

 投稿
投稿






背景
Fuzzer是一种通过产生一系列非法的、非预期的或者随机的输入向量给目标程序,从而完成自动化的触发和挖掘目标程序中的安全漏洞的软件测试技术。相比于形式化的软件漏洞测试技术(比如,符号执行技术 ),Fuzzer往往能够在实际的应用中挖掘更多的漏洞。形式化的漏洞挖掘技术的优势在于其不需要实际执行程序,然而在处理程序底层的某些操作(比如函数的虚指针)时,现有的符号执行技术往往不能做到精准的分析。因此,这两种技术在实际的应用中各有优劣。
一个形象的Fuzzer例子就比如下面让一个猴子去测试应用程序。通过让它胡乱点击电脑的键盘或者移动鼠标,产生不在预期内的输入,从而发现目标程序的bug。(Android应用测试中的Monkey测试也是类似的,它通过胡乱点击Android手机上所有可见的控件,进行压力测试,当Android应用出现闪退或者不能响应的问题时,bug也就发现了)

漏洞测试猿(盗图自:参考)
可以发现,完成一个Fuzzer的过程,包括:一只猴子(fuzzer 输入构造模块)、一个可以运行的程序以及崩溃的程序捕捉(fuzzer的错误反馈与捕捉)。
基于变种的Fuzzer(Mutation-based)
上面的Fuzzer方式虽然能够发现一些错误,但是由于猴子产生的输入实在太过随机,大部分的输入都是不合法的,这些不合法的数据往往会被目标程序识别而丢弃(比如,对于不符合通信协议规范的数据包,接收方会直接过滤掉)。因此,这种测试方式的实际效率是很低的。为了解决这个问题,一种Fuzzer被提出来:基于变种的Fuzzer(mutation-based fuzzer)。它的关键在于变种。同样是产生非预期的输入,基于变种的Fuzzer不再是胡乱的产生输入,而是在已知合法的输入的基础上,对该输入进行随机变种或者依据某种经验性的变种,从而产生不可预期的测试输入。典型的工具有:Taof, GPF, ProxyFuzz, Peach Fuzzer。
比如,如果打算使用Peach Fuzzer中的mutation功能来fuzz一个PNG图片的绘图器(windows里面的mspaint,Linux里面的feh,OSX里面的Safari),就有以下的大致流程。
一个PNG图片的典型格式如下:
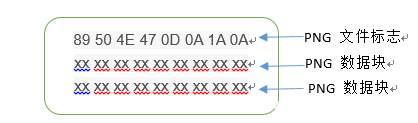
一个PNG的图片总是以上述的一串固定字节开始的。其中0x89超出了ASCII字符的范围,这是为了避免某些软件将PNG文件当做文本文件来处理。文件中剩余的部分由3个以上的PNG的数据块(Chunk)按照特定的顺序组成。
在拿到了多张合法的PNG图片之后,Peach Fuzzer中一种最简单的变种方式就是随机置换模式(random)。即,将除了头部PNG标志以外的数据,将其他位置的数据进行随机的变换。根据上述需求,Peach Fuzzer的一种典型的配置文件可以按照下面的方式撰写:
---png.xml---
<Test name="Default">
<Agent ref="WinAgent" platform="windows"/>
<StateModel ref="TheState"/>
<Publisher class="File">
<Param name="FileName" value="fuzzed.png"/>
</Publisher>
<Strategy class="Random"/>
<Logger class="Filesystem">
<Param name="Path" value="logs" />
</Logger>
</Test>其中,agent 标签中可以进一步配置执行的程序以及导入的参数,比如:
<Param name="CommandLine" value="mspaint.exe fuzzed.png" />mspaint.exe是windows下面的绘图程序,fuzzed.png是变种之后的png图片。可以在上述配置文件中看到在标签Publisher中设置了变种之后的文件名称为fuzzed.png。
标签StateModel中定义的是一些与PNG测试相关的参数,比如,设置合法输入的文件路径:
<Data name="data" fileName="samples_png/*.png"/>其中,文件夹samples_png下面放置的都是合法的png图片,之后的变种测试文件都是基于这个目录下面的文件而来的。
标签Strategy就是设置变种的策略为随机的模式(random)。
标签Logger里面定义的是发现错误或者bug时信息记录的位置。
最后,使用下面的命令就可以利用Peach Fuzzer进行PNG的绘图工具测试了:
peach png.xml
基于模板的Fuzzer(Generation-based)
可以发现,基于变种的Fuzzer对于合法的输入集合有较强的依赖性。为了能够测试尽可能多的输入类型,必须要有足够丰富类型的合法输入,以及花样够多的变种方式。想要花样足够多的变种方式都被测试一遍,将会花费较多的测试时间。如果测试人员对目标程序或者协议已经有了较为充分的了解,那么也有可能制造出更为高效的Fuzzer工具。即,测试的目的性更强,输入的类型有意识的多样化,将有可能更快速的挖掘到漏洞。这类方法的名称叫做基于模板的Fuzzer(Generation-based)。正如其名,此类Fuzzer工具的输入数据,依赖于安全人员结合自己的知识,给出输入数据的模板,构造丰富的输入测试数据。
典型的工具有:SPIKE, Sulley, Mu‐4000, Codenomicon,等等。
下面我们就以fuzz一个刻意构造的具有的漏洞的windows程序,来解释一下基于模板fuzz的过程。
可运行的目标程序:vulnserver。 这是一个基于windows的带有漏洞的程序。(它包括主程序和dll程序,两个得放在一个目录下面才可以。)
聪明一点的猴子:SPIKE。
反馈消息捕获:利用OD,wireshark等工具。
在配置和安装SPIKE的时候,可能会出现无法找到aclocal-1.1x的问题,那么就执行下面的命令:参考
autoreconf -f -i.然后再:
./configure && make一个典型的POST请求格式如下面所示:
POST /testme.php HTTP/1.1
User-Agent: Mozilla/4.0
Host: testserver.example.com
Content-Length: 256
Connection: close
inputvar=admin根据已有的工作对vulnserver的分析,可以发现其中可以fuzz的字段如下面所示:
[fuzzable] [fuzzable] HTTP/1.1
User-Agent: [fuzzable]
Host: [fuzzable]
Content-Length: [fuzzable]
Connection: [fuzzable]
inputvar=[fuzzable]那么,根据上面分析的潜在的fuzz输入点,可以利用SPIKE构造测试脚本了。以testme.php为例子的话,可以构造下面的脚本:
//vul.spk
s_string("POST /testme.php HTTP/1.1rn");
s_string("Host: testserver.example.comrn");
s_string("User-Agent: ");
s_string_variable("Mozilla/4.0");
s_string("Content-Length: ");
s_blocksize_string("block1", 5); // [正统的fuzz方式]增加一个5字符长度的内容来表示后面用block包含起来的payload长度。
//s_string_variable("200"); //[可选的fuzz方式],对content-length进行任意的fuzz
s_string("rnConnection: closernrn");
s_block_start("block1");
s_string("inputvar=");
s_string_variable ("abcdefg");
s_block_end("block1");这里解释一下上面的脚本语法。
s_string()是利用SPIKE产生一个固定的字符串,用这个语法,表示SPIKE不会改变这个字符串的内容。
s_string_variable()表示SPIKE可以改变这个位置的字符串内容。比如:
s_string("CDF");
s_string_variable ("666");运行出来的结果是:
CDF666
CDF667每次变化的是后面的666,前面的CDF是不会变化的。
s_blocksize_string(‘blockx’)表示会自动计算后面的用blockx标记的块中的字符串长度大小,这个语法经常用来统计content-length里面。从上面的脚本中也可以发现,也可以不利用这个语法,而是直接利用s_string_variable()来对于目标的长度也进行任意的测试。
s_block_start(“block1”);和s_block_end(“block1”);表示一个数据块的开始和结束。这个里面的内容,可以被s_blocksize_string()用来统计长度。
接下来,当在目标主机上开启了vulnserver.exe之后,就可以在攻击主机上运行下面的命令来进行fuzz了:
generic_send_tcp 192.168.1.121 9999 vul.spk 0 0其中generic_send_tcp是在编译了SPIKE之后的一个常用的发送POST请求的工具。它的用法是这样的:
./generic_send_tcp ip port something.spk SKIPVAR SKIPSTRSKIPVAR表示选择第几个s_string_variable开始进行变种测试。这种设置可以使得前面已经测试过的位置不在重复测试。比如,我们上面的vul.spk有两个s_string_variable。
SKIPSTR表示从s_string_variable的第几个字符开始变种测试。比如第一个s_string_variable是Mozilla/4.0,偏移为1的话,就是从o开始变种测试。
测试启动之后,应该有下面类似的结果:

在被测试的目标主机上,可能会有这样类似的结果:
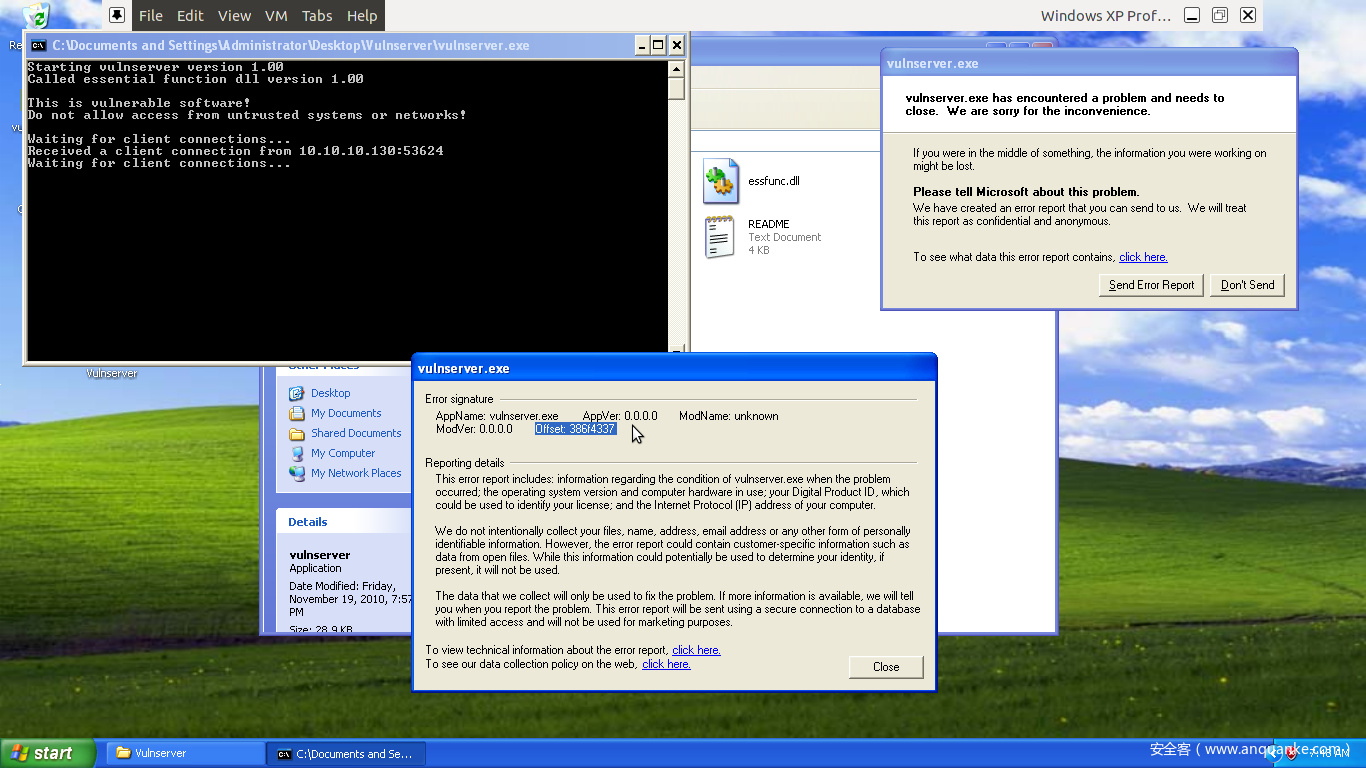
接着,通过在wireshark上观察造成这种结果的数据包,来逆推造成程序崩溃的输入。再利用OD等调试工具来确认vulnserver.exe中出现漏洞的实际位置,从而分析原因。
基于反馈演进的Fuzzer(Evolutionary-based)
然而,不论是上面的变种Fuzzer还是模板Fuzzer,仍然会面临挖洞效率低的问题。对于变种测试,由于依赖基础的合法输入,那么到底选择多少合法输入才能穷尽的覆盖到尽可能多的测试点呢?对于模板测试,Fuzzer会按照我们设定好的测试点尝试之后停止,但是,这样就足够了吗,这样就能够真正的覆盖到所有的测试点了吗?
可以发现,我们在使用上面两种fuzzer的时候,脑海里面始终会想起一个问题:这样的脚本/随机化的处理方法,真的能够穷尽的fuzz到所有的地方了吗?这便引出了fuzz工具里面一个经典的问题,fuzz的覆盖率问题。简单来说,我们一种指标来衡量,fuzz工具是不是真正的覆盖到了我们想要覆盖的所有范围。当然,有时候,覆盖所有的范围将会消耗的时间,这就需要测试人员来权衡时间和覆盖率了。这就引出了新的一类方式,基于反馈演进的Fuzzer。即,此类Fuzzer会实时的记录当前对于目标程序测试的覆盖程度,从而调整自己的fuzzing输入。听起来是不是更加智能了?^_^
其中,程序的覆盖率是一个此类方法的核心。目前,有以下几个代码覆盖率指标在演进模糊测试里面会经常碰到:
A. 路径覆盖率。(可以有类似的利用BL算法的路径标记和压缩算法。)
B. 分支覆盖率。
C. 代码行覆盖率。
比如下面的例子:
If( a> 2)
a=2;
if (b > 2)
b=2;
else
a=3;b=4;多少个测试数据集可以覆盖100%的代码行?——2个数据集(a=3,b=3; a=3,b=2)
多少个测试数据集可以覆盖100%的分支?——4个数据集(a=3,b=3; a=1, b=3; a=3,b=2; a=1,b=2)
多少个测试数据集可以覆盖100%的路径?—— 4个数据集(a=3,b=3; a=1, b=3; a=3,b=2; a=1,b=2)
其中,比较常见的指标是分支和路径的覆盖率。根据上面的定义,我们想要获得程序测试的反馈,得要对原有的程序进行注入,追踪程序执行了哪些分支或者路径,在和整个程序包含的所有分支或者路径相比较,从而调整fuzz的输入。
基于追踪路径覆盖率的方法
比如,我们仍然以上面的例子来解释的话,最简单的方法就是在每个代码块中注入,最终输出全部的路径。我们以产生分支条件来区分不同的代码块,那么就有如下的代码块切分方式以及程序注入方式:
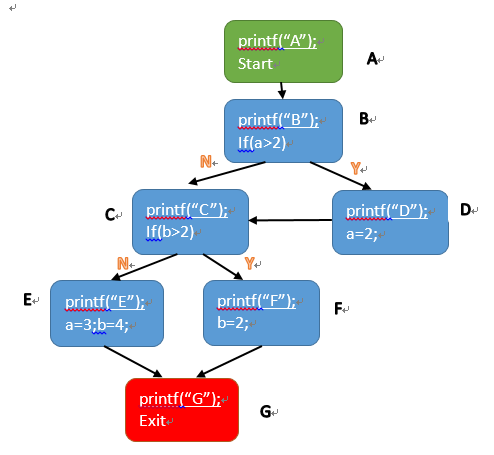
上图中,白色的下划线为注入的打印log,用来记录执行的路径。
因此,当输入为a=3,b=3的时候,输出的路径为:ABDCFG
当循环变多以后,输出的路径会很长,不利于高效率的比较。因此,后来又许多的路径编码的算法,将上述的路径编码为某个数字。比如下面的方法,取自PAP,即profile all path:
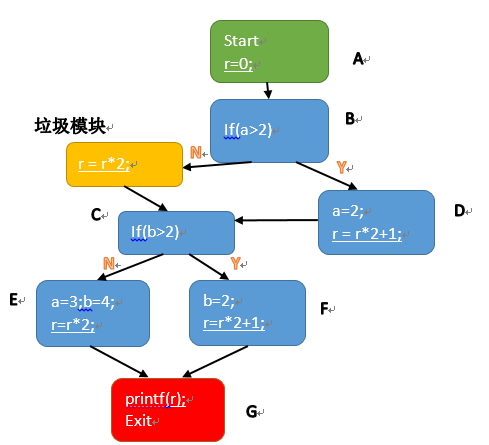
PAP的思想就是,看看每个具有多个入度的代码块。有n条入度,则在每个入度的边上注入语句r=r*n+n%i; 其中i就是第i入度边。通过这种余数的方式来区分不同的边,通过不断的乘以n来区分不同的条件分支或者循环分支。
比如代码块C,它有从if条件语句过来的两条入度,a>2或者a<=2。假设有两个入度,那么就就注入了两条语句r=r*2以及r=r*2+1。为了能够区分if(a>2)这个语句的分支,我们增加了一个垃圾模块,即把原来的语句改造成了:
If(a>2){ a=2;
r=r*2+1;
}else{ //垃圾模块
r=r*2;
}同样的例子,当输入为a=3,b=3的时候,输出的数字为3,对应的路径为:ABDCFG。
通过仅仅比较数字的大小就知道哪些路径已经执行了,这是非常有利于提高效率的。除了PAP方法,在更早的时候,还有一种方法,它能够将路径进行更好的压缩,比如B.L.。假设总共有m条路径,那么它可以将路径压缩为[0,n-1].
笔者曾经实现过一个针对Android smali语言的全路径追踪算法。即通过对smali文件进行代码注入的方式,追踪Android程序执行了哪些路径。路径执行完之后,会得到一个数字,该数字即对应着一个路径。该项目是早期写的,基于的算法是[B.L.] (https://www.cs.purdue.edu/homes/xyzhang/spring10/epp.pdf)。感兴趣的同学可以看看相关的参考资料。
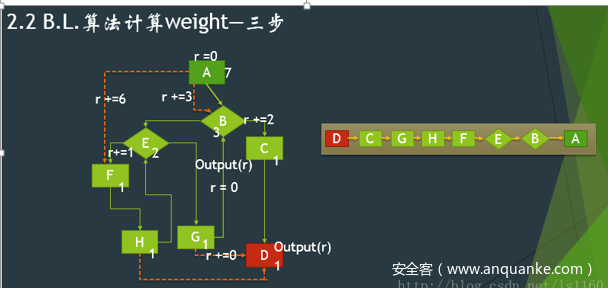
基于分支覆盖率的方法
可以发现,路径覆盖率的方式有一个不好的点,就是后面会产生路径爆炸的问题。因此,后来的方法更倾向于使用基于分支覆盖的方式。漏洞的爆发也往往由于触发了非预期的分支造成的。比如,一个著名的fuzz工具AFL(american-fuzzy-lop,中文名是美种费斯垂耳兔)利用的就是就分支的覆盖方式。这个技术部分已经有同学分析过了,感兴趣的同学可以看看资料。
著名Fuzz工具AFL的使用
前面既然提到了著名的fuzz工具AFL,这里就抛砖引玉介绍一下它的基本使用方式。更深入的技术细节已经有很多文字分析过了,感兴趣的同学可以看看文末的参考文献。
这里介绍的参考案例参考自网上的资源,它介绍了如何利用AFL对LibTIFF进行模式测试,我看了诸多的例子,认为还是这个比较容易入门。整体的流程与该网上介绍的流程差不多,这里就提示两个地方,文中没有声明的。
第一,如果在执行AFL的时候出现了问题,那么就按照提示来进行补充安装就好了。比如,在我的程序中,出现了一个问题,是要修改core dump notification的设置。
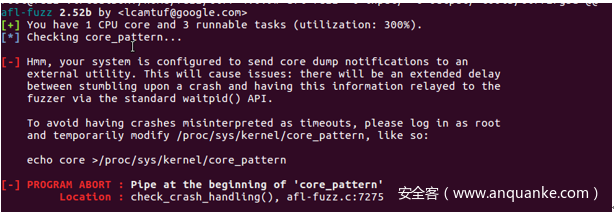
那么就在ubuntu中以root登录,然后执行
echo core >/proc/sys/kernel/core_pattern,就可以。
第二,测试样例是需要在这个网址下载使用的:http://lcamtuf.coredump.cx/afl/demo/
选择下载所有的测试数据集。
拷贝到input里面,然后执行命令(直接拷贝参考链接中的命令将会执行不成功,因此应该是这样的)
afl-fuzz -i input/ -o output/ tools/ tiff2rgba @@接下来就出现类似的执行界面,开始进行fuzz
接着就是等待测试的结果了。
研究界在Fuzzer方面的进展
近年来,学术界也对Fuzzer技术有较为密切的关注。在今年,信息安全的顶级会议S&P2018、NDSS2018、CCS就有好多篇文章关于Fuzzer。
比如CCS的这两篇:Hawkeye: Towards a Desired Directed Grey-box Fuzzer,Revery: from Proof-of-Concept to Exploitable (One Step towards Automatic Exploit Generation)。S&P的CollAFL: Path Sensitive Fuzzing ,T-Fuzz: fuzzing by program transformation ,Angora: Efficient Fuzzing by Principled Search 。
上述介绍的基于变种的Fuzzer工具中有一个较为严重的问题:当生成变种的输入之后,变种的输入向量很有可能会被目标程序的校验程序给过滤掉,比如CRC校验,hash校验等。这样会大大降低fuzz的效率,因为变种产生的是大量无用的输入,这些输入对于最终探索的路径覆盖率的贡献是较低的。而且,对于某些藏的比较深的bug,比如,有多个校验条件保护的bug,是比较难发现的。
为了解决这个问题,S&P18的工作T-Fuzz提出了一个思路:相比于已有的方法利用符号执行等方式去求解那些合法的输入(符号执行的基础内容可以看符号执行——从入门到上高速),它直接将目标程序中的校验语句给去除,然后进行fuzzing测试,找到了bug之后,再看看触发bug的这些输入会不会通过校验测试。这样,从发现的bug里面验证是否输入合法,相比于正向的去求解总共有哪些合法的解,复杂性要大大降低很多。
为了说明这个问题,这篇文章举了一个具体的例子,这个例子中的代码主要用来解析和解压某种文件格式:

可以发现,在C1部分它检测了特定的文件格式头部,即头部是否是‘SECO’;第二个C2检测了数据合理性范围;第三个C3检测了数据的CRC。可以发现,要通过这么多的阻碍,找到最终的bug在deccompress()这个函数,它的求解复杂度是很大的。那么通过先删除这些check,再检验触发bug的输入是否能够通过验证请求,将会使得问题更加容易解决。
总结
最终,总结一下今天所介绍的技术。本文首先介绍了最原始的monkey测试,并且引入monkey测试里面的所体现的fuzzer的模块:目标程序、fuzz输入生成和bug反馈捕获。接着,由于monkey产生输入的无目标性,本文介绍了一种相对智能一点的方式,通过变种已有合法输入的方式,提高测试的效率。然后,当测试人员对于目标程序相对熟悉的时候,本文介绍了另一种fuzzing方式,基于模板的fuzzer,并且介绍了典型的模板fuzzer SPIKE的典型使用方式,让大家有了更为深入的了解。随着fuzz的进步,想要测试到更多的bug,需要有更为合理的指标去调整fuzz的策略,因此,本文介绍了新的fuzzing方式,基于反馈演进的fuzzer。并且介绍了两个fuzzing的指标:基于追踪路径覆盖率和基于追踪分支覆盖率的方式。最后,本文还介绍了研究界fuzzer的最新进展。希望本文能够让大家对于fuzzer有更深刻的了解。如果文中有理解不正确的地方,还望各位不吝赐教。
相关参考:
American Fuzzy Lop。
http://lcamtuf.coredump.cx/afl/
它由google project zero的Michal Zalewski (lcamtuf)开发的。
其后还有基于windows版本的fuzzer,WinAFL
https://github.com/googleprojectzero/winafl
AFL内部实现细节一览
AFL技术白皮书
https://blog.csdn.net/gengzhikui1992/article/details/50844857



