
0x01 决策树概述
决策树是一种用于分类和回归的模型,是一种有监督的机器学习算法,可用于分类和回归问题。树回答连续的问题,这些问题使我们在给出答案的情况下沿着树的某个路线前进。
当构建决策树时,我们知道变量使用哪个变量和哪个值来拆分数据,从而快速预测结果。
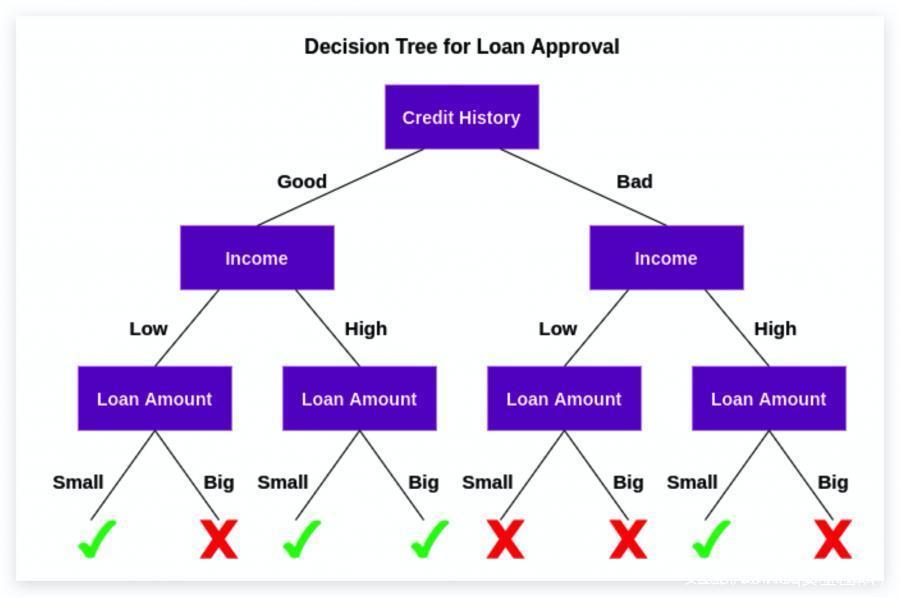
决策树优点
- 易于解释并实现直观的可视化
- 内部运作可以被观察,从而使复制工作成为可能
- 可以快速适应数据集
- 可以处理数值和分类数据
- 可以使用“树”图有序地查看和解释最终模型
- 在大型数据集上表现良好
- 速度极快
决策树缺点
- 构建决策树需要能够确定每个节点的最佳选择的算法
- 决策树容易过度拟合,尤其是当树特别深时
0x02 随机森林概述
森林具有与决策树几乎相同的超参数,通常来说,一棵树没法得到有效的以及希望得到的结果,这时候就需要用到随机森林的概念,随机森林是一种用于分类、回归和其他任务的集成学习方法。
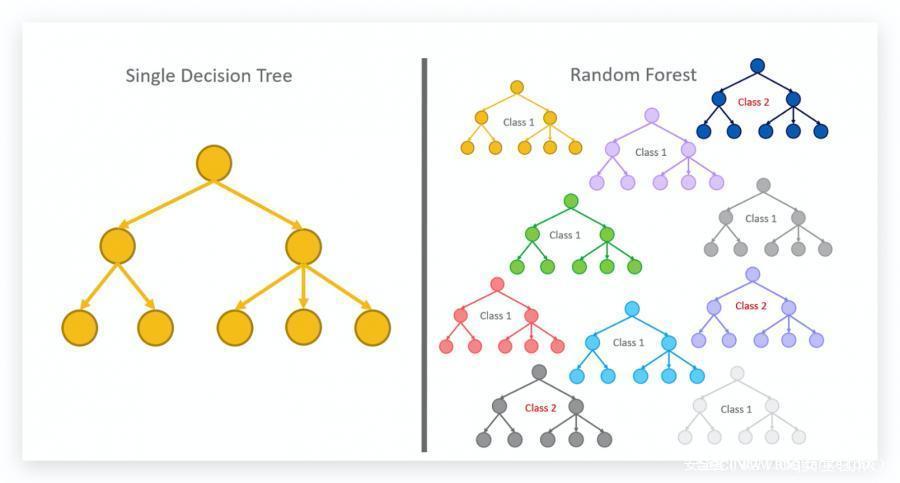
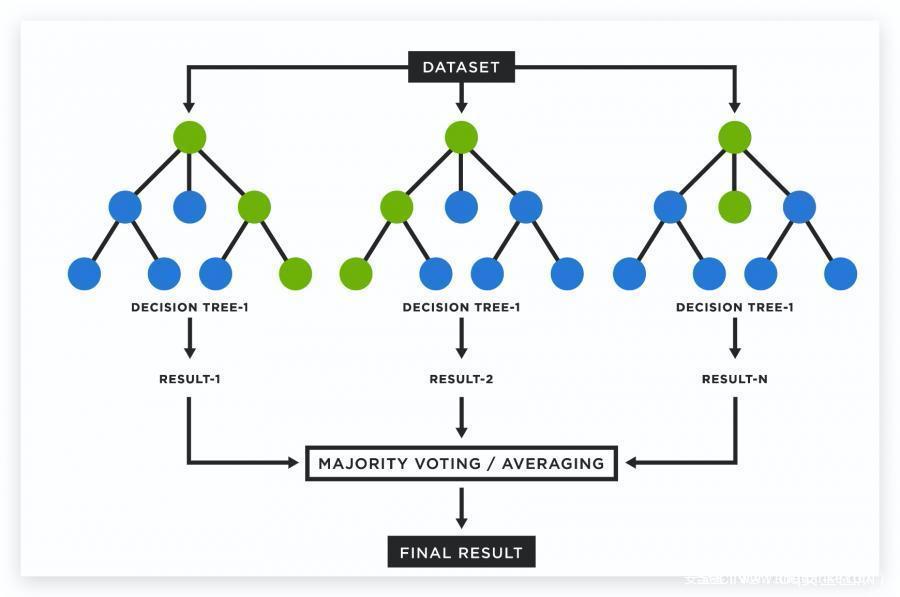
随机森林可以理解成一组决策树,是将很多决策最终聚合成一个结果,通过在训练时构建大量决策树来进行操作,是一种基于树的机器学习算法,它利用多个决策树的力量进行决策。
在构建随机森林算法模型时,我们必须定义要制作多少棵树以及每个节点需要多少个变量。
1995 年, Tin Kam Ho 使用随机子空间方法创建了第一个随机决策森林算法,在 Ho 的公式中,这是一种实现随机判别”分类方法的方法。
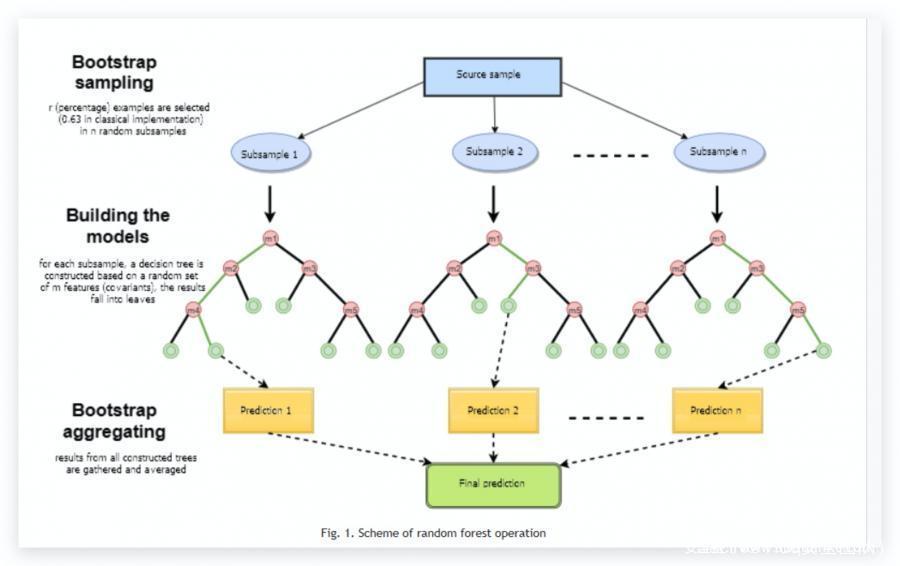
随机森林减少方差的方法:
- 对不同的数据样本进行训练
- 使用随机的特征子集
![]()
随机森林优点
- 随机决策森林纠正了决策树的过度拟合
- 随机森林通常优于决策树,但它们的准确性低于梯度提升树
- 更多的树会提高性能并使预测更稳定
随机森林缺点
- 随机森林算法模型更复杂,因为是决策树的组合
- 更多的树会降低计算速度
0x03 决策树与随机森林的区别
随机森林算法和决策树之间的关键区别在于,决策树是使用分支方法说明决策的所有可能结果的图。相比之下,随机森林算法的输出是一组根据输出工作的决策树。
决策树相对于决策森林,模型更好搭建,对于随机森林来说,最终模型可视化程度较差,如果数据量太大或者没有合适的处理方法去处理数据,就会导致需要很长的时间才能创建。
决策树总是存在过度拟合的空间;随机森林算法通过使用多棵树来避免和防止过拟合。
决策树需要低计算量,从而减少了实现时间并且精度低;随机森林会消耗更多的计算量。生成和分析的过程非常耗时。
决策树可以很容易实现可视化;随机森林可视化复杂。
0x04 修建
修剪是进一步切碎这些树枝。它作为一种分类来以更好的方式补贴数据。就像我们说修剪多余部分的方式一样,它的工作原理是一样的。
到达叶节点,修剪结束。它是决策树中非常重要的一部分。
0x05 总结
与随机森林相比,决策树非常容易。决策树组合了一些决策,而随机森林组合了几个决策树。
决策树在大型数据集上运行速度快且易于操作。随机森林模型需要严格的训练,大量的随机森林,更多的时间。







发表评论
您还未登录,请先登录。
登录