

题目还是好玩。
TacticalArmed
看程序的启动项发现了回调函数,里面创建一个线程。
这个线程里面还添加了一个异常处理函数:且里面有一个int2d中断。如果有调试器,调试器就会接管这个 int 2dh 产生的异常从而不走我们设置的异常回调处理函数。
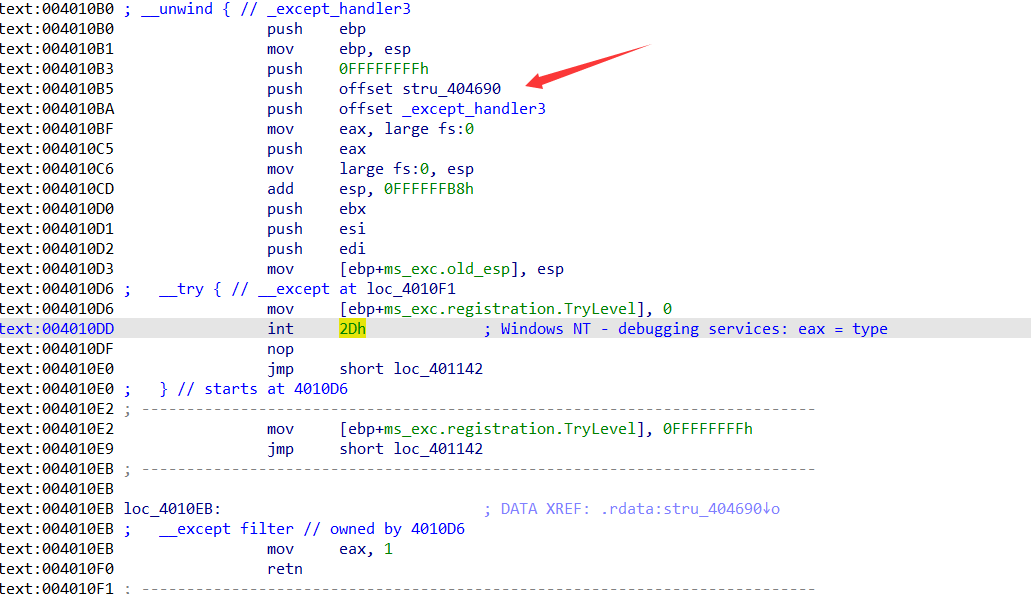
看到注册的异常处理函数:赋值4个4字节数据。
所以说我们要把int2d产生的异常交给程序处理才是正确的行为。也就是要有那个4个4个字节数据执行的过程。
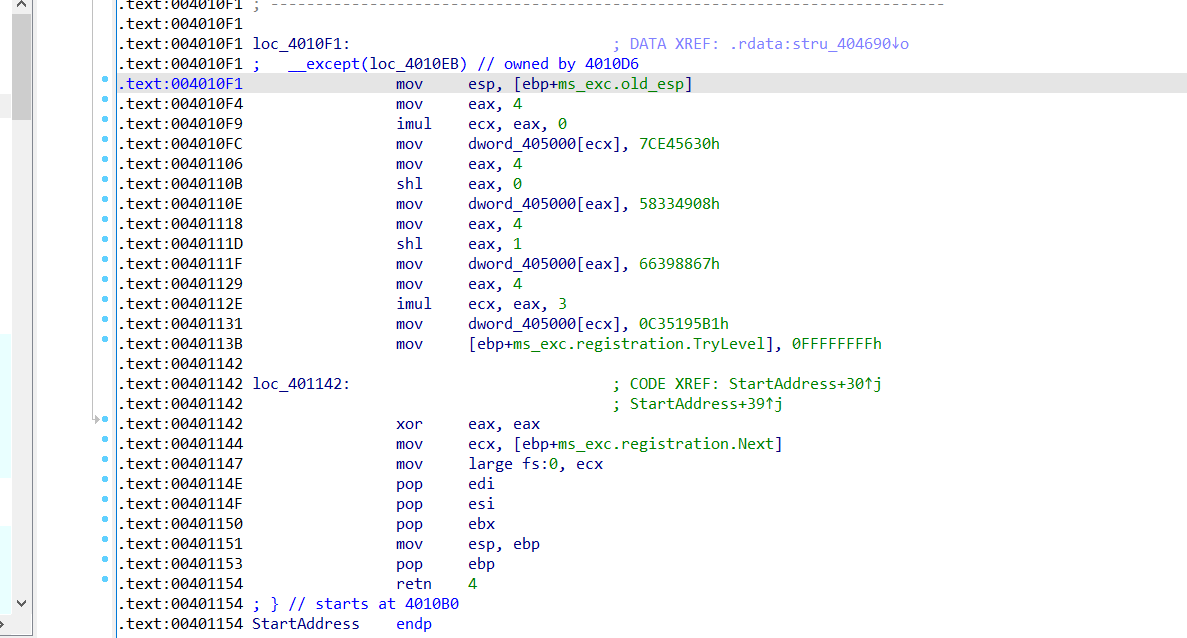
再看到main函数,首先预留了16字节大小的可读可写可执行的内存。
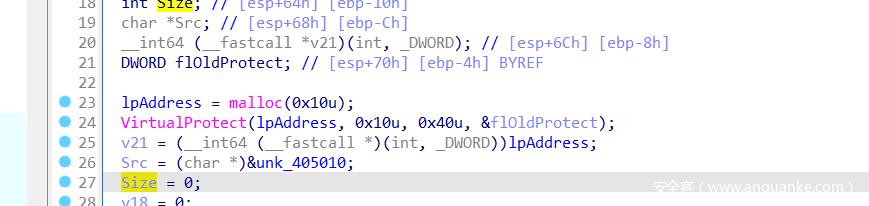
下面的加密:从整体结构可以看出来程序是8字节一组加密,且每组加密33轮,加上开始赋值的4个4字节数据,这很大概论是tea类加密了。
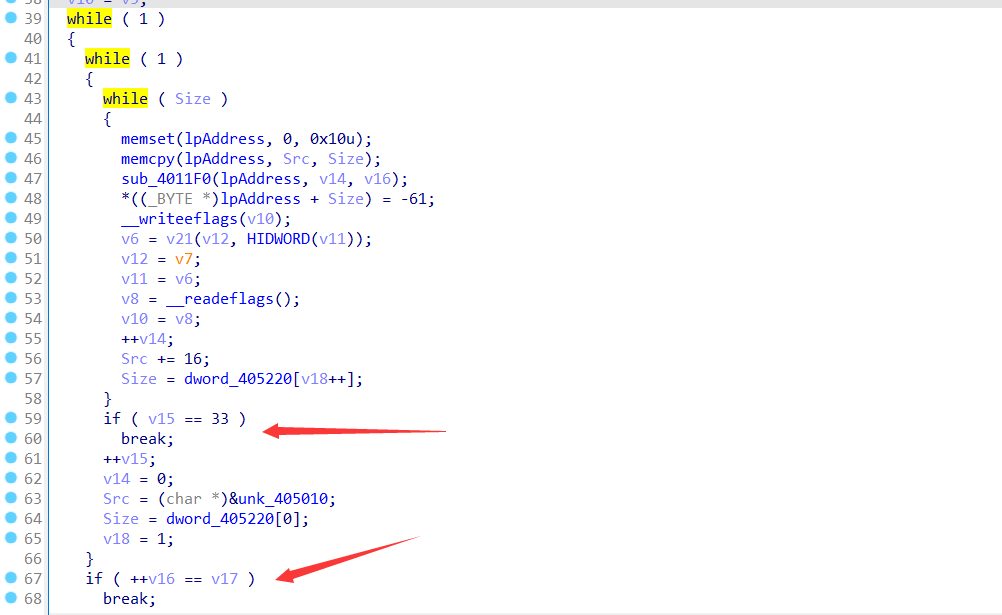
然后调试跟踪一下流程,ida调试会卡住,选择x32dbg
就是跟踪看v21每次执行了那些指令。
mov ecx, dword ptr ds:[0x00405748]
sub ecx, 0x7E5A96D2
mov dword ptr ds:[0x00405748], ecx
mov edx, dword ptr ds:[0x0040564C]
shr edx, 0x5
mov eax, dword ptr ds:[0x00405004]
add eax, edx
mov ecx, dword ptr ds:[0x00405748]
add ecx, dword ptr ds:[0x0040564C]
xor eax, ecx
mov edx, dword ptr ds:[0x0040564C]
shl edx, 0x4
mov ecx, dword ptr ds:[0x00405000]
add ecx, edx
xor eax, ecx
mov edx, dword ptr ds:[0x00405648]
add edx, eax
这样简单跟踪下,记录开始的一些加密指令,手动反编译或者在ida中反编译下:
sum = 0
sum -= 0x7E5A96D2
enc[0] += (((enc[1] >> 5) + key[1]) ^ (enc[1]+sum))^((enc[1] << 4)+key[0])
很明显的tea,注意一下deltea和轮数就好。
解密。
def de_tea(enc, sum):
v0 = enc[0]
v1 = enc[1]
for i in range(33):
v1 -= ((v0<<4) + key[2]) ^ (v0 + sum) ^ ((v0>>5) + key[3])
v1 &= 0xffffffff
v0 -= ((v1<<4) + key[0]) ^ (v1 + sum) ^ ((v1>>5) + key[1])
v0 &= 0xffffffff
sum += 0x7E5A96D2
sum &= 0xffffffff
return [v0, v1]
enc = [0x422F1DED, 0x1485E472, 0x35578D5, 0xBF6B80A2, 0x97D77245, 0x2DAE75D1, 0x665FA963, 0x292E6D74,0x9795FCC1, 0xBB5C8E9]
key = [0x7CE45630, 0x58334908, 0x66398867, 0xC35195B1]
sum = 0
x = 0
flag = b''
for i in range(5):
sum = (x-0x7E5A96D2*33)&0xffffffff
x = sum
enc[2*i:2*i+2] = de_tea(enc[2*i:], sum)
#print(a.to_bytes(4, "little")+b.to_bytes(4, "little"))
for i in enc:
flag += i.to_bytes(4, "little")
print(flag)
gghdl
从字符串定位到关键函数,然后用字符串帮助我们理清一下程序流程,如出现wrong的分支我们就不用去分析了。
其中让我看清程序程序的加密流程是从case4:
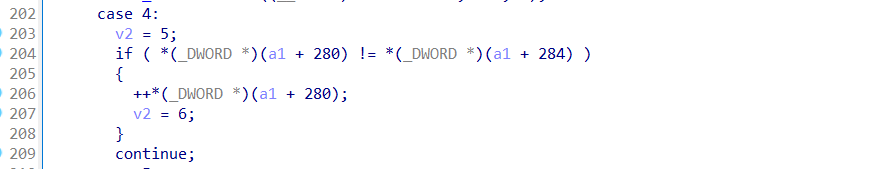
这里v2表示下一步要执行的分支,开始赋值的5,然后如果那个if条件成立修改v6的为6,也就是修改下一步要执行分支。
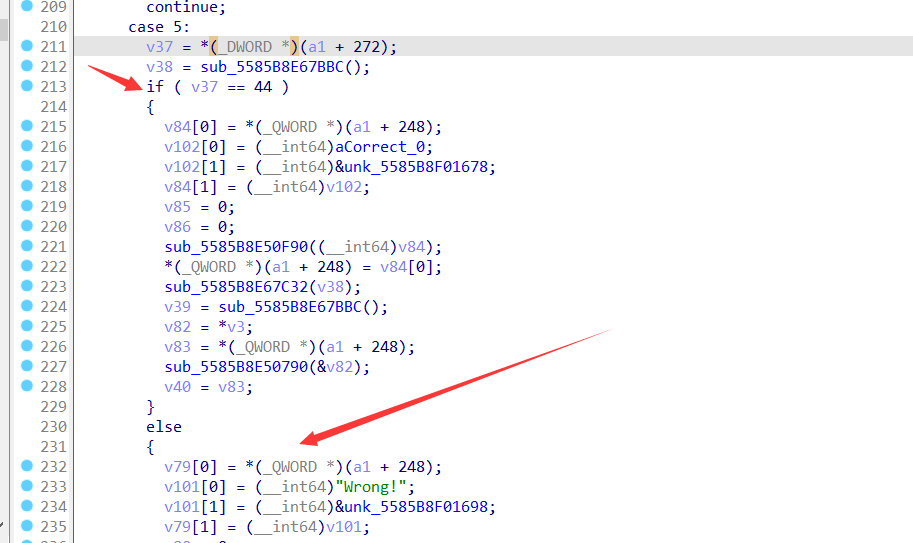
看一下5和6对应的分支。
5:
6:
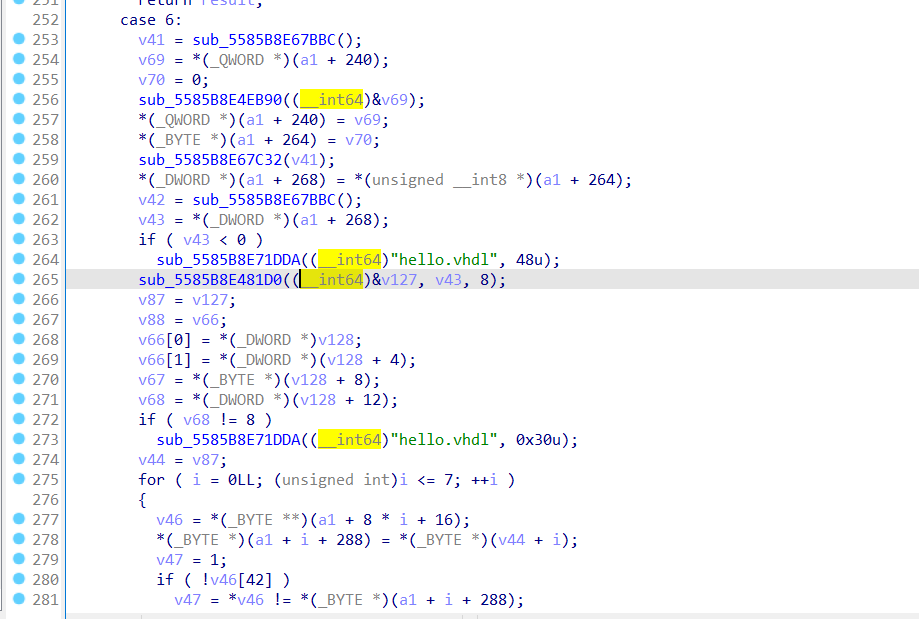
不难看出5是最后的判断分支,也就是最后是否正确的判断;6是加密分支。
然后在调试验证一下那个条件判断比较的2个值:很明显是比较当前index是否等于44
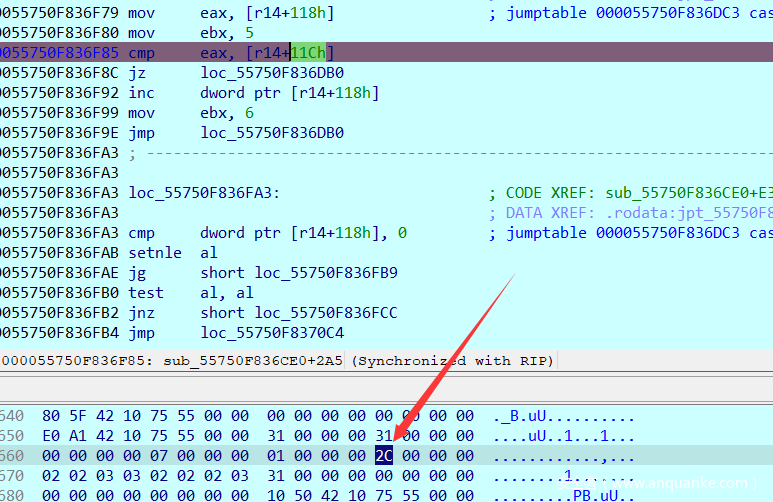
从以上我们就能知道程序是在循环取出每个字节进行加密。
然后再来直接看到最后判断成功要满足的条件。v37要等于44,也就是(_DWORD )(a1 + 272);等于44
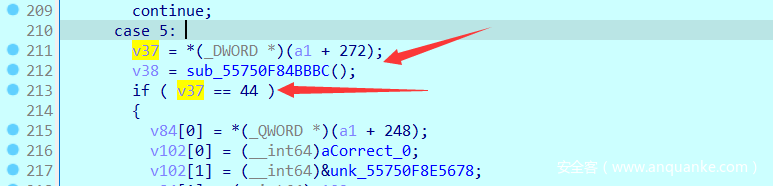
点击272,从ida中的高亮看程序那些代码对他进行了修改。可以发现都在case7中,且case7中进行分段的处理。输入的[0, 7] [8, 16], [16, 24]….
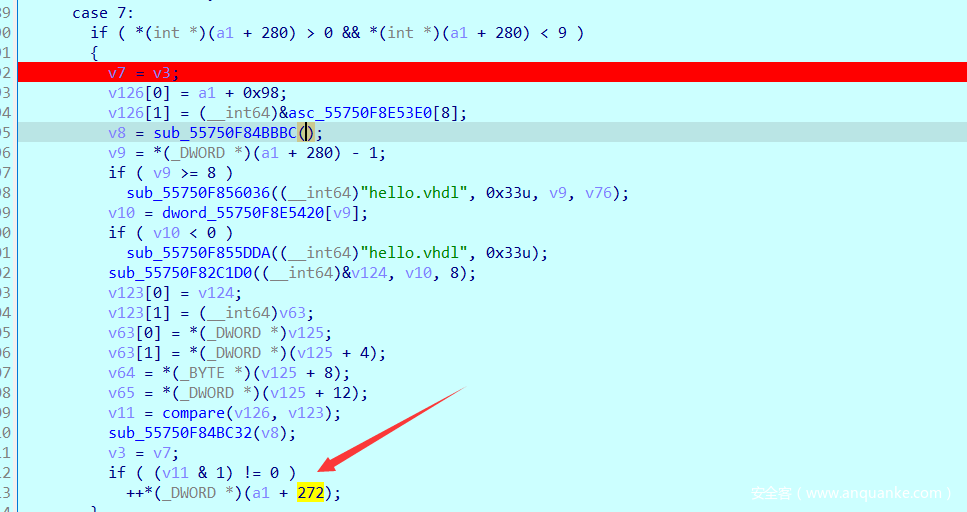
也是看到要v11的值要为1才进行++(_DWORD )(a1 + 272);
而v11是进行compare函数来比较的返回值,这里分析后注释的。
最后就是加密操作,更多的是用数据测试出来的。
调试看到输入只经过一个函数: sub_55750F82C1D0((__int64)&v127, v43, 8);
返回值是8位,且都只有2和3组成。
我输入的3经过这个函数变成了

其实他就是我输入的该字节的二进制,只是表示的不同,减个2就是了。
同样看到case7中取了一个数据进行同样的操作,最后和输入的加密结果对比,那可以锁定这里是取密文了。
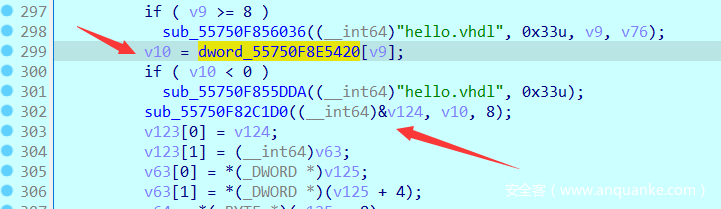
但输入在经过转化二进制后还进行了一个加密操作,具体没去跟,但从测试结果可以知道是单字节映射。
然后输入不同的数据去猜测加密,尝试了加法和减法,但每次加减值并不一样。最后在测试异或时发现每次异或的都是同一个值:0x9c
取出case7中的每部分密文简单解密一下就好:
>>> a = 0x000000D8, 0x000000DD, 0x000000CF, 0x000000DF, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC
>>> a = [0x000000D8, 0x000000DD, 0x000000CF, 0x000000DF, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC]
>>> p1 = [a[i]^0x9c for i i range(len(a))]
File "<stdin>", line 1
p1 = [a[i]^0x9c for i i range(len(a))]
^
SyntaxError: invalid syntax
>>> p1 = [a[i]^0x9c for i in range(len(a))]
>>> p1
[68, 65, 83, 67, 84, 70, 123, 48]
>>> bytes(p1)
b'DASCTF{0'
>>> b = [0x000000AA, 0x000000AE, 0x000000A5, 0x000000AD, 0x000000A5, 0x000000AA, 0x000000AE, 0x000000B1]
>>> p2 = [b[i]^0x9c for i in range(len(b))]
>>> p2
[54, 50, 57, 49, 57, 54, 50, 45]
>>> bytes(p2)
b'6291962-'
>>> c = [0x000000FD, 0x000000FE, 0x000000FD, 0x000000F8, 0x000000B1, 0x000000A8, 0x000000AC, 0x000000FF]
>>> p3 = [c[i]^0x9c for i in range(len(c))]
>>> p3
[97, 98, 97, 100, 45, 52, 48, 99]
>>> d = [0x000000A4, 0x000000B1, 0x000000A4, 0x000000AF, 0x000000AD, 0x000000A4, 0x000000B1, 0x000000FA]
>>> p4 = [d[i]^0x9c for i in range(len(d))]
>>> p4
[56, 45, 56, 51, 49, 56, 45, 102]
>>> e = [0x000000AC, 0x000000FD, 0x000000AA, 0x000000FE, 0x000000AD, 0x000000A4, 0x000000AA, 0x000000A8]
>>> p5 = [e[i]^0x9c for i in range(len(e))]
>>> f = [0x000000A4, 0x000000AE, 0x000000FF, 0x000000E1, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC, 0x00000128]
>>> p6 = [f[i]^0x9c for i in range(len(f))]
>>> p6
[56, 50, 99, 125, 84, 70, 123, 48, 436]
>>> p = p1+p2+p3+p4+p5+p6
>>> p
[68, 65, 83, 67, 84, 70, 123, 48, 54, 50, 57, 49, 57, 54, 50, 45, 97, 98, 97, 100, 45, 52, 48, 99, 56, 45, 56, 51, 49, 56, 45, 102, 48, 97, 54, 98, 49, 56, 54, 52, 56, 50, 99, 125, 84, 70, 123, 48, 436]
>>> bytes(p)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: bytes must be in range(0, 256)
>>> p[:-2]
[68, 65, 83, 67, 84, 70, 123, 48, 54, 50, 57, 49, 57, 54, 50, 45, 97, 98, 97, 100, 45, 52, 48, 99, 56, 45, 56, 51, 49, 56, 45, 102, 48, 97, 54, 98, 49, 56, 54, 52, 56, 50, 99, 125, 84, 70, 123]
>>> bytes(p[:-2])
b'DASCTF{06291962-abad-40c8-8318-f0a6b186482c}TF{'
虚假的粉丝
直接看到判断的地方。这里的比较就是用开始的输入去找找f目录下的指定文件,之后也是按照输入去取指定位置的数据,最后取出的数据的第一位要为’U’,第四十位要为:’S’
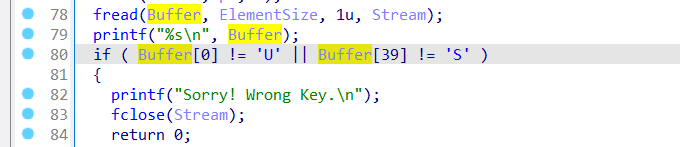
然后继续看后面,又是一个输入的判断。
继续看下去,就是用第二次的输入去解密ASCII-faded 5315.txt文件的内容。
所以现在的关键点就是去获取第二次的11位输入,因为用了它去解密ASCII-faded 5315.txt文件。
考虑是开始的输入去获取的那个文件有提示信息,先写脚本找到这个文件:
for i in range(1, 5317):
f = open("f/ASCII-faded %04d.txt"%i, "rb")
data = f.read()
if b'U' in data and b'S' in data:
print(i)
print(data.decode())
f.close()
得到是第4157个文件。
可以看到上面有一段字符串:UzNDcmU3X0szeSUyMCUzRCUyMEFsNE5fd0FsSzNSWMa,也是程序要打印出来的。
base64得到:S3Cre7_K3y%20%3D%20Al4N_wAlK3RX苺
base64解码内容正好有第二次输入要满足的值:Al4N_wAlK3R
修改程序eip后输入,在播放最后看到flag
ROR
z3可以解决的问题,注意一点的就是:
TypeError: list indices must be integers or slices, not BitVecRef
也就是list的index不能为z3的数据类型,那么我们先取出index就好了。
from z3 import *
s = Solver()
Str = [BitVec('x%d'%i, 8) for i in range(40)]
print(Str)
v5 = [0]*8
v5[0] = 128
v5[1] = 64
v5[2] = 32
v5[3] = 16
v5[4] = 8
v5[5] = 4
v5[6] = 2
v5[7] = 1
byte_405000 = [0x65, 0x08, 0xF7, 0x12, 0xBC, 0xC3, 0xCF, 0xB8, 0x83, 0x7B, 0x02, 0xD5, 0x34, 0xBD, 0x9F, 0x33, 0x77, 0x76, 0xD4, 0xD7, 0xEB, 0x90, 0x89, 0x5E, 0x54, 0x01, 0x7D, 0xF4, 0x11, 0xFF, 0x99, 0x49, 0xAD, 0x57, 0x46, 0x67, 0x2A, 0x9D, 0x7F, 0xD2, 0xE1, 0x21, 0x8B, 0x1D, 0x5A, 0x91, 0x38, 0x94, 0xF9, 0x0C, 0x00, 0xCA, 0xE8, 0xCB, 0x5F, 0x19, 0xF6, 0xF0, 0x3C, 0xDE, 0xDA, 0xEA, 0x9C, 0x14, 0x75, 0xA4, 0x0D, 0x25, 0x58, 0xFC, 0x44, 0x86, 0x05, 0x6B, 0x43, 0x9A, 0x6D, 0xD1, 0x63, 0x98, 0x68, 0x2D, 0x52, 0x3D, 0xDD, 0x88, 0xD6, 0xD0, 0xA2, 0xED, 0xA5, 0x3B, 0x45, 0x3E, 0xF2, 0x22, 0x06, 0xF3, 0x1A, 0xA8, 0x09, 0xDC, 0x7C, 0x4B, 0x5C, 0x1E, 0xA1, 0xB0, 0x71, 0x04, 0xE2, 0x9B, 0xB7, 0x10, 0x4E, 0x16, 0x23, 0x82, 0x56, 0xD8, 0x61, 0xB4, 0x24, 0x7E, 0x87, 0xF8, 0x0A, 0x13, 0xE3, 0xE4, 0xE6, 0x1C, 0x35, 0x2C, 0xB1, 0xEC, 0x93, 0x66, 0x03, 0xA9, 0x95, 0xBB, 0xD3, 0x51, 0x39, 0xE7, 0xC9, 0xCE, 0x29, 0x72, 0x47, 0x6C, 0x70, 0x15, 0xDF, 0xD9, 0x17, 0x74, 0x3F, 0x62, 0xCD, 0x41, 0x07, 0x73, 0x53, 0x85, 0x31, 0x8A, 0x30, 0xAA, 0xAC, 0x2E, 0xA3, 0x50, 0x7A, 0xB5, 0x8E, 0x69, 0x1F, 0x6A, 0x97, 0x55, 0x3A, 0xB2, 0x59, 0xAB, 0xE0, 0x28, 0xC0, 0xB3, 0xBE, 0xCC, 0xC6, 0x2B, 0x5B, 0x92, 0xEE, 0x60, 0x20, 0x84, 0x4D, 0x0F, 0x26, 0x4A, 0x48, 0x0B, 0x36, 0x80, 0x5D, 0x6F, 0x4C, 0xB9, 0x81, 0x96, 0x32, 0xFD, 0x40, 0x8D, 0x27, 0xC1, 0x78, 0x4F, 0x79, 0xC8, 0x0E, 0x8C, 0xE5, 0x9E, 0xAE, 0xBF, 0xEF, 0x42, 0xC5, 0xAF, 0xA0, 0xC2, 0xFA, 0xC7, 0xB6, 0xDB, 0x18, 0xC4, 0xA6, 0xFE, 0xE9, 0xF5, 0x6E, 0x64, 0x2F, 0xF1, 0x1B, 0xFB, 0xBA, 0xA7, 0x37, 0x8F]
enc = [0x65, 0x55, 0x24, 0x36, 0x9D, 0x71, 0xB8, 0xC8, 0x65, 0xFB, 0x87, 0x7F, 0x9A, 0x9C, 0xB1, 0xDF, 0x65, 0x8F, 0x9D, 0x39, 0x8F, 0x11, 0xF6, 0x8E, 0x65, 0x42, 0xDA, 0xB4, 0x8C, 0x39, 0xFB, 0x99, 0x65, 0x48, 0x6A, 0xCA, 0x63, 0xE7, 0xA4, 0x79]
res = []
for i in range(len(enc)):
res.append(byte_405000.index(enc[i]))
Buf2 = [0]*40
for i in range(0, 40, 8):
for j in range(8):
v4 = ((v5[j] & Str[i + 3]) << (8 - (3 - j) % 8)) | ((v5[j] & Str[i + 3]) >> ((3 - j) % 8)) | ((v5[j] & Str[i + 2]) << (8 - (2 - j) % 8)) | ((v5[j] & Str[i + 2]) >> ((2 - j) % 8)) | ((v5[j] & Str[i + 1]) << (8 - (1 - j) % 8)) | ((v5[j] & Str[i + 1]) >> ((1 - j) % 8)) | ((v5[j] & Str[i]) << (8 - -j % 8)) | ((v5[j] & Str[i]) >> (-j % 8))
Buf2[j + i] = byte_405000[(((v5[j] & Str[i + 7]) << (8 - (7 - j) % 8)) | ((v5[j] & Str[i + 7]) >> ((7 - j) % 8)) | ((v5[j] & Str[i + 6]) << (8 - (6 - j) % 8)) | ((v5[j] & Str[i + 6]) >> ((6 - j) % 8)) | ((v5[j] & Str[i + 5]) << (8 - (5 - j) % 8)) | ((v5[j] & Str[i + 5]) >> ((5 - j) % 8)) | ((v5[j] & Str[i + 4]) << (8 - (4 - j) % 8)) | ((v5[j] & Str[i + 4]) >> ((4 - j) % 8)) | v4)]
for i in range(40):
s.add(Buf2[i] == res[i])
if s.check() == sat:
m = s.model()
flag = [m[i].as_long() for i in Str]
print(bytes(flag))
else:
print("Not Found!")







发表评论
您还未登录,请先登录。
登录