

作者:houjingyi
编译与反编译相关的知识是比较枯燥的,本文试图结合对androguard(https://github.com/androguard/androguard)的内置dad反编译器来进行讲解。那么学习这一部分知识有什么用处呢?就拿android应用来说,VMP/java2c等等加固混淆的实现和对抗都和编译与反编译的原理息息相关,理解这一部分的知识无论是对于正向开发还是逆向分析都是有很大帮助的。比如github上开源的一个java2c方案dcc(https://github.com/amimo/dcc)也用了dad的代码。java2c可以理解成是一个比较特殊的编译的过程,正常情况是把java代码编译成字节码交给虚拟机解释执行,java2c是把java代码”编译”成c代码。本文首先会介绍一些编译与反编译相关的基本理论,然后会让读者大致了解一下androguard,最后会对androguard的内置dad反编译器中的一些关键的代码进行讲解。
基本理论
支配(dominates):若从进入程式块到达基本块N的所有路径,都会在到达基本块N之前先到达基本块M,则基本块M是基本块N的支配点。由支配点构成的树就是支配树。
前进边(advancing edge):是指向的基本块是在图的深度优先搜索中没有走过的基本块。
倒退边(back edge):是指向的基本块是在图的深度优先搜索中已经走过的基本块。倒退边多半表示有循环。
区间图(interval graph):是指给定一个节点h,其区间图是h为入口节点,并且其中所有闭合路径都包含h的最大的单入口子图。h被称为区间头节点或简称头节点。
对于一个CFG,可以把它区间图称为一阶图。二阶图将每个区间图作为一个节点,以此类推。如果最终能够把CFG转化为单个节点,就称该CFG是可规约的(reducible)。
拓扑排序(topological sorting):拓扑排序是一个有向无环图的所有顶点的线性序列。且该序列必须满足下面两个条件:
- 每个顶点出现且只出现一次。
- 若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
前序/后序/逆后序:
深度优先搜索在遍历图的过程中,可以记录如下顺序:
前序:即在递归调用之前将顶点加入队列,代表深度优先搜索访问顶点的顺序。
后序:即在递归调用之后将顶点加入队列,代表深度优先搜索顶点遍历完成的顺序。
逆后序:即在递归调用之后将顶点压入栈,代表着顶点的拓扑排序。
androguard简介
本文分析的androguard源代码版本为3.3.5。
decompiler:提供反编译功能,主要有两种方式实现,一种是使用jadx,一种是使用内置的名为dad的反编译器,(还有一些其他的第三方反编译器均已废弃)。decompiler/dad目录即为dad反编译器的实现了。
我们运行一下decompile.py试试,apk就直接用提供的测试apk:androguard-3.3.5/examples/android/TestsAndroguard/bin/TestActivity.apk。
% python3 decompile.py
INFO: ========================
INFO: Classes:
......
INFO: Ltests/androguard/TestActivity;
......
INFO: ========================
Choose a class (* for all classes): TestActivity
INFO: ======================
......
INFO: 9: foo
......
INFO: ======================
Method (* for all methods): 9
INFO: Source:
INFO: ===========================
package tests.androguard;
public class TestActivity extends android.app.Activity {
private static final int test2 = 20;
public int[] tab;
private int test;
public int test3;
public int value;
public int value2;
public int foo(int p3, int p4)
{
int v0 = p4;
while(true) {
int v4_1;
if (p3 < v0) {
v4_1 = (v0 + 1);
try {
p3 = (v0 / p3);
v0 = v4_1;
} catch (RuntimeException v1) {
p3 = 10;
}
} else {
if (p3 == 0) {
break;
}
v4_1 = v0;
}
v0 = v4_1;
}
return v0;
}
}
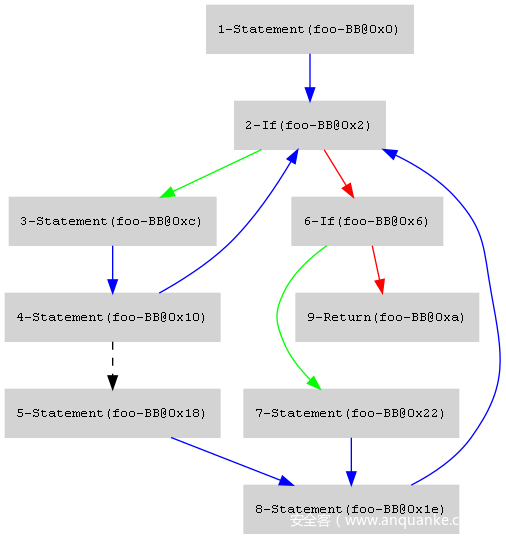
同时在/tmp/dad/blocks,/tmp/dad/pre-structured和/tmp/dad/structured可以看到生成的CFG图。非条件节点的边是蓝色的,条件节点为true的边是绿色的,条件节点为false的边是红色的。try catch的边是黑色的虚线。
/tmp/dad/pre-structured:
/tmp/dad/structured:
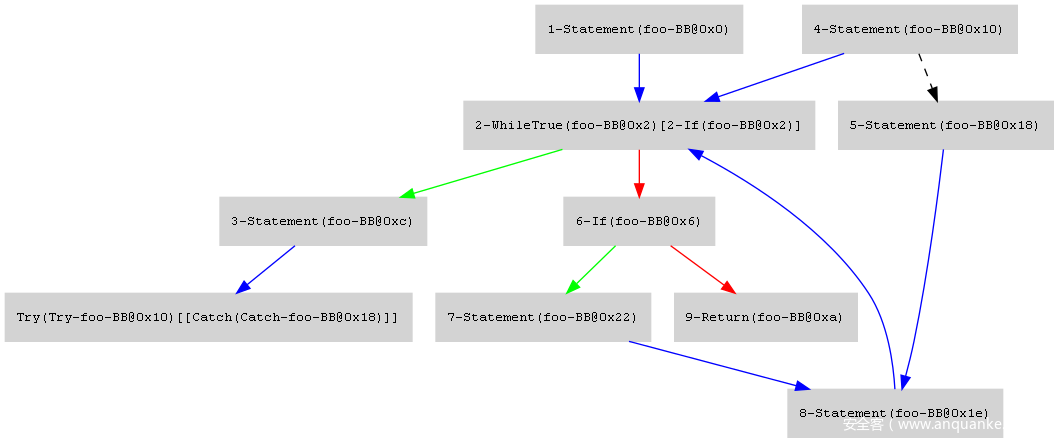
这一部分之后还会详细解释,下面对dad目录下的文件做个简介。
源码分析
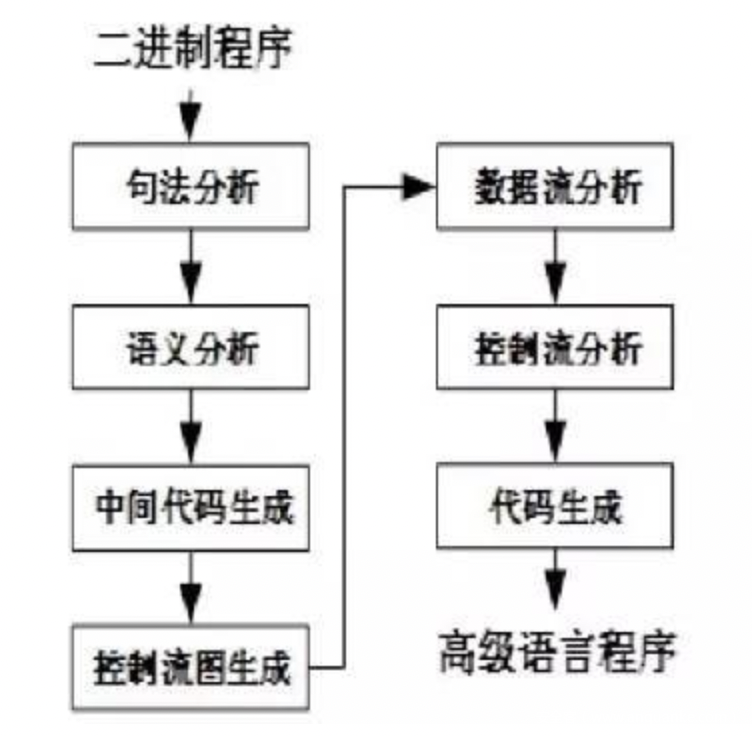
网上找的一张图。按照反编译技术实施的顺序划分,则可以分为7个阶段,它们是:句法分析、语义分析、中间代码生成、控制流图生成、控制流分析、代码生成。
当我们运行decompile.py的时候调用了DvMachine处理提供的apk(dex/odex)文件,通过androguard/core/analysis/analysis.py中的Analysis类对其进行分析。对于每个class通过ClassAnalysis进行分析;对于每个method通过MethodAnalysis进行分析。
self.vms.append(vm)
for current_class in vm.get_classes():
self.classes[current_class.get_name()] = ClassAnalysis(current_class)
for method in vm.get_methods():
self.methods[method] = MethodAnalysis(vm, method)
在MethodAnalysis中,h表示分支指令和对应的目的地址,l表示所有的目的地址,例如对于下面这个method:
(0),v1, +5,length:4,if-lez
(4),v0, v1, 2,length:4,mul-int/lit8
(8),v0,length:2,return
(10) v0, v1, 2,length:4,add-int/lit8
(14) -3,length:2,goto
h:
{0: [4, 10], 8: [-1], 14: [8]}
l:
[4, 10, -1, 8]
所有的分支指令:
throw
throw.
if.
goto
goto.
return
return.
packed-switch$
sparse-switch$
据此创建DVMBasicBlock并通过BasicBlocks列表进行管理,接下来主要的处理是在process函数中。
下面就重点讲一下process函数中涉及到的控制流图生成(graph.py),数据流分析(dataflow.py)和控制流分析(control_flow.py)。
opcode_ins.py
所有的opcode。
instruction.py
表示opcode的类,对应于上图中的中间代码生成,比如if-eq,if-ne等等这些opcode都用ConditionalExpression类表示。
writer.py
输出源代码。
dast.py
输出AST。
basic_blocks.py
提供build_node_from_block函数,根据提供的block的最后一条指令返回对应的block类型。返回的类型包括:
ReturnBlock,SwitchBlock,CondBlock,ThrowBlock和StatementBlock。
graph.py
得到CFG的逆后序。
得到CFG的后序。
将CondBlock拆分为StatementBlock和新的CondBlock,StatementBlock是头节点,新的CondBlock仅由跳转条件组成。
通过合并/删除StatementBlock来简化CFG:如果StatementBlock B跟在StatementBlock A后面,并且StatementBlock B除了StatementBlock A没有其它的前任节点,那么我们可以将A和B合并成一个新的StatementBlock。
还删除除了重定向控制流之外什么都不做的节点(只包含goto的节点)。
dom_lt函数/immediate_dominators函数
通过Lengauer-Tarjan算法构造支配树。dom[i]表示支配i的节点。
广度优先搜索。
通过block(DVMBasicBlock)得到node(basic_blocks.py中定义的block类型)。
首先检查该block是否有对应的node,没有就创建出来。
如果说这是一个try block,则把catch node也创建出来,加到catch_edges(try node,即CFG中黑色虚线箭尾)和reverse_catch_edges(catch node,即CFG中黑色虚线箭头)。
对于该block的所有child如果没有对应的node就创建出来,添加该node到child node的edge。如果这个node是SwitchBlock,则将child node添加到node的cases中;如果这个node是CondBlock,则将node的true或false设置为child node。
构造CFG。
调用bfs函数得到DVMBasicBlock序列,对于每个DVMBasicBlock调用make_node函数然后加到图中,设置graph的entry和exit。
control_flow.py
控制流分析。
给定一个控制流图,计算该图区间图(interval graph)的集合。
对于最前面运行decompile.py举的例子,如果大家去看/tmp/dad/pre-structured中生成的CFG图,该图有两个区间图,一个是1-Statement(foo-BB@0x0)这一个节点组成的区间图,另外一个就是其他节点组成的区间图。
算法:
将图的入口加入头节点列表,遍历所有头节点:取出头节点并标记,将其加入一个区间图,如果存在一个节点,其所有前驱节点都在当前区间图中就将该节点加入当前区间图,重复直到所有可能的节点都被加入当前区间图; 此时如果存在一个节点不在区间图中但是它的一个前驱节点在区间图中,那么这个节点就是另一个区间图的头节点,将该节点加入头节点列表,重复直到所有可能的节点都被加入头节点列表。
计算CFG的导出序列,也就是如把CFG最终转化为单个节点。返回两个参数,第一个参数Gi是区间图的列表,第二个参数Li是区间图的头节点的列表。Gi[0]是原始图,Gi[1]是一阶图,Gi[x]是x阶图;Li[0]是一阶图的头节点,Li[1]是二阶图的头节点,Li[x]是x+1阶图的头节点。
返回循环的类型:
Pre-test Loop:检查条件后才执行循环;
Post-test Loop:先执行循环再检查条件;
End-less Loop:无限循环。
标记x.follow['loop'] = y,表示x这个循环节点结束之后应该是y节点。
识别循环。遍历derived_sequence函数返回的两个列表,如果对于一个头节点,有一个它的前驱节点和它位于同一个区间图,那么就标记一个循环。
比如对于下面的代码:
public void testWhile() {
int i = 5;
int j = 10;
while (i < j) {
j = (int) (((double) j) + (((double) i) / 2.0d) + ((double) j));
i += i * 2;
}
f13i = i;
f14j = j;
}
derived_sequence函数返回的结果:
Gi[0]:(原始图)
[
1-Statement(testWhile-BB@0x0),
2-If(testWhile-BB@0x6),
4-Statement(testWhile-BB@0xa),
3-Return(testWhile-BB@0x24)
]
Gi[1]:(一阶图)
[
Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}),
Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)})
]
Li[0]:(一阶图的头节点)
{
1-Statement(testWhile-BB@0x0): Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}),
2-If(testWhile-BB@0x6): Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)})
}
Li[1]:(二阶图的头节点)
{
Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)}): Interval-Interval-testWhile-BB@0x0({Interval-testWhile-BB@0x6({2-If(testWhile-BB@0x6), 3-Return(testWhile-BB@0x24), 4-Statement(testWhile-BB@0xa)}), Interval-testWhile-BB@0x0({1-Statement(testWhile-BB@0x0)})})
}
遍历Li[0],BB@0x0没有前驱节点;BB@0x6的第一个前驱节点BB@0x0和它不在同一个区间图中;第二个前驱节点BB@0xa和它在同一个区间图中(BB@0x6为头节点,包含节点BB@0x6,BB@0x24,BB@0xa的区间图),所以标记一个循环。
标记x.follow['if'] = y,表示x这个if{…}else{…}结束之后应该是y节点。
标记x.follow['switch'] = y,表示x这个switch结束之后应该是y节点。
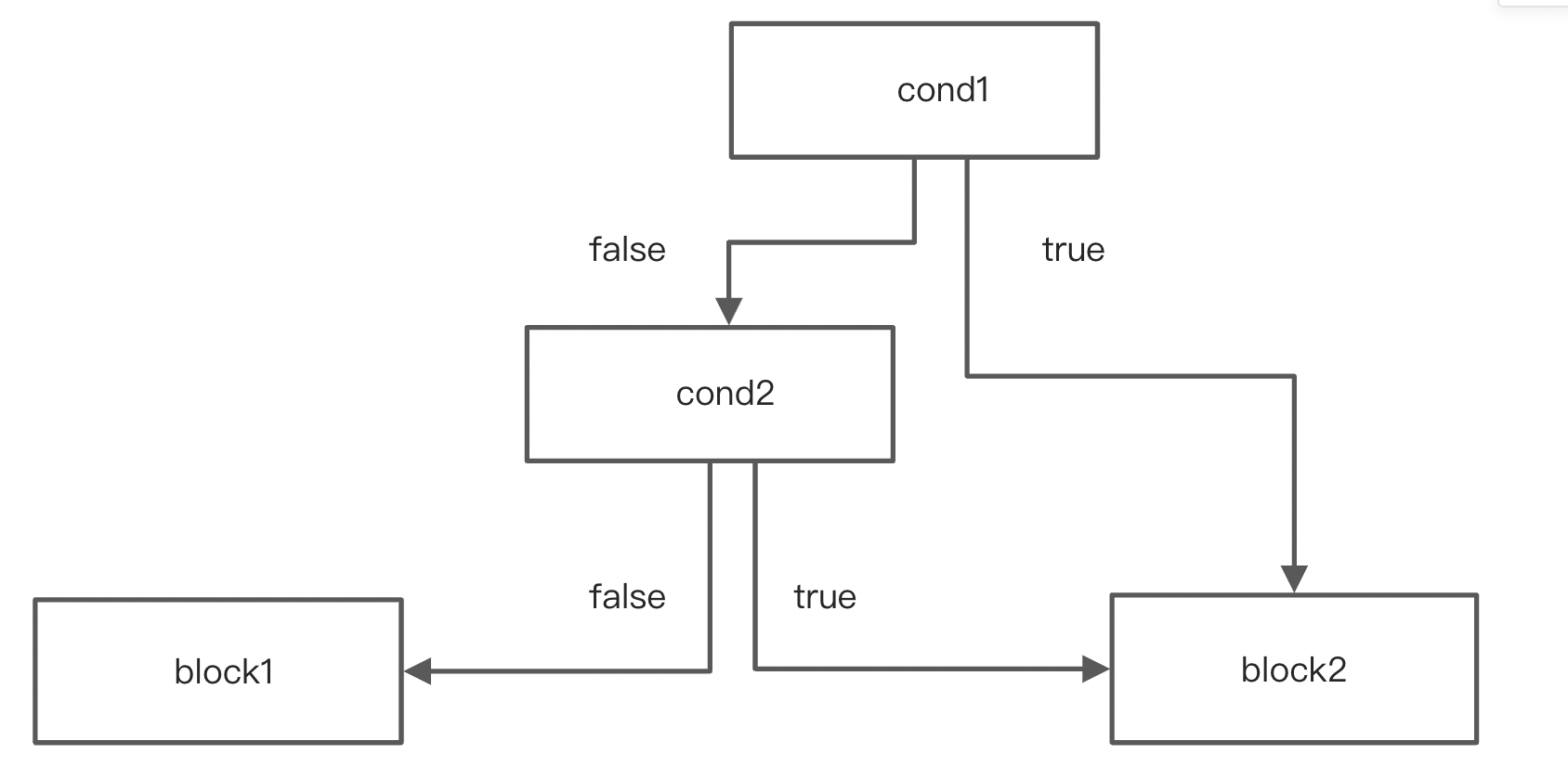
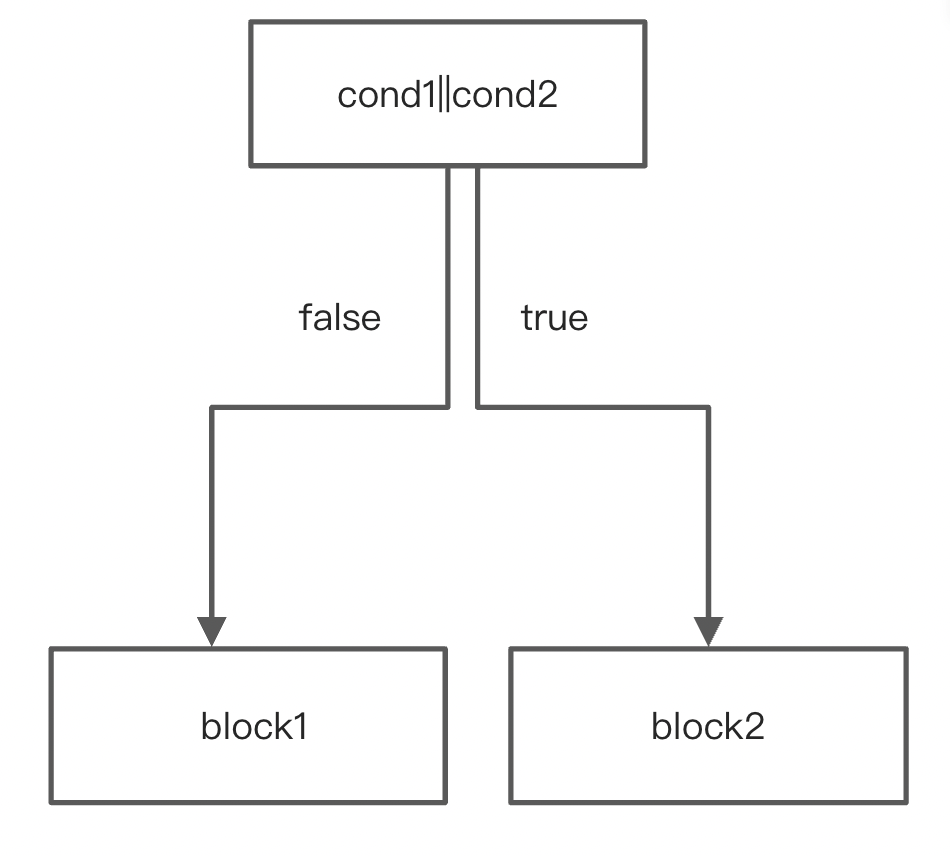
短路求值,将两个CondBlock合并成一个。总共四种情况。
第一种情况合并前后:
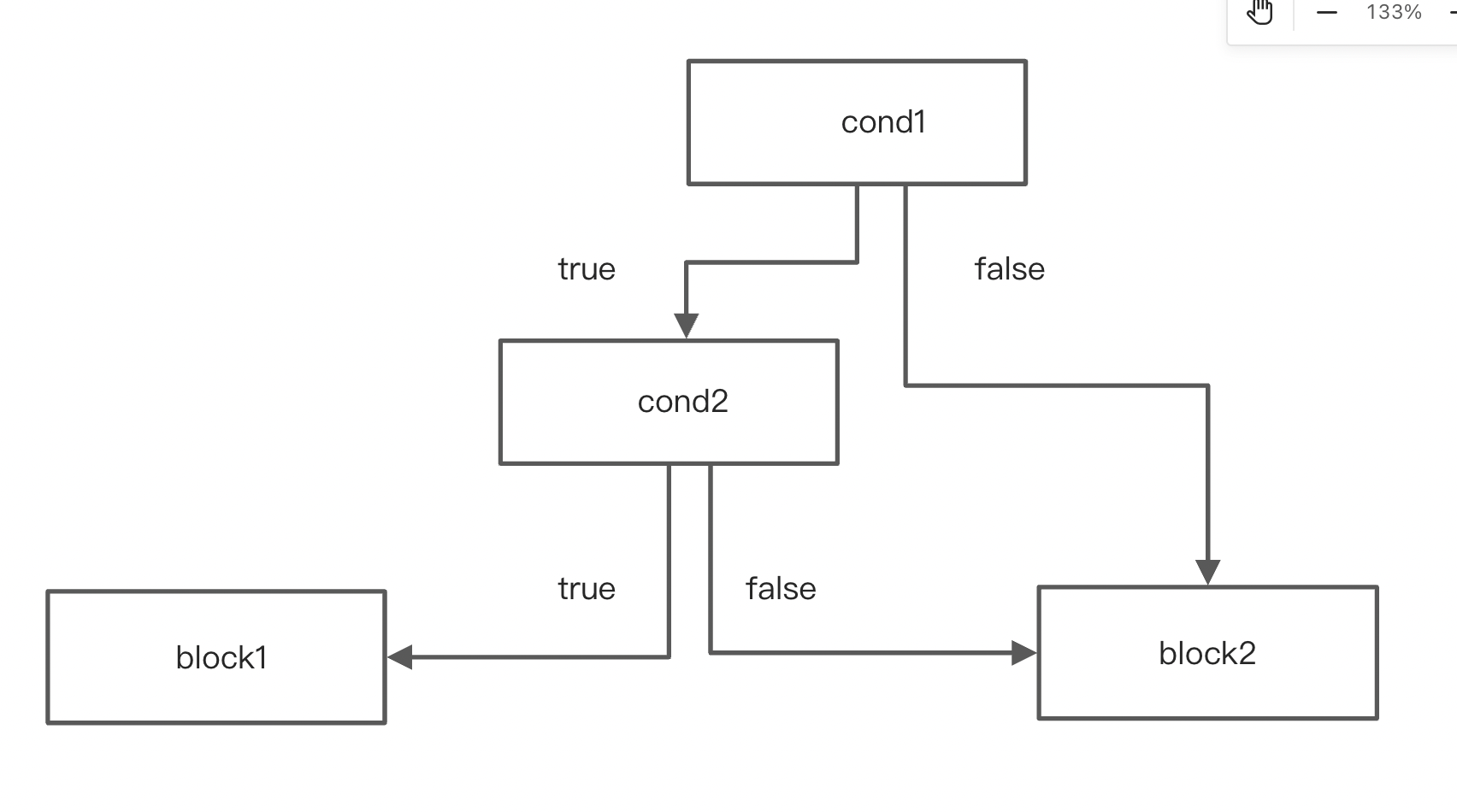
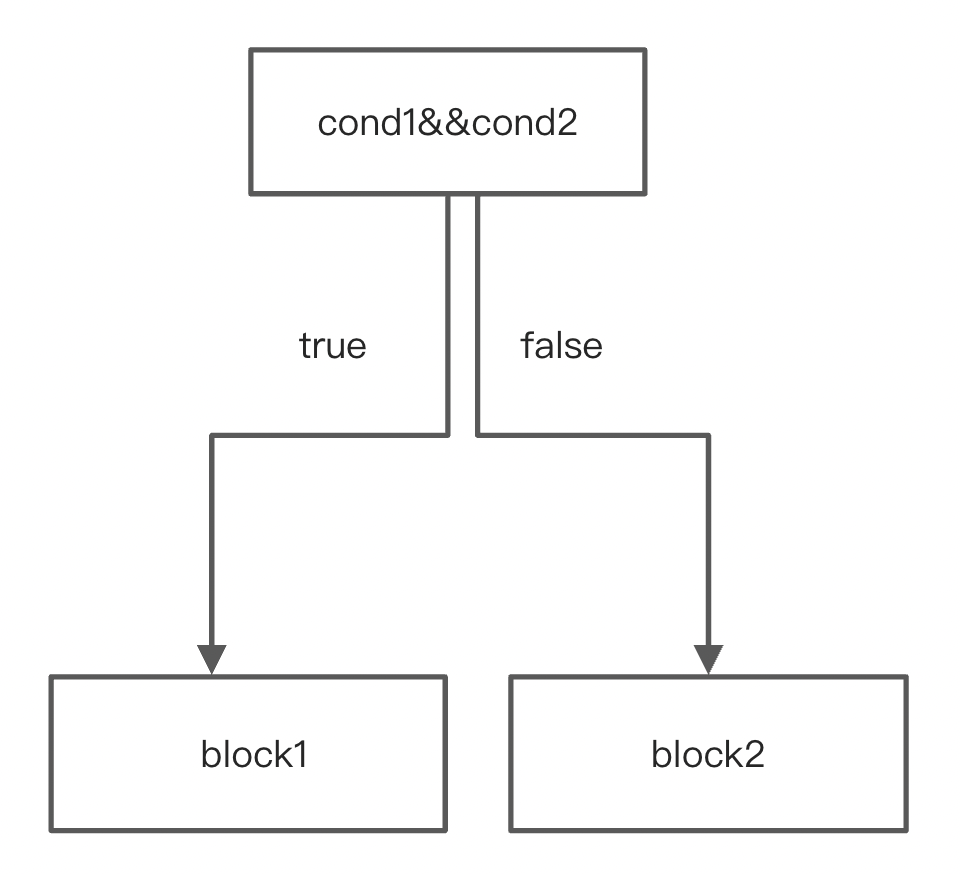
第二种情况合并前后:
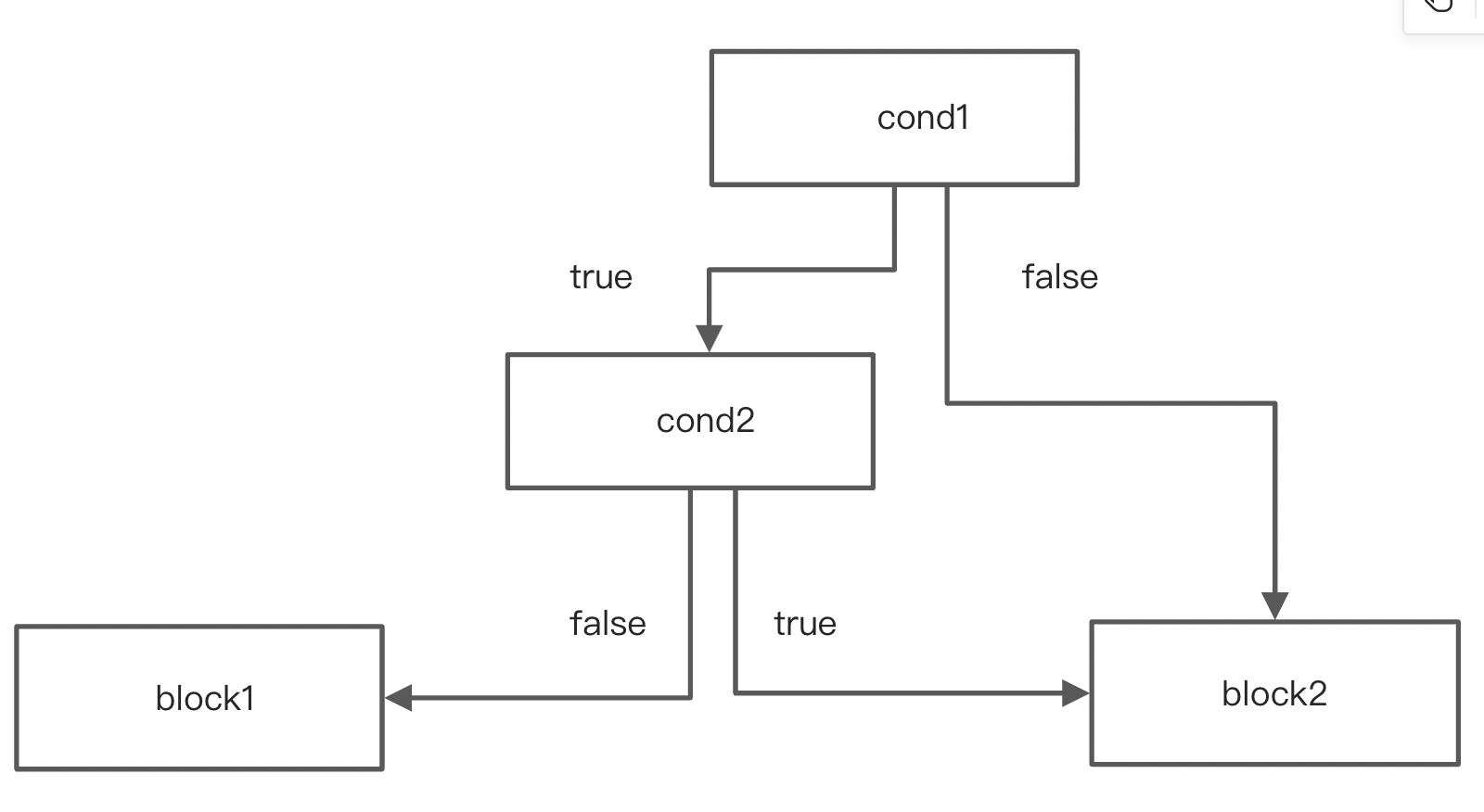
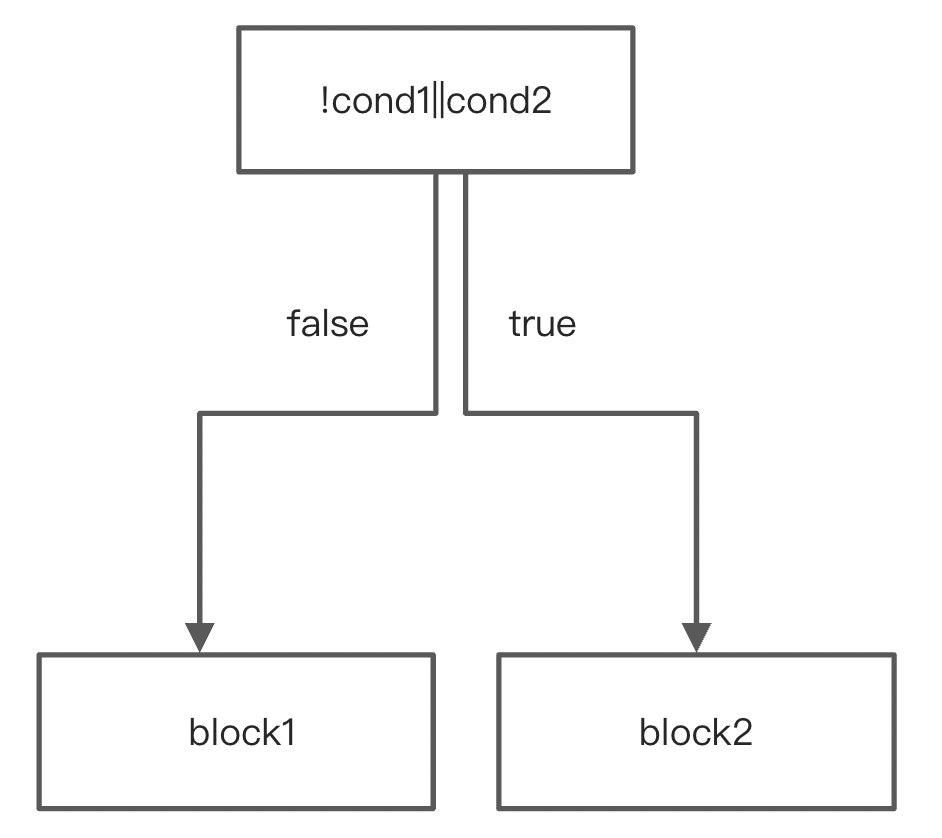
第三种情况合并前后:
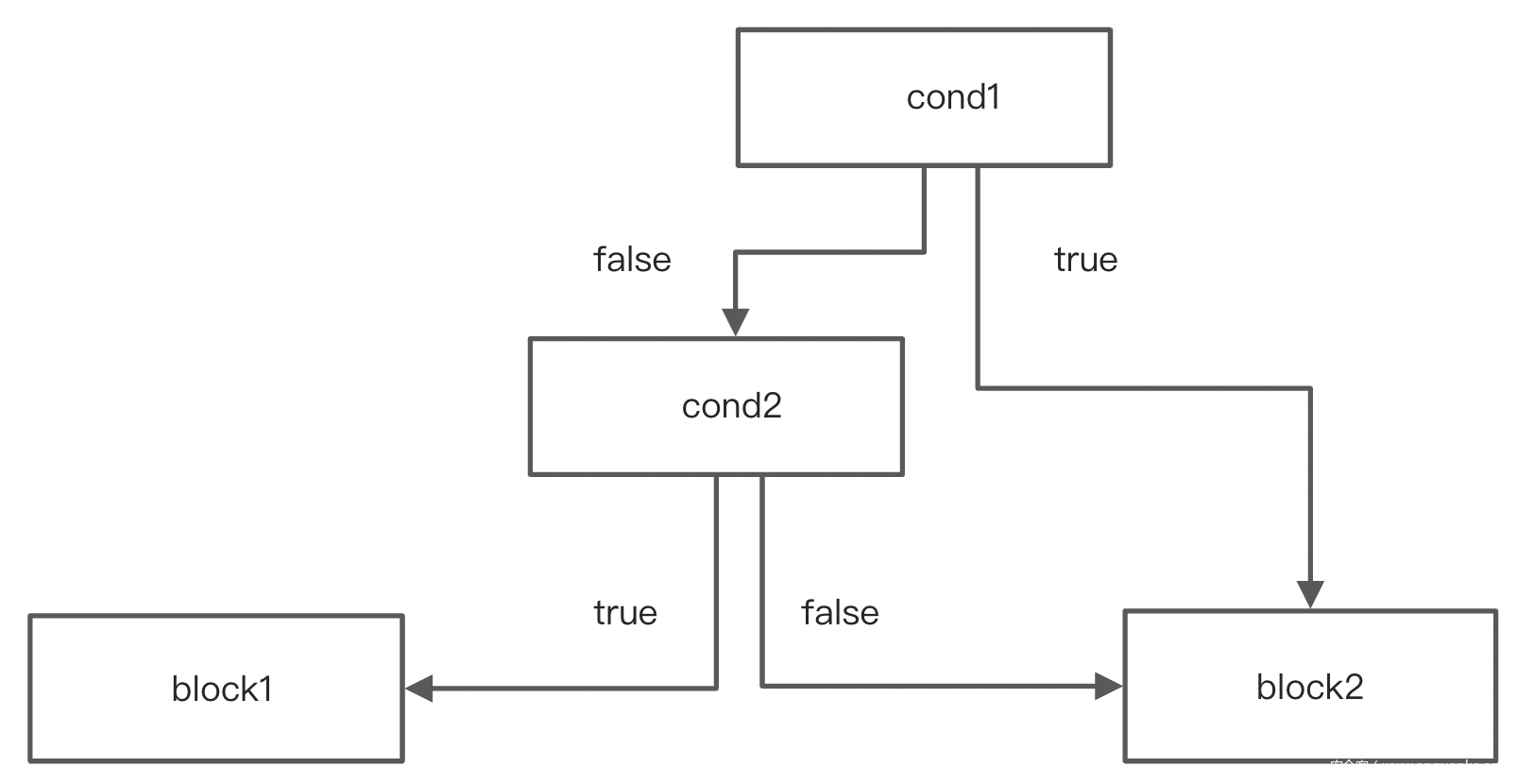
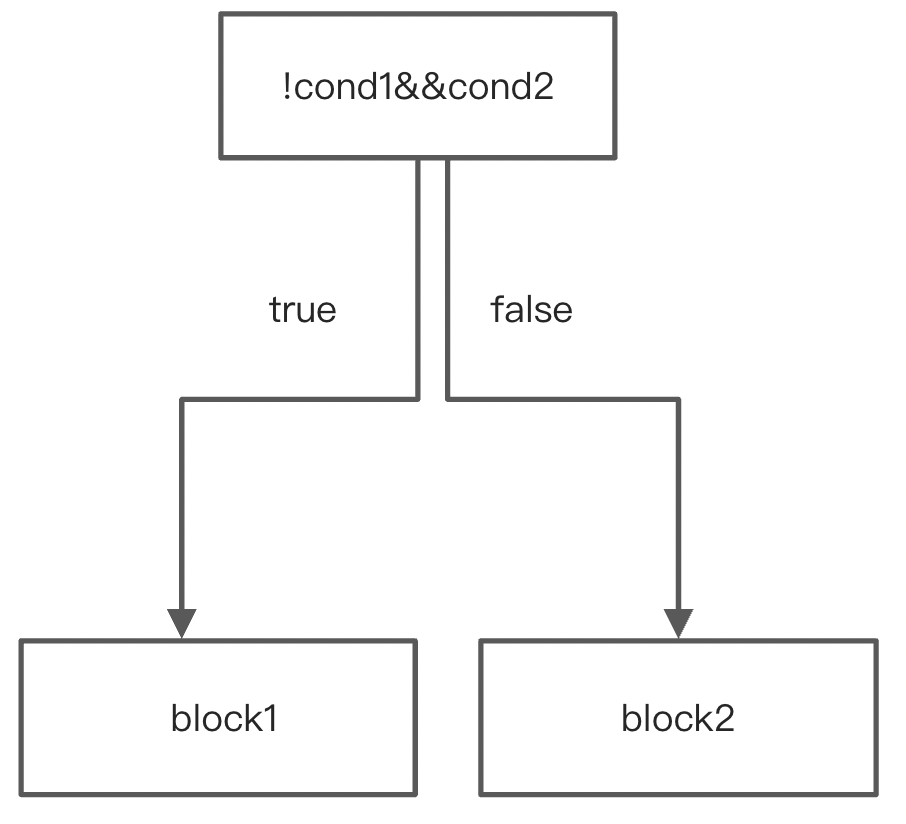
第四种情况合并前后:
实际例子:
public static int testShortCircuit4(int p, int i) {
if ((p <= 0 || i == 0) && (p == i * 2 || i == p / 3)) {
return -p;
}
return p + 1;
}
pre-structured:
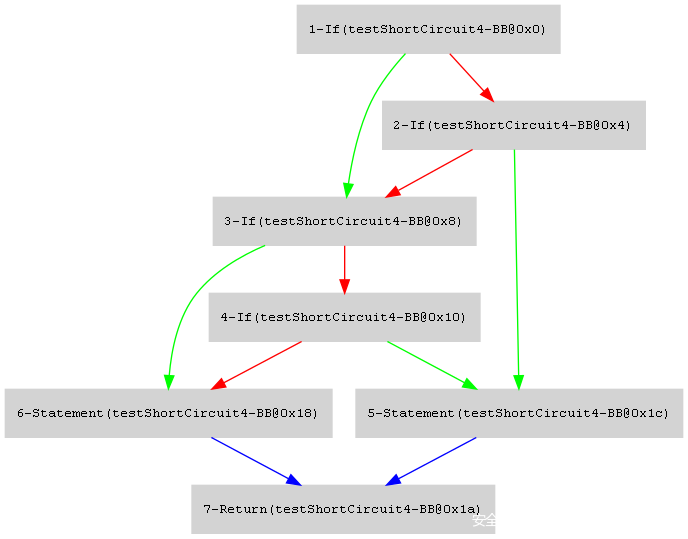
structured:

根据loop_struct函数识别出的循环添加一个LoopBlock类型的node并删除原来的node。
通过reverse_catch_edges遍历所有catch块,支配其的节点即为对应的try块,据此新建CatchBlock和TryBlock,加入图中并更新图。
更新支配树。
主要就是调用前面提到的这些函数识别出一些结构。
dataflow.py
数据流分析。一些基本知识可以参考下面这几篇文章。
实际例子:
public int test1(int val) {
return (val + 16) - (this.value * 60);
}
get_loc_with_ins返回的loc和ins:
0 ASSIGN(VAR_0, CST_16)
1 ASSIGN(VAR_1, (+ PARAM_4 VAR_0))
get_used_vars:0,4
2 ASSIGN(VAR_2, THIS.value)
get_used_vars:3
3 ASSIGN(VAR_2, (* VAR_2 CST_60))
get_used_vars:2
4 ASSIGN(VAR_1, (- VAR_1 VAR_2))
get_used_vars:1,2
5 RETURN(VAR_1)
寄存器传播。
对于上面的例子构建的DU和UD链:
use_defs:
(x, y):[z]表示第y行的var x是在第z行定义的
{ (0, 1): [0], (4, 1): [-2], (3, 2): [-1], (2, 3): [2], (1, 4): [1], (2, 4): [3], (1, 5): [4] }
def_uses:
(x, y):[z]表示第y行定义的var x在第z行使用
{ (0, 0): [1], (4, -2): [1], (3, -1): [2], (2, 2): [3], (1, 1): [4], (2, 3): [4], (1, 4): [5]} )
-1表示第一个参数,-2表示第二个参数。
静态单赋值SSA,通过分割变量使得每个变量仅有唯一的赋值。
对于上面的例子split_variables之后的DU和UD链:
use_defs:
{ (0, 1): [0], (4, 1): [-2], (3, 2): [-1], (5, 4): [1], (6, 5): [4], (7, 3): [2], (8, 4): [3] }
def_uses:
{ (0, 0): [1], (4, -2): [1], (3, -1): [2], (5, 1): [4], (6, 4): [5], (7, 2): [3], (8, 3): [4]} )
清除死代码并更新DU和UD链。







发表评论
您还未登录,请先登录。
登录