一、低成本解决“风险代码”
一直以来,“漏洞”作为一种典型的风险管理对象,链接了动态扫描(DAST)、静态扫描(SAST)等风险发现工具和企业风险修复流程。但围绕漏洞建立的“风险发现”和“风险修复”两者间存在天然矛盾,且随着风险治理从事后移向事前而加剧。一方面,风险发现时机前移,距离线上实际状态更远,增加了“漏洞”可利用性和危害的评估难度,发现潜在问题的数量级上升;另一方面,漏洞修复流程实施成本高昂,依赖安全与业务双方人工分析、协同修复,且往往优先处理可利用性高且危害明确的漏洞;矛盾加剧反而会阻塞前移后的风险治理。
无恒实验室尝试将风险管理对象从传统“漏洞”转变为“风险代码”,并联合代码智能团队尝试利用LLM实现“风险代码自动发现与修复闭环”,降低治理成本、提升治理效率。
“风险代码”指由于存在“缺陷”有概率引发线上漏洞的代码,是构成代码漏洞的必要不充分条件。而“校验缺失”是最常见的风险代码类型之一。由于缺少对关键变量进行关系校验、值域校验、类型校验、模式校验等必要合法性检查,会导致非法请求数据进入业务流程,造成安全危害。例如在下述获取订单详情的代码中,如果不校验订单属主与当前登录用户是否一致,则可导致攻击者利用越权漏洞获取他人订单造成信息泄露。
func GetOrder(ctx *gin.Context, req *OrderReq) (*OrderResp, error) {
if req.OrderId == nil {
logs.CtxError(ctx, "OrderId is nil")
return nil, common.NewError(common.ReqError, "OrderId is nil")
}
orderResp, err := order.GetOrder(req.OrderId)
if err != nil {
logs.CtxError(ctx, "Get Order error")
return nil, err
}
if orderResp == nil {
logs.CtxError(ctx, "Order is nil")
return nil, common.NewError(common.RespError, "Order is nil")
}
if orderResp.GetAccount().Id != GetUserId(ctx) {
logs.CtxError(ctx, "The current user does not have permission to obtain the order info")
return nil, common.NewError(common.AuthError, "The current user does not have permission to obtain the order info")
}
return orderResp, nil
}
图1: 缺少if-condition校验代码(17-20行)会导致水平越权漏洞
(为方便本文阐述构造的测试代码,不存在于模型数据集中)
二、校验缺失风险 与 LLM基础能力
解决校验缺失风险的关键是结合业务场景分析校验需求。不同业务场景间的校验需求有显著差异,比如订单查询场景需要校验订单和用户的归属关系、员工组织架构信息查询场景需要校验部门和员工的层级关系、工作流更新场景需要校验访问用户是否有目标工作流的编辑权限。通过人工定制规则来一一覆盖所有场景是不现实的,我们需要用技术自动完成以下任务:
1)从代码中识别定义校验需求的关键信息;
2)从历史数据自动学习校验需求和校验实现方式;
3)最终对于给定代码能自动补全缺失的校验代码。
近期大规模语言模型(LLM)技术的发展,特别是CodeX、Codegen、StarCoder等大规模代码生成模型的出现,为自动识别与修复校验缺失风险提供可行路线:
-
- · LLM的代码生成能力:LLM模型通过Billion到Trillion级别参数、结合上百G代码/文本混合数据训练,已展现出对开发者编码意图的理解能力,并能据此补全后续代码。可利用其代码生成能力实现校验代码生成补全、实现自动修复。
-
- · LLM的代码理解和分析能力:经过预训练(Pretraining),LLM模型本身掌握通用的代码语法和文本语义分析能力。并基于对历史代码分析任务数据的学习、具备一定程度的代码领域任务分析能力、e.g.,简单的数据流分析。可满足代码分析和场景理解的基础需求。
-
- · LLM对校验需求推断能力:LLM的逻辑推理能力可帮助从代码中多角度信息合理推断校验需求,包含但不限于高阶语义、注释含义、数据流依赖等。甚至有能力解释补充校验语句的原因,对业务研发更为友好。以图1中函数片段为例,将17-20行校验语句移除后询问StarChat引入校验原因,可获得合理回答:

图2: StarChat分析需补全校验原因
三、训练风险代码LLM 与效果案例分享
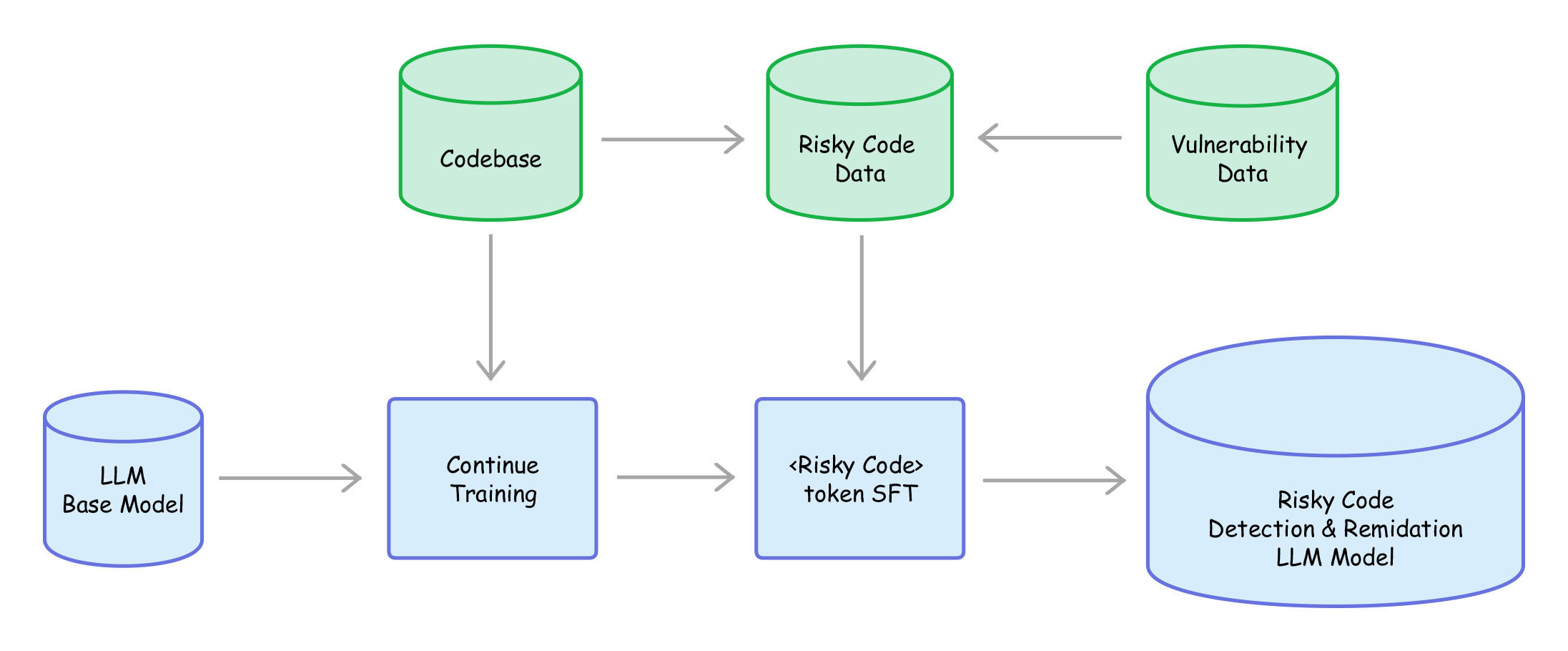
无恒实验室&代码智能团队使用开源LLM模型(CodeGen、StarCoder、StarChat)作为base model,结合公司内部代码和历史漏洞数据,对base model进一步Continue Training 和 Supervised Fine-Tune,训练其对不同业务场景风险代码的识别与修复能力。在使用Risky Code LLM解决校验缺失风险过程中,我们得到如下初步结论:
1、Risky Code LLM可在语义层面理解业务场景、分析校验需求并补全校验语句
将图1移除17-20行校验语句后输入Risky Code LLM,模型会生成如下校验语句(PS:图1中示例不存在于模型任何数据集、更能说明模型泛化能力)。新生成校验语句与原校验语句不完全相同,将orderResp.GetAccount().Id 替换为了同语义的orderResp.UserId。说明模型在‘语义层面’进行补全,成功识别到代码来自“获取订单信息”场景,关联‘需要对订单的属主与当前登录用户进行校验’需求,并生成校验代码。同时,模型能够仿照输入Prompt中的日志打印语句和返回语句的格式,生成格式正确的日志打印语句和返回语句。
Q:<function>``func GetOrder(ctx *gin.Context, req *OrderReq) (*OrderResp, error) {
if req.OrderId == nil {
logs.CtxError(ctx, "OrderId is nil")
return nil, common.NewError(common.ReqError, "OrderId is nil")
}
orderResp, err := order.GetOrder(req.OrderId)
if err != nil {
logs.CtxError(ctx, "Get Order error")
return nil, err
}
if orderResp == nil {
logs.CtxError(ctx, "Order is nil")
return nil, common.NewError(common.RespError, "Order is nil")
}
return orderResp, nil
}``
<validate>
---- 以下为Risky Code LLM补全结果----
A: if orderResp.UserId != common.GetUserID(ctx) {
logs.CtxError(ctx, "No permission to get order, OrderID:%v, UserID:%v", req.OrderId, common.GetUserID(ctx))
return nil, common.NewError(common.RespError, "No permission to get order")
}
图4: 风险代码识别与修复能力展示
2、Risky Code LLM 会结合Prompt 细粒度信息调用逻辑推理能力
LLM在生成代码过程中对给定Prompt进行了细粒度分析,能够捕捉prompt中信息的变化,动态生成相符的校验语句。将Case 1请求代码中的变量orderResp修改成orderInfo,补全校验语句也随之改变。这也说明LLM补全代码并不是在死板拷贝训练数据中的特定语句,而是从训练样代码本中提炼出‘更高层’的‘校验需求’,并基于当前场景推理出最终实现形式。
Q:<function>``func GetOrder(ctx *gin.Context, req *OrderReq) (*OrderResp, error) {
if req.OrderId == nil {
logs.CtxError(ctx, "OrderId is nil")
return nil, common.NewError(common.ReqError, "OrderId is nil")
}
orderInfo, err := order.GetOrder(req.OrderId)
if err != nil {
logs.CtxError(ctx, "Get Order error")
return nil, err
}
if orderInfo == nil {
logs.CtxError(ctx, "Order is nil")
return nil, common.NewError(common.RespError, "Order is nil")
}
return orderInfo, nil
}``
<validate>
---- 以下为Risky Code LLM补全结果----
A: if orderInfo.UserId != common.GetUserID(ctx) {
logs.CtxError(ctx, "No permission to get order, OrderID:%v, UserID:%v", req.OrderId, common.GetUserID(ctx))
return nil, common.NewError(common.RespError, "No permission to get order")
}
图 5: 细微扰动实验说明Risk Code LLM调用推理能力
3、在Prompt内丰富上下文信息可缓解幻觉(hallucination)问题
幻觉问题在我们场景中的体现是,LLM有时会无中生有、强行编造一些结构体的成员变量,导致生成错误的校验语句。LLM产生幻觉的主要原因是信息缺失,因此LLM基于Pretraining习得能力尝试生成的答案并不正确。比如,在上述“获取订单信息”场景中,假设业务场景中订单的归属是某个组织,而不是个人,同组织的用户可以互相查看订单,那么此时生成校验UserId的一致性就是错误的。我们可以在prompt中补充orderResp的结构体定义,模型通过In-Context Learning学习到orderResp中的成员变量,进而生成正确的校验语句:
Q:<context>``type OrderResp struct {
GroupId int
OrderId int
OrderStatus int
OrderContent string
}``
<function>``func GetOrder(ctx *gin.Context, req *OrderReq) (*OrderResp, error) {
if req.OrderId == nil {
logs.CtxError(ctx, "OrderId is nil")
return nil, common.NewError(common.ReqError, "OrderId is nil")
}
orderResp, err := order.GetOrder(req.OrderId)
if err != nil {
logs.CtxError(ctx, "Get Order error")
return nil, err
}
if orderResp == nil {
logs.CtxError(ctx, "Order is nil")
return nil, common.NewError(common.RespError, "Order is nil")
}
return orderResp, nil
}``
<validate>
---- 以下为Risky Code LLM补全结果----
A: if orderResp.GroupId != common.GetGroupID(ctx) {
logs.CtxError(ctx, "GroupId not match, req:%v, orderResp:%v", req, orderResp)
return nil, common.NewError(common.RespError, "GroupId not match")
}
图 6: 通过丰富Prompt上下文解决幻觉
四、讨论
我们展示了利用LLM低成本解决风险代码的可能性,但目前仍有很多技术挑战需要解决:
如何利用LLM解决不同类型的风险代码:通过LLM实现风险代码自动修复,可节省传统漏洞治理流程中人工成本、提升了修复效率、缩短风险暴露时间。在此基础上,有可能做到真正治理“未知漏洞”的效果。风险代码是漏洞发生的必要不充分条件,梳理可能引发漏洞的风险代码类型并全量治理、可以提前解决很多潜在漏洞危害。但目前风险代码类型的定义还需要人工分析,方案的完整实施需探索更高效、支撑所有类型风险代码的方法。
如何利用LLM自身语言逻辑解释SFT任务:模型通过SFT的确成功调用了其语义分析和逻辑推理能力来识别与修复风险代码,形成了解决风险代码的“任务逻辑”。目前我们正引导Risky Code LLM使用语言来描述风险代码识别与修复任务推理过程,希望通过LLM原有的“语言逻辑”来表示SFT任务习得的“任务逻辑”,进一步提升任务可解释性。
五、结语
以ChatGPT为首的大规模语言模型的出现使得安全领域中很多传统方法的遗留问题出现了新解法。目前,字节跳动无恒实验室&代码智能团队正在利用LLM技术实现IDE安全插件,用于在研发开发的过程中对校验语句缺失的场景进行预警和修复,实现安全风险的左移。同时,也在使用该技术弥补传统的数据流分析方法无法覆盖的漏洞,共同保护用户数据和隐私安全。在未来,无恒实验室将持续探索大规模语言模型在安全领域的应用,针对传统方法面临的疑难问题给出大模型时代的答案,为用户的数据隐私安全提供切实保障。最后,欢迎大家进行技术交流讨论。
六、关于无恒实验室&代码智能团队
代码智能团队是字节跳动Dev Infra的创新技术实验室,实验室的使命是加速软件工程和智能技术的融合和互补,推动软件开发各个方面的技术进步。为了实现这一目标,实验室汇集了来自不同领域和背景的最优秀的研究人员和开发工程师,推动解决字节跳动和软件工程社区的挑战。
无恒实验室是由字节跳动资深安全研究人员组成的专业攻防研究实验室,致力于为字节跳动旗下产品与业务保驾护航。通过漏洞挖掘、实战演练、黑产打击、应急响应等手段,不断提升公司基础安全、业务安全水位,极力降低安全事件对业务和公司的影响程度。无恒实验室希望持续与业界共享研究成果,协助企业避免遭受安全风险,亦望能与业内同行共同合作,为网络安全行业的发展做出贡献。







发表评论
您还未登录,请先登录。
登录