

简介
Hybrid Fuzzing 是结合了 Fuzzing 和 Symbolic Execution 的分析技术,能够结合两种技术的优点,同时互补不足。但是在两者的结合中,涌现出一些新的问题。本文对近年来在顶会及相关知名会议中发表的 hybrid fuzzing 论文进行梳理。
背景
Fuzzing
fuzzing 又称模糊测试,是一种轻量级的动态测试方法,通过不停变异输入,输入给测试程序,观察程序运行是否表现异常来检测是否存在漏洞。fuzzing 以其快速高效的效果,成为近年来较为流行的漏洞挖掘技术。
fuzzing 的优点在于快速高效,以 AFL 为代表,AFL 是一种 Coverage-guided fuzzing,追求尽可能的覆盖到多的代码,每当有变异的输入覆盖到新的代码,就将该输入保存下来作为 seed,后续在其之上继续变异。通过这样不停迭代,探索到更多的代码区域。
但由于 fuzzing 的变异通常是随机的,对于一些简单的条件分支语句,因为 fuzzing 的速度够快,能够很快的探索输入空间从而满足条件,但是对于一些复杂的条件语句,fuzzing 需要探索的输入空间巨大,很难在有限的时间内探索到。
Symbolic/Concolic Execution
symbolic execution 符号执行是程序分析技术的一种,通过采用抽象的符号来代替实际执行值,作为程序的输入变量,得到每个路径抽象的符号表达式,最后对符号表达式进行求解,得到一个具体的变量值,该具体值就可以执行该条路径。
这里提到的符号执行是静态的,并不是真实的执行,每分析到一个分支语句,需要构建 true 和 false 两条路径的表达式,故复杂的程序路径数量往往成指数倍的增长,导致路径爆炸 (path exploration) 的问题。
动态符号执行 (Dynamic symbolic execution) 是传统静态符号执行的一种变体,是同时使用符号值和具体值进行执行的一种方法,所以又称为 concolic execution,意为 concrete + symbolic (实际执行 + 符号执行)。concolic 执行会首先产生一些随机输入,用这些输入喂给程序运行,在运行过程中同时符号化的执行程序。因为采用的是具体的输入,所以执行该输入的时候,只会沿着这个输入的路径进行执行,在分支处对条件进行取反,求解得到该路径分支上另一条路径的解,生成新的测试输入,再将新的输入让程序执行,就会得到另一条没有被执行过的路径,如此循环,来完成对所有路径的探索。
所以实际上,concolic 执行采用的是深度优先的搜索策略,每次 concolic 执行会沿着某一个输入的路径,完整执行程序到结束,然后再对路径上没有测试的路径约束条件取反,得到新的输入,再将新输入给程序执行,进入新的路径。
符号执行技术无论是静态还是动态,相对于 fuzzing 来说,开销是很大的,但是其针对复杂的条件语句是非常有效的,能够求解很多仅仅依靠 fuzzing 随机变异策略无法满足的约束条件。
Hybrid fuzzing
hybrid fuzzing 混合模糊测试,实际上就是将 fuzzing 和 concolic execution 结合起来,在 fuzzing 的同时,用 fuzzing 产生的输入给 concolic execution 执行。
由于 fuzzing 的高效,能够快速探索大部分的程序路径,生成大量的输入,当遇到复杂的约束条件时,可以求助于 concolic execution。 concolic execution 可以帮助 fuzzing 求解复杂的约束条件,而 fuzzing 可以为 concolic execution 快速探索程序路径。
Driller
hybrid fuzzing 的概念提出的很早,但2016年的 Driller 是最早将 hybrid fuzzing 应用实际的论文,Driller 本质上是将 AFL 和 angr 简单结合起来,当 AFL 停滞不前的时候,就切换 angr 进行求解,帮助 fuzzing 过复杂的约束。
QSYM
2018年 QSYM 被提出,文章中提到现有的 concolic execution engine 并不是为 hybrid fuzzing 定制的,存在很多性能上的瓶颈,QSYM进行很多优化:
(1) 首先,用动态二进制翻译 (Dynamic Binary Translation) 取代 IR (Inter Representation)来执行,现有的符号执行引擎采用 IR 来执行处于工程上的考量,因为 IR 指令数量少,实现相对容易,但是将二进制程序指令转化为 IR 只能以基本块为单位,但是基本块中的指令并不是全部与输入有关,一些无关指令可以跳过,但是基于 IR 的符号执行无法进行指令级的优化。所以 QSYM 放弃 IR,转而使用DBT,对每条二进制指令进行动态插桩,进行符号执行。
(2) 放弃了符号执行中的快照机制,因为传统的符号执行需要在分支处进行分叉,分为 true 和 false 两个分支,故路径是成指数倍增长,为了避免多条路径重复执行的开销,引入了快照机制,将分支处的状态保存下来,以待后续继续执行。但在 hybrid fuzzing 的场景中,fuzzing 产生的输入完全是随机的,并不一定是有相同的前缀路径,快照对于 hyrbrid fuzzing 中的 concolic engine 来说没有什么用,所以直接放弃快照。
(3) 对求解的优化,有时候符号执行会遇到 over-constraint 问题,此时对收集的部分约束进行求解,即便它不完整,能够解决over-constraint的问题。
(4) 对基本块进行剪枝,记录下已经求解的分支,后续不再求解,并对基本块出现的次数进行检测,如果基本块重复出现多次,则进行剪枝,同时记录基本块出现的上下文,当上下文不同时则会保留,避免过度剪枝。
QSYM 的效果很好,且完全适配 AFL,缺点是只支持 X86 的部分指令。
问题
当然,hybrid fuzzing 也不是那么无敌,也存在很多问题:
(1) 由于 symbolic execution 自身的原因,执行起来很慢,开销很大。
(2) concolic execution 和 fuzzing 的结合,由于 fuzzing 产生输入的速度很快,concolic execution 不可能将这些seed全部执行一遍,所以需要对这些输入进行调度,换句话说,就是对 seed/path 进行排序,决定哪些输入应该先被执行。
(3) 当符号执行构建的约束过于复杂时,求解器也无法对这些约束求解。
(4) 在将hybrid fuzzing 应用到其他领域时,例如 OS kernel 上,需要解决特定的应用问题。
分类
本文提到的论文都是近年来,发表在安全类会议较为知名会议上的 hybrid fuzzing 相关论文。
按照采用的方法和应用做一个简单的分类:
Prioritization/scheduling
- Digfuzz (NDSS 2019)
- Savior (S&P 2020)
- MEUZZ (USENIX RAID 2020)
Improvement of constraint solving
- Intriguer (CCS 2019)
- PANGOLIN (S&P 2020)
Applying to OS kernel
- CAB-Fuzz (Usenix Security 2017)
- HFL (NDSS 2020)
论文解读
DigFuzz
本文认为,现有的 hybrid fuzz 存在两种策略:
(1) 一种是 demand launch,即按照需要,在 fuzzing 过程停滞不前时,采用 concolic execution 帮助求解分支条件。这种方式比较笨拙,当 fuzzing 进行的过程中的时间被浪费了。
(2) 还有一种是 optimal switch,即对一条路径用 fuzzing 探索和用 concolic execution 进行探索的代价进行评估,用代价最小的方式。但是评估 concolic execution 的开销需要收集路径约束,这个代价本身就很大了。
所以本文提出一种 discriminative dispatch 的策略,用一种代价较小的方法评估每条路径的难度,按照探索难度对路径进行排序,将难度最大的路径留给 concolic execution 进行探索。
这里的难点在于,如何用一种轻量级的方法评估一条路径的探索难度,DigFuzz 提出基于蒙特卡洛的路径概率排序模型 (Monte Carlo Based Probabilistic Path Prioritization Model, MCP3),在 fuzzing 的过程中,用 seed 的 trace 构建执行路径树,用覆盖率计算每个分支的概率,路径的概率为路径上分支的概率相乘,最后基于路径的概率对路径进行排序,概率越小代表路径越难探索,将最难探索的路径优先给 concolic execution 进行探索。
Savior
本文认为,现有的 coverage-guided hybrid fuzzing 忽略了对漏洞的检测问题:
(1) 存在漏洞的代码是少数,所以以coverage为导向引导不是最佳策略
(2) 即便能够到达存在漏洞的代码位置,很多漏洞因为没有满足特定的数据条件,也未必能触发漏洞。
Savior 认为应该以 bug 为导向,针对上述两个问题,Savior 采用两个方法来解决:
(1) bug-driven prioritization:采用静态分析得到每个分支可以到达的基本块数量,动态分析得到 seed 执行路径上未探索分支,综合可以得到这些未探索分支可以到达的基本块数量。利用 UBSan (Undefined Behavior Sanitizer) 在每个基本块上标记的数量来表示存在漏洞的可能性大小,综合上述 metric 用于对 seed 进行排序。
(2) bug-guided verification:提取执行路径上的 UBSan label,并对这些 label 中的 predicate 进行验证,即用 concolic execution 为这些 label 生成约束并求解,验证 label 中的 predicate 是否满足。
虽然 Savior 的 key idea 是 bug-driven hyrbrid fuzzing,实际上也是对 seed 做了一个排序,只是这个排序是基于 UBsan 和 trace 中到达基本块数量做的。
MEUZZ
本文一作和 Savior 是同一人,所以思路也是相似的,也是对 seed 做一个排序调度,只不过本文是基于机器学习的方法做的。
本文认为,seed selection 在 hybrid fuzzing 中有很重要的作用,因为 fuzzing 速度远大于 concolic,由于时间和资源有限,concolic execution 只能执行部分的 seed,故需要对 seed 进行调度排序。
而现有的工作对 seed 的挑选都是基于一些启发式规则,这些规则并不能完全适用于所有程序。基于学习的方法是最适合于不同的程序的,可以根据程序的执行情况进行学习,从而调整 seed selection 策略。
所以 MEUZZ 提出基于机器学习的方法来进行 seed selection。首先是对程序和 seed 进行特征提取,然后对 concolic engine 产生的每个 seed 构建一个后代树,记录在 fuzz 过程中,从该 seed 产生的后代 seed,将这棵树的大小,即 node 数量作为 seed 的 label,在 hybrid fuzzing 过程中不断更新模型,挑选 seed。
Intriguer
问题
本文认为,hybrid fuzzing 中还存在一些问题可以改进:
(1) 符号模拟非常慢
(2) 一些不必要的求解占据了大多数的时间
(3) 资源被过度分配
(4) 一些难触发的漏洞被忽略了
下面具体来说明一下这些问题:
符号模拟执行慢
根据本文调研,发现程序中大部分的数据转移指令,例如 mov 一类的指令,在程序中占比很大,但是这些指令没有符号模拟的必要,因为只需要对 mov 指令的前后两条指令的数据的值进行比较,就可以知道数据的转移位置。
所以,如果可以避免这些 mov 类的指令执行,可以大大缩短符号模拟的时间。
不必要的求解
程序中存在一些复杂的函数,例如 hash 函数,加密解密函数,压缩函数等等,这些函数操作非常复杂,涉及的输入很多,且容易产生无法求解的约束,减少对这些约束的求解,避免多数时间浪费在这些不必要的求解上。
资源过度分配
concolic execution 相比 fuzzing,求解能力强很多,类似 magic byte 这样程序中常见的约束很容易解掉,但是本文认为,类似于x == 0xdeadbeef,以及x > 0 ^ x < 1000这样的约束,都不是真正复杂的约束,应该将 solver 用在真正复杂难解的约束上。
难以触发的bug
这一点与 Savior 的说法一致,因为有些漏洞的触发需要控制流条件和数据条件同时满足才能触发,hyrbrid fuzzing 只能帮助到达代码位置,而数据条件的满足需要额外的操作。
Field-level constraint solving
所以本文提出了一种利用 field 信息,简化求解和执行的方法。利用 taint 追踪输入在程序中的数据流信息,包括数据对应在输入的 offset以及数据的 value。
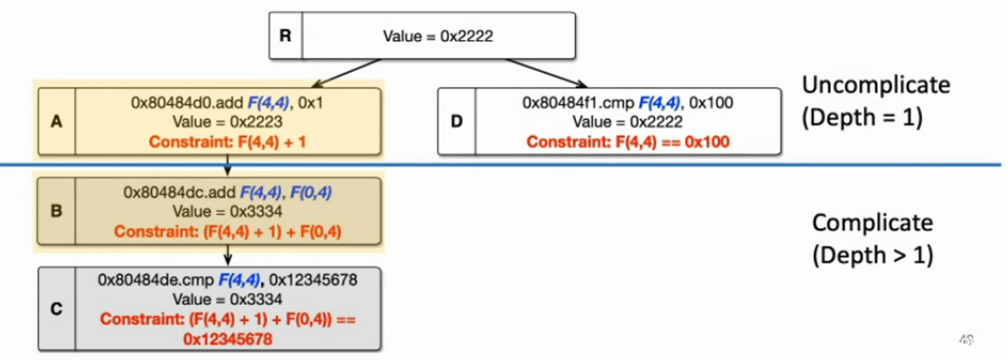
以一个简单的C代码为例:

假设a来自于输入的{0x0, 0x1, 0x2, 0x3},b来自输入的{0x4, 0x5, 0x6, 0x7},最后需要对第5行的约束a+c == 0x12345678进行求解。
将这段代码的汇编指令如下:

本文的方法则如下:

假设此时a=0x1111,b=0x2222,根据 taint,我们可以知道第1条mov 指令的操作数是b,值为0x2222,以及来自于输入的 offset是 {0x4, 0x5, 0x6, 0x7},这时候无需对第一条 mov 指令进行符号模拟,直接执行第2条指令add eax, 0x1
此时我们知道 eax 中是变量 b,直接构建约束b + 1,并且知道结果为 0x2223,中间的 mov 指令即便不进行符号模拟,直接到第6条指令add eax, edx,此时根据 value 和 offset,我们可以直接构建约束 (b+1)+a。
最后在 cmp 指令处,对约束 (b+1)+1 = 0x12345678进行求解即可。
由此可以看出,中间的 mov 指令不需要符号模拟,不影响最后的约束构建和求解。

在执行过程中,会将指令的 field 和 value 都记录下来,针对同一个输入,构建出 field transition tree,针对这棵树来构建约束

为了求解效果最大化,根据树的节点深度进行划分,只有深度大于1的节点被认为是复杂约束,将 solver 仅用于复杂约束的求解。同时仿照 Savior 的做法,在一些算数指令上插入一些边界检查的约束,例如F+100 > INT_MAX、F-100 < 0等
Pangolin
本文解决的是 hybrid fuzzing 中,计算冗余的问题。
一条路径可能会有多个分支,假设已经对该路径的第一个分支进行了求解,需要对下一个分支进行探索,此时,第一个分支的解信息其实可以帮助我们缩小后续分支的搜索空间,降低后续分支的求解难度。
以图为例,假设第3行的约束已经被求解,得到解空间为x=3, y=4, 0<z<200,这个信息可以在两个方面帮助我们探索第4行的分支:
- 将 fuzzing 过程中,对Z的变异从整个正整数空间缩小到(0, 200)
- 将 concolic execution 中,第4行分支的约束从
z*z<40000 ^ z>195简化为0<z<200 ^ z>195

本文的 key idea 就是保留和重用路径上一个阶段的解空间,本文称为:多边形路径摘要 (polyhedral path abstraction),这些路径摘要是与目标路径约束相关的输入变量的边界范围。
首先需要推断出路径摘要,文章提出一种方法,可以将路径约束简化为一组线性不等式,这个不等式是近似但不完全等于路径约束,是包含的关系,保证不等式的范围完全覆盖路径约束的数据范围。
然后引导 fuzzing 变异,保证变异的范围在路径摘要的范围内,且满足均匀分布。同时能够加快求解的速度,主要是能快速验证约束是否可解,因为简化后的不等式组都是线性的,如果简化后的不等式组都不可解,说明真正的路径约束更加不可能求解,直接剪枝。
CAB-Fuzz
本文是对闭源 OS 进行的一个 concolic execution 工作,其实不能算是 hybrid fuzzing。CAB-Fuzz 的取名意为Context-Aware and Boundary-focused。其次值得一提的是,本文的作者中有 QSYM 的作者Insu Yun。
对闭源 OS 进行符号执行,常见的挑战就是状态爆炸问题,而且对于闭源的 OS,缺少文档和配套的 test suites,很难构建一个合适 pre-context。
本文实际上是绕过了这两个问题:
(1) 因为状态太多,本文就集中于边界的值上,文章观察到,边界值是最容易出问题的地方,特别是循环的边界和数组的边界,所以在循环时取0次、1次、最大次的值进行符号执行,数组的值取最低地址和最高地址的值进行符号执行。
(2)至于如何构建context,文章直接采用 real world program 执行,在执行后自然构建 context 以后,再进行 on-the-fly concolic execution,绕过了这个问题。
HFL
本文是对 Linux kernel 的一个 hybrid fuzzing 工具,面临的 challenge 主要是以下几点 kernel 特定的问题:
(1) 由 syscall 参数决定的间接控制流跳转
(2) syscall 决定的系统内部状态
(3) syscall 调用时需要推断嵌套参数类型
现有的 hybrid fuzzing 要么是没有解决这些问题,要么是用静态分析不准确的部分解决这些问题。
本文针对以上问题的解决方法如下:
(1) 在编译时将原有的间接控制流跳转转为直接的跳转,例如图

(2) 对 syscall 的调用顺序进行推断,首先进行静态的指针分析,收集所有对相同地址进行读写的指令对,作为 candidate pair,然后在运行时对 candidate pair 进行进一步验证,符号执行时是否确实是对相同地址的读写。最后对这些指令操作的数据进行追踪,相关的函数就是存在调用顺序依赖的关系。
(3) 最后是识别嵌套的参数类型,具体是先对一些 transfer 函数进行监控,通过内存位置和内存 buffer 的长度来进行判断嵌套的参数类型。
参考文献
[1] Driller: Augmenting Fuzzing Through Selective Symbolic Execution
[2] QSYM: A Practical Concolic Execution Engine Tailored for Hybrid Fuzzing
[3] Send Hardest Problems My Way: Probabilistic Path Prioritization for Hybrid Fuzzing
[4] SAVIOR: Towards Bug-Driven Hybrid Testing
[5] MEUZZ: Smart Seed Scheduling for Hybrid Fuzzing
[6] Intriguer: Field-Level Constraint Solving for Hybrid Fuzzing
[7] Pangolin: Incremental Hybrid Fuzzing with Polyhedral Path Abstraction
[8] CAB-FUZZ: Practical Concolic Testing Techniques for COTS Operating Systems
[9] HFL: Hybrid Fuzzing on the Linux Kernel







发表评论
您还未登录,请先登录。
登录