

通过利用人们的心理漏洞,基于Web的现代网络社会工程(SE,Social Engineering)攻击可操纵受害者下载恶意软件并暴露个人信息。为了有效地吸引用户,某些SE攻击会从登录页面开始构成一系列欺骗性网页,并且在每个网页上都进行浏览器交互,称为多步SE攻击。此外,在网页上执行的不同浏览器交互通常会分支为多个序列,以将用户重定向到不同的SE攻击。
本文提出工具StraySheep,该系统可自动抓取一系列网页并检测各种多步骤SE攻击。本研究评估了StraySheep的三个模块(登录页面收集、网页爬取和搜索引擎检测)的有效性,包括SE攻击登录页面收集率、web爬虫获取SE攻击的效率以及检测攻击的准确性。实验结果表明,StraySheep比Alexa top站点和趋势词搜索结果多发现20%的SE攻击,比简单的爬虫模块提高5倍的爬取效率,检测SE攻击的准确率为95.5%。
0x01 Introduction
社会工程学(SE)在心理上操纵人们执行特定的动作。现代的基于Web的攻击利用SE来进行恶意软件感染和在线欺诈,这被称为基于Web的SE攻击(或简称为SE攻击)。攻击者通过诱人的Web内容或警告消息巧妙地引导用户的浏览器交互,以使用户下载恶意软件或泄漏敏感信息。例如,要下载盗版游戏,用户单击非法下载网页上的下载按钮。然后,显示带有病毒感染警报的弹出窗口。相信虚假信息的用户单击“确认”按钮并下载虚假的防病毒软件。
自动收集SE攻击的常见系统包括访问从搜索引擎收集的网页。这些系统使用Web浏览器来爬取网页并通过仅从每个网页中提取特征来识别特定的SE攻击。但是,某些类型的SE攻击会构成从登录页面开始的一系列网页,并且需要在每个网页上进行浏览器交互(例如,单击HTML元素)才能达到攻击,将其称为多步SE攻击。这是因为每个网页通过使用不同的心理策略逐渐欺骗用户。另外,在网页上执行的不同浏览器交互操作通常会分支为多个序列,从而将用户重定向到不同的SE攻击,因为存在与用户兴趣或心理脆弱性相对应的多种攻击情形。尽管当前的系统仅分析登录页面或进行仅限于特定攻击的浏览器交互,但很少有人努力遵循此类网页序列来收集多步SE攻击。
本文建议使用StraySheep,该系统可自动抓取网页序列并检测从目标网页派生的各种多步骤SE攻击。 StraySheep基于两个关键思想。第一个想法是模拟用户的多步浏览行为,也就是说,通过选择心理上吸引用户以导致他们受到SE攻击的可能元素,有意遵循网页的顺序。 StraySheep不仅遵循网页的单一顺序,而且还对从登录页面派生的多个序列进行爬取。第二个想法是从到达的网页以及整个网页序列中提取特征。与以前的方法从单个网页提取特征的方法不同,StraySheep从单个网页中提取特征或识别没有用户交互(即URL重新命名)而自动导致的恶意URL链,而从这些方法中提取特征它积极且递归地遵循了整个网页顺序。也就是说,StraySheep分析到达的网页的图像和语言特征,到达网页之前发生的浏览器事件(例如,显示弹出窗口和警报)以及导致用户遭受SE攻击的浏览器交互。这些特征代表了所有SE攻击的共同特征,即说服和欺骗用户。因此,通过将这些特征组合到分类序列中,StraySheep可以更准确地检测各种多步SE攻击。
0x02 Background
SE用于通过利用人们的心理来操纵人们执行特定的动作,并且已广泛用于各种基于Web的攻击中,例如恶意软件下载,恶意浏览器扩展安装,调查欺骗和技术支持欺骗。伪装成合法软件可实现恶意软件下载和恶意浏览器扩展安装。调查欺骗会招募被虚假调查奖励吸引的用户,以诱骗他们提供敏感信息并访问攻击者控制的网页。通过说服用户致电假冒的技术支持台并安装键盘记录器,远程访问工具或恶意软件来进行技术支持欺骗。
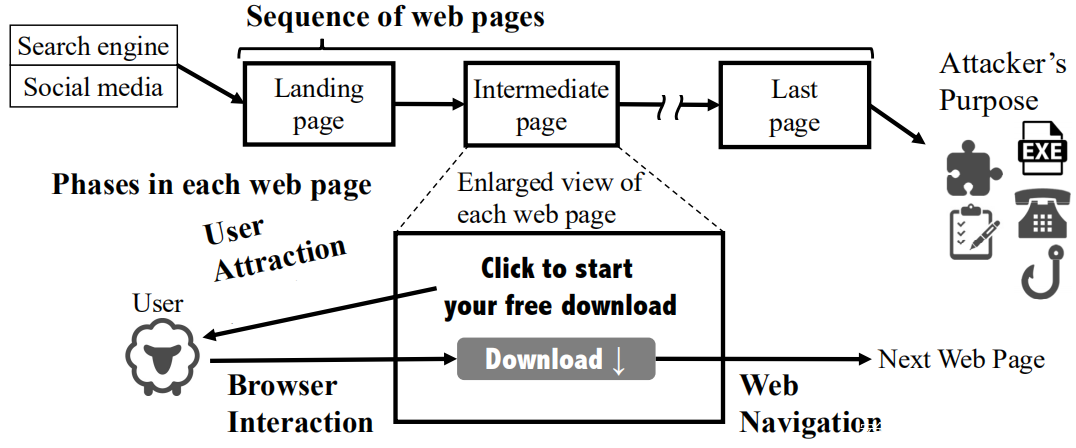
多步骤SE攻击使用多个利用不同心理策略的网页来有效地吸引用户访问后续网页。上图显示了经过多步SE攻击的一系列网页以及每个网页中的三个简化阶段:用户吸引,浏览器交互和Web导航。因此,三个阶段可以从登录页面开始多次重复,该登录页面是响应于单击搜索引擎结果或社交媒体链接而出现的。单个网页上不同的用户交互也会导致不同的SE攻击。
1)对用户的吸引
通过使用网页的内容来欺骗和说服用户诱导浏览器交互,从心理上吸引了用户。例如,这些网页广告可免费下载视频游戏,使用伪造的病毒警告威胁用户,并请求伪造的软件更新。这种心理吸引的主要目的是使用户与导航到恶意软件下载或攻击者控制的网页的HTML元素(例如a和div)进行交互,称此类HTML元素为诱饵元素。诱饵元素的共同之处在于它们包含指示元素行为或类别的单词或形状。诱饵元素具有视觉效果,例如易于理解的包含“单击此处下载”的下载按钮和包含“立即观看”或指向右侧的三角形的电影播放按钮。诱饵元素的特征还在于在其文本内容中包含诸如“ download-btn”和“ video-play-link”之类的词,以及诸如id,class和alt之类的文档对象模型(DOM)属性。多个诱饵元素可以布置在单个网页上。在这种情况下,单击这些诱饵元素会导致不同的SE攻击。
2)浏览器交互
在上一个用户吸引阶段受其影响的用户将被引导与网页上的诱饵元素进行交互。该浏览器交互阶段主要是对诱饵元素的明确单击,但也包括意外单击。例如,意外点击包括单击整个网页,上下文菜单和浏览器的后退按钮上的覆盖图。这些点击是由JavaScript强制生成的,目的是将用户重定向到新网页或显示弹出窗口,而不是用户的意图。
3)网页导航
在Web导航阶段,浏览器事件是由于浏览器交互而发生的。这些浏览器事件重定向到当前窗口或新窗口(弹出窗口)中的另一个网页,显示警报对话框并下载文件。网页重定向发生在多步骤SE攻击的中间步骤中,将用户引导至下一个网页。在下一页上,可能再次发生其他用户吸引力,浏览器交互和Web导航。在没有完成对一个网页的攻击的情况下反复使用户访问多个网页的目的是逐步说服用户并提高攻击的成功率。例如,为了提高在非法流媒体站点上观看电影的用户的攻击成功率,攻击者会显示一个弹出窗口,该弹出窗口为专用视频播放器提供了警告对话框,例如“请安装HD播放器以继续。”在第一个网页上提供自动软件下载的说明。而且,在多步骤SE攻击中的多个网页序列通常从登陆网页或中间网页分支,因为此类网页包含导致不同页面的两个或更多个诱饵元素。
4)收集SE攻击的问题
有三种自动收集SE攻击的方法:跟踪Web流量,使用爬虫进行归档以及使用Web浏览器进行搜寻。
第一种方法是从通过被动网络监视获得的网络流量中重构SE攻击。为了采取措施抵制SE攻击,重要的是不仅要揭示从目标页面到达的单个SE攻击,而且还要揭示从网页分支的所有攻击。但是,该方法仅用于观察用户访问的单个网页序列。而且,它不能用于观察从任意网页开始的SE攻击。即,它不能用于观察未受影响的用户但其他用户可能受到影响的攻击。
第二种方法是使用爬虫(例如Heritrix和GNU Wget)访问每个网页。此类爬虫从下载的网页HTML源代码中提取链接,然后递归地对其进行搜寻。这种方法可以解决第一种方法的问题,该方法无法收集用户未达到的SE攻击,因为它可以输入任意URL。但是,这些爬虫只能执行简单的内容下载和静态内容解析。 SE攻击通常使用JavaScript动态生成的Web内容,这需要用户交互才能导航到下一页。因此,这些类型的爬虫无法收集大多数SE攻击。
第三种方法是使用诸如Selenium之类的工具实现Web浏览器自动化。 Web浏览器自动化能够将用户后期交互与每个网页上的所有元素进行模拟。通过这种方法,可以解决第二种方法的问题。如果将浏览所有链接的想法与第二种方法应用于Web浏览器自动化,即单击每个网页上的所有元素,则理想情况下,可以收集从目标网页派生的所有多步SE攻击。但是,递归地跟踪所有元素会花费大量时间,因为浏览器需要时间来运行JavaScript和呈现网页。
总之,为了在短时间内有效地观察多步骤SE攻击,必须通过从每个网页上的数千个HTML元素中选择可能的诱饵元素来减少要爬取的元素的数量。为了详细分析多步SE攻击,还需要递归地跟踪导致从登陆页面派生SE攻击的多个网页序列,而不是仅跟踪单个网页序列。因此,收集和分析多步骤SE攻击的要求正在通过Web浏览器自动化方法进行爬取,选择可能会导致SE攻击的诱饵元素,并与诱饵元素进行递归交互。
0x03 StraySheep
本文提出了一种名为StraySheep的系统,该系统可以自动收集导致SE攻击的登录页面,对网页进行爬取并检测多步SE攻击。
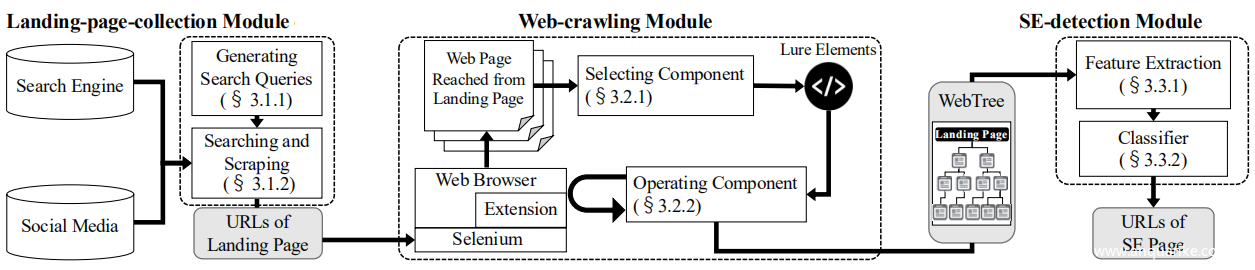
StraySheep包含三个模块:登陆页面收集,网络爬取和SE检测, StraySheep的概述如上图所示。登陆页收集模块通过利用搜索引擎和社交媒体来收集导致SE攻击的网页URL。 Web爬虫模块从登陆页收集模块收集的URL开始递归Web爬取,选择并单击引诱元素,然后输出WebTree。 WebTree由树状抽象数据组成,其中包括在从登录页面分支的每个Web页面上观察到的日志,例如Web导航,浏览器交互作用以及快照(屏幕快照和HTML源代码)。 SE检测模块从WebTree提取特征并使用分类模型识别多步SE攻击。
1)登陆页收集模块
登陆页面收集模块利用搜索引擎和社交媒体来查找登陆页面,作为网络爬虫模块的输入。许多SE攻击使用带有版权的网页(例如非法下载和免费视频流)吸引谨慎的用户。为了诱使用户访问此类网页,攻击者使用搜索引擎优化技术,并在社交媒体上发布消息,这些消息包括指向登录页面的链接。此类社交媒体发布的示例包括用于非法安装软件的说明视频和介绍免费游戏下载站点的消息。为了有效地收集此类登录页面,登录页面收集模块使用基于Web搜索的方法,该方法包括两个步骤:生成搜索查询以及搜索和抓取。
(a)生成搜索查询
登陆页面收集模块生成搜索查询,以搜索可能导致SE攻击的登陆页面的URL。为了生成搜索查询,该模块会收集核心关键字,这些关键字代表付费内容的标题或名称(例如“ Godzilla”和“ Microsoft Office”),并将它们与预定义的限定词(例如free download”, “crack”和“stream online”)。为了收集核心关键字,该模块通过根据每个站点使用预定义的去除逻辑自动去除流行的电子商务(EC)站点和在线数据库站点,并按内容类别(例如,视频,软件和音乐)对核心关键字进行分组。这些核心关键字可以通过重新收集排名和新发行信息来定期更新。
使用限定符的目的是(1)限制搜索结果的覆盖范围,包括非法下载和流式传输,而不是合法站点;以及(2)增加搜索结果的差异。使用搜索引擎上的自动建议/相关搜索功能来预先手动准备限定词。当用户在搜索引擎中查询某个单词时,这些搜索功能会提供相应的关键字预测列表。向搜索引擎输入了一些付费内容标题,并为每个类别收集了限定词,因为需要的限定词根据核心关键字的类别而有所不同。例如,视频的限定词是“stream”, “movie”, “online”。再例如,软件类别的限定词是 “download”, “crack”, “key”。
(b)搜索和提取
该模块通过使用生成的搜索查询从搜索引擎或社交媒体中检索URL。它将它们输入到搜索引擎和社交媒体上的搜索表单中,以广泛收集相应的URL。由于所需的最低搜索功能,某些社交媒体并不总是提供全面的搜索结果。因此,该模块还使用搜索引擎来收集社交媒体帖子。最后,它输出从搜索结果中收集的URL和从社交媒体发布中抓取的链接,作为网络爬取模块的输入。
2)网页爬取模块

Web爬虫模块使Web浏览器自动化,以递归地爬取由登陆页收集模块收集的URL,并输出WebTree作为爬取结果。上图显示了WebTree的概念模型,该模型表示从登陆页派生并由网络隐蔽模块访问的网页序列。 Web爬取模块从登录页面开始,单击网页上的多个诱饵元素,然后递归地跟踪从该登录页面派生的多个网页。深度表示网络爬取的递归计数。当此模块到达完成加载并等待浏览器交互的网页时,深度会增加。该模块使用Selenium和原始的浏览器扩展来自动控制和监视Web浏览器。对于系统的原型,选择Google Chrome作为浏览器,但是Selenium也可以控制其他Web浏览器。因此,网络抓取模块可以使用不同的浏览器。在以下部分中,将描述Web爬取模块的两个组件:选择和操作。
(a)选择组件
选择组件通过分析HTML源代码和网页屏幕截图来收集诱饵元素,该诱饵元素导致导致SE攻击的Web导航表示元素类别或动作的单词通常用于诱饵元素的DOM属性,文本内容以及在按钮图形内绘制的文本,例如,“ download-btn”中的“ download”类属性中的“”,然后在可点击按钮内绘制的文本的“立即点击”中的“点击”。要选择包含诸如诱惑元素之类的关键字的元素,选择组件将解析HTML源代码并执行网页屏幕截图的图像处理。选择组件的目的不是准确地检测导致SE攻击的元素,而是选择可能的诱饵元素以减少与之交互的元素的数量。通过仅遵循选定的元素,Web爬网模块可以有效地达到各种SE攻击。请注意,同一网页上可能有多个诱饵元素;因此,此组件将分析网页上的所有元素。选择组件还执行图像处理的原因是为了补充在按钮图像(即img元素)中绘制的字符串的获取,这是无法从HTML源代码获取的。该组件还通过诱饵元素的形状来标识它们,例如三角形视频播放按钮。
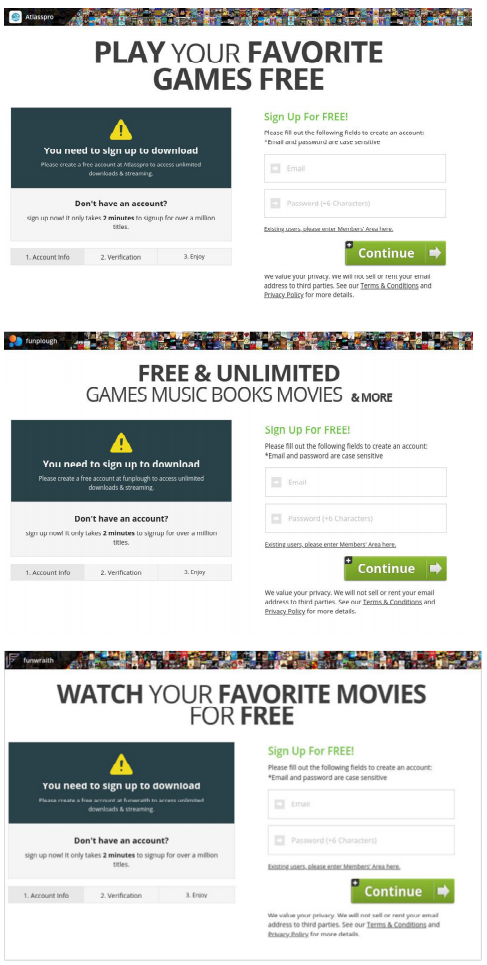
本文解释了一种用于选择诱饵元素的关键字的统计方法,将实际上已将用户重定向到SE攻击的元素(诱饵元素)与尚未将用户重定向到任何SE攻击的其他元素(非诱饵元素)进行比较,并提取特定于诱饵元素的单词。更具体地说,从收集的元素中提取属性,文本内容和在按钮上绘制的字符串,并将这些单词分为两个文档:一个诱饵元素文档和一个非诱饵元素。然后计算两个文档的词频逆文档频率(tf-idf),并从诱惑元素文档中手动选择具有高tf-idf值的单词。
在HTML源代码分析中,如果元素至少符合以下四个规则之一,则此组件将其确定为诱饵元素:
•元素的文本内容中使用了一个关键字。
•在id,class或alt DOM属性中设置了关键字。
•关键字用作链接(元素)或图像(img元素)的URL指示的文件名。
•可执行文件(例如.exe或.dmg)或压缩文件(例如.zip或.rar)用作链接扩展名。
在图像处理分析中,此组件从屏幕快照中提取在每个元素中编写的字符串,并匹配HTML源代码分析中使用的关键字。为了从屏幕截图中确定按钮的坐标和大小,该组件利用OpenCV查找表示按钮区域的矩形轮廓。它还使用光学字符识别(OCR)和Tesseract OCR从发现的组件的矩形中提取字符串。该组件执行与提取的字符串匹配的关键字,并将包含该区域中的关键字之一的元素确定为诱饵元素。为了获取视频播放按钮作为引诱元素,该模块还会找到一个指向右侧的三角形轮廓。最后,该组件会输出多个诱饵元素,这些诱饵元素可能会导致来自网页的SE攻击。
(b)操作组件
操作组件执行浏览器交互(即,点击诱饵元素),监视Web导航并构建WebTree。它模拟了在按下CTRL键以在新的浏览器选项卡中打开网页的情况下点击诱饵元素的情况,因为通过单击即可将当前页面转移到另一个网页。因此,可以在新选项卡中打开链接或弹出窗口,而无需更改原始选项卡。为了模拟前文中描述的意外点击,操作模块还单击了body元素,带有上下文单击的body元素以及浏览器的后退按钮。当打开新选项卡时,选择组件将再次找到诱饵元素,并且操作组件将以深度优先的顺序执行浏览器交互,除非达到预定的最大深度。将在后文中说明在以下实验中使用的最大深度。

该操作组件还监视Web导航。为了监视JavaScript函数调用,此组件将钩住现有的JavaScript函数,以便它可以检测已执行的JavaScript函数名称及其参数。该组件要监视的JavaScript函数是alert(),window.open()和浏览器扩展的安装函数(例如chrom.webstore.install())。函数alert()常用于SE攻击中,该攻击通过突然显示带有引起用户焦虑的消息的对话框来威胁用户。 window.open()函数将打开一个新的浏览器窗口,并用于弹出广告。该组件还挂钩了浏览器扩展的安装功能,并根据参数检测安装了哪种类型的浏览器扩展。该组件还监视URL重定向,该重定向将用户导航到另一个URL。 URL重定向分为客户端重定向和服务器端重定向。当此组件单击诱饵元素时,Web浏览器可能会进行客户端重定向,例如JavaScript函数location.href。另一方面,Web服务器在加载网页之前进行服务器端重定向以导航到另一个网页。该组件监视浏览器在服务器端重定向期间通过的URL,以标识将用户导航到SE攻击的服务器,例如广告提供商。
操作组件进行浏览器交互并监视Web导航,直到完成单击所有选定的诱饵元素为止。该组件从网页序列(即屏幕截图,网页的HTML源代码,浏览器交互和网页导航)中汇总信息,最后输出WebTree作为SE检测模块的输入。
3)SE检测模块
SE检测模块从Web爬网模块输出的WebTree中提取特征,并使用分类模型识别多步SE攻击。该模块首先从WebTree中提取序列。序列被定义为一系列从目标页面(根节点)到最后页面(叶子节点)的呈现的网页。请注意,该序列不代表URL重定向链(多次将用户转发到另一个URL的自动过程),而是代表一系列通过用户交互显示的网页。然后,此模块从到达深度为两个或更多的网页的每个序列中提取特征。与检查URL重定向链的结构相似性的传统方法不同,此模块从整个序列中提取特定于多步SE攻击的特征:网页内容,触发页面转换的浏览器交互以及网络导航。最后,它使用分类器识别每个序列的最后一页是否为SE页,并输出检测到的网页的URL。 4.3节介绍了用于识别SE攻击的基本事实数据。
(a)特征提取
为了对诱使用户进行交互的网页进行分类,通常使用在访问网页后可以获取的信息,例如图像和HTML特征。但是,如果分类程序使用此类特征,则它无法检测到与合法页面相似的SE页面,例如与合法Flash更新页面非常相似的假冒软件更新网页或使用安全厂商徽标的假冒感染警报页面。因此不仅使用从单个网页中提取的特征,还使用从整个序列中提取的所有特征来设计特征向量。具体来说,它分析序列的最后一页,最后一页之前的页面(上一页)以及整个序列,如下图所示分为三个阶段。
SE的优势:对用户吸引力,浏览器交互和Web导航。StraySheep是第一个通过递归地从登录页面爬取网页来自动收集整个序列中的这些特征的系统。就基于用户吸引力的特征而言,StraySheep从最后一页和上一页中提取外观,文档含义和HTML结构。然后,它基于浏览器交互来查找特征,例如在网页上执行的操作以及引诱上一页和整个序列中的元素。 SE检测模块还分析发生在最后一页,上一页和整个序列上的Web导航。将在下面详细说明每个SE攻击阶段的特征提取方法。
对用户的吸引力:网页的外观和文本内容的语义属性包括攻击者诱骗用户的意图。 HTML文档结构也是使用相同文档模板分析网页相似性的重要指标。 SE检测模块从序列的最后一页和上一页提取图像和语言特征。它还从最后一页和前一页计算HTML标签直方图,RGB颜色直方图和文本字段的长度。为了提取图像特征使用AKAZE,这是一种视觉算法,可检测局部图像特征。 SE检测模块使用先前构建的训练模型从最后一页和前一页的屏幕截图中提取128维图像特征。使用Doc2Vec作为文档建模算法来提取语言特征。该模块使用预先训练的doc2vec模型从最后一页和上一页的文本内容中提取300维特征。通过从HTML源代码中清除HTML标签来提取网页文档的文本内容。 SE检测模块还计算屏幕快照的RGB(红色,绿色和蓝色)值的直方图,每种颜色有10个bin,并显示文本内容的HTML标签的直方图。此模块最多使用40个HTML标记(例如div和img),这些标记经常出现在预先收集的网页上。它计算文本内容中的字符数。
浏览器交互:SE检测模块分析引起SE攻击的诱饵元素和动作。为了从浏览器交互中提取特征,该模块计算按顺序执行Web爬虫模块的左击和意外单击(主体单击,主体上下文单击和后退按钮单击)的次数。该模块还计算序列中单击的诱饵元素(a和iframe)的类型,并确定前一页上诱饵元素的大小(x,y)和坐标(宽度,高度)。
Web导航:SE检测模块分析由于浏览器交互而发生的浏览器事件。文件下载和扩展名安装指示与SE攻击直接相关的事件,例如恶意软件下载和摊位中不需要的扩展名。由于SE攻击通常是通过广告提供商传递的,因此重定向具有SE攻击特有的特征。导航方法(例如重定向和弹出窗口)对于分析SE攻击很重要。该模块确定文件的下载和扩展安装是否发生在最后一页和上一页。它计算显示弹出窗口的时间以及在服务器端和客户端重定向期间观察到的URL数量。它还检查显示的警报对话的数量和序列的长度,即爬虫深度。
(b)分类器
结合从序列中提取的特征来创建特征向量,并构造一个二元分类器来识别SE网页。使用随机森林作为学习算法,因为可以测量有助于分类的每个特征的重要性。与其他算法相比的评估结果在后文中给出。
0x04 Evaluation
本研究评估了StraySheep的三个模块(登陆页收集,网络爬取和SE检测)。首先通过将StraySheep与先前收集SE攻击的系统进行比较来评估StraySheep的质量优势。然后,根据导致SE攻击的登陆页面数和访问的恶意页面总数,通过将其两种收集方法(搜索引擎和社交媒体)与三种基准URL收集方法进行比较,评估了登陆页面收集模块的有效性和域名。此外还进行了一次爬取实验,通过比较每单位时间到达的恶意域名数量,将其爬虫方法与两种基准爬虫方法进行比较,以确定Web爬虫模块的效率。最后,在检测精度方面证实了SE检测模块的有效性。
1)定性评估
从五个方面对StraySheep与以前的系统进行了定性比较,以收集SE攻击。下表总结了结果。

收集方法:先前用于被动观察HTTP流量以分析SE攻击的系统只能以用户的实际下载事件触发的方式收集信息。另一方面,使用StraySheep主动爬取任意网页能够在许多用户到达网页之前主动检测SE攻击。
与元素互动:要观察多步骤SE攻击,需要与HTML元素进行交互并递归地遵循页面转换。StraySheep可以收集各种SE攻击并观察源自比登陆页面更深的网页的不同类型的调查欺骗。
提取特征:StraySheep从到达的网页中提取图像,HTML结构和语言上下文等特征,并分析序列以准确检测多步SE攻击。如上表所示,以前的系统都没有使用StraySheep中使用的所有特征。
登陆页集合的来源:StraySheep从两个常见的平台收集登陆页:搜索引擎和社交媒体。 StraySheep是使用这两个平台的唯一系统。
收集的SE攻击类型:尽管先前的系统仅限于检测特定攻击,但StraySheep通过遵循每个网页上的诱饵元素来收集各种多步骤SE攻击。
总而言之,StraySheep是第一个通过递归地跟踪网页上的多个诱饵元素来收集多步SE攻击的系统,该SE攻击不限于特定攻击。 StraySheep还通过从到达的网页和序列中提取各种类型的特征来检测多步骤SE攻击。
2)实验装置
在Ubuntu 16.04上为Google Chrome 69实施了StraySheep。它同时在分配了Intel Xeon 32逻辑处理器和256 GB RAM的虚拟机上最多运行32个实例。对于浏览器设置,将用户代理设置为Windows 7的Google Chrome,并为每次登录页面访问重置了浏览器cookie。检索实验跨度为2018年11月至2018年12月,StraySheep使用了一个IP地址。需要为性能评估设置超时时间,因为后文中提到的两个基准Web爬虫模块需要大量时间(最多几周)才能完成Web爬取。在初步实验中,使用StraySheep进行的Web爬取大约90%在一个小时内完成(相似的结果如图5所示);因此,将超时设置为一小时。为了在使用超时时找到收集最大恶意域名的最佳最大深度,将深度从2更改为6。恶意域名的数量单调增加到第四级,并随着深度的增加而减少。因此,在以下实验中,将最大深度设置为4。
为了确定选择诱饵元素的关键字,遵循了前文所述的统计方法。首先,手动浏览登陆页(例如游戏下载,电影流和洪流站点),然后单击各种HTML元素。还浏览了从中导航的中间页面,例如假病毒警报,文件下载以及URL缩短器提供的广告页面。然后,从978个网页中收集了1,447个诱饵元素,确认最终导致了SE攻击。为了确定所访问的网页是否包含SE攻击,使用了URL /域黑名单(Google安全浏览,Symantec DeepSight和hpHosts)来匹配访问的网页,并使用以下命令检查了下载的二进制文件的MD5哈希值:病毒总数。本研究定义了一个SE页面,该页面与其标签与SE攻击(例如,网络钓鱼,技术支持诈骗和调查诈骗)相关联的黑名单相匹配,或者开始下载恶意软件或潜在有害程序(PUP)。在以下实验中,使用了相同的方法来检查SE页面。从登陆页和中间页中随机选择了5,000个不会重定向到任何SE页面的非诱饵元素。创建了包含从属性和文本内容中提取的单词的诱饵元素和非诱饵元素的文档,以计算tf-idf。最后通过排除专有名词(例如游戏和电影标题)和tf-idf值为零的单词,选择了31个特定于诱饵元素的关键字。
3)URL收集的有效性
为了展示StraySheep的登陆页收集模块的有效性,验证了该模块收集的登陆页;因此,使用Web爬行模块递归地爬取登录页面,并确定访问的网页是否引起SE攻击。比较了五种方法(即登陆页收集模块的两种方法(搜索引擎和社交媒体)和三种基准方法(Alexa热门网站,趋势词和核心)导致SE攻击的已收集目标网页的数量)关键字),为每种方法收集了5k个登陆页。
搜索引擎(StraySheep的方法):该方法从EC /数据库站点(例如ama zon.com,steampowered.com,billboard.com和imdb.com)收集了总共3k个核心关键字,从Alexa的前500个站点中进行了选择。这些核心关键字分为五个类别:软件(游戏和应用程序),视频(电影,动画和电视剧),音乐,电子书和漫画。该方法通过将核心关键字与每个类别的平均30个预定义限定词进行连接来生成90k个搜索查询。它使用Microsoft Bing Web搜索API (Bing API)搜索查询,并收集了大约1M个唯一URL。在该网络搜索中,它为每个搜索查询从多达30个搜索结果中收集了URL。请注意,包含相同核心关键字但带有不同限定词的搜索查询有时会返回重复的搜索结果,而某些搜索查询所返回的搜索结果少于30个。最后,从收集的1M URL中随机采样了5k URL,以进行爬虫实验。
社交媒体(StraySheep的方法):该方法还使用与上述搜索引擎实验相同的搜索查询,搜索了七个社交媒体平台(Facebook,Twitter,Youtube,Dailytion,Vimeo,Flickr和GoogleMap)。此方法从发布消息(来自Facebook,Twitter和Flickr),上传视频的描述(来自Youtube,Dailymotion和Vimeo)以及GoogleMap的“我的地图”的描述中提取链接。它使用Youtube,Dailymotion和Facebook上的搜索表单,因为它们具有灵活的搜索机制,并在Bing API中搜索其他社交媒体平台,以针对每个搜索查询最多收集30个社交媒体帖子。它为每个社交媒体平台搜索了1万个搜索查询(从9万个搜索查询中抽样),总共找到了13万个独特的社交媒体帖子。这些搜索查询通常返回少于30个搜索查询。然后,通过抓取这些130k社交媒体帖子,此方法收集了4.5k唯一链接。一些社交媒体帖子不包含任何链接或包含多个链接。最后,从45k链接中随机采样了5k URL,以进行爬虫实验。
Alexa top站点(基准方法):从Alexa top站点收集了前5k个主要域名,并通过在域名中添加“ http://”将其转换为5k URL。
趋势词(基准方法):使用Bing API搜索了从Google趋势收集的前1k个趋势词,并从30k个搜索结果中随机选择了5k个URL(每个查询检索了30个结果)。
核心关键字(基准方法):只需在Bing API中搜索使用上述搜索引擎方法收集的3k核心关键字,然后从90k搜索结果中随机采样5k URL(每个查询检索30个结果)。

上表列出了每种方法的Web爬取结果。导致SE攻击并由搜索引擎和社交媒体方法收集的登陆页面,每5k登陆页面分别占21.2%和16.2%。而这三种基准方法(Alexa top站点,趋势词和核心关键字)的方法要小得多,分别为0.7%,1.3%和0.9%。根据搜索引擎和社交媒体方法的结果,唯一访问的URL和域名的数量大于三种基准方法的数量。从搜索引擎和社交媒体方法收集的URL中获取的恶意软件样本数量也比其他三种方法要多。
4)网页爬取效率
为了评估StraySheep的网络爬虫模块的效率,尤其是跟踪由选择组件选择的诱饵元素的特征,比较了三个网页爬虫模块中被访问网页中SE页面的比例以及达到SE攻击的时间: StraySheep的网络爬虫模块和两个基准网络爬虫模块。然后,比较了StraySheep和TrueClick的爬取性能。
与基准网络爬虫模块和StraySheep的爬取性能比较,实现了两个基准模块:ElementCrawler,它提取网页上的所有可见元素,然后单击它们;以及LinkCrawler,它纯粹选择所有链接元素(HTML标签)带有href属性),然后点击它们。请注意,ElementCrawler选择的元素包含LinkCrawler选择的所有元素。 ElementCrawler和LinkCrawler是StraySheep的网络抓取模块的替代实现,通过将选择组件替换为从HTML源代码中选择所有元素或所有链接的特征来实现。输入到这三个模块的登录页面是与登录页面收集模块收集的相同的10k URL,这是从搜索引擎收集的5k URL和从社交媒体收集的另外5k URL 。在前文中提到的相同条件下,使用ElementCrawler和LinkCrawler新检索了1万个登陆页。将这些抓取结果与上述实验(其中StraySheep的网络抓取模块抓取了1万个登陆页面)的结果进行了比较。以与上述实验相同的方式,使用黑名单和VirusTotal识别了SE页面。

上表列出了每个网络爬虫模块的总页面数,唯一访问的页面数和域名。通过StraySheep的网络爬虫模块访问的唯一访问页面和SE页面的域名数量为6,283页和513个域名,比基线模块大,并且SE页面的页面和域名的百分比也为大于基准模块(分别为8.5和6.7%)。尽管ElementCrawler和LinkCrawler的总页数是StraySheep的网络抓取模块的三倍,但StraySheep的网络抓取模块在所有SE页面中的百分比最高(5.4%)。这是因为StraySheep的网络抓取模块从数千个元素中选择引诱元素来抓取可能导致SE攻击的网页,而ElementCrawler和LinkCrawler只是轮流点击元素并到达许多良性网页。
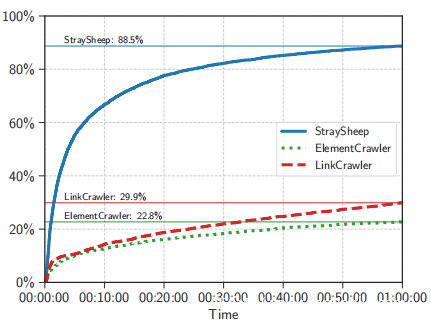
接下来,通过比较完成从目标页面跳转到访问网页所花费的时间来分析每个网络爬虫模块的效率。图5是每个Web爬网模块的时间的累积分布函数(CDF),它显示了从1万个登陆页面开始的所有Web爬网中在特定时间完成的Web爬网的百分比。发现StraySheep的网络抓取模块中有88.5%在一个小时的超时内完成。相比之下,ElementCrawler在超时时间内仅完成了22.8%的Web爬网,而LinkCrawler完成了29.9%。对于StraySheep的网络抓取模块,每个登陆页面完成网络抓取的平均时间为14分钟,对于ElementCrawler为49分钟,对于LinkCrawler为47分钟。
为了衡量网络爬虫模块在整个爬取时间内发现SE攻击的能力,计算了爬取效率:
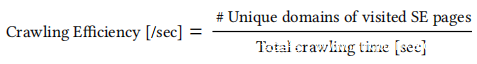
爬取效率表示每单位时间可以到达SE页的唯一域名的能力,较高的爬取效率意味着该模块可以有效地到达新的SE页面。

在上表中显示每个Web爬虫模块的爬取效率。表中的总爬取时间代表完成对1万个登陆页面的爬取时间的总和。StraySheep的Web爬网模块的爬取效率是ElementCrawler的4.1倍,是LinkCrawler的5.1倍,使其成为抵御SE攻击的最有效模块。由于StraySheep的网络抓取模块通过使用选择组件检测到导致SE页面的诱饵元素,因此与两个基线模块相比,它在更少的时间内访问了更多SE页面们还研究了访问SE攻击的能力,这些攻击可以通过多个网页到达。
使用TrueClick和StraySheep进行爬取性能的比较还进行了一项附加实验,比较了StraySheep和TrueClick在爬取SE页面和收集恶意软件可执行文件方面的性能。 TrueClick是一种工具,可将假广告标语与真正的下载链接区分开。 TrueClick与StraySheep的目的相似,它可以找到旨在欺骗用户并定向到恶意网站或恶意软件可执行文件的HTML元素,但它仅能找到广告提供商显示的元素,而与网站所有者的意图无关。
由于TrueClick的源代码尚未发布,因此根据实现详细信息重新实现了TrueClick,使用了手动收集的数据集,其中包含87个假广告标语和51个真实广告,这几乎等于原始数据集(165个假广告标语和94个正版下载链接),以训练机器学习模型。经过训练的模型可以识别出98.6%的假广告标语。然后使用TrueClick实施替换了StraySheep的选择组件,从而创建了基准爬虫模块。


为了等效地比较登陆页收集和网络抓取时间在相同实验条件下的抓取结果,收集了5k URL,并使用StraySheep爬虫模块和基准模块(截至2019年11月)爬取了网络。上表汇总了结果。与TrueClick相比,StraySheep访问的SE页面更多,因为它不仅会诱骗标语,而且还会跟踪网站所有者故意放置的导致SE攻击的按钮和链接。 StraySheep成功下载了266个恶意软件样本,而TrueClick仅下载了1个恶意软件样本。这是因为,在大多数情况下,真正的下载链接会分发恶意软件样本,而不是从登录页面上的第一个假广告标语重定向的网页上的假广告标语。下表显示了在每个深度观察到的唯一SE页面的数量。
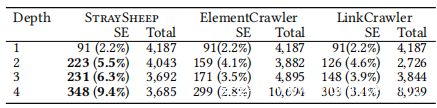
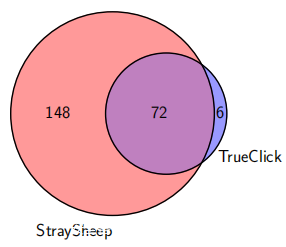
Straysheep随着爬取的深入,遭受了更多的SE攻击。相反,TrueClick到达的SE页面数量明显比深度3减少了很多。这样做的原因是,随着从登陆页更深入地爬取,假广告标语的数量减少了。另外,故意放置的诱饵元素(包括正版下载链接)主要导致更深层次的SE攻击。下图显示了使用每个搜寻器观察到的SE页面域名的重叠情况。尽管StraySheep并未访问由广告动态投放的少量SE页面,但它涵盖了TrueClick观察到的大多数SE页面。总之,要收集更多的多步骤SE攻击,不仅需要检测假广告标语,还需要遵循诱饵元素。
5)评估SE检测模块
使用WebTrees评估了StraySheep的SE检测模块的有效性,WebTrees是StraySheep的网络抓取模块的输出。使用了从3万个登陆页面开始的网络爬取结果构建的30万个WebTree。这些网络树由StraySheep的网络抓取模块抓取的1万个登陆页和另外的2万个登陆页组成。以与前文中提到的1万个登陆页相同的方式,收集并随机采样了2万个登陆页。在相同的环境中同时进行了Web爬取,以输出额外的20k WebTree。
为了创建评估数据集,从30k WebTree中提取了恶意和良性序列。 3万个WebTree包含总共243,914个唯一的网页(13,415个唯一的域)。为了将这些网页标记为SE页面,使用了黑名单和VirusTotal。将51,501个唯一的网页(唯一的1,066个域)标记为SE页面,并提取了1,066个序列,这些序列从不同的登录页面中获得1,066个不同的域名。排除了无法访问或停放的域页面,并创建了1,045个序列作为恶意数据集。为了创建一个良性数据集,随机采样了1,045个未访问SE页面的序列。
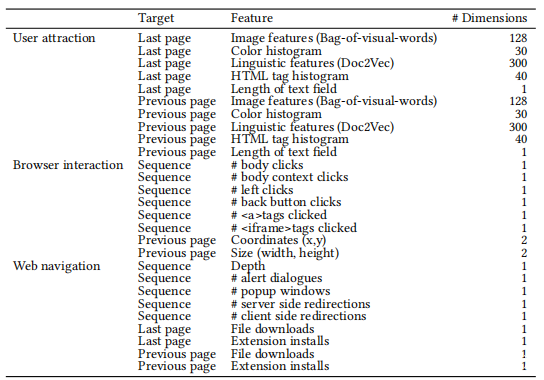
为了评估SE检测模块的检测准确性,对标记的数据集进行了10倍交叉验证(CV)。 SE检测模块对本研究的数据集进行分类的精度为97.4%,召回率为93.5%,准确性为95.5%。当将学习算法从随机森林更改为支持向量机,逻辑回归和决策树时,它们的准确度分别为93.6%,90.8%和90.7%。特征重要性的百分比占从上一页提取的特征(最后一页特征)的65.2%,从前一页提取的特征(上一页特征)的28.2%和从整个序列中提取的特征(序列特征)的6.6%。 ),如上表所示。
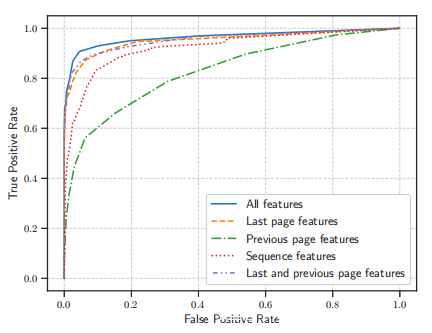
为了显示检测精度与特征之间的关系,将特征分为四个特征集:最后一页,上一页,序列,最后一页和上一页的组合(没有本研究的序列特征的特征集)。使用前文中讨论的具有相同数据集的所有特征集和四个划分的特征集进行了10倍CV。上图显示了分类结果的ROC曲线。最准确的结果是按最后一页和上一页,最后一页,序列,上一页特征集的组合顺序使用所有特征的CV。每个结果的曲线下面积(AUC)为0.965、0.955、0.948、0.923和0.829。该实验表明,本研究分析语言,图像和HTML特征的原始页面级特征可用于检测各种类型的SE攻击,即不仅限于特定的SE攻击。但是,可以使用StraySheep自动收集的上一页的特征和序列进行更准确的分类。
0x05 Detailed Analysis of Detected Multi-Step SE Attacks
按照前文提到的方法对收集的多步骤SE进行了详细分析。为了显示StraySheep发现了各种各样的SE攻击,对观察到的SE页面的域名进行了分类,并研究了攻击者的技术以欺骗和诱骗用户每个SE攻击类别。然后分析了导致SE页面的浏览器交互和广告提供商,以阐明SE攻击的原因,最后调查了托管SE攻击的网络基础架构。
首先解释用于详细分析的检测到的序列和域名。如前所述,有些可疑网页的外观与已知的SE页面相似。为了找到这样的SE页面,利用SE检测模块对评估中未使用的11304个域名的其余192620个序列进行分类。通过从分类结果中手动排除误报(27个域),发现359个域名是SE攻击。这个过程是通过分析屏幕截图来检查建议的软件和扩展或登录页面是否与合法服务相关联的。误报的一个示例是Facebook登录页面,该页面由弹出窗口打开,该弹出窗口通过单击共享按钮从非法软件下载博客重定向。另一个示例是合法的防病毒产品的下载页面,该页面通过单击iframe中的广告进行转移。分析了总共1,404个唯一域名(前文中提到的1,045个域名和新发现的359个域名),共有5,922个序列达到了1,404个域名。从一到三的顺序步数(即页面转换数)分别为11,855(20.8%),13,813(24.3%)和31,254(54.9%)。
1)SE攻击类别

为了明确StraySheep检测到的多步骤SE攻击的类型,将1404个域名分为11类,如上表所示。使用了黑名单标签(Google安全浏览,Symantec DeepSight,hpHosts)和VirusTotal的病毒扫描结果对攻击进行分类,利用AVClass将检测到的二进制文件分类为PUP或恶意软件。还检查了这些域名网页的外观,以补充分类。
PUP和恶意软件:确定的最常见类别是PUP(566个域名)和恶意软件(310个域名)。这些类别是SE攻击,其中由于浏览器交互而下载了PUP和恶意软件。 StraySheep下载了6,924个唯一的二进制可执行文件(例如.exe或.dmg)。例如,发现这些二进制文件被伪装成伪造的游戏安装程序,伪造的防病毒软件和伪造的Java / Flash更新器。在6,924个二进制文件中,通过在VirusTotal中检查它们的MD5哈希值并使用AVClass,检测到1,591个独特的二进制文件,其中包括1,090个恶意软件样本和501个PUP。确认3,336个唯一二进制文件从未上传到VirusTotal,尽管其余的1,997个唯一二进制文件已经上传,但VirusTotal中的任何防病毒软件都未检测到它们。
在3336个未上载的二进制文件中,有2141个具有1347个唯一文件名,这些文件名是根据上一页自动设置的(例如,“ [the title of the previous page] .exe.rename”)。下载这些二进制文件的网页包含说明,以诱使用户删除“ .rename”并执行它们。找到了504个唯一的域名下载这些二进制文件。在这504个域名中,有175个与黑名单匹配,另外329个由StraySheep检测到。使用户更改文件扩展名的原因是为了规避Web浏览器的下载保护功能。由于这些二进制文件的哈希值在每次下载时也会更改,因此从未将任何一个上传到VirusTotal。为了检查这些二进制文件是否是恶意的,从二进制文件中选择了十个样本并将其上载到VirusTotal。然后,将所有十个样本检测为“ StartSurf”或“ Prepscram”家族名称。
不必要的浏览器扩展:将181个域名归为分发不必要的浏览器扩展,确认已将这些域名检测为“假冒浏览器扩展程序下载”或“不需要的扩展程序”,从而导致安装了128个独特的Google Chrome浏览器扩展程序的页面(https://chrome.google.com/webstore )。但是发现爬虫在工作一个月后,浏览器扩展安装页面上仍然有119个(93.0%)扩展可用。通过调查这些浏览器扩展,发现18个(14.1%)扩展是搜索工具栏,而14个(10.9%)扩展是文件转换器。安全厂商的博客文章和在线论坛指出,某些扩展程序是恶意扩展程序或浏览器劫持者,它们会修改网络浏览器设置,跟踪用户的浏览并注入不需要的广告文字。使用真实的浏览器对某些浏览器扩展进行动态分析观察到了可疑行为,例如显示弹出广告以及将默认浏览器的主页和搜索引擎更改为在许多恶意软件示例中进行了硬编码的网页。为了确定这些浏览器扩展的流行程度,在搜索引擎上搜索了每个扩展名。然后发现100个扩展名(78.1%)的搜索结果由一个或多个网页组成,这些网页解释了“如何删除[浏览器扩展名]”或“病毒删除指南”。
令人惊讶的是,这些网页中的大多数不仅介绍了删除方法,还提出了更多伪造的删除工具,这些工具被检测为PUP或恶意软件。攻击者准备了这些网页,以诱骗技术娴熟的用户,这些用户破坏了这些浏览器扩展。因此,即使用户成功删除了不需要的浏览器扩展,他们也成为其他SE攻击的受害者。 StraySheep的SE检测模块在分类的181个域名中新发现了21个域名。 StraySheep通过分析分发网页和导致网页的序列,而不是分析其源代码和行为,成功地找到了不需要的浏览器扩展。
多媒体欺骗:找到了要求注册信用卡的网页(94个域名),以换取免费提供的电影或音乐访问权。它们的内容(例如输入表单,徽标和背景图像)彼此共享。在本文中称它们为多媒体欺骗。黑名单中仅列出了27.7%(26/94)的域名;但是,StraySheep的SE检测模块新发现了72.3%(68/94)的域名。一些安全厂商的博客文章和在线论坛报告说,这些网页欺诈性地向信用卡收费。发现域名中经常使用某些词(例如媒体,戏剧和书籍),例如etnamedia.net,kelpmedia.com,dewymedia.com,parryplay.com,cnidaplay.com和mossyplay.com。
网络钓鱼:观察到94个域名被检测为网络钓鱼,这些域名正试图窃取用户的敏感信息,例如电子邮件地址或密码。
调查欺骗:发现了25个调查诈骗域名,这些域名伪造为著名公司,并承诺奖励iPhone和礼品卡等。StraySheep递归地遵循诱饵元素来检测从没有调查内容的登录页面到达的调查欺骗。
技术支持欺骗:观察到20个技术支持诈骗域名,其中显示了虚假的病毒感染消息和支持中心的电话号码,以敦促用户致电。 StraySheep从搜索引擎的结果和社交媒体发布开始,通过一系列网页达到了欺骗网页,而其他系统则没有发现。
伪造的浏览器历史记录注入:发现16个Fake浏览器的Tory注入攻击域名,该域名向浏览器的历史记录中注入了URL,从而迫使用户在单击浏览器的后退按钮时重定向到另一个SE页面。为了与此类攻击进行交互,StraySheep尝试单击每个网页的“后退”按钮,并确定该操作导致了其他SE页面。
恶意广告重定向:找到了13个Malvertisement网站重定向域,它们也将用户引导到其他SE页面。
加密劫持:发现了三个Cryptojacking域名,它们通过注入JavaScript代码秘密使用用户的CPU资源来挖掘加密货币。
其他SE攻击:除了上述提及的SE攻击外,还观察到其他各种SE攻击,例如,仅检测到“社会工程”标签。
2)多步骤SE攻击的通用基础结构
为了弄清楚多步骤SE攻击的常见基础结构以及攻击者的攻击技巧,分析了导致SE页面的56,922个序列。
意外点击引起的SE攻击:观察到由于意外点击(例如在网页上的任意位置和浏览器的后退按钮上单击)而导致打开的弹出式窗口/弹出式窗口。这类弹出式窗口通常由广告提供商向网页所有者提供的JavaScript代码设置。以下三个文件是在网页上加载最频繁的文件,引导用户访问SE页面:“ c1.popads [.] net / pop.js”,“ cdn.popcash [.] net / pop.js”和“ cdn”. cpmstar [.] com / cached / jspopunder_v101.pack.js”。由于此类广告是SE攻击分发的通用基础结构,因此它们可用于各种网页。发生意外点击导致弹出窗口的序列占所有序列的20.0%(11,373 / 56,922)。在目标网页中,由意外点击引起的弹出窗口发生的顺序为所有顺序的8.7%(4,952 / 56,922)。还观察到了退出驱动的重定向,该重定向是通过单击浏览器的后退按钮触发的,该重定向占所有序列的4.5%(2,578 / 56,922)。
告警对话框:在所有序列中,有2.9%(1,651 / 56,922)包含一个网页,其中显示了多个告警对话框。发现66条不同的告警消息,例如假病毒感染和假奖励,这些消息可能会严重影响用户的心理。为了调查告警消息的内容与临时使用的SE之间的关系,将66条告警消息分类为Comply,Alert和Entice这三个攻击类别。在伪造的Java / Flash更新网页上发现了30个通常用于诱骗用户安装PUP和恶意软件的Comply告警,例如“请安装Java继续”,和“您的Flash Player可能已过时。请安装更新以继续”。发现了19个Entice告警,使用户输入了敏感信息,例如“恭喜!您的IP地址已获选为免费Netflix年会员!”。在某些情况下,发现了17个Alert告警,这些警报告警显示警告消息,例如“需要立即采取措施,我们已经检测到木马病毒”,并带有警报声音(例如,<audio src =“ alert.mp3 ” autoplay>)。指示用户安装假冒的防病毒软件或致电假冒的技术支持中心。
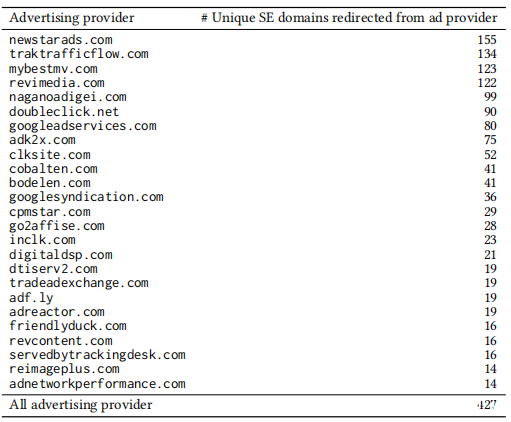
广告域名:在线广告通常会导致SE攻击,为了分析广告提供商提供的SE攻击,从序列上的服务器端重定向中提取了广告提供商的域名(广告域)。利用公共广告提供商列表来确定广告主干。下表列出了广告域以及从每个广告域重定向的SE页面的唯一域名数量,发现25个广告域导致SE攻击。广告域经常发布的SE攻击类别为多媒体欺骗,不需要的浏览器扩展,伪造的防病毒软件(PUP /恶意软件类别)和伪造的Java更新(PUP /恶意软件类别)。重定向到SE页面最多域名的广告域是newstarads.com,该域名包含155个唯一域名。两个域名(doubleclick.net和googleadservices.com)重定向到不需要的浏览器扩展名的89和79个唯一域名,它们也重定向到相同的网络钓鱼域名。研究发现,这些广告域名达到了SE域名总数的30.4%(427 / 1,404)。

SE攻击的发生率:为了衡量有多少用户遇到了多步骤SE攻击,分析了用户访问量的统计信息。如前所述,使用了SameWeb,Alexa Web信息服务(AWIS)和DNSDB来调查StraySheep收集的1,404个域名的网站访问量。
SimilarWeb和AWIS提供了域名的网站访问量统计信息。 DNSDB是一个被动DNS数据库,它提供域名的DNS查询总数。上表列出了在每个深度新发现的唯一域名的数量(按升序排列)以及网站流量和DNS查询的统计信息(最小值,最大值,总和,平均值)。请注意,带有有效数据的#个域名表示不包括零或数据源中不可用的数据的域名数量。由于大多数SE页面的域名都是在第二深度处观察到的,因此在更深的深度处仍然观察到44.9%(630)的域名。换句话说,只有通过使用StraySheep跟踪多个网页才能访问许多更深层次的域名。用户访问和DNS查询的统计数据表明,这些网站的人口数量处于同一水平,并且在较浅的深度观察到了域名,其中某些域名已被以前的系统覆盖。
例如,SimilarWeb在第四层深度(5,676,195)的总访问量平均值与第二层深度(5,682,611)几乎相同,并且比第一层深度(4,740,811)大。同样,在深度3和深度4的AWIS每百万浏览量的总和为511.27,占总数的21.9%。在DNSDB的数据中,第三层深度(181)的有效域名数少于第二层深度(425);但是,DNS查询的总和(302,969,603)大于深度3的DNS(52,593,168)。因此,证明了StraySheep通过从登录页面中删除多个网页可以爬取许多恶意域名。而且,以前的系统无法访问的这些域名具有大量的用户访问权限。原因之一是这些域名是由大型广告提供商分发的,如下表所示。
0x06 Discussion
1)局限性
StraySheep在系统环境,系统实现和系统规避方面存在局限性。
系统环境:在本文讨论的评估中,StraySheep在单个环境中运行。由于广告网络或伪装技术的缘故,某些SE页面可能不会每次都提供相同的网页。具体而言,网站根据源IP地址,Web浏览器环境和浏览历史来更改要交付的网页。在这种情况下,存在当前StraySheep环境中无法达到的SE攻击。但是如前所述,StraySheep不依赖于所选的浏览器环境和连接网络。因此,准备多个浏览器环境和连接网络使本研究能够收集与环境有关的SE攻击。
系统实施:StraySheep实现了基于Web搜索的URL收集方法。因此,源自其他类型来源(例如电子邮件)的攻击不在其范围内。由于SE攻击试图吸引更多用户访问其网页,因此攻击者应准备易于从流行的Web平台(即搜索引擎和社交媒体)访问的登录页面。 StraySheep涵盖了这些平台,并使用易于定制的搜索查询来检索登陆页面。由于互动HTML表单没有在StraySheep当前的网络抓取模块中实现,因此它无法抓取需要登录,创建帐户和进行调查的网页。但是,StraySheep的SE检测模块可以识别这些网页,因为它不仅使用所到达网页的特征,而且还使用从整个序列中提取的特征。
系统绕过:可能存在一种针对StraySheep的网络抓取模块的规避技术,创建一个网页将用户重定向到SE攻击,而无需准备任何诱饵元素。该技术导致StraySheep的SE攻击的收集效率降低。还可能有另一种规避技术,在SE攻击过程中引入了CAPTCHA身份验证。使用StraySheep的当前实现无法收集使用CAPTCHA身份验证的SE攻击。但是,这些规避技术大大减少了潜在受害者的数量,从而导致攻击成功率降低。因此,本研究认为攻击者不太可能真正执行这些规避,因为这有悖于SE攻击的当前趋势。
可能还存在针对StraySheep的SE检测模块的逃避技术,攻击者修改SE页面的外观,以逃避将来网页的设计和结构。但是,此模块还从整个网页序列中提取特征,例如出现弹出窗口显示伪造的感染警报以及用户意外点击引起的重定向。因此认为攻击者仍然难以绕过,因为这些特征代表了攻击者吸引用户访问其网页的有效技术。
2)道德考虑
本文研究遵循研究伦理原则和最佳实践原则。当对各种网站进行并行爬取时,每个爬虫会话都顺序遍历了同一网站上的Web内容,因此只生成了有限量的网站流量,这并没有增加网站的工作量。按照真实的网络浏览器的方式精心抓取了创建的Web请求,并未创建任何破坏或利用网站的有害Web请求。由于使用了真正的Web浏览器,因此爬虫会根据Web浏览器的自然行为忠实执行。此外,进行自动抓取的目的不是破坏良性网络广告的获利模型。除了主动爬取,没有其他现实可行的方法可以直接观察SE攻击。但是,存在意外导致的恶意按点击付费(PPC)或按安装付费(PPI)货币化的风险。本文的爬虫并非故意将精力集中在特定的PPC或PPI服务上。
0x07 Conclusion
本文提出了一个名为StraySheep的系统来爬取网页并检测多步SE攻击。主要思想基于(1)模拟用户的多步浏览行为,以有效地抓取导致SE攻击的网页,以及(2)从已获得的网页以及整个网页序列中提取特征以准确检测这样的攻击。实验结果表明,StraySheep导致的SE攻击比Alexa top站点和趋势词的搜索结果多20%,对SE的攻击效率比简单的爬虫模块高5倍,并且以95.5%的准确率检测SE攻击。 StraySheep对于安全供应商,搜索引擎提供商和社交媒体公司而言,在分析SE攻击趋势方面将非常有用。







发表评论
您还未登录,请先登录。
登录