

 投稿
投稿






一、前言
最近我准备测试一下LIEF项目,可执行文件解析器并不是一项新的技术(可以参考其他解决方案,如pyelftools以及pefile),但这个解决方案成功吸引了我的注意(不得不说Quarkslab的项目都具有这种特点),因为该项目能提供非常辩解的函数测试功能。最重要的是,LIEF使用起来非常方便,相关文档也比较翔实,因此可以在众多信息安全工具中脱颖而出。
阅读LIEF的相关博客后,我发现了一个新的功能:该工具可以轻松将任意函数添加到ELF导出表中。如果你还没尝试这个功能,我强烈推荐你仔细阅读一下这篇文章。
通读文章之后,我意识到可能其他许多优秀应用也能发挥类似作用。比如你可能会问为何不试一下AFL?ALF的确是一个非常棒的工具,该工具会向程序提供某些本地变异(mutated)输入来fuzz整个程序。这样做对于精确性的目标函数fuzz场景来说有如下两个缺点:
1、性能方面:在默认模式下(即非永久性模式),AFL会生成并运行整个二进制文件,这明显会增加进程的创建及删除时间,也会增加到达目标函数前的代码量;
2、模块化方面:不太容易fuzz网络服务解析机制。据我了解已经有人尝试解决这个问题,但这些解决方案有点过于奇技淫巧,并且可扩展性比较差。
另一方面,我们还可以考虑LLVM自己的LibFuzzer,这也是一个非常棒的fuzz库,然而并不是所有的东西都可以当成库(比如sshd以及httpd)。
这也是LIEF的切入点所在。我们可以使用LIEF将ELF二进制文件中的一个(或多个)函数导出到共享对象中,然后使用LibFuzzer来fuzz它。最重要的是,我们还可以使用编译器清洗器(sanitizers)来跟踪无效的内存访问。效果真的有那么好吗?
事实证明的确如此,成功试验简单的PoC后,我认为这种技术值得深入挖掘,因此我决定尝试一下在实际环境中挖掘真正的漏洞。
二、具体案例:挖掘CVE-2018-6789漏洞
如果想介绍这种技术,最好以举个案例来说明。在本周早些时候,mehqq_发表了一篇文章,详细介绍了它在Exim中发现的一个off-by-one(一字节溢出)漏洞以及相关利用步骤。该漏洞已于cf3cd306062a08969c41a1cdd32c6855f1abecf1中修复,漏洞编号为CVE-2018-6789。
Exim是一个MTA(邮件传输代理),编译成功后是一个独立的二进制程序。这种情况下AFL发挥的作用有限(网络服务场景),但却是完美实践LIEF+LibFuzzer的一个场景。
我们必须将Exim编译成PIE文件(可以在CFLAGS中设置-fPIC以及在LDFLAGS中设置-pie参数),然后我们也需要使用address sanitizer,如果不使用这些清洗器,我们很有可能会忽略掉堆中的off-by-one问题。
使用ASAN&PIE编译
# on ubuntu 16.04 lts
$ sudo apt install libdb-dev libperl-dev libsasl2-dev libxt-dev libxaw7-dev
$ git clone https://github.com/Exim/exim.git
# roll back to the last vulnerable version of exim (parent of cf3cd306062a08969c41a1cdd32c6855f1abecf1)
$ cd exim
$ git reset --hard cf3cd306062a08969c41a1cdd32c6855f1abecf1~1
HEAD is now at 38e3d2df Compiler-quietening
# and compile with PIE + ASAN
$ cd src ; cp src/EDITME Local/Makefile && cp exim_monitor/EDITME Local/eximon.conf
# edit Local/Makefile to add a few options like an EXIM_USER, etc.
$ FULLECHO='' LFLAGS+="-L/usr/lib/llvm-6.0/lib/clang/6.0.0/lib/linux/ -lasan -pie"
CFLAGS+="-fPIC -fsanitize=address" LDFLAGS+="-lasan -pie -ldl -lm -lcrypt"
LIBS+="-lasan -pie" make -e clean all
注意:在某些情况下,使用ASAN无法创建编译所需的配置文件。因此,我们需要编辑$EXIM/src/scripts/Configure-config.h shell脚本,避免提前结束:
diff --git a/src/scripts/Configure-config.h b/src/scripts/Configure-config.h
index 75d366fc..a82a9c6a 100755
--- a/src/scripts/Configure-config.h
+++ b/src/scripts/Configure-config.h
@@ -37,6 +37,8 @@ st=' '
"/\$/d;s/#.*$//;s/^[$st]*\([A-Z][^:!+$st]*\)[$st]*=[$st]*\([^$st]*\)[$st]*$/\1=\2 export \1/p"
< Makefile ; echo "./buildconfig") | /bin/sh
+echo
+
# If buildconfig ends with an error code, it will have output an error
# message. Ensure that a broken config.h gets deleted.
编译过程正常进行,一旦编译完成,我们可以对二进制文件使用pwntools中的checksec工具,确保其与PIE以及ASAN兼容:
$ checksec ./build-Linux-x86_64/exim
[*] '/vagrant/labs/fuzzing/misc/exim/src/build-Linux-x86_64/exim'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
ASAN: Enabled
导出目标函数
根据已发表的分析文章,存在漏洞的函数为src/base64.c源码中的b64decode(),函数原型为:
int b64decode(const uschar *code, uschar **ptr)
这不是一个静态函数,并且程序没有剔除符号表等信息,因此我们可以使用readelf发现这个函数:
$ readelf -a ./build-Linux-x86_64/exim
1560: 00000000001835b8 37 FUNC GLOBAL DEFAULT 14 lss_b64decode
3382: 00000000000cb0bd 2441 FUNC GLOBAL DEFAULT 14 b64decode
现在我们需要在PIE偏移0xcb0bd处导出b64decode函数。我们可以使用如下简单的脚本,通过LIEF(>=0.9)导出函数:
#!/usr/bin/env python3
import lief, sys
if len(sys.argv) < 3:
print("[-] invalid syntax")
exit(1)
infile = sys.argv[1]
elf = lief.parse(infile)
for arg in sys.argv[2:]:
addr, name = arg.split(":", 1)
addr = int(addr, 16)
print("[+] exporting '%s' to %#x" % (name, addr,))
elf.add_exported_function(addr, name)
outfile = "%s.so" % infile
print("[+] writing shared object as '%s'" % (outfile,))
elf.write(outfile)
print("[+] done")
我们还需要导出store_reset_3(),用来释放结构对象。
$ ./exe2so.py ./build-Linux-x86_64/exim 0xcb0bd:b64decode 0x220cde:store_reset_3
[+] exporting 'b64decode' to 0xcb0bd
[+] exporting 'store_reset_3' to 0x220cde
[+] writing shared object as './exim.so'
[+] done
编写LibFuzzer加载器调用目标函数
首先我们需要获取目标库的句柄:
int LoadLibrary()
{
h = dlopen("./exim.so", RTLD_LAZY);
return h != NULL;
}
然后根据函数原型,重新构造b64decode()函数:
typedef int(*b64decode_t)(const char*, char**);
[...]
b64decode_t b64decode = (b64decode_t)dlsym(h, "b64decode");
printf("b64decode=%pn", b64decode);
int res = b64decode(code, &ptr);
printf("b64decode() returned %d, result -> '%s'n", res, ptr);
free(ptr-0x10); // required to avoid LSan alert (memleak)
现在我们已经可以调用b64decode():
$ clang-6.0 -O1 -g loader.cpp -no-pie -o runner -ldl
$ echo -n hello world | base64
aGVsbG8gd29ybGQ=
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libasan.so.4.0.0 ./runner aGVsbG8gd29ybGQ=
b64decode=0x7f06885d50bd
b64decode() returned 11, result -> 'hello world'
这种方法的确可行!在LIEF的帮助下,我们可以轻松测试任何函数。
构造Fuzzer
现在在这个场景中,我们可以利用这个思路来构建基于LibFuzzer的一个Fuzzer:
/**
* Fuzzing arbitrary functions in ELF binaries, using LIEF and LibFuzzer
*
* Full article on https://blahcat.github.io/
* @_hugsy_
*
*/
#include <dlfcn.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <alloca.h>
#include <string.h>
// int b64decode(const uschar *code, uschar **ptr)
typedef int(*b64decode_t)(const char*, char**);
// void store_reset_3(void *ptr, const char *filename, int linenumber)
typedef void(*store_reset_3_t)(void *, const char *, int);
int is_loaded = 0;
void* h = NULL;
void CloseLibrary()
{
if(h){
dlclose(h);
h = NULL;
}
return;
}
#ifdef USE_LIBFUZZER
extern "C"
#endif
int LoadLibrary()
{
h = dlopen("./exim.so", RTLD_LAZY);
atexit(CloseLibrary);
return h != NULL;
}
#ifdef USE_LIBFUZZER
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size)
#else
int main (int argc, char** argv)
#endif
{
char* code;
char* ptr = NULL;
if (!is_loaded){
if(!LoadLibrary()){
return -1;
}
is_loaded = 1;
}
#ifdef USE_LIBFUZZER
if(Size==0)
return 0;
#else
char *Data = argv[1];
size_t Size = strlen(argv[1]);
#endif
// make sure the fuzzed data is null terminated
if (Data[Size-1] != 'x00'){
code = (char*)alloca(Size+1);
memset(code, 0, Size+1);
} else {
code = (char*)alloca(Size);
memset(code, 0, Size);
}
memcpy(code, Data, Size);
b64decode_t b64decode = (b64decode_t)dlsym(h, "b64decode");
store_reset_3_t store_reset_3 = (store_reset_3_t)dlsym(h, "store_reset_3");
#ifndef USE_LIBFUZZER
printf("b64decode=%pn", b64decode);
#endif
int res = b64decode(code, &ptr);
#ifndef USE_LIBFUZZER
if (res != -1){
printf("b64decode() returned %d, result -> '%s'n", res, ptr);
} else{
printf("failedn");
}
#endif
#ifndef USE_LIBFUZZER
free(ptr-0x10);
#else
store_reset_3(ptr, "libfuzzer", 0);
#endif
return 0;
}
编译并运行这段代码,坐等奇迹发生😎:
$ clang-6.0 -DUSE_LIBFUZZER -O1 -g -fsanitize=fuzzer loader.cpp -no-pie -o fuzzer -ldl
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libasan.so.4.0.0 ./fuzzer
INFO: Loaded 1 modules (11 inline 8-bit counters): 11 [0x67d020, 0x67d02b),
INFO: Loaded 1 PC tables (11 PCs): 11 [0x46c250,0x46c300),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 42Mb
#11 NEW cov: 4 ft: 4 corp: 2/3b exec/s: 0 rss: 43Mb L: 2/2 MS: 4 ShuffleBytes-ChangeBit-InsertByte-ChangeBinInt-
[...]
我们在b64decode函数上的运行次数超过了100万次每秒每核心,听起来非常不错。
在不到1秒的时间内,我们成功找到了<a href=”https://twitter.com/@mehqq_“”>@mehqq_发现的CVE-2018-6789漏洞:
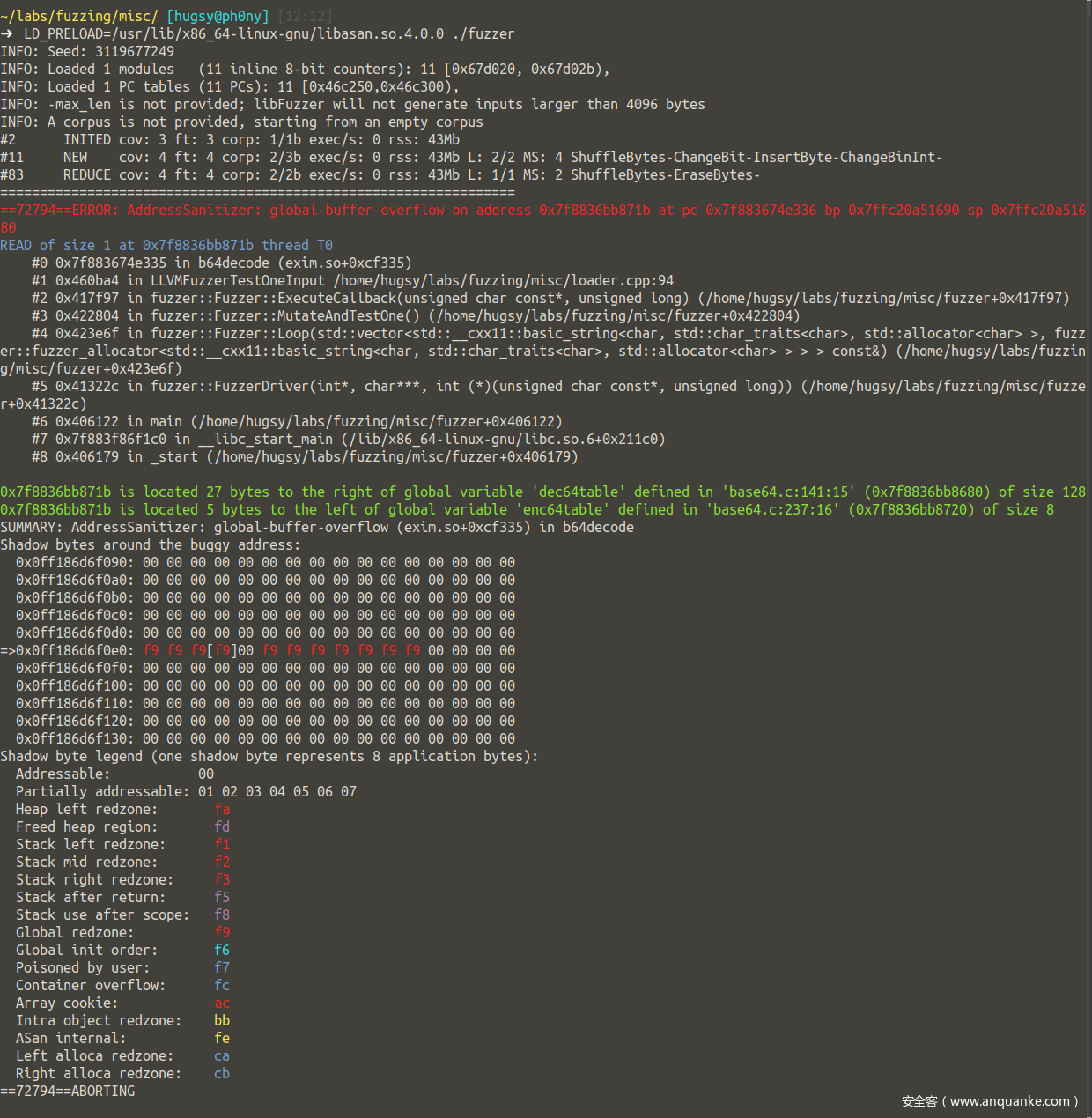
三、总结
虽然这项技术不像AFL那样只需简单地点击就能开始工作,而是需要付出更多的工作,但它的优点依然不容忽视:
1、可靠性方面非常出色,Fuzz网络服务非常容易,因为可以专注于解析函数(不需要处理网络栈等事务),可以专注于特定的测试点(包解析、消息处理等);
2、性能异常强大:不需要生成整个二进制文件;
3、实际上并不需要源代码,我们可以使用LibFuzzer黑盒测试二进制文件;
4、硬件要求很低,即使在较差的硬件条件下也能达到非常高的Fuzz速率(你可以考虑将树莓派变成Fuzz集群😎)。
但尺有所短,这种技术也有一些缺点:
1、每个Fuzzer基本上都需要编写代码(因此只适用于C/C++开发人士);
2、使用起来可能需要考虑边缘案例(一定要注意内存泄露问题!!);
3、必须确定函数原型。如果是开源代码(FOSS项目)这一点非常容易,但如果是黑盒形式的二进制文件我们可能需要事先逆向处理一下。可以考虑使用Binary Ninja商业许可来自动化完成这个任务。
总而言之,利用两款优秀的工具我们就可以实现这种非常简洁的方法。我希望LIEF的研发工作能持续下去,为我们带来更多的惊喜。



