

iddm带你读论文——SymQEMU:Compilation-based symbolic execution for binaries
本篇文章收录于2021年网络安全顶会NDSS,介绍了最新的符号执行技术,并且清晰地比较了当前流行的各种符号执行的引擎的优劣势,可以比较系统的了解符号执行技术的相关知识
title = {{SymQEMU}: Compilation-based symbolic execution for binaries},
author = {Poeplau, Sebastian and Francillon, Aurélien},
booktitle = {Network and Distributed System Security Symposium},
year = 2021,
organization = {Network \& Distributed System Security Symposium},
month = {February},
affiliations = {Eurecom, Code Intelligence},
extralink = {Details: tools/symbolic_execution/symqemu.html}
download_address = https://www.ndss-symposium.org/wp-content/uploads/2021-118-paper.pdf`
摘要
符号执行技术是针对软件分析和bug检测的强力技术,基于编译的符号执行技术是最近提出的一种方法,当对象源代码可以得到时可以提升符号执行的性能。本文提出了一种新的基于编译的,针对二进制文件的符号执行技术。此系统名为symqemu,在qemu基础之上开发,在将target程序转换为host架构的机器码之前修改其IR,这使得symqemu能够将编译符号执行引擎的能力应用于二进制文件,并且在维持架构独立性的同时能够获得性能上的提升。
本文提出了这个方法以及其实现,我们利用统计学方法证明了他比最先进的符号执行引擎s2e以及qsym,在某些benchmarks上,他甚至由于针对源码带分析的symcc。并且利用symqemu在经过多重测试的library上发现了一个位置漏洞,证明了他在实际软件中的可用性。
介绍
符号执行技术近年来大力发展,一种有效但是代价大的技术,其经常与fuzzing技术混合,并成为混合fuzzing,fuzzing用来探索容易到达的路径,而符号执行用来探索不易到达的路径。
针对符号执行技术的重要特征之一就是其是否需要提供源代码进行分析,而真实世界中的大多数程序(由于某些原因)是不提供源代码的。
所以binary-only的符号执行技术被迫切需要,但是面临一个两难的困境,到底是选择性能的提升还是架构的独立性呢?比如,QSYM针对binary有很高的性能,但是其仅限于x86处理器的指令集。它不仅仅造成了系统架构依赖性,并且由于现在处理器指令的庞大提升了其复杂性。SE则是可以被广泛的应用但是性能较差,S2E可以分析多架构代码以及内核代码。然而他这么做的代价是针对target程序的多种翻译的最终表示,导致了复杂性升高以及影响性能。
在本文中,我们提出了一个方法(a)独立于被测试的程序的target架构(b)实现复杂度低(c)具有高性能。symqemu的关键是qemu的cpu 仿真可以同于轻量级的符号执行机制:不是像s2e中使用中的那种计算复杂度高的将target程序向IR的转换方式,我们hook qemu中的二进制转换机制为了将符号处理直接编译到机器码中。这样使得在性能优于最先进符号执行系统的同时可以保持加够独立性。目前,我们针对于linux用户程序(ELF binaries),但我们可以将其拓展到任何qemu支持的架构中取,同时我们将symqemu开源来加速未来相关领域的研究。
将符号处理编译到target程序中同样是symcc的核心工作,其性能优于其他符号执行引擎,但是symcc只针对于有源码的程序。symqemu性能优于se2以及qsym,并且相比于基于源代码的symcc性能来说,某些情况也是可以比较。
本文工作主要有一下贡献:
- 分析了当前最先进的binary-only的符号执行引擎并且明确了其设计中的优势和劣势。
- 提出了一个方法,融合了其他工具的优势,避免了其他工具的缺点,核心idea是应用基于编译的符号执行技术到binary上,我们工具的源代码开源。
- 进行了详细的评价试验,并且实验数据以及实验脚本开源。
背景
符号执行
符号执行的目的是在目标程序的执行过程中跟踪中间值是如何计算的,每一个中间值都可以表示为程序输入的一个公式。在任何点,系统都会使用这个公式查看这个点是否可达,这个指针是否为空等。如果答案是确定的,那么符号执行引擎将会提供测试用例,一个新的输入例子来触发对应的行为。所以符号执行可以被方便的用来探测程序路径以及触发bug。
为了跟踪程序的计算过程,符号执行系统必须对程序指令集有一个深入的理解,许多实现都是通过将程序翻译为IR,比如LLVM和VEX。IR随后被符号化执行,因为执行器只需要处理IR(通常由少量的指令集构成),所以实现相对比较简单。<font color=red>并且在之前的工作中我们发现,在对进行测试的程序的高级表示的查询较低级指令的表示的查询更加容易解决。</font>
然而将程序转换为IR需要计算能力并且对程序执行过程引入了开销;然而一些实现过程放弃了翻译而直接工作在机器代码上,这种解决方案除了性能上的优势,同时在执行器无法怎样解释指令时,会帮助提升鲁棒性。然而在另一方面,这种解决方案会导致执行器被限制在了一种特定的架构之中。另一种基于源码的执行器在实际中并不是那么广泛使用,因为大多数情况下只能得到二进制文件。
binary-only符号执行
仅仅针对二进制文件的符号执行添加了许多挑战:缺少源代码,将程序翻译为IR需要可靠的反汇编器;由于静态反汇编的挑战,大多数实现都是在运行态按需进行反汇编。当源码不可得时,针对架构的支持同样也是重要的,此时交叉编译不可行。尤其针对嵌入式设备来说,缺少对多架构的支持是不可行的。
无需翻译的执行器除了面对复杂实现带来的可维护问题外,还面临可移植性问题。将程序翻译为中间语言的执行器需要可靠的反汇编器,已经有大量的工作来确定翻译器的准确性。基于源码的执行器可以较容易的获得IR。
基于二进制文件的符号执行对于高性能以及多架构支持具有更迫切的需求。
最先进解决方案
下面描述最先进的符号执行实验方案以及他们各自对应解决的问题。
angr
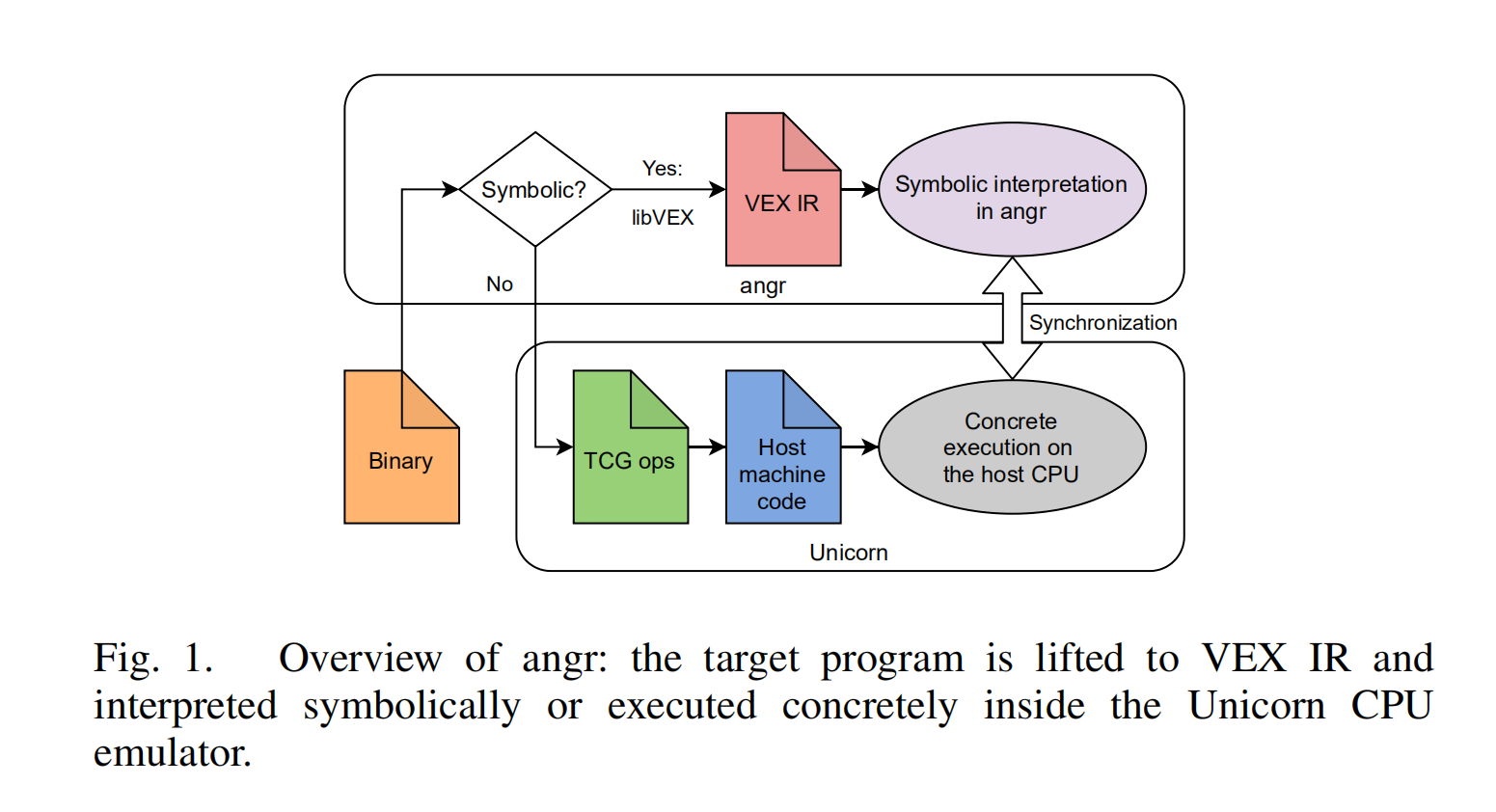
一个经典的符号执行翻译器,使用VEX,Valgrind框架的翻译器和IR。目标程序在运行时被翻译。其中一个优化,angr可以在Unicorn,基于qemu的快速CPU模拟器,上执行不涉及符号数据的计算。
由于基于VEX,agnr固然可以支持所有VEX能够处理的架构,因为angr核心由python语言实现,所以他速度慢但是很通用。
s2e
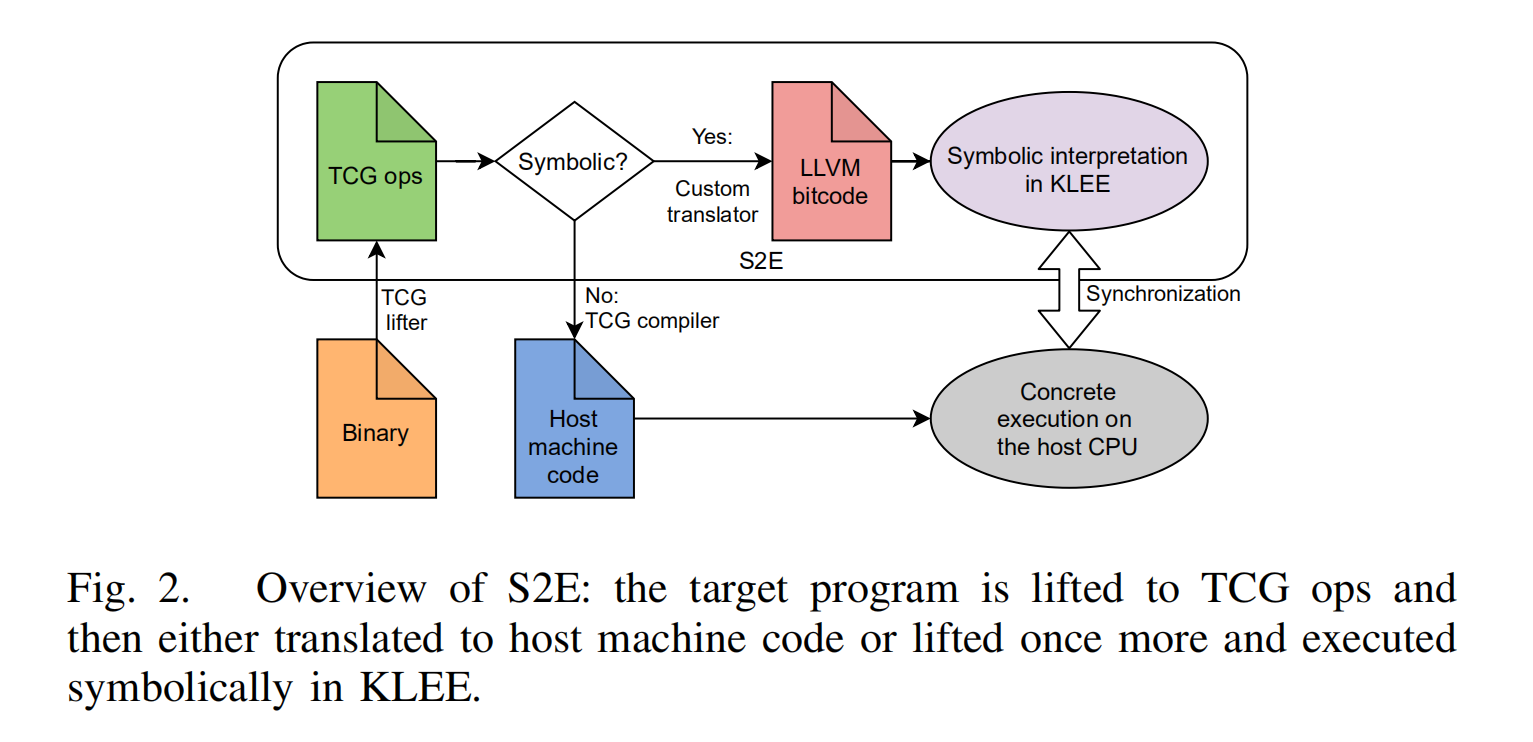
由于想要将基于源代码符号执行覆盖范围拓展到目标程序依赖以及操作系统内核,创造了s2e。为了实现这个目的,s2e在qemu仿真器内执行整个操作系统并且将其与KLEE链接为了符号化执行相关代码。
这个系统相当复杂,包括被测试程序的多重翻译:
- QEMU是一个二进制文件翻译器,比如在通常操作中,他讲目标程序从机器代码翻译为一种中间表示即TCG ops,然后将其重新编译为针对host CPU的机器码。
- 当执行是设计符号化数据时,S2E使用的修改过的QEEMU不再将TCGops重编译为机器代码,他将其翻译为LLVM bitcode,随后将其传递给KLEE。
- KLEE符号化解释执行LLVM bitcode,然后将结果的具体情况回传给QEMU。
此系统可以很灵活的处理不同处理器架构,并且可以支持针对操作系统全层面的计算跟踪。然而他需要付出一下代价:S2E是一个具有庞大代码基础的复杂系统。并且两部分翻译,从机器码翻译为TCG ops和从TCG ops翻译为LLVM bitcode损害了他的性能。与angr针对用户态程序来比较,S2E需要更多的设计建立以及运行,但是提供了一个更加全面的分析。
QSYM
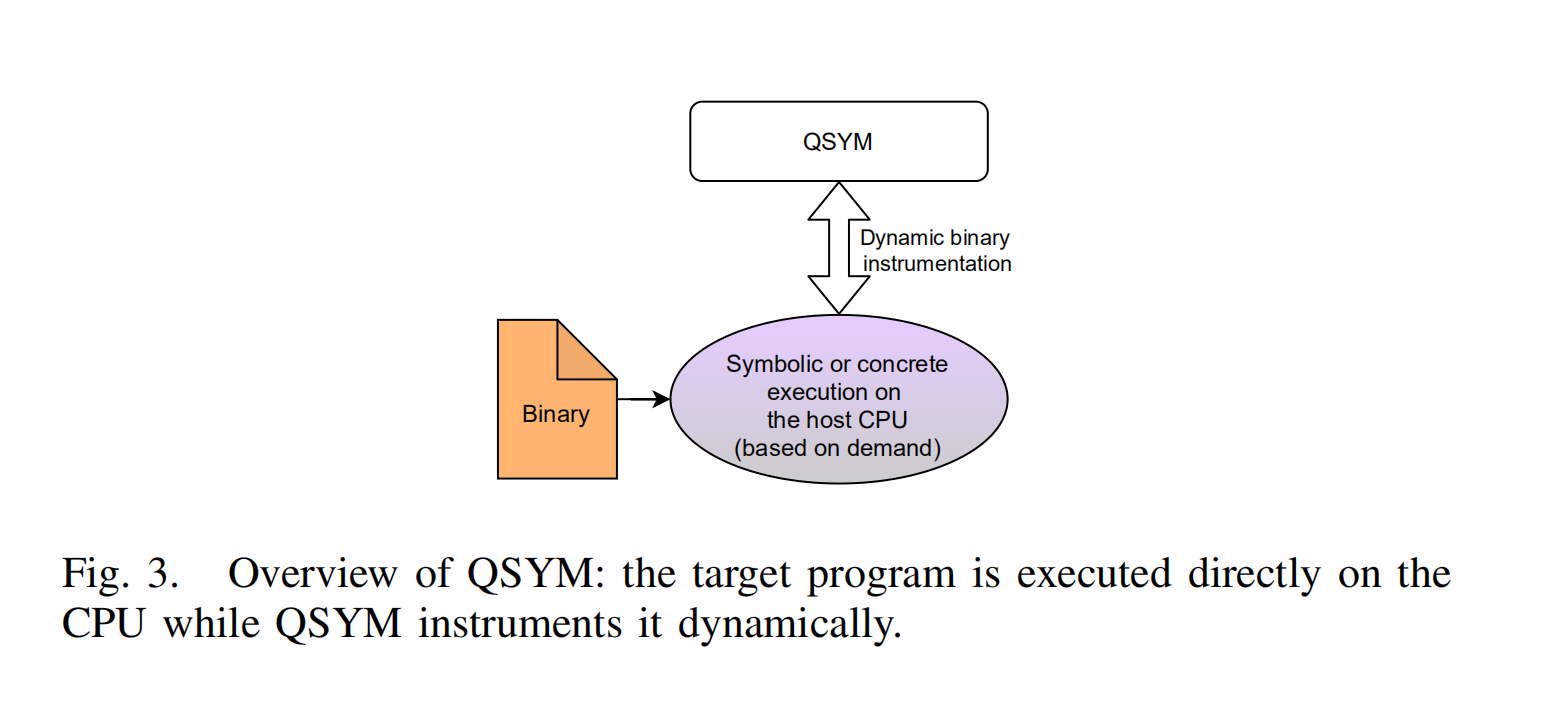
QSYM在性能上有极大的增强,他不将目标程序翻译为中间语言。他在运行态时向x86机器码内进行插桩来向二进制文件内添加符号追踪。具体来讲,他应用了Inter Pin,一种动态二进制插桩框架,来向目标程序内插入hook代码。在hook内部,他和程序运行的实际代码等价的运行符号代码。
这种方式产生了一种针对x86程序的非常快速并且鲁棒性很强的符号执行引擎。然而,这个系统固然会被限制在x86框架内,并且实现是繁琐的,因为他需要处理在计算中可能出现的任何指令。并且将其迁移到其他架构将会有很大的困难。
symcc

最近提出的符号执行工具,SYMCC,同样是本文作者之前的工作,基于源代码的,不支持分析二进制文件。SYMQEMU的灵感来自于SYMCC,所以简要概括一下他的设计。
我们在设计SYMCC时观察到,目前大多数符号执行系统是解释器。然而我们却提出一个基于编译的方法,并且展示了他能够提升执行性能以及系统实际探索能力。SYMCC在编译器内进行hook,并且在target代码内进行插装,并且注入实施支持库的调用。因此符号执行成为了被编译文件的一部分。并且分析代码可以进行优化,并且插装代码并不会在每次执行时进行重复。
SYMCC基于编译的方式需要编译器,所以他只能在被测试程序源代码可用时发挥作用。尽管如此,我们认为这个方式是足够有前途,所以一直寻找一种方式将其应用到binary-only的方面之中,本文的主要工作就是说明基于编译的符号执行系统是如何在二进制文件上高效的工作。
SYMQEMU
现在提出针对binry-only设计实现的SYMQEMU。他的灵感来自于之前的工作并结合了如今最先进的符号执行系统的技术。
design
系统两个主要目标:
- 实现高效能,以致于实际软件。
- 合理的架构独立性,比如将其迁移到新的处理器架构不需要做过多工作。
基于之前的调查,我们发现流行的最先进的符号执行系统实现了如下两个目标中的一个,但并非全部:angr和s2e是架构灵活的但是性能差;QSYM在性能上比较高但是其只针对x86架构。
如今针对架构独立的解决方案是将被测程序翻译为IR,这样如果想要支持一个新的架构,只有翻译器需要移植,理想情况下,我们选择一种中间语言,其已经存在支持多种架构的相关翻译器。以中间语言灵活地表示程序是一种著名的,已经成功的应用于许多其他领域的技术,比如编译器设计以及静态代码分析。我们也将这种技术合并到我们的设计中来。
当将程序翻译为中间语言获得便利的同时,我们同样需要了解这种方式对于性能的影响:将binary-only程序静态翻译是具有挑战性的,因为反汇编器可能是不可靠的,尤其是存在间接跳转的情况下,并且在分析过程中运行时进行翻译会提升功耗。我们认为这是s2e性能劣于QSYM的主要原因。我们的目标就是找到一种翻译系统同时保持性能优越。
首先,我们主要到s2e以及angr都收到了非重要问题的影响,并且这些问题都是可以通过工程方面的工作解决的:
- S2E将被测试程序翻译了两次,然而如果符号执行过程是在第一次中间表示上实现的话,第二次翻译过程其实是可以避免的。
- angr的性能受到python实现影响,将其核心代码移植到一种更快速的语言中会显著提升速度。
然而我们的贡献并不仅仅是找出并且避免上述两个问题,我们还观测到:s2e以及angr,以及其他所有的binaty-only的符号执行器,都解释执行被测试程序的中间表示,解释是设计的核心部分。我们推测,将目标程序编译为插桩版本将会带来很高的性能上的提升。虽然SYMCC是基于源代码的,基于编译的符合执行引擎,但是他证明了这一点。
收到上述观测到的启发,我们的设计方法如下:
- 在运行态将目标程序翻译为IR。
- 为符号执行所需的IR插桩。
- 将IR编译为适合CPU运行分析的机器码并且直接执行。
通过将插桩的目标程序编译为机器码,补偿了在第一阶段将二进制文件翻译为中间代码时的性能损失。CPU执行机器码比解释器运行IR速度快得多,因此我们获得了一个可以与没有翻译的系统的性能相当的系统,同时由于进行了程序翻译可以保持架构的独立性。
implementation
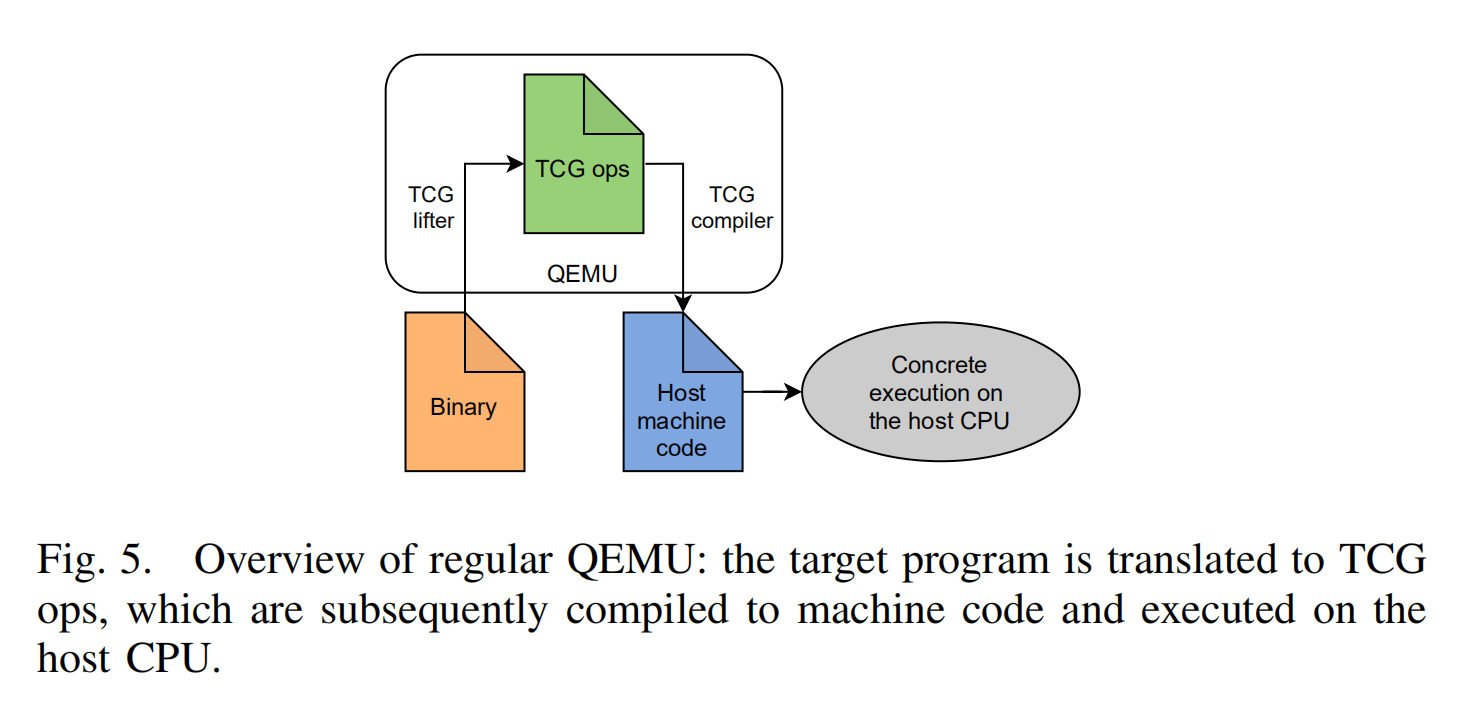
我们在qemu的基础之上实现了SYMQEMU,选择qemu的原因是因为他是一个鲁棒性的系统仿真器,并且可以支持许多架构,在他的基础之上进行实现,我们可以实现架构独立性。并且qemu还有另一个特点正好满足我们的需求,他不仅将二进制文件翻译为针对处理器独立的IR,他同时支持将中间语言便已成为host CPU的机器码。qemu的主要优点是他能够将二进制文件翻译为不同host架构的机器代码,并且可以完成全系统仿真,方便于之后拓展支持交叉架构的固件分析。
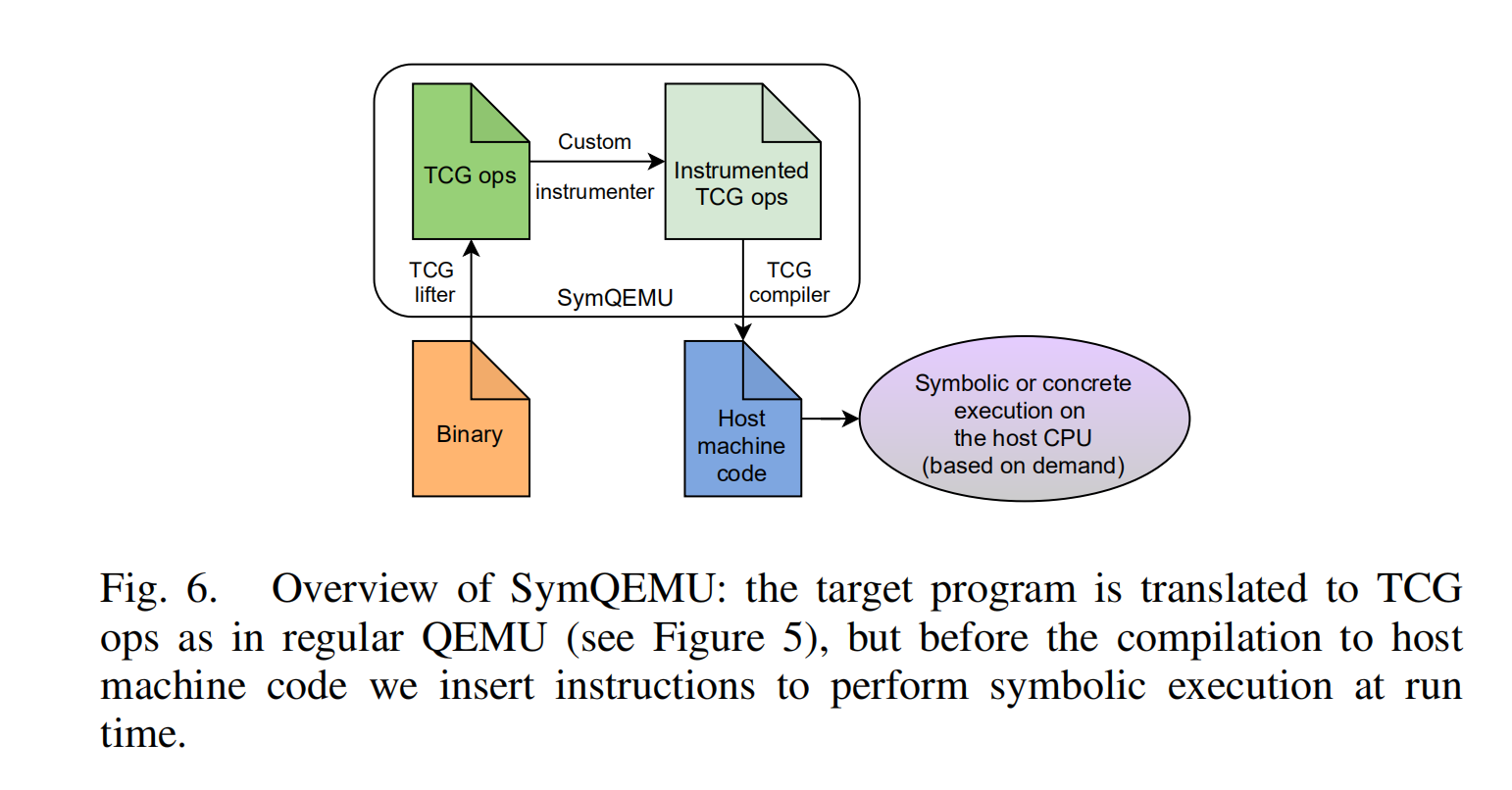
具体来说,我们拓展了QEMU的组件TCG。在未被修改的qemu中,TCG负责将guest架构的机器码块翻译为架构独立的语言,叫做TCG ops,然后编译这些TCG ops为host架构的机器码。由于性能原因,这些翻译好的blocks随后被缓存,所以翻译在每次执行过程中只需要进行一次。SYMQEMU在这过程中插入了一步:当被测程序翻译为TCG ops时,我们不仅插桩来模拟guest CPU而且产生一些额外的TCG ops来建立对应的符号约束表达式。针对建立符号表达式以及求解这些的支持库,symqemu重用SYMCC的支持库,即重用QSYM的。
(此处有详细例子,感兴趣去读原文)
目前我们使用的qemu linux用户模式的仿真,即我们只模拟了普通用户空间的guest系统。系统调用被转换来满足host架构的要求,这些是针对host的内核来工作的,使用了qemu常规的机制。因此我们的符号执行分析在系统调用处停止,与QSYM以及angr类似。与全系统仿真(比如s2e)来讲,这样节省了为每个target架构准备系统镜像的方面,并且提升了性能,因为是直接运行kernel代码而不是通过仿真。但是如果需要的话,SYMQEMU是很容易的被拓展为QEMU的全系统仿真。
架构独立
首先要明确,执行分析的主机的架构叫做host,被测代码在其架构之上被编译的叫做guest。尤其是在嵌入式设备分析中,host与guest架构不同是显然的,嵌入式设备的系统进行符号执行分析的能力不足,所以将固件放置到其他系统中进行分析,SYMQEMU就是为这种情况准备的,能够在多架构下运行。
SYMQEMU利用qemu TCG translators,涵盖多种处理器类型,并且我们针对其修改几乎独立于target架构。
也就是说,SYMQEMU可以在相关的host架构上运行并且可以支持所有qemu能够处理的guest架构下的二进制文件的分析。
与之前的设计比较
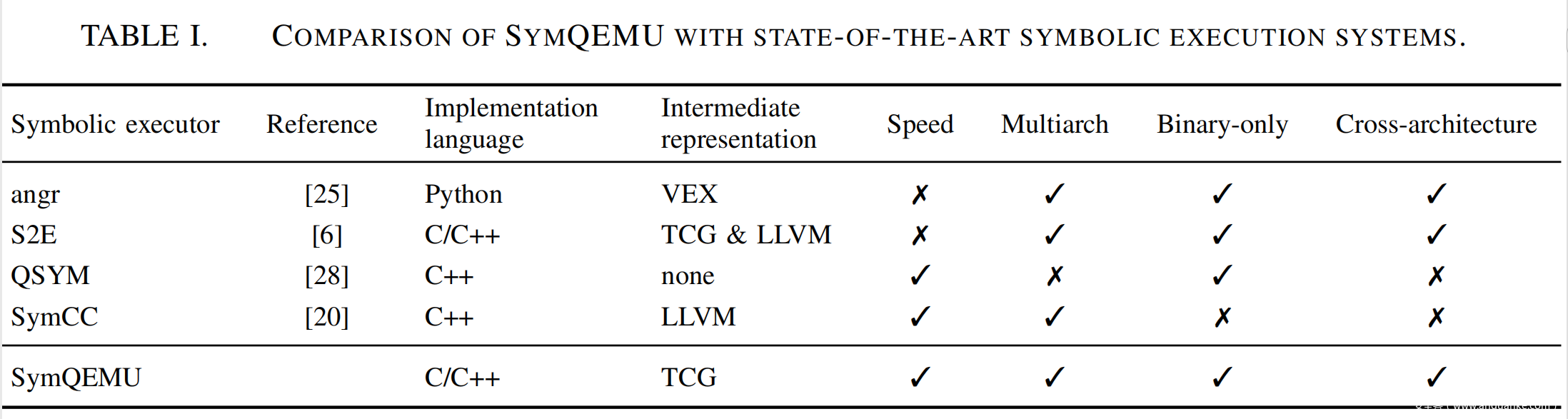
本节之处SYMQEMU与最先进的符号执行系统的不同之处。
与angr和s2e相似,SYMQEMU使用传统的,以IR来完成符号执行处理,显著的降低了实现的复杂性。但是不同于此二者的是,他是基于编译的符号执行技术,显著的提升了性能。
与QSYM比较,SYMQEMU设计最重要的优势是架构灵活性的同时,能够维持很高的执行速度。在qemu之上进行设计使其能够或者很多的数量的模拟器支持的架构处理能力。
SYMCC虽然不能够分析二进制代码,但是其给SYMQEMU提供了基于编译的思路。此二者都是通过修改其IR来在目标程序中插入符号处理,并且都是将结果直接编译为能够高效运行的机器码。然而SYMCC是面向源代码的,而SYMQEMU解决了分析二进制文件的不同指令集的挑战,SYMQEMU在翻译过程中的TCG ops中插桩,SYMCC在编程过程中的LLVM bitcode内插桩。并且SYMQEMU解决了guest和target架构不匹配的问题。
我们认为本文工作结合了s2e以及angr的优势,即多架构支持,同时结合了symcc的优点,高性能,摒弃了他们的缺点;并且我们找到了一种方式,能够将SYMCC的核心idea应用到二进制文件的分析之中。
内存管理
当symqemu分析软件时,他会建立很多符号公式来描述中间结果和路径约束。他们占用的内存会随着时间而一直增长,所以symqemu需要一种方式来清除那些不再被使用的公式。
首先我们讨论一下为什么内存管理是第一位的。IR在任何合理的程序中或对程序流有影响,或者成为最终结果的一部分;在前者情况下,对应的表达式被添加到路径约束的集合中,并且不能被清楚;但是针对后者情况,表达式成为最终结果的描述中的字表达式。所以符号表达式是什么时候变成不重要的呢?关键就是程序的输出是程序结果的一部分,但是他可能在程序的结束之前就已经产生了。
所以我们应该在符号在最后一次使用之后将其清除。QSYM使用的C++ smart points来实现了这个目的,但是我们在被修改的qemu中不能简单的相同的办法:TCG是一个动态翻译器,由于性能因素,它不产生任何被翻译代码的拓展分析。这使得高效的确定插入清除代码的位置非常困难。并且经验告诉我们,大多数程序中包含很少的,在程序执行过程之中无用的,相关符号数据和表达式,所以我们不想我们的清除机制造成很大的功耗。
我们使用了一种乐观的清除机制,在一种expression garbage collector的基础之上:SYMQEMU跟踪所有从后端获得的符号表达式,如果他们的数目非常大时进行回收。最主要的观测是所有live表达式可以通过扫描如下发现
- 模拟的CPU符号寄存器
- 存储对应符号内存结果的符号表达式的,内存中的shadow regions
以上两种,后端都是可感知的。在感知到所有live表达式之后,symqemu将其与所有已经创建的符号表达式进行比较,并且释放那些不再使用的表达式。尤其是当一个程序在寄存器和内存中移除了计算的结果,对应的符号表达式同样被认为不再使用也被移除。我们将 expression garbage collector 和QSYM’s smart pointer based memory management相联系,这两种基础都认为表达式不再使用之后可以被释放。
修改TCG ops
我们的方法要求能够像TCG ops中插桩。然而TCG不支持在翻译过程之中的拓展修改功能,作为一个翻译器,他高度关注速度问题。因为,对于TCG ops的程序化修改的工作很少。然而LLVM提供了丰富的API,支持compiler检查和修改LLVM bitcode。TCG ops单纯的将指令存储在一个平面链表中,而没有任何高层次的类似于基本快的数据结构。并且程序流被期望与翻译块呈线性关系。
为了不和TCG产生不一致,我们的实现对每一个指令生成时进行符号处理。虽然这种方法可以避免与TCG 优化以及代码生成器产生的问题,但是使得静态优化技术不可行,因为我们每次仅仅关注一条指令。尤其是我们无法静态确定给定的值是否是实际值,并且如果所有的操作都是符号值的情况下,我们也不能产生跳过符号计算的阶段的跳转。
因此我们最终于TCG所需要的运行环境的限制条件达成了妥协,同时允许我们有相关很高的执行速度:我们在支持的调用库中进行实际值性检查,这样,如果实际计算的输入都是准确值的话,就可以直接跳过符号值计算,但是这样会导致额外的库调用开销。
shadow call stack
QSYM引入了上下文敏感的基本快剪枝,如果在同样的调用堆栈环境中频繁调用确定的计算会导致压抑符号执行(基于如下直觉,在同样的上下文环境中重复的执行分析并不会导致新的发现)。为了实现这个优化,符号执行需要维护一个shadow call stack,记录跟踪call以及return指令。
在qemu基础之上,我们面临一个新的挑战,TCG ops是一个非常低级别的target程序的中间表示。尤其是,call以及return指令不是被表示为单独的指令而是被翻译为一系列TCG ops。比如一个在x86架构下的程序调用会生成TCG ops,其将返回地址push到模拟的stack上,调整guest的stack pointer,并且根据被调用函数来修改guest的指令。这使得仅仅通过检测TCG ops来以一个可靠并且架构独立的方式来识别call以及return是不可能的。我们选择了如下优化来提高鲁棒性:在架构独立的,能够将机器代码转换为TCG ops的qemu 代码中,每当遇到call和return时,我们会通知代码生成器。缺点就是针对每个target架构,类似的通知代码都必须被插入到翻译代码中去,但这并不复杂。
评价
详见原文,主要是一些指标与测试效果
未来工作
全系统仿真
SYMQEMU目前运行符号执行针对linux用户态二进制程序,之后将会对其拓展到全系统分析,尤其是针对嵌入式设备而言,分析此类程序要求全系统仿真。
我们认为在SYMQEMU实现这一改进是可能的。将target翻译为TCG ops,对其插桩,并将其编译为机器码,这些基本过程不改变。需要添加的一个机制是将符号化数据引入到guest系统中,这是受到S2E fake-instruction技术的启发,以及当在guest内存以及符号表达式之间存在映射时,shadow-memory系统需要记录虚拟MMU的数量。最终将会产生一个不仅可以对用户态程序进行测试,同样可以对内核代码进行测试的系统,并且其同样可分析非linux系统的代码以及裸固件等。
caching across executions
混合fuzzing技术的特点之一是能够对同一程序进行大量的连续执行。作为动态翻译器,SYMQEMU在运行态按需翻译target程序。并且翻译的结果在单个运行的过程之中被缓存,但是当目标程序执行终止时这些缓存结果会被丢弃。我们猜想,可以通过缓存多个执行过程中的翻译结果,可以显著提升结合SYMQEMU的混合FUZZ的性能。主要的挑战就是需要确定目标是确定性加载的,以及针对自我修改代码需要进行特殊处理。所以,这些潜在的优化性能提升主要在于被测程序的特点。
symbolic QEMU helpers
QEMU利用TCG ops表示机器码,然而一些target的指令难以用TCG ops来进行表示,尤其是在CISC架构之上。针对这情况,QEMU使用helpers:可以被TCG调用的内置变异函数,仿真target架构的每一个复杂指令。由于helpers工作在常规的TCG架构之外,SYMQEMU在TCG层级的插桩不能插入符号处理到他们之中。这样的结果是implicit concretization,在分析使用大量目标的指令时会产生精读损失。
我们有如下两种实现qemu helpers符号处理的方式:
- 第一种方式是为每一个要求的helper手动添加符号等价式,更像在一些符号执行引擎中使用的常用libc功能的函数总结。这个方式非常容易实现,但是不方便应用于大数量的helpers中。
- 另一种方式是自动化的实现helpers的符号化版本。为了实现这个目的,SYMCC可以被用来编译符号化追踪到helpers中,他的源代码作为QEMU的一部分是公开的。最终得到的二进制文件是和SYMQEMU兼容的,因为SYMCC的使用相同的符号推理的后端。S2E也是使用类似的方式编译helpers到KLEE中的解释器中的LLVM bitcode。
相关工作
binary-only符号执行
Mayhem是一个高性能的基于解释器的符号执行系统,赢得过DAPRA CGC比赛,然而由于其不开源无法比较性能。Triton是可以以两种方式运行的符号执行系统,一种使用二进制文件转换,类似于QSYM,一种使用CPU仿真,类似于S2E以及angr。Eclipser覆盖了介于fuzzing和符号执行之间的一些中间区域,他认为在分支条件和输入数据之间存在线性关系。这种约束的简化提升了系统的性能,然而他却不能发现常规符号执行系统可以发现的那些路径。Redqueen利用一种启发式的方法寻找路径条件和输入之间的关系。SYMQEMU相比较来说实现了全系统仿真。
运行态bug检测
混合fuzzing依靠fuzzer以及sanitizers来检测bugs。Address sanitizer是一种流行的用来检测确定内存错误的sanitizer。由于其需要源代码来产生插桩程序, Fioraldi et al设计了QASan,基于qemu的系统来对二进制文件实现类似的检测。有大量的需要源代码的sanitizers。我们推测通过QASan的思路,可以将大量上述sanitizers用于二进制文件分析。
混合fuzzing
Driller是基于angr的混合fuzzer,其设计理念类似于QSYM,但是有其angr的python实现以及基于解释器的方式,其执行速度较低。与QSYM以及SYMQEMU比较,它使用了一种更加精细的策略来融合fuzzer以及符号引擎:他监控fuzzer的进展情况,并且当其似乎遇到自身无法解决的障碍时,会自动切换到符号执行。类似的,最近提出的Pangolin通过不仅提供fuzzer测试用例,以及一些抽象的符号约束,还有快速样本生成方法,强调了fuzzer结合符号执行的优势;利用这些,fuzzer能够生成可以有很大概率解决由符号执行生成的路径约束的输入。
我们认为更加精细的符号执行和fuzzer的组合可以很大程度上提升混合fuzzing的性能。
总结
我们提出了SYMQEMU,一种基于编译的,针对二进制文件的符号执行引擎。我们的评价展示了SYMQEMU性能优于最先进的符号执行引擎并且可以在某些方面与基于源代码的符号执行技术相匹配。而且SYMQEMU非常方便的向其他架构进行迁移,只需要几行代码即可。







发表评论
您还未登录,请先登录。
登录