。
# 目录: busybox/_install/
find . | cpio -o --format=newc > ../rootfs.img
用下面的命令启动环境
qemu-system-x86_64 \
-kernel [your kernel arch/x86_64/boot/bzImage path] \
-initrd [your rootfs.img path] \
-append "console=ttyS0 root=/dev/ram rdinit=/sbin/init" \
-cpu kvm64 \
--nographic --gdb tcp::1234
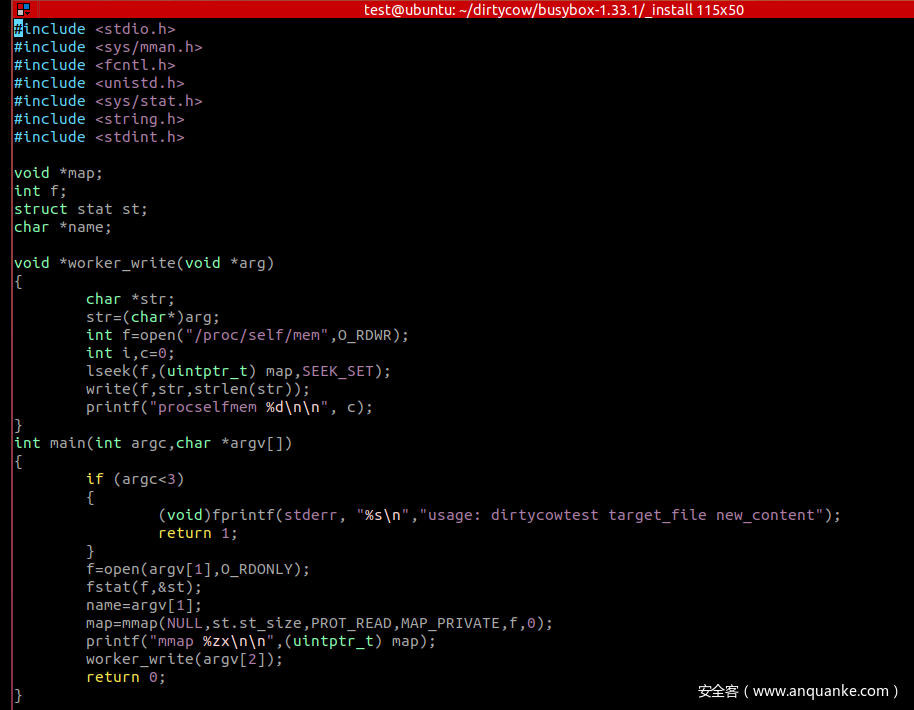
2. 单线程 poc
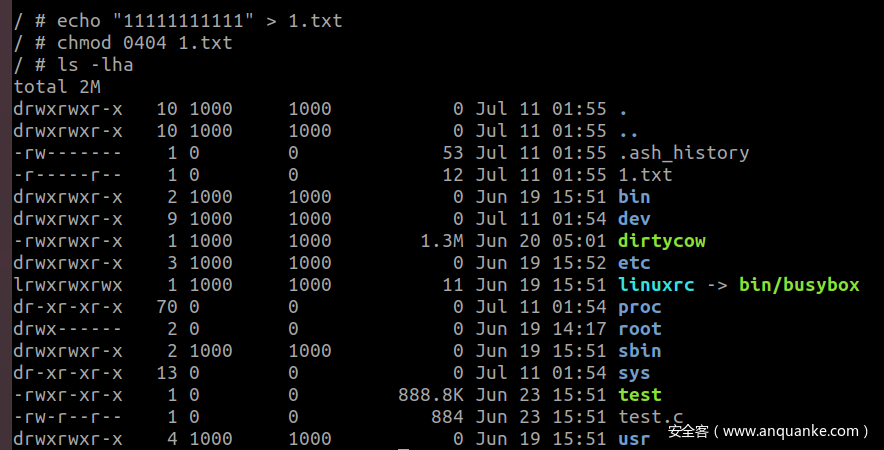
首先创建一个只读文件
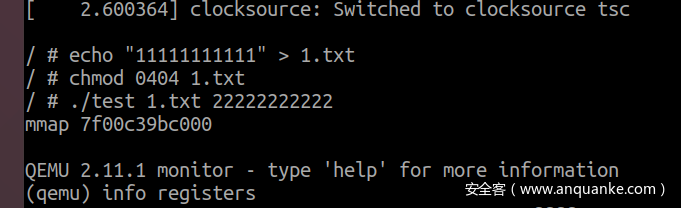
运行poc,并根据输出的虚拟地址进行寻址,此时 follow_page_mask 和 faultin_page 均已执行两回,此时已经完成了 COW 并执行了关键的一步:清除了 FOLL_WRITE 属性。
此时我们模拟 madvise 的功能,清除pte的信息,会导致 follow_page_mask 再次引发缺页,缺页处理后获得的 pte 是没有 FOLL_WRITE属性的,进而也就不会有 FAULT_FALG_WRITE 引发 COW,从而触发了漏洞修改了只读页面。
(gdb) x/10xg 0x7fc3a4698de0
0x7fc3a4698de0: 0x8000000000203865 0x0000000000000000
0x7fc3a4698df0: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e00: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e10: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e20: 0x0000000000000000 0x0000000000000000
(gdb) set *0x7fc3a4698de0=0x0
(gdb) x/10xg 0x7fc3a4698de0
0x7fc3a4698de0: 0x8000000000000000 0x0000000000000000
0x7fc3a4698df0: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e00: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e10: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e20: 0x0000000000000000 0x0000000000000000
(gdb) set *0x7fc3a4698de4=0x0
(gdb) x/10xg 0x7fc3a4698de0
0x7fc3a4698de0: 0x0000000000000000 0x0000000000000000
0x7fc3a4698df0: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e00: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e10: 0x0000000000000000 0x0000000000000000
0x7fc3a4698e20: 0x0000000000000000 0x0000000000000000
(gdb) c
Continuing.
调这个经典漏洞着实是花了很长一段时间,中间也是走走停停,不过最终还是搞清楚了原理,在此感谢各位无私分享的师傅们~
参考链接
https://bbs.pediy.com/thread-266033.htm
https://bbs.pediy.com/thread-246024.htm
https://cloud.tencent.com/developer/article/1373361
https://man7.org/linux/man-pages/man2/fork.2.html
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/diff/?id=474c90156c8dcc2fa815e6716cc9394d7930cb9c
https://www.jianshu.com/p/2d30dce24bdb
https://abcdxyzk.github.io/blog/2015/09/11/kernel-mm-vma-base/
https://github.com/manuscola/mm_addr/blob/master/fileview.c
https://juejin.cn/post/6844903828446248968







发表评论
您还未登录,请先登录。
登录