

概述
main()函数return时, 有一些析构工作需要完成
- 用户层面:
- 需要释放libc中的流缓冲区, 退出前清空下stdout的缓冲区, 释放TLS, …
- 内核层面:
- 释放掉这个进程打开的文件描述符, 释放掉task结构体, …
- 再所有资源都被释放完毕后, 内核会从调度队列从取出这个任务
- 然后向父进程发送一个信号, 表示有一个子进程终止
- 此时这个进程才算是真正结束
因此我们可以认为:
- 进程终止 => 释放其所占有的资源 + 不再分配CPU时间给这个进程
内核层面的终止是通过exit系统调用来进行的,其实现就是一个syscall , libc中声明为
#include <unistd.h>
void _exit(int status);
但是如果直接调用_exit(), 会出现一些问题, 比如stdout的缓冲区中的数据会直接被内核释放掉, 无法刷新, 导致信息丢失
因此在调用_exit()之前, 还需要在用户层面进行一些析构工作
libc将负责这个工作的函数定义为exit(), 其声明如下
#include <stdlib.h>
extern void exit (int __status);
因为我们可以认为:
- exit() => 进行用户层面的资源析构 + 调用_exit()进行系统级别的析构
在pwn中, _exit()是无法利用的, 但是exit()是有很多攻击点的, 因此本文会着重分析libc中exit()函数实现, 相关机制, 及其利用手法
exit()源码分析
- exit()为libc中定义的函数, 是对__run_exit_handlers()的包装
void exit(int status)
{
//退出时调用__exit_funcs链表中的函数,__exit_funcs位于libc的.data段
__run_exit_handlers(status, &__exit_funcs, true);
}
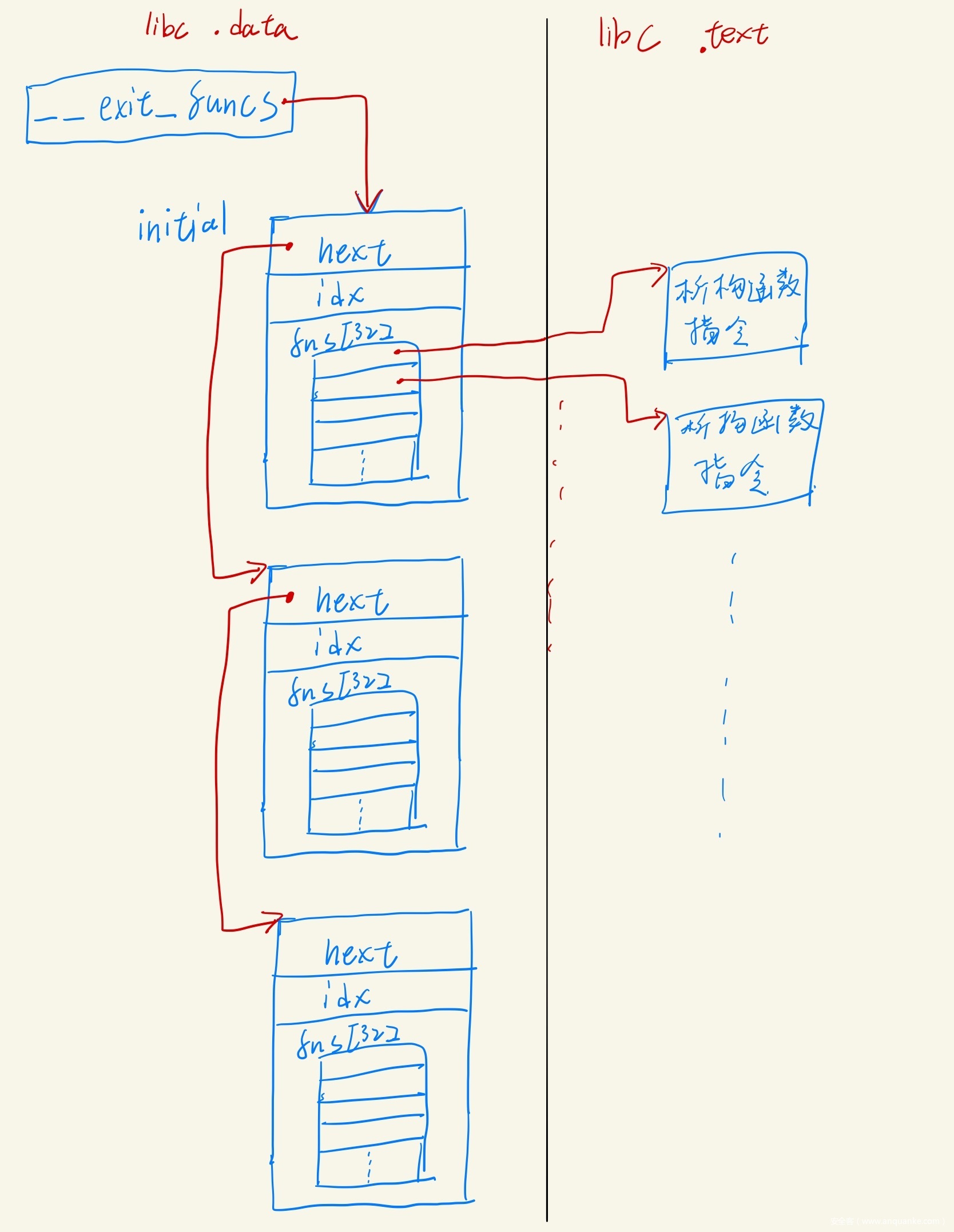
- 其中有一个重要的数据结构:__exit_funcs, 是一个指针, 指向 / 保存析构函数的数组链表/, 其定义如下
static struct exit_function_list initial; //initial定义在libc的可写入段中 struct exit_function_list *__exit_funcs = &initial; //exit函数链表 - exit_function_list结构体定义, 里面保存了多个析构的函数的描述:
struct exit_function_list
{
struct exit_function_list *next; //单链表, 指向下一个exit_function_list结构体
size_t idx; //记录有多少个函数
struct exit_function fns[32]; //析构函数数组
};
- struct exit_function是对单个析构函数的描述, 可以描述多种析构函数类型
//描述单个析构函数的结构体 struct exit_function { long int flavor; /* 函数类型, 可以是{ef_free, ef_us, ef_on, ef_at, ef_cxa} - ef_free表示此位置空闲 - ef_us表示此位置被使用中, 但是函数类型不知道 - ef_on, ef_at, ef_cxa 分别对应三种不同的析构函数类型, 主要是参数上的差异 */ union //多个种函数类型中只会有一个有用, 所以是联合体 { void (*at)(void); //ef_at类型 没有参数 struct { void (*fn)(int status, void *arg); void *arg; } on; //ef_on类型 struct { void (*fn)(void *arg, int status); void *arg; void *dso_handle; } cxa; //ef_cxa类型 } func; };
- 用图片表示如下:
弄清楚libc是如何组织析构函数之后, 分析__run_exit_handlers()是如何处理这些析构函数的
-
run_exit_handlers()的主要工作就是调用exit_funcs中保存的各种函数指针
//调用atexit与on_exit注册的函数,顺序为注册的逆序 void attribute_hidden __run_exit_handlers(int status, struct exit_function_list **listp, bool run_list_atexit) { //首先释放线程局部储存, 即TLS #ifndef SHARED if (&__call_tls_dtors != NULL) #endif __call_tls_dtors(); //遍历exit_fundtion_list链表,链表种每个节点里又有一个函数指针数组,根据里面的函数类型进行调用 while (*listp != NULL) { struct exit_function_list *cur = *listp; //cur指向当前exit_function_list节点 //cur->idx表示cur->fns中有多少个函数,从后往前遍历 while (cur->idx > 0) //遍历exit_function_list节点中 析构函数数组fns[32]中的函数指针 { const struct exit_function *const f = &cur->fns[--cur->idx]; //f指向对应析构函数的描述符 switch (f->flavor) //选择析构函数类型 { //三种函数指针 void (*atfct)(void); void (*onfct)(int status, void *arg); void (*cxafct)(void *arg, int status); //这两种类型不调用 case ef_free: case ef_us: break; //on类型的参数为注册时设定的参数 case ef_on: onfct = f->func.on.fn; //设置函数指针 #ifdef PTR_DEMANGLE PTR_DEMANGLE(onfct); #endif onfct(status, f->func.on.arg); //调用这个函数指针 break; //at没有参数 case ef_at: atfct = f->func.at; #ifdef PTR_DEMANGLE PTR_DEMANGLE(atfct); #endif atfct(); break; //cxa类型则先为设定时的参数,再为状态码 case ef_cxa: cxafct = f->func.cxa.fn; #ifdef PTR_DEMANGLE PTR_DEMANGLE(cxafct); #endif cxafct(f->func.cxa.arg, status); break; } } *listp = cur->next; //listp指向下一个exit_function_list节点 //最后一个链表节点为libc .data段中的initial,不需要释放 //除此以外的节点都是malloc申请得到的, 所以需要释放 if (*listp != NULL) free(cur); } if (run_list_atexit) //调用_atexit RUN_HOOK(__libc_atexit, ()); _exit(status); //真正的exit系统调用 }
劫持__exit_funcs链表?
那么有没有可能通过劫持__exit_funcs去当exit()调用我们想要的函数呢?
我们动态调试来分析一个例子
- 在exit调用run_exit_handlers()时下断点, 找到exit_funcs指针
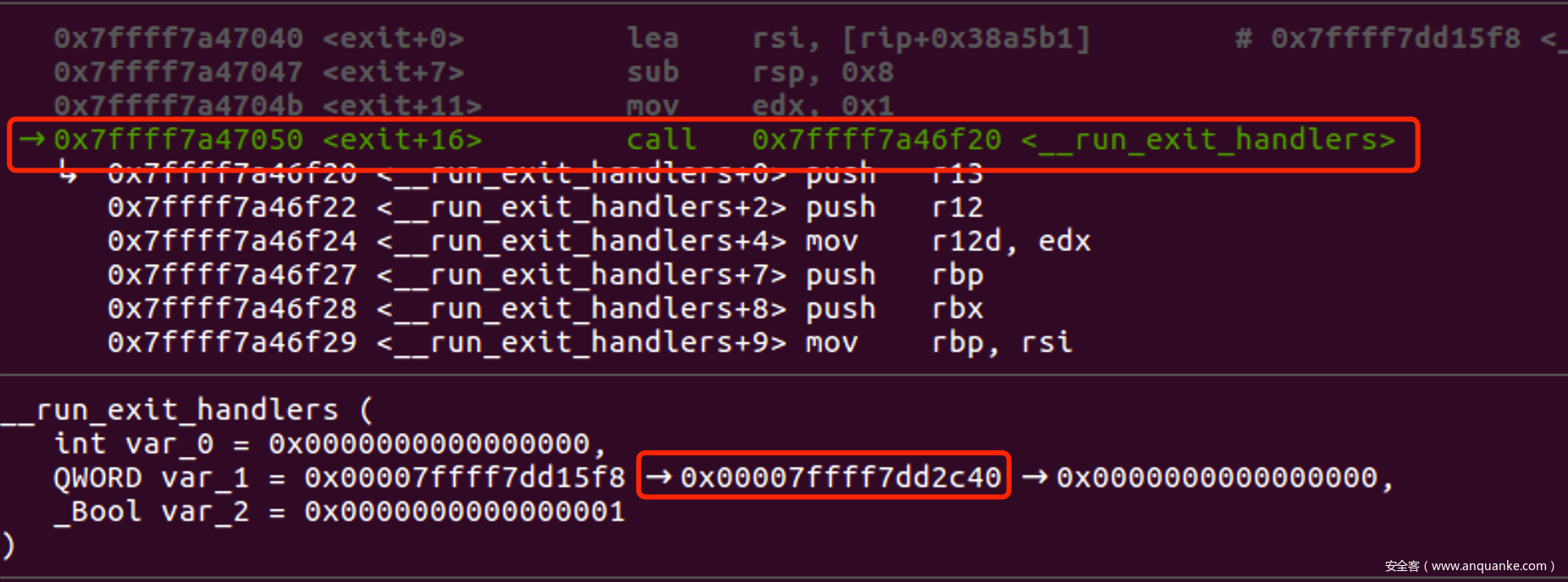
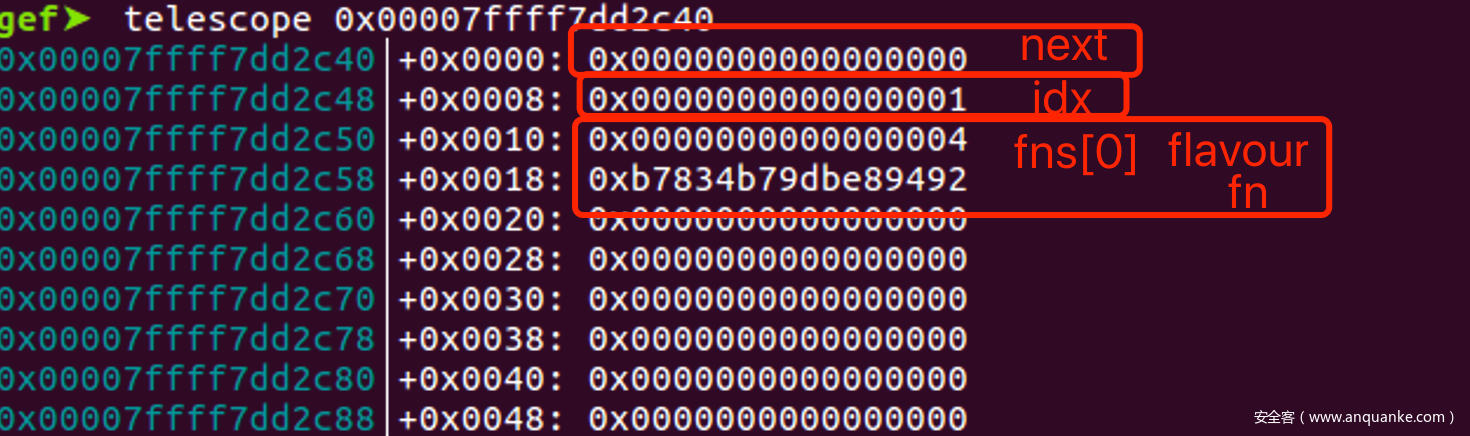
- 查看里面保存的数据, 发现最重要的函数指针fns[0].on.fn是类似于乱码一样的东西, 这是因为libc为了安全, 对其进行的加密
- 我们看一下__run_exit_handles()是怎么解密并调用的
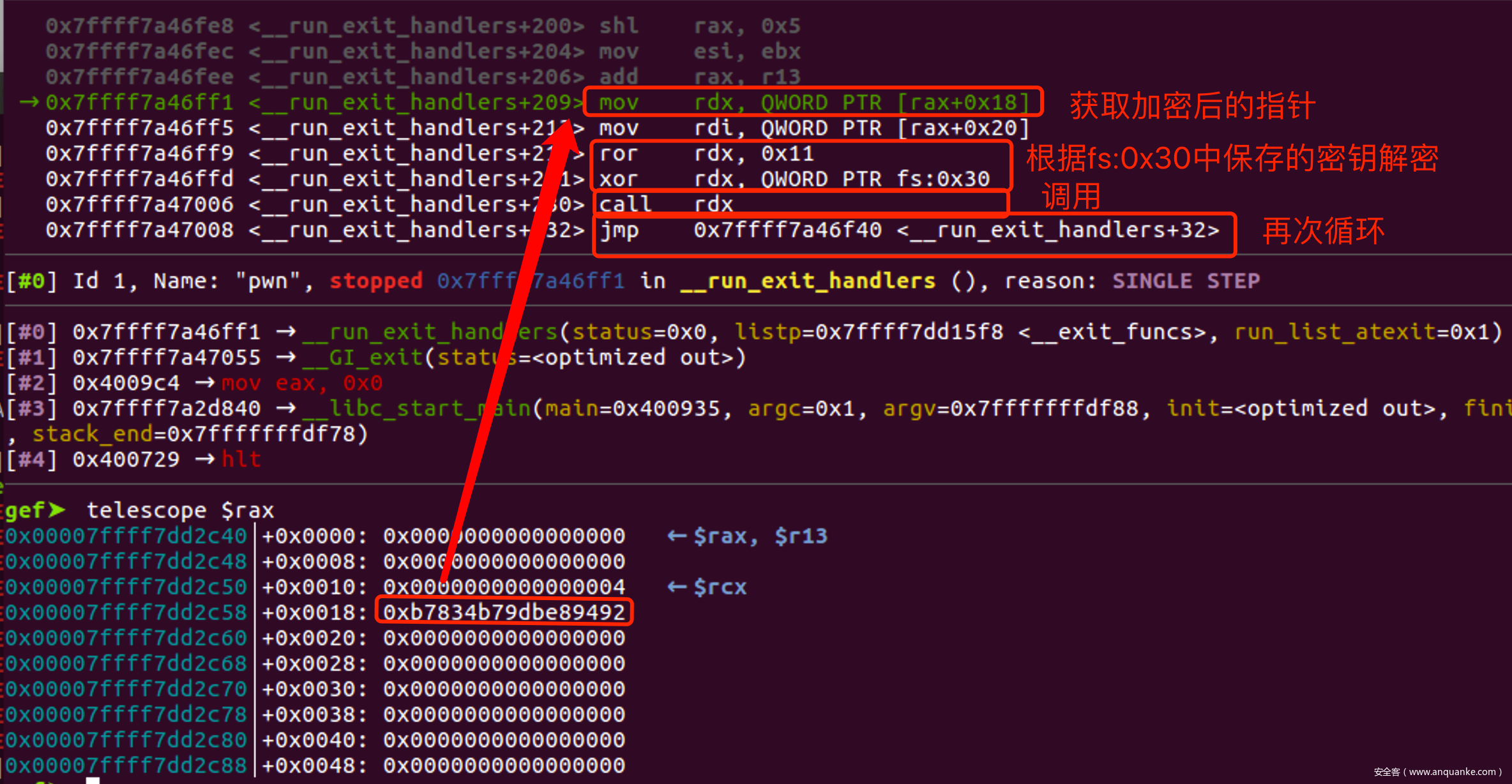
- 其中关键的key是fs:0x30, 那么这又是什么?
- fs是一个段寄存器, 里面存放着GDT表的索引
- CPU开启分段机制后, 段寄存器可以结合gdtr寄存器找到对应段描述符, 根据段描述符得到段的基址, 大小, 属性等等
- x86架构没有对fs怎么使用做出明确规定, linux中让fs指向当前线程的控制块, 也就是tcbhead_t结构体, 也就是说 fs:0x30 寻址结果和 *(tcbhead_t+0x30) 一样
- tcbhead_t定义如下, 栈溢出时常见的 fs:0x28得到的就是tcb中的stack_canary值
typedef struct
{
void *tcb; /* Pointer to the TCB. Not necessarily the
thread descriptor used by libpthread. */
dtv_t *dtv;
void *self; /* Pointer to the thread descriptor. */
int multiple_threads;
int gscope_flag;
uintptr_t sysinfo;
uintptr_t stack_guard; //栈canary, fs:0x28
uintptr_t pointer_guard; //指针加密, fs:0x30
unsigned long int vgetcpu_cache[2];
/* Bit 0: X86_FEATURE_1_IBT.
Bit 1: X86_FEATURE_1_SHSTK.
*/
unsigned int feature_1;
int __glibc_unused1;
/* Reservation of some values for the TM ABI. */
void *__private_tm[4];
/* GCC split stack support. */
void *__private_ss;
/* The lowest address of shadow stack, */
unsigned long long int ssp_base;
/* Must be kept even if it is no longer used by glibc since programs,
like AddressSanitizer, depend on the size of tcbhead_t. */
__128bits __glibc_unused2[8][4] __attribute__ ((aligned (32)));
void *__padding[8];
} tcbhead_t;
综上, 想要劫持__exit_funcs链表, 不仅要能写入, 还需要控制或者泄露tcb中的pointer_guard, 难度太高, 放弃
__exit_funcs如何添加析构函数()
既然难以攻击exit_funcs, 那么尝试从exit_funcs中的函数入手
我们首先要弄明白, __exit_funcs中的函数是怎么添加的
- libc提供了一个接口: atexit()用来注册exit()时调用的析构函数
/* DSO由GCC定义,用来识别模块的*/
extern void *__dso_handle __attribute__((__weak__));
/* 注册一个exit时调用的析构函数*/
int atexit(void (*func)(void))
{
return __cxa_atexit((void (*)(void *))func, NULL, &__dso_handle == NULL ? NULL : __dso_handle);
}
-
cxa_atexit()是对internal_atexit()的封装
- 注意: __exit_funcs就是exit()时是用的那个指针
//注册一个exit/共享库被卸载时调用的函数,只会被C++编译器生产的代码调用,C会通过atexit调用
int __cxa_atexit(void (*func)(void *), void *arg, void *d)
{
return __internal_atexit(func, arg, d, &__exit_funcs);
}
libc_hidden_def(__cxa_atexit)
- internel_atexit()通过new_exitfn()找到一个在__exit_funcs链表上注册析构函数的位置, 然后进行写入
/*
参数:
- func 析构函数指针
- arg 参数指针
- d DSO
- listp 析构函数数组链表指针
*/
int attribute_hidden __internal_atexit(void (*func)(void *), void *arg, void *d, struct exit_function_list **listp)
{
struct exit_function *new = __new_exitfn(listp); //先在__exit_funcs链表上添加一个描述析构函数的结构体
if (new == NULL)
return -1;
#ifdef PTR_MANGLE
PTR_MANGLE(func);
#endif
//然后设置分配到的这个结构体
new->func.cxa.fn = (void (*)(void *, int))func; //函数指针
new->func.cxa.arg = arg; //参数
new->func.cxa.dso_handle = d;
atomic_write_barrier();
new->flavor = ef_cxa; //类型
return 0;
}__new_exitfn()的逻辑大致为
- 先尝试在__exit_funcs中找到一个exit_function类型的ef_free的位置, ef_free代表着此位置空闲
- 如果没找到, 就新建一个exit_function节点, 使用头插法插入__exit_funcs链表, 使用新节点的第一个位置作为分配到的exit_function结构体
- 设置找到的exit_function的类型为ef_us, 表示正在使用中, 并返回
//从listp上返回一个新的exit_function结构体
struct exit_function *__new_exitfn(struct exit_function_list **listp)
{
struct exit_function_list *p = NULL;
struct exit_function_list *l;
struct exit_function *r = NULL;
size_t i = 0;
__libc_lock_lock(lock); //上锁
//寻找一个析构函数类型为ef_free的位置
for (l = *listp; l != NULL; p = l, l = l->next) //遍历链表,l指向当前节点, p指向l的前一个节点
{
for (i = l->idx; i > 0; --i) //搜索l中的函数指针数组fns[32]
if (l->fns[i - 1].flavor != ef_free) //有一个不是ef_free的就停止
break;
if (i > 0) //在l中找到了, 停止链表遍历
break;
/* 只有全部都是ef_free才能走到这里 */
l->idx = 0;
}
if (l == NULL || i == sizeof(l->fns) / sizeof(l->fns[0])) //没有找到空闲位置
{
/*
l==null 说明整个__exit_funcs中都没有ef_free
i == sizeof(l->fns) / sizeof(l->fns[0]) 说明对于l节点, fns已经全部遍历了, 都没找到ef_free
此时就需要插入一个新的exit_function_list节点
*/
if (p == NULL)
{
assert(l != NULL);
p = (struct exit_function_list *)calloc(1, sizeof(struct exit_function_list)); //申请一个结构体, p指向新节点
if (p != NULL) //分配冲哥
{
p->next = *listp; //头插法, 再__exit_funcs中插入一个节点
*listp = p;
}
}
if (p != NULL) //分配成功
{
r = &p->fns[0]; //r指向新节点的第一个析构函数描述结构体
p->idx = 1;
}
}
else //找到空闲位置了, l节点中第i个为ef_free
{
r = &l->fns[i];
l->idx = i + 1;
}
/* 此时这个函数位置的类型从空闲(ef_free)变为使用中(ef_us), 等待写入函数指针 */
if (r != NULL)
{
r->flavor = ef_us;
++__new_exitfn_called;
}
__libc_lock_unlock(lock);
return r;
}
__exit_funcs中有什么函数?
exit()中的析构函数很明显是在main()执行之前就已经注册了, 那么是谁注册的呢?
我们首先需要明白一个程序是怎么启动的?
- 新程序的启动往往是通过libc中exe()系列函数进行的, exe系列函数最终都可以归纳为execve这个系统调用
- 系统层面
- kernel会检查这个文件的类型
- 确定是elf之后会为新进程分配页表, 文件描述符, task描述符等各种资源
- 然后解析这个elf文件, 把text data bss等段都映射到内存中
- 然后jmp到elf的入口点, 从而开始执行
ELF的入口点_start()
但是现代ELF一般都使用了运行时重定位机制
也就是说elf文件的text段还有些地址位置还没有确定, 只有运行是才知道, 比如各种libc库函数的地址, 编译时并不知道libc会被mmap到哪里,
自然也不知道libc中函数的地址
因此如果kernel发现需要运行时重定位, 那么就会转而jmp到这个elf指定的动态链接器(也就是常用的ld.so.2),
由ld去重定位elf中相关地址后再jmp到elf的入口点
但是ld并不是直接执行main()函数, 因为有析构函数就必定有构造函数, 在进入main之前还需要进行参数设置, 申请流缓冲区等操作
实际上ld会跳转到elf中的_start标号处, 这才是elf中第一个被执行的指令地址
- _start标号处的程序由汇编编写, 对应libc中start.S文件,
- _start做的工作很少, 只会为__libc_start_main()设置好参数, 然后调用
- _start()会在编译的时候被链接入ELF文件中
- 而libc_start_main()定义在libc中, _start()通过PLT+GOT调用到libc_start_main()
_start()的源码:
ENTRY (_start) /* 编译时告诉链接器, 这里才是整个函数的入口点 */
/* Clearing frame pointer is insufficient, use CFI. */
cfi_undefined (rip)
/* 初始化栈底: %ebp=0 */
xorl %ebp, %ebp
/* 设置__libc_start_main的参数
调用__libc_start_main的参数会通过如下寄存器传递, 因为linux才用cdecl函数调用约定:
main: %rdi
argc: %rsi
argv: %rdx
init: %rcx
fini: %r8
rtld_fini: %r9
stack_end: stack. */
mov %RDX_LP, %R9_LP /* 设置参数rtld_fini */
#ifdef __ILP32__
mov (%rsp), %esi /* Simulate popping 4-byte argument count. */
add $4, %esp
#else
popq %rsi /* Pop argc */
#endif
/* 设置参数argv */
mov %RSP_LP, %RDX_LP
/* rsp对齐 */
and $~15, %RSP_LP
/* Push garbage because we push 8 more bytes. */
pushq %rax
/* Provide the highest stack address to the user code (for stackswhich grow downwards). */
pushq %rsp
#ifdef SHARED
/* 设置参数init和fini */
mov __libc_csu_fini@GOTPCREL(%rip), %R8_LP
mov __libc_csu_init@GOTPCREL(%rip), %RCX_LP
/* 设置参数main函数地址 */
mov main@GOTPCREL(%rip), %RDI_LP
/* 调用__libc_start_main()
__libc_start_main()进行一些构造工作, 然后调用main()
main() return到__libc_start_main之后 __libc_start_main会进行析构工作 */
call __libc_start_main@PLT
#else
/* Pass address of our own entry points to .fini and .init. */
mov $__libc_csu_fini, %R8_LP
mov $__libc_csu_init, %RCX_LP
mov $main, %RDI_LP
/* Call the user's main function, and exit with its value.
But let the libc call main. */
call __libc_start_main
#endif
hlt /* Crash if somehow `exit' does return. */
END (_start)
编译后的结果可以看的更加清楚, 用IDA反汇编结果如下
- 由此注册析构函数的关键点就在__libc_start_main()中
__libc_start_main()
这个函数定义在libc源码的libc-start.c文件中, 由于比较复杂, 因此只分析关键部分
- 首先是其参数列表也就是_start()传递的参数, 我们中重点注意下面三个
- init: ELF文件 也就是main()的构造函数
- fini: ELF文件 也就是main()的析构函数
- rtld_fini: 动态链接器的析构函数
static int __libc_start_main(
int (*main)(int, char **, char **MAIN_AUXVEC_DECL), //参数: main函数指针
int argc, char **argv, //参数: argc argv
ElfW(auxv_t) * auxvec,
__typeof(main) init, //参数: init ELF的构造函数
void (*fini)(void), //参数: fini ELF的析构函数
void (*rtld_fini)(void), //参数: rtld_fini ld的析构函数
void *stack_end //参数: 栈顶
)
{
...函数体;
}
- 进入函数体, __libc_start_mian()主要做了以下几件事
- 为libc保存一些关于main的参数, 比如__environ…
- 通过atexit()注册fini 与 rtld_fini 这两个参数
- 调用init为main()进行构造操作
- 然后调用main()函数
static int __libc_start_main(...)
{
/* 保存main的返回地址 */
int result;
//获取环境变量指针, 并保存到libc的.data中
char **ev = &argv[argc + 1];
__environ = ev;
/* 保存下栈顶 */
__libc_stack_end = stack_end;
...;
/* 初始化TLS */
__pthread_initialize_minimal();
/* 设置stack guard */
uintptr_t stack_chk_guard = _dl_setup_stack_chk_guard(_dl_random);
/* 设置pointer gurad */
uintptr_t pointer_chk_guard = _dl_setup_pointer_guard(_dl_random, stack_chk_guard);
...;
/* 注册动态链接器(ld.so.2)的析构函数 */
if (__glibc_likely(rtld_fini != NULL))
__cxa_atexit((void (*)(void *))rtld_fini, NULL, NULL);
/* 进行一些简单的libc初始化工作: 在libc中保存argc argv env三个参数 */
__libc_init_first(argc, argv, __environ);
/* 注册ELF的fini函数 */
if (fini)
__cxa_atexit((void (*)(void *))fini, NULL, NULL);
/* 如果ELF有构造函数的话, 那么先调用init() */
if (init)
(*init)(argc, argv, __environ MAIN_AUXVEC_PARAM);
...;
/* 调用main() */
result = main(argc, argv, __environ MAIN_AUXVEC_PARAM);
/* 如果main()返回后, __libc_start_main()回帮他调用exit()函数 */
exit(result);
}
至此我们知道libc_start_mian()会在exit_funcs中放入下面两个函数
- ELF的fini函数
- ld的rtld_fini函数
然后会调用一个构造函数:
- init()
我们分别分析这三个要素
被编译在elf的text段中, 由_start()传递地址给__libc_start_main()
就是一个空函数, 没什么用

让我们思考一个问题: 如果只有fini与init的话, ELF只能有一个构造/ 析构函数
当具有多个构造析构函数时改怎么办呢?
ELF的解决方法是, 把所有的构造函数的指针放在一个段: .init_array中, 所有的析构函数的指针放在一个段 .fini_array中


init就负责遍历.init_array, 并调用其中的构造函数, 从而完成多个构造函数的调用

我们说完了.init_array, 那么对于.fini_array呢?
很明显不是ELF的fini()负责 , 因为他就是一个空函数, 那么就只能由rtdl_fini来负责
rtdl_fini实际指向_dl_fini()函数, 源码再dl-fini.c文件中, 会被编译到ld.so.2中
但是为了不再源码中迷失, 我们首先需要搞明白_dl_fini()需要进行哪些工作
首先我们需要了解linux的共享库机制
- 假设程序A B都使用了printf函数
- 如果编译时都在在A.ELF B.ELF中写入printf的指令, 那么会造成空间上的浪费
- linux会把printf的指令写入libc.so.6中, 然后把libc分别映射到进程A 进程B的虚拟地址空间中
- 这样A B执行printf函数时, 实际只用了一份代码, 可以避免空间上的浪费
- 我们把进程空间中的一个单独文件, 称之为模块
- ld.so.2会通过dl_open()把所需文件到进程空间中, 他会把所有映射的文件都记录在结构体_rtld_global中
- 当一个进程终止, ld.so.2自然需要卸载所映射的模块, 这需要调用每一个非共享模块的fini_arrary段中的析构函数
- 一言以蔽之: _dl_fini()的功能就是调用进程空间中所有模块的析构函数
- Linux Namespaces机制提供一种资源隔离方案。
- 我们可以认为namespace就是一个进程的集合, 这个进程集合中可以看到相同的全局资源, 并与其他命名空间独立
- 这里不是重点, 了解这个概念可以帮助理解rtld结构体

接着来看_rtld_global结构体, 这个结构体很复杂, 我们只看与本文相关的
- _rtld_global一般通过宏GL来引用, 这个结构体定义在ld.so.2的data段中
#define GL(name) _rtld_global._##name
extern struct rtld_global _rtld_global __rtld_global_attribute__;
- 再看其结构体struct rtld_global的定义
- 一些缩写的含义:
- ns代表着NameSpace
- nns代表着Num of NameSpace
- struct rtld_global先以命名空间为单位建立了一个数组 _dl_ns[DL_NNS]
- 在每个命名空间内部加载的模块以双向链表组织, 通过_ns_loaded索引
- 同时每个命名空间内部又有一个符号表_ns_unique_sym_table, 记录着所有模块导出的符号集合
- 一些缩写的含义:
struct rtld_global
{
#define DL_NNS 16
struct link_namespaces
{
//每个模块用_ns_loaded描述, 这个命名空间中所映射的模块组成一个双向链表, _ns_loaded就是这个链表的指针
struct link_map *_ns_loaded;
/* _ns_loaded中有多少模块 */
unsigned int _ns_nloaded;
/* 映射模块的搜索表 */
struct r_scope_elem *_ns_main_searchlist;
/* This is zero at program start to signal that the global scope map is
allocated by rtld. Later it keeps the size of the map. It might be
reset if in _dl_close if the last global object is removed. */
size_t _ns_global_scope_alloc;
/* 这个命名空间中的符号表, 单个命名空间中的符号不允许重复 */
struct unique_sym_table
{
__rtld_lock_define_recursive(, lock) struct unique_sym
{
uint32_t hashval; //符号hash值
const char *name; //名称
const ElfW(Sym) * sym; //符号
const struct link_map *map; //所属模块
} * entries; //entries可以理解为struct unique_sym数组的指针, 通过entries[idx]就可找到第idx个符号
size_t size; //有多少个元素
size_t n_elements;
void (*free)(void *); //析构函数
} _ns_unique_sym_table;
/* 记录命名空间变化的, debug用 */
struct r_debug _ns_debug;
} _dl_ns[DL_NNS]; //一个命名空间一个link_namespace结构体
/* _dl_nns表示使用了多少个命名空间: Dynamic Link Num of NameSpace */
size_t _dl_nns;
...;
}
- 接着我们分析下struct link_map, 来看看ld是怎么描述每一个模块的
- ELF文件都是通过节的组织的, ld自然也延续了这样的思路,
- l_info中的指针都指向ELF中Dyn节中的描述符, Dyn中节描述符类型是ElfW(Dyn)
struct link_map
{
ElfW(Addr) l_addr; /* 模块在内存中的的基地址 */
char *l_name; /* 模块的文件名 */
ElfW(Dyn) * l_ld; /* 指向ELF中的Dynamic节 */
struct link_map *l_next, *l_prev; /* 双向链表指针 */
struct link_map *l_real;
/* 这个模块所属NameSapce的idx */
Lmid_t l_ns;
struct libname_list *l_libname;
/*
l_info是ELF节描述符组成的的数组
ELF中一个节, 使用一个ElfW(Dyn)描述
各个类型的节在l_info中的下标固定, 因此可以通过下标来区分节的类型
*/
ElfW(Dyn) * l_info[DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM + DT_VALNUM + DT_ADDRNUM];
const ElfW(Phdr) * l_phdr; /* ELF的头表 */
ElfW(Addr) l_entry; /* ELF入口点 */
ElfW(Half) l_phnum; /* 头表中有多少节 */
ElfW(Half) l_ldnum; /* dynamic节中有多少描述符 */
...;
}
- ElfW(Dyn)是一个节描述符类型, 宏展开结果为Elf64_Dyn, 这个类型被定义在elf.h文件中, 与ELF中的节描述对应
typedef struct { Elf64_Sxword d_tag; /* 便签, 用于标注描述符类型 */ union { Elf64_Xword d_val; /* 内容可以是一个值 */ Elf64_Addr d_ptr; /* 也可以是一个指针 */ } d_un; } Elf64_Dyn; - 至此rtld_global的结构就清楚了, 他自顶向下按照: 命名空间->模块->节 的形式描述所有的模块, 通过_ns_unique_sym_table描述命名空间中所有的可见符号
- 图示如下
理解了模块是如何组织的之后, _dl_fini的任务就显而易见了:
- 遍历rtld_global中所有的命名空间
- 遍历命名空间中所有的模块
- 找到这个模块的fini_array段, 并调用其中的所有函数指针
- 找到这个模块的fini段, 调用
void internal_function _dl_fini(void)
{
#ifdef SHARED
int do_audit = 0;
again:
#endif
for (Lmid_t ns = GL(dl_nns) - 1; ns >= 0; --ns) //遍历_rtld_global中的所有非共享模块: _dl_ns[DL_NNS]
{
__rtld_lock_lock_recursive(GL(dl_load_lock)); //对rtld_global上锁
unsigned int nloaded = GL(dl_ns)[ns]._ns_nloaded;
/* 如果这个NameSapce没加载模块, 或者不需要释放, 就不需要做任何事, 就直接调用rtld中的函数指针释放锁 */
if (nloaded == 0 || GL(dl_ns)[ns]._ns_loaded->l_auditing != do_audit)
__rtld_lock_unlock_recursive(GL(dl_load_lock));
else //否则遍历模块
{
/* 把这个命名空间中的所有模块指针, 都复制到maps数组中 */
struct link_map *maps[nloaded];
unsigned int i;
struct link_map *l;
assert(nloaded != 0 || GL(dl_ns)[ns]._ns_loaded == NULL);
for (l = GL(dl_ns)[ns]._ns_loaded, i = 0; l != NULL; l = l->l_next) //遍历链表
if (l == l->l_real) /* Do not handle ld.so in secondary namespaces. */
{
assert(i < nloaded);
maps[i] = l;
l->l_idx = i;
++i;
/* Bump l_direct_opencount of all objects so that they are not dlclose()ed from underneath us. */
++l->l_direct_opencount;
}
...;
unsigned int nmaps = i; //多少个模块
/* 对maps进行排序, 确定析构顺序 */
_dl_sort_fini(maps, nmaps, NULL, ns);
//释放锁
__rtld_lock_unlock_recursive(GL(dl_load_lock));
/* 从前往后, 析构maps中的每一个模块 */
for (i = 0; i < nmaps; ++i)
{
struct link_map *l = maps[i];
if (l->l_init_called)
{
/* Make sure nothing happens if we are called twice. */
l->l_init_called = 0;
/* 是否包含fini_array节, 或者fini节 */
if (l->l_info[DT_FINI_ARRAY] != NULL || l->l_info[DT_FINI] != NULL)
{
/* debug时打印下相关信息 */
if (__builtin_expect(GLRO(dl_debug_mask) & DL_DEBUG_IMPCALLS, 0))
_dl_debug_printf("\ncalling fini: %s [%lu]\n\n",DSO_FILENAME(l->l_name),ns);
/* 如果有fini_array节的话 */
if (l->l_info[DT_FINI_ARRAY] != NULL)
{
/*
l->l_addr: 模块l的加载基地址
l->l_info[DT_FINI_ARRAY]: 模块l中fini_array节的描述符
l->l_info[DT_FINI_ARRAY]->d_un.d_ptr: 模块l中fini_arrary节的偏移
array: 为模块l的fini_array节的内存地址
*/
ElfW(Addr) *array = (ElfW(Addr) *)(l->l_addr + l->l_info[DT_FINI_ARRAY]->d_un.d_ptr);
/*
ELF中 fini_arraysz节用来记录fini_array节的大小
l->l_info[DT_FINI_ARRAYSZ]: 模块l中fini_arraysz节描述符
l->l_info[DT_FINI_ARRAYSZ]->d_un.d_val: 就是fini_array节的大小, 以B为单位
i: fini_array节的大小/一个指针大小, 即fini_array中有多少个析构函数
*/
unsigned int i = (l->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof(ElfW(Addr)));
while (i-- > 0) //从后往前, 调用fini_array中的每一个析构函数
((fini_t)array[i])();
}
/* 调用fini段中的函数 */
if (l->l_info[DT_FINI] != NULL)
DL_CALL_DT_FINI(l, l->l_addr + l->l_info[DT_FINI]->d_un.d_ptr);
}
...;
}
/* Correct the previous increment. */
--l->l_direct_opencount;
}
}
}
...;
}
rtdl_fini()带来的可利用点
rtdl_fini()十分依赖与rtld_global这一数据结构, 并且rtld_global中的数据并没有被加密, 这就带来了两个攻击面
- 劫持rtld_global中的锁相关函数指针
- 修改rtld_global中的l_info, 伪造fini_array/ fini的节描述符, 从而劫持fini_array/ fini到任意位置, 执行任意函数
劫持rtld_global中的函数指针
ld相关函数在使用rtld_global时都需要先上锁, 以避免多进程下的条件竞争问题
相关函数包括但不限于:
- _dl_open()
- _dl_fini()
- ….
上锁操作是通过宏进行的, 我们将其展开
- 宏定义:
# define __rtld_lock_lock_recursive(NAME) GL(dl_rtld_lock_recursive) (&(NAME).mutex) # define GL(name) _rtld_global._##name - 宏展开
__rtld_lock_lock_recursive(GL(dl_load_lock)); //对rtld_global上锁
=> GL(dl_rtld_lock_recursive) (& GL(dl_load_lock).mutex)
=> _rtld_global.dl_rtld_lock_recursive(&_rtld_global.dl_load_lock.mutex)
可以看到实际调用的是dl_rtld_lock_recursive函数指针
释放锁的操作也是类似的, 调用的是_dl_rtld_unlock_recursive函数指针, 这两个函数指针再rtld_global中定义如下
struct rtld_global
{
...;
void (*_dl_rtld_lock_recursive)(void *);
void (*_dl_rtld_unlock_recursive)(void *);
...;
}
动态调试中可以看的更清楚:
并且ld作为mmap的文件, 与libc地址固定
也就是说, 当有了任意写+libc地址后, 我们可以通过覆盖_rtld_global中的lock/ unlock函数指针来getshell
劫持l_info伪造fini_array节
我们的目标是伪造rtld_global中关于fini_array节与fini_arraysize节的描述
将fini_array节迁移到一个可控位置, 比如堆区, 然后在这个可控位置中写入函数指针, 那么在exit()时就会依次调用其中的函数指针
l_info中关于fini_array节的描述符下标为26, 关于fini_arraysz节的下标是28, 我们动态调试一下, 看一下具体内容


可以发现, l_info中的指针正好指向的就是Dynamic段中相关段描述符

此时我们就可以回答ELF中fini_array中的析构函数是怎么被调用的这个问题了:
- exit()调用__exit_funcs链表中的_rtdl_fini()函数, 由_rtdl_fini()函数寻找到ELF的fini_array节并调用
假设我们修改rtld_global中的l_info[0x1a]为addrA, 修改l_info[0x1c]为addrB
那么首先再addrA addrB中伪造好描述符
addrA: flat(0x1a, addrC)
addrB: flat(0x1b, N)
然后在addrC中写入函数指针就可以在exit时执行了
fini_array与ROP
当我们可以劫持fini_array之后, 我们就具备了连续调用多个函数的能力, 那么有无可能像ROP一样, 让多个函数进行组合, 完成复杂的工作?
我们首先需要从汇编层面考察下fini_array中的函数是怎么被遍历并调用的, 因为这涉及到参数传递问题
我们可以看到在多个fini_array函数调用之间, 寄存器环境十分稳定, 只有: rdx r13会被破坏, 这是一个好消息
考察执行call时的栈环境, 我们发现rdi总是指向一个可读可写区域, 可以当做我们函数的缓冲区
那么就已经有了大致的利用思路,
我们让fini_array先调用gets()函数, 在rdi中读入SigreturnFrame
然后再调用setcontext+53, 即可进行SROP, 劫持所有寄存器
如果高版本libc, setcontext使用rdx作为参数, 那么在gets(rdi)后还需要一个GG, 能通过rdi设置rdx,
再执行setcontext
劫持fini
fini段在l_info中下标为13,这个描述符中直接放的就是函数指针, 利用手法较为简单, 但是只能执行一个函数, 通常设置为OGG


例如我们可以修改rtld_global中l_info[0xd]为addrA, 然后再addrA中写入
addrA: flat(0xd, OGG)
就可以在exit()时触发OGG
exit()与FILE
还记得一开始的run_exit_handlers么, 在遍历完exit_funcs链表后, 还有最后一句
if (run_list_atexit) //调用_atexit
RUN_HOOK(__libc_atexit, ());
__libc_atexit其实是libc中的一个段

这个段中就是libc退出时的析构函数
其中默认只有一个函数fcloseall()

- 这个函数会调用_IO_cleanup()
int __fcloseall (void) { /* Close all streams. */ return _IO_cleanup (); } - _IO_cleanup()会调用两个函数
- _IO_flush_all_lockp()会通过_IO_list_all遍历所有流, 对每个流调用_IO_OVERFLOW(fp), 保证关闭前缓冲器中没有数据残留
- _IO_unbuffer_all()会通过_IO_list_all遍历所有流, 对每个流调用_IO_SETBUF(fp, NULL, 0), 来释放流的缓冲区
int _IO_cleanup(void)
{
/* 刷新所有流 */
int result = _IO_flush_all_lockp(0);
/* 关闭所有流的缓冲区 */
_IO_unbuffer_all();
return result;
}
- 那么至此我们又发现一个攻击点, 可以通过劫持流的虚表中的overflow函数为system, 在fp头部写入/bin/sh, 就可以在exit()关闭流时getshell
- 这里只是一个抛砖引玉, 更多的内容就是FSOP相关的了
总结
- 整个exit流程如下
- 相关利用手法
- 劫持ld中rtld_global结构体的_dl_rtld_unlock_recursive/_dl_rtld_lock_recursive
- 劫持ld中rtld_global结构体的l_info中关于fini_array / fini 的描述符, 从而伪造一个析构函数节
- 如果可写入的话: 劫持ELF中fini_array节
- 劫持流的虚表中overflow函数指针, 在fcloseall()时触发







发表评论
您还未登录,请先登录。
登录