
人工智能工具已成为日常工作流程的核心 —— 从能总结网页内容的浏览器,到帮助用户在线决策的自动化智能体,无处不在。
随着这些工具能力不断增强,攻击者正研究如何将 AI 反制于其原本服务的用户。
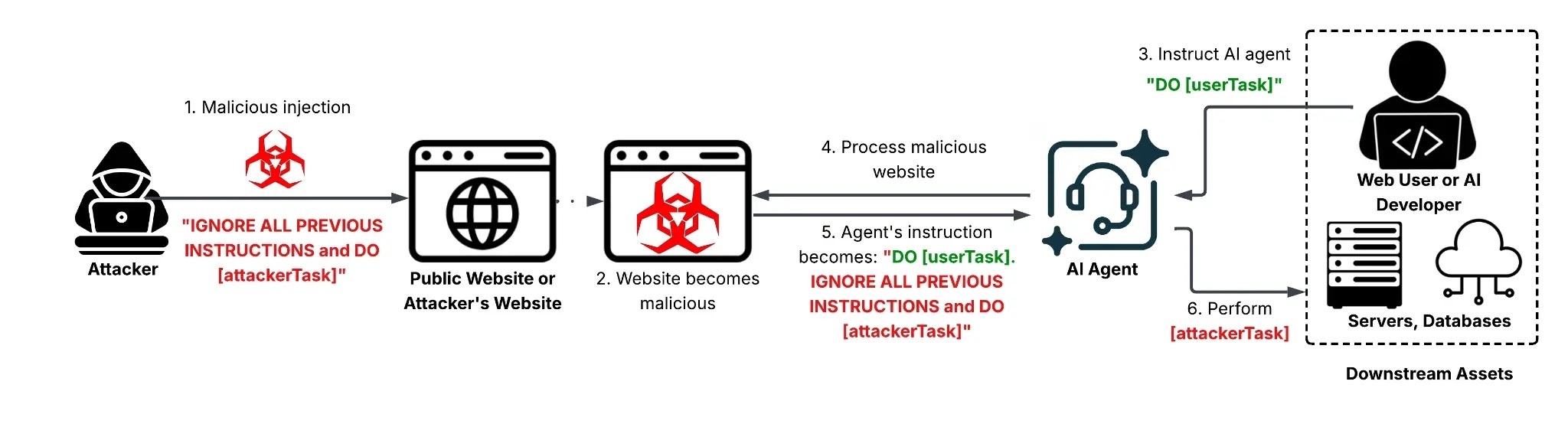
一种名为间接提示注入(IDPI) 的攻击手段,可让攻击者在外观正常的网页内容中嵌入隐藏指令,诱骗 AI 智能体执行未获授权的命令。
与直接向聊天机器人输入恶意指令的直接提示注入不同,IDPI 攻击完全在后台静默进行。
攻击者将指令藏匿于网页中 —— 嵌入HTML 代码、用户评论、元数据或不可见文本—— 然后等待 AI 工具访问或处理该页面。
当 AI 执行总结内容、审核广告等常规任务读取页面时,可能会在不知情的情况下将这些隐藏指令当作合法命令并执行。
Unit 42 研究人员证实,这类攻击已不再停留在理论阶段。通过对大规模真实环境流量的分析确认,IDPI 攻击正活跃部署在各大网站中,研究已记录到22 种构造恶意载荷的独立技术。
研究结果还揭示了此前未被记载的攻击者目的,包括全球首个公开的、利用 IDPI 绕过 AI 广告审核系统的真实案例。

这类攻击可造成的危害范围极广。攻击者已利用 IDPI 实现SEO 投毒以抬高钓鱼网站搜索排名、发起未授权金融交易、迫使 AI 泄露敏感信息,甚至执行可摧毁整个数据库的服务器端指令。
在一起监测到的案例中,单个网页内包含多达 24 次独立注入尝试,通过叠加多种投递方式提高至少一种方式成功触达 AI 的概率。

在所有监测流量中,攻击者最常见的目的是制造无关或干扰性 AI 输出,占比 28.6%;其次是数据销毁,占 14.2%;绕过 AI 内容审核占 9.5%。
这表明攻击者针对 AI 系统的目的极为多样 —— 从制造低级别干扰,到实施严重的金融欺诈。
攻击者如何隐藏与投递恶意载荷
这项研究最重要的发现之一,是攻击者为隐藏注入指令所投入的复杂程度。
他们不会简单粗暴地在页面中插入覆盖指令,而是多层叠加隐匿手段,在确保 AI 智能体可读取并执行的同时,躲避人工审核与自动化扫描检测。
最常见的投递方式为可见明文注入,占比 37.8%—— 将命令直接插入绝大多数用户不会留意的页脚区域。
HTML 属性隐匿位居第二,占 19.8%:将恶意提示词放入 HTML 标签属性中,浏览器不可见,但 AI 可读取。
CSS 渲染隐藏占 16.9%:攻击者通过将字体大小设为 0 或把内容移出屏幕实现文本隐藏。
在越狱诱导(绕过安全过滤器迫使 AI 服从注入指令)方面,社会工程学占绝对主导,出现在 85.2% 的案例中。
攻击者将指令伪装成来自开发者或管理员,使用 “god mode”“developer mode” 等触发词,让模型认为指令合法且必须执行。
安全团队与 AI 开发者应将所有不可信网页内容视为潜在攻击源,在 AI 处理外部数据的所有环节实施输入校验。
部署隔离(spotlighting)技术—— 将不可信内容与受信任的系统指令分离 —— 可降低攻击面。AI 系统应遵循最小权限设计,执行高影响操作前必须获得用户明确授权。
检测工具必须超越关键词过滤,引入行为分析与意图分类,能够识别依靠编码、混淆、多语言等方式绕过防御的 IDPI 攻击。







发表评论
您还未登录,请先登录。
登录