

前言
近期在研究符号执行相关的技术。近年利用符号执行进行分析的论文在安全的顶会中出现较为频繁,因此,笔者在本文中将做一份总结和近期学习的知识分享。会由浅入深的从符号执行的基础讲起,再延伸到目前科技的最前沿,带领大家看看在符号技术利用方面,到底发展到什么程度的。
符号执行入门
那么什么是符号执行(symbolic execution)技术呢?Wiki中的定义是:在计算机科学中,符号执行技术指的是通过程序分析的方法,确定哪些输入向量会对应导致程序的执行结果向量的方法。通俗的说,如果把一个程序比作DOTA英雄,英雄的最终属性值为程序的输出(包括攻击力、防御力、血槽、蓝槽),英雄的武器出装为程序的输入(出A杖还是BKB)。那么符号执行技术的任务就是,给定了一个英雄的最终属性值,分析出该英雄可以通过哪些出装方式达到这种最终属性值效果。(咚咚咚!LGD明年还会回来的!)
可以发现,符号执行技术是一种白盒的静态分析技术。即,分析程序可能的输入需要能够获取到目标源代码的支持。同时,它是静态的,因为并没有实际的执行程序本身,而是分析程序的执行路径。如果把上述英雄的最终属性值替换成程序形成的bug状态,比如,存在数组越界复制的状态,那么,我们就能够利用此技术挖掘漏洞的输入向量了。
这里再举一个简单的例子,让大家有深刻的理解。
以下面的源代码为例子:
int m=M, n=N, q=Q;
int x1=0,x2=0,x3=0;
if(m!=0)
{
x1=-2;
}
if(n<12)
{
if(!m && q)
{
x2=1;
}
x3=2;
}
assert(x1+x2+x3!=3)
上述代码是一个简单的c语言分支结构代码,它的输入是M,N,Q三个变量;输出是x1,x2,x3的三个变量的和。我们这里设置的条件是想看看什么样的输入向量<M,N,Q>的情况下,得到的三个输出变量的和等于3. 那么我们通过下面的树形结构来看看所有的情况:
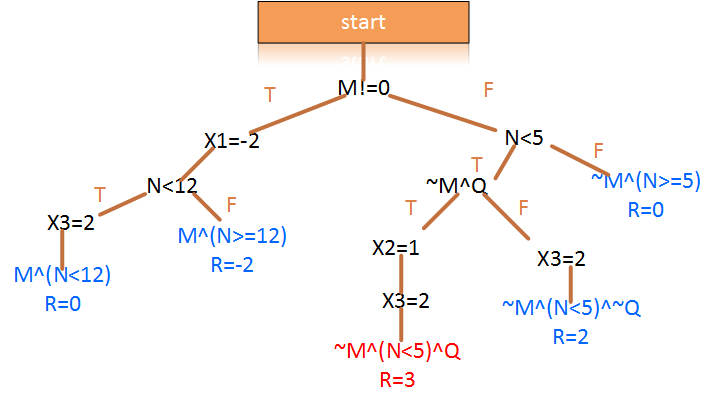
上面的分析图把所有可能的情况都列举出来了,其中,叶子节点显示的数值表示当前输入情况下,可以得到的数值。(比如,如果英雄出装是M^(N<12),那么最终的属性值R=0)。其中M^(N<12)表达的是,M是非零值且N要小于12,Q为任意值的情况下,得到R=0。可以发现,当条件为~M^(N<5)^Q时,得到了最终结果等于3.即,我们通过这种方式逆向发现了输入向量。如果把结果条件更改为漏洞条件,理论上也是能够进行漏洞挖掘了。
对于如何根据最终得到的结果求解输入向量,已经有很多现成的数学工具可以使用。上述问题其实可以规约成约束规划的求解问题(更详细的介绍看这里:Constraint_programming )。比较著名的工具比如SMT(Satisfiability Modulo Theory,可满足性模理论)和SAT。
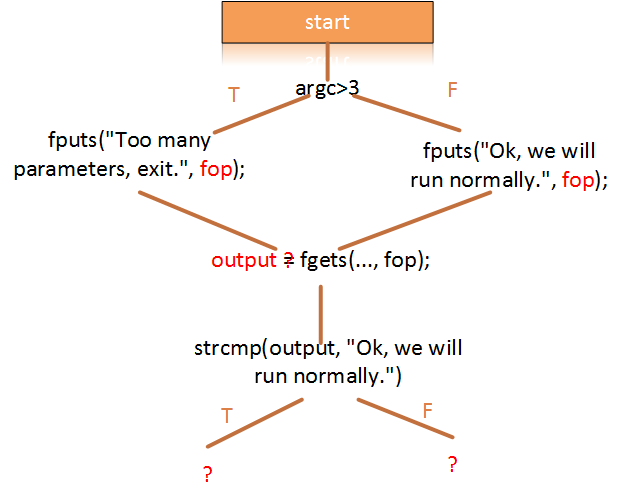
但是在实际的漏洞分析过程中,目标程序可能更加复杂,没有我们上面的例子这么简单。实际的程序中,可能包含了与外设交互的系统函数,而这些系统函数的输入输出并不会直接赋值到符号中,从而阻断了此类问题的求解。比如下面的这个包含了文件读写的例子:
int main(int argc, char* argv[])
{
FILE *fop = fopen("test.txt");
...
if(argc > 3)
{
fputs("Too many parameters, exit.", fop);
}
else
{
fputs("Ok, we will run normally.", fop);
}
...
output = fgets(..., fop);
assert(!strcmp(output, "Ok, we will run normally."));
return 0;
}
上述示例代码中,想要发现什么情况下会得到输出”Ok, we will run normally.”这个字符串。通过一系列的执行到if语句,此时,根据输入的参数个数将会产生两个分支。分支语句中将执行系统的文件写操作。在传统的符号执行过程中,此类函数如果继续沿着系统函数的调用传递下去的话,符号数值的传递将会丢失。而在之后的output = fgets(…, fop);这行代码中,符号从外部获得的数值也将无法正常的赋值到output中。因此,符号执行无法求解上述问题,因为在调用系统函数与外设交互的时候,符号数值的赋值过程被截断了。
为了解决这个问题,最经典的项目就是基于LLVM的KLEE(klee)它把一系列的与外设有关的系统函数给重新写了一下,使得符号数值的传递能够继续下去。从比较简化的角度来说,就是把上面的fputs函数修改成,字符串赋值到某个变量中,比如可以是上面的fop里面。再把fgets函数修改成从某个变量获取内容,比如可以是把fop的地址给output。这样,就能够把符号数值的传递给续上。当然,这里举的例子是比较简单的例子,实际在重写函数的时候,会要处理更复杂的情况。在KLEE中,它重新对40个系统调用进行了建模,比如open, read, write, stat, lseek, ftruncate, ioctl。感兴趣的读者可以进一步阅读他们发表在OSDI2008年的论文(KLEE-OSDI08)他们的文章深入浅出,非常适合学习。
符号执行上高速
近几年,由于物联网设备逐渐的大众化,嵌入式设备的漏洞挖掘需求更加显著。那么在嵌入式的环境下,使用符号执行技术挖掘漏洞可行吗?答案是肯定的。但,需要解决的问题除了类似于KLEE中出现的与外设交互的系统调用建模以外,还需要解决嵌入式设备中经常出现的混合代码情况。即,给出的嵌入式源代码中,有c语言代码、二进制代码(共享库)和汇编代码。面对这种情况应该如何启用符号执行呢?
我们来看看下面的基于ARMv7架构的一个例子,
unsigned char msg[] = "world";
int index;
void uart_send(unsigned char a)
{
__asm volatile("SVC #0");
__asm volatile("BX LR");
}
void os_uart_send(){...}
int main(int argc, char* argv[])
{
uart_send(msg[index++]);
return 0;
}
上述嵌入式代码有高级语言的C代码,以及还有ARMv7的汇编代码。嵌入式应用程序中写汇编代码的目的通常是为了使得程序的执行效率更高。该代码的主要作用是通过uart发送消息。函数uart_send()中,通过指令“SVC #0”切换成SVC的寄存器模式之后,将实际上调用函数os_uart_send()发送消息。其中,uart_send函数的参数将直接在os_uart_send()函数中使用。上述代码,通过LLVM转换成LLVM-IR的形式,为下面的代码。
@msg = global [6xi8]c"world0"
@index = global i32 0
define void @uart_send(i8 zeroext) #0
{
entry:
call void asm sideeffect "SVC #0",""()
call void asm sideeffect "BX LR",""()
unreachable
}
define void @os_uart_send(){...}
define int @main() #1
{
entry:
%0 = load i32* @index
%inc = add nsw i32 %0, 1
store i32 %inc, i32* @index
%arrayidx = getelementptr inbounds [6xi8]* @msg, i32 0, i32 %0
%1 = load i8* %arrayidx
call void @uart_send(i8 zeroext %1)
ret i32 0
}
为什么要转换成LLVM-IR的代码呢。LLVM-IR是LLVM的一种中间的语言表达形式,也是一种汇编语言的形式。现有的KLEE工具就是LLVM-IR工具实现的符号执行虚拟机。在解释上面的代码之前,简单介绍几个LLVM-IR的基础语法,以便更清楚的理解。
LLVM-IR的变量有三种,通过前缀@或者%的形式区分,其中@表示全局变量,%表示局部变量:
- %或者@接数字,表示的是临时变量,在一个函数中,从0开始编号使用。比如%0,%1,。。
- %或者@接字符串,表示有名字的变量,可以任意使用;
- 第三类就是立即数
@msg = global [6xi8]c"world0"
@index = global i32 0
上述代码初始化了全局变量msg和index。
entry:
%0 = load i32* @index
%inc = add nsw i32 %0, 1
store i32 %inc, i32* @index
上述代码中,i32表示是32位的类型,i32表示的指向i32类型的指针类型。%0 = load i32 @index表示将全局变量index的值赋值给局部变量%0. Add nsw是有符号的相加。再加完之后,又把数值存储回了全局变量index。
%arrayidx = getelementptr inbounds [6xi8]* @msg, i32 0, i32 %0
%1 = load i8* %arrayidx
call void @uart_send(i8 zeroext %1)
上述代码中,[6xi8] 这种形式表示的是数组类型,这里就是含有6个8位的元素的数组。Getelementptr inbounds即使获得数组对应元素的指针。之后利用语句%1 = load i8* %arrayidx获取指针指向的8位的值,在传入到函数uart_send中执行。
可以发现,如果按照已有的KLEE方法,在转换成LLVM-IR代码之后,由于代码中含有arm架构的汇编,而该arm代码中没有明显的调用参数的代码和方式,使得符号数值的传递再次中断,导致KLEE方法不能执行。因此,我们需要对上述含有混合LLVM-IR代码的内存进行再次转化,使得含有低级语意的arm汇编也能够被KLEE的符号执行虚拟机分析。
最近在安全顶会USENIX Security18上发表的论文Inception,正是完成了上面的这件事情。它通过程序分析的方式,将混合油高级语言和低级语言的代码同时转化成KLEE能够分析的语言,从而执行符号执行的分析。根据Inception里面的思想,上述LLVM-IR转化之后,可以有下面的表达形式:
@msg = global [6xi8]c"world0"
@index = global i32 0
; stack is stored in global variables
@R0 = global i32 0, align 4
@SP = global i32 0, align 4
@_SVC_fe = global i32 0, align 4
@LR = global i32 0, align 4
@.stack = global [8202xi4] zeroinitializer
define void @uart_send(i8) #0
{
; pass the parameters from high level to the low level.
entry:
%1 = zext i8 %0 to i32
store i32 %1, i32* @R0
br label %"uart_send+0" ; jmp to the actual code
"uart_send+0":
%SP1 = load i32* @SP ; load the stack pointer
store i32 0, iew* @_SVC_fe
store i32 268436580, i32* @PC ; store pointer execution
call void (...)* @_sv_call()
call void (...)* os_uart_send() ; invoke uart send function and using the value from the R0
%LR1 = load i32* @LR1 ;load return address
ret void
}
define void @os_uart_send(){...}
define int @main() #1
{
entry:
%0 = load i32* @index
%inc = add nsw i32 %0, 1
store i32 %inc, i32* @index
%arrayidx = getelementptr inbounds [6xi8]* @msg, i32 0, i32 %0
%1 = load i8* %arrayidx
call void @uart_send(i8 zeroext %1)
ret i32 0
}
可以发现,相比于之前的LLVM-IR。函数uart_send中多了一部分内容。
; stack is stored in global variables
@R0 = global i32 0, align 4
@SP = global i32 0, align 4
@_SVC_fe = global i32 0, align 4
@LR = global i32 0, align 4
@.stack = global [8202xi4] zeroinitializer
这部分代码对于arm汇编中只用的寄存器架构搬移了出来,并且声明成了全局变量的形式,之后,arm在寄存器和栈中的操作,都会转化成在上述全局变量中的操作。
entry:
%1 = zext i8 %0 to i32
store i32 %1, i32* @R0
br label %"uart_send+0" ; jmp to the actual code
上述代码的主要功能是讲参数msg[i++]获得的值传递给寄存器R0中,这种显示的表达,将使得符号的数值传递串联起来。%1 = zext i8 %0 to i32表示将参数i8转化成i32。store i32 %1, i32* @R0表示将转化后的内容%1存储到寄存器R0中。Br是条件跳转语句,在这里,br将执行无条件跳转到”uart_send+0”中。
"uart_send+0":
%SP1 = load i32* @SP ; load the stack pointer
store i32 0, iew* @_SVC_fe
store i32 268436580, i32* @PC ; store pointer execution
call void (...)* @_sv_call()
上述代码主要为转换arm的寄存器模式为SVC模式。
call void (...)* os_uart_send() ; invoke uart send function and using the value from the R0
%LR1 = load i32* @LR1 ;load return address
上述内容则调用了函数os_uart_send,并使用了参数R0。因此,完成了符号数值的传递。上述寄存器的赋值,以及该系统函数的调用,可以转化成语意为调用了R0参数的函数调用。Arm的函数调用规范见ABI
更详细的arm指令可以参考arm
LLVM-IR的参考可以见LLVM-IR
Inception项目的安装可以基于docker,使得操作更加简单了Inception-docker-install
总结
总体来说,现有的符号执行工具,在开源方面,主要还是基于KLEE项目的。可见对于KLEE项目的深入理解,将有助于我们打造更加高效的工具。有了高效的工具,就能够使得我们一边学习理论,一遍验证,从而走上高速公路。Inception工具是就ARM架构,而对于路由器中常使用的MIPS架构,就笔者现在所知,现在还尚未有类似的符号执行工具发布(如果已经由类似工具,欢迎读者留言)。其中,基于IDA的脚本工具bugscam,经过揭秘路由器0DAY漏洞的作者修改之后,也能够支持分析MIPS架构的漏洞了。然而,其误报率非常之高,笔者在使用了之后,发现该工具报告的漏洞基本都不可用。因此,如何基于上述符号执行的思想,结合IDA工具中强大的反汇编能力,开发也具有符号执行功能的MIPS架构漏洞分析工具,相信也是非常有价值的。由于时间仓促,笔者对于一些部分的理解难免有误,望各位读者见谅以及不吝赐教。感谢。







发表评论
您还未登录,请先登录。
登录