

开始测试
作为测试的一部分,客户端提供了对根目录的列目录功能。在用Burp Intruder模块发起完全扫描之前,我通过repeater模块,在几个选择的页面中仔细查找,发现了secret.html,我感觉这个页面有些奇怪,于是发了一个请求并得到了如下的秘密内容:
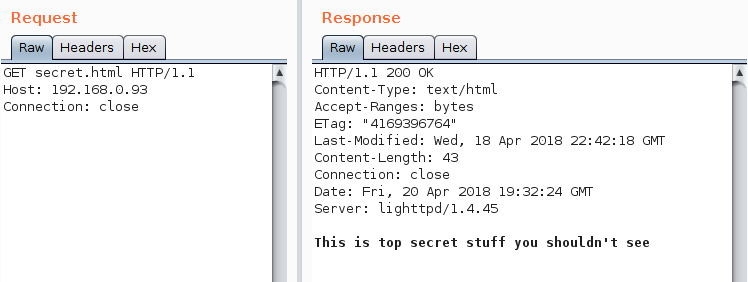
这样就能查看秘密内容?也太easy了吧,但是我没有烦恼,继续探索。
我在浏览器中输入那个url地址,结果却是“对不起,你无法查看内容”,如图
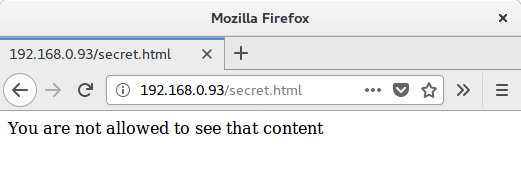
这跟我想的不一样,我想这可能跟session有关,但是看Burp代理中的请求,貌似一样啊。
虽然Firefox中有一些额外的headers,但那也是正常的啊。
burp代理如图:
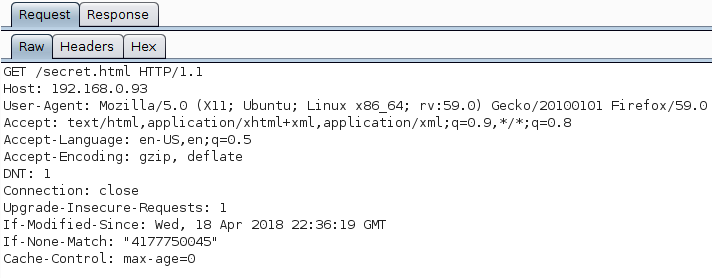
我琢磨着如果不用Firefox,使用curl能否看到内容?我直接把burp repeater中的请求复制过来,粘贴到命令行中:

奇怪的是,url粘贴的时候竟然出现了错误,少了一个/,但是我可以手工修改过来,请求后结果如图:

结果还是不允许查看,这跟我预想的也不一样。于是我直接从burp中获取curl命令并且运行,结果如图:

没有返回东西,而且url地址也不对,还是少了一个‘/’,这就有点头疼了。
此时,我应该意识到哪里有问题,但是没有,我还是直接加上‘/’,继续尝试请求,结果如图:
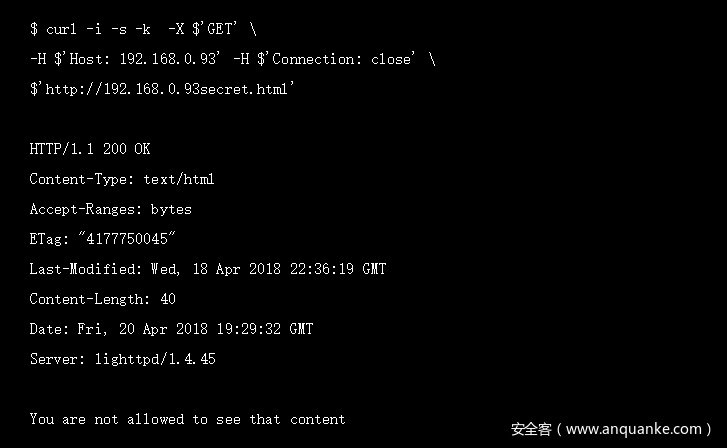
结果还是一样,这就奇了怪了。Burp能够访问到秘密的内容,Firefox和curl却不能。
我们再试试Netcat,我先建立一个连接,然后从burp repeater中复制url到nc中执行,如图:

没有返回内容,连接是开着的,但是服务器没有响应。也许我哪里输错了,于是我将请求放到一个文件中,然后通过文件的方式发起请求:
连接还是被挂起,没有响应。现在,我有点蒙,整不明白。梳理一下情况:
Burp能够访问秘密内容
Curl使用burp提供的url无法访问秘密内容
Burp中提供的curl命令也无法访问秘密内容
Netcat的任何尝试也都是挂起状态
请求中肯定有不同的地方而我没有发现。我们往下一层走,用wireshark抓包看看。
首先是burp 请求:
然后是burp生成的curl命令:

有几个不同的地方,这个请求带有curl 的user agent和接受的header。
WAFs和其他简单的防御系统都会对user agent进行检查,所以有可能就是这么简单。我们去掉额外的headers再尝试一遍: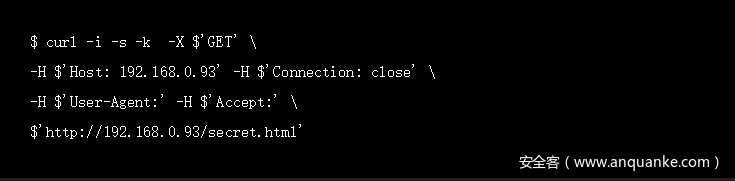
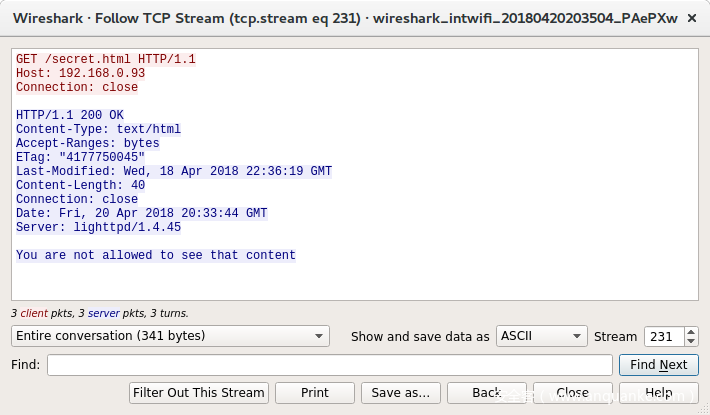
盯着这些请求仔细看,看似没有区别,但我还是发现了其中的差异,
burp请求的是secret.html,而curl请求的是/secret.html。这个额外的‘/’肯定就是差异所在,
这也解释了为什么从burp复制的url和burp生成的curl命令都少了一个‘/’。
Burp能够发起请求并读到内容,因为文件名在请求中已经指定,而curl则要求url包含文件名。
由于我无法使用curl复现这个请求,所以使用Netcat试试,看看能否搞明白为什么失败。我们看看wireshark中的Netcat连接,如图:
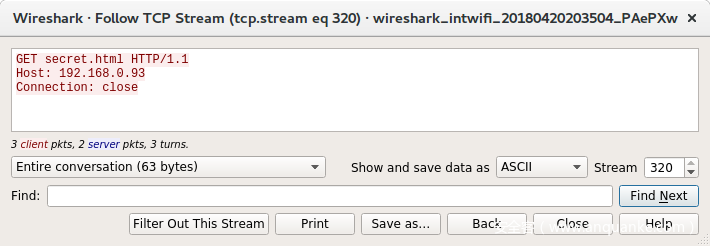
对比查看两个请求,都是请求的secret.html,而不是/secret.html,但是肯定有细微的差别。
我们来看看十六进制视图是怎样的:
Burp十六进制视图
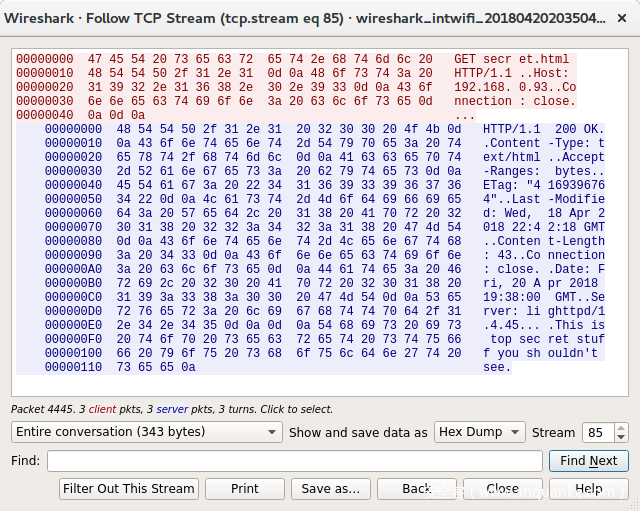
Netcat十六进制视图:
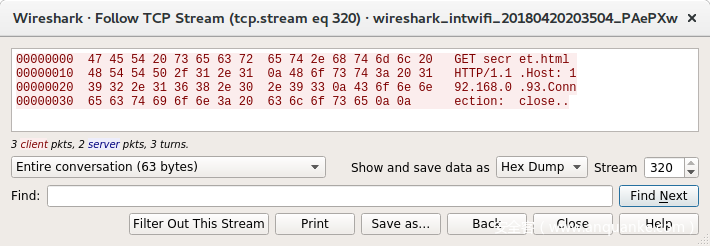
盯着看了一会儿,终于发现了不一致的地方,burp使用的是DOS形式的行尾结束符(rn),而Netcat使用的是Unix结束符(n)。
因为之前我把请求放在文件中,使用vim的话,行尾结束符就会被很容易的修改,打开文件,输入如下内容:

然后保存。如果你不擅长使用vim,你也可以使用dos2Unix包中的unix2dos应用。
转换之后我们再来试一下:

耶,成功了,可以查看到内容。现在我可以通过Netcat复现请求,我们来看看究竟是不是斜线‘/’的问题。加上‘/’之后再试试看:

我们得到的是无法查看。请求secret.html可以访问,请求/secret.html被拒绝。
这种请求无法通过浏览器或者其他工具,因为它们将整个url视为参数,只有那些把主机和文件看做两个独立实体的才能解析这种请求。
虽然一开始我很蒙,搞不明白其中的细微差别,不过现在我可以复现这个问题了。
我觉得我应该找个时间跟开发者聊一聊,看他们知不知道这个问题。
继续深挖
跟做应用测试一样,客户端也要检查服务器配置,因此他们提供了Lighttpd的配置,当我发现下面这一样后,问题随之解决。

看起来非常简单,任何请求以/secret.html开头的页面将会在内部被重定向到/not_permitted.html页面。
但是当我请求secret.html,而不是/secret.html,这个规则就不适用了,我的请求并没有被重定向,所以我能访问到秘密内容。
明白这点后,我想看看是否能够通过curl或者浏览器来查看秘密内容。第一次尝试如下url:

我尝试了curl和很多浏览器,但他们都一样,在发请求之前进行了简化,所以最后还是请求的/secret.html。
我尝试了多重../组合,都失败了。最终下面这条请求成功了:
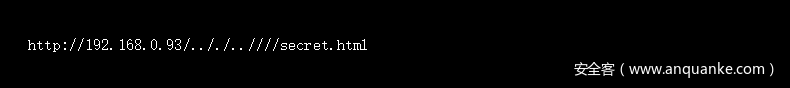
我发现‘.’号会简化,但是多余的‘/’不会。所以下面的url是有效的并且能够访问到秘密内容,因为请求的是//secret.html,这跟它们的正则不匹配。

在众多浏览器中确认过这个url有效之后,我就可以把它作为证据写到报告里作为漏洞利用的例子。
虽然花了一些时间,但总比直接给他们展示一张burp的repeater截图说:“嘿,我看到了你们的秘密内容,但不知道是怎么看到的”。
希望你看完我是符合调试这个漏洞对你有所帮助。这展示了计算机的确定性,任何事情都有原因。
有时候只是需要花点时间来弄明白它的规则,当你知道游戏规则后,你就可以在游戏中轻而易举的获胜,正所谓知己知彼,百战不殆。
测试其他web服务器
我决定对Apache,Nginx和IIS也进行测试,但是都返回“400 Bad request”响应。
Apache

查看错误日志文件,也多了一条记录:

Nginx

Nginx中没有错误日志。
IIS

我没有权限访问IIS日志文件来查看是否有错误日志。
防御
不要在根目录存放秘密文件。如果存放在根目录意外,它依然可以被其他页面调用,但是无法直接通过url访问;
代码层防御,增加过滤函数,添加必要的‘/’,移除所有额外的‘/’;
应用如下规则,提示403禁止访问页面:
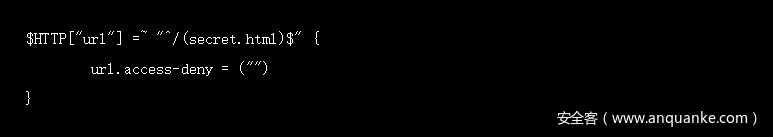
Server.errorfile-prefix选项可以设置为返回一个自定义的403错误页面。
如果你想修复重写规则,最简单的办法就是通过正则匹配移除‘/’:

这条规则会拦截所有访问包含secret.html的请求。如果类似这种文件在这个网站中是唯一的,那么这条规则十分有效。
如果其他人在网站上有一个view_secret.html文件,那么这条规则就会给其他人带来一堆问题,他们看不到自己的页面并且苦恼的琢磨着为什么。
下面这个规则更好,无论secret.html前面跟着多少个‘/’,都重定向到禁止页面。

我觉得这也不是最好的解决方案,因为可能会有其他字符插入到文件名中来绕过规则。
最后一条建议依赖于secret.html的目的。
如果它是一个模板文件,被其他文件引用,那么可以在文件中添加一些逻辑,只有通过正确访问才显示内容,否则不显示内容,
比如对引用它的文件做相同的认证和授权检查。
审核人:yiwang 编辑:边边







发表评论
您还未登录,请先登录。
登录