

对一种非常有趣的DGA的分析文章,该DGA使用虚拟机作为保护措施。原文较长,故分为两个部分,第一部分先介绍对虚拟的逆向分析,第二部分介绍DGA的实现。
Pitou的域名生成算法(DGA)是迄今为止我逆向过的最难的DGA,其在内核模式下运行,并受到虚拟机的保护。在引文之后,本文将展示Pitou的虚拟机是如何工作的。之后,将介绍两种对字节码进行逆向的方法。最终,我会从Pitou中将DGA提取出来,用python进行复现 。完这篇文章的附录部分是完整的虚拟指令集的文档。
引文
在我看来,域名生成算法是一个恶意软件中最容易被人弄清的部分。对于一个没有加壳的样本,人们通常可以在几个小时内对算法进行逆向。为什么会这样呢?
- 大部分DGA通常没有明显的保护措施。
- 大部分DGA相对容易本地实现。无论是通过API调用,如DnsQuery和gethostbyname,还是通过模拟,例如add al, 61h 。
- 大部分DGA是简洁易懂的。如果使用Hex Rays这样的反编译器,分析更加容易,可以生成非常接近源代码的结果。
- DGA的模式基本上是清晰的。例如,组成域名的字母是通过将一个随机数映射到字母a-z的方法在循环中确定的。
Pitou的DGA与一般的DGA有四个不同点:
- 整个域名生成算法,包括种子,都是虚拟化的。虚拟机是一种特别有效的代码保护形式,分析起来很有挑战性,或者至少非常耗时。
- Pitou是一个具有动态解析API调用的木马(rootkit)。此外,Pitou使用NDIS钩子来隐藏网络通信。由于第1点中给出的原因,使用通常的DGA模式是不可行的。
- DGA非常长,对于种子需要进行复杂的基于日期的计算。
- DGA有两个严重的错误(bug),这使得它更加难以理解。
这些原因,尤其是第一个原因,使得Pitou成为迄今为止我分析的最难的域名生成算法。
前人的工作
这篇博客文章专门分析Pitou的DGA,故不涉及所有其他方面。
2014年8月,F-Secure研究人员发表了一篇关于Pitou的优秀报告,我强烈建议阅读该报告,以便了解更多关于Pitou的特性。随附的博客文章简要回答了关于Pitou的最重要的问题。该报告中有一个关于DGA的专门章节,其中提到了算法的一些属性。但是,没有列出算法本身,也没有列出运行DGA的虚拟机的详细信息。
2016年1月,赛门铁克(Symantec)在其安全中心发布了一篇Pitou的文章。它列出了恶意软件可能连接到的20个域名,但没有提到这些域名仅具有有限的生命周期。
2018年1月,TG 软件研究中心(C.R.A.M.)发布了一篇关于Pitou的博客文章。该文章列出了四个域名,但是没有提到,更没有讨论产生这些域名的域名生成算法。
在这篇博文发布的14天前,Brad Duncan在SANS Internet Storm博客上发表了一篇标题为Rig Exploit Kit send Pitou.B Trojan的日志。他还在自己的个人博客上写了两篇关于另外两个不同的Pitou样本的文章。这表明即使在F-Secure报告的5年后,Pitou和它的DGA仍然是相关的。正如博客文章末尾的表格所示,带有原始种子的DGA仍然在使用,这可能要归功于对DGA的良好保护。
域名例子
下面的Wireshark截图显示了2019年6月20日查询的20个域名:

这些域名使用一些不常见的顶级域,如.mobi和.me,尽管这些域名的辅音和元音在某种程度上交替使用,来产生类似可发音的效果,但是依然可以很容易通过人工检查出来。
本次分析样本
我对以下文件进行了逆向,它被ESET、Ikarus和Microsoft检测为Pitou。
| MD5 | 28060e9574f457f267fab2a6e1feec92 |
| SHA1 | 9529d4e33498dd85140e557961c0b2d2be51db95 |
| SHA256 | 43483385f68ad88901031ce226df45b217e8ba555916123ab92f63a97aef1d0e |
| 文件大小 | 522K |
| 编译时间戳 | 2017-10-31 10:15:25 UTC |
| 链接 | VirusTotal |
将文件解压缩到二进制文件,解压后Avast、AVG和Fortinet也将其检测为Pitou。
| MD5 | 70d32fd5f467b5206126fca4798a2e98 |
| SHA1 | 6561129fd718db686673f70c5fb931f98625a5f0 |
| SHA256 | f43a59a861c114231ad30d5f9001ebb1b42b0289777c9163f537ac8a7a016038 |
| 文件大小 | 405K |
| 编译时间戳 | 2017-08-22 10:24:10 UTC |
| 链接 | VirusTotal |
上面的可执行文件会在之后删除掉木马。Pitou分别包含一个32位和一个64位模块来支持这两种体系结构。
32-bit
| MD5 | 9a7632f3abb80ccc5be22e78532b1b10 |
| SHA1 | 2d964bb90f2238f2640cb0e127ce6374eaa2449d |
| SHA256 | ab3b7ffaa05a6d90a228199294aa6a37a29bb42c4257f499b52f9e4c20995278 |
| 文件大小 | 431K |
| 编译时间戳 | 2017-03-22 01:21:01 UTC |
| 链接 | VirusTotal |
64-bit
| MD5 | 264a210bf6bdded5b4e35f93eca980c4 |
| SHA1 | 8f6ff0dd9b38c633e6f13bde24ff01ab443191f6 |
| SHA256 | ddb82094dec1fc7feaa4d987aee9cc0ec0e5d3eb26ba9264bb6ad4aa750ae167 |
| 文件大小 | 478K |
| 编译时间戳 | 2017-02-27 06:13:41 UTC |
| 链接 | VirusTotal |
这里,我只分析了64位版本。
虚拟机
这部分介绍保护DGA的虚拟机,以及Pitou组件的其他功能。首先展示虚拟机的主要组成。然后,讨论VM及其字节码的属性。
组件
Tim Blazytko和Moritz Contag的这段视频很好地介绍了虚拟机的主要组件,包括:
- VM入口/ VM出口
- VM调度器
- 处理程序表
VM入口和出口负责上下文的切换。VM入口将本机上下文(寄存器和标志)复制到虚拟环境。在下面的屏幕截图中展示了进入虚拟机。
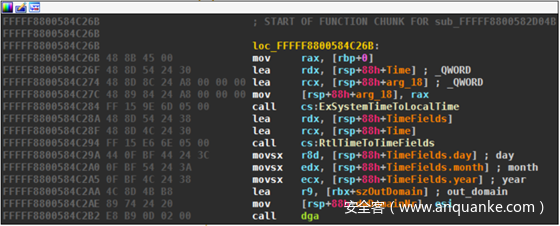
根据x64调用约定将四个参数传递给虚拟化的DGA(rcx、rdx、r8和r9中)。在讨论DGA的参数时,我将重新讨论这些参数及其含义。对DGA的调用会在堆栈上产生一个返回值,该值稍后在调用ret退出时用于VM退出,以便在调用DGA之后立即跳回到原来代码处。调用将指向原来代码处:
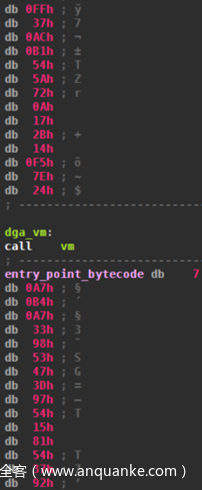
这个5字节长度的调用,位于VM执行字节码的中间。调用的目的是将接下来地址的地址(用entry_point_bytecode标记)放入堆栈。这个地址是虚拟DGA的入口点,并不在字节码的开头。然后调用跳转到虚拟机的开始。从46个不同的位置可以进行虚拟机的调用,意味着有46个不同的字节码起点,而所有起点可能都实现了Pitou的不同组件,例如:
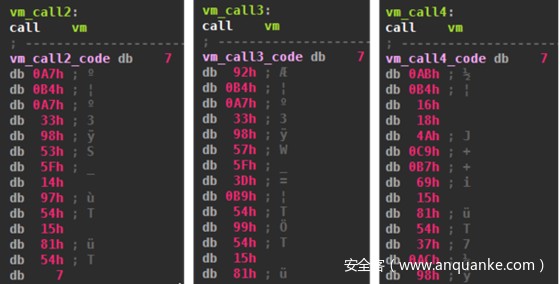
因为原生代码也可以在字节码的中间,如call指令,所以VM必须能够识别该指令并跳过它。稍后我们将看到这是如何实现的。
VM本身启动如下:
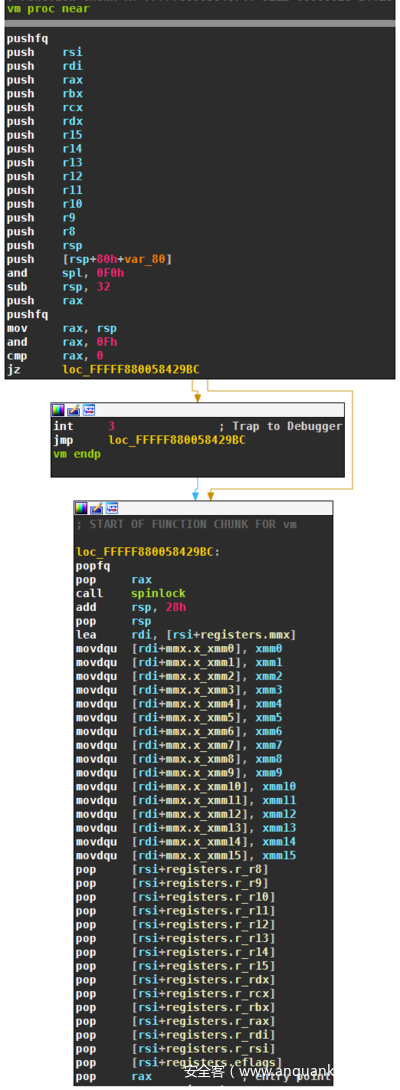
本机上下文被复制到虚拟上下文,通过寄存器rsi进行访问。复制的内容包括:
- 标志位,通过pushfq
- 通用寄存器rax、rbx、rcx、rdx、rdi、rsi和r8到r15。寄存器rip、rsp和rbp不会被复制,因为VM本身会使用它们。
- XMM寄存器,尽管没有任何虚拟指令修改它们。
屏幕截图的最后一行pop rax,从堆栈中删除虚拟代码的入口点。这个入口点也保存在虚拟上下文中:
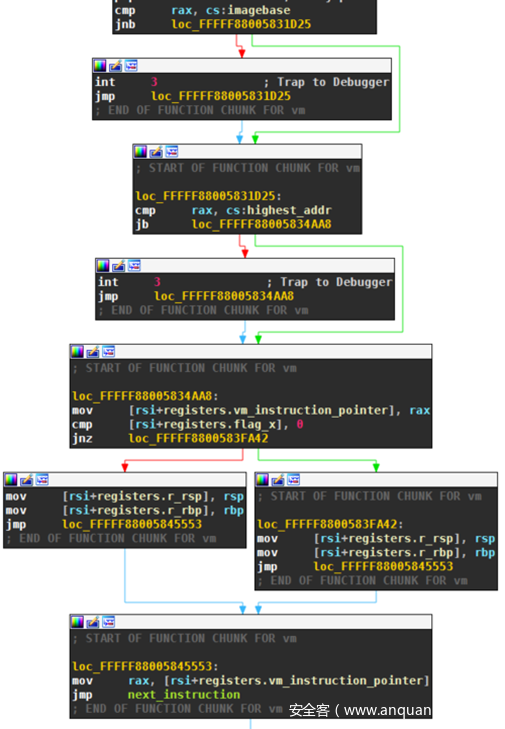
上面的截图显示了VM 入口如何检查入口点是否在字节码中。我将字节码的最低地址命名为imagebase,将最高地址命名为highest_addr。如果入口点在此范围内,则将虚拟指令指针设置为入口点。这就是VM入口。
调度器的任务是获取和解码指令。处理程序(handler)通常属于被调用的操作码,Pitou的VM也不例外。同时这个处理程序(handler)还负责更新VM的上下文,特别是指令指针。
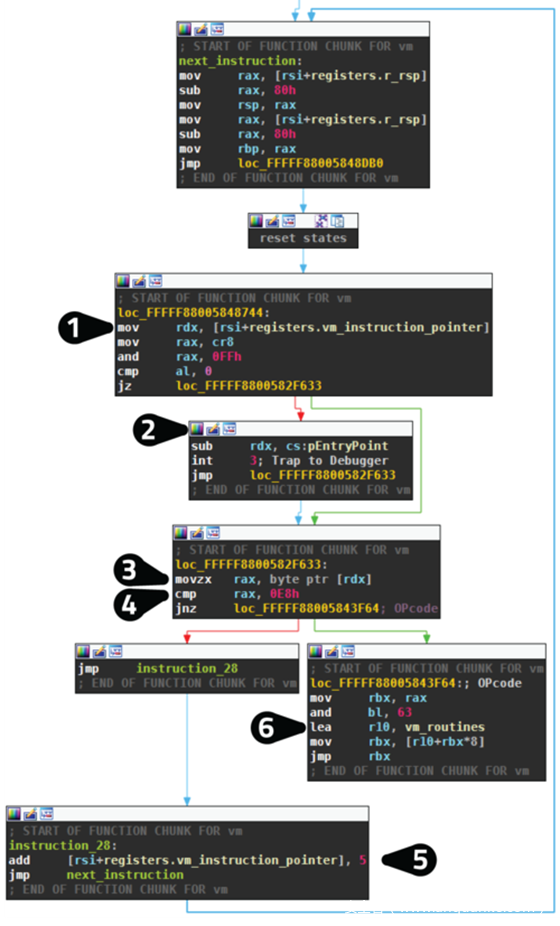
下面的截图展示了VM调度器。首先,读取虚拟指令指针(1)。如果设置了控制寄存器CR8,则指令指针转换为从入口点开始的偏移量,并触发软件中断(2)。然后调度器读取指令指针上的字节。如果它指向E8(4),则VM处于本地调用,用于将入口点传递给VM(详情见VM入口部分)。调用的五个字节被简单地跳过(5)。其他所有字节的值都是有效的字节码。最不重要的6比特对应于操作码,它引用处理程序表中的函数。然后VM跳转到这个函数(6)。
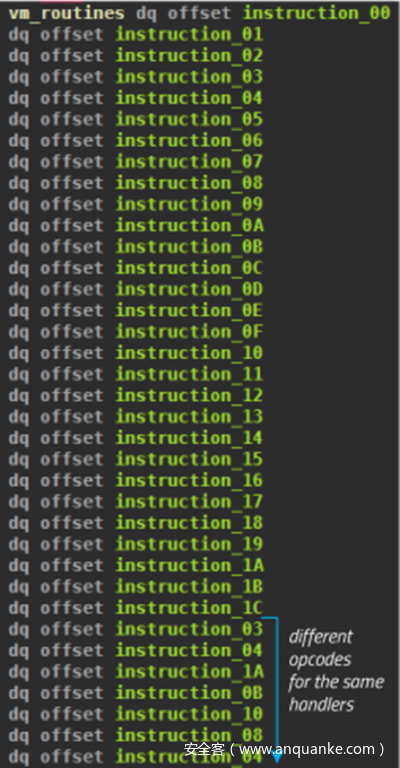
6位可以表示多达64个不同的函数,其中0x28被排除,因为它对应于保留字节0xE8中的操作码部分。然而,只有处理程序表中的前29个条目指向不同的程序。我根据调用它们的主操作码将它们标记为instruction_00到instruction_1C。从操作码0x1D开始,重用之前的函数,例如,0x1D使用操作码0x03的处理程序。一些处理程序函数只由一个操作码访问,而另一些则由多个操作码访问。例如,0x07、0x47、0x87、0xc7都映射到同一个处理程序。
虚拟jmp/call/ret指令(处理程序0x02)同样控制VM出口。这个处理程序的详细说明在附录部分。下面处理程序的截屏展示了如何从虚拟上下文恢复本地寄存器。退出VM的操作很简单:通过使用堆栈上的地址,处理程序最后只返回VM入口之后的代码。
属性
Pitou的虚拟机是基于堆栈的,其执行64位代码。至少64位模块是这样做的,32位的模块可能有32位虚拟指令。接下来说明虚拟机的属性。所有说明的完整列表可在附录中找到。
VM使用x64通用寄存器和标志的虚拟副本。正如所预料的,它还具有一个虚拟指令指针、一个虚拟堆栈指针和一个虚拟基指针。此外,还有两个状态寄存器可用,被用于跳转:
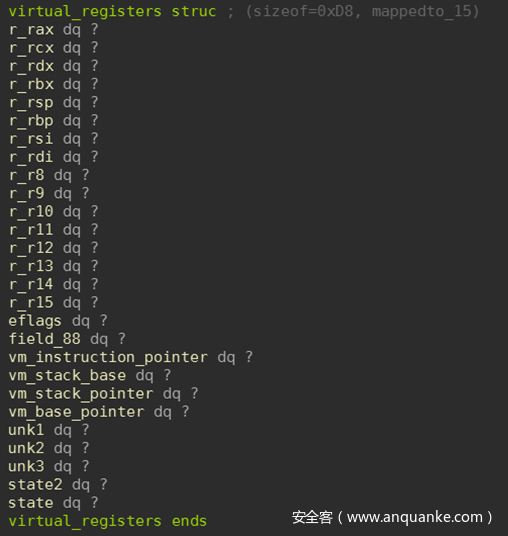
指令集
虚拟指令的长度从1字节到11字节不等。正如VM调度器部分介绍的,第一个字节的最低6位是代表处理程序函数的操作码。最高的2位可用于选择处理程序中的变量。只有第一个字节是必需的。事实上,许多虚拟指令只有1字节长。通常由前缀的两位之一决定后面跟着一个或两个可选的指定字节。格式因指令而异(例如,它可以包含关于指令使用哪个内存段的信息、或者下面的操作数是否有正负之分,或者指令的大小)。在可选说明符之后,可能会跟着一个可选操作数。
操作数以小端顺序存储,可以是字节(bytes)、字(words)、双字(double-words)或四字(quad-words)。操作数和说明符使用以下密钥进行异或加密:
- 字节是用0x57加密
- 字用0x13F1加密
- 双字用0x69B00B7A加密
- 四字用0x7EF5142A570C5298加密
例如,操作数AB01加密后值为0x125A (0x01AB XOR0x13F1)。跳转目标地址相对于虚拟代码的初始地址。例如,如果虚拟代码从0xFFFFF87EC582C000开始,那么带有解密操作数0x123的跳转将把虚拟指令指针设置为0xFFFFF87EC582C123。指令0x01、指令0x04、指令0x06和指令0x18可以使用虚拟代码的相对地址。处理程序0x18指令也可以使用可执行程序初始地址的相对地址。这允许处理程序访问VM外部的内存。DGA使用这个地址来读取静态字符串,比如顶级域列表。这是唯一一条与位置无关的指令,即如果虚拟代码放置在其他位置,则需要重新定位。
看一个例子:如果设置为0,则跳转至地址0xfffff8800586c445的虚拟指令JZ 0xfffff8800586c445编码如下:

- 条件跳转是处理程序0x06。这个处理程序使用前两个比特位。
- 第一个比特位决定条件是一元(0)还是二元比较(1)。在我们的例子中,为一元条件。第二个比特位只适用于二元比较。总的来说,第一个字节是0x06。
- 说明符的前两个比特(最重要的)决定标志如何组合。1 0表示如果设置了所有选中的标志,则满足条件。剩下的6个比特是用作各种标志的比特掩码。JZ指令只需要查看ZF标志,因此比特掩码中只设置了这个位。整个说明符是0xDF,然后用密钥0x57加密它,得到最终的值0x88。
- 跳转目标地址计算如下:从目标(0xfffffff8800586c445)中减去镜像基址(image base) (0xfffff87EC582C000),然后对结果进行异或加密(密钥0x7EF5142A570C5298)。
由于虚拟机是基于堆栈的,所以堆栈非常重要。虽然虚拟机模拟64位代码,即它最多处理64位的值,但堆栈宽128位。每个堆栈实体由两个64比特槽位组成。大多数指令只使用存储在较低地址的槽位,显示在堆栈图左侧的部分。我将这个槽位称为值槽或常规存储槽。另一个槽比第一个槽高64位,通常用于存储左槽(值槽)里值的地址。我把这个槽位称为额外槽位。
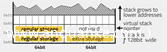
和正常情况一样,该堆栈遵循“后进先出”原则。它向较小的地址增长,向较大的地址收缩。虚拟堆栈寄存器变量指向堆栈中的最后一项。
逆向工程
这部分讨论虚拟机的逆向。起初,我编写了一个反汇编程序,但对它的输出不满意,单独来看还是太复杂了,难以理解。特别是缺少用于用户定义指令的工具,使得分析变得困难。
第二种方法是将虚拟代码变成C代码。这工作得出奇的顺利,最终实现了一个算法,虽然还是很复杂,还有一些错误,但已经很容易理解了。我使用DGA的一部分作为例子来说明算法的四个步骤,选取的这部分对应一个简单的数学语句,可以用C语言写成一行。这应该能让你了解每个步骤的结果有多长,以及它们是多么的难以理解。
方法一:反汇编
分析VM的通常步骤如下(更加详细的步骤可以看这本书[Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and Obfuscation]):
- 研究如何从字节码解码指令,特别是哪些位是决定处理程序函数的操作码,像之前在VM 调度器部分所讲的,第一个字节的最低6个比特指定处理程序,该处理程序对指令的其余部分进行解码,并将指令指针前置。
- 了解VM的体系结构。这在虚拟机部分已经介绍了。
- 最后,必须分析处理程序。这是分析中最耗时的部分。在Pitou中,有29个必须进行逆向的不同函数。
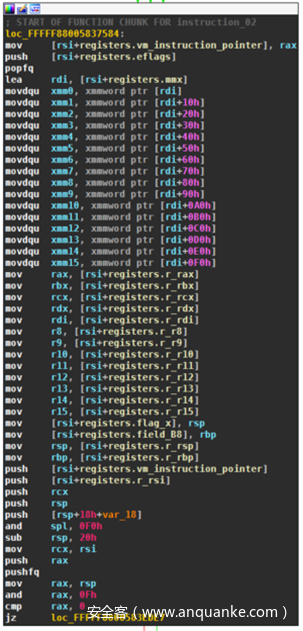
下面的截图显示了第一个操作码0x00对应的处理程序。函数不是很长,更幸运的是没有进行混淆。

下图显示了操作码0x00(别名0x2F和0x35)的指令编码以及对堆栈的影响。
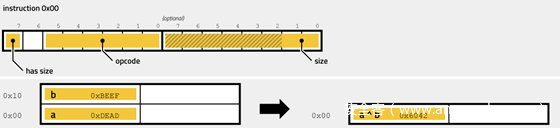
指令编码字段的含义:
| 范围 | 比特 | 描述 |
| 设置大小 | 1 | 0: 没有设置大小, 默认是双字, 1: 大小 (大小占1 字节) |
| 操作码 | 6 | 必须是 0x00, 0x2F 或 0x35 |
| 大小 | 8 | (可选项) 操作大小, 0: 字节, 1: 字, 2: 双字, 3: 四字 |
处理程序使用前缀的第一个比特确定是否设置可选的操作大小。如果该位没有设置,则假定操作为32位,并且指令只有一个字节长。另一方面,如果设置了,则必须跟随另一个字节,其中最低的两位决定操作的大小。0代表一个字节(8位),1代表一个字(16位),2代表一个双字(32位,默认选项),3代表一个四字(64位)。该指令从堆栈中弹出两个值,对它们进行异或并将结果压回到堆栈中,将值转换为指定的大小。反汇编器很容易重新实现这个处理程序:
- 检查是否设置了has size位,如果设置了,则读取下一个字节,并根据最后两个位(0表示字节等)确定数据大小。否则,默认是双字大小。
- 输出XOR <size>。
- 如果设置了has size位,则将指令指针加2,如果没有则加1。
在重新实现所有29个处理程序之后,可以对字节码进行反汇编。下面摘录自己反汇编的字节码,展示了 XOR dword edx, edx,即将寄存器edx归零,虚拟指令及其对x64指令堆栈的影响:
FFFFF8800585817C NOP
(empty stack)
FFFFF8800585817D PUSH dword (rdx, addr(rdx))
| rdx | addr(rdx) |
FFFFF8800585817F PUSH dword (addr(rdx), addr(rdx))
| addr(rdx) | addr(rdx) |
| rdx | addr(rdx) |
FFFFF88005858181 DREFH dword
| rdx | addr(rdx) |
| rdx | addr(rdx) |
FFFFF88005858182 XOR dword
| edx XOR edx | addr(rdx) |
FFFFF88005858183 P2E dword
(empty stack)- 第一个指令NOP,是空指令,什么也不做。
- 寄存器rdx与处理程序0x12一起被推送到堆栈上,但是对于推送地址标志使用了两种不同的设置:第一个PUSH将寄存器rdx的值推入堆栈的值槽,第二个PUSH推入寄存器rdx的地址(在这两种情况下,地址都存储在堆栈实体的额外槽位中)。
- 栈顶寄存器rdx的地址由DREFH dword得到。堆栈上的两个实体的rdx现在是相同的。我不明白为什么编译器一开始没推入地址而不是寄存器。
- XOR dword指令从最上面的两个堆栈实体中获取值,进行异或并将结果推回到堆栈上。额外槽位保持不变,也就是,在异或操作之前,该额外槽位的值是栈顶的元素值。
- 最后,指令 P2E dword 从堆栈中弹出实体,并将值槽(edx异或edx)移动到额外槽提供的内存地址中-addr(rdx)。这意味着,虚拟寄存器rdx被设置为0。
下面是示例代码片段的字节码,如引言中所述,它对应于DGA中的一个简单数学语句:
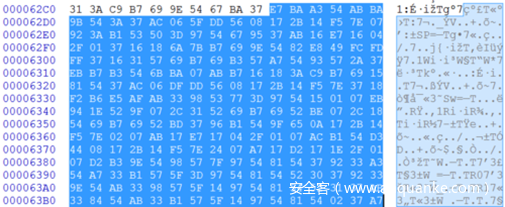
反汇编器从上面的字节码生成以下代码:

第一个数字是每一行的地址。蓝色方块中的数字是处理程序编号。之后是组成指令的字节。大多数是1或2字节长,但也有更长的指令,如10字节长度的条件跳转指令。该指令的助记符位于字节码之后,并带有一些语法高亮显示。由于我放弃了反汇编方法,所以目前的助记符并不都是特别好的选择和有意义的,在附录中你可以找到它们。
如果耐心等待,我们或许可以从反汇编器的输出中提取DGA。然而,我放弃了这个方法,因为:
- 反汇编程序的输出非常长,共有3681行。
- 虚拟机使用特殊的指令,如上面所示的P2E或DREFH。这些都是新指令,需要练习才能快速掌握。
- 没有工具可以很好地显示输出,例如,可以帮助查看代码流的图形工具。
有多种方法可以使反汇编更具可读性,例如:
- 添加模式以减少行数。例如,上面组成XOR edx、edx的6行代码非常常见。巧妙的模式匹配可以大大减少行数。
- 将反汇编程序实现为一个IDA Pro处理模块。在IDA中提供很多可用的注释工具,将提供一个很好的图形视图,使代码更具可读性。
我没有去实现这些想法,因为我心里有一个更诱人的目标:将虚拟代码反编译为C。你可以使用Github上的Python脚本自己运行反汇编程序:
python3 main.py disassembly -o pitou.dis方法二:反编译器
接下来展示如何将虚拟代码反编译为C代码。我的计划是首先将字节码转换为x64程序集,然后将其组装为x64二进制文件。之后,使用IDA Pro中的Hex Rays插件打开该文件并生成x64反汇编代码和C代码。采用这样的步骤,目的是能够使用已有的工具,特别是Hex Rays反编译器。这一点值得特别注意,因为DGA中使用了许多整数乘除法实例,这些实例在汇编中很难读取,但是反编译器可以很好地处理它们。

在这四个步骤中,唯一没有工具的步骤是将VM的字节码转换为x64程序集。二进制翻译的任务是将虚拟指令序列重新编译成x64汇编。
我决定通过模拟字节码并同时动态输出相应的x64指令来进行转换。为了模拟虚拟指令,我使用了方法1中的反汇编器。其提供了指令的解码以及代码的递归遍历。由于VM是基于堆栈的,因此必须模拟堆栈。每个堆栈槽跟踪两个方面:
- 立即数或寄存器名。我将其标记为堆栈的值槽和额外槽位两个槽位的值部分(值和额外值(value和extra),见下面表格的形式)。
- 仅当(1)是寄存器时,指向堆栈上的寄存器值的汇编指令列表((1)见VM调度器部分)。这个指令列表可以是空的。我给指令列表加上了值指令和额外指令的标签。
下面将展示如何模拟大多数的虚拟指令。我希望可以讲清楚这个方法。不管怎样,如果想获得更多的细节,可以看我在Github上的二进制翻译程序的源代码都。
一元操作的虚拟指令包括NEG;INC 和DEC;NOT;SHR, SHL, ROR, ROL, SAR, 和SAL。它们都使用以下方式反编译:
- 从堆栈中弹出一个值。如下面示例中的rcx。
- 如果值是寄存器,则根据指令的大小进行转换,例如,Dword将把rcx转换为ecx。转换后的寄存器成为新堆栈实体的值。
- 如果弹出堆栈元素中存在值指令(value instructions),则将其组合起来。然后添加<助记符(mnemonic)> <大小(size)> <值(value)>,如NEG DWORD ecx。将指令序列设置为新堆栈元素的值指令。
- 将额外值和额外指令从弹出的堆栈元素复制到新元素的额外槽位的相应位置。
- 将新的堆栈元素压入堆栈。
反编译器只影响堆栈,没有任何输出。下表显示调用NEG处理程序之前的堆栈(未设置大小标志):
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rcx | ADD rcx, 10 SHR rcx, 2 | addr(rcx) |
调用处理程序后:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| ecx | ADD rcx, 10 SHR rcx, 2 NEG DWORD ecx | addr(rcx) |
注:这里作者将之前虚拟栈中讲的槽位进行再次划分,每个槽位划分为值部分和指令部分。
有7条虚拟指令执行二进制操作:XOR、SBB、SUB、OR、AND、CMP和ADD,二元算术指令的处理类似于一元运算:
- 从堆栈中弹出两个值。下面的例子中的[r10 + 1]和rax,第一个值是指令的源操作数,第二个是目的操作数。
- 如果目的操作数值是寄存器,则根据指令的大小进行转换。例如Word把rax转换为al。转换后的目标寄存器成为新堆栈元素的值。
- 如果弹出的两个元素中含有值指令则将其组合在一起。然后添加 <助记符(mnemonic)> <大小(size)> <目标值(target value)>, <源值(src value)>,如XOR byte al, [r10 + 1]。将指令序列设置为新堆栈元素的值指令。
- 将第二个弹出堆栈元素的额外(extra)和额外指令(extra instructions)的值复制到新元素的额外槽位的对应位置。
- 将新的堆栈元素压入堆栈。
像=与一元操作类似,反编译器只更改堆栈,没有任何输出。下表显示调用XOR处理程序之前的堆栈,设置了大小(size)标志,设置为0(表示字节):
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| [r10 + 1] | SHR r10d, 2 | r10 | ADD QWORD r10, 1 |
| rax | SHL rax, 2 | addr(rax) |
xor操作后,堆栈更改为:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| al | SHR r10d, 2 SHL rax, 2 XOR BYTE al, [r10 + 1] | addr(rax) |
写数据的虚拟指令有M2E、M2V、P2E和P2V。例如,M2E指令将堆栈顶部元素值槽中的数据移动到额外槽指定的内存位置。通常,额外槽位包含虚拟寄存器的地址,最终值槽中的数据被移动到虚拟寄存器。例如,如果应用到下面的栈中,rsp的内容将被写入rax:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rsp | SUB QWORD rsp, 8 | addr(rax) | SHL QWORD rax, 3 ADD QWORD rax, 1 |
这个操作对应于汇编中的MOV rax, rsp。但是,在值指令和额外指令列中可以看到,rsp和rax在堆栈上已经进行了修改:转换已影响了堆栈。所以这些操作需要反编译器在MOV语句之前进行简单地更改来实现:
SHL QWORD rax, 3
ADD QWORD rax, 1
SUB QWORD rsp, 8
MOV rax, rsp在虚拟机的大多数字节码序列中,目的操作数和源操作数都是相同的。在这些情况下,MOV被移除,例如,MOV rsp, rsp不会被写入。现在这些指令已经被实现了,如果处理程序还没有完全弹出堆栈,那么它们将从相应的堆栈槽中删除(像P2E, P2V),值(value)和额外(extra)列保持不变。
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rsp | addr(rax) |
从堆栈中弹出也是同样的操作。在堆栈上POP dword rax :
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rdx | SHR rdx, 2 | addr(rdx) |
结果返回一个空堆栈,可以翻译表示为:
SHR rdx, 2
MOV DWORD eax, edx这种方法有一个小问题。考虑一下上述操作可能产生的这三行指令,前两行源于实现值指令字段,最后一行是实际移动。
SHL QWORD rax, 2
ADD QWORD rax, r11
MOV QWORD rcx, rax这里的问题是,第一行修改了rax,而第二条指令再次使用。然而,因为所有操作都发生在堆栈上,所以原始的虚拟寄存器不会被更改。在本例中,有一个简单的修复方法:操作的目标寄存器rcx在之前的汇编中没有使用。因此,它可以作为寄存器rax的替代品。这样就可以使用汇编指令MOV rcx,rax来复制值。而这时,MOV rcx, rax可以省略,因为计算已经使用了rcx:
MOV rcx, rax
SHL QWORD rcx, 2
ADD QWORD rcx, r11不幸的是,这种方法并不能总是奏效,如下面的例子所示:
SHL QWORD rax, 1
ADD QWORD rax, rax在这种情况下,对移动指令的目标寄存器rax进行计算操作,因此rax被消除。最终目标rax作用与污点寄存器类似。在这些情况下,二进制转换使用r15作为临时寄存器。显然,这个寄存器是可以被使用的,所以它首先存储在堆栈中,在结束时被恢复。我从[rsp-1000]中任意选择。由于除了RET之外虚拟机不使用本地堆栈,所以这应该不会造成任何问题。保存r15之后,它将接收执行MOV r15, rax的污点寄存器rax的值。然后按照原来的两行代码,将rax替换为r15。最后,将r15移回rax,并且从堆栈中还原r15:
MOV [rsp-1000], r15
MOV r15, rax
SHL QWORD r15, 1
ADD QWORD r15, rax
MOV rax, r15
MOV r15, [rsp-1000]JMP、CALL和RET处理程序本质上是带有一些附加步骤的一元操作。首先,弹出堆栈中的值:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| 0xFFFFF8800588FCBA | 0xFFFFF8800588FCBA |
堆栈变为空。如果该值是一个字节码地址,那么反编译器会在十六进制字符串前加上addr,为跳转目标生成一个标签,如:
JMP _addr_FFFFF8800588FCBA在目标地址也有同样的标签:
ADD QWORD rsp, 8
RET
_addr_FFFFF8800588FCBA:
MOV DWORD eax, 1目标也可以是符号表达式。其中,[rsp]非常有趣,因为JMP [rsp]在本质上与RET相同。上面的反编译器片段显示了一个使用RET替代JMP [rsp]的例子。
条件跳转if x→y很容易实现:根据上一节中的表格确定助记符,然后如果给定的是相对偏移量,则将目标转换为绝对地址。跳转目标的处理与处理程序0x02相同。一个输出例子:
JNZ _addr_FFFFF8800588FCBA处理程序0x0B中的虚拟数据类型转换只需要转换为相应的助记符和输出。
处理程序POPD从栈中移除n个元素,并且输出值槽和额外槽中的所有指令。如:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| r10d | AND DWORD r10d, r10d | addr(r10) | |
| r8d | XOR DWORD r8d, r8d | addr(r8) | |
| ebx | AND DWORD ebx, ebx | addr(rbx) |
变成:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| ebx | AND DWORD ebx, ebx | addr(rbx) |
输出:
AND DWORD r10d, r10d
XOR DWORD r8d, r8dSTACKSWP处理程序交换栈两个顶部元素中的值槽,包括值指令部分。例如:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| r10d | AND DWORD r10d, r10d | addr(r10) | |
| r8d | XOR DWORD r8d, r8d | addr(r8) |
变成:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| r8d | XOR DWORD r8d, r8d | addr(r10) | |
| r10d | AND DWORD r10d, r10d | addr(r8) |
没有输出。
取消引用只发生在堆栈上,不生成任何输出。例如:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rax | ADD QWORD rax, rsp ADD QWORD rax, 56 | addr(rax) |
变成:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| [rsp + rax + 56] | rax | ADD QWORD rax, rsp ADD QWORD rax, 56 |
如果取消引用发生,转换还会将ADD指令替换为+。因此,在许多情况下,取消引用可以清除指令并将其移动到值(value)部分。
两个什么也不做的指令:NOP,TRIPLE。两个修改无关紧要状态变量的指令:SET1,STATE。对这四个指令进行二进制转换,没有任何变化。
乘法(MUL)和除法(DIV)是特别的:首先,将两个虚拟寄存器rax和rdx复制到本地寄存器。然后从堆栈中弹出一个值,如:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rcx | addr(rcx) |
栈清空。然后执行MUL <大小> <弹出的值>或者DIV <大小><弹出的值>,例如,MUL BYTE cl。结果不会再压到堆栈上,相反的是,虚拟上下文存储这两个本地寄存器rax和rdx。
有符号乘法(IMUL)的工作方式也不同。指令从堆栈中弹出两个值。第一个存入rdx,第二个存入rax。然后根据大小计算IMUL Byte dl、IMUL Word dx、IMUL Dword edx或IMUL Qword rdx。最后,rdx和rax被压回到堆栈上。
例如,执行之前的栈:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| r9 | addr(r9) | ||
| rax | addr(rax) |
执行后为:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rdx | addr(rax) | ||
| rax | addr(r9) |
这个过程的汇编代码:
MOV rdx, r9d
IMUL DWORD rdx处理程序0x18和0x12中的两个PUSH指令将最近的寄存器或寄存器的地址压入栈。二进制转换只改变堆栈,而不产生任何输出。
例如,压入寄存器rbp:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rax | addr(rax) |
执行后:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rbp | addr(rbp) | ||
| rax | addr(rax) |
比较奇怪的指令MDIAG, MDIAGA, PDIAG, PDIAGA只影响栈,进行翻译只需要移动栈内元素。例如在栈上执行PDIAG:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| r9 | ADD QWORD r9, -1 | addr(r9) | |
| rax | addr(rax) |
结果为:
| 值(value) | 值指令(value instructions) | 额外值(extra) | 额外指令(extra instructions) |
| rax | r9 | ADD QWORD r9, -1 |
下面的代码片段显示了反汇编和生成的x64程序集
FFFFF880058766F6 NOP
FFFFF880058766F7 PUSH dword (addr(r8), addr(r8))
FFFFF880058766F9 DREFH dword
FFFFF880058766FA PUSH dword (r8, addr(r8))
FFFFF880058766FC AND dword
FFFFF880058766FD POPD
▶ AND DWORD r8d, r8d
FFFFF880058766FE NOP
FFFFF880058766FF STATE 1
FFFFF88005876700 IF NOT ZF -> JMP 0xFFFFF8800587C8F8
▶ JNZ _addr_FFFFF8800587C8F8
FFFFF8800587670A NOP
FFFFF8800587670B PUSH dword (51EB851Fh, 51EB851Fh)
FFFFF88005876710 POP dword rax
▶ MOV DWORD eax, 1374389535
FFFFF88005876712 NOP
FFFFF88005876713 PUSH dword (addr(r9), addr(r9))
FFFFF88005876715 DREFH dword
FFFFF88005876716 PUSH dword (rax, addr(rax))
FFFFF88005876718 IMUL dword
▶ MOV rdx, r9
▶ IMUL DWORD r9d
FFFFF88005876719 POP dword rdx
FFFFF8800587671B POP dword rax
FFFFF8800587671D NOP
FFFFF8800587671E PUSH dword (addr(rdx), addr(rdx))
FFFFF88005876720 DREFH dword
FFFFF88005876721 PUSH byte (5h, 5h)
FFFFF88005876724 SAR dword
FFFFF88005876726 P2E dword rdx
▶ SAR DWORD edx, 5
FFFFF88005876727 NOP
FFFFF88005876728 PUSH dword (addr(rdx), addr(rdx))
FFFFF8800587672A DREFH dword
FFFFF8800587672B POP dword rax
▶ MOV DWORD eax, edx
FFFFF8800587672D NOP
FFFFF8800587672E PUSH dword (addr(rax), addr(rax))
FFFFF88005876730 DREFH dword
FFFFF88005876731 PUSH byte (1Fh, 1Fh)
FFFFF88005876734 SHR dword
FFFFF88005876735 P2E dword rax
▶ SHR DWORD eax, 31
FFFFF88005876736 NOP
FFFFF88005876737 PUSH dword (rdx, addr(rdx))
FFFFF88005876739 PUSH dword (addr(rax), addr(rax))
FFFFF8800587673B DREFH dword
FFFFF8800587673C ADD dword
FFFFF8800587673D P2E dword rdx
▶ ADD DWORD edx, eax
FFFFF8800587673E NOP
FFFFF8800587673F PUSH dword (addr(rdx), addr(rdx))
FFFFF88005876741 DREFH dword
FFFFF88005876742 PUSH byte (64h, 64h)
FFFFF88005876745 IMUL dword
▶ MOV rax, 100
▶ IMUL DWORD edx
FFFFF88005876746 POPD
FFFFF88005876747 PUSH dword (addr(rdx), addr(rdx))
FFFFF88005876749 PDIAG
FFFFF8800587674A P2E dword rdx
▶ MOV DWORD edx, eax
FFFFF8800587674B NOP
FFFFF8800587674C PUSH dword (r9, addr(r9))
FFFFF8800587674E PUSH dword (addr(rdx), addr(rdx))
FFFFF88005876750 DREFH dword
FFFFF88005876751 CMP dword
FFFFF88005876752 POPD
▶ CMP DWORD r9d, edx
FFFFF88005876753 NOP
FFFFF88005876754 STATE 1
FFFFF88005876755 IF NOT ZF -> JMP 0xFFFFF88005867CB8
▶ JNZ _addr_FFFFF88005867CB8
FFFFF8800587675F NOP
FFFFF88005876760 PUSH dword (51EB851Fh, 51EB851Fh)
FFFFF88005876765 POP dword rax
▶ MOV DWORD eax, 1374389535
FFFFF88005876767 NOP
FFFFF88005876768 PUSH dword (addr(r9), addr(r9))
FFFFF8800587676A DREFH dword
FFFFF8800587676B PUSH dword (rax, addr(rax))
FFFFF8800587676D IMUL dword
▶ MOV rdx, r9
▶ IMUL DWORD r9d从上面可以看到,二进制翻译极大地减少了指令的数量。原来的3681条反汇编被压缩成786条x64条指令,减少了约80%。在本文中作为例子使用的代码片段中也可以看到这个过程。反汇编变成的x64汇编代码:
_addr_FFFFF880058766F6:
AND DWORD r8d, r8d
JNZ _addr_FFFFF8800587C8F8
MOV DWORD eax, 1374389535
MOV rdx, r9
IMUL DWORD r9d
SAR DWORD edx, 5
MOV DWORD eax, edx
SHR DWORD eax, 31
ADD DWORD edx, eax
MOV rax, 100
IMUL DWORD edx
MOV DWORD edx, eax
CMP DWORD r9d, edx
JNZ _addr_FFFFF88005867CB8
MOV DWORD eax, 1374389535
MOV rdx, r9
IMUL DWORD r9d
SAR DWORD edx, 7
MOV DWORD eax, edx
SHR DWORD eax, 31
ADD DWORD edx, eax
MOV rax, 400
IMUL DWORD edx
MOV DWORD edx, eax
CMP DWORD r9d, edx
JNZ _addr_FFFFF8800587C8F8
JMP _addr_FFFFF88005867CB8
_addr_FFFFF88005867CB8:
MOV DWORD eax, 1
JMP _addr_FFFFF88005852C11
_addr_FFFFF8800587C8F8:
XOR DWORD eax, eax
JMP _addr_FFFFF88005852C11上面这段代码的可读性更好。主要缺少的仍然是代码流在图中的表示,以及对占很大部分的优化的整数除法的更好处理。
在第一步中,创建了x64程序集。为了能够使用IDA Pro对其进行分析,首先必须将其转换为可执行文件。为此,我使用了Netwide Assembler (NASM)。只需要对上一节中的代码中的两部分头部进行修改。我将VM从本地上下文中读取的数据复制到数据( data )部分,文本( text) 部分是之前的实际代码。虽然DGA是一个函数,但我直接将它用作二进制文件的入口点。
section .data
data_FFFFF8800589E540 dd 31,28,31,30,31,30,31,31,30,31,30,31
data_FFFFF8800589E570 dd 31,29,31,30,31,30,31,31,30,31,30,31
...
section .text
global _startGithub上的代码已经在运行时添加了这部分:
python3 main.py nasm -o pitou.asm然后可以用它编译生成目标文件:
nasm -f elf64 pitou.asm
ld pitou.o -o pitou.bin当然,这使得我们的代码又变成不可读的,因为它现在又是二进制格式的。在我们的例子中如下:
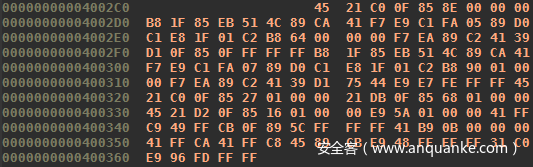
上一步中的可执行文件现在可以在IDA中打开进行反汇编。下面是我们的摘录。与第1种方法不同的是,我们有了图形视图和添加注释的可能性。
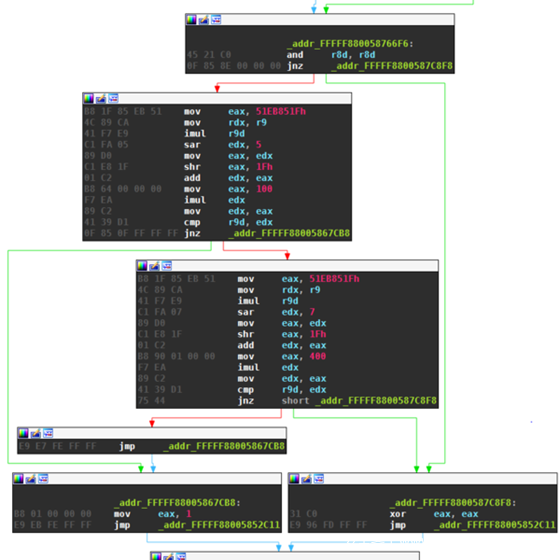
最后,Hex Rays可以将反汇编程序反编译为C代码。我们例子中代码片段如下:

方法1中很长的反汇编变成了一行C代码,它对应于上面的语句。
年份是闰年么?
你可以使用Github上的Python脚本自己运行反编译器。
python3 main.py nasm -o pitou.nasm






发表评论
您还未登录,请先登录。
登录