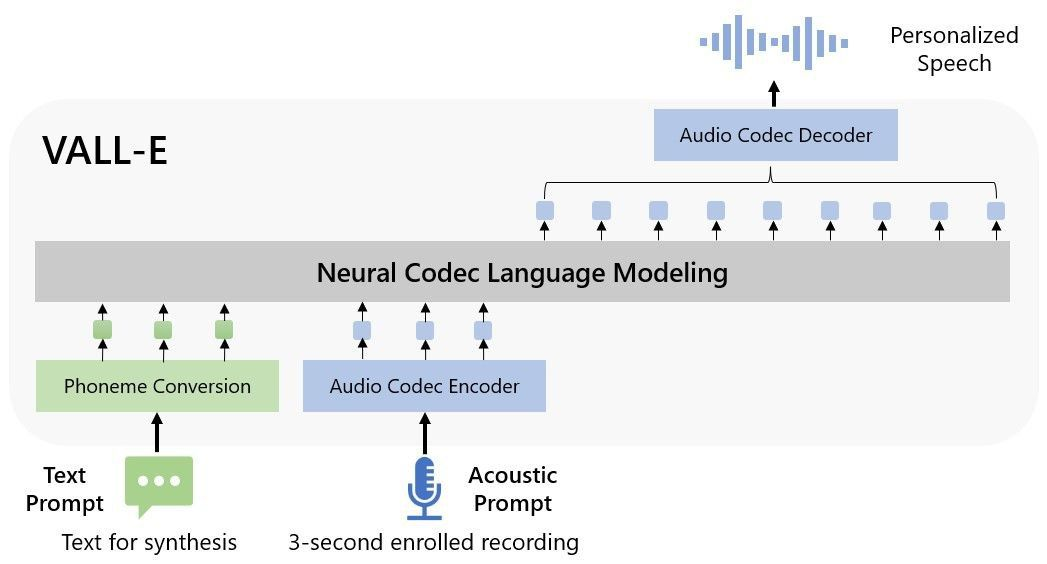
微软新文本语音模型VALL-E只要听3秒钟的声音样本就能复制任何人的声音。
VALL-E 是一种基于转换器(transformer)的文本语音模型,比之前的模型有显著的改进,旧的模型需要长时间训练才能生成新的声音。此外,在生成的语音中声音的语调、卡里斯马(或魅力)和风格都完全一致。这是文本语音系统朝着更自然的声音迈出的重要一步。[阅读原文]

2024-07-10 17:00:28
2023-06-06 17:21:40
2023-05-05 12:03:24
2023-05-05 12:01:24
2023-05-05 11:59:52
2023-11-22 10:45:43
2023-10-16 11:17:03
2023-10-13 10:37:40
2023-10-11 10:23:45
2023-03-29 10:15:11
2023-03-17 11:29:01
2023-03-16 12:00:51






发表评论
您还未登录,请先登录。
登录