
2025年11月18日,关键互联网基础设施提供商Cloudflare发生大规模宕机,导致众多知名网站和服务无法访问,引发全球网络间歇性故障。
此次问题源于内部服务性能降级,触发了HTTP 500错误,影响了Cloudflare的控制台、API和核心网络服务,导致全球数百万用户遭遇部分服务中断。
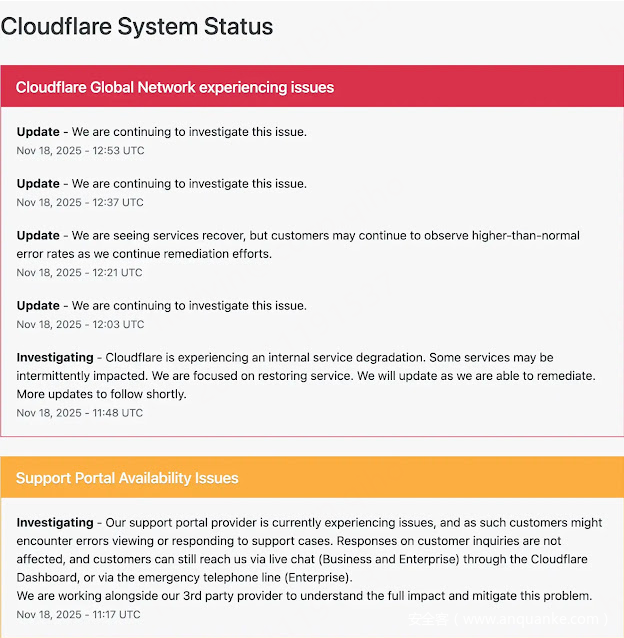
Cloudflare于协调世界时(UTC)11:48首次确认问题,称正经历内部服务性能降级,部分服务受间歇性影响,并承诺尽快恢复功能。
协调世界时12:03,该公司仍在调查中;随后在协调世界时12:21更新称,服务已开始恢复,但在修复期间,客户可能会遇到高于正常水平的错误率;协调世界时12:37,Cloudflare确认将继续调查,截至协调世界时傍晚,尚未宣布完全解决。
颇具讽刺意味的是,Cloudflare自身的状态页面在故障高峰期无法访问,导致受影响用户无法获取实时更新。
此次宕机波及整个互联网,冲击了依赖Cloudflare内容分发网络(CDN)、DDoS防护和DNS服务的平台。
社交媒体巨头X(原Twitter) 出现间歇性访问问题,用户报告加载失败和引用Cloudflare内部服务器问题的错误消息;故障跟踪平台Downdetector在高峰期记录了超过11,000份报告,其中61%与X移动应用相关,28%与网站相关。
AI服务如OpenAI的ChatGPT和Perplexity AI对许多用户而言无法访问,显示Cloudflare错误页面,提示用户几分钟后重试。
其他受影响的服务包括设计工具Canva、音乐流媒体服务Spotify、游戏平台如**《英雄联盟》和Discord**、电商网站Shopify、博客平台Medium,甚至依赖Cloudflare基础设施的加密货币交易所。
影评网站Letterboxd和故障跟踪平台Downdetector自身也加入了受影响行列,随着全球报告激增,用户不满情绪加剧。此次中断与上月亚马逊网络服务(AWS) 宕机事件类似,凸显了中心化互联网依赖的脆弱性。
部分数据中心的计划性维护可能加剧了延迟,例如:
- LAX(洛杉矶):协调世界时10:00-14:00
- ATL(亚特兰大):协调世界时11月18日07:00至11月19日22:00
- SCL(圣地亚哥):协调世界时12:00-15:00
- PPT(塔希提):协调世界时12:00-16:00
流量重定向可能是造成混乱的原因之一。此外,Cloudflare的支持门户因第三方提供商出现独立问题,阻碍了案例查看,但未影响响应处理。
根据状态页面显示,截至印度标准时间下午6:24,恢复工作仍在进行中,许多网站已恢复稳定,但欧洲、北美和亚洲等地区仍报告存在持续错误。Cloudflare强调其正专注于缓解措施,承诺在问题解决后提供更多细节,而用户在此次数字中断期间纷纷转向替代服务。
2025年10月20日,AWS在美国东部1区(一个对众多应用至关重要的区域)遭遇长时间中断。此次宕机持续超过15小时,影响了Slack、Atlassian和Snapchat等服务。
此后,10月29日,微软Azure因一次意外的DNS配置更改发生全球宕机。该问题影响了Azure前门和内容分发网络,导致全球范围内出现连接超时和解析问题,所有区域均报告严重状态。
Cloudflare更新[2025年11月18日——协调世界时14:34]:我们已部署一项更改,恢复了控制台服务。我们仍在努力解决广泛的应用服务影响。







发表评论
您还未登录,请先登录。
登录