

前言
想提高一下自己读代码的能力,加上对FUZZ知之甚少,仅仅是知道模糊的过程,这对于一个二进制选手来说是远远不够的,因此这几天放弃了调试内核CVE,转而阅读AFL源码,到现在已经有很多基于AFL的开源软件了,比如AFL plusplus和AFL Unicorn,但是都是基于AFL,可见这一开源的FUZZ工具是多么经典,因此花了大概五天进行源码阅读(太菜了,代码看着看着就看不懂了),虽然afl-fuzz的源码有8000+行,但是代码逻辑很清晰,注释也非常完整,结合着注释以及网上看到的其他资料,这里自己总结一下学习到的东西,也是一篇集他人之长的杂文,不写点东西以我的记性应该很快就忘掉了。
基本使用
我基本是参考初探AFL-Fuzz这篇文章,安装,插桩编译,之后使用afl-fuzz进行fuzz,最后成功将一个栈溢出的demo搞崩并得到测试的case。qemu无源码的没有实验,大概知道了用法就去看源代码了
设计思想
FUZZ基本大家都有一些大概的认识,对于有源码的项目来说我们使用afl-gcc或者alf-g++,这是gcc的wraper(封装),在编译前向一些关键节点进行插桩,这些桩能够记录程序的执行路径,从而反馈出程序的执行情况。如果我们自己想写个fuzz的程序,最简单的思路莫过于将输入用例做随机变换之后尝试将其作为输入给程序查看执行情况,即调用execv这样的函数,但是这样的代价是很高的,因为在调用exec这个函数之后将产生一个的新程序来代替原进程,当前进程的数据段、代码段和堆栈段都会被改变,且新的进程的PID同原进程相同,我们无法通过PID来标识不同的测试用例,这种方式是很低效的。因此原作者用一种新的结构进行开发,即forserver架构。也就是每次要进行测试的时候就fork出一个子进程进行测试,子进程复制父进程的数据段等,且拥有自己的PID,这就是进程的写时复制。这样的好处就是我们省去了重新装载程序的时间原作者博客。
整体架构
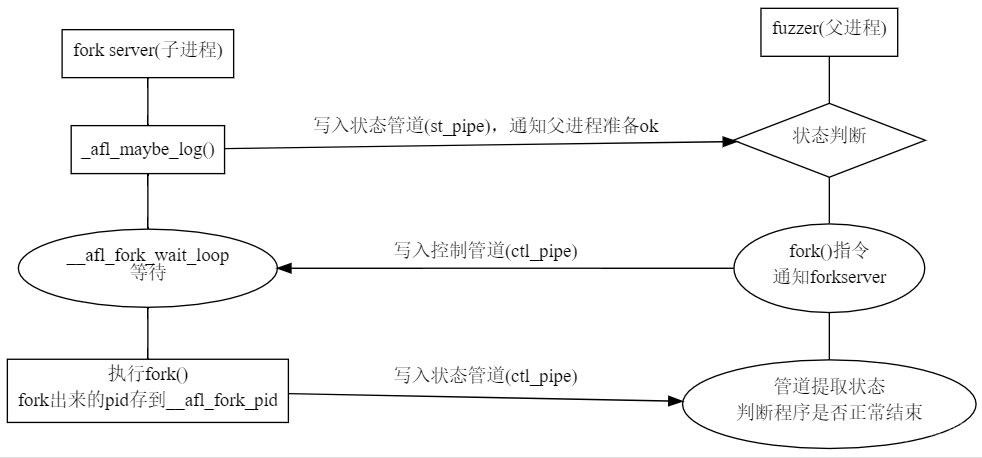
在看雪上找到了一篇很详细的分析,其中解答了我很多看源码困惑的地方,其中一个关键的点就是这个架构,在alf-gcc中先起了一个fork-server,在这个fork出的子进程里调用了execve去执行二进制程序,然后结合afl-as的代码可以看到插桩的桩代码中也包含了fork函数的调用,这样的话就是fuzzer->forkserver->exec target Bin->bin->bin_sub_process(被fuzz的app),这样看起来fuzzer是最终被fuzz的程序的祖祖父进程,但是execve根据我们之前的介绍是直接将创建的进程替换掉原进程的,除非出错否则不会返回,因此实际上forkserver与target bin可以看作是同一个进程的不同程序,其父进程都是fuzzer,故最终的调用关系是下面这样的

afl-gcc.c
这个文件用来编译源代码,其实际上是gcc的封装,在组装参数的时候可以看到,as_path是afl-as,查看gcc的参数可以看到-B是指定编译器,也就是说这里先把汇编码给了afl-as,看后者的代码会发现它也只是个真正as的wrapper,在源程序的汇编中插桩之后再传递给real as。
tmp = alloc_printf("%s/afl-as", dir);
if (!access(tmp, X_OK)) {
as_path = dir;
ck_free(tmp);
return;
}
//......
cc_params[cc_par_cnt++] = "-B";
cc_params[cc_par_cnt++] = as_path;
afl-as.c
正如之前提到的,这里有是插桩的核心部分,主要函数为add_instrumentation(),插桩完毕之后用fork起子进程调用真正的汇编器。下面源码中增加了注释,作者也提到了需要插桩的部分有条件跳转和基本块。其中R(MAP_SIZE)等同于random(2^16),这个是为每个桩分配独有的ID,根据碰撞概率一般不会重复。
static void add_instrumentation(void)
{
//前面忽略,这个循环是核心
while (fgets(line, MAX_LINE, inf)) {
/* In some cases, we want to defer writing the instrumentation trampoline
until after all the labels, macros, comments, etc. If we're in this
mode, and if the line starts with a tab followed by a character, dump
the trampoline now. */
//这里猜测是在main函数等基本块之前插桩,`t`+alpha
if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok &&
instrument_next && line[0] == 't' && isalpha(line[1])) {
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));
instrument_next = 0;
ins_lines++;
}
/* Output the actual line, call it a day in pass-thru mode. */
//原样输出
fputs(line, outf);
//省略
/* If we're in the right mood for instrumenting, check for function
names or conditional labels. This is a bit messy, but in essence,
we want to catch:
^main: - function entry point (always instrumented)
^.L0: - GCC branch label
^.LBB0_0: - clang branch label (but only in clang mode)
^tjnz foo - conditional branches
...but not:
^# BB#0: - clang comments
^ # BB#0: - ditto
^.Ltmp0: - clang non-branch labels
^.LC0 - GCC non-branch labels
^.LBB0_0: - ditto (when in GCC mode)
^tjmp foo - non-conditional jumps
Additionally, clang and GCC on MacOS X follow a different convention
with no leading dots on labels, hence the weird maze of #ifdefs
later on.
*/
if (skip_intel || skip_app || skip_csect || !instr_ok ||
line[0] == '#' || line[0] == ' ') continue;
/* Conditional branch instruction (jnz, etc). We append the instrumentation
right after the branch (to instrument the not-taken path) and at the
branch destination label (handled later on). */
//条件跳转
if (line[0] == 't') {
if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) {
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));
ins_lines++;
}
continue;
}
//这里把main_payload插入代码中(应该是位于代码段的尾部)
if (ins_lines)
fputs(use_64bit ? main_payload_64 : main_payload_32, outf);
if (input_file) fclose(inf);
fclose(outf);
if (!be_quiet) {
if (!ins_lines) WARNF("No instrumentation targets found%s.",
pass_thru ? " (pass-thru mode)" : "");
else OKF("Instrumented %u locations (%s-bit, %s mode, ratio %u%%).",
ins_lines, use_64bit ? "64" : "32",
getenv("AFL_HARDEN") ? "hardened" :
(sanitizer ? "ASAN/MSAN" : "non-hardened"),
inst_ratio);
}
}
下面着重分析汇编代码的逻辑,汇编代码位于afl-as.h头文件中(以32位代码为例,64位功能相同),其中trampoline_fmt_32是一个调用代码,main_payload_32是完整的代码,下面的代码不难分析,前面保存了寄存器的值,ecx存储了格式化字符串,这个%08x对应的是之前提到的随机数,其作用是标识每一个插桩节点。
static const u8* trampoline_fmt_32 =
"n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */n"
"n"
".align 4n"
"n"
"leal -16(%%esp), %%espn"
"movl %%edi, 0(%%esp)n"
"movl %%edx, 4(%%esp)n"
"movl %%ecx, 8(%%esp)n"
"movl %%eax, 12(%%esp)n"
"movl $0x%08x, %%ecxn"
"call __afl_maybe_logn"
"movl 12(%%esp), %%eaxn"
"movl 8(%%esp), %%ecxn"
"movl 4(%%esp), %%edxn"
"movl 0(%%esp), %%edin"
"leal 16(%%esp), %%espn"
"n"
"/* --- END --- */n"
"n";
核心函数为__afl_maybe_log,lahf作用是将EFLAGS 寄存器标志位加载到AH,seto为溢出置位,之后判断__afl_area_ptr是否为空,这个指针用来保存共享内存,如果不为空表明已经初始化完成了,直接进入__afl_store,这里首先把__afl_prev_loc(之前的我位置)同当前位置的key异或,保存在edi寄存器,之后当前的key右移一位,作为下一个的__afl_prev_loc,这个右移是一个很巧妙的设计,如果代码块的跳转为A->B或B->A,直接对两个Key异或结果是一样的,因此右移可以区分出一些特殊情况。下面那个incb代码中edx为map,edi为索引,即map表中对应的索引加一,表明一次hit。
如果之前的共享内存地址为空,就进入__afl_setup这个标签,如果__afl_setup_failure的值不为0(0为正常,非零异常),通过getenv($SHM_ENV_VAR)环境变量来获得共享内存的ID,如果不为空就调用atoi以及shmat,最终将这个地址存储在__afl_area_ptr中方便之后使用(不必再初始化),下面启动fork_server。
fork_server和fuzzer之间是通过管道通信的,在宏定义里可以看到默认的FORKSRV_FD为198,这里读管道为198,写管道为199。开始先通知fuzzer,之后在read处阻塞等待fuzzer的消息,得到fuzzer通知之后父进程fork出一个子进程,在这个子进程里会关闭与fuzzer通信的文件描述符,jmp到__afl_store记录下基本块的hit情况之后向后继续执行main函数。而父进程记录下刚才启动的子进程的pid发送给fuzzer并等待子进程执行完毕,子进程结束之后将其状态告知fuzzer。之后开始新一轮的等待。后面每次基本块都会执行__afl_maybe_log,但由于已经得到了共享内存的位置不会fork新的进程,之后只是记录基本块的跳转情况,这样就大大节约了资源。
至此,在目标程序的插桩代码基本分析完毕。
static const u8* main_payload_32 =
"n"
"/* --- AFL MAIN PAYLOAD (32-BIT) --- */n"
"n"
".textn"
".att_syntaxn"
".code32n"
".align 8n"
"n"
"__afl_maybe_log:n"
"n"
" lahfn"
" seto %aln"
"n"
" /* Check if SHM region is already mapped. */n"
"n"
" movl __afl_area_ptr, %edxn"
" testl %edx, %edxn"
" je __afl_setupn"
"n"
"__afl_store:n"
"n"
" /* Calculate and store hit for the code location specified in ecx. Theren"
" is a double-XOR way of doing this without tainting another register,n"
" and we use it on 64-bit systems; but it's slower for 32-bit ones. */n"
"n"
#ifndef COVERAGE_ONLY
" movl __afl_prev_loc, %edin"
" xorl %ecx, %edin"
" shrl $1, %ecxn"
" movl %ecx, __afl_prev_locn"
#else
" movl %ecx, %edin"
#endif /* ^!COVERAGE_ONLY */
"n"
#ifdef SKIP_COUNTS
" orb $1, (%edx, %edi, 1)n"
#else
" incb (%edx, %edi, 1)n"
#endif /* ^SKIP_COUNTS */
"n"
"__afl_return:n"
"n"
" addb $127, %aln"
" sahfn"
" retn"
"n"
".align 8n"
"n"
"__afl_setup:n"
"n"
" /* Do not retry setup if we had previous failures. */n"
"n"
" cmpb $0, __afl_setup_failuren"
" jne __afl_returnn"
"n"
" /* Map SHM, jumping to __afl_setup_abort if something goes wrong.n"
" We do not save FPU/MMX/SSE registers here, but hopefully, nobodyn"
" will notice this early in the game. */n"
"n"
" pushl %eaxn"
" pushl %ecxn"
"n"
" pushl $.AFL_SHM_ENVn"
" call getenvn"
" addl $4, %espn"
"n"
" testl %eax, %eaxn"
" je __afl_setup_abortn"
"n"
" pushl %eaxn"
" call atoin"
" addl $4, %espn"
"n"
" pushl $0 /* shmat flags */n"
" pushl $0 /* requested addr */n"
" pushl %eax /* SHM ID */n"
" call shmatn"
" addl $12, %espn"
"n"
" cmpl $-1, %eaxn"
" je __afl_setup_abortn"
"n"
" /* Store the address of the SHM region. */n"
"n"
" movl %eax, __afl_area_ptrn"
" movl %eax, %edxn"
"n"
" popl %ecxn"
" popl %eaxn"
"n"
"__afl_forkserver:n"
"n"
" /* Enter the fork server mode to avoid the overhead of execve() calls. */n"
"n"
" pushl %eaxn"
" pushl %ecxn"
" pushl %edxn"
"n"
" /* Phone home and tell the parent that we're OK. (Note that signals withn"
" no SA_RESTART will mess it up). If this fails, assume that the fd isn"
" closed because we were execve()d from an instrumented binary, or becausen"
" the parent doesn't want to use the fork server. */n"
"n"
" pushl $4 /* length */n"
" pushl $__afl_temp /* data */n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */n"
" call writen"
" addl $12, %espn"
"n"
" cmpl $4, %eaxn"
" jne __afl_fork_resumen"
"n"
"__afl_fork_wait_loop:n"
"n"
" /* Wait for parent by reading from the pipe. Abort if read fails. */n"
"n"
" pushl $4 /* length */n"
" pushl $__afl_temp /* data */n"
" pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */n"
" call readn"
" addl $12, %espn"
"n"
" cmpl $4, %eaxn"
" jne __afl_dien"
"n"
" /* Once woken up, create a clone of our process. This is an excellent usen"
" case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedlyn"
" caches getpid() results and offers no way to update the value, breakingn"
" abort(), raise(), and a bunch of other things :-( */n"
"n"
" call forkn"
"n"
" cmpl $0, %eaxn"
" jl __afl_dien"
" je __afl_fork_resumen"
"n"
" /* In parent process: write PID to pipe, then wait for child. */n"
"n"
" movl %eax, __afl_fork_pidn"
"n"
" pushl $4 /* length */n"
" pushl $__afl_fork_pid /* data */n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */n"
" call writen"
" addl $12, %espn"
"n"
" pushl $0 /* no flags */n"
" pushl $__afl_temp /* status */n"
" pushl __afl_fork_pid /* PID */n"
" call waitpidn"
" addl $12, %espn"
"n"
" cmpl $0, %eaxn"
" jle __afl_dien"
"n"
" /* Relay wait status to pipe, then loop back. */n"
"n"
" pushl $4 /* length */n"
" pushl $__afl_temp /* data */n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */n"
" call writen"
" addl $12, %espn"
"n"
" jmp __afl_fork_wait_loopn"
"n"
"__afl_fork_resume:n"
"n"
" /* In child process: close fds, resume execution. */n"
"n"
" pushl $" STRINGIFY(FORKSRV_FD) "n"
" call closen"
"n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) "n"
" call closen"
"n"
" addl $8, %espn"
"n"
" popl %edxn"
" popl %ecxn"
" popl %eaxn"
" jmp __afl_storen"
"n"
"__afl_die:n"
"n"
" xorl %eax, %eaxn"
" call _exitn"
"n"
"__afl_setup_abort:n"
"n"
" /* Record setup failure so that we don't keep callingn"
" shmget() / shmat() over and over again. */n"
"n"
" incb __afl_setup_failuren"
" popl %ecxn"
" popl %eaxn"
" jmp __afl_returnn"
"n"
".AFL_VARS:n"
"n"
" .comm __afl_area_ptr, 4, 32n"
" .comm __afl_setup_failure, 1, 32n"
#ifndef COVERAGE_ONLY
" .comm __afl_prev_loc, 4, 32n"
#endif /* !COVERAGE_ONLY */
" .comm __afl_fork_pid, 4, 32n"
" .comm __afl_temp, 4, 32n"
"n"
".AFL_SHM_ENV:n"
" .asciz "" SHM_ENV_VAR ""n"
"n"
"/* --- END --- */n"
"n";
afl-fuzz.c
这个是我们fuzz启动的入口,代码8000+行(看的我都麻木了- -),下面会挑核心的逻辑来讲,细枝末节不再赘述。
从main函数开始,先是获取时间/扔随机数种子/解析参数/设置异常处理/设置环境变量/设置banner/检查终端/获取CPU核数,然后到了设置共享内存的函数
EXP_ST void setup_shm(void) {
u8* shm_str;
if (!in_bitmap) memset(virgin_bits, 255, MAP_SIZE);
//数组用来存储有无见过崩溃/tmouts
memset(virgin_tmout, 255, MAP_SIZE);
memset(virgin_crash, 255, MAP_SIZE);
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
if (shm_id < 0) PFATAL("shmget() failed");
atexit(remove_shm);
shm_str = alloc_printf("%d", shm_id);
/* If somebody is asking us to fuzz instrumented binaries in dumb mode,
we don't want them to detect instrumentation, since we won't be sending
fork server commands. This should be replaced with better auto-detection
later on, perhaps? */
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
ck_free(shm_str);
//shm_id是这块共享内存的标识id,NULL地址让系统自动选择合适的一块进行分配
trace_bits = shmat(shm_id, NULL, 0);
if (!trace_bits) PFATAL("shmat() failed");
}
下面是对不同的执行次数进行划分(比如32次到127次都会认为是64次)
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
static u16 count_class_lookup16[65536];
EXP_ST void init_count_class16(void) {
//唔左移动8位相当于移动了一个字节,也就是说是类似(b1)(b2)这样的字节idx的数组,上面原始数组不同范围取最大值,保证2^n
u32 b1, b2;
for (b1 = 0; b1 < 256; b1++)
for (b2 = 0; b2 < 256; b2++)
count_class_lookup16[(b1 << 8) + b2] =
(count_class_lookup8[b1] << 8) |
count_class_lookup8[b2];
}
pivot_input在输出目录中为输入的testcase创建硬链接,其中的mark_as_det_done将一些经过确定性变异的文件放入deterministic_done目录,之后就不会再重复测试。load_extras加载用户自己定义的token,find_timeout设置超时时间,setup_stdio_file设置输入输出目录,check_binary检查二进制文件的合法性(是否是bash文件,是否有ELF头以及是否插桩过了)
下面开始第一次的fuzz,核心函数为perform_dry_run,其功能是将给的所有测试用例跑一遍,确保软件如期工作,故只会跑一遍。需要说明的是这里的文件在初始的时候被抽象到一个自定义的结构体中,且组成了队列,这个结构体如下,含义在注释中均有说明
struct queue_entry {
u8* fname; /* File name for the test case */
u32 len; /* Input length */
u8 cal_failed, /* Calibration failed? */
trim_done, /* Trimmed? */
was_fuzzed, /* Had any fuzzing done yet? */
passed_det, /* Deterministic stages passed? */
has_new_cov, /* Triggers new coverage? */
var_behavior, /* Variable behavior? */
favored, /* Currently favored? */
fs_redundant; /* Marked as redundant in the fs? */
u32 bitmap_size, /* Number of bits set in bitmap */
exec_cksum; /* Checksum of the execution trace */
u64 exec_us, /* Execution time (us) */
handicap, /* Number of queue cycles behind */
depth; /* Path depth */
u8* trace_mini; /* Trace bytes, if kept */
u32 tc_ref; /* Trace bytes ref count */
struct queue_entry *next, /* Next element, if any */
*next_100; /* 100 elements ahead */
};
在这个函数中核心的调用为res = calibrate_case(argv, q, use_mem, 0, 1);,之后对res判断确定程序的运行情况(crash or sth),拿翻译看下,这函数的意思是校准用例,看注释的话意思应该是在输入的时候进行测试,前期发现一些有问题的测试用例。应该一共跑个3次或者8次(取决于是否是快速模式),如果没启动forkserver那么在这用init_forkserver启动。这个函数有必要多讲一下。
开局也不多说,直接就fork出子进程,为其设置一些资源,拷贝文件描述符,设置环境变量等,最终调用execv(target_path, argv);替换进程去执行Binary,由于execv正常是不会返回的,所以出错后后面会在共享内存那里设置一个EXEC_FAIL_SIG,通过对于管道文件的读取可以判断forkserver是否正常启动,这块就和之前插桩的代码联系了起来,判断方式是说如果正常操作会有一个4字节的Hello信息(但是这tm不是五字节吗喂),确保启动正常就进入waitpid(forksrv_pid, &status, 0)的等待,后面对接收到的status进行判断确定子进程的运行状况。
EXP_ST void init_forkserver(char** argv) {
static struct itimerval it;
int st_pipe[2], ctl_pipe[2];
int status;
s32 rlen;
ACTF("Spinning up the fork server...");
if (pipe(st_pipe) || pipe(ctl_pipe)) PFATAL("pipe() failed");
forksrv_pid = fork();
if (forksrv_pid < 0) PFATAL("fork() failed");
if (!forksrv_pid) {
//子进程
struct rlimit r;
/* Umpf. On OpenBSD, the default fd limit for root users is set to
soft 128. Let's try to fix that... */
if (!getrlimit(RLIMIT_NOFILE, &r) && r.rlim_cur < FORKSRV_FD + 2) {
//设置可以打开的最大的文件描述符的数量
r.rlim_cur = FORKSRV_FD + 2;
setrlimit(RLIMIT_NOFILE, &r); /* Ignore errors */
}
if (mem_limit) {
r.rlim_max = r.rlim_cur = ((rlim_t)mem_limit) << 20;
#ifdef RLIMIT_AS
//进程最大的虚地址内存
setrlimit(RLIMIT_AS, &r); /* Ignore errors */
#else
/* This takes care of OpenBSD, which doesn't have RLIMIT_AS, but
according to reliable sources, RLIMIT_DATA covers anonymous
maps - so we should be getting good protection against OOM bugs. */
setrlimit(RLIMIT_DATA, &r); /* Ignore errors */
#endif /* ^RLIMIT_AS */
}
/* Dumping cores is slow and can lead to anomalies if SIGKILL is delivered
before the dump is complete. */
r.rlim_max = r.rlim_cur = 0;
//4 core
setrlimit(RLIMIT_CORE, &r); /* Ignore errors */
/* Isolate the process and configure standard descriptors. If out_file is
specified, stdin is /dev/null; otherwise, out_fd is cloned instead. */
//为子进程分配新的session id
setsid();
dup2(dev_null_fd, 1);
dup2(dev_null_fd, 2);
if (out_file) {
dup2(dev_null_fd, 0);
} else {
dup2(out_fd, 0);
close(out_fd);
}
/* Set up control and status pipes, close the unneeded original fds. */
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
close(ctl_pipe[0]);
close(ctl_pipe[1]);
close(st_pipe[0]);
close(st_pipe[1]);
close(out_dir_fd);
close(dev_null_fd);
close(dev_urandom_fd);
close(fileno(plot_file));
/* This should improve performance a bit, since it stops the linker from
doing extra work post-fork(). */
//非延迟绑定
if (!getenv("LD_BIND_LAZY")) setenv("LD_BIND_NOW", "1", 0);
/* Set sane defaults for ASAN if nothing else specified. */
setenv("ASAN_OPTIONS", "abort_on_error=1:"
"detect_leaks=0:"
"symbolize=0:"
"allocator_may_return_null=1", 0);
/* MSAN is tricky, because it doesn't support abort_on_error=1 at this
point. So, we do this in a very hacky way. */
setenv("MSAN_OPTIONS", "exit_code=" STRINGIFY(MSAN_ERROR) ":"
"symbolize=0:"
"abort_on_error=1:"
"allocator_may_return_null=1:"
"msan_track_origins=0", 0);
execv(target_path, argv);
//失败会到这里来
/* Use a distinctive bitmap signature to tell the parent about execv()
falling through. */
*(u32*)trace_bits = EXEC_FAIL_SIG;
exit(0);
}
//父进程
/* Close the unneeded endpoints. */
close(ctl_pipe[0]);
close(st_pipe[1]);
fsrv_ctl_fd = ctl_pipe[1];
fsrv_st_fd = st_pipe[0];
/* Wait for the fork server to come up, but don't wait too long. */
it.it_value.tv_sec = ((exec_tmout * FORK_WAIT_MULT) / 1000);
it.it_value.tv_usec = ((exec_tmout * FORK_WAIT_MULT) % 1000) * 1000;
setitimer(ITIMER_REAL, &it, NULL);
rlen = read(fsrv_st_fd, &status, 4);
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 0;
setitimer(ITIMER_REAL, &it, NULL);
/* If we have a four-byte "hello" message from the server, we're all set.
Otherwise, try to figure out what went wrong. */
if (rlen == 4) {
OKF("All right - fork server is up.");
return;
}
if (child_timed_out)
FATAL("Timeout while initializing fork server (adjusting -t may help)");
if (waitpid(forksrv_pid, &status, 0) <= 0)
PFATAL("waitpid() failed");
if (WIFSIGNALED(status)) {
if (mem_limit && mem_limit < 500 && uses_asan) {
SAYF("n" cLRD "[-] " cRST
"Whoops, the target binary crashed suddenly, before receiving any inputn"
" from the fuzzer! Since it seems to be built with ASAN and you have an"
" restrictive memory limit configured, this is expected; please readn"
" %s/notes_for_asan.txt for help.n", doc_path);
} else if (!mem_limit) {
SAYF("n" cLRD "[-] " cRST
"Whoops, the target binary crashed suddenly, before receiving any inputn"
" from the fuzzer! There are several probable explanations:nn"
" - The binary is just buggy and explodes entirely on its own. If so, youn"
" need to fix the underlying problem or find a better replacement.nn"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and mayn"
" break afl-fuzz performance optimizations when running platform-specificn"
" targets. To fix this, set AFL_NO_FORKSRV=1 in the environment.nn"
#endif /* __APPLE__ */
" - Less likely, there is a horrible bug in the fuzzer. If other optionsn"
" fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.n");
} else {
SAYF("n" cLRD "[-] " cRST
"Whoops, the target binary crashed suddenly, before receiving any inputn"
" from the fuzzer! There are several probable explanations:nn"
" - The current memory limit (%s) is too restrictive, causing then"
" target to hit an OOM condition in the dynamic linker. Try bumping upn"
" the limit with the -m setting in the command line. A simple way confirmn"
" this diagnosis would be:nn"
#ifdef RLIMIT_AS
" ( ulimit -Sv $[%llu << 10]; /path/to/fuzzed_app )nn"
#else
" ( ulimit -Sd $[%llu << 10]; /path/to/fuzzed_app )nn"
#endif /* ^RLIMIT_AS */
" Tip: you can use http://jwilk.net/software/recidivm to quicklyn"
" estimate the required amount of virtual memory for the binary.nn"
" - The binary is just buggy and explodes entirely on its own. If so, youn"
" need to fix the underlying problem or find a better replacement.nn"
#ifdef __APPLE__
" - On MacOS X, the semantics of fork() syscalls are non-standard and mayn"
" break afl-fuzz performance optimizations when running platform-specificn"
" targets. To fix this, set AFL_NO_FORKSRV=1 in the environment.nn"
#endif /* __APPLE__ */
" - Less likely, there is a horrible bug in the fuzzer. If other optionsn"
" fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.n",
DMS(mem_limit << 20), mem_limit - 1);
}
FATAL("Fork server crashed with signal %d", WTERMSIG(status));
}
if (*(u32*)trace_bits == EXEC_FAIL_SIG)
FATAL("Unable to execute target application ('%s')", argv[0]);
if (mem_limit && mem_limit < 500 && uses_asan) {
SAYF("n" cLRD "[-] " cRST
"Hmm, looks like the target binary terminated before we could complete an"
" handshake with the injected code. Since it seems to be built with ASAN andn"
" you have a restrictive memory limit configured, this is expected; pleasen"
" read %s/notes_for_asan.txt for help.n", doc_path);
} else if (!mem_limit) {
SAYF("n" cLRD "[-] " cRST
"Hmm, looks like the target binary terminated before we could complete an"
" handshake with the injected code. Perhaps there is a horrible bug in then"
" fuzzer. Poke <lcamtuf@coredump.cx> for troubleshooting tips.n");
} else {
SAYF("n" cLRD "[-] " cRST
"Hmm, looks like the target binary terminated before we could complete an"
" handshake with the injected code. There are %s probable explanations:nn"
"%s"
" - The current memory limit (%s) is too restrictive, causing an OOMn"
" fault in the dynamic linker. This can be fixed with the -m option. An"
" simple way to confirm the diagnosis may be:nn"
#ifdef RLIMIT_AS
" ( ulimit -Sv $[%llu << 10]; /path/to/fuzzed_app )nn"
#else
" ( ulimit -Sd $[%llu << 10]; /path/to/fuzzed_app )nn"
#endif /* ^RLIMIT_AS */
" Tip: you can use http://jwilk.net/software/recidivm to quicklyn"
" estimate the required amount of virtual memory for the binary.nn"
" - Less likely, there is a horrible bug in the fuzzer. If other optionsn"
" fail, poke <lcamtuf@coredump.cx> for troubleshooting tips.n",
getenv(DEFER_ENV_VAR) ? "three" : "two",
getenv(DEFER_ENV_VAR) ?
" - You are using deferred forkserver, but __AFL_INIT() is nevern"
" reached before the program terminates.nn" : "",
DMS(mem_limit << 20), mem_limit - 1);
}
FATAL("Fork server handshake failed");
}
等启动forkserver完毕之后,又一个核心函数出现了,就是这里的run_target,这个函数在之后每次调用新的二进制程序的时候都会使用,其先检查有无启动forkserver,没有的话就先启动一个,否则我们只注重与forkserver的交互即可(使用ctl_fd写,st_fd读),因为binary那边会一直返回子进程的进程号,所以一直等到结果为-1即可中止,最后拿classify_counts((u32*)trace_bits);将结果进行分类。
has_new_bits判断之前的测试有没有增加新的路径(二元的tuple),逻辑应该就是拿virgin_map这个map同trace_bits进行比较.
update_bitmap_score这个函数很有意思,注释里说每当我们发现一个新的路径,都会调用这个函数来判断其是不是更加地favorable,这个favorable的意思是说是否包含最小的路径集合来遍历到所有bitmap中的位,我们专注于这些集合而忽略其他的。核心的比较方式是fav_factor = q->exec_us * q->len;即测试用例执行的时间以及输入长度的乘积,注释说希望找到更快或者规模更小的用例,一旦当前的fav_factor比top_rated[i]要小就会更新这个表,将原来的winner的tc_ref--,当前的插入表中。
至此,我们以及将perform_dry_run中的函数分析完毕。
下面会调用cull_queue函数,函数前的注释说我们已经进入了第二个阶段,即用routine来遍历top_rated entry,不断寻找之前没见到过的bytes并且将它们标为favored。函数首先判断sore_changed是不是为真,之后拿贪心算法找能够遍历到所有节点的最小测试集合,比如有三个节点n0,n1,n2,n3和3个测试用例s1,s2,s3。top_rated[0]=s0,top_rated[s2]=s2且s0覆盖n0,n1;s1覆盖n2其中初始化temp_v=[1,1,1,1],1就表示对应节点没有访问到,初始化为都没访问到。开始先判断temp_v[0]=1,说明没访问到,之后就去看top_rated[0],发现为1,说明存在一个用例能访问到这个n0,因此进一步查看这个用例,得到其覆盖范围trace_mini=[1,1,0]故据此更新temp_v=[0,0,1],往下看n1,访问过了,再看n2仍未访问到,再去看top_rated得到s2,再看s2的覆盖范围更新temp_v,就这样标注s0和s1为favored,如果他俩还没有被fuzz,还要pending_favored++。完成上述操作之后将无用的用例标为冗余。
/* The second part of the mechanism discussed above is a routine that
goes over top_rated[] entries, and then sequentially grabs winners for
previously-unseen bytes (temp_v) and marks them as favored, at least
until the next run. The favored entries are given more air time during
all fuzzing steps. */
static void cull_queue(void) {
struct queue_entry* q;
static u8 temp_v[MAP_SIZE >> 3];
u32 i;
if (dumb_mode || !score_changed) return;
score_changed = 0;
memset(temp_v, 255, MAP_SIZE >> 3);
queued_favored = 0;
pending_favored = 0;
q = queue;
while (q) {
q->favored = 0;
q = q->next;
}
/* Let's see if anything in the bitmap isn't captured in temp_v.
If yes, and if it has a top_rated[] contender, let's use it. */
for (i = 0; i < MAP_SIZE; i++)
if (top_rated[i] && (temp_v[i >> 3] & (1 << (i & 7)))) {
u32 j = MAP_SIZE >> 3;
/* Remove all bits belonging to the current entry from temp_v. */
while (j--)
if (top_rated[i]->trace_mini[j])//这里是之前提到的取反操作
temp_v[j] &= ~top_rated[i]->trace_mini[j];
top_rated[i]->favored = 1;
queued_favored++;
if (!top_rated[i]->was_fuzzed) pending_favored++;
}
q = queue;
while (q) {//标记冗余用例
mark_as_redundant(q, !q->favored);
q = q->next;
}
}
再往后就是一个大的循环,也是AFL最最核心的部分,循环开始依然是用cull_queue对队列进行筛选,如果一个cycle都没有新发现尝试更换策略,最终调用skipped_fuzz = fuzz_one(use_argv);这个函数里对测试用例做了变异,下面一节着重分析这个函数AFL的变异策略
fuzz_one && 变异策略
开始先根据标志位跳过一些测试用例。如果fuzz过或者没有queue_cur->favored标志,会有99%的概率被跳过;如果fuzzed&&no-favored,有90%概率跳过,如果没有fuzz过,有75%概率跳过。
之后打开文件,将内容map到in_buf上。
/* Probabilities of skipping non-favored entries in the queue, expressed as
percentages: */
#define SKIP_TO_NEW_PROB 99 /* ...when there are new, pending favorites */
#define SKIP_NFAV_OLD_PROB 95 /* ...no new favs, cur entry already fuzzed */
#define SKIP_NFAV_NEW_PROB 75 /* ...no new favs, cur entry not fuzzed yet */
假如之前校准的时候有错误,则还会进行一次校准CALIBRATION,当然校准错误的次数有上限,为三次。
下面一步为TRIMMING,调用方式为u8 res = trim_case(argv, queue_cur, in_buf);这个函数主要是用来调整测试用例大小的。起始以文件的1/16大小,一直到1/1024为步长,依次删除文件的某一步长(write_with_gap函数),将得到的check_sum同原来的比较,如果相同说明这部分不会影响测试的结果,删除这部分。
之后调用calculate_score为这次测试的质量进行打分,这个分数在之后的havoc_stage使用。
下面就是主要的变异策略。
BITFLIP就是按位翻转,有多种翻转位数/步长的操作,值得一提的是,如果一段连续的序列翻转之后都不会改变(原执行路径破坏),则可以将这段序列识别为一个token。程序会记录下来为后面变异做准备。之后调用common_fuzz_stuff测试变异后的文件。在8/8模式下,会生成一个eff_map。这个表的意义是如果我们翻转一整个比特都不能得到1(同原执行路径不同),那么这个字节很有可能属于data而非metadata(元数据)。因而在之后的变异中会跳过这些无用的字节。
if (cksum != queue_cur->exec_cksum) {
eff_map[EFF_APOS(stage_cur)] = 1;
eff_cnt++;
}
ARITHMETIC是对数据做加减运算,同样有多种步长/翻转长度模式。这次变换就会利用刚才的eff_map筛选,加减的上限为35,变换过程中还会对数据大小端进行判断。
/* Maximum offset for integer addition / subtraction stages: */
#define ARITH_MAX 35
INTERESTING是做插入/替换等变换,替换成的数字是一些interesting_val,可以看到下面都是一些容易整数溢出的数字。替换的大小也有8/16/32bit
/* Interesting values, as per config.h */
static s8 interesting_8[] = { INTERESTING_8 };
static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 };
static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
/* List of interesting values to use in fuzzing. */
#define INTERESTING_8
-128, /* Overflow signed 8-bit when decremented */
-1, /* */
0, /* */
1, /* */
16, /* One-off with common buffer size */
32, /* One-off with common buffer size */
64, /* One-off with common buffer size */
100, /* One-off with common buffer size */
127 /* Overflow signed 8-bit when incremented */
#define INTERESTING_16
-32768, /* Overflow signed 16-bit when decremented */
-129, /* Overflow signed 8-bit */
128, /* Overflow signed 8-bit */
255, /* Overflow unsig 8-bit when incremented */
256, /* Overflow unsig 8-bit */
512, /* One-off with common buffer size */
1000, /* One-off with common buffer size */
1024, /* One-off with common buffer size */
4096, /* One-off with common buffer size */
32767 /* Overflow signed 16-bit when incremented */
#define INTERESTING_32
-2147483648LL, /* Overflow signed 32-bit when decremented */
-100663046, /* Large negative number (endian-agnostic) */
-32769, /* Overflow signed 16-bit */
32768, /* Overflow signed 16-bit */
65535, /* Overflow unsig 16-bit when incremented */
65536, /* Overflow unsig 16 bit */
100663045, /* Large positive number (endian-agnostic) */
2147483647 /* Overflow signed 32-bit when incremented */
DICTIONARY是替换/插入token到原文件中,共有user extras (over)/user extras (insert)/auto extras (over)。其中替换是有上限的,数量高于上限就按概率替换。
HAVOC综合之前的变异方式,引用Seebug一篇文章
随机选取某个bit进行翻转
随机选取某个byte,将其设置为随机的interesting value
随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个byte,对其减去一个随机数
随机选取某个byte,对其加上一个随机数
随机选取某个word,并随机选取大、小端序,对其减去一个随机数
随机选取某个word,并随机选取大、小端序,对其加上一个随机数
随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
随机选取某个byte,将其设置为随机数
随机删除一段bytes
随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
完成上述变异之后会进入SPLICING,将2个seed文件随机位置分割开,将当前文件的头同另一个文件的尾拼起来,中间还会检查选取的两个文件的差异性以及拼接之后的文件的变异性。之后再给havoc继续折腾,测试,这个seed搞完再换cycle的下一个,一直到一个cycle结束。
然后就是另一个cycle,新的变异(因为上次变异可能找到了新的路径,cull_queue就是发掘新的路径)
locate_diffs(in_buf, new_buf, MIN(len, target->len), &f_diff, &l_diff);
if (f_diff < 0 || l_diff < 2 || f_diff == l_diff) {
ck_free(new_buf);
goto retry_splicing;
}
/* Split somewhere between the first and last differing byte. */
split_at = f_diff + UR(l_diff - f_diff);
总结
花了大概五天时间,翻了很多资料总结成这一篇,参考了很多大佬的资料,说是看源码实际上很多地方卡住然后翻其他人的资料帮助理解,这次的体会就是算法是很重要的,比如那个贪心算法,大二学过不过很久没刷算法有点生疏卡了一会儿。
参考
[https://bbs.pediy.com/thread-254705.htm]
[http://www.wenweizeng.com/2020/01/12/afl-analyze2/]
[https://rk700.github.io/2017/12/28/afl-internals/]
[https://xz.aliyun.com/t/6457#toc-2]
[https://paper.seebug.org/496/#havoc]
[https://xz.aliyun.com/t/4628#toc-3]
[https://xz.aliyun.com/t/4628#toc-3]






发表评论
您还未登录,请先登录。
登录