
前言:
近年来,云原生架构被广泛的部署和使用,业务容器化部署的比例逐年提高,对于突发重大漏洞等0day安全事件,往往给安全的应急带来重大的挑战。例如前段时间广受影响的重大漏洞的爆发,可以说是云原生架构下安全建设和安全运营面临的一次大考。
本文将以该高危任意代码执行漏洞作为案例,分享云原生架构下的安全建设和安全运营的思考。
漏洞处置回顾
漏洞爆发后,第一时间关注的一定是攻击者能否利用漏洞攻击业务系统,可以通过哪些方式实施攻击。对于容器环境,从攻击视角来看,通常可以有以下几种入侵途径。
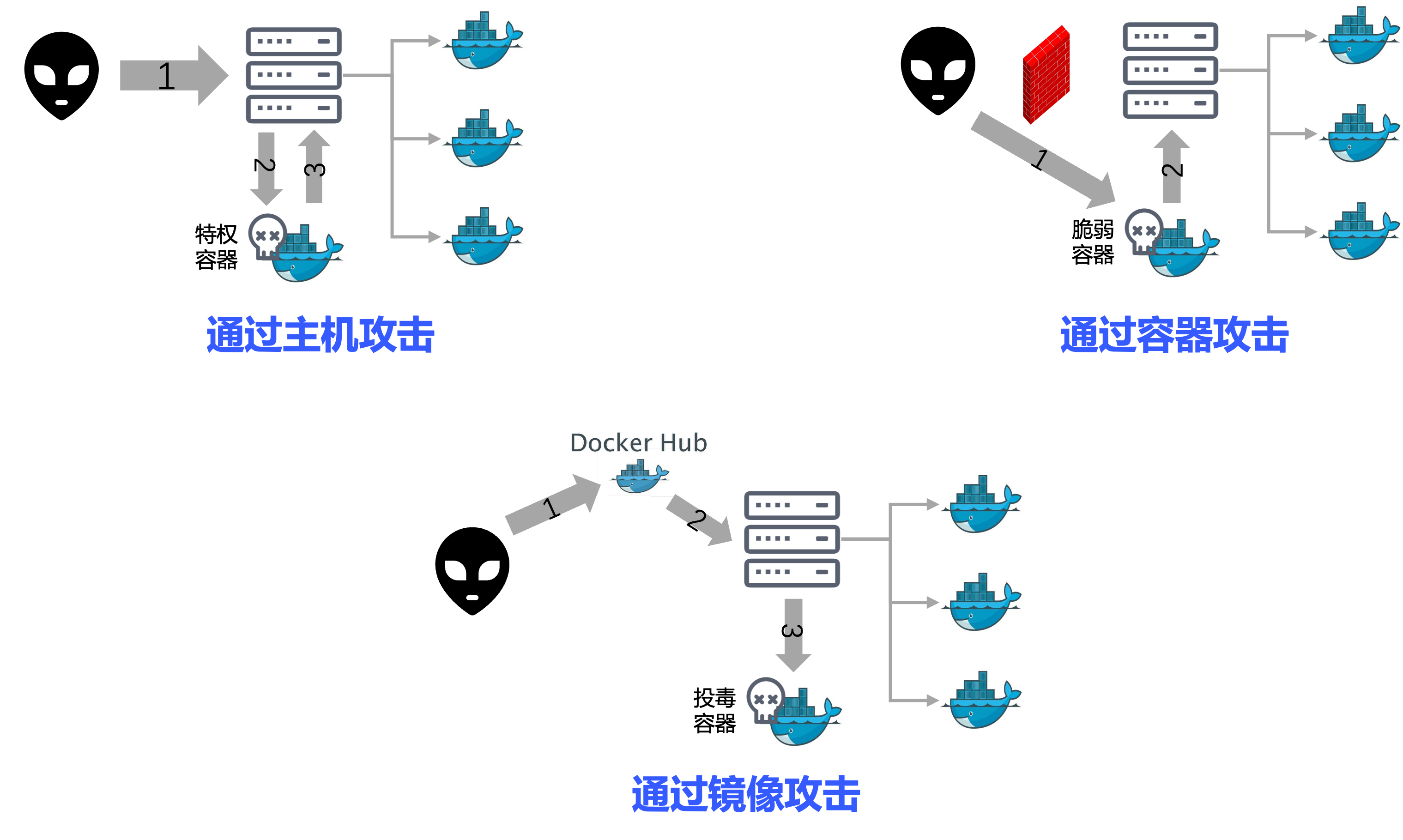
1)通过容器主机实施攻击。这种通常是由于主机配置问题引起,例如对公网开放并且未开启认证的Docker RemoteAPI,或者是未开启认证的Kubernetes API Server。
2)通过脆弱的容器实施攻击。这种类型攻击主要以容器环境中部署应用程序的脆弱性作为攻击突破口。
3)通过投毒的镜像实施攻击。主要通过对公共仓库中的镜像进行投毒,当镜像被拉取运行时,即可执行相关的攻击操作。
攻击者可以做什么?
本次log4j2漏洞的影响,主要是体现在第二种攻击方式上,也就是攻击者会通过受影响的应用程序,利用漏洞对容器化的应用实施攻击。
一旦第一步漏洞利用成功,接下来就会按照通常的渗透攻击逻辑,一方面在主机执行恶意程序;另一方面通过横向移动,扩大攻击范围,这里的横向移动既会涉及主机层面的容器逃逸,也包括东西向网络层面的移动攻击。
如何快速响应处置?
云原生架构下,在漏洞的应急响应上,总体思路和传统安全事件的应急是一致的。首先需要对漏洞的原理以及可能被利用的方式进行分析,确定修复和缓解方案,同时制定相关安全产品的防护规则,实现对漏洞利用的检测和拦截,最后就是有条不紊的进行漏洞的修复和处置。
在容器环境中,具体可以梳理出如下的一些关键操作步骤:
• 首先,需要确定现有业务的受影响范围。例如:确定仓库中所有受漏洞影响的镜像,确定受影响的线上业务;
• 其次,升级相关安全产品的防护策略。例如通过WAF规则以及防火墙规则等实现对漏洞利用的攻击进行一定程度的暂时性拦截;必要时升级运行时检测策略,一旦入侵成功,可以快速的发现并进行处置。
• 最后,就是修复漏洞,升级到官方发布的修复版本。
为什么不容易
安全应急或者安全运营的效率,很大程度上依赖安全能力的建设。上述处置步骤,相对来说是理想情况下的一种处置流程,或者是需要在一套完善的安全能力建设基础之上才可以轻松实施的处置流程。
根据腾讯云在2021年11月份发布的《腾讯云容器安全白皮书》显示,当前云原生用户在安全能力的建设上可谓是参差不齐,像镜像漏洞扫描、主机安全加固以及集群监控审计等基础安全能力,落地部署的比例也仅仅只有50%左右,甚至有7%的用户在云原生的使用时没有任何安全能力的部署。
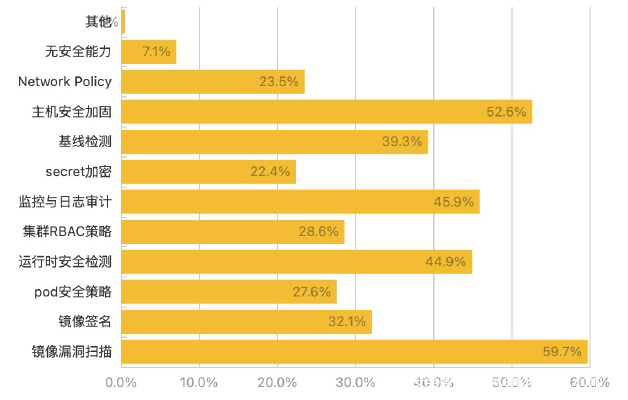
因此,在这样的现状下,面对log4j2这样的0day漏洞,在应急处置上,难免会出现各种捉襟见肘的问题。
控制影响范围
对于漏洞的处置,首先就是控制漏洞影响范围。因为漏洞的修复需要一定的时间周期,像log4j2这种使用范围如此之广的组件,甚至有预测,漏洞影响将会持续很长一段时间,因此控制新的影响资产增加也是十分重要的。
这里主要体现在两个方面:
(1)防止包含漏洞镜像的入库。CI集成以及镜像入库等阶段,需要严格进行安全检查,防止漏洞的引入。
(2)防止包含漏洞镜像的运行。在新的服务启动运行时,需要检测相关镜像是否包含漏洞,对于未通过安全检测的镜像,要严格阻止其启动运行。
怎么确定受影响范围
1)识别所有受到漏洞影响的镜像
在确定业务的受影响范围时,如果部署了容器镜像安全扫描的能力,安全厂商通常会在第一时间更新漏洞库或检测规则,用户可以直接通过对镜像仓库的所有镜像进行扫描发现受影响的镜像。
如果没有部署镜像安全扫描,腾讯云容器安全服务提供7天的免费试用,用户可以通过其中的镜像扫描功能,对镜像资产进行排查。最差情况下,用户可以使用开源的镜像扫描工具(例如Clair/Anchore/Trivy等)进行问题排查,但是有一点需要注意,使用开源工具前,要确保漏洞库或者检测规则已经包含了对目标漏洞的检测。
2)识别受影响的运行工作负载
当确定了受影响的镜像后,就需要根据这个列表确定受影响的线上业务。假如我们的日常安全运营做的足够完善,理论上这个列表跟受影响的业务列表应该是一致的。或者是我们需要部署相应的安全能力,实现镜像资产到线上业务资产的映射。
假如这些都没有的话,就需要逐个集群的检索当前使用的镜像,判断其是否受到影响,例如可以使用“kubectl describe pods —all-namespaces| grep image”这种最粗暴的指令获取集群运行业务所使用的所有镜像。
到这里我们发现,如果仓库中镜像的数量太多,其实也可以采用另一种思路,先使用类似“kubectl describe pods —all-namespaces| grep image”这样的命令,逐个集群查询到所有线上业务使用的镜像,然后对于这些镜像定向的进行漏洞检测。
怎么修复
面对漏洞的爆发,所有人都希望能充分了解这个漏洞,并在第一时间使用对应的补丁解决问题。不幸的是:一方面,软件开发和测试需要时间周期,漏洞的修复不会那么快;另一方面,在微服务架构下,受影响的镜像可能会非常多,这同样给漏洞的修复带来很大的挑战。
因此,在漏洞修复的同时,我们可以通过建议的缓解措施进行缓解,例如,对于log4j2漏洞,可以添加jvm启动参数:
-Dlog4j2.formatMsgNoLookups=true进行暂时的缓解。
但是,在云原生架构下,应用程序的启动命令以及运行参数等信息,都是直接打包在镜像中,这样又回到前文提到的问题,如果受影响的镜像数量非常庞大的时候,这种临时的缓解措施在实施起来也将面临重大的挑战。
在云原生架构下,我们看到可以有几种针对漏洞的缓解性操作:
(1)修改线上运行环境
我们可以通过kubectl edit pod…命令,修改线上服务Pod的运行参数,实现漏洞的缓解。针对批量的运行参数修改,我们也推出了一个开源的工具 。
值得注意的是,上述处置方式在修改完参数之后,会自动重启服务,用户在使用时,需评估相应的重启风险。
(2)利用漏洞特性缓解
以log4j2为例,这是个远程任意代码执行的漏洞,简单来说,就是在打印日志时,如果发现日志内容中包含关键词 ${,那么这个里面包含的内容会当做变量来进行替换,导致攻击者可以任意执行命令。
因此在进行漏洞缓解时,可以利用漏洞的这一特性,将缓解指令通过漏洞传进去,实现利用漏洞来缓解漏洞的效果。
这种方法针对不同的漏洞,不具有普适性。
(3)漏洞利用的阻止
前面两种操作,都是从漏洞本身出发,通过缓解方式,使得漏洞不能被利用。另外一种缓解措施就是一旦前述缓解措施失效或被绕过,可以在漏洞利用的关键路径上,进行操作的拦截,从而达到漏洞缓解的效果。
这种操作对安全能力有一定的依赖,一方面,安全能力需要能够检测出漏洞利用的行为,另一方面,需要能够精准的对进程行为进行阻断。尤其是对于log4j2这种任意代码执行的漏洞,漏洞利用的检测对安全能力有着较高的要求。
通过上述几种临时缓解措施后,接下来我们需要做的就是,结合线上环境使用的镜像以及业务重要性和优先级等因素,有条不紊的将受影响的组件升级至官方发布的稳定修复版本。
云原生架构下安全运营的挑战和优势
从上述漏洞处置的过程我们可以发现,云原生架构下在漏洞的处置修复上,容器环境既面临一定的挑战,同时也有着一定的优势。
挑战
1)镜像数量大。一方面,由于log4j2本身就是应用范围很广的组件,而且在微服务架构下,应用又会进行很多细粒度的微服务拆分,因此在仓库中会受影响的镜像会涉及到很多个Repositories;另一方面,由于DevOps等敏捷开发流程的使用,镜像仓库中的每一个镜像又会有很多个版本(每个Repository有很多个Tags)。因此,在漏洞处置的过程中会发现,扫描出来的受影响镜像数量巨大。
2)僵尸镜像。所谓的僵尸镜像,其实可以理解为存储在仓库中的旧版本镜像,或者过期镜像,已经几乎不会再被运行使用。如果对仓库中的镜像没有很好的管理机制,这种僵尸镜像的数量也会非常大。这种现象其实也很好理解,DevOps带来业务快速的迭代,自然就会产生大量的过期镜像。
在常规的安全运营中,这些僵尸镜像原则上是应该及时被清除的(不需要考虑备份回滚的问题,代码仓库会有),这种清除操作不仅仅是需要覆盖镜像仓库,同样适用于主机上的僵尸镜像。
3)不可变基础设施。云原生架构的一个典型特征就是不可变的基础设施,所谓的不可变基础设施,是指一旦部署了服务之后决不允许被修改。如果需要以任何方式更新、修复或修改某些内容,则需要修改相对应的镜像,构建全新的服务镜像来替换旧的需要改变的服务镜像,经过验证后,使用新的镜像重新部署服务,而旧的则会被删除。
这种特性,给我们针对线上业务在进行漏洞缓解的时候带来了很大的不便。一方面体现在修改应用的运行参数和环境变量等信息上;另一方面体现在这种缓解措施的修改,会引发运行时安全的再次告警,因为这种操作违背了不可变基础设施的要求,不是正常的业务操作流程。
优势
• 资产可视化,快速定位。资产问题一直是安全建设和安全运营中重要的问题,同时也是最让人头疼的问题。云原生架构很好的解决了资产的问题,通过Kubernetes等编排平台以及镜像仓库等组件,可以让我们快速的进行资产梳理、问题定位。
• 流程自动化,快速生效。Kubernetes等编排平台提供了一整套的业务自动化管理方案,包括配置管理、服务编排、任务管理等。因此,对于漏洞的修复可以实现快速分发和对应的灰度升级等。
• 安全左移,快速控制。能够在CI/CD等多个环节进行安全左移检测,镜像入库前的检测,阻止包含漏洞镜像推送到仓库,降低增量风险;在运行时进行准入检测,对于包含漏洞风险的镜像,阻止其启动运行,减小线上环境新增暴露面。
• 微服务架构。在微服务架构下,应用间相对独立,这给漏洞修复带来的好处,一方面,针对某个镜像的漏洞修复,影响范围小,提高漏洞修复效率;另一方面,微服务架构下,服务功能单一,很多重复的功能会形成独立服务,这样减小了修复数量。
这次漏洞的爆发,给我们在云原生安全建设和运营上敲响了警钟,以该事件作为切入点,企业在云原生架构的落地过程中,需要系统全面的考虑安全能力的建设和运营了。我们将在下一篇文章中,结合自身实践,系统的分享我们对于云原生架构下安全建设和安全运营的思考。
腾讯容器安全服务(Tencent Container SecurityService, TCSS)提供容器资产管理、镜像安全、集群安全、运行时入侵检测等安全服务,保障容器从镜像构建、部署到运行时的全生命周期安全,帮助企业构建容器安全防护体系。







发表评论
您还未登录,请先登录。
登录